AlexNet 논문을 읽고 팀원 및 멘토님과 나누었던 이야기를 정리한다.
Data 전처리
rescale과 crop
논문에서 256*256 size의 입력 이미지를 만들기 위해 rescale 후 center crop을 하였다고 언급하였다. 각각의 처리가 어떤 특징을 가지는지 살펴보았다.
rescale만 하는 경우에는 이미지를 압축해야 하기 때문에 정보의 소실이 많을 수 있다.center crop만 하는 경우에는 원하는 object가 crop된 이미지에 포함되는 것을 보장할 수 없다.
두 연산의 단점을 보완하고 고정된 크기의 입력 데이터를 만들기 위해 rescale 후 center crop을 사용한 것으로 보인다.
정규화
논문에서는 training set의 밝기 평균을 빼주었다고만 언급하고 있다. 구체적인 설명이 없어서 batch 별로 계산을 한 것인지, 데이터 별로 한 것이지는 알 수 없다. 밝기 값을 빼주는 것은 0~255인 각 픽셀 값을 평균 밝기가 0이 되도록 분포를 옮기는 것을 의미한다.
평균이 0이 되도록 하는 이유는 입력 값이 너무 클 경우 gradient exploding 현상이 발생할 수 있기 때문이다. 기울기가 점차 커져 결국 발산하게 되는 현상이다. 이를 방지하기 위해 일반적으로는 평균을 빼고 표준편차로 나누는 정규화 방법을 사용한다. 표준편차로 나누지 않은 이유는 알 수 없지만 정규화의 방법이라고 생각하면 될 것 같다.
ReLU 함수
Non-Saturating
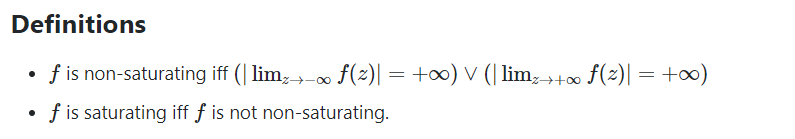
Non- Saturating 함수는 양의 무한대 또는 음의 무한대로 x가 이동할 때 함수값이 수렴하지 않는 함수를 말한다. ReLU 함수의 경우 양의 무한대로 x가 이동할 때 함수값이 양의 무한대로 발산하므로 non-saturating 함수이다.
sigmoid, tanh와 같은 saturating 함수는 모델의 층이 깊어지면 기울기가 0이 되어 더이상 학습이 되지 않는 gradient vanishing 문제가 발생한다.
학습 속도
AlexNet에서 ReLU를 사용한 주 목적은 학습 속도 가속이다. ReLU는 최대 기울기가 1로 0.25인 sigmoid 함수보다 훨씬 큰 값을 가진다. 또한 max 연산 하나만 수행하면 되어 속도가 빠르다.
Local Response Normalization
Local Response Normalization(LRN)은 AlexNet에서 사용한 특이한 normalization 방법이다. 하지만 이후 논문에서 증명이 안된 잘못된 방법이라는 것이 밝혀졌다고 한다. 현재는 LRN이 아니라 Batch Normalization을 사용한다.
Overlapping Pooling 과 Overfitting
가장 많은 이야기를 나눈 부분이다. 논문에서도 마지막 한줄로 가볍게 언급하고 넘어간 부분이라 서로 이해한 것에 큰 차이가 있었다.
Overfitting이란?
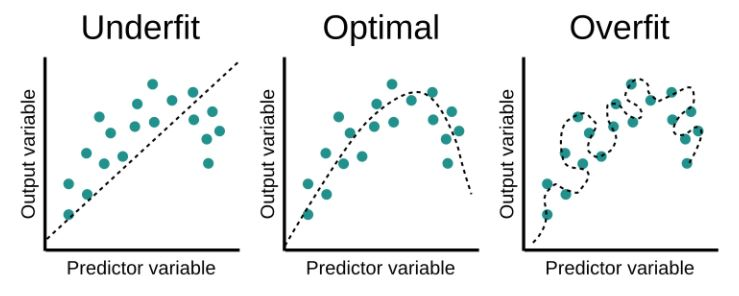
Overfitting은 위의 그림과 같이 학습 데이터를 과하게 학습한 경우를 의미한다. 학습 데이터에 대한 정확도는 매우 높으나, 테스트 데이터에서는 잘 작동하지 않는다. 보통 학습 데이터가 부족하거나 데이터 특성에 비해 모델이 너무 복잡한 경우 발생한다.
Data reduction 관점
Overfitting을 해결하는 가장 쉬운 방법은 데이터를 늘리는 것이다. 데이터가 너무 적으면 원하는 object의 특징이 아닌 noise, 해당 데이터의 특정 패턴을 학습할 확률이 높다. 따라서 데이터를 늘려서 원하는 object의 일반적인 패턴을 학습할 수 있게하여 overfitting을 방지하는 것이다.

Overwrapping Pooling은 overfitting을 방지하는 역할을 할 수 있다. 위의 예시와 같이 Pooling을 사용하면 비슷하지만 다른 데이터들이 모델 내부에서 같은 데이터로 처리 될 수 있다. 이는 결국 데이터의 양이 감소하는 것과 같은 효과로 overfitting을 유발할 수 있는 것이다. 반면 Overwrapping Pooling은 모두 다른 데이터로 인식한다. 논문에서 언급한 Overwrapping Pooling이 Overfitting을 어렵게 한다는 의미는 아마 이런 관점에서의 설명이라고 추측해본다.
parameter 관점
모델의 parameter 수가 많을수록 Overfitting을 유발할 수 있다. 데이터 특성에 비해 모델이 너무 복잡해질 수 있기 때문이다. Pooling은 parameter 수를 줄이기 위해 필요 없는 값을 버리고, 필요한 값만 뽑아서 압축하는 과정이다.
같은 Pooling unit size(z)를 사용하였을 때 결과로 나오는 데이터는 overwrapping pooling이 그냥 pooling보다 크다. 따라서 사용해야 하는 parameter 수도 많아진다. 이런 관점에서는 overwrapping pooling이 일반 pooling보다 overfitting을 방지하는 효과가 있다고 보기 어렵다.
Test time augmentation
AlextNet은 테스트에서도 하나의 이미지를 5개로 crop하여서 결과를 만들고, 그 결과들을 합쳐서 추론을 한다. 이러한 테스트 방법은 모델의 불확실성을 추정할 수 있게 하는 장점이 있다.
일반적으로 모델을 서비스할 때는 모델이 추론한 값이 정답인지 확인할 수 없는 경우가 많다. labeling이 되지 않은 값이 입력으로 들어오기 때문이다. 이러한 경우에 모델이 추론한 결과를 얼마나 신뢰해도 되는지 판단할 수 있는 수치가 불확실성이다. AlexNet과 같이 하나의 이미지를 5개로 늘려서 테스트를 진행한다면, 5개의 이미지 결과 값의 차이를 불확실성 추정에 사용할 수 있다. 즉 5개 결과의 varience를 불확실성 추정 방법으로 사용하는 것이다.
이렇게 추정한 불확실성은 모델을 평가하는 수치로 사용될 수도 있다. 만약 어떤 카테고리만 불확실성이 높다면 해당 카테고리만 더 학습을 시키는 등 모델 성능 개선을 위한 여러 전략을 세울 수 있게 된다.
참고
- non-saturating : https://stats.stackexchange.com
- Overfitting : https://wikidocs.net/152777
- Overwrapping Pooling : https://stats.stackexchange.com
