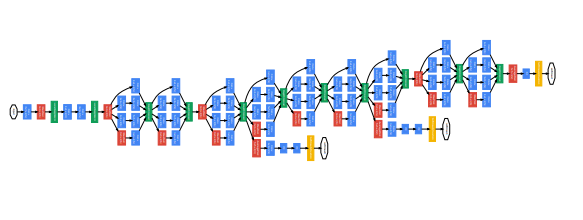
논문 : Going Deeper With Convolutions
Abstract
본 논문은 ImageNet Large-Scale Visual Recognition Challenge 2014(ILSVRC14)에서 classification과 detection을 위한 최신 기술인 Deep Convolutional neural network architecture를 제안한다. 해당 구조는 Inception이라 불린다.
NetWork 내부 자원 활용을 개선하여 깊고 넓은 모델을 연산 추가 없이 가능하게 한 것이 주요 특징이다.
최적화에는 Hebbian principle과 multi-scale processing을 사용하였다.
Hebbian Principle
뉴런간 weight를 결정, 조정하는 원칙이다.
- 2개의 뉴런이 동시에 활성화되면 Weight를 증가시킨다.
- 2개의 뉴런이 따로 활성화되면 Weight를 감소시킨다.
ILSVRC14에 제출한 22층의 깊은 네트워크를 GoogLeNet이라고 부른다.
Introductin
CNN의 발전으로 image recognition과 object detection은 크게 발전했다. 이러한 발전은 powerful한 하드웨어, 거대한 dataset, 커진 model뿐만 아니라 새로운 아이디어, 알고리즘, 개선된 network architecture 덕분이다. GoolgLeNet은 ILSVRC 2014의 이전 우승 모델보다 12배 적은 파라미터 개수를 가지지만 더 정확하다. Object detection은 deep architecture과 기존의 computer vision의 시너지 덕분에 크게 발전하였다.
모바일 및 임베디드 컴퓨터에서 전력과 메모리 사용 알고리즘 효율성이 더욱 중요해지고 있음도 주목할만하다. inference time에서의 multiply-adds(곱, 덧셈으로 이루어진 연산) 연산이 1.5 billion번을 넘지 않도록 모델을 설계하여 단순히 학문적으로 끝나는 것이 아니라 실제 real world에서 사용할 수 있게 했다.
이 논문에서는 효율적인 deep neural network architecture(Inception)에 집중한다. 여기서 Deep은 2가지 의미로 사용된다. 먼저 Inception 모듈이라는 새로운 구조를 제안하는 것을 의미한다. 두번째로는 말 그대로 network의 deapth가 깊다는 것을 의미한다. 이 구조의 장점은 ILSVRC 2014 calssification and detection challenges에서 현재 가장 좋은 성능을 보여주는 모델을 능가하는 성능을 보여주는 것으로 증명되었다.
Related Work
-
CNN 구조와 최근 트렌드
LeNet-5 이후로 CNN의 일반적인 구조는 Convolutional layer를 쌓은 뒤 1개 이상의 fully-connected layer를 사용하는 것이다. 최근 MNIST 같이 큰 데이터 셋에 대한 트렌드는 dropout을 사용해 오버피팅을 해결하면서layer의 개수와 size를 늘리는 것이다. -
Network-in-Network
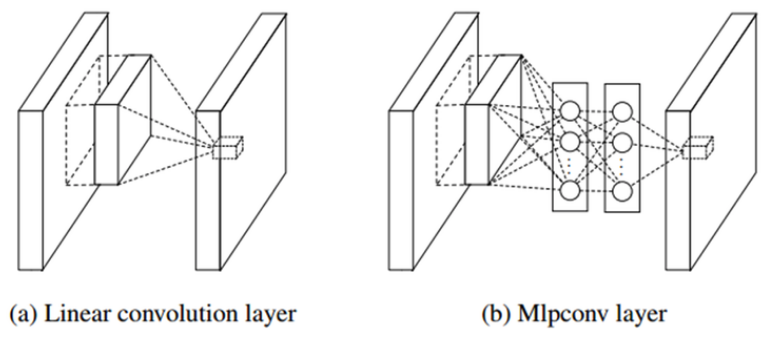
Network-in-Network는 네트워크의 표현력을 증가시키기 위해 Lin이 제안한 방법이다. 이 방법을 Convolution layer에 적용하면 1×1 convolution layer를 적용한 것과 같다.
GoogLeNet은 1×1 convolution layer를 2가지 목적으로 사용한다.1. 계산 병목 제거를 위한 차원 축소 모듈 2. 네트워크 depth와 width를 성능 패널티 없이 늘리기 위함
Network-in-Network
Convolution을 할 때 Filter대신 MLP를 사용하여 Feature를 추출하는 방법이다.
- Object Detection
Object detection에 주로 사용하는 방법은R-CNN이다. R-CNN은 객체가 있을 것으로 추정하는bounding box를 찾는 일과 찾은 bounding box의이미지를 분류하는 CNN으로 나뉜다. 본 논문은 유사한 pipeline을 사용하지만 더 정확한 객체 bounding box 찾기와 이미지 분류 방법을 탐색한다.
Motivation and High Level Considerations
-
network size늘리기
network의 성능을 개선하는 가장 쉬운 방법은 size(depth, width)를 늘리는 것이다. 그러나 이 방법은 2개의 큰 문제가 있다.- 파라미터가 많아져
overfitting으로 이어진다.
training set이 적을 때 더 큰 문제가 된다. 하지만 좋은 training set을 만드는 것은 어렵고 비용이 많이 든다. 따라서 아주 큰 bottleneck이 될 수 있다.
- network size를 균등하게 늘리면
연산이 크게 증가한다.
convolutional layer에서 filter 크기를 늘리면 연산량은 quadratic하게 증가한다. 만약 weight가 0에 가까워지면, 많은 연산이 낭비된다. 연산 자원은 언제나 제한되어 있기에 네트워크 크기를 늘리는 것보다자원의 효율적 분배가 중요하다.
- 파라미터가 많아져
위의 두가지 문제를 해결하는 가장 좋은 방법은 convolution 안까지 fully connected layer를 saparsely connected architecture로 변경하는 것이다. 만약 dataset의 확률 분포를 알 수 있다면, 최적의 네트워크는 마지막 layer의 값의 상관관계를 분석하여 관련 높은 뉴런끼리 클러스터링하여 얻을 수 있다.
-
sparse 연산의 비효울성
오늘날의 컴퓨터는 균일하지 않은 sparse data 계산에 매우 비효율적이다. lookup 오버헤드와 cache miss는 sparse matrix가 성공하지 못하는 큰 이유이다. 여러 논문에서는 sparse matrix 연산을 상대적으로 dense한 submatrices로 나누어 계산하면 좋은 성능을 보인다고 제안한다. -
Inceptionarchitecture
Inception architecture는 위에서 언급한 approximate sparse matrix의 case study로 시작되었다. learning rate, 하이퍼 파라미터 조정, 학습 방법 개선 등을 한 결과 localization과 object detection에서 좋은 효과를 보였다.
Architectural Details
-
Inception architecture
Inception architecture는 CNN에서최적의 local sparse구조를 찾고, 이 구조를dense components로 바꾸는 것이 주요 아이디어이다. 최적의 local sparse 구조를 반복하면되기 때문이다.
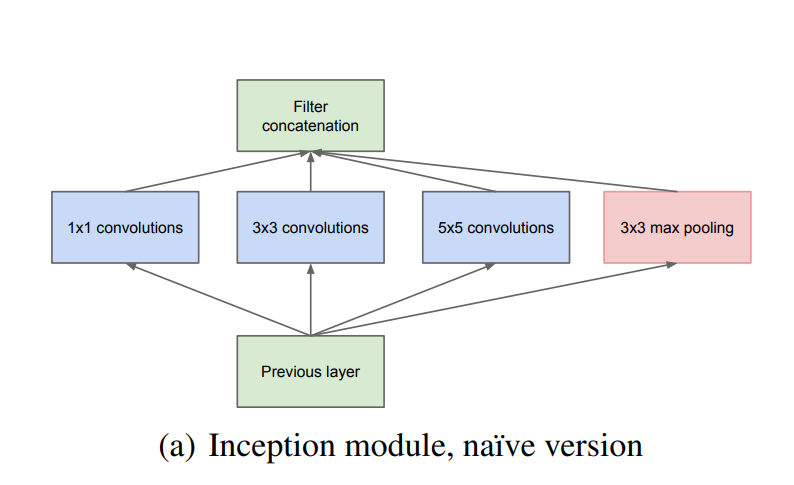
편리를 위해 filter를1×1,3×3,5×5크기로 제한하여 사용한다. Filter들을 병력적으로 convolution하고 합쳐서 하나의 출력 벡터를 만든다. CNN에서 pooling layer은 필수적이므로 추가한다. -
Naive version의 문제점
위에서 설명한 Inception은 naive version이다. High-level feature을 추출하기 위해서는 깊은 layer에서만 추출이 가능하다. 하지만 layer가 깊게 쌓일 수록 5×5 convolution 연산은 연산량을 매우 크게 만드는 문제가 발생한다. -
1×1 Convolution layer
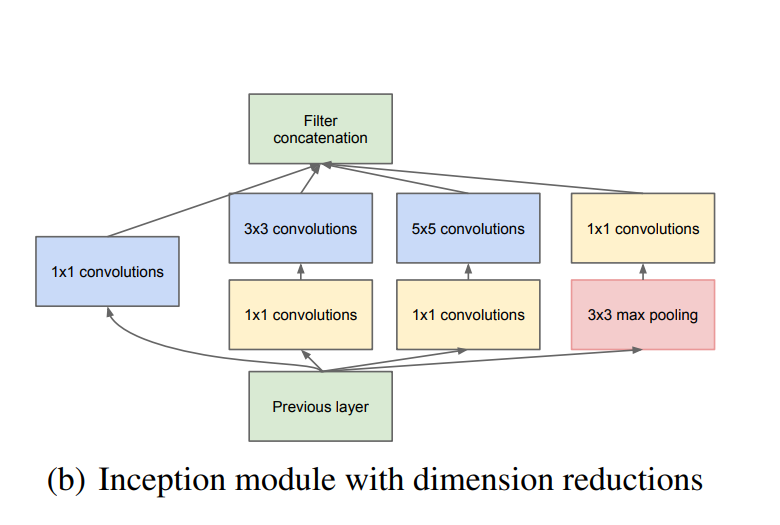
층을 쌓을 때 연산량이 과하게 늘어나는 것을 방지하기 위해 1×1 convolution layer를 사용한다. 1×1 convolution으로 차원을 축소하여 3×3, 5×5 convolution layer의 연산량을 줄인다. 1×1 convolution 후 ReLU를 적용하여 비선형성을 늘리는 장점도 있다. -
Inception architecture의 장점
학습 기간에서 메모리 효율을 위해 lower layer에서는 전통적인 CNN을 사용하고, Inception은 higher layer에서 사용하는 것이 좋다.
Inception은 각 단계에서 unit 개수를 과한 연산량 증가 없이 늘릴 수 있도록 한다. Inception은 이미지를 다양한 scale로 처리하기 한 후에 합치기 때문에 동시에 다양한 크기의 feature를 추출할 수 있다는 장점도 있다.
GoogLeNet
-
GoogLeNet
GoogLeNet은 Inception 구조의 한 형태로 ILSVRC14에 제출한 모델이다. 성능은 살짝 낮지만 앙상블 기법을 사용하면 성능을 개선할 수 있다. 224×224 크기의 RGB 채널 이미지를 mean subtraction을 해서 입력으로 받는다. 모든 convolution 연산 뒤에는ReLU를 적용한다.
파라미터가 없는 pooling layer를 제외하면22 layer이고 총 100여개의 unit으로 구성된다. -
Auxiliary classifier
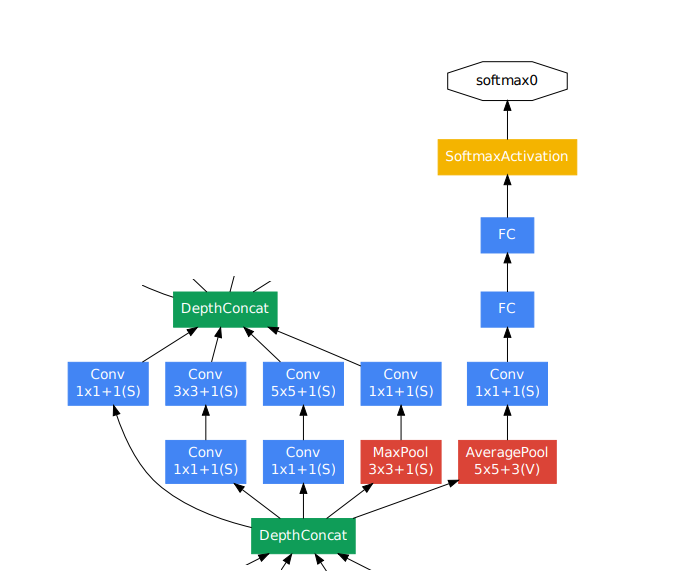
Large depth는 back propagation에서 gradient 전달을 어렵게 만든다. 흥미로운 점은 shallower network가 좋은 성능을 낸다는 것이다. 즉 중간층에서 만드는 feature가 매우discriminative하다는 것을 알 수 있다. 따라서 중간에 auxiliary claasifers를 연결하여 역전파되는gradient를 증가시키고,regularization효과가 나타나도록 하였다. Loss에는 0.3이 곱해진 값이 더해진다. 이후 inference에서는 사용하지 않는다. -
출력 부분
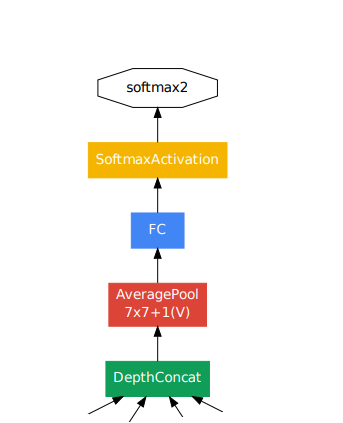
최종 classifier 전에 average pooling layer를 사용한다.Global Average Pooling을 사용한 것으로 각 feature를 하나의 값으로 만들어 결과를 1차원 벡터로 만들어 준다. Average pooling은fine-tuning을 쉽게 만든다. Average pooling을 사용하는 것이 fully connected layer를 사용하는 것보다 성능을 향상시켰지만, dropout은 average pooling에서도 필수적이었다.Global Average Pooling
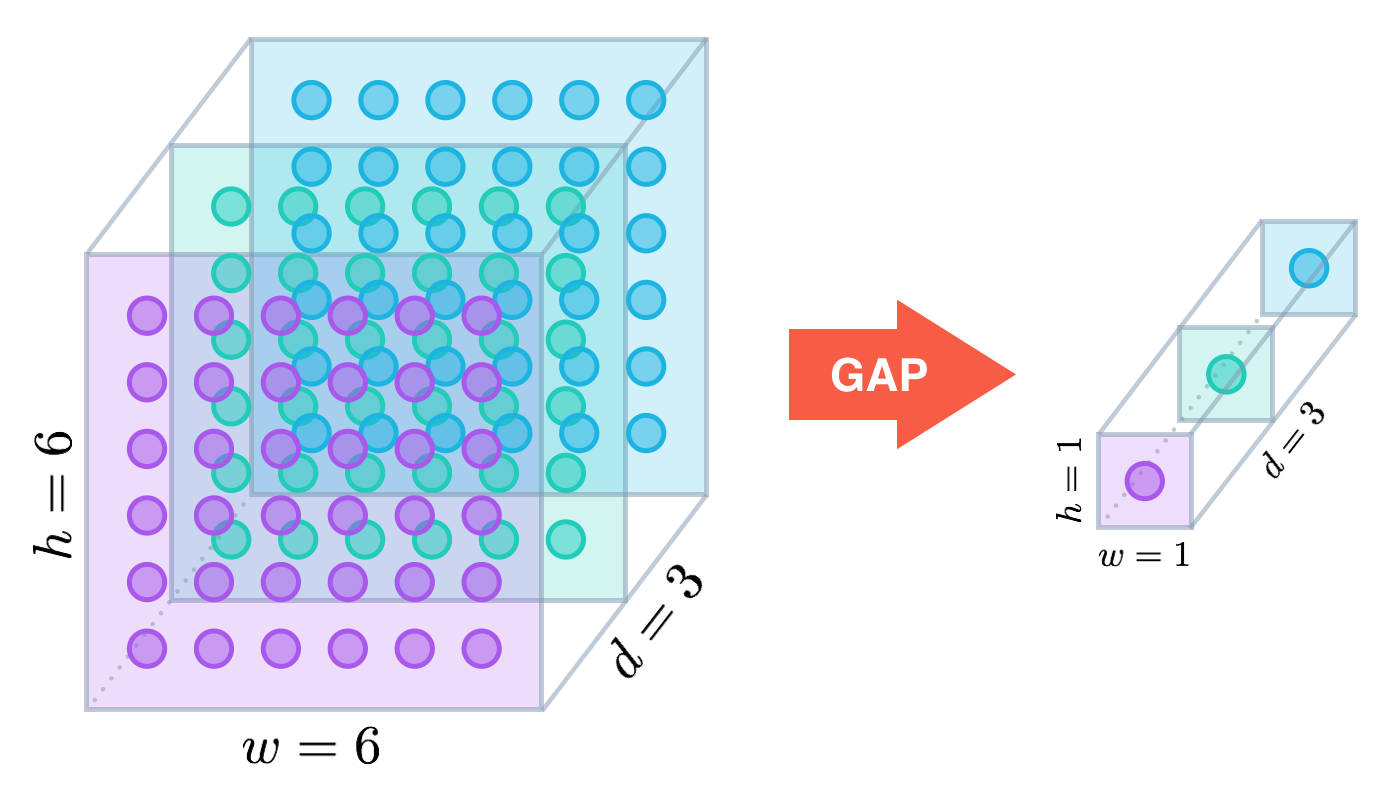
-
전체 구조
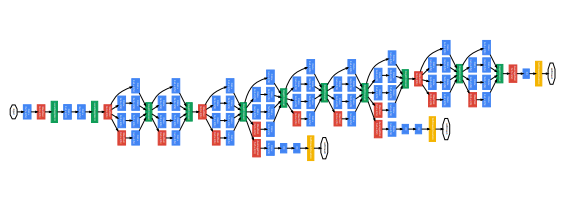
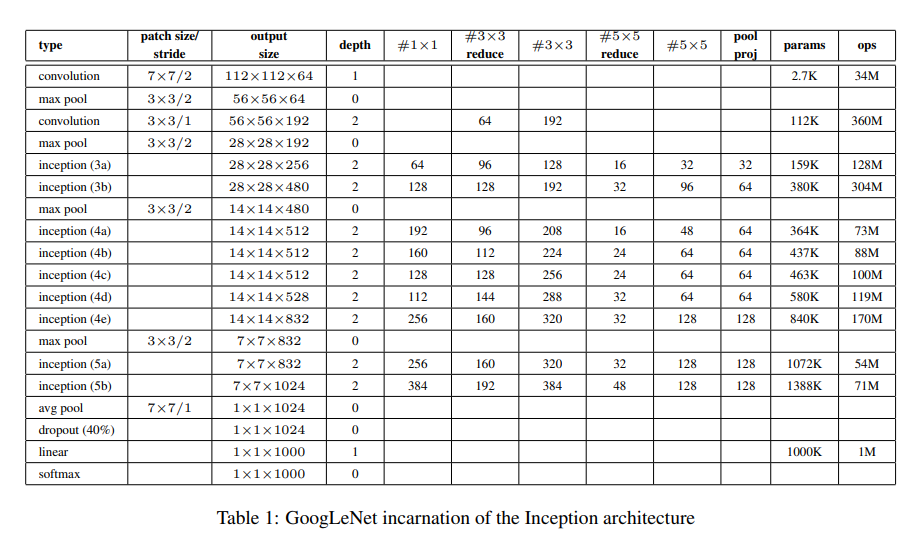
Training Methodology
-
학습 방법
분산처리를 사용하였으며, optimizer로asynchronous stochastic gradient descent를 사용하였다. 8 epoch마다 learning rate가 4% 갑소한다. -
sampling 방법
Image sampling method는 학습 중 계속 변경되었다. 이는 dropout, learning rate등 하이퍼파라미터의 변경과 동시에 이루어졌기 때문에 효율적인 학습을 위한 가이드를 제공하기는 어렵다. 그러나 전체 이미지의 8%~100% 크기의 이미지를 사용하고, 종횡비를 3/4과 4/3 사이로 사용하는 것이 효과적으로 보여진다. -
Overfitting 방지
Photometric distortion로 데이터를 늘려 overfitting을 방지했다.
ILSVRC 2014 Classification Challenge Setup and Results
-
aggressive crop
external data를 사용하지 않고 aggressive cropping 기법을 사용하였다. 먼저 이미지의 짧은 쪽이 256,288,320,252가 되도록 resize한다. 그 후 각 이미지에서 왼쪽, 가운데, 오른쪽 사가형을 가져온다. 가져온 이미지의 코너 4개와 가운데에서 224*224 크기를 crop하고 원래 이미지를 244*244로 resize하여 총 6개의 이미지를 얻는다. 마지막으로 모든 이미지에 mirrored version을 만들어 추가한다.하나의 이미지로 4×3×6×2개의 이미지를 만들 수 있다.
-
number of models
7개의 독립적인 모델을 만들어 사용하였다. 모두 같은 GoogLeNet 모델이지만 sampling 방법과 input 순서만 다르다. 7개의 모델의 softmax를 평균내서 예측한다. -
결과
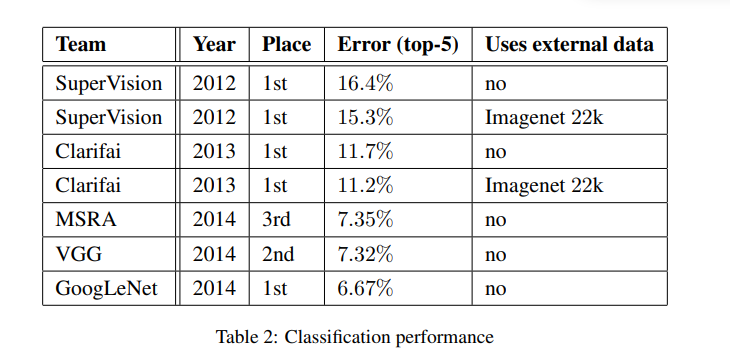
별도의 training data를 활용하지 않았지만 1위를 차지하였다.
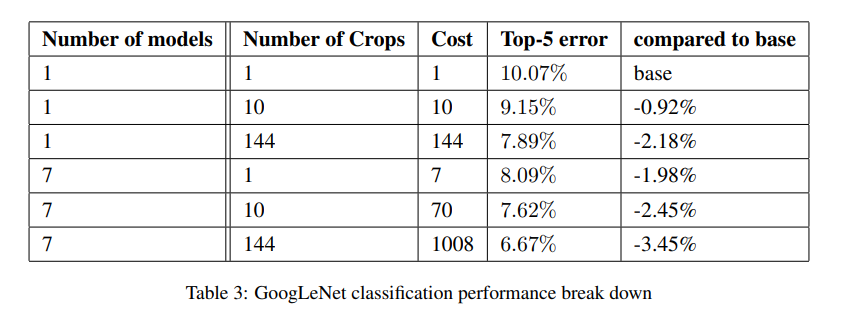
앙상블과 crop개수에 따른 모델 성능이다. Crop한 이미지가 많고 앙상블한 모델 수가 많은 경우 가장 좋은 성능을 보인다.
ILSVRC 2014 Detection Challenge Setup and Results
-
ILSVRC 2014 Detection Challenge
ILSVRC detection은 200개 class의 객체의bounding box를 만드는 문제이다. Bounding box가 정답과 최소 50% 겹치고, class를 맞게 분류하는 경우 정답으로 여긴다. Classification 문제와는 다르게 각 이미지는 object가 많거나 아예 없을 수도 있고 scale도 매우 다르다.Mean average precision(mAP)로 평가한다.Mean average precision(mAP)
Objeect Detection의 성능 평가 방법이다.
- Precision (정밀도) : 검출 결과 중 옳게 검출한 비율
- Recall (재현율) : 검출해야하는 객체 중 제대로 검출한 비율
recall에 대응하는 precision의 평균을 average Precision이라고 한다. -
GoogLeNet Object Detection
객체 검출 후에 CNN을 사용하여 classification을 하는 R-CNN과 비슷한 과정을 사용한다. 시간이 부족하여bounding box regression은 하지 않았다.- region proposal step
Selective Search+multi-box prediction을 사용한다.false positive(틀린 검출)를 줄이기 위해 superpixel의 크기를 2배로 사용하여 selective search의 결과를 반으로 줄인다. 그 결과 single model에서 mAP가 1% 상승하였다. - region classification
Inceptin Model사용하여 region classification을 하였다. 6개의 ConvNet을 ensemble한 결과 accuracy가 40에서 43.9까지 개선되었다.
- region proposal step
-
결과
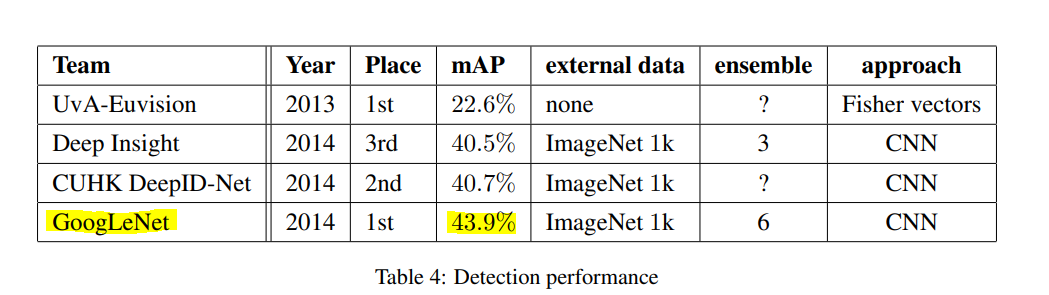
2013년과 비교하여 object detection accuracy가 2배가 되었다.
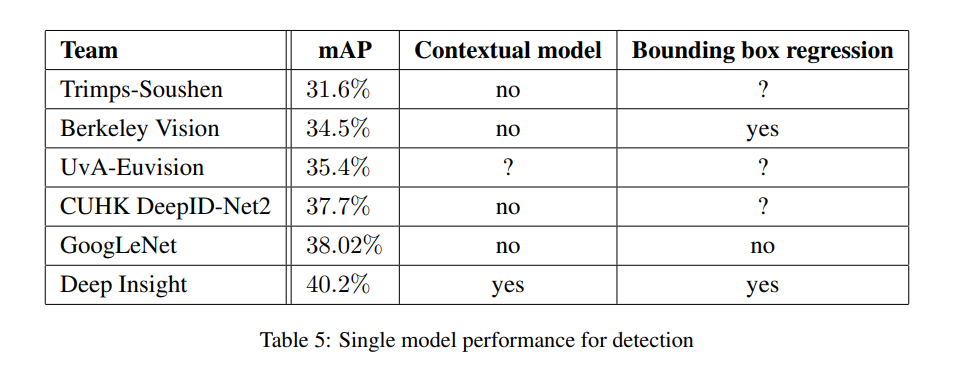
single model의 성능만 비교하면Deep Insight가 더 높은 성능을 보인다. 하지만 Deep Insight는 ensemble했을 때0.3%만 성능이 증가한다. 반면 GoogLeNet은 ensemble 했을 때 성능이 크게 증가한다.
Conclusions
-
최적의 sparse structure를 dense building block으로 근사하는 방법이
neural network의 성능 개선에 사용할 수 있는 방법임을 증명했다. (연산량은 조금 늘고, 성능을 상당히 향상시켰다.) -
object detection에 context 고려, bounding box regression을 하지 않고도 경쟁력을 보여줬다. 이는
Inception Architecture이 강점이 있음을 보여준다. -
비슷한 depth와 width를 가지는 expensive 모델로도 비슷한 성능을 기대할 수 있다. 하지만
sparser achitecture를 사용하는 것이 일반적으로 실현가능하고 유용한 아이디어이다.
참고
- hebbian principle : https://en.wikipedia.org/wiki/Hebbian_theory
- Network-in-Network : https://oi.readthedocs.io
- mAP : https://lapina.tistory.com/98
- global average pooling : https://kobiso.github.io/research/research-NIN/
