논문 링크 : Very Deep Convolutional Networks for Large-Scaled Image Recognition
Abstract
-
large-scale image recognition의 정확도(accuracy)에
네트워크의 깊이가 미치는 영향을 조사한다. -
Main Contiribution
3×3의 작은 convolution filter를 사용하여 점점 깊어지는 network를 평가하여, 깊이가 16~19 layer일때 이전 구조보다 개선 가능함을 보였다. -
ImageNet Challenge 2014의 localisation과 classification에서 1등과 2등을 차지했다.
Introduction
-
최근 ConvNet
최근 ConvNet은 large-scale image and video recognition에서 큰 성공을 보였다. AlextNet을 개선하여 더 좋은 Accuracy를 얻으려는 다양한 시도가 있었다. (첫번째 층에서 작은 receptive과 stride 사용 ... ) -
Network Depth
이 논문에서는 ConvNet의 중요한 요소인Depth를 다룬다. 다른 파라미터는 고정하고, 모든 layer에 아주 작은3×3 Convolution filter를 사용하여 Convolution layer를 추가함을 통해 network 깊이를 증가시킨다. -
VGG 결과
Network 깊이를 증가 시킨 결과 ILSVRC classification과 localisation에서 좋은 정확도를 보이고, 다른 image recognition dataset에도 적용 가능했다(우수한 성능을 보였다).
2개의 가장 성능이 좋았던 모델을 공개해 이후 연구에 사용할 수 있도록 한다.
ConvNet Configutations
Architecture
-
Input
224×224 RGB 이미지을 입력으로 받는다. training set의 픽셀 평균값을 빼는 전처리만 한다. -
Filter
매우 작은 receptive field를 가지는3×3 filter를 사용한다. (3×3은 상하좌우, 중앙의 특징을 추출할 수 있는 가장 작은 사이즈이다.) 특정 층에서는1×1 convolution filter도 사용한다. 1×1 filter 뒤에는 non-linearity가 뒤따른다.
Stride는 1을 사용하고,Padding은 input의 해상도를 유지하기 위해 사용한다. 3×3 filter를 사용할 때의 padding은 1이다. -
Max Pooling
Max Pooling은 모든 layer에 적용되지는 않고, 5개의 layer 뒤에만 따라온다.2×2 window size를 사용하며, stride는 2이다. -
Fully-Connected layers
Convolution layer 뒤에는 3개의Fully-Connected layer가 있다. 첫번째와 두번째 layer는 4096개의 채널을 가지고, 3번째 layer는 1000개의 class로 분류하기 위한 1000-way soft-max layer이다. -
ReLU와 LRN
모든 hidden layer는 AlexNet과 같이ReLU를 사용한다. 하지만Local Response Normalization(RLN)은 사용하지 않는다. 메모리 사용과 계산 시간을 줄일 수는 있지만, 성능을 개선하지는 않기 때문이다.
Configurations
-
평가한 모델 구조
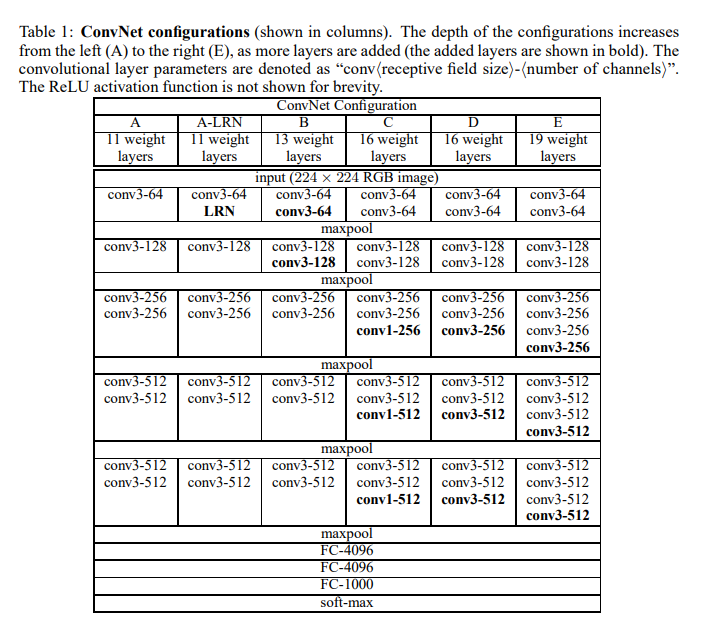
이 논문에서 평가한 ConvNet의 configuration은 위 표의 각 colum과 같다. A-E는 모두 architecture에서 언급한 구조를 따른다. 다른 점은depth뿐이다. 11개의 layer를 가지는 A에서 시작해 19개의 layer를 가지는 E까지 평가한다.
Width(channel 개수)는 모두 64에서 시작하여 각 Pooling layer에서 2배가 되어 최종적으로 512까지 늘어난다. -
Parameter 개수

각 모델에 대한parameter 개수이다. 깊은 depth에도 불구하고, large conv를 사용한 얕은 모델보다 parameter 수가 작다.
Discussion
-
Small 3×3 receptive fields
VGG는 AlexNet과 다르게 전체 네트워크에서 매우 작은3×3 conv. filter를 사용한다.
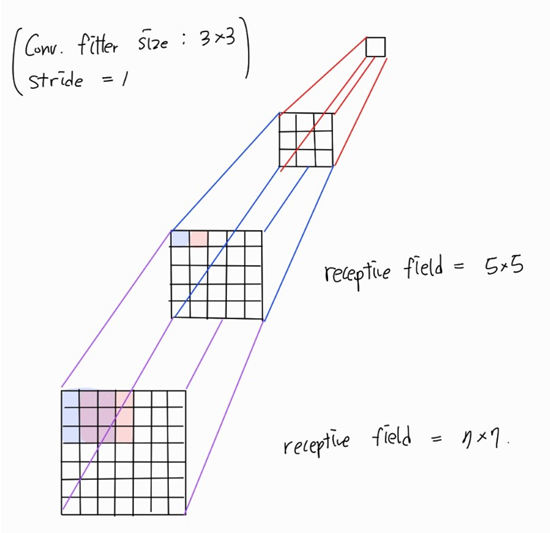
5×5 filter 하나는 3×3 filter를 2개와 receptive field가 같다.
7×7 filter 하나는 3×3 filter를 3개와 receptive field가 같다.
장점 1. Descriminative
3×3을 여러개 사용하며 ReLU 함수를 사용하면 decision function를 더discriminative하게 만들 수 있다. (결과의비선형성을 증가시킬 수 있다.)장점 2. Parameter 개수
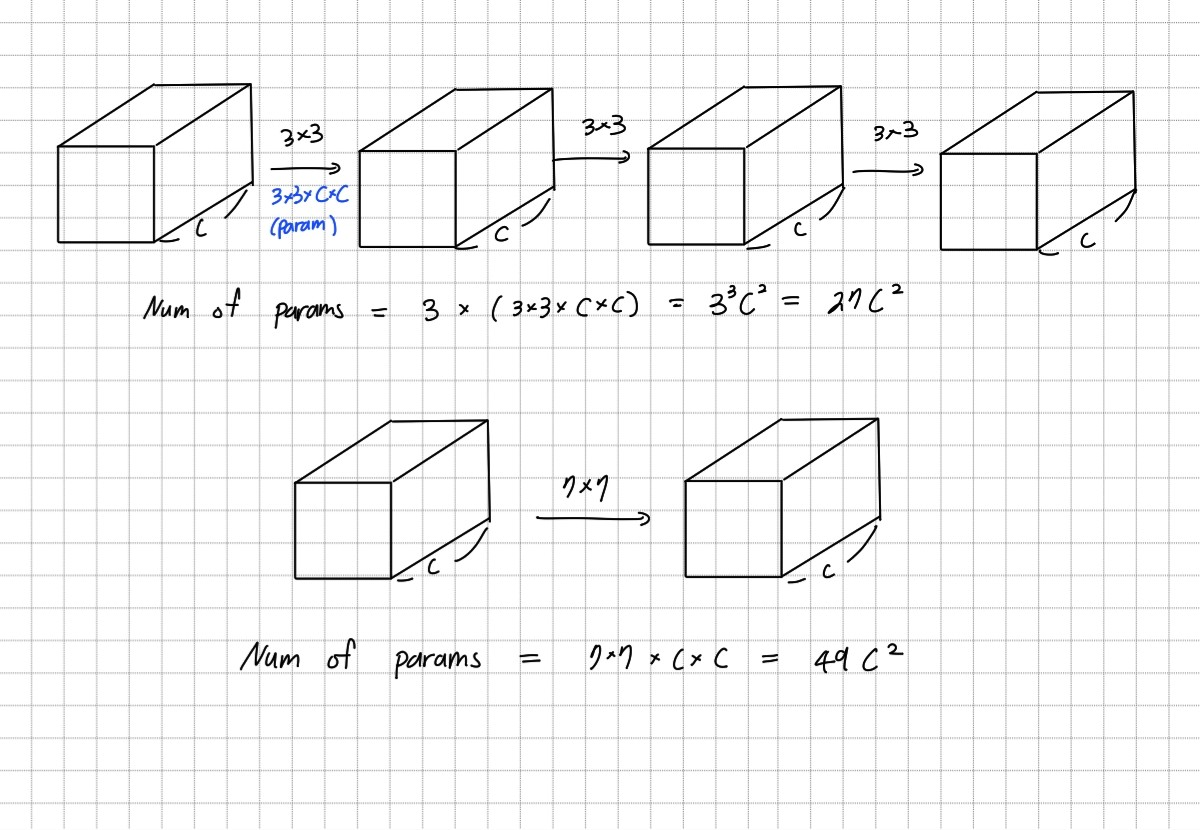
7×7 filter를 하나 사용하는 것보다 3×3 filter를 3개 사용하는 것이 필요한 parameter의 수가 81% 더 적다. 이는 7×7 filter를 3×3 filter로 decomposition하여regularisation하는 것으로 볼 수 있다.
-
1×1 Conv. layer
모델 C에서는 1×1 filter를 사용한다. 1×1 filter는 receptive fields에 영향을 주지 않으면서, 결과의non-linearlity증가시키기 위해 사용한다. 모델에서 1×1 filter는 입력과 출력의 채널 크기도 변경하지 않고 ReLU를 적용하여 non-linearlity만 더한다. -
관련 연구
『Flexible, high performance convolutional neural networks for image classification』에서도작은 Conv. filter를 사용하였지만 모델의 depth가 얕고, ImageNet과 같은 큰 dataset을 사용하지 않았다.
『Multi-digit number recognition from street view imagery using deep convolutional neural networks』에서는deep ConvNets를 사용하여 depth가 깊을 수록 더 좋은 성능을 보여줌을 보여줬다.
GoogLeNet은 VGG와 비슷하게 모델이 deep하고, 작은 convolutin filter를 사용하였다. 하지만 구조가 더 복잡하고 연산량을 줄이기 위해 spatial resolution을 급격히 감소시켰다.Single-network의 classification정확도는 vgg가 GoogLeNet을 능가한다.
Classification Framework
Training
-
최적화 방법
mini-batch gradient descent(batch size = 256)와momentum(0.9)을 사용하였다.
-
Regularization
L2 weight decay와 첫번째, 두번째 fully-connected layer에dropout(0.5)를 사용한다.
-
Learning schedule
처음에는 0.01로 시작하여 validation accuracy가 개선되지 않으면 10배로 줄인다. 최종적으로 3번 감소했고, 370K iteration(74 epochs) 후에 종료되었다.
AlextNet보다 parmeter가 많고 depth가 깊은데 더 적은 ephocs가 필요한 이유는 작은 3×3 filter를 사용했기 때문에 생긴implict regularisation(파라미터 수 감소)와 이후 설명할 특정 층의pre-initialisation때문이다.
-
Weight 초기화
Wegith를 잘못 초기화하면 학습이 지연될 수 있기 때문에 weight 초기화는 매우 중요하다. 이 문제를 해결하기 위해random initialisation으로 학습하기에 충분히 얕은 모델 A를 먼저 학습시킨다 (pre-training). 이후 학습된 A의 weight 값으로 앞쪽의 Convolution layer 4개와 3개의 Fully-connected layer를 초기화한다.pre-training을 사용하지 않고
Glorot & Bengio(2010)의 random initialisation를 사용해도 됨을 논문 제출 후 발견했다고 한다.나머지 중간 layer는 평균이 0이고 표준편차가 0.01인 정규 분포를 따르는 random 값으로 초기화한다. Bias는 0으로 초기화한다.
-
Data augmentation
224×224 고정 크기의 이미지를 얻기 위해서 rescale(Training image size에서 자세히 설명)한 이미지에random crop을 사용한다. 한 이미지당 하나의 crop을 만들고,random horizontal flipping과random RGB color shift(color juttering)을 사용한다.
-
Training image size
S를 종횡비를 유지한 rescale 이미지에서 짧은 부분이라고 가정한다. 224×224 크기로 crop하기 때문에 S는 224보다 같거나 커야 한다. S의 크기를 정하는 방법은 다음과 같이 2가지가 있다.- single-scale training
S를 한가지로 고정하는 방식이다. 논문에서 사용한 방식은 256과 384를 사용한다. 학습 속도를 향상시키기 위해 먼저 모델을S = 256으로 학습시킨다. 이후S = 384로 모델을 학습시킬 때 앞서 256으로 학습한 모델의 weight를 초기값으로 사용하고, 더 작은 initial learning rate인 0.001을 사용한다.
- multi-scale training
각 이미지는256에서 512 사이 값중 random 값을 S로 사용한다(scale juttering). 이미지마다 객체의 크기가 다르므로 S를 다르게 사용하는 것이 효과적이다. 학습 속도 때문에 S = 384의 고정된 값으로 pre-trained된 모델을fine-tuning하여 multi-scale model을 학습시킨다.
- single-scale training
Testing
-
Fully-connected layers
첫번째 FC layer는7×7 Conv. layer로, 두번째와 세번째 FC layer는1×1 Conv. layer로 변경한다. FC layer를 사용하지 않기 때문에 입력 이미지의 크기가 고정될 필요가 없다. Soft-max 함수에 들어가기 전 feature map(class score map)은 채널은 항상 1000이지만 spatial resolution은 입력 크기에 따라 달라지므로average pooling을 사용하여 1×1×1000이 되도록 한다. -
Data Augment
test set은 horizontal flipping을 사용한다. 원본과 flip된 이미지의 결과 평균을 최종 결과로 사용한다. -
Crop
GoogLeNet에서 사용한 Multi-crop은 계산 시간을 늘리고 성능에 크게 도움이 되지 않는다고 판단하였다. 하지만 다른 연구에서 crop을 사용하여 성능을 개선한 것을 참고하여3개의 scale을 가지는 이미지와 flip한 이미지를5×5 그리드로 crop을 참고용으로 사용하였다. 즉 한 이미지에150개의 crop이미지를 사용한다.
Implementation Details
4개의 GPU를 사용하는 Multi-GPU system을 사용하였다. Batch는 GPU batch로 나누어져 각 GPU에서 gradient를 계산한 뒤, 평균을 사용해 full batch의 gradient를 구해 사용한다. 학습 시간은 2주에서 3주가 걸렸으며 이는 Single GPU에 비해 3.75배 빠르다.
Calssification Experiments
ILSVRC 2012 dataset을 사용한다. 대부분의 실험에서 validation set은 test set으로 사용하였다.
Single Scale Evaluation
Rescale된 Test 이미지의 짧은 부분을 Q라고 한다. Single scale evaluation은 Q를 하나의 값으로 고정하는 방법이다. Test의 S가 고정된 값이라면 Q = S를 사용하고, 고정된 값이 아니라면 Q = 0.5(Smin, Smax)를 사용한다. 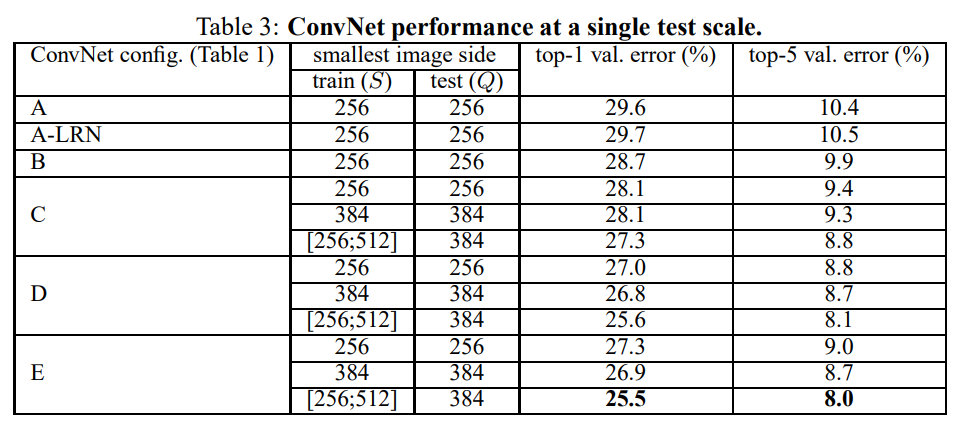
- LRN
LRN을 사용한A-LRN과 사용하지 않은A를 비교하였을 때 LRN은 성능을 개선하지 않다고 판단하여 더 깊은 모델에서는 사용하지 않았다.
- Depth
ConvNet의depth가 깊어질수록 성능이 개선됨을 확인하였다. 해당 논문에서는 19 layer를 사용하는 것에 error rate가 수렴하였지만, 더 큰 데이터셋을 사용한다면 더 깊은 모델이 도움이 될 것으로 보인다.
- 1×1 Conv. layer
C는B에 1×1 layer를 추가한 모델이다. 두 모델의 성능을 비교하였을 때 1×1 layer를 통해 추가된non-linearity는 성능에 도움이 되는 것으로 보인다.
C와D의 depth는 같다. C는 3×3 layer와 1×1 layer를 섞어서 사용하였고, D는 3×3 layer만 사용한 것이 다르다. 결과를 보면 C보다 D가 더 성능이 좋다. 따라서spatial context를 capture하는 것이 중요함을 알 수 있다.
- Scale jittering
S = 256, S = 384 처럼 고정된 값을 사용할 때 보다 S = [256;512]처럼scale jittering을 사용하였을 때의 결과가 더 좋다. Test에서는 Q를 고정된 값으로 사용해도 scale jittering이 도움이 되는 것으로 보인다.
Multi-Scale Evaluation
Test 단계에서 scale jittering의 효과를 알아본다. S와 Q가 너무 차이나면 오히려 성능이 떨어졌다. 따라서 고정된 S를 사용하면 Q = {S-32, S, S+32}를 사용하고, 학습에서 scale jittering을 사용하였다면 Q = {Smin, 0.5(Smin + Smax), Smax}를 사용한다. 3개의 Q로 각 모델을 test하여 평균을 최종 결과로 사용한다.
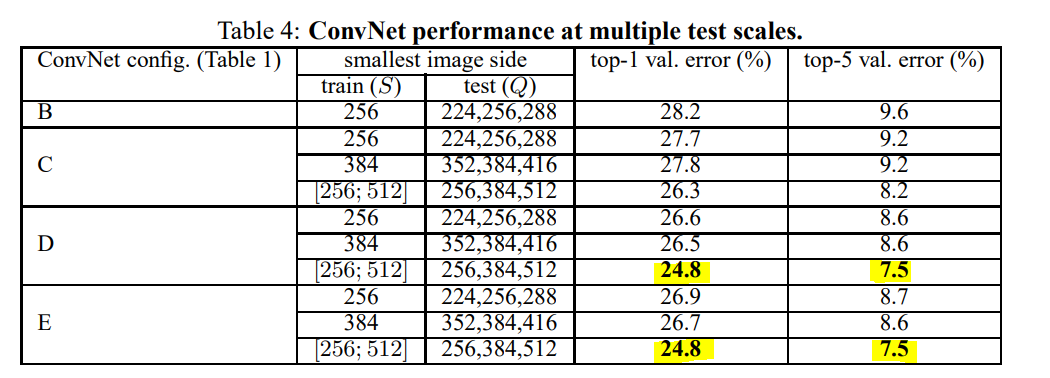
Test 단계에서scale jittering을 사용하였을 때 single-scale evaluation보다 성능이 개선되었다. 가장 좋은 성능을 보인 것은 depth가 깊은 D와 E이다. 학습시에도 S를 고정된 값으로 사용하는 것보다 scale jittering을 사용하는 것이 성능이 더 좋았다. Single-network에서 best performance 24.8%, 7.5%이다.
Multi-crop Evaluation
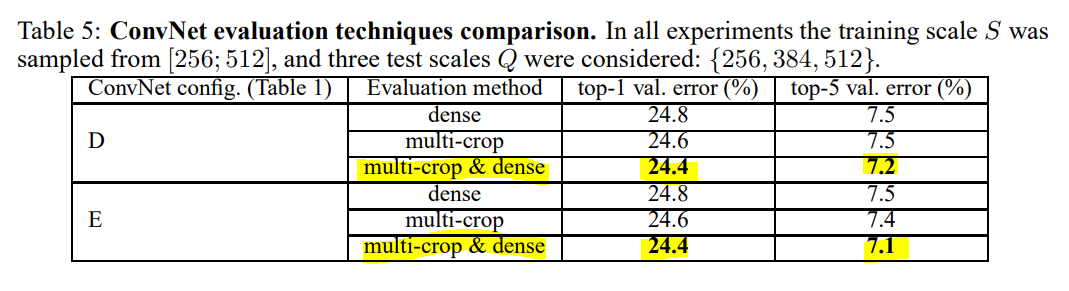
Dense ConvNet evaluation(리뷰 참고)와 multi-crop evaluation 방법을 비교하였을 때는 multi-crop 방법이 더 성능이 좋다. 이 차이는 convolution boundary conditions을 다루는 차이로 인해 발생하다고 생각한다. 그러나 두 방법은 서로 상호보완적이므로 두 방법의 sofr-max 값의 평균을 사용하였을 때 가장 좋은 성능을 보인다.
ConvNet Fusion

ILSVRC 대회에 제출시 위와 같이 7개의 모델을 ensemble하여 제출하였다. 대회 제출 이후에 best-performing 모델인 D와 E만 ensemble하는 것이 더 좋은 결과를 내는 것을 알게되었다.
Comparison with the State Of the Art
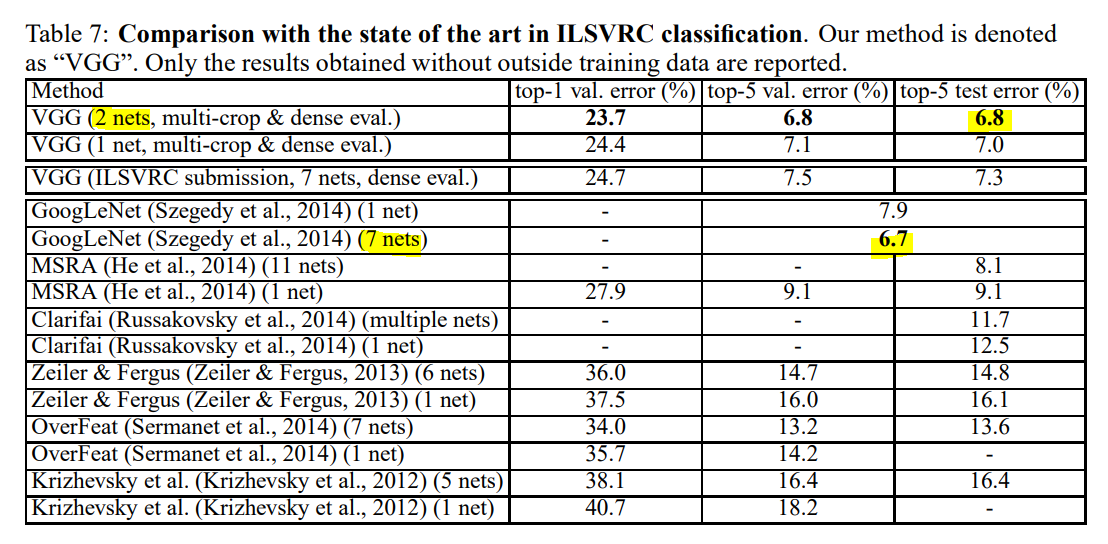
VGG는 ILSVRC-2014 2등을 차지했다. 이전 세대의 모델보다 훨씬 좋은 성능을 보이며 1등을 차지한 GoogLeNet과 비교해도 경쟁력이 있다. 주목할 점은 다른 모델에 비해 VGG는 매우 적은 모델(2개)을 ensemble하였다는 점이다. Single-net performance에서는 VGG가 가장 좋은 성능을 보였다. VGG는 Classic한 ConvNet 구조에서 크게 벗어나지 않으며, depth를 충분히 늘려 성능을 개선했다.
Conclusion
- Large-scale image classification을 위한
very deep convolutional networks학습을 평가하였다. depth가 accuracy 개선에 도움이 됨을 증명하였다.- AlextNet과 같은
calssic한 CNN 구조에서 depth만 충분히 늘린다면, ImageNet에서 좋은 결과를 달성할 수 있다.
