VGG는 모델 구조는 어렵지 않았는데 평가 방법이 복잡하고 어려웠다. 전부 이해하지는 못했지만, 조원과 멘토님과 이야기하며 이해한 것을 정리한다.
Dense evaluation은 조금 더 공부가 필요할 것 같다.
Main Idea
VGG의 main idea는 큰 conv filter를 사용하지 않고, 작은 3×3 필터를 깊게 쌓겠다는 것이다. 3×3 필터를 여러번 쌓는 것으로 receptive field를 유지하였고 실제로 깊은 모델의 성능이 더 좋다는 것을 증명하였다.
Fully Convolutional Network
AlextNet, GoogLeNet, VGG 등 지금까지 CNN 모델들은 Convolution layer를 지나 마지막 분류에서는 Fully Connected layer를 사용하였다. FC layer를 사용하기 위해 flattern을 해야 해서 공간적인 정보의 소실이 있었을 뿐만 아니라, 입력 이미지의 크기가 고정되어야 한다는 단점이 있었다.
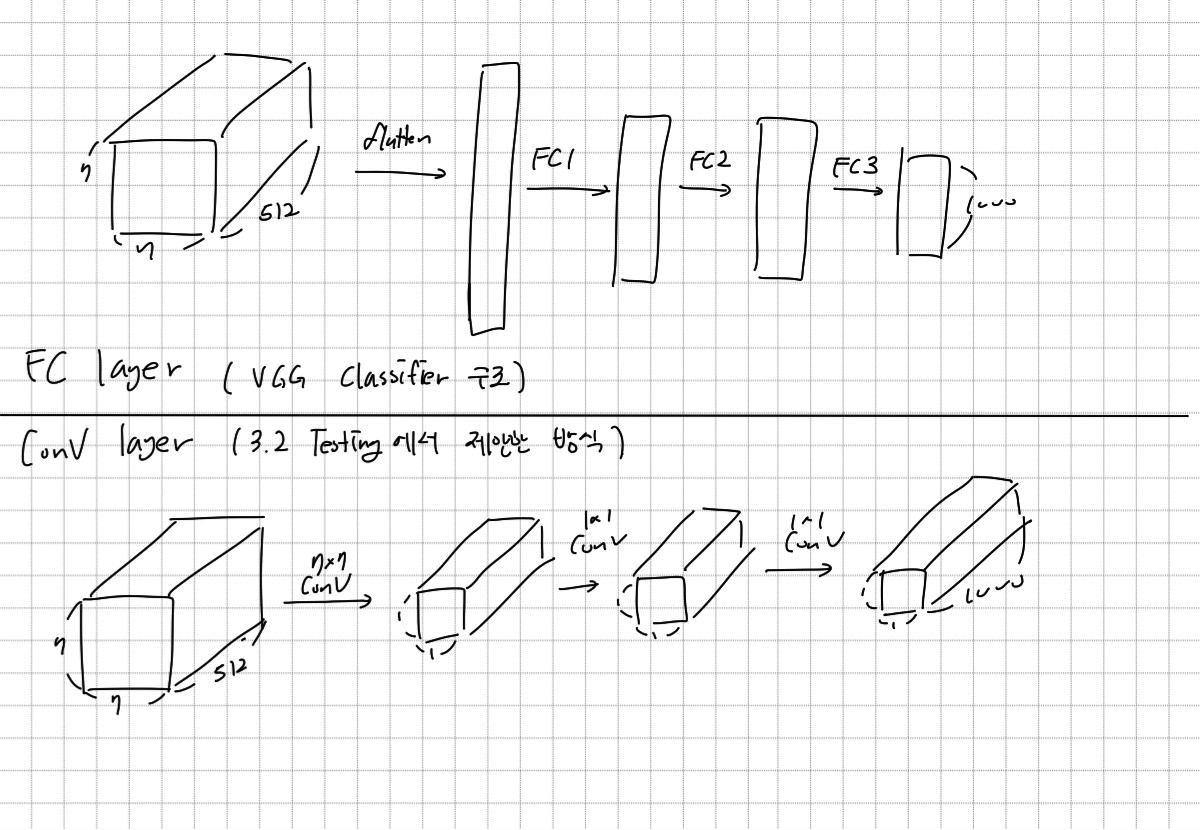
Fully Convolutinal Network는 FC layer를 Conv layer로 바꿔 모든 layer를 Conv layer로 구성하는 것이다. Global average ppoling과 1×1 Conv. filter를 사용하여 FC layer와 같은 결과를 얻을 수 있다. 논문에서는 Testing에서 FCN을 사용하고, 만약 마지막 결과가 1×1×1000이 아닌 경우에는 Global average pooling을 사용한다고 언급하였다.
그러나 Testing에서만 해당 방식을 사용하는 이유와, Conv filter로 사용하는 값에 대해서는 어떠한 언급도 하지 않았다. 이 부분은 더 공부가 필요할 것 같다.
FCN을 사용하는 이유는 입력 이미지가 고정된 사이즈를 가져야 할 필요가 없어지고, 공간 정보를 유지할 수 있기 때문이다.
Dense Evaluation
다른 블로그 글을 참고하면, Dense Evaluation은 FC layer로 feature를 전달하기 전 Max Pooling을 Densely하게 적용하는 방법이라고 한다. Max Pooling을 Overlapping없이 사용하면 해당 윈도우 내의 가장 큰 값만 추출하여 표현력이 떨어진다고 생각했고 이를 극복하기 위해 Max Pooling을 촘촘히 적용하는 것이다.
결국 AlexNet에서 사용한 Overlapping Pooling과 비슷한 개념인 것 같다.
FCN을 사용하면 crop을 할 필요가 없다고 하는 것으로 봐서는 Dense Evalutation과 FCN을 묶어서 같이 생각하는 것 같기도 하다.
Dense Evaluation과 Multi-Crop Evaluation
차이점
이 논문에서 설명하는 Dense Evaluation과 Multi-crop evaluation의 차이점은 모델에 이미지를 입력할 때 전체를 넣느냐, 일부분만 넣느냐로 이해할 수 있다.
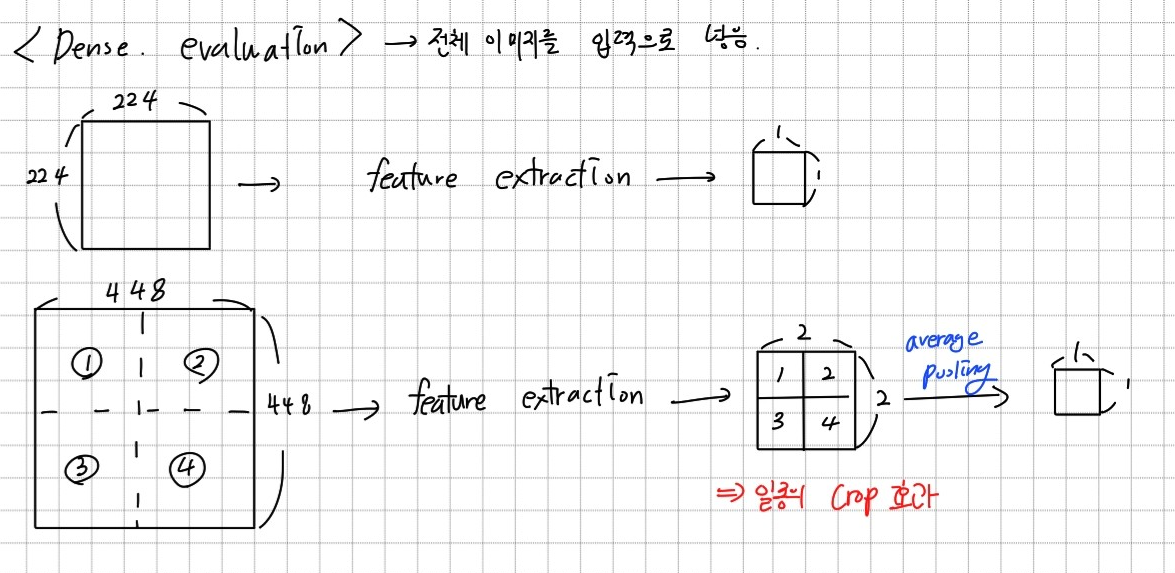
Dense evaluation은 이미지 사이즈와 상관없이 전체 이미지를 입력으로 넣는다.
큰 이미지를 넣은 경우에는 feature map에 원래 이미지를 crop하여 여러장으로 넣은 것과 같이 나오고, 이를 average pooling하므로 결국 일종의 crop효과를 얻을 수 있다.
(논문에서 언급된 내용은 아니다.)
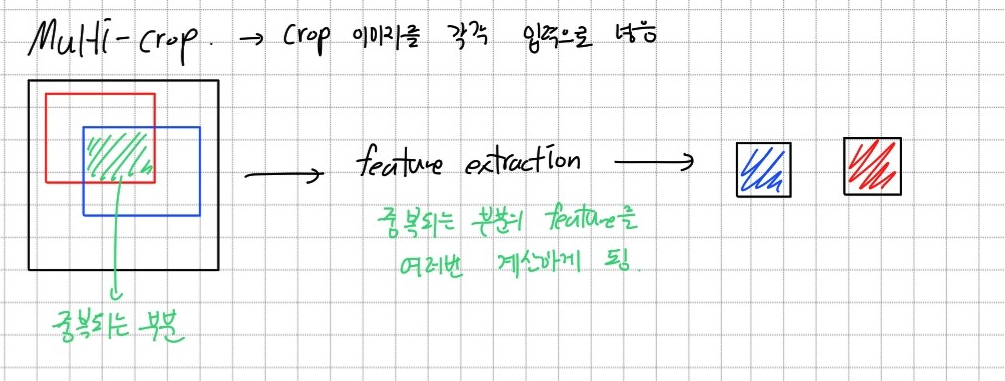
Multi-crop은 이미지를 고정된 크기로 잘라서 모델에 각각 넣는 것이다. 중복된 부분이 있어도 특징 추출을 각각 하기 때문에 중복된 연산이 필요하고, 본 논문에서는 이를 비효율적이라고 생각하였다.
padding 차이
3.2 Testing 중 다음과 같은 내용이 있다.

Dense Evaluation은 주변의 값을 padding으로 사용하고, multi-crop evaluation은 zero padding을 사용한다고 설명한다. 이게 어떤 말인지 잘 이해가 안갔었는데 단순하게 이미지의 특정 부분에 대한 feature를 추출할 때를 생각하면 이해가 가는 거 같다. Dense evaluation은 전체 이미지를 넣기 때문에 padding에 주변 값을 사용할 수 있다. 반면 multi-crop은 이미 잘린 이미지를 모델에 넣기 때문에 padding을 0으로 줄 수밖에 없는 것이다.
complementarity
이 논문에서 dense evaluation과 multi-crop evaluation을 자꾸 설명하는 이유는 두 가지 방법을 적절히 섞었을 때 가장 좋은 성능을 보였기 때문이다. 두 방법은 상호보완적인 방법인데, dense evaluation은 이미지 전체를 보게되어 global한 특징을 잘 추출할 수 있고 muli-crop은 특정 부분에 집중하여 local한 특징을 잘 추출하기 때문이다.
Gradient vanishing
GoogLeNet에서는 중간 layer에 추가적인 classifier를 연결해 gradient vanishing 문제를 해결하려고 하였다. 그런데 vgg는 GoogLeNet과 비슷하게 deep한 모델임에도 gradient vanishing 문제에 대한 언급이 일절 없다. VGG에서는 Gradient vanishing 문제가 발생하지 않는지 궁금했다.
일단 VGG보다는 GoogLeNet이 깊이가 더 깊다. 그리고 GoogLeNet에서 auxiliary classifier를 사용한 것이 gradient vanishing 문제가 발생해서 해결하기 위함인지, 그저 gradient vanishing 문제를 예방하기 위해 사용한 것인지 모른다. 따라서 vgg에서 무조건 gradient vanishing 문제가 발생한다고 볼 수는 없다고 한다.
Depth, Dataset size와 CV
최근에는 매우 깊은 모델과 매우 큰 dataset을 사용하는 모델(ex. chatGPT)이 좋은 성능을 보여주고 있다. 그러나 Computer Vision에서는 왜 이렇게 큰 모델이 없는지 이야기 나누었다.
가장 큰 이유는 Computer vision이 사용되는 분야에서 원하는 사회적인 요구가 다른 분야와 다르기 때문이다. Computer vision은 보통 카메라와 같이 작은 장비에서 사용하고, 실시간으로 결과를 얻을 수 있는 것을 원한다. 따라서 모델 경량화 및 속도 개선이 더 큰 수요가 있는 것이다. 또 다른 이유로는 이미지는 labeling이 필요하고, labeling은 매우 어려운 작업이라는 점이 있다.
