ls -1ha /content/drive/MyDrive/LG헬로비전_DX_School/250117/kaggle.json!mkdir -p ~/.kaggle # making dictory
!cp /content/drive/MyDrive/LG헬로비전_DX_School/250117/kaggle.json ~/.kaggle/ #!mv(move)
# Permission Warning이 발생하지 않도록 해줍니다.
!chmod 600 ~/.kaggle/kaggle.json
# 내가 참가한 대회 리스트 확인
!kaggle competitions list!kaggle competitions download -c titanic!unzip /content/titanic.zipimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
train = pd.read_csv('/content/drive/MyDrive/LG헬로비전_DX_School/250117/train.csv')
test = pd.read_csv('/content/drive/MyDrive/LG헬로비전_DX_School/250117/test.csv')
print(train.head())
print(train.tail())
print(train.isnull().sum())
print(train.isna().sum())
print(train.describe())
print(train.info())def bar_chart(feature):
survived = train[train['Survived']==1][feature].value_counts()
dead = train[train['Survived']==0][feature].value_counts()
df = pd.DataFrame([survived, dead])
df.index = ['Survived', 'Dead']
df.plot(kind='bar', stacked=True, figsize=(10, 5))bar_chart('Sex') # 무슨 이유로 남성분들이 사망을 하셨을까?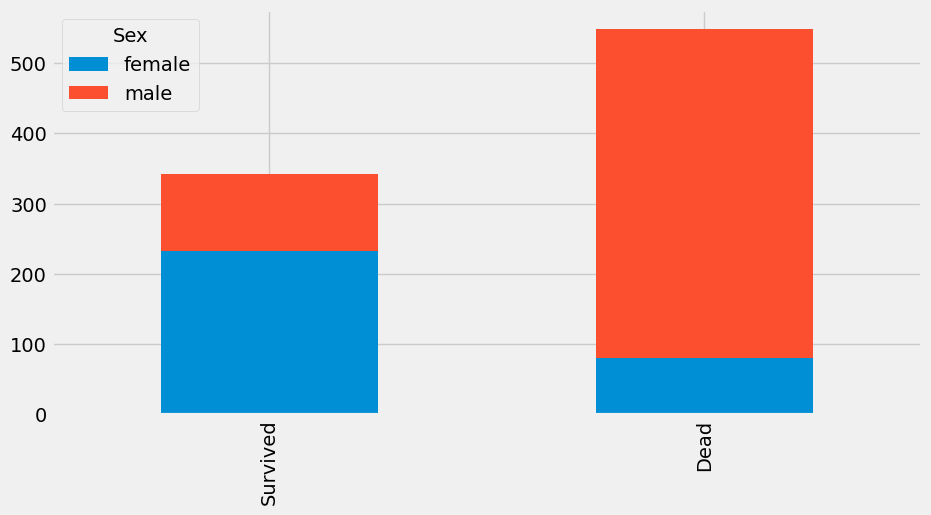
bar_chart('SibSp') # 함께 탑승한 형제 또는 배우자 수에 따라서 생존이 왜 다르지?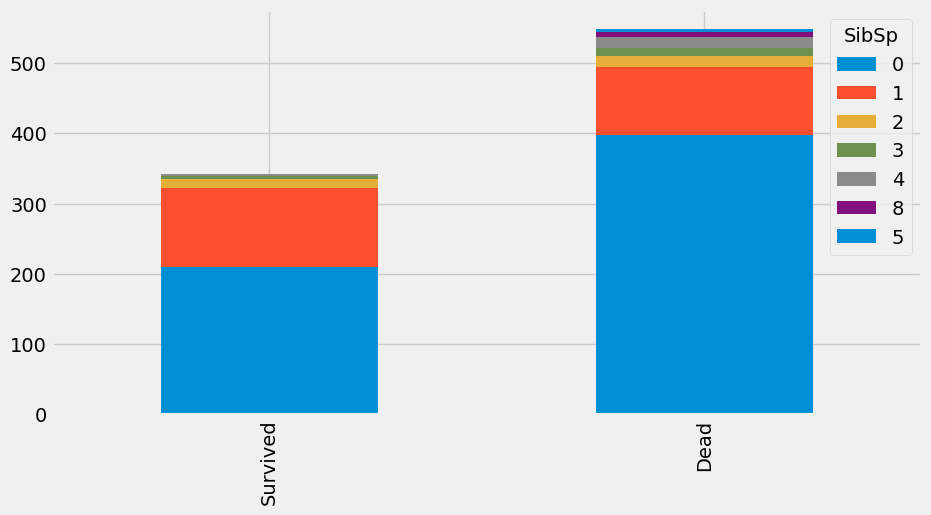
bar_chart('Parch')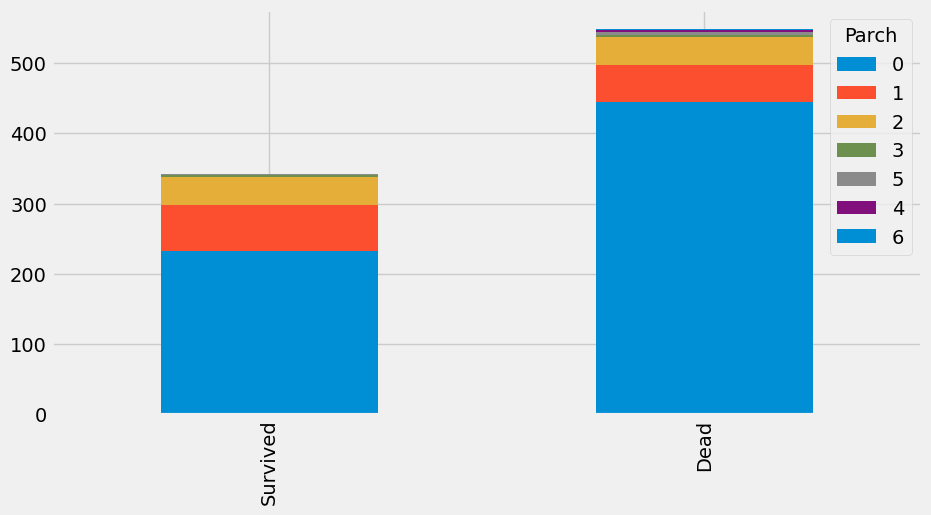
# 생존 여부에 따른 파이차트를 그려보자.
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')f, ax = plt.subplots(1,2,figsize=(18,8))
train['Survived'].value_counts().plot.pie(explode=[0,0.1], autopct='%1.1f%%', ax = ax[0], shadow=True)
# explode : 각 항목을 파이의 원점에서 튀어나오는 정도를 나타냄
# autopct : 각 항목의 퍼센트를 표시함
# shadow : 그림자를 그릴 것인지?
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot(x=train['Survived'], ax=ax[1])
ax[1].set_title('Survived')
plt.show()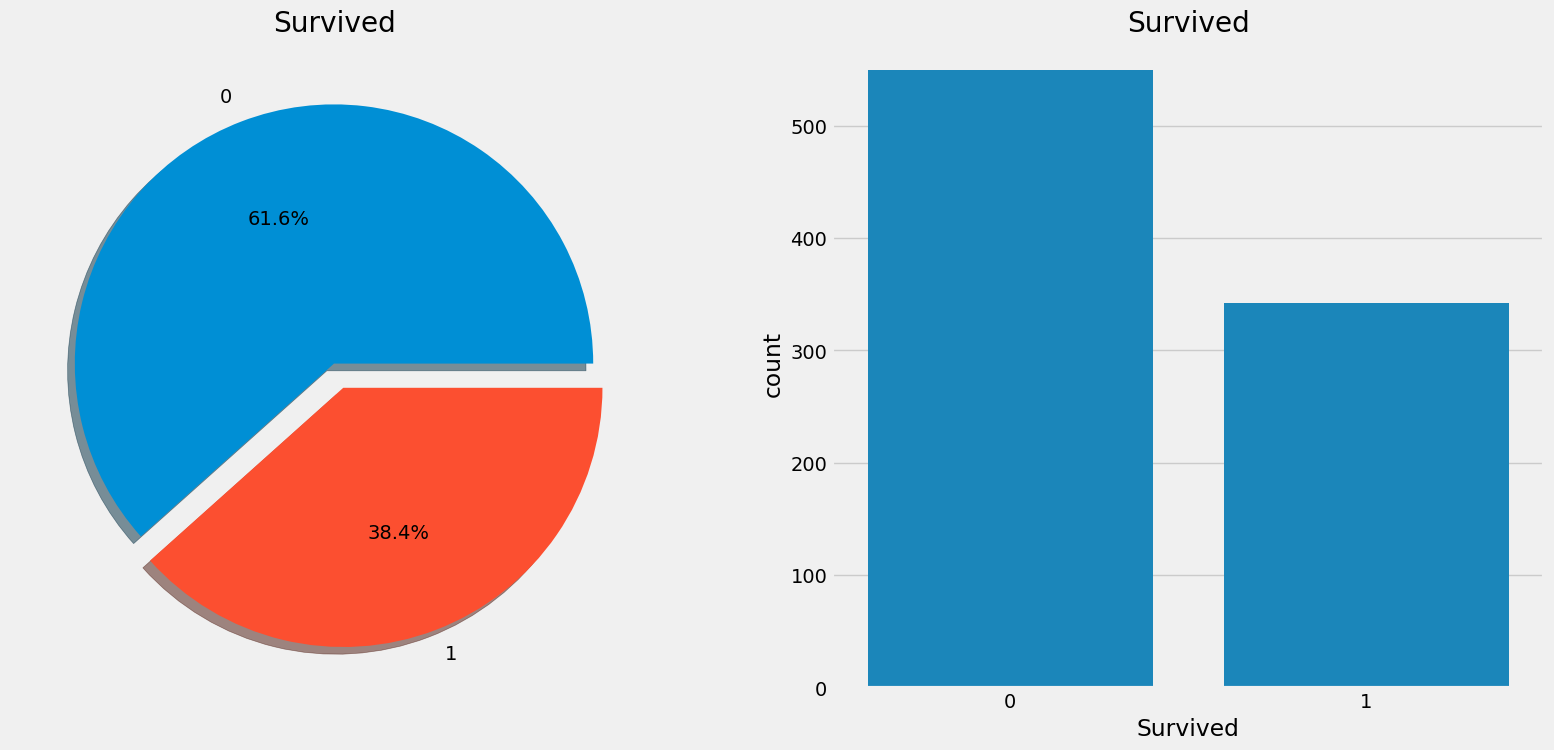
# crosstab(분할표)은 두 개 이상의 범주형 변수 간의 관계를 요약하고 시각화하기 위해 사용됨
pd.crosstab(train.Pclass, train.Survived, margins=True).style.background_gradient(cmap='summer_r')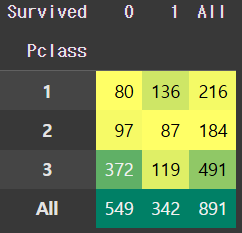
f, ax = plt.subplots(1,2,figsize=(18,8))
train['Pclass'].value_counts().plot.bar(color=['#CD7F32','#FFDF00','#D3D3D3'], ax=ax[0])
ax[0].set_title('Number fof Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot(x='Pclass', hue='Survived', data=train, ax=ax[1])
ax[1].set_title('Pclass : Survived vs Dead')
plt.show()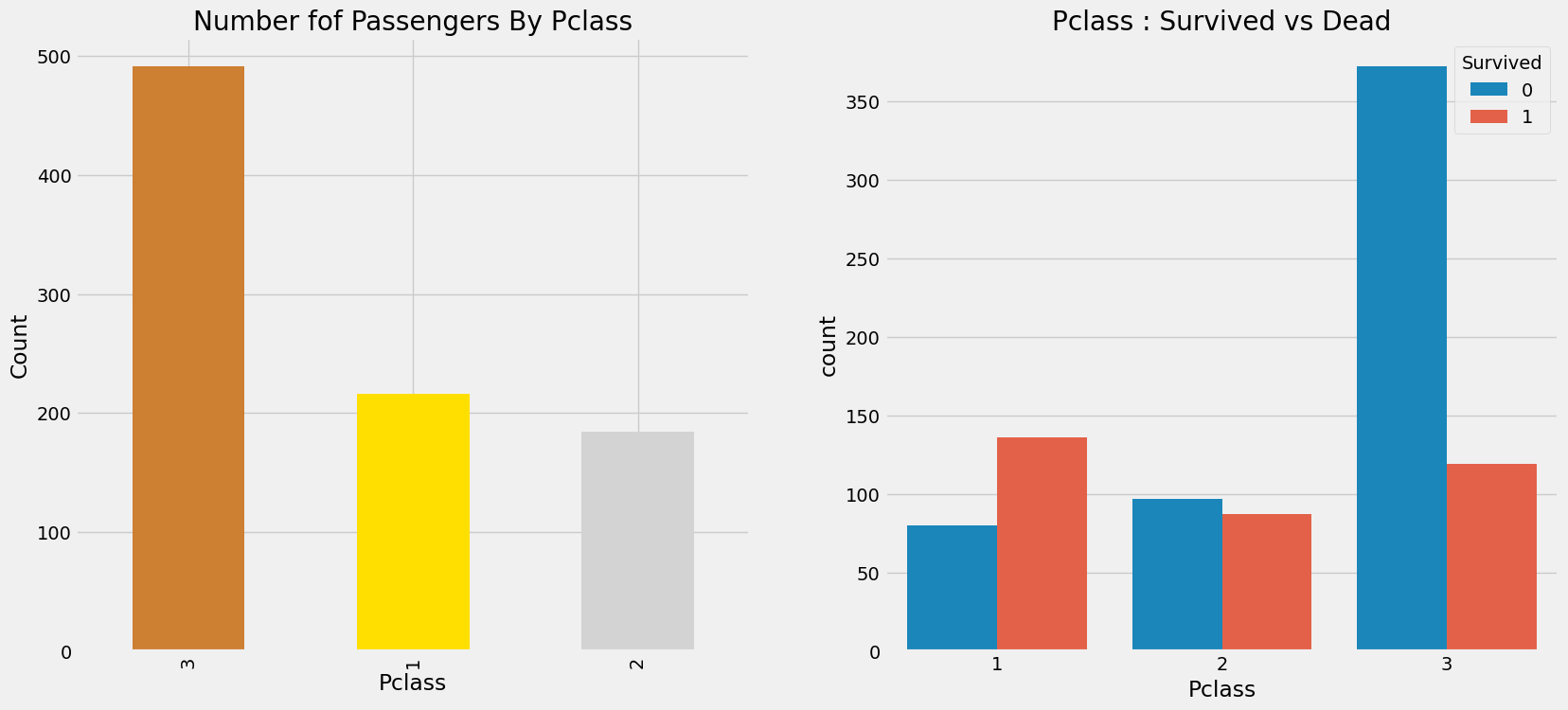
pd.crosstab([train.Sex, train.Survived], train.Pclass, margins=True).style.background_gradient(cmap='summer_r')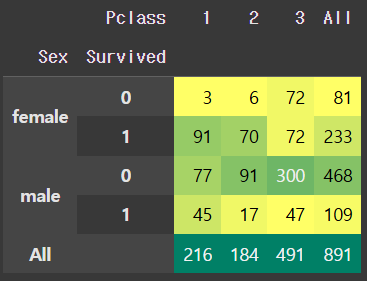
sns.pointplot(x = 'Pclass', y = 'Survived', hue='Sex', data=train)
plt.show()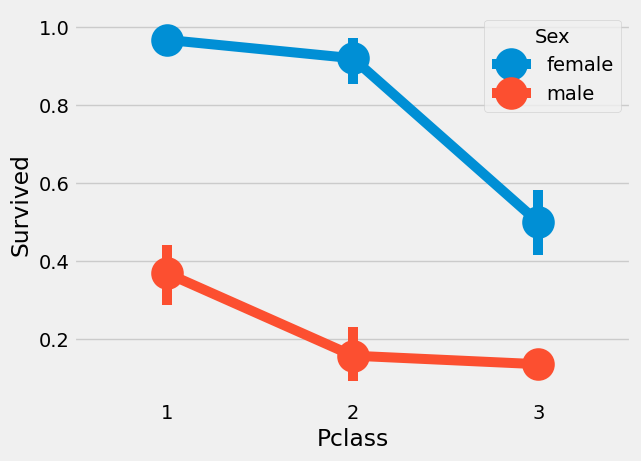
f, ax = plt.subplots(1, 2, figsize=(18,8))
sns.violinplot(x='Pclass', y='Age', hue='Survived', data=train, split=True, ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived')
ax[0].set_yticks(range(0, 110, 10))
sns.violinplot(x='Sex', y='Age', hue='Survived', data=train, split=True, ax=ax[1])
ax[1].set_title('Sex and Age vs Survived')
ax[1].set_yticks(range(0, 110, 10))
plt.show()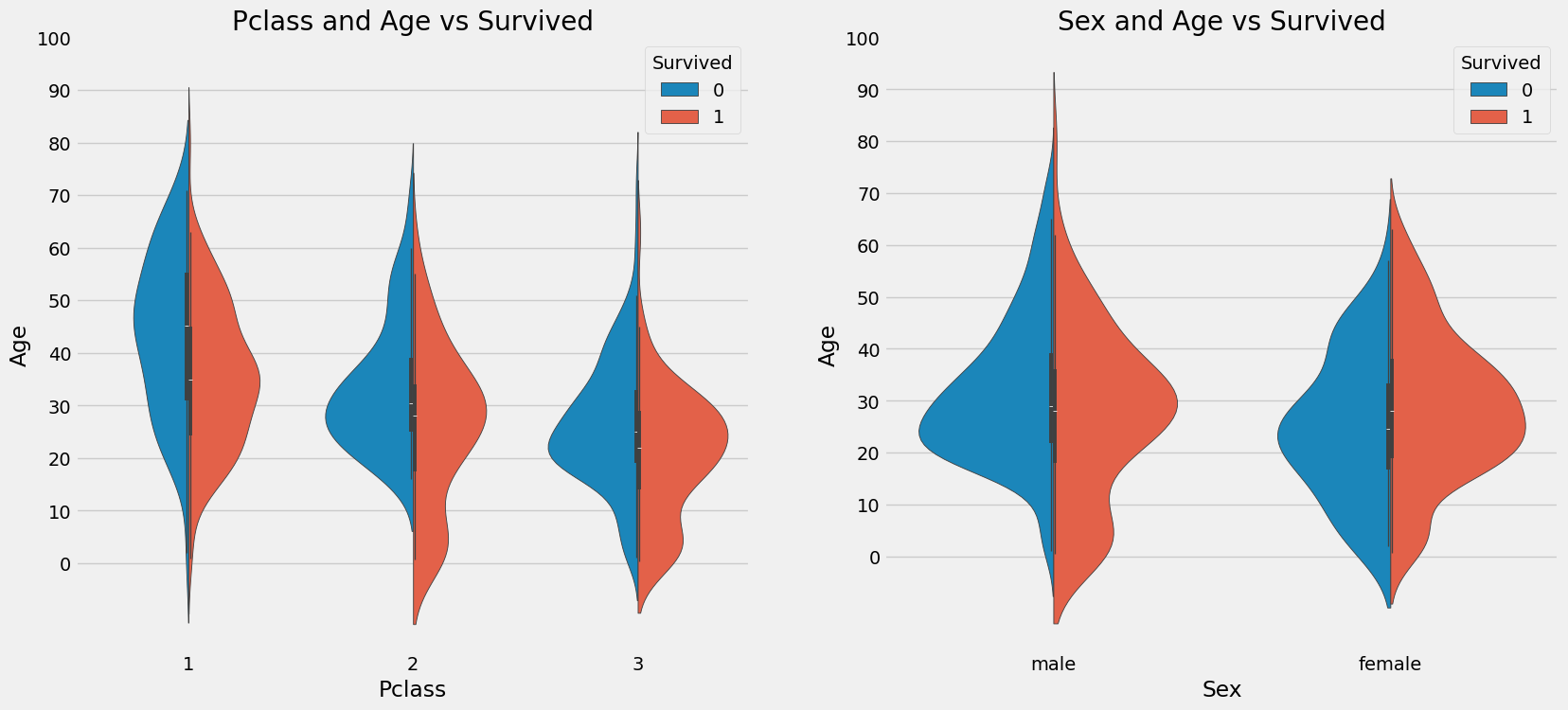
train['Name']
train['Name'].str
train['Name'].describe()# 정규표현식
train['Name'].str.extract('([A-Za-z]+)\.', expand=False) # 대문자 A부터 Z, 소문자 a부터 z까지
# . 기준으로 자르고 확장을 막음?train['title'] = train['Name'].str.extract('([A-Za-z]+)\.', expand=False)train['title'].value_counts()# 성별 : male, female -> one-hot-encoding?
# pandas의 get_dummies
# sklearn - from sklearn.preprocessing import OneHotEncoder
sex_mapping = {'male':0,'female':1}
train['Sex'] = train['Sex'].map(sex_mapping)train['Sex']bar_chart('Sex')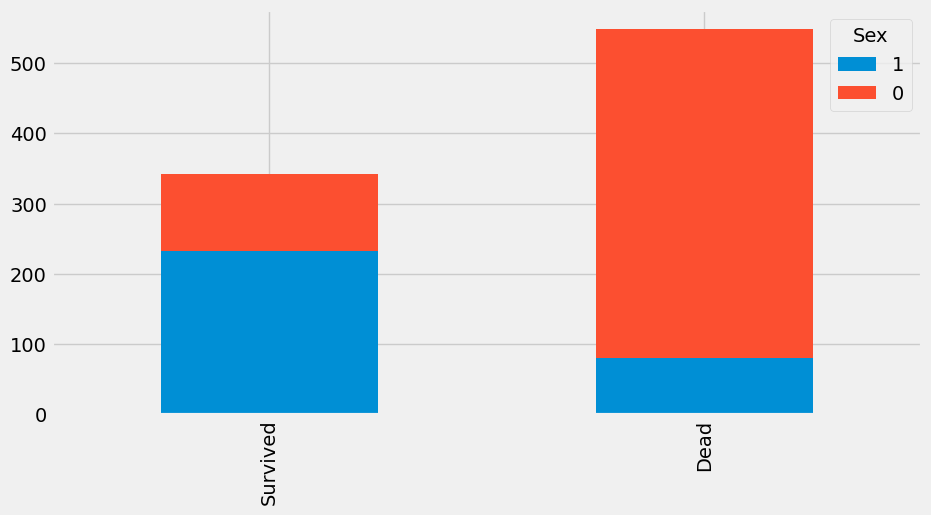
train['Age'].fillna(train.groupby('title')['Age'].transform('median'), inplace=True)
train['Age'].isnull().sum()# 사망자의 나이가 어떻게 될까? + 생존자 -> 그림
# feactgrid
facet = sns.FacetGrid(train, hue = 'Survived', aspect=4)
# aspect : 가로 세로 비율
facet.map(sns.kdeplot, 'Age', shade = True) # kde : 이차원 밀집도 그래프
facet.set(xlim=(0, train['Age'].max()))
facet.add_legend()
sns.axes_style('dark')
plt.show()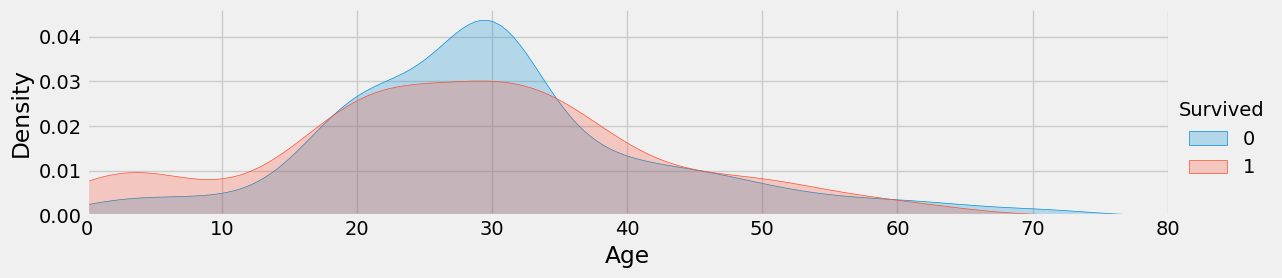
test = pd.read_csv('/content/drive/MyDrive/LG헬로비전_DX_School/250117/test.csv')
train_test_data = [train, test]# 16세 이전 index -> 0, 16세 26세 -> 1 ....
for dataset in train_test_data:
dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0
dataset.loc[((dataset['Age'] > 16) & (dataset['Age'] <= 26)), 'Age'] = 1
dataset.loc[((dataset['Age'] > 26) & (dataset['Age'] <= 48)), 'Age'] = 2
dataset.loc[((dataset['Age'] > 48) & (dataset['Age'] <= 64)), 'Age'] = 3
dataset.loc[dataset['Age'] > 64, 'Age'] = 4
dataset['Age'] = dataset['Age'].map({0:'Child', 1:'Young', 2:'Middle', 3:'Prime', 4:'Old'}).astype(str)
bar_chart('Age')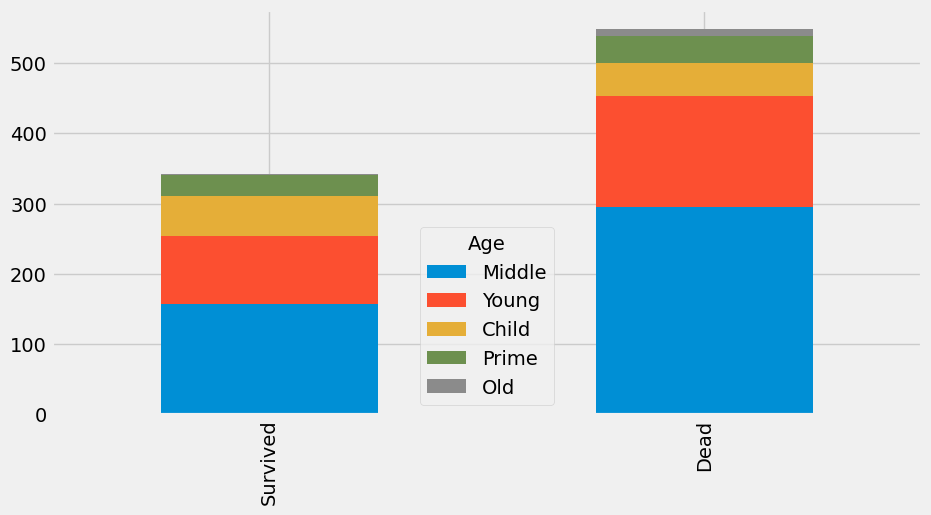
파생 변수 : 사람이 논리적으로 입증하기는 힘드나, 변수로 새로 생성
Familysize
:함께 동승한 부모님 + 형제 배우자 수 = Familysize
train['Familysize'] = train['SibSp'] + train['Parch'] + 1
test['Familysize'] = test['SibSp'] + test['Parch'] + 1facet = sns.FacetGrid(train, hue='Survived', aspect=4)
facet.map(sns.kdeplot, 'Familysize', shade = True)
facet.set(xlim=(0, train['Familysize'].max()))
facet.add_legend()
plt.show()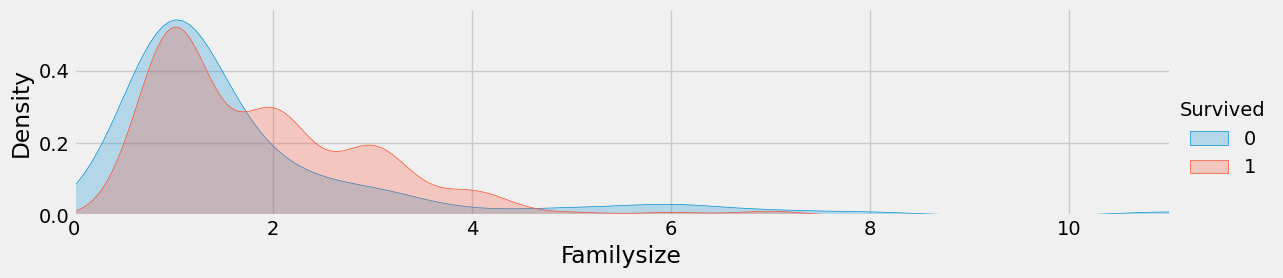
크롤링(1)
!pip install requests
import requests
res = requests.get('http://naver.com')
print('응답코드 : ', res.status_code) # 200이면 정상
res1 = requests.get('http://google.com')
print('응답코드 : ', res1.status_code)
res2 = requests.get('http://www.naver.com/user/')
print('응답코드 : ', res2.status_code) # 404 : 사용자가 사이트에서 존재하지 않는 URL을 탐색했을 때 발생
res = requests.get('http://naver.com')
print('응답코드 : ', res.status_code) # 200이면 정상
if res.status_code == requests.codes.ok:
print('정상입니다.')
else:
print("문제가 생겼습니다. [에러코드 ", res.status_code,"]")
res = requests.get('http://naver.com')
print('응답코드 : ', res.status_code) # 200이면 정상
res.raise_for_status() # html을 올바르게 작동하는 것 아니면 에러가 발생
print('웹 스크래핑을 진행합니다.')import requests
# 요청시 헤더정보를 크롬으로 지정
request_headers = {
'User-Agent' : ('Mozilla/5.0 (Windows NT 10.0;Win64; x64)\
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98\
Safari/537.36'), }
url = "https://search.naver.com/search.naver"
response = requests.get(url,headers = request_headers)
print(response)
#해당 url 요청할 때 headers를 임의로 설정하여 요청한 케이스# params 속성 이용하기
import requests
URL = 'https://www.google.com/search'
param = {"q" : "python"}
Response = requests.get(URL, params=param)
print('Response.status_code:', Response.status_code)
Response.text# 서울시 미세먼지 데이터를 활용해보자.
import requests
res = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
resj = res.json()
print(resj['RealtimeCityAir']['row'][0]['NO2'])# 서울 구 이름과 해당 구에 미세먼지 데이터만 가져와 출력해보자.
import requests
r = requests.get('http://openapi.seoul.go.kr:8088/6d4d776b466c656533356a4b4b5872/json/RealtimeCityAir/1/99')
rjson = r.json()
citys = rjson["RealtimeCityAir"]["row"]
for city in citys:
gu_name = city["MSRSTE_NM"]
gu_mise = city["IDEX_MVL"]
print(gu_name, gu_mise)beautifulsoup
: HTML정보로 부터 원하는 데이터를 가져오기 쉽게, 비슷한 분류의 데이터별로 나누어주는(parsing) 파이썬 라이브러리
from bs4 import BeautifulSoup
import requests as req
url = 'https://search.naver.com/search.naver'
res = req.get(url, params={'query':'정처기'})
if res.status_code == 200:
soup = BeautifulSoup(res.text, 'html.parser')
# '정보처리기사' 포함된 텍스트를 모두 찾기
target_lst = []
for element in soup.find_all(text=True): # 모든 텍스트를 가져옴
if '정보처리기사' in element:
target_lst.append(element.strip())
print(target_lst)
else:
print(f"요청 실패: {res.status_code}")import requests # HTTP 요청을 보내기 위한 라이브러리
from bs4 import BeautifulSoup # HTML 문서를 파싱하는 라이브러리
# 네이버 금융 - 업종별 시세 페이지 URL
url = 'https://finance.naver.com/sise/sise_group.nhn?type=upjong'
# 1단계: GET 요청을 보내 페이지의 HTML 가져오기
response = requests.get(url)
# 2단계: 응답 상태 확인 및 파싱
if response.status_code == 200:
# HTML 문서를 BeautifulSoup 객체로 파싱
soup = BeautifulSoup(response.text, 'html.parser')
# 업종 이름이 포함된 <td> 태그 찾기
td_tags = soup.find_all('td', style='padding-left:10px;')
# 3단계 각 <td> 태그 내 <a> 태그에서 텍스트 추출
print("업종 목록:")
for td in td_tags:
a_tag = td.find('a') # <td> 내부에서 <a> 태그 찾기
if a_tag:
sector_name = a_tag.text.strip() # 업종명 텍스트 추출 및 공백 제거
print(sector_name)
else:
# 요청 실패 시 에러 메시지 출력
print(f"페이지 요청 실패: 상태 코드 {response.status_code}")import requests # HTTP 요청을 보내기 위한 라이브러리
from bs4 import BeautifulSoup # HTML 문서 파싱을 위한 라이브러리
# 네이버 금융 "IT서비스" 업종 페이지 URL
url = 'https://finance.naver.com/sise/sise_group_detail.naver?type=upjong&no=267'
# GET 요청 보내기
response = requests.get(url)
# 응답 상태 확인
if response.status_code == 200:
# HTML 파싱을 위한 BeautifulSoup 객체 생성
soup = BeautifulSoup(response.text, 'html.parser')
# 종목 정보가 담긴 테이블의 행들 선택
rows = soup.select('table.type_5 tr') # 테이블의 모든 <tr> 행 선택
# 각 행에서 종목명과 현재값 추출
for row in rows:
stock_name_tag = row.select_one('td.name a') # 종목명 추출 (a 태그가 포함된 td.name)
current_price_tag = row.select_one('td.number[style="padding-right:15px;"]') # 현재값 추출 (td 태그 중 스타일이 padding-right:15px;인 값)
# 종목명과 현재값이 모두 존재하는 경우에만 출력
if stock_name_tag and current_price_tag:
stock_name = stock_name_tag.text.strip() # 종목명 텍스트 추출
current_price = current_price_tag.text.strip() # 현재값 텍스트 추출
# 결과 출력
print(f"IT서비스 종목: {stock_name}, 현재값: {current_price}")
else:
# 페이지 요청 실패 시 상태 코드 출력
print(f"페이지 요청 실패: 상태 코드 {response.status_code}")import requests as req
from bs4 import BeautifulSoup
import re
# URL 설정
url = 'https://search.naver.com/search.naver'
# HTTP 요청 보내기
try:
res = req.get(url, params={'query': '정처기'}, timeout=5) # 5초 타임아웃 설정
res.raise_for_status() # 응답 상태 코드가 200번대가 아닐 경우 예외 발생
except req.exceptions.RequestException as e:
print(f"HTTP 요청 중 오류 발생: {e}")
else:
# 성공적으로 데이터를 받았다면, HTML 파싱
res.encoding = 'utf-8' # 한글 인코딩 설정
soup = BeautifulSoup(res.text, 'html.parser')
# 정규 표현식을 사용하여 "정보처리기사"를 포함한 텍스트 찾기
target_lst = []
pattern = re.compile(r'.*정보처리기사.*') # "정보처리기사"가 포함된 텍스트 찾기 위한 정규식 패턴
# 페이지에서 모든 텍스트 추출
for element in soup.find_all(text=True): # 모든 텍스트 요소 순회
if pattern.match(element): # "정보처리기사"를 포함하는 텍스트만 필터링
target_lst.append(element.strip()) # 공백 제거 후 리스트에 추가
# target_lst += element.strip() -> 결과가 이상함(나중에 꼭 해볼 것)
# 결과 출력
if target_lst:
print("정보처리기사 관련 텍스트 목록:")
for item in target_lst:
print(item)
else:
print("정보처리기사 관련 텍스트를 찾을 수 없습니다.")정규표현식
1) .
.은 한 개의 임의의 문자를 나타낸다. 예를 들어 정규 표현식이 a.c라고 한다면, a와 c사이에 어떤 1개의 문자라도 올 수 있다는 뜻이다.
import re
r = re.compile("a.c")
print(r.search("kkk")) # 아무런 결과도 출력되지 않는다.
print(r.search("abc"))2) ?
?는 ? 앞의 문자가 존재할 수도 있고, 존재하지 않을 수도 있는 경우를 나타낸다. 예를 들어서 정규 표현식이 ab?c라고 한다면, b는 있다고 취급할 수도 있고 없다고 취급할 수도 있다. 즉, abc와 ac 모두 매치할 수 있다.
r = re.compile("ab?c")
print(r.search("abbc")) # 아무것도 출력되지 않음
print(r.search("abc")) # b가 있는 것으로 판단하여 abc를 매치함
print(r.search("ac")) # b가 없는 것으로 판단하여 ac를 매치함3) *
*은 바로 앞의 문자가 0개 이상일 경우를 나타낸다. 앞의 문자는 존재하지 않을 수도 있으며, 또는 여러 개일 수도 있다. 예를 들어 정규 표현식이 abc라고 한다면 ac, abc, abbc, abbbc 등과 매치할 수 있다.
r = re.compile("ab*c")
print(r.search("a")) # 아무것도 출력되지 않음
print(r.search("ac"))
print(r.search("abc"))
print(r.search("abbc"))4) +
+는 *와 유사하다. 하지만 다른 점은 앞의 문자가 최소 1개 이상이어야 한다. 예를 들어 ab+c라고 하면, ac는 매치되지 않는다.
r = re.compile('ab+c')
print(r.search("ac")) # 아무것도 출력되지 않는다.
print(r.search("abc"))5) ^
^는 시작되는 글자를 지정한다. 가령 정규표현식이 ^a라면 a로 시작되는 문자열만을 찾아낸다.
r = re.compile('^a')
print(r.search('bbc')) # 아무것도 출력되지 않음
print(r.search('ab'))6) []
[]안에 문자들을 넣으면 그 문자들 중 한 개의 문자와 매치라는 의미를 가진다. 예를 들어 정규 표현식이 [abc]라면, a 또는 b 또는 c가 들어가 있는 문자열과 매치된다. 범위를 지정하는 것도 가능하다. [a-zA-Z]는 알파벳 전부를 의미하며, [0–9]는 숫자 전부를 의미한다.
[a-c] #[abc]와 같음
[0-5] #[012345]와 같음
[a-zA-Z] #모든 알파벳
[0-9] 숫자
r = re.compile("[abc]")
print(r.search('zzz')) # 아무것도 출력되지 않음
print(r.search('a'))
print(r.search('acg'))
print(r.search('babo'))
r = re.compile("[a-z]")
print(r.search('AAA')) # 아무것도 출력되지 않음
print(r.search('aA'))7) [^문자]
[^문자]는 5)에서 설명한 ^와는 완전히 다른 의미로 쓰인다. 여기서는 ^ 기호 뒤에 붙은 문자들을 제외한 모든 문자를 매치하는 역할을 한다. 예를 들어 [^abc]라는 정규 표현식이 있다면, a 또는 b 또는 c가 들어간 문자열을 제외한 모든 문자열을 매치한다.
r = re.compile('[^abc]')
print(r.search("a")) # 아무것도 출력되지 않음
print(r.search("ahoho"))
print(r.search("1st"))정규 표현식 모듈 함수 예제
1) re.match()와 re.search()의 차이
search()가 정규 표현식 전체에 대해서 문자열이 매치하는지를 본다면, match()는 문자열의 첫 부분부터 정규표현식과 매치하는지를 확인한다. 문자열 중간에 찾을 패턴이 있다고 하더라도, match 함수는 문자열의 시작에서 패턴이 일치하지 않으면 찾지 않는다.
r = re.compile("ab.")
print(r.search("kkkabc"))
print(r.match("kkkabc")) # 아무것도 출력되지 않음
print(r.match("abckkk"))위의 경우 ab.이기 때문에 ab뒤에 어떤 한 글자가 존재할 수 있다는 패턴을 의미한다. search 모듈 함수에 kkkabc라는 문자열을 넣어 매치되는지 확인한다면 abc라는 문자열에서 매치되어 Match object를 리턴한다. 하지만 match 모듈 함수의 경우 앞 부분이 ab.와 매치되지 않기 때문에, 아무런 결과도 출력하지 않는다. 하지만 abckkk로 시도하면 시작 부분과 매치되었기 때문에 정상적으로 Match object를 리턴한다.
2) re.findall()
findall() 함수는 정규 표현식과 매치되는 모든 문자열들을 리스트로 리턴한다. 단, 매치되는 문자열이 없다면 빈 리스트를 리턴한다.
text = """이름 : 김철수
전화번호 : 010 - 1234 -1234
나이 : 30
성별 : 남"""
print(re.findall("\d+", text))
print(re.findall("\d+", "문자열입니당.")) # 빈리스트 반환3) re.sub() sub() 함수는 정규 표현식 패턴과 일치하는 문자열을 찾아 다른 문자열로 대체할 수 있다.
text="Regular expression : A regular expression, regex or regexp[1] (sometimes called a rational expression)[2][3] is, in theoretical computer science and formal language theory, a sequence of characters that define a search pattern."
re.sub('[^a-zA-Z]',' ',text)위와 같은 경우, 영어 문장에 각주 등과 같은 이유로 특수 문자가 섞여 있다. 자연어 처리를 위해 특수 문자를 제거하고 싶다면 알파벳 외의 문자는 공백으로 처리하는 등의 사용 용도로 쓸 수 있다.
# 네이버 검색 API 예제 - 블로그 검색
import os
import sys
import urllib.request
client_id = "fRibnH94ClLlzjTbqSGk"
client_secret = "m1Zb0DhpYr"
encText = urllib.parse.quote("경북궁")
url = "https://openapi.naver.com/v1/search/blog?query=" + encText # JSON 결과
# url = "https://openapi.naver.com/v1/search/blog.xml?query=" + encText # XML 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
print(response_body.decode('utf-8'))
else:
print("Error Code:" + rescode)import os
import sys
import urllib.request
import json
import pandas as pd
def getresult(client_id,client_secret,query,display=10,start=1,sort='sim'):
#sort : sim(정확도순으로 내림차순 정렬(기본값)), date(날짜순으로 내림차순 정렬)
encText = urllib.parse.quote(query)
url = "https://openapi.naver.com/v1/search/blog?query=" + encText + \
"&display=" + str(display) + "&start=" + str(start) + "&sort=" + sort
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
response_json = json.loads(response_body)
else:
print("Error Code:" + rescode)
return pd.DataFrame(response_json['items'])
import pandas as pd
client_id = "fRibnH94ClLlzjTbqSGk"
client_secret = "m1Zb0DhpYr"
query = '경복궁'
display=100
start=1
sort='sim'
result_all=pd.DataFrame()
for i in range(0,2):
start= 1 + 100*i
result= getresult(client_id,client_secret,query,display,start,sort)
result_all=pd.concat([result_all,result])
result_allNaver_client_id = "key"
Naver_client_secret = "key"
Kakao_API_key= 'key' #인증받은 rest api key 값 입력할 것.
Google_SEARCH_ENGINE_ID = 'key'
Google_API_KEY = 'key'Trash_Link = ["tistory", "kin", "youtube", "blog", "book", "news", "dcinside", "fmkorea", "ruliweb", "theqoo", "clien", "mlbpark", "instiz", "todayhumor"]
def Google_API(query, wanted_row):
query= query.replace("|","OR")
query += "-filetype:pdf"
start_pages=[]
df_google= pd.DataFrame(columns=['Title','Link','Description'])
row_count =0
for i in range(1,wanted_row+1000,10):
start_pages.append(i)
for start_page in start_pages:
url = f"https://www.googleapis.com/customsearch/v1?key={Google_API_KEY}&cx={Google_SEARCH_ENGINE_ID}&q={query}&start={start_page}"
data = requests.get(url).json()
search_items = data.get("items")
try:
for i, search_item in enumerate(search_items, start=1):
# extract the page url
link = search_item.get("link")
if any(trash in link for trash in Trash_Link):
pass
else:
# get the page title
title = search_item.get("title")
# page snippet
descripiton = search_item.get("snippet")
# print the results
df_google.loc[start_page + i] = [title,link,descripiton]
row_count+=1
if (row_count >= wanted_row) or (row_count == 300) :
return df_google
except:
return df_google
return df_googledef Naver_API(query,wanted_row):
query = urllib.parse.quote(query)
display=100
start=1
end=wanted_row+10000
idx=0
sort='sim'
df= pd.DataFrame(columns=['Title','Link','Description'])
row_count= 0
for start_index in range(start,end,display):
url = "https://openapi.naver.com/v1/search/webkr?query="+ query +\
"&display=" + str(display)+ \
"&start=" + str(start_index) + \
"&sort=" + sort
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",Naver_client_id)
request.add_header("X-Naver-Client-Secret",Naver_client_secret)
try:
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
items= json.loads(response_body.decode('utf-8'))['items']
remove_tag = re.compile('<.*?>')
for item_index in range(0,len(items)):
link = items[item_index]['link']
if any(trash in link for trash in Trash_Link):
idx+=1
pass
else:
title = re.sub(remove_tag, '', items[item_index]['title'])
description = re.sub(remove_tag, '', items[item_index]['description'])
df.loc[idx] =[title,link,description]
idx+=1
row_count+=1
if (row_count >= wanted_row) or (row_count == 300):
return df
except:
return dfdef Daum_API(query,wanted_row):
pages= wanted_row//10
method = "GET"
url = "https://dapi.kakao.com/v2/search/web"
header = {'authorization': f'KakaoAK {Kakao_API_key}'}
df= pd.DataFrame(columns=['Title','Link','Description'])
row_count=0
for page in range(1,pages+10):
params = {'query' : query, 'page' : page}
request = requests.get( url, params= params, headers=header )
for i, item in enumerate(request.json()["documents"], start=1):
link = item['url']
try:
written_year=int(item['datetime'][:4])
except:
written_year = 2023
if (any(trash in link for trash in Trash_Link) or (written_year <2020)):
pass
else:
title= item["title"]
description = item["contents"]
df.loc[10*page+i] =[title,link,description]
row_count+=1
if (row_count >= wanted_row) or (row_count == 300):
remove_tag = re.compile('<.*?>')
df['Title'] =df['Title'].apply(lambda x :re.sub(remove_tag, '',x))
df['Description'] =df['Description'].apply(lambda x :re.sub(remove_tag, '',x))
return df
remove_tag = re.compile('<.*?>')
df['Title'] =df['Title'].apply(lambda x :re.sub(remove_tag, '',x))
df['Description'] =df['Description'].apply(lambda x :re.sub(remove_tag, '',x))
return dffrom datetime import datetime
today = datetime.today().strftime("%Y%m%d")
todaydef final(query,wanted_row=100):
df_google = Google_API(query,wanted_row)
df_google['search_engine']='Google'
df_naver = Naver_API(query,wanted_row)
df_naver['search_engine']='Naver'
df_daum = Daum_API(query,wanted_row)
df_daum['search_engine']='Daum'
df_final= pd.concat([df_google,df_naver,df_daum])
df_final['search_date'] = today
df_final.reset_index(inplace=True,drop=True)
return df_final############### 검색할 검색어를 query에, 검색엔진당 추출할 문서의 개수를 wanted_row 에 적어주세요####################
query = "뇌진탕 | 외상성 뇌손상 | 두부외상"
wanted_row = 100
import pandas as pd
import re # Regular expression(정규표현식)
import requests
import urllib
df = final(query=query, wanted_row=wanted_row)
dfdf[df['search_engine']=='Naver']
import pandas as pd
df1 = pd.DataFrame({'name':['이철수','김영희','홍길동','John Smith','Mary Doe'],
'sex' : ['M','F','M','M','F'],
'age': [23, 25,21,33,45],
'height':[153.5, 153.5, 163.4,180.0, 165.7]})
df1
df1[['age','height']]
df1[df1['sex']=='M']
df1[df1['age'].isin([25,33])]
df1['height']>=160.02 and 5 # 5
2 & 5 # 0
2 or 5 # 2
2 | 5 # 7df1[(df1['sex']=='M') & (df1['height']>=160.0)]
df1[(df1['age']<=30) | (df1['height']<160.0)]