
스키마 = 데이터베이스
DDL
index
- 검색 조건으로 사용되는 컬럼인 경우 따로 정렬해 두면 데이터를 찾을 때 빨리 찾을 수 있다.
- 특정 컬럼의 값을 A-Z 또는 Z-A로 정렬시키는 문법이 인덱스이다.
- DBMS는 해당 컬럼의 값으로 정렬한 데이터 정보를 별도의 파일로 생성한다.
- 보통 책 맨 뒤에 붙어있는 색인표와 같다.
- 인덱스로 지정된 컬럼의 값이 추가/변경/삭제 될 때 인덱스 정보도 갱신한다.
- 따라서 입력/변경/삭제가 자주 발생하는 테이블에 대해 인덱스 컬럼을 지정하면,
입력/변경/삭제 시 인덱스 정보를 갱신해야 하기 때문에
입력/변경/삭제 속도가 느려지는 문제가 있다. - 대신 조회 속도는 빠르다.
create table test1(
no int primary key,
name varchar(20),
age int,
kor int,
eng int,
math int,
constraint test1_uk unique (name, age),
fulltext index test1_name_idx (name) -- 이름 데이터를 가지고 인덱스를 만들어줘!
);
insert into test1(no,name,age,kor,eng,math) values(1,'aaa',20,80,80,80);
insert into test1(no,name,age,kor,eng,math) values(2,'bbb',21,90,80,80);
insert into test1(no,name,age,kor,eng,math) values(3,'ccc',20,80,80,80);
insert into test1(no,name,age,kor,eng,math) values(4,'ddd',22,90,80,80);
insert into test1(no,name,age,kor,eng,math) values(5,'eee',20,80,80,80);- name 컬럼은 인덱스 컬럼으로 지정되었기 때문에
DBMS는 데이터를 추가하거나 삭제할 때 name 컬럼의 색인표를 갱신한다. - 단점, 이런 이유로 이름으로 검색할 때 찾기 속도는 빠르지만,
입력,변경,삭제 속도는 느리게 된다.
FULLTEXT INDEX 추가하기
FULLTEXT INDEX는 일반적인 인덱스와는 달리 매우 빠르게 테이블의 모든 텍스트 필드를 검색한다.
이 인덱스는 검색 엔진과 유사한 방법으로 자연어를 이용하여 데이터를 검색할 수 있도록 모든 데이터의 문자열 단어를 저장한다.
인덱스 컬럼의 활용
검색할 때 사용한다.
select * from test1 where name = 'bbb';컬럼 값 자동 증가
- 숫자 타입의 PK 컬럼 또는 Unique 컬럼인 경우 값을 1씩 자동 증가시킬 수 있다.
- 즉 데이터를 입력할 때 해당 컬럼의 값을 넣지 않아도 자동으로 증가된다.
- 단 삭제를 통해 중간에 비어있는 번호는 다시 채우지 않는다.
즉, 증가된 번호는 계속 앞으로 증가할 뿐이다.
- 테이블 생성
create table test1(
no int not null,
name varchar(20) not null
);
- 특정 컬럼의 값을 자동으로 증가하게 선언한다.
- 단, 반드시 해당 컬럼이 key(primary key 나 unique)여야 한다.
→ 건너 뛰면, 건너 뛴 번호부터,
삭제해도, 삭제한 번호 이후로 번호가 자동으로 붙는다.
alter table test1
modify column no int not null auto_increment; /* 아직 no가 pk가 아니기 때문에 오류*/
alter table test1
add constraint primary key (no); /* 일단 no를 pk로 지정한다.*/
alter table test1
add constraint unique (no); /* no를 unique로 지정해도 한다.*/
alter table test1
modify column no int not null auto_increment; /* 그런 후 auto_increment를 지정한다.*/- 입력 테스트
/* auto-increment 컬럼의 값을 직접 지정할 수 있다.*/
insert into test1(no, name) values(1, 'xxx');
/* auto-increment 컬럼의 값을 생략하면 마지막 값을 증가시켜서 입력한다.*/
insert into test1(name) values('aaa');
insert into test1(no, name) values(100, 'yyy');
insert into test1(name) values('bbb'); /* no는 101이 입력된다.*/
insert into test1(name) values('ccc'); /* no=102 */
insert into test1(name) values('ddd'); /* no=103 */
/* 값을 삭제하더라도 auto-increment는 계속 앞으로 증가한다.*/
delete from test1 where no=103;
insert into test1(name) values('eee'); /* no=104 */
insert into test1(name) values('123456789012345678901234');
/* 다른 DBMS의 경우 입력 오류가 발생하더라도 번호는 자동 증가하기 때문에
* 다음 값을 입력할 때는 증가된 값이 들어간다.
* 그러나 MySQL(MariaDB)는 증가되지 않는다.
*/
insert into test1(name) values('fff'); /* no=105 */뷰(view)
- 조회 결과를 테이블처럼 사용하는 문법
- select 문장이 복잡할 때 뷰로 정의해 놓고 사용하면 편리하다.
- 원본 테이블 만들기
create table test1 (
no int primary key auto_increment,
name varchar(20) not null,
class varchar(10) not null,
working char(1) not null,
tel varchar(20)
);
insert into test1(name,class,working) values('aaa','java100','Y');
insert into test1(name,class,working) values('bbb','java100','N');
insert into test1(name,class,working) values('ccc','java100','Y');
insert into test1(name,class,working) values('ddd','java100','N');
insert into test1(name,class,working) values('eee','java100','Y');
insert into test1(name,class,working) values('kkk','java101','N');
insert into test1(name,class,working) values('lll','java101','Y');
insert into test1(name,class,working) values('mmm','java101','N');
insert into test1(name,class,working) values('nnn','java101','Y');
insert into test1(name,class,working) values('ooo','java101','N');뷰 만들기
직장인만 조회한 결과를 가상 테이블로 만들기
create view worker
as select no, name, class from test1 where working = 'Y';- view가 참조하는 테이블에 데이터를 입력한 후 view를 조회하면?
⇒ 새로 추가된 컬럼이 함께 조회된다. - 뷰를 조회할 때 마다 매번 select 문장을 실행한다.
⇒ 미리 결과를 만들어 놓는 것이 아니다. - 일종의 조회 함수 역할을 한다.
- 목적은 복잡한 조회를 가상의 테이블로 표현할 수 있어 SQL문이 간결해진다.
insert into test1(name,class,working) values('ppp','java101','Y');
select * from worker;즉, 뷰는 따로 데이터를 가져와서 별도의 테이블을 만든 것이 아니라,
그저 데이터를 가져와서 보여주는 것이다.
그래서 원본 테이블 수정하면 뷰도 자동으로 바로 수정된다.
뷰 삭제
drop view worker;KEY - 데이터를 구별하는 식별자
컬럼: 이름, 이메일, 암호, 성별, 학교, 나이, 주민번호, 휴대폰, 주소, 우편번호, 재직여부
1. KEY
데이터를 식별할 때 사용할 수 있는 컬럼들의 값
{이름, 이메일}
{이름, 학교, 우편번호}
{이메일}
{이름, 주민번호}
{주민번호}
{이름, 주소}
{이름, 휴대폰}
{휴대폰, 우편번호}
2. Candidate KEY (후보키 = 최소키)
KEY중에서 최소의 컬럼으로 줄인 키
{이메일}
{주민번호}
{휴대폰}
{이름, 주소} ← 굳이? 한 개의 컬럼으로 된 KEY가 많으니까 두 개 이상의 컬럼을 키로 사용할 필요가 없다.
3. Primary KEY (주키)
후보키 중에서 DB관리자가 선정한 키
{이메일}
Alternative KEY (대안키)
주키 대신 사용 가능한 후보키 → unique 컬럼으로 지정한다.
{주민번호}
{휴대폰}
4. Artificial KEY
PK로 사용하기에 적절한 키가 없다면, 임의의 컬럼을 만들어 PK로 지정한다.
→ 보통 '일련번호' 컬럼!
{학생번호}
변경할 수 있으려면, PK가 되어서는 안된다!
{이메일}
{주민번호} ← 개인정보보호에 포함되기 떄문에 (법에 따라) 사용 불가!
{휴대폰}
DBMS 서버와 다중 클라이언트 접속

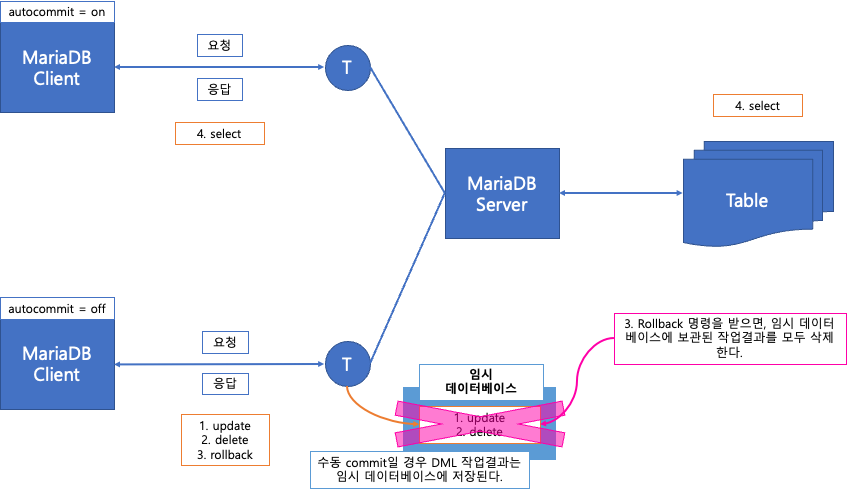
Commit과 Rollback → transaction을 다룬다.
데이터처리 작업 중에서 한 단위로 묶어서 처리해야하는 경우가 있다.
Transaction: 여러개의 DML작업을 한 단위로 묶은 것
그 단위에 묶인 작업이 모두 성공할 때만 업무가 완성된다.
DML(Data Manipulation Language)
데이터 등록, 변경, 삭제를 다루는 SQL 문법
insert, delete, update, select
insert
- 데이터를 입력할 때 사용하는 문법이다.
- 제약 조건 추가:
alter table 테이블명
add constraints 컬럼명 - 자동 증가 칼럼 지정:
alter table 테이블명
modify column 컬럼명 데이터타입 (not null) auto_increment;
/* PK 컬럼 지정 */
alter table test1
add constraint test1_pk primary key (no);
/* 자동 증가 컬럼 지정 */
alter table test1
modify column no int not null auto_increment;- 전체 컬럼 값 입력하기
/* 컬럼을 지정하지 않으면
* 테이블을 생성할 때 선언한 컬럼 순서대로
* 값을 지정해야 한다.*/
insert into 테이블명 values(값,....);
insert into test1 values(null,'aaa','111','222','10101','seoul');
/* 컬럼을 명시할 수 있다. 이때 값을 입력하는 컬럼의 순서를 바꿀 수 있다. */
insert into 테이블명(컬럼,컬럼,...) values(값,값,...);
insert into test1(name,fax,tel,no,pstno,addr)
values('bbb','222','111',null,'10101','seoul');- 값을 입력할 컬럼을 선택하기. 단 필수 입력 컬럼은 반드시 선택해야 한다.
/* no 컬럼은 필수 입력 컬럼이지만,
자동 증가 컬럼이기 때문에 값을 입력하지 않아도 된다.*/
insert into test1(name,tel) values('ccc','333');여러 개의 값을 한 번에 insert 하기
insert into test1(name,tel) values
('aaa', '1111'),
('bbb', '2222'),
('ccc', '3333');select 결과를 테이블에 바로 입력하기
select 결과의 컬럼명과 insert 테이블의 컬럼명이 같을 필요는 없다.
그러나 결과의 컬럼 개수와 insert 하려는 컬럼 개수가 같아야 한다.
결과의 컬럼 타입과 insert 하려는 컬럼의 타입이 같거나 입력 할 수 있는 타입이어야 한다.
insert into test2(fullname,phone)
select name, tel from test1 where addr='seoul';update
- 등록된 데이터를 변경할 때 사용하는 명령이다.
update 테이블명 set 컬럼명=값, 컬럼명=값, ... where 조건...;delete
- 데이터를 삭제할 때 사용하는 명령이다.
delete from 테이블명 where 조건;autocommit
mysql은 autocommit의 기본 값이 true이다.
따라서 명령창에서 SQL을 실행하면 바로 실제 테이블에 적용된다.
수동으로 처리하고 싶다면 autocommit을 false로 설정하라!
set autocommit=false;insert/update/delete을 수행한 후 승인을 해야만 실제 테이블에 적용된다.
commmit;마지막 commit 상태로 되돌리고 싶다면,
rollback;DQL(Data Query Language)
데이터를 조회할 때 사용하는 문법
select
- 테이블의 데이터를 조회할 때 사용하는 명령이다.
조회하는 컬럼에 별명 붙이기
- 별명을 붙이지 않으면 원래의 컬럼명이 조회 결과의 컬럼이름으로 사용된다.
- 위의 예제처럼 복잡한 식으로 표현한 컬럼인 경우 컬럼명도 그 식이 된다.
- 이런 경우 별명을 붙이면 조회 결과를 보기 쉽다.
Selection과 Projection

- where 절과 연산자를 이용하여 조회 조건을 지정할 수 있다.
- 이렇게 조건을 지정하여 결과를 선택하는 것을 "셀렉션(selection)" 이라 한다.
