
- DB 모델링
- 엔티티 식별 및 속성 식별
- 제1,2,3 정규화 방법
- 논리 모델링 및 물리 모델링
- 포워드 엔지니어링을 통해 DDL 생성 및 테이블 생성
DB 모델링
- 모델링? 시스템을 분석하고 구조화시켜 글과 그림으로 표현(추상화)한 것.
- 렌더링? 명령어를 해석하여 화면에 출력하는 것.
예) HTML 렌더링 => HTML 태그를 해석하여 그에 해당하는 UI를 출력하는 것. - DB 모델링? 데이터를 분석하고 구조화시켜 데이터 속성과 관계를 글과 그림으로 표현(추상화)한 것.
- 목표? 데이터가 중복되지 않도록 테이블을 구조화하는 것.
- 중복 데이터를 제거 ==> 데이터의 안정성, 신뢰성을 높인다. ==> 일관성, 무결성을 유지한다.
주요 용어
- table(relation; entity; file)
- intension(schema; header) => 데이터 구조 설계도
- extension(instance; data) => 데이터
- row(tuple; record) => 데이터(여러 컬럼으로 이루어진) 한 개. 예) 학생
- column(attribute; field) => 데이터의 한 항목. 예) 이름, 학번, 전화번호
키(key)
- 데이터를 구분할 때 사용할 식별자.
- "수퍼 키(super key)"라 부르기도 한다.
- 식별자?
- 데이터를 구분할 때 사용하는 값.
- 한 개 이상의 컬럼으로 구성된다.
- 식별자를 key라고 부른다.
- 예) 학생(학번, 이름, 전화, 이메일, 학과, 우편번호, 주소, 주민등록번호)
- 학번 (O)
- 주민등록번호 (O)
- 이메일 (O)
- 전화 (X)
- 이름 (X)
- (이름,전화) (O)
- (이메일,이름) (O)
- (이름,학과,학번) (O)
- (이름,학과,전화) (O)
후보키(candidate key) 선정
- super key 들 중에서 선별된 최소키를 가리킨다.
- 최소키? 최소한의 컬럼 값 만으로 식별이 가능한 key.
- 수퍼 키 예)
- 학번 (O)
- 주민등록번호 (O)
- 이메일 (O)
- (이름,전화) (O) => 이름과 전화 값을 묶은 것 보다 적은 개 수의 후보 키가 있다면 가능한 제외하라!
- (이메일,이름) (X) => 이메일 만으로 식별 가능
- (이름,학과,학번) (X) => 학번 만으로 식별 가능
- (이름,학과,전화) (x) => 이름과 학과, 전화 보다 더 적은 컬럼의 후보 키가 있기 때문에 가능한 제외한다.
기본 키/주 키(primary key; PK) 선정 p.83
- 후보키 중에서 데이터 식별자로 사용하기 위해 선정된 키.
- 예) 학번
- 나머지 후보키는 대안키(alternate key)라 부른다.
- 예) 주민등록번호, 이메일, (이름,전화)
- 왜? 비록 PK는 아니지만 PK와 마찬가지로 데이터 식별자로 대체하여 사용할 수 있기 때문이다.
대리 키(surrogate key)/인공 키(artificial key)
- 주 키의 컬럼의 개수가 많거나 주 키로 사용할 적절한 컬럼이 없는 경우,
일련번호와 같은 임의의 컬럼을 추가하여 PK로 만든다.- 예1) 게시물 첨부파일(파일명, 등록일)
- 파일명이 중복될 수 있다.
- 파일명과 등록일을 묶어서 PK로 사용하기에는 적절하지 않다.
- 이런 경우 "첨부파일번호" 컬럼을 임의로 추가하여 PK로 설정한다.
- 결론) 게시물 첨부파일(파일번호, 파일명, 등록일)
- 예2) 수강신청(수강생이름, 수강생전화, 수강생이메일, 과목명, 결제여부, 결제유형)
- 주 키로 사용할만한 적절한 컬럼이 없다.
- 여러 개의 컬럼을 묶어서 주 키로 사용하자니 너무 복잡하다.
- 이런 경우에도 "수강신청번호"와 같은 임의의 컬럼을 추가하여 PK로 선정하는 것이 좋다.
- 예1) 게시물 첨부파일(파일명, 등록일)
- 주 키로 선정된 컬럼의 값은 변경될 수 없기 때문에, (다른 곳에서 사용하고 있지 않다면 변경 가능)
일련번호와 같은 임의의 컬럼을 pk로 사용한다.- pk가 아닌 컬럼은 언제든 값을 변경할 수 있다.
UNIQUE키 같은 경우, 중복은 안되지만, 변경은 가능하다. - 예1) 수강생(이름, 나이, 핸드폰, 이메일, 우편번호, 주소, 은행명, 계좌번호, 최종학력, 전공)
- 핸드폰이나 이메일은 PK로 사용할 수 있다.
- 그러나 핸드폰이나 이메일은 가끔 변경될 수 있다.
- 문제는 PK로 지정된 컬럼은 한 번 사용되면 변경할 수 없다는 것이다.
- 핸드폰과 이메일처럼 나중에 변경될 수 있는 컬럼인 경우 PK로 지정하지 않는 것이 좋다.
- 그럼 PK 컬럼은 무엇을 사용하는가?
- 이런 경우 "수강생번호"와 같은 임의의 컬럼을 만들어 PK로 사용한다.
- 예2) 페이스북에 로그인할 때 이메일이나 전화번호를 사용하지만,
실제 주키로 사용하는 것은 사용자 일련번호이다.
- pk가 아닌 컬럼은 언제든 값을 변경할 수 있다.
대체 키(alternate key)
- 후보 키(candidate key) 중에서 PK로 선정된 키를 제외한 나머지 후보 키를 가리킨다.
- 대체 키 예)
- 학번 (X) => 만약 학번이 PK로 선정되었다면 대체 키가 아니다.
- 주민등록번호 (O) => PK 대신 사용할 수 있는 키를 대체 키라 부른다.
- 이메일 (O) => PK 대신 사용할 수 있는 키를 대체 키라 부른다.
- 대체 키는 테이블을 정의할 때 Unique 컬럼으로 지정된다.
- 즉 PK는 아니지만 값이 중복되면 안되는 컬럼이기 때문에 중복되지 않도록 유니크 컬럼으로 지정한다.
외래 키(foreign key)
- 다른 릴레이션(테이블)의 PK 값을 저장하는 컬럼.
- FK가 있는 테이블을 자식 테이블(릴레이션)이라 부르고,
FK가 가리키는 PK컬럼이 있는 테이블을 부모 테이블(릴레이션)이라 부른다. - 보통 부모-자식 관계를 맺는 테이블이 있을 때,
자식 테이블 쪽에 부모 테이블의 데이터를 가리키기 위해 외부키 컬럼을 둔다.
[논리모델]
- 특정 DBMS를 고려하지 않고 수행하는 개념적인 모델링
01. 엔티티 식별 및 속성 식별
- 특정 값들의 집합? 시스템에서 다루는 데이터를 식별한다.
- 다른 말로 "테이블"이라고 한다.
- 테이블을 구성하는 값 => 속성(attribute) = 컬럼(column)
- 예:
- 학생(이름,전화,이메일,주소,...)
- 강의(강의명,설명,시작일,종료일,강의료,...)
02. 주 키 선정(Primary Key; PK)
- 데이터를 구분할 때 사용할 식별자를 지정한다.
- 만약 PK로 지정할 적절한 컬럼이 없거나, 있더라도 여러 개의 컬럼을 묶어서 사용해야 하는 경우
surrogate key(대리 키=인공 키) 사용을 고려하라!
03. 테이블 간의 관계 식별
1) 포함 관계 및 배타적 관계 식별
- 여러 테이블에 공통으로 포함되는 컬럼이 있는 경우, 별도의 테이블로 분리한다.
- 공통 데이터를 저장하고 있는 테이블 쪽(수퍼 타입 테이블)을 부모 테이블로 하고
부모 테이블을 참조하는 테이블(서브 타입 테이블)을 자식 테이블로 하여 테이블 간에 관계를 맺는다.- 자식 테이블 쪽에 FK가 추가된다.
- 관계 유형
- 포함 관계
- 여러 테이블에서 동시에 포함할 수 있는 관계이다.
- 배타적 관계
- 여러 테이블 중에서 오직 한 개의 테이블만 포함할 수 있는 관계다.
- 참고:
- 포함관계와 배타적관계를 제어할 수 있는 SQL 문법은 없다.
- 프로그래밍으로 제어해야 한다.
- 포함 관계
2) 일반 관계
- 두 테이블 사이의 관계 식별하여 연결한다.
- 부모-자식 관계로 정의한다.
- 데이터를 참조하는 쪽이 자식 테이블이다.
- 데이터를 참조 당하는 쪽이 부모 테이블이다.
04. 제1정규화
- 정규화? 데이터 중복을 찾아내어 별도의 테이블로 데이터를 분리시키는 것.
- 중복 데이터 또는 중복 컬럼을 별도의 테이블로 분리하여 부모-자식 관계를 맺는다.
- 데이터를 참조 하는 테이블이 자식테이블이고, 데이터를 갖고 있는 테이블이 부모 테이블이다.
- 자식 테이블에서는 부모 테이블의 데이터를 가리키기 위해 그 데이터의 pk값을 보관해야 한다.
- 부모-자식 테이블을 식별하기 애매할 때 1 : 다 관계에서 1 쪽이 부모 테이블이다.
- 이렇게 부모 테이블의 데이터에 대해 PK값을 저장하는 컬럼을 외부키(FK)라 부른다.
- 중복 컬럼? 사진1, 사진2, 사진3
- 중복 데이터? 교육센터명, 부서명, 은행명, ...
05. 제2정규화
- PK가 여러 컬럼으로 이루어진 경우에 수행
- 모든 일반 컬럼은 반드시 PK 컬럼에 종속되어야 한다.
그렇지 않은 일반 컬럼이 있다면 별도의 테이블로 분리하여 부모-자식 관계를 맺는다.
06. 제3정규화
- 어떤 컬럼이 PK가 아닌 다른 일반 컬럼에 종속되는 경우가 있다면,
별도 테이블로 분리하여 부모-자식 관계를 맺는다.- 예) 우편번호와 기본 주소
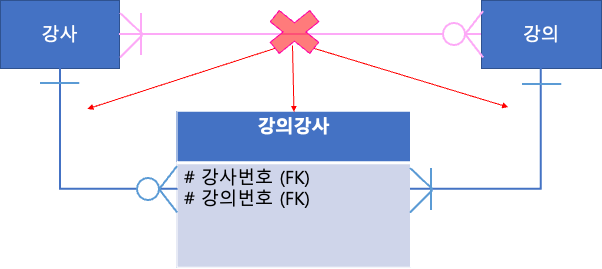
07. 다 대 다 관계의 해소
- 테이블과 테이블 사이에 다 대 다 관계를 형성한다면,
일 대 다의 관계로 변경해야 한다. - 왜? DBMS는 물리적으로 다 대 다 관계의 데이터를 저장할 수 없다.
- 해결책?
두 테이블의 관계를 저장할 테이블을 만든다.
"관계 테이블" 이라 부른다.
관계 테이블은 각 테이블과 일 대 다의 관계를 맺는다.
08. 관계의 차수 지정 p.321 ~ 324, 329
- 데이터 끼리 상호 관계의 개수를 지정한다.
- 예)
1 : (0이상) => FK 컬럼이 not null 이다.
1 : 1.. (1이상) => FK 컬럼이 not null 이다.
0,1 : (0이상) => FK 컬럼이 null 허용이다.
0,1 : 1.. (1이상) => FK 컬럼이 null 허용이다.
09. 유니크(Unique) 컬럼 지정
- PK는 아니지만 PK처럼 중복되어서는 안되는 컬럼이다.
- 대체 키(alternate key) 컬럼이 유니크 컬럼이 된다.
- 즉 PK로 선정되지 않은 나머지 후보 키는 유니크 컬럼으로 지정하여 데이터가 중복되지 않도록 한다.
10. null 허용 여부 지정
- 필수 입력 컬럼인지 선택 입력 컬럼인지 지정한다.
11. 인덱스 컬럼 지정
- 데이터를 찾을 때 검색 조건으로 사용할 컬럼을 지정한다.
- 조회 컬럼으로 지정하면 그 컬럼의 값으로 색인표가 자동으로 생성되어
데이터를 찾는 속도가 빨라진다. - 장점: select 속도가 빨라진다.
단점: insert,update,delete 할 때 마다 색인표를 갱신해야하므로 속도가 느리다.
12. 포함관계와 배타적 관계 식별
- 테이블의 공통 컬럼을 추출하여 수퍼 타입 테이블을 정의한다.
- 부모(수퍼타입 테이블) ↔ 자식(서브타입 테이블) 관계를 맺는다.
- DBMS의 문법으로는 포함관계와 배타적 관계를 구분할 수 없다.
⇒ 프로그래밍으로 처리해야한다.
[물리모델]
- 특정 DBMS에 맞춘 물리적인 모델링
21. DBMS에 맞춰서 테이블명과 컬럼명을 설정한다.
- DBMS에서 테이블명과 컬럼명을 작성할 때 보통 다음의 규칙에 따라 작성한다.
예) first name(FST_NM), regist date(REG_DT), teacher assignment(TCH_ASN) - 단어는 알파벳 3자 또는 4자로 축약해서 표현한다.
- 단어와 단어 사이는 밑 줄( _ )로 표현한다.
22. 도메인(domain) 정의 및 적용
- 비슷한 종류의 컬럼들을 묶어 새 타입으로 정의한다.
- 이점: 타입을 변경할 때 한 번에 여러 컬럼을 변경할 수 있어서 유지보수에 좋다.
23. 번호가 자동 증가하는 컬럼을 지정
- 테이블의 PK 중에서 자동으로 증가해야 하는 컬럼을 지정한다.
24. 기본 값 및 제약 조건 설정
- 일부 컬럼에 대해 기본 값을 설정한다.
- 일부 컬럼의 값의 범위를 지정한다.
포워드 엔지니어링(forward engineering)
- 모델 ----> 코드
- 참고: 리버스 엔지니어링(reverse engineering)
코드 ----> 모델
정규화
- 데이터가 중복되지 않도록 구조화시키는 것.
- 참고: 역정규화 (실행 속도를 높이기 위해 데이터 중복을 허용하는 것)
관계: 부모 테이블과 자식 테이블
부모 테이블
- 자식 테이블이 참조하는 데이터를 갖고 있는 테이블
자식 테이블
- 부모 테이블의 데이터를 참조하기 위해 그 데이터의 PK 값을 갖고 있는 테이블
- 이렇게 부모 테이블의 PK를 저장하는 컬럼을 FK(Foreign Key)라 부른다.
외부키(Foreign Key; FK)
- 자식 테이블에서 부모 테이블의 특정 데이터를 가리키는 컬럼이다.
- 반드시 부모 테이블의 PK 컬럼 값을 저장해야 한다.
다른 일반 컬럼의 값은 사용할 수 없다.
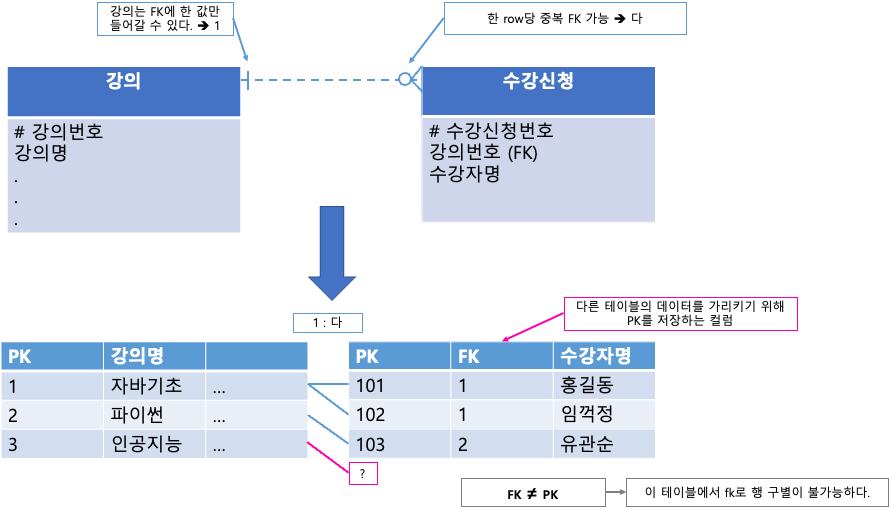
식별 관계와 비식별 관계
비식별 관계(non-identifying)
- 자식 테이블의 외부키(FK)가 그 테이블에서 일반 컬럼으로 사용될 때
- 즉 관계를 표현하는 외부키가 그 테이블에서 식별자로 사용되지 않는 것을 말한다.
- FK != PK
식별 관계(identifying)
- 자식 테이블의 외부키(FK)가 그 테이블에서 PK 컬럼으로 사용될 때
- 즉 관계를 표현하는 외부키가 그 테이블에서 식별자로 사용되는 것을 말한다.
- FK == PK
KEY

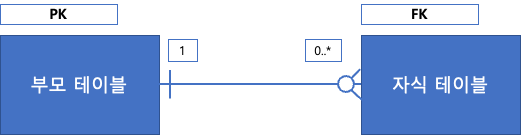
부모는 자식을 여러 개 가질 수 있지만, 자식은 부모를 하나만 가질 수 있다.
DB 모델링
DB 모델링 → 데이터 분석 → 구조화 → 데이터 중복 제거
데이터 중복 제거 ⇒ 일관성, 무결성 보장
논리 모델링
- 개념 모델링
- 자연어로 작성
물리 모델링
- DBMS에 맞춰서 논리 모델링을 변경
- 가이드라인에 따라서 테이블명과 컬럼명 작성

DB 모델링 절차
1. 업무 분석
업무 분석 전문가(Business 도메인 전문가) 담당
2. 데이터베이스 모델링
DB 설계자 담당
→ Entity(테이블) 및 attribute(속성, 열) 식별
메소드 ≒ 연산자 (operator)
부모 - 자식 관계:
식별관계 vs. 비식별관계
1. Non-Identifying (비식별관계)
2. Identifying (식별관계)

A는 B를 가질 수도 안가질 수도 있고, B는 A를 무조건 갖는다.
⇒ B에 값이 없을 수도 있다. 하지만 A에는 값이 무조건 있다.
다대다 관계의 해소
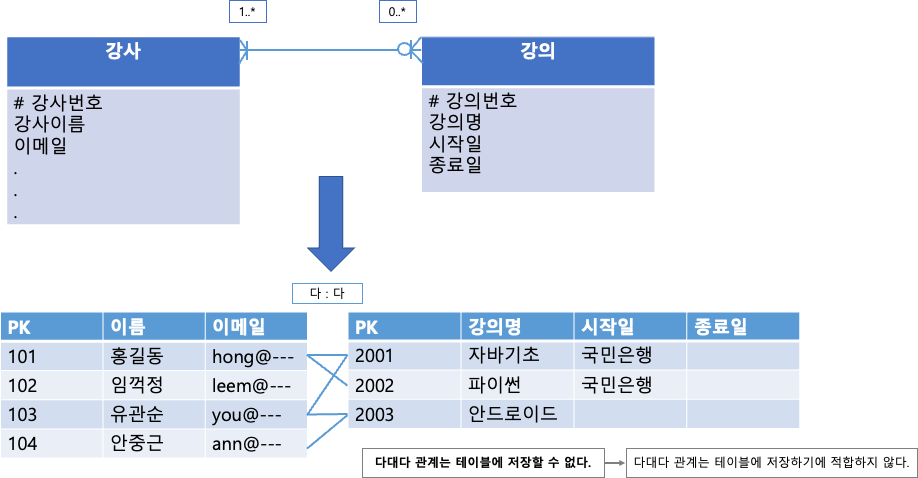
다대다 관계는 테이블에 저장할 수 없다.
→ 다대다 관계는 테이블에 저장하기에 적합하지 않다.
⇒ 해결: 다대다 관계를 표현하는 관계 테이블 을 사용한다.
관계차수
1 : 0...*

0,1 : 0 ... *

포함관계 VS. 배타적관계
1. 배타적관계
회원은 매니저, 강사, 학생 중 한 개의 유형만 가입이 가능하다.
다른 유형에 중복 가입하려면, 다른 아이디/이메일을 사용해야한다.
⇒ 회원 데이터 한 개는 매니저, 강사, 학생 중 오직 한 개의 유형과만 관계를 맺는다.

2. 포함관계
회원은 매니저, 강사, 학생에 동시 가입할 수 있다.
⇒ 즉, 회원기본정보(ID, PWD, Email, ...)를 공유해서 → 매니저, 강사, 학생 데이터를 추가할 수 있다.
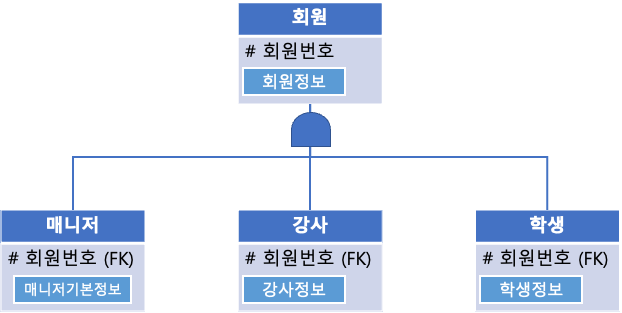
→ 대표적인 예시


https://github.com/Dingadung