
- SQL 사용법
- 조인 사용법
- 서브 쿼리 사용법
- GROUPING 사용법
- DB 모델링
- ER-Diagram 도구 설치(www.exerd.com)
SELECT: all vs. distinct
모든 데이터 가져오기
→ all은 생략할 수 있다.
select (all) loc from room;중복 값을 한 개만 추출할 때 distinct를 붙인다.
select distinct loc from room;컬럼이 2개 이상일 때
→ 그 커럼들의 값이 중복일 경우만 한 개로 간주한다.
select distinct loc, name from room;SELECT: ORDER BY
select 컬럼1, 컬럼2, ...
from 테이블
order by 컬럼 (asc || dsc), 컬럼 (asc || dsc), ...SELECT: alias
별명이 있을 경우, 컬럼의 값을 추출할 때 별명을 사용해야 한다.
select 컬럼명 (as) 별명, 식 (as) 별명
.
.
.count()를 호출할 때 컬럼 이름을 지정하면 ,
해당 컬럼의 값이 null 이 아닌 데이터만 카운트한다.
SELECT: 집합
합집합
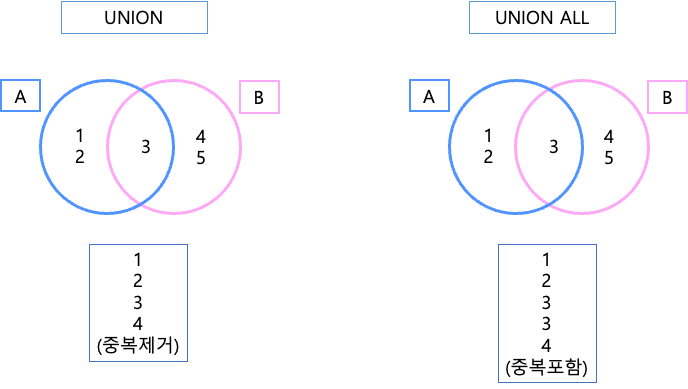
union : 중복 값 자동 제거
select distinct bank from stnt
union
select distinct bank from tcher;union all: 중복 값 제거 안함
select distinct bank from stnt
union all
select distinct bank from tcher;차집합
mysql 은 차집합 문법을 지원하지 않는다.
따라서 다음과 기존의 SQL 문법을 사용해서 처리해야 한다.
select distinct bank
from stnt
where not bank in (select distinct bank from tcher);교집합
mysql 은 교집합 문법을 지원하지 않는다.
따라서 다음과 기존의 SQL 문법을 사용해서 처리해야 한다.
select distinct bank
from stnt
where bank in (select distinct bank from tcher);JOIN
→ 여러 테이블에 분산 저장된 데이터를 한 개의 데이터로 모으는 것
서로 관련된 테이블의 데이터를 연결하여 추출하는 방법
기법
- CROSS 조인(=Cartesian product)
- NATURAL 조인
- JOIN ~ ON
- OUTER JOIN
cross join
= Cartesian join
의미 없는 조인
natural join 의 문제점
- 두 테이블의 조인 기준이 되는 컬럼 이름이 다를 때 연결되지 못한다.
- 상관 없는 컬럼과 이름이 같을 때 잘못 연결된다.
- 같은 이름의 컬럼이 여러 개 있을 경우 잘못 연결된다.
모든 컬럼의 값이 일치할 경우에만 연결되기 때문이다.
만약에 두 테이블에 같은 이름을 가진 컬럼이 여러 개 있다면,
join ~ using(기준컬럼) 을 사용하여, 두 테이블의 데이터를 연결할 때 기준이 될 컬럼을 지정한다.
natural join 의 문제점 2
두 테이블에 같은 이름의 컬럼이 없을 경우 연결하지 못한다
만약 두 테이블에 같은 이름을 가진 컬럼이 없으면, natural join을 수행하지 못한다.
또한 join using 으로도 해결할 수 없다.
이럴 경우 join ~ on 컬럼a=컬럼b 문법을 사용하여 각 테이블의 어떤 컬럼과 값을 비교할 것인지 지정하라!
GROUP BY
Group으로 묶인 경우, Group 함수를 사용할 수 있다.
GROUP BY가 있는데 조건에 부합하는 것이 아무것도 없으면 공집합이 된다.

https://github.com/Dingadung