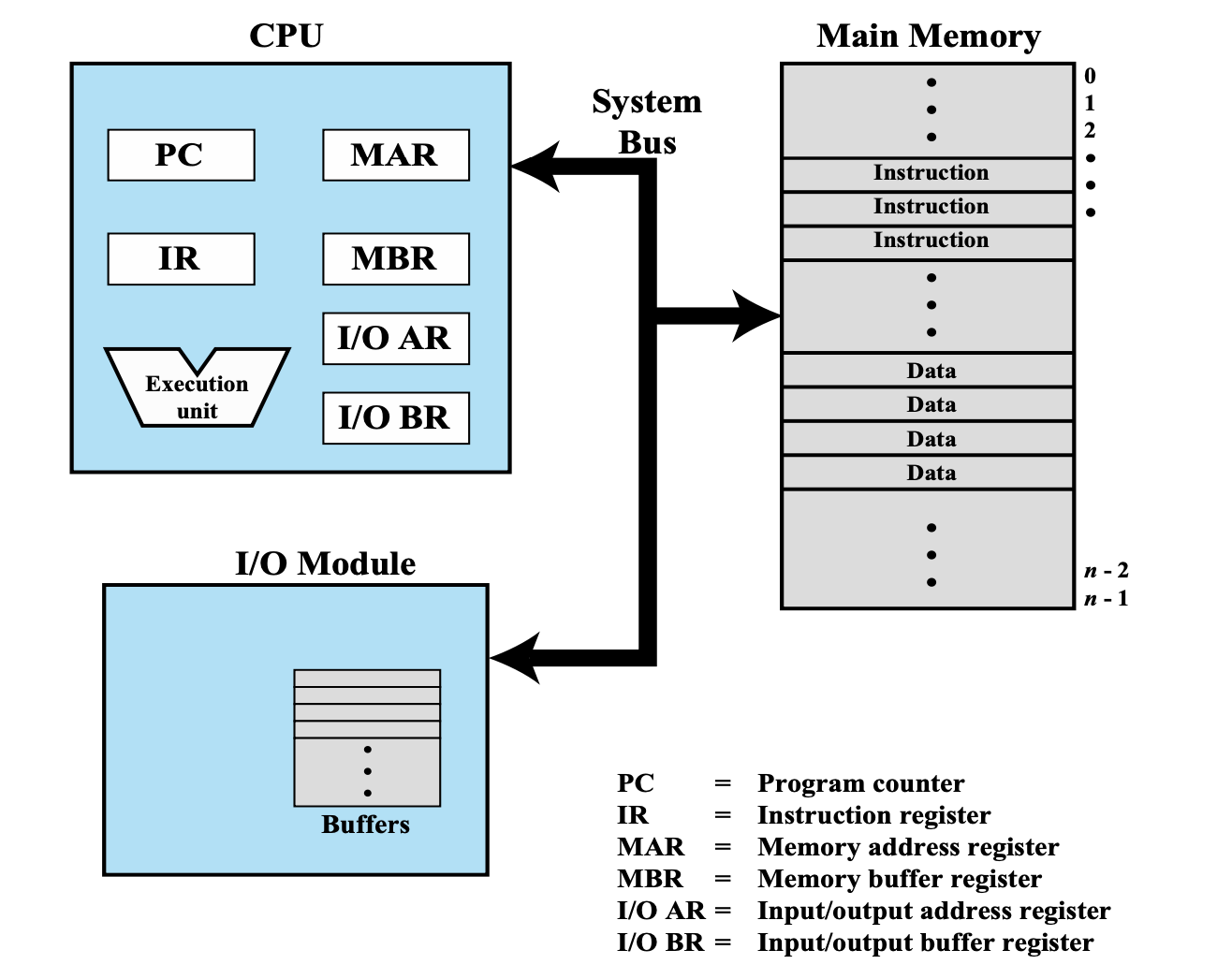
Computer Component:
Top-Level View
Program Execution
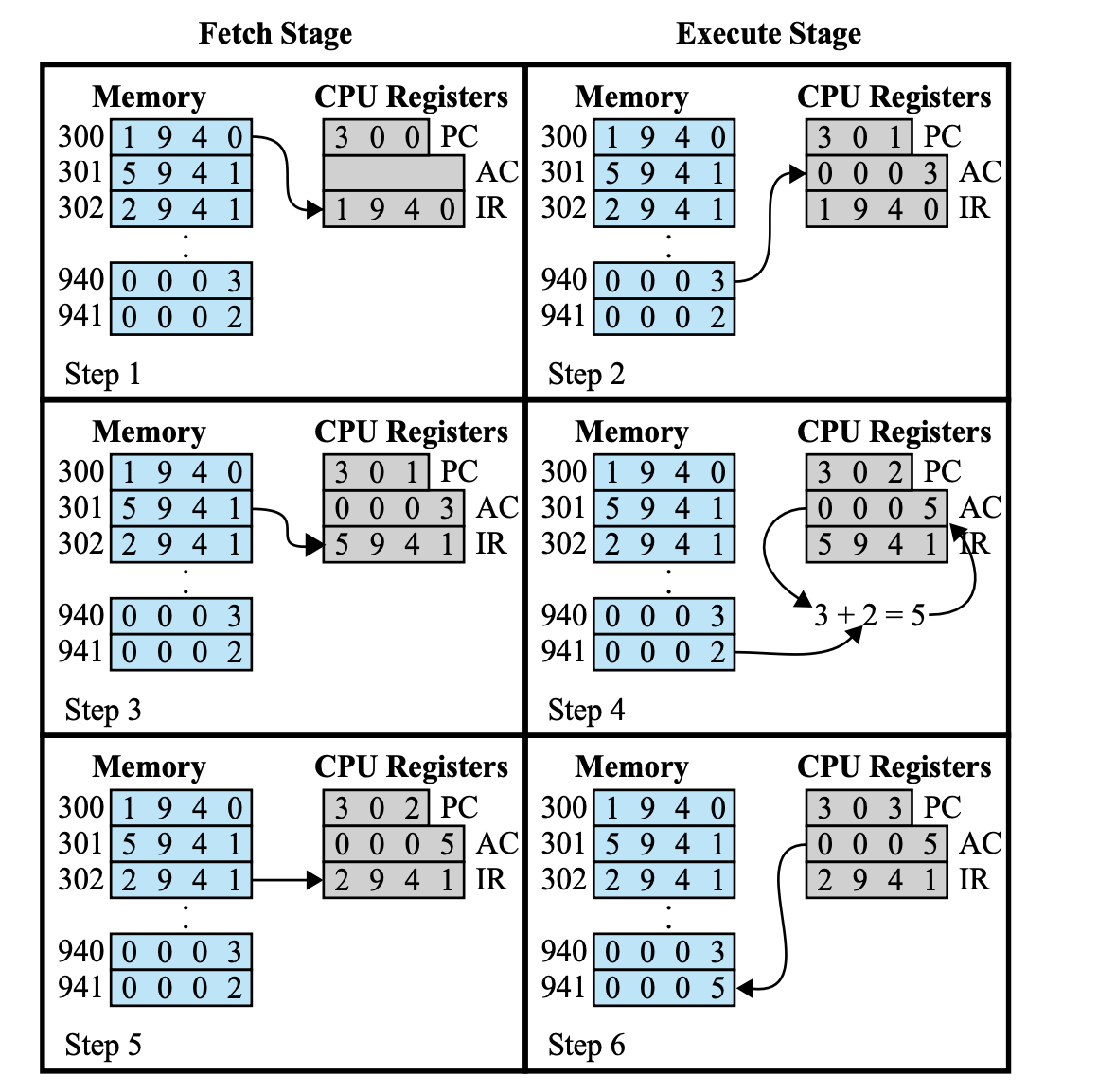
Fetch Stage
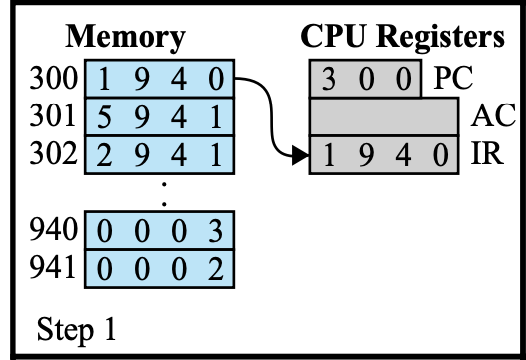
PC에 들어있는 300은 Step1 이전에 들어 있었던 것이다.
PC에 300이 들어 있다고 해서 우리가 메모리 300번지에 있는 명령어를 읽어올 수 없다.
→ 내가 메모리에서 무언가를 읽어 오려면 내가 읽어오려고 하는 명령 또는 데이터의 주소가 MAR에 들어 있어야 한다.
Fetch Stage의 과정
⇒ 메모리에서 300번지에 들어있는 명령어 읽어 오는 과정
fetch stage가 시작하기 전에,
PC: 300, IR: 이전 실행 명령어가 들어 있다.
- PC에 들어 있는 300 번지 주소를 MAR로 옮긴다.
- 메모리 읽기
- 메모리 300번지에 있는 명령어가 MBR로 온다.
그러나 명령어가 MBR로 왔다고 해서 내가 이 명령어를 실행시킬 수 있는 것은 아니다.
왜냐하면 명령어를 분석하려면 명령어가 IR로 들어가야 하기 때문이다.- MBR로 들어온 명령어를 IR로 옮긴다.
중요한 것은 위의 과정에서 PC의 값은 다음 명령어의 주소를 가르키도록 변경되어야 한다는 것이다.
다음 명령이 무엇인지는 알 수 없기 때문에 우선은 바로 다음 명령은 다음줄에 있는 명령이라고 가정하여 PC의 값에 +1을 한다.
Fetch Stage
1. PC → MAR (읽어오려는 메모리 주소 옮기기)
2. PC++
3. memory read 명령 실행
4. 명령어 → MBR
5. MBR → IR
⇒ Fetch Stage가 끝나면 PC는 1이 증가되어 있다.
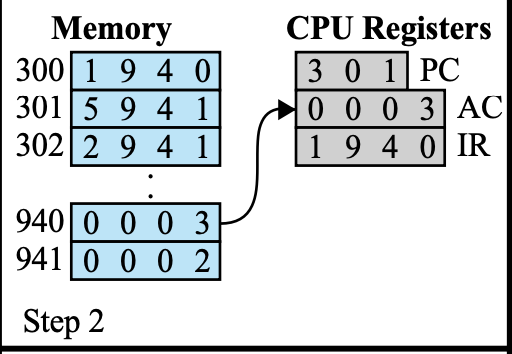
Execution Stage
Read
- IR의 Operation code 확인
어떤 명령을 시작하든간에 우선 명령을 분석해야한다.
→ 명령어에 따라 Execution Stage의 단계가 달라진다. - IR → MAR
Fetch Stage에서는 PC에 저장된 번지가 MAR로 이동을 했다면,
Execution Stage에서는 IR에 저장된 번지가 MAR로 이동한다. - MBR → AC(read) or AC → MBR(write)
데이터를 읽어올 때는 Fetch Stage와 다르게 IR이 아니라 AC에 데이터를 저장한다.
명령어(instructions)
- 0001(1) = Load AC from memory(읽어오기)
메모리 → AC - 0010(2) = Stroe AC to memory(저장하기)
AC → 메모리 - 0101(5) = Add to AC from memory(더하기)
위의 세 명령어는 모두 데이터가 이동하는 명령어이다.
데이터가 이동하는 명령어
- Processor-memory data transfer
- Processor-I/O data transfer
- Data processing
산술논리연산 명령어(+, -, and, or)
데이터가 이동하지 않는 명령어
- Control
jump 명령어, 조건을 확인한 후 주소 번지 이동시키는 명령어
데이터가 필요 없는 명령어이다.
⇒ 모든 명령어가 데이터가 필요한 것은 아니다.
명령어는 위의 4가지만 존재한다.
IR

IR의 첫번째 숫자는 명령어를 나타낸다.
Read IR 예시
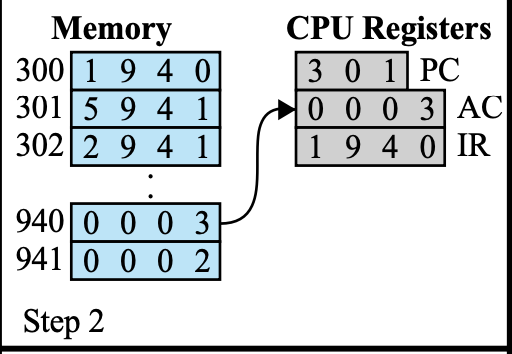

= 메모리 940번지에 있는 수를 읽어와서 AC에 넣어라 (Load)
- IR의 Operation code 확인 = 1
어떤 명령을 시작하든간에 우선 명령을 분석해야한다. - IR → MAR
Fetch Stage에서는 PC에 저장된 번지가 MAR로 이동을 했다면,
Execution Stage에서는 IR에 저장된 번지가 MAR로 이동한다. - memory load
- memory → MBR
- MBR → AC
데이터를 읽어올 때는 Fetch Stage와 다르게 IR이 아니라 AC에 데이터를 저장한다.
Add IR 예시
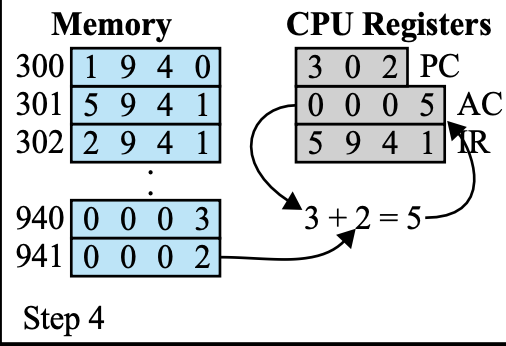

= 메모리 941번지에 있는 수와 AC에 있던 수를 더해 AC에 다시 넣어라 (Add)
- IR의 Operation code 확인 = 5
어떤 명령을 시작하든간에 우선 명령을 분석해야한다. - IR → MAR
Fetch Stage에서는 PC에 저장된 번지가 MAR로 이동을 했다면,
Execution Stage에서는 IR에 저장된 번지가 MAR로 이동한다. - memory read
- memory → MBR
- MBR → AC + MBR → AC
실제로는 레지스터가 무지하게 많기 때문에 이런식으로 계산 안한다.
Store IR 예시
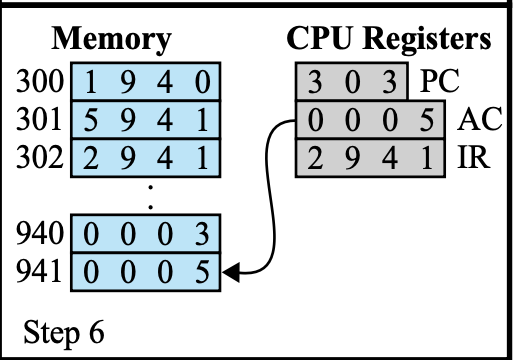

= 메모리 941번지에 AC에 있는 수를 저장해라 (Store)
- IR의 Operation code 확인 = 2
어떤 명령을 시작하든간에 우선 명령을 분석해야한다. - IR → MAR
Fetch Stage에서는 PC에 저장된 번지가 MAR로 이동을 했다면,
Execution Stage에서는 IR에 저장된 번지가 MAR로 이동한다. - AC → MBR
- memory write
- MBR → memory
Interrupts
🌟 제일 중요해용 🌟
CPU가 명령어를 한줄 한줄 실행하고 있을 때 중단하는 것
→ 3가지 관점에서 Interrupts(중단)를 바라봐야 한다.
1. 내가 프로그램일 때
A라는 어플리케이션 프로그램일 때, 10번째 명령어까지 실행하고 갑자기 중단 됨
→ 나는 무슨 일이 생겼는지 모름
→ 이후 시간이 흐르고 11번째 명령어부터 다시 실행
→ 중단
→ 재개
...
2. 내가 OS일 때
(전체 시스템 관점에서)
A를 실행하다가 A를 중단
→ OS 실행 (중단, OS가 프로그램을 바꾸는 역할을 한다.)
→ B 실행
→ OS 실행 (중단)
→ A 실행
...
3. 내가 CPU일 때
CPU는 프로그램 A가 실행되고 있는지, B가 실행되고 있는지, C가 실행되고 있는지 모른다.
→ 그저 한줄 한줄 명령어를 실행할 뿐, 이 한줄 한줄의 어떤 프로그램의 명령어인지는 모른다.
그러나, App이 실행되고 있는지 OS가 실행되고 있는지는 알아야한다.
- OS가 실행되고 있을 경우에는 컴퓨터의 많은 자원에 access할 수 있지만,
- 다른 기본 App들은 매우 한정적으로 access할 수 있기 때문이다.
⇒ OS가 프로그램을 CPU(프로세서)에게 뺏고 주고 하는 것이다.
Interrupt가 걸리는 이유
4가지 이유가 있다.
1. Program Interrupt
잘못 이해하는 부분: 프로그램에서 인터럽트를 다룬다. → X
프로그램에서는 인터럽트를 다룰 수 없다.
프로그램의 명령어가 한줄한줄 실행되다가,
이 명령어 한줄의 실행결과와 관련된 다양한 하드웨어가 Interrupt를 거는 것이다.
어떻게 명령을 실행했길래 Interrupt가 발생?
- Overflow
Condition 명령어에서 발생할 수 있다. - division by zero
잘못된 연산 - Illegal mechine instruction
CPU의 IR OP code 분석 - reference outside a user's allowed memory space
CPU는 access 가능한 메모리 영역을 표시해두어서 그 영역을 넘어가는 번지수를 요청할 때 Interrupt를 걸 수 있다.
2. Timer Interrupt
시스템 안의 CPU는 한 개이기 때문에 App 하나만 실행할 수는 없다.
⇒ 각 프로그램마다 실행할 수 있는 시간이 정해져 있다. : Time Slice
동시에 여러 프로그램들이 실행되는 것처럼 보이게 된다.
OS가 나타나서 프로그램을 다른 것으로 바꾼다.
3. I/O Interrupt
I/O Controller가 발생시키는 Interrupt이다.
젤 어려워용!
4. Hardware failure Interrupt
하드웨어에 문제가 발생해서 프로그램 다 멈추고 OS가 문제를 해결하는 것
대부분의 I/O Devices은 프로세서(CPU)보다 속도가 느리다!
⇒ 프로세서 입장에서는 입력과 출력을 기다리는 것이 거의 천년만년이다..
장치를 위해서 멈추고 있으면 너무 CPU라는 장비가 아깝게 되는 것이다..
Program Flow of Control with or Without Interrupts- 1
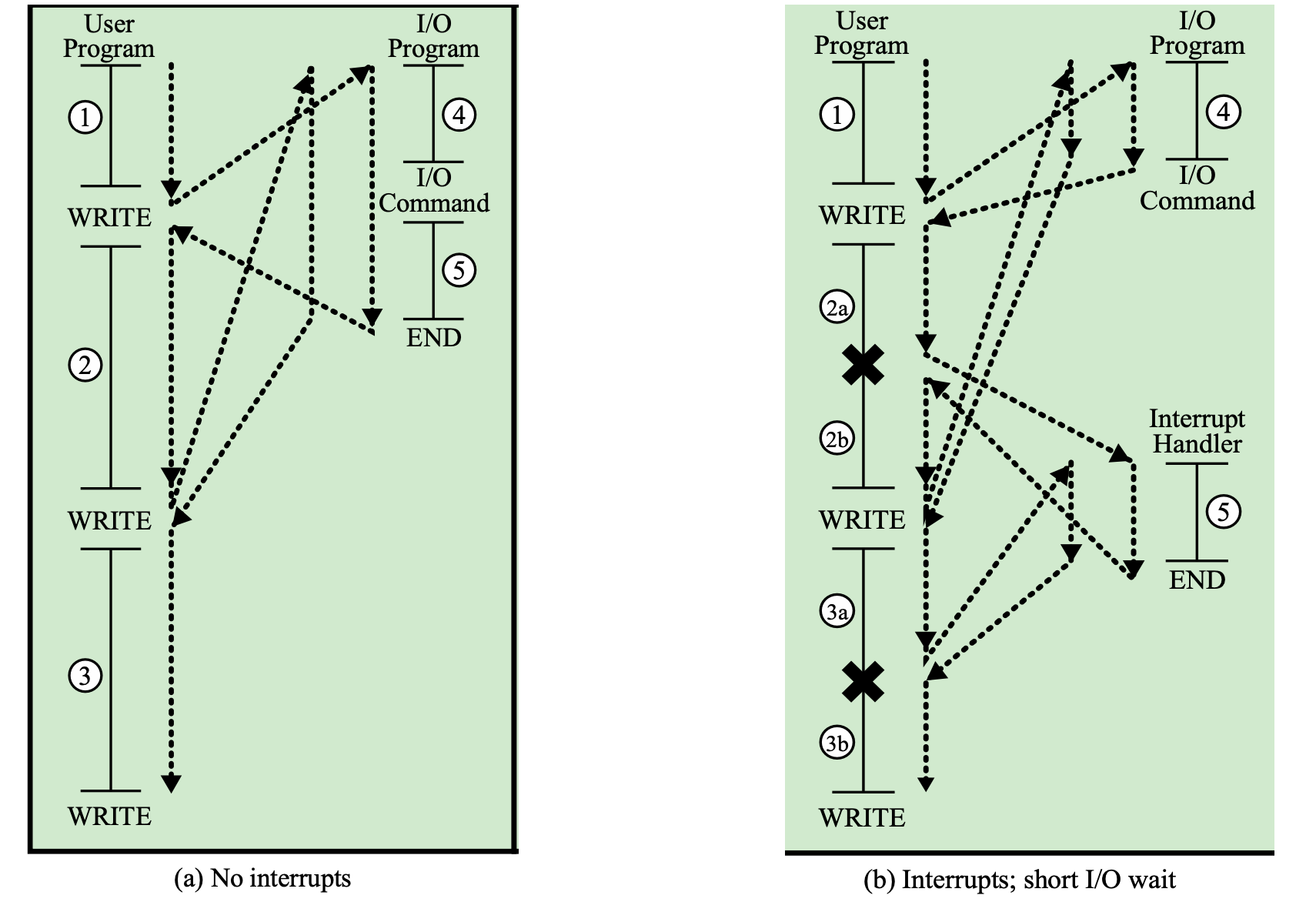
메모리 ↔ CPU ↔ buffer ↔ I/O modules
WRITE = print
외부에서 입력을 받으면 입출력 모듈은 buffer에 입력 받은 값을 저장한다.
이 내용물을 CPU를 통해서 Main Memory로 이동시키는 것
Write는 CPU가 하는 것이 아니다.
CPU는 I/O Device에게 입출력을 하라고 지시만 한다. (I/O Command)
- 입력을 하든, 출력을 하든 I/O buffer를 사용해야한다.
I/O Command 실행 → 입력 받기
- 입출력이 끝나면 끝이 아니라 return등을 통해 입출력이 성공적으로 이루어 졌는지 확인을 해서 user 프로그램에게 알려준다.
(성공여부 확인 작업까지 해야 입출력 작업이 완전히 끝나게 된다.)
1 - 4 ----- 5 - 2 - 4 ----- 5 - 3 - 4 ----- 5
→ 줄이 긴 것은 CPU가 노는 시간이다.
⇒ 시간이 너무 아깝기 때문에 인터럽트를 사용하게 된다.
(b) 4번 내내, I/O가 입력을 받는 시간 내내 기다리지 않고 바로 돌아와서 다른 프로그램을 실행하는 것
⇒ 더 빠르다.
I/O Interrupt
다른 프로그램을 하다가 I/O 작업이 끝나면 작업이 끝났다고 인터럽트를 보내는데, 이것이 I/O 인터럽트이다.
이는 Interrupt Handler가 제어한다.
Timing Diagram : Short I/O Wait
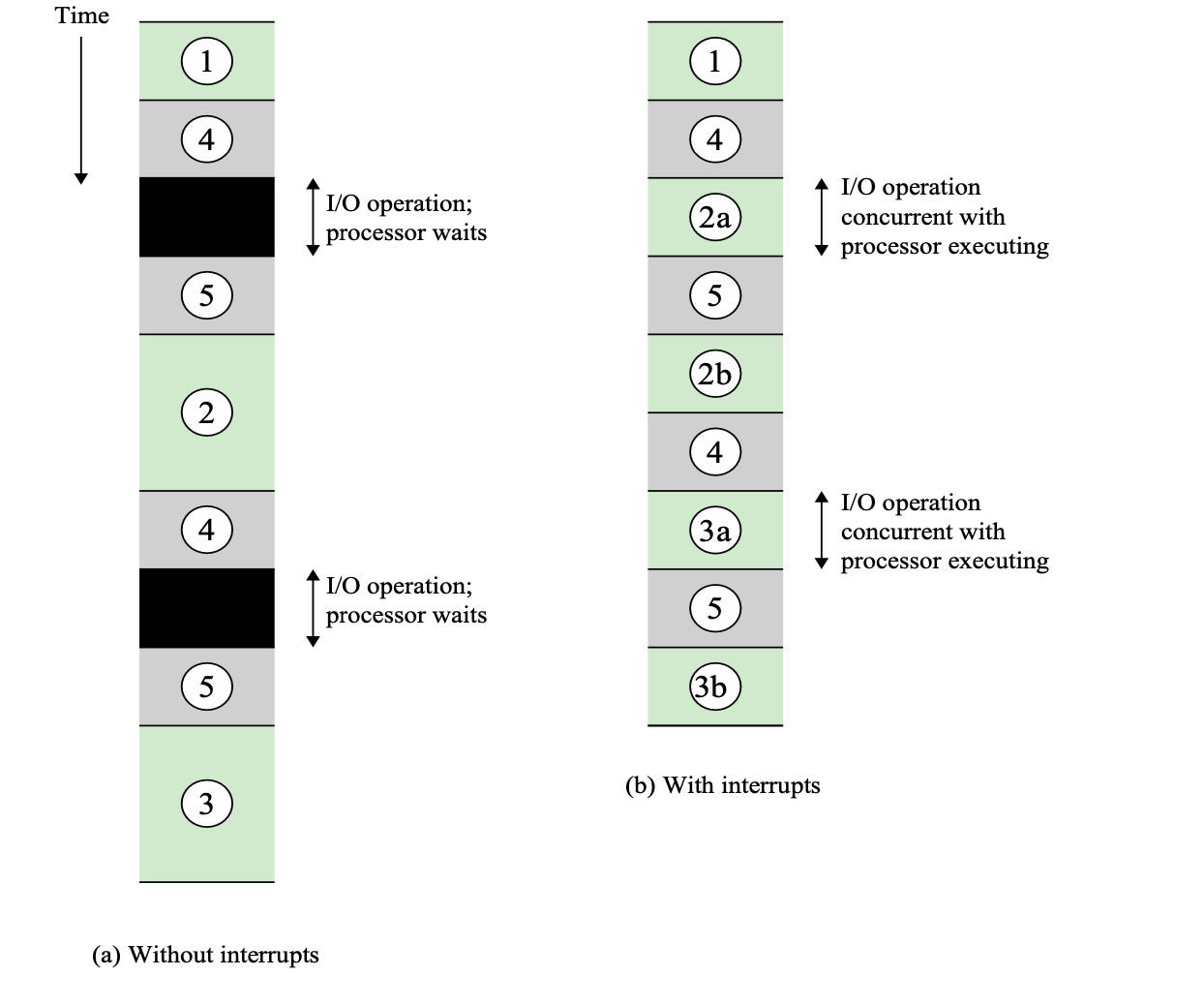
Interrupt Handler
왼쪽 그림이 user program, 오른쪽 그림이 Interrupt Handler이다.
-
Interrupt Handler는 OS의 한 부분이다.
-
Interrupt Handler는 Interrupt가 발생하면 Interrupt를 처리하는 역할을 한다.
-
모든 항목마다 적절한 Interrupt Handler가 따로 존재한다.
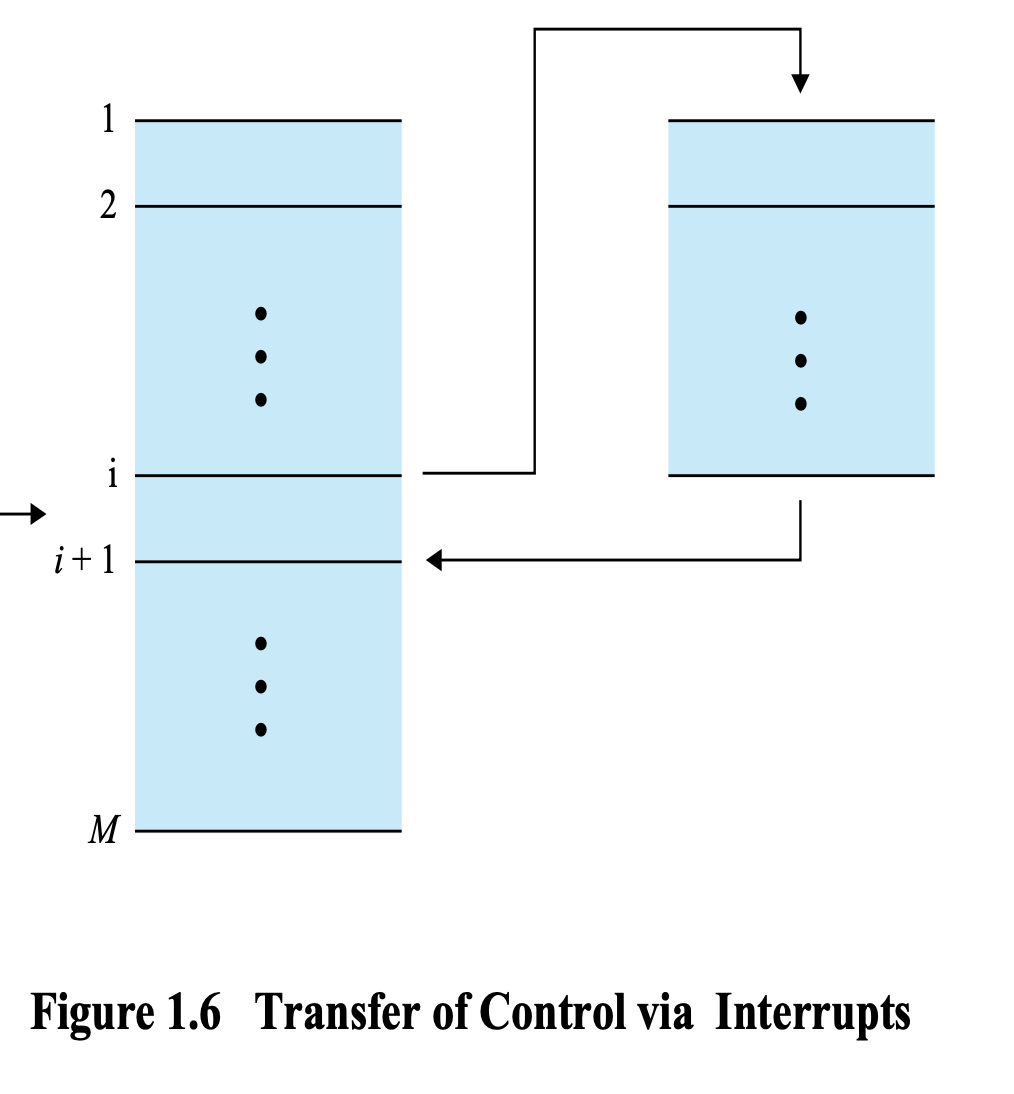
Interrupt Handler가 실행되는 과정
- user program이 i번째 명령어까지 실행
- interrupt
- 실행하던 프로그램 종료
- Interrupt Handler 프로그램 실행
- Interrupt Handler가 아까의 5번(입출력 성공여부 확인)까지 실행
- 다시 i+1 코드 실행
Q. Interrupt가 걸려도 왜 바로 처리를 하지 않을까?
Fetch Stage → Execute Stage → Interrupt Stage
왜 Fetch, Execute 이후에서야 Interrupt가 처리될까?
Interrupt가 처리된 이후에는 PC가 복귀가 되어 PC에 저장된 다음 명령어가 실행되기 때문에 이전 명령어는 처리가 완료되어야 있어야 한다.
Instruction cycle Fetch-Execute이 진행되면 PC가 증가되어 버리기 때문에 완료되지 않은 상태에서 인터럽트가 진행되고, PC가 복구되면 이전 명령어는 진행되지 못하게 된다.
Instruction Cycle with Interrupts
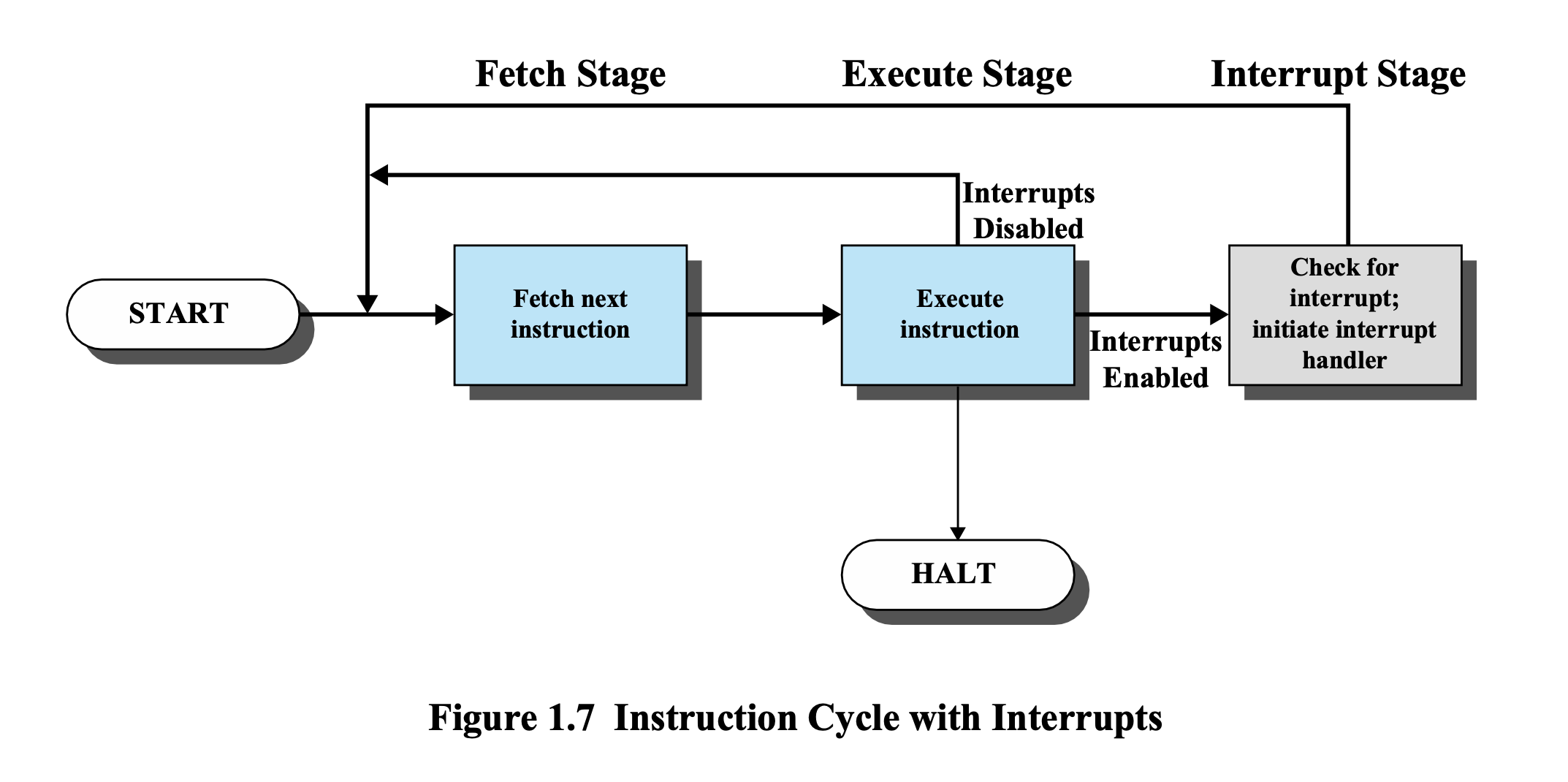
하나의 프로그램의 사이클의 아니다.
Execute Stage가 끝날 때마다 Interrupt가 걸렸는지 확인한다.
Interrupt가 왜 걸렸는지 누가 걸었는지를 확인해야한다.
해당하는 Interrupt Handler를 실행한다.
Initiate Interrupt Handler
Q. Interrupt Stage에서는 Interrupt가 걸린 이유를 파악하고 이 Interrupt Handling 하기 위한 적절한 프로그램을 실행시킨다.
→ X
Interrupt Stage에서는 프로그램을 실행시킬 수 없다.
명령 하나를 실행시키는 사이클이다.
따라서 인터럽트 핸들러라는 새로운 프로그램을 시작해야하기 때문에
결국 Interrupt Stage에서는 OS를 실행시킨다.
⇒ OS 실행
Q. OS의 실행 순서?
PC 값 OS 명령어로 변경하기
Program Flow of Control With or Without Interrupts (2)
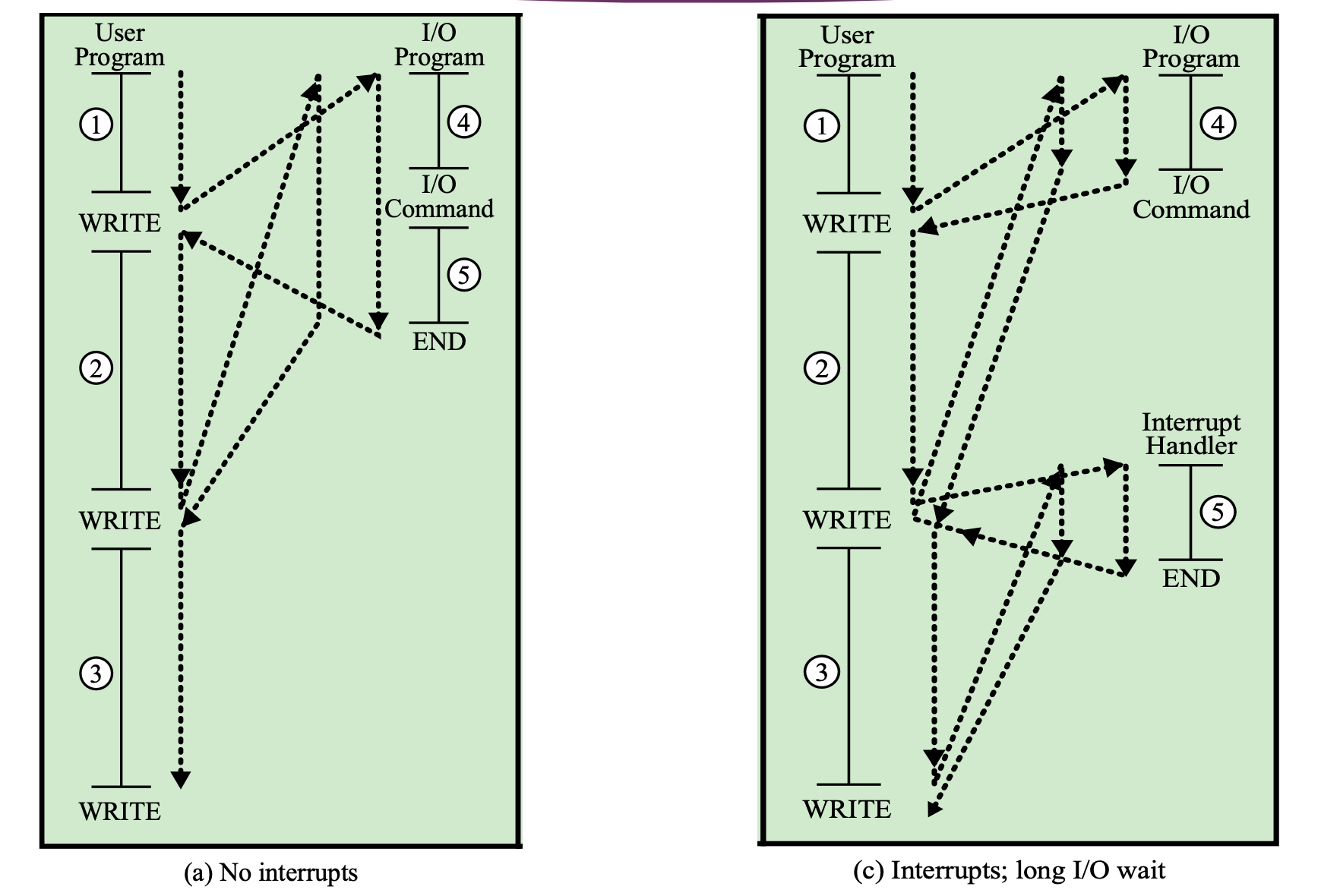
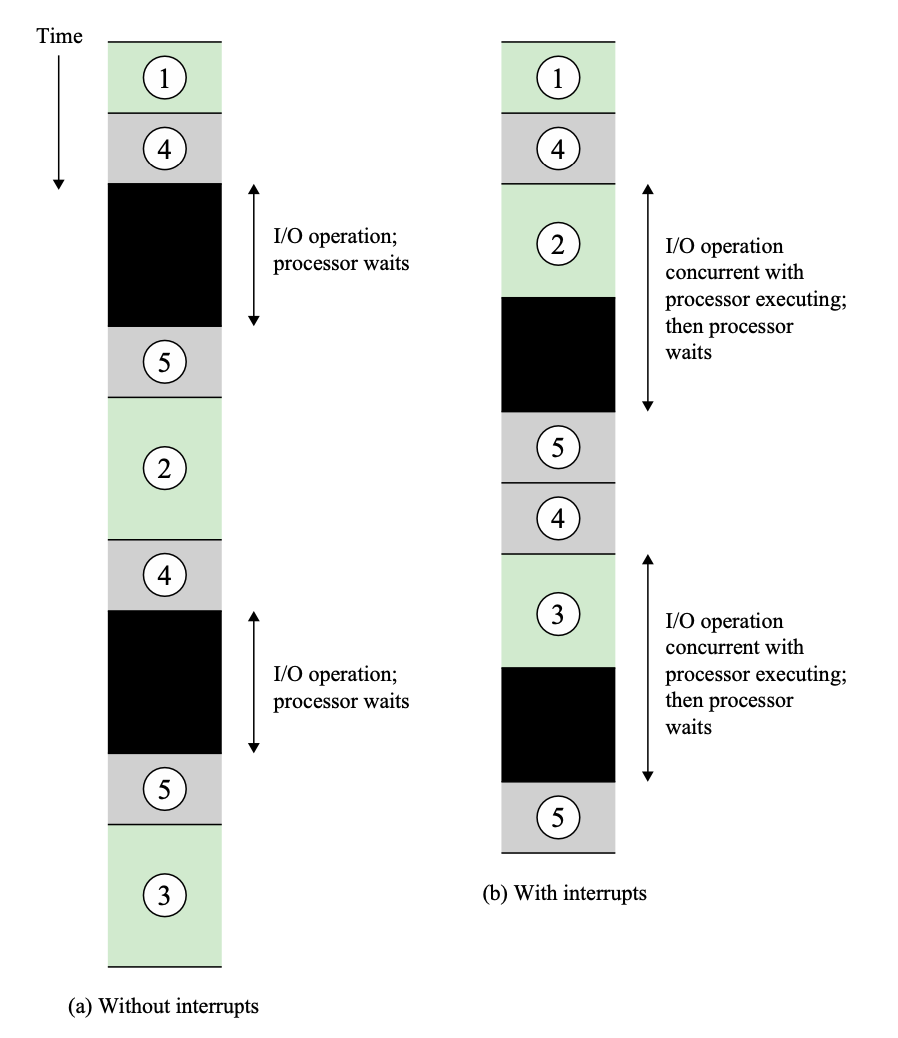
c에서 2에서 인터럽트가 걸리지 안하 5번 작업이 끝날 때까지 기다린다.
1 4 2(2가 끝날 때까지 I/O가 안끝남) 5 4 3(3이 끝날때까지 I/O가 안끝남) 5
프로그램 바꾸기
OS실행 방법?
OS도 프로그램이기 때문에
A 프로그램 실행하다 → Interrupt → OS → B 프로그램 실행
PC에 OS 실행 명령어 주소 번지를 저장한다.
PC의 값을 바꾸면 프로그램이 변경될 수 있다.
인터럽트 이후 이어서 실행을 해야하기 때문에 OS로 프로그램을 변경하기 전에
메모리는 안전하기 때문에 중단된 명령어들(CPU 값들)을 모두 레지스터에 저장해준다.
Simple Interrupt Processing
인터럽트 처리 과정
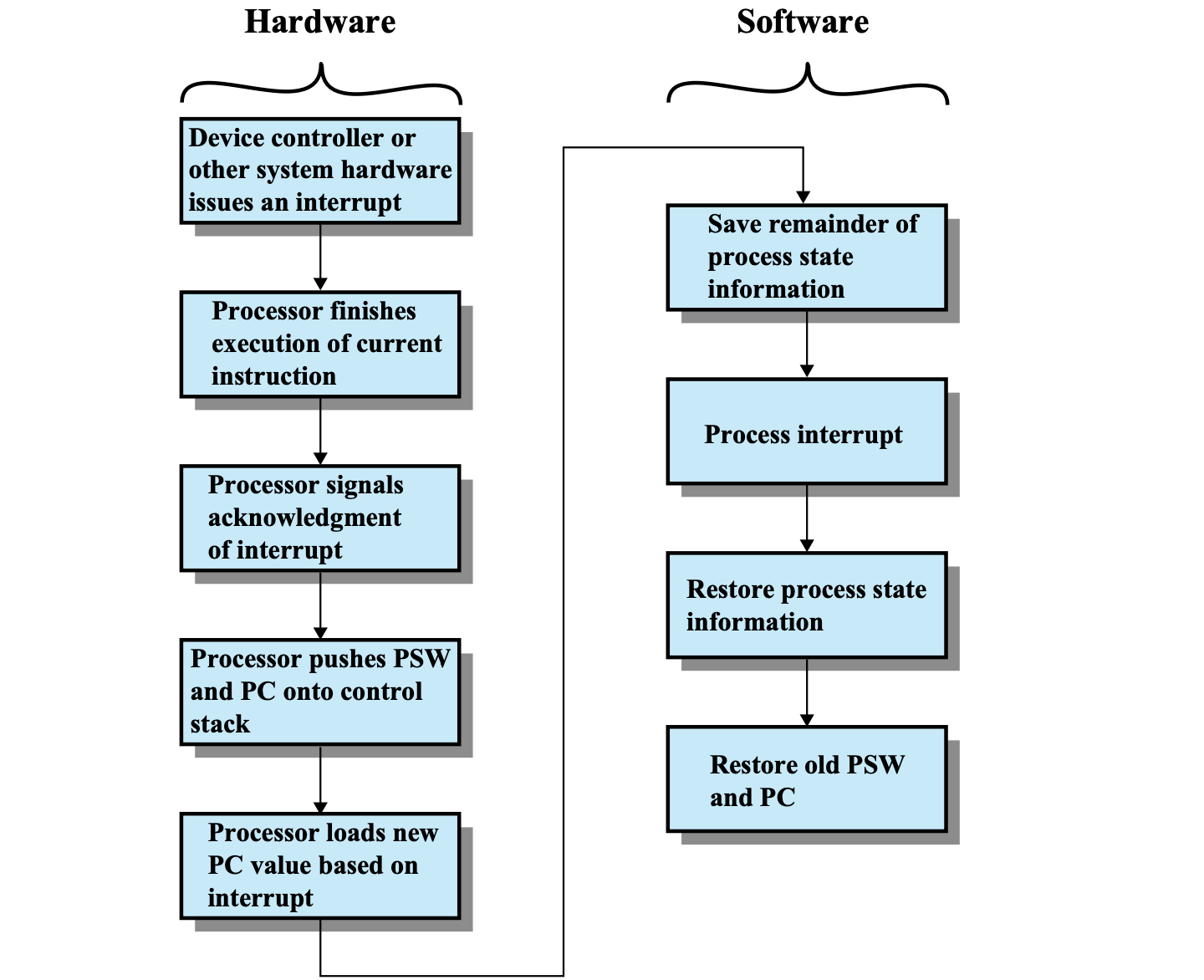
HardWare
- CPU가 처리
- Device Controller가 인터럽트 발생(I/O)
- 지금 실행하고 있는 명령어는 끝까지 처리한다.
Fetch과정에서 PC가 증가하게되는데 Execute처리가 되지 않고 Interrupt가 실행되고 PC가 복구되면 이전 명령어는 실행되지 않는다. - CPU가 인터럽트 인지
- CPU가 PSW와 PC값 control stack(안전한 메모리, 하드웨어)에 저장
- PC에 OS 실행 주소 번지 저장
SoftWare
OS 또는 Interrupt Handler가 처리
OS는 어마어마하게 큰 프로그램, 시스템을 관리하는 프로그램이다.
Hardware와 Software가 만나는 부분이 굉장히 많은데 그걸 OS가 처리한다.
- 나머지 중요한 CPU 정보들, process state를 저장
- 인터럽트가 왜 발생했는지 확인 후 적절한 처리
- process state CPU 복구
- PC, PSW 복구
Q. PC, PSW 따로 저장하는 이유?
마지막에 process state 먼저하는 이유?
새로 실행을 시작할 PC 값을 저장하는 순간 인터럽트 핸들러의 작업이 끝나기 때문이다.
새로운 프로그램이 바로 시작되어 버린다.
이전의 중요한 정보들이 모두 저장되지 못한채로 새로운 프로그램이 시작된다.
OS가 해야할 것을 먼저 끝내고 다른 프로그램이 시작되어야한다.
따라서 Hardware에서도 5번 이후 6번이 실행되어야 한다.
6번에선 이미 PC 가 OS 주소로 바뀌기 때문이다.
