Interrupts: short I/O wait
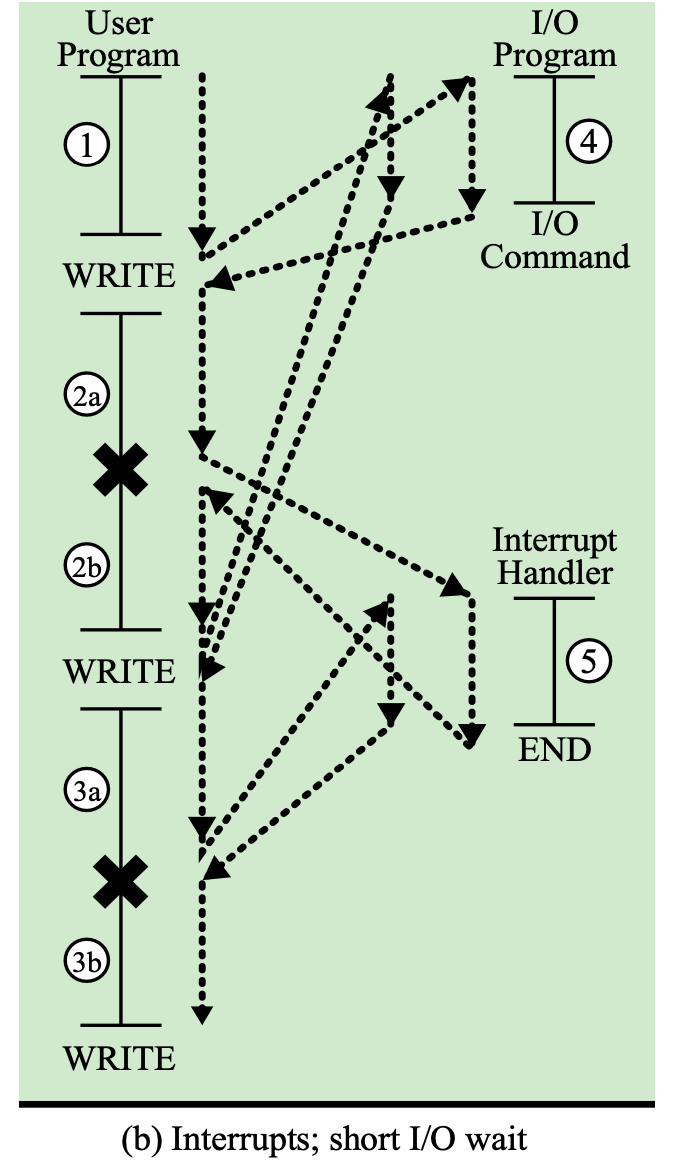
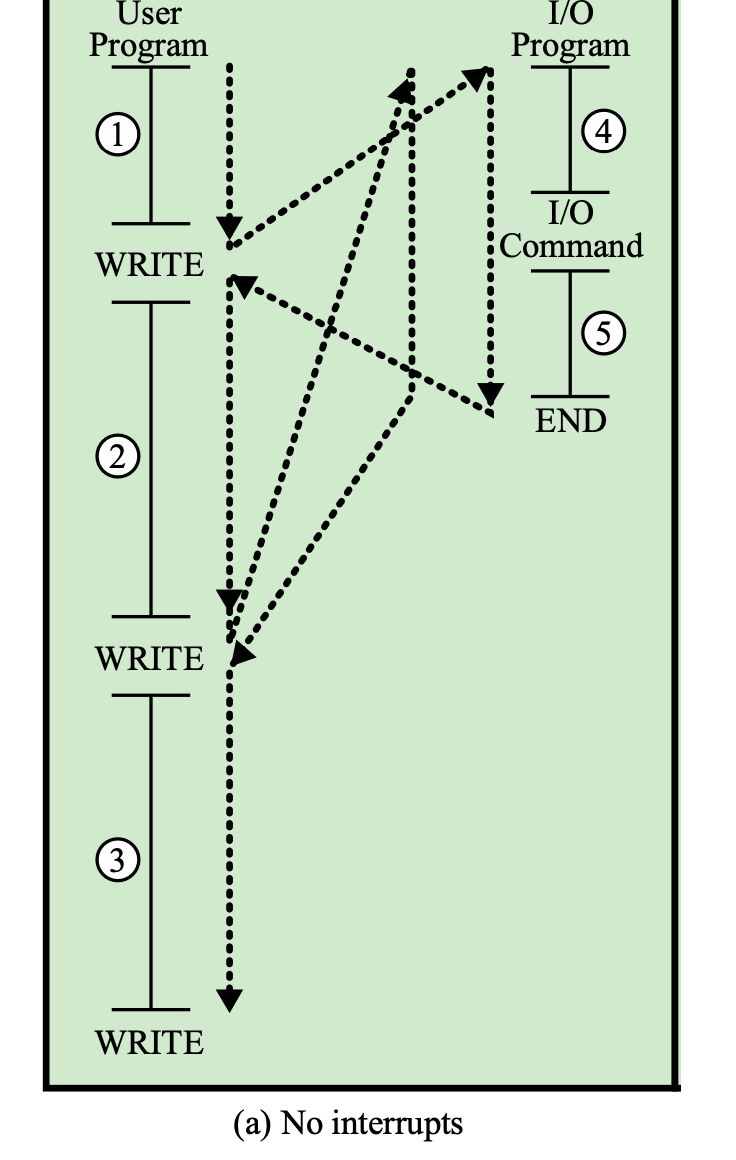
System call
System call: User Program에서 OS에게 I/O같은 것을 요청하는 것
-
User Program이 WRITE라는 System call을 호출한다.
-
WRITE는 함수 호출이지 명령문이 아니다.
→ print, scanf는 명령문이 아니라 함수 호출문이다. -
4번 코드는 User Program의 일부가 아니라 OS 코드의 일부이다.
→ 입출력은 OS가 한다. -
4번 코드는 Interrupt가 아니다. 그저 System call을 호출한 것이다.
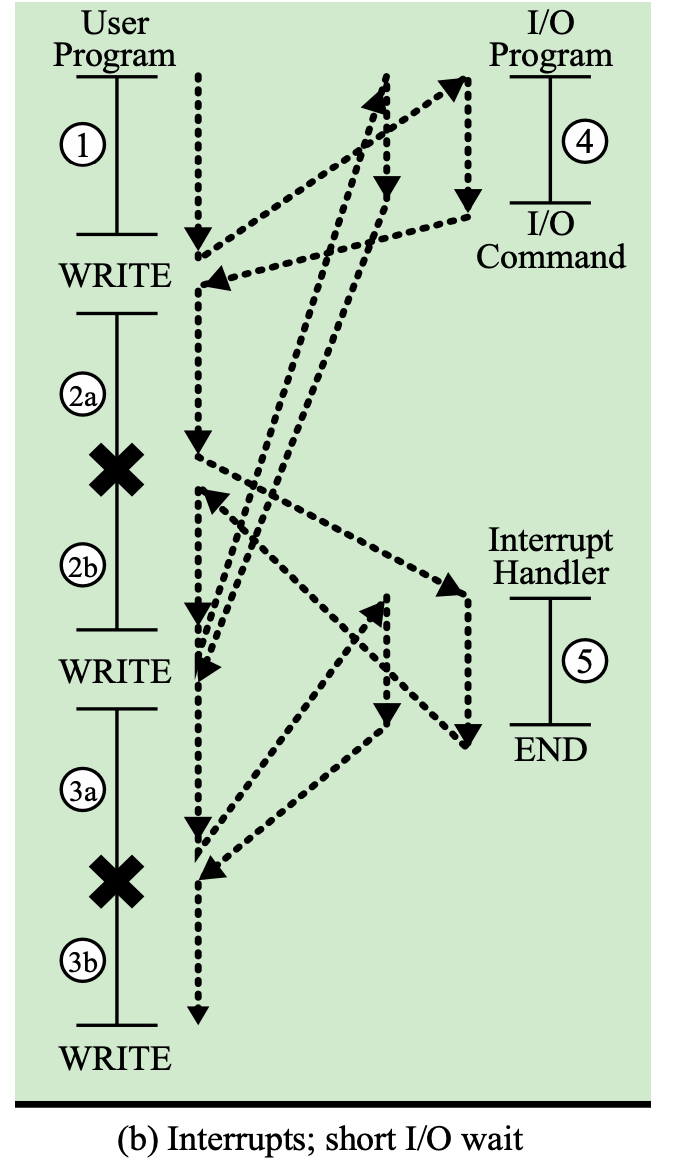
I/O Interrupt
-
OS입장에서 생각해보니, 입출력을 받을 때까지 다른 프로그램을 실행시켜도 될 것 같아서 프로그램A → 프로그램B로 실행하는 프로그램을 변경한다.
-
프로그램B가 실행하는 도중 프로그램 A의 입출력이 끝났을 때 프로그램B에 인터럽트를 걸어서 프로그램을 강제 종료한다.
⇒ 즉, I/O 인터럽트는 B 프로그램에게 A 프로그램의 입출력 작업이 끝났음을 알려 B 프로그램의 진행을 방해하는 것을 말한다.
5번 코드는 Interrupt Handler 가 다루며, 4번 코드가 아닌 5번 코드를 진행하기 위해 하는 것이 I/O Interrupt 이다
Q. I/O Interrupt는 입출력을 하기 위해서 OS를 호출하는 것이다
→ X
4번코드의 입출력하기 위함이 아니다.
Q. I/O Interrupt는 내 프로그램의 입출력 때문에 발생한다.
→X
다른 프로그램의 I/O 때문에 발생한다.
Q. I/O Interrupt는 I/O 작업이 시작할 때 발생한다.
→X
끝날 때 발생한다.
Changes in Memory and Registers
→ Interrupt 처리과정
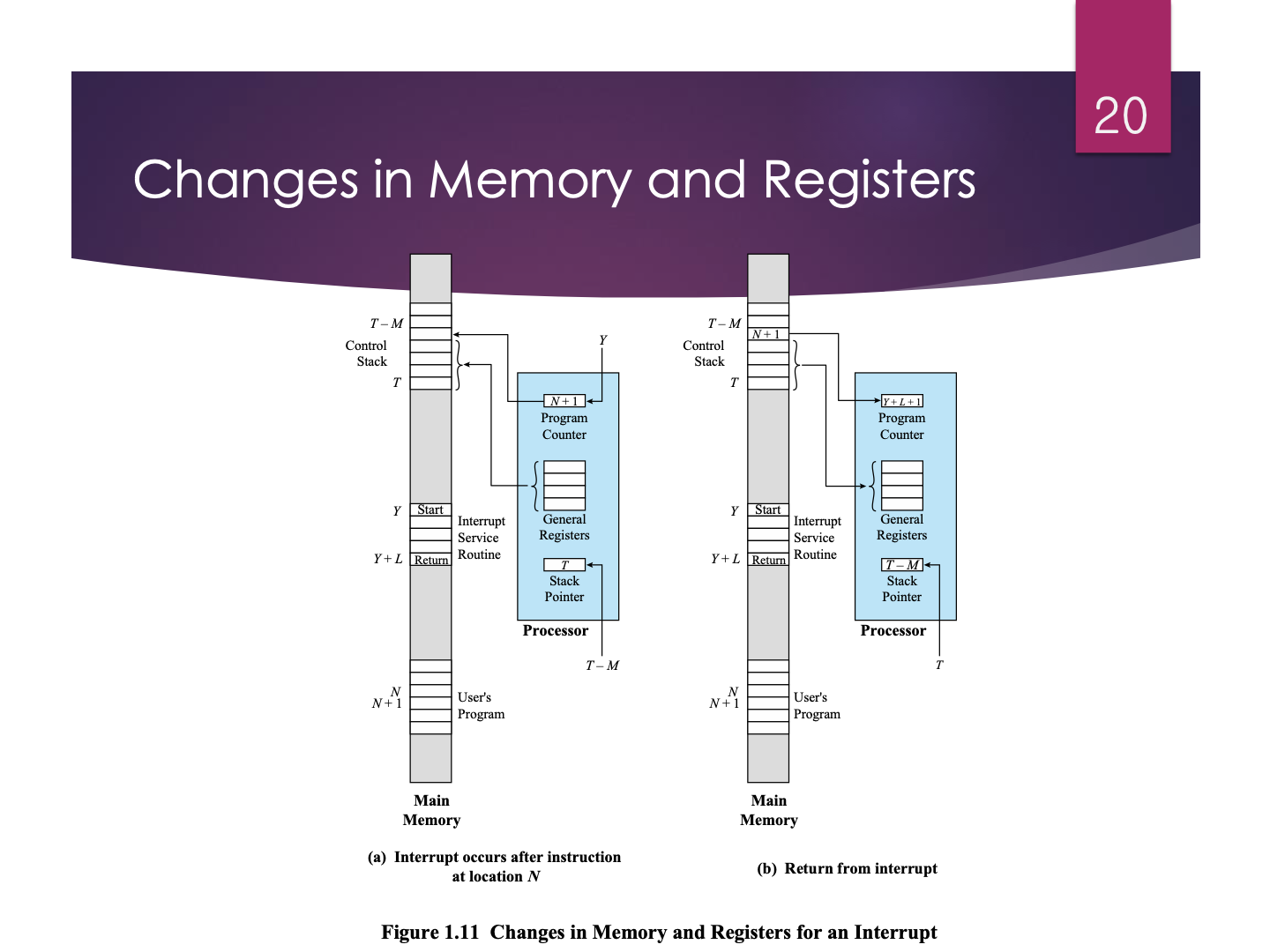
왼편에 있는 그림
- 컴퓨터의 CPU의 상태를 저장하는 과정
- 번지수 N에 있는 명령어 이후 인터럽트 발생
오른편에 있는 그림
- OS가 작업을 다 마치고 이전에 실행하던 또는 다른 프로그램의 CPU 상태를 restore하는 과정
- 인터럽트 처리후 복구하는 과정
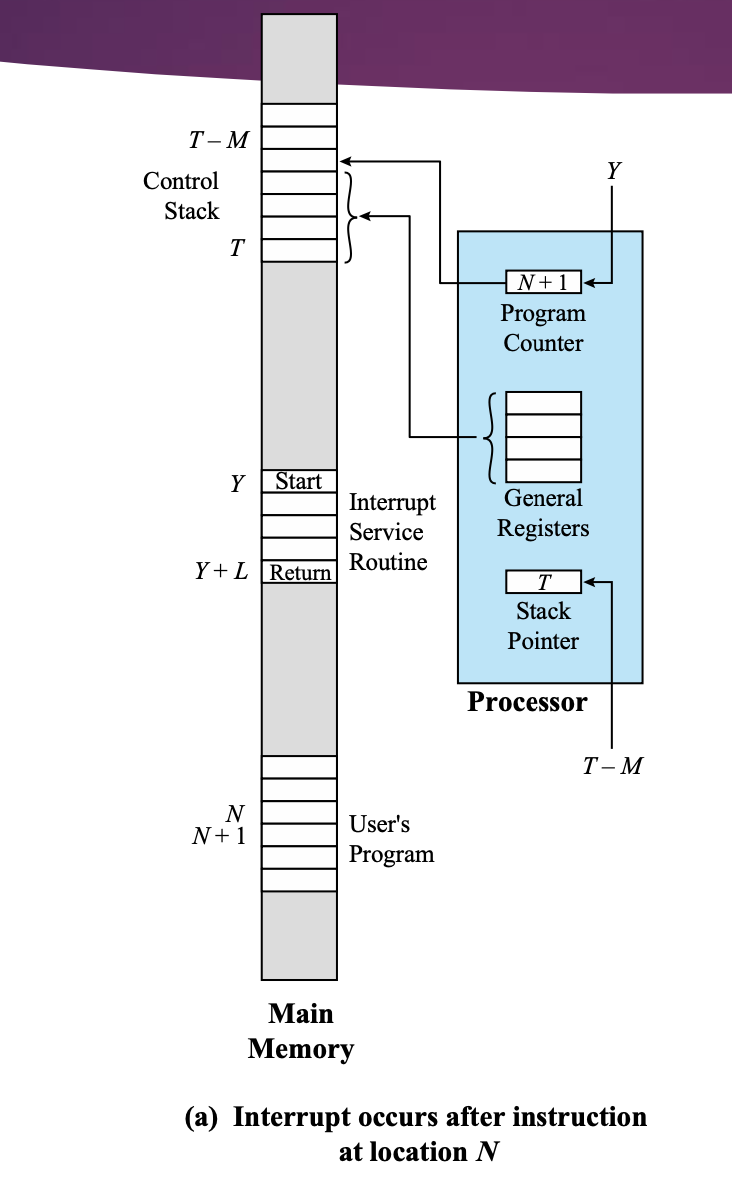
User's Program
PC를 보면 N + 1이 저장되어 있으므로 현재는 UserProgram의 N 명령어를 실행 중이다.
Interrupt Service Routine
인터럽트 핸들러 코드이다.
인터럽트 핸들러 코드는 OS의 코드이다.
Control Stack
중단된 프로그램들의 CPU 상태가 stack처럼 쌓여 있는 곳이다.
Stack Pointer
Stack의 Top이 어딘지 가르킨다.
General Register
CPU 안에 있는 Register의 상태들을 다 저장해야한다.
사실 CPU 안의 모든 값들을 저장할 필요는 없다. (IR, MBR, MAR → 데이터가 이동할 때만 사용한다.)
하지만 그냥 다 저장하는게 편하기 때문에 다 저장하는 것이다.
순서
- PC의 N+1 값을 Control Stack에 저장
PC → Control Stack
(flow chart 4번 코드) - Interrupt Handler가 Y번째부터 시작되므로 Y를 PC에 저장한다.
Interrupt Service Routine → PC - Y ~ Y + L까지 Interrupt Service Routine 처리
- 남은 나머지 General Register의 값들을 모두 Control Stack에 저장
- Stack Pointer의 값 업데이트
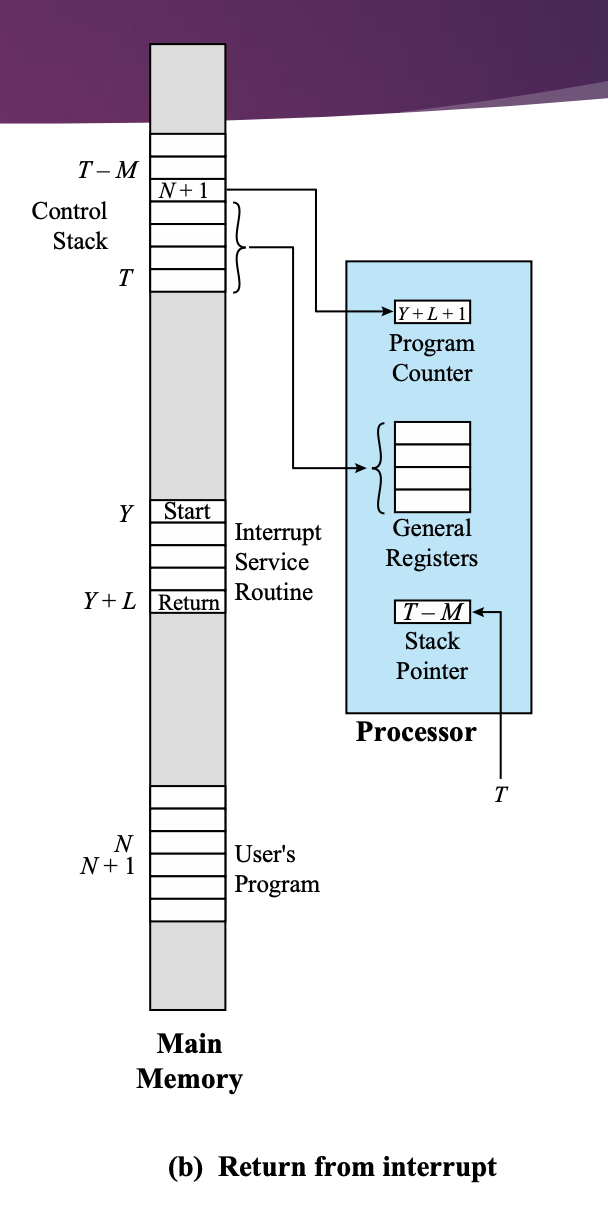
순서
- 인터럽트 처리 끝
- 현재 PC에 Y+L+1이 저장되어 있으므로 Y+L의 return 명령어를 처리하는 중이다.
- General Registers 값들을 모두 restore한다.
- PSW와 PC를 restore한다.
- pop()이 되었으므로 Stack Pointer를 바꾸어준다.
- 그 뒤 PC를 N+1로 바꿔준다.
Memory Hierachy
컴퓨터에 저장된 모든 실행 파일들은 HDD(HarD Disk)에 저장되어 있는데,
실행을 하기 위해서는 Main Memory에 올라가야 한다.
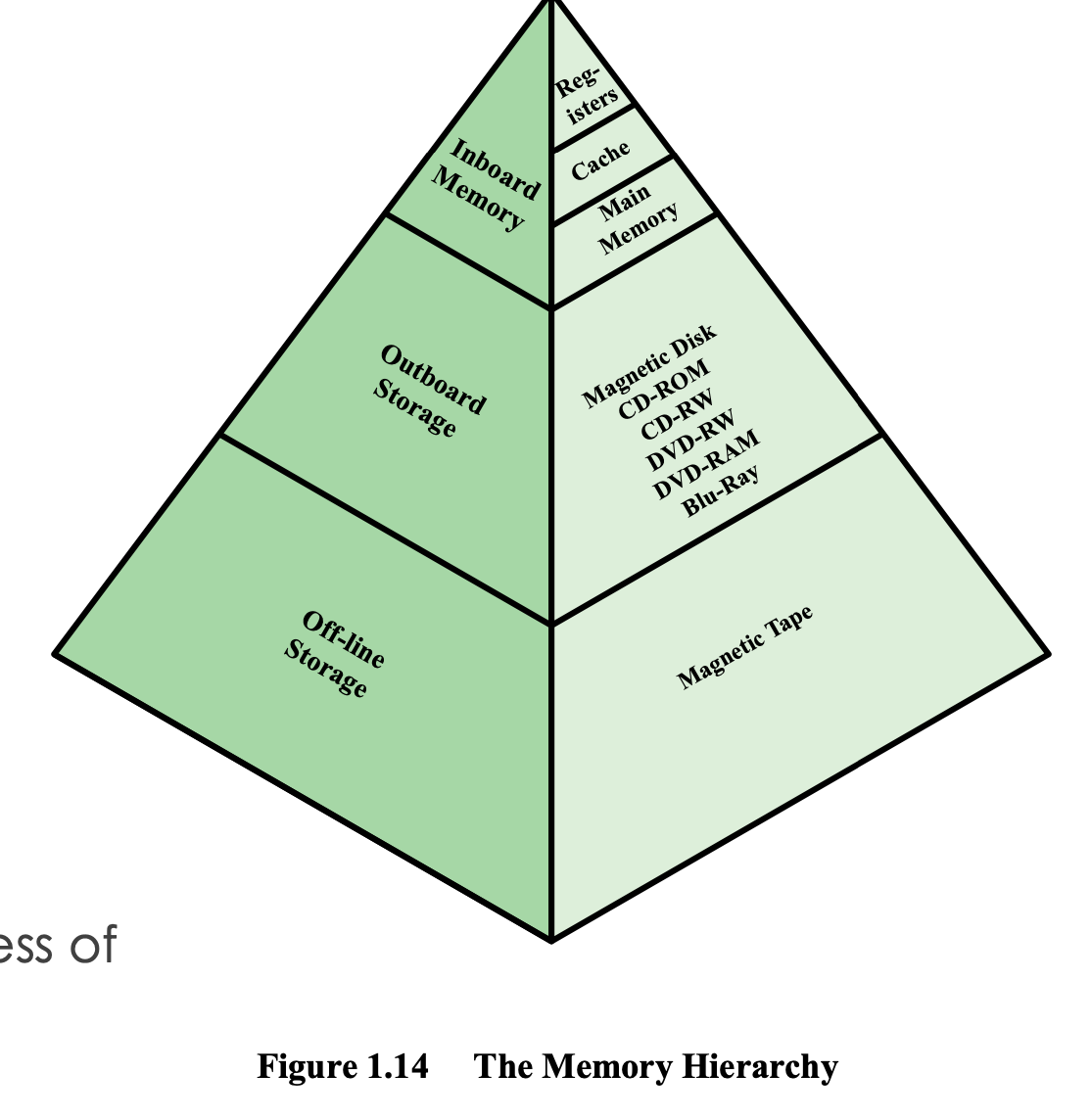
Magnetic Disk = HDD
Memory Hierach은 프로그램이 이동하는 경로이다.
이동순서
Disk → Main Memory → Cache → Register 순으로 이동하게 된다.
Q. 왜 이런 복잡한 이동순서를 가지고 있을까?
→ Main Memory부터 휘발성이기 때문에 전원을 끄는 순간 저장되어 있던 데이터가 모두 사라지게 된다.
→ 저장용량이 문제가 된다.
HDD는 용량이 크기 때문에 모든 파일을 저장할 수 있지만 Memory에는 모든 것을 저장할 수 없다.
- 메모리는 나누어져 있다.
- 실행되는 프로그램도 나누어져 있다.
주된 메모리의 제한들
- 용량 제한
→ 기술적 문제로 인하여 캐시나 레지스터의 용량을 키우고 싶어도 키울 수 없다. - 속도 문제
- 비용 문제
Going Down the Hierachy
(계층이 내려갈 수록)
- 싸다
- 용량이 커진다.
- 접근 속도가 빨라진다.
- 시스템이 효율적으로 이루어질 수 있도록 최대한 하드디스크에 접근하는 일을 줄인다.
→ 속도가 느린 애들은 가끔씩 접근해서 속도를 높인다.
효율적으로 프로그램을 실행시키기 위해
- 한 페이지 단위로,
HDD → Main Memory로 명령어 읽어오기 - 한 블럭 단위로,
Main Memory → 캐시로 명령어 읽어오기 - 한 word(문장) 단위로,
캐시 → 레지스터로 명령어 읽어오기
Reference locality
내가 사용하는, CPU에 의하여 참조되는 메모리의 함수들(Instruction, Data)은 뭉쳐있어야 한다.
⇒ 즉, 변수 선언 위치가 중요하다!
Cache Memory
- CPU는 메모리의 속도보다 빠르다.
- CPU 처리 속도만큼 빠르다
→ 따라서 PC에서는 Cache에 먼저 실행하려는 번지의 명령어가 있나 확인하고,
캐시에 해당 번지의 명령어가 없으면 main memory로 가서 확인하고 해당 번지 주변의 명령어 한 블럭을 가져오고,
main memory의 속도를 빨라보이게 한다.
(별 일 없으면 다음 명령어 실행 순서는 순차적으로 진행된다는 가정하에 캐시를 사용하여 진행된다.) - 캐시는 메인 메모리의 일부분을 복사하여 포함한다.
- 메인 메모리의 속도를 증가시킨다.
- Operating System이 관리하지 않는다.
Q. why is cache memory invisible to the operating system?
(OS에서 Cache를 관리하지 않고 Hardware에서 관리하는 이유?)
컴퓨터의 성능향상을 위해서이다.
속도 향상 → 더 빠르고 빈번하게 명령어와 데이터에 접근할 수 있다.
OS로 인한 overhead나 delay를 없애기 위함이다.
캐시는 빠른 액세스가 가능한 하드웨어에서 데이터를 가져오면서 속도 향상을 노리며, 동시에 동일 데이터에 대한 접근 시 미리 구성된 데이터를 응답하여 불필요한 검색 작업을 방지할 수 있다.
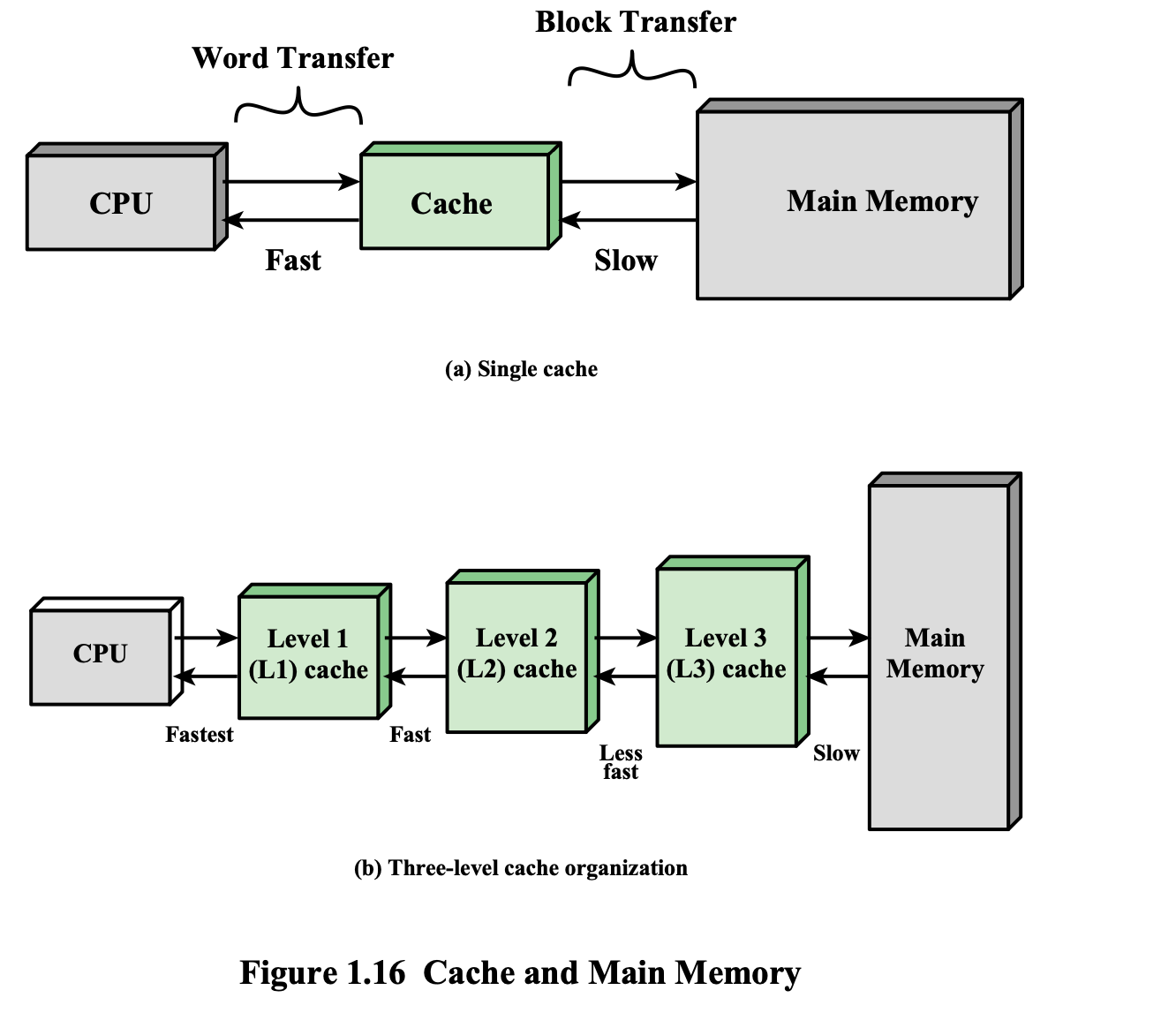
- word는 Instruction 하나를 의미하는 단위이다.
- cache가 CPU에 가까울수록 빠르고 Main Memory에 가까울수록 느리다.
I/O Techniques
세 개의 기술들이 I/O operations에서 가능하다.
1. Programmed I/O
I/O 프로그램을 OS가 실행을 하고 I/O device가 작업을 하는 동안 그냥 서있는 것
2. Interrupt-Driven I/O
I/O Device가 작업을 하는 동안에 CPU는 User Program을 계속 실행하다가 나중에 I/O 작업이 다 끝나면 인터럽트가 걸리면 OS가 5번 코드를 처리하는 것을 말한다.
-
표준 입출력시 사용한다.
-
data의 이동 경로
⇒ Main Memory ↔ CPU ↔ I/O
3. Direct Memory Access (DMA)
data의 이동경로
⇒ Main Memory ↔ I/O
-
굉장히 많은 양의 데이터가 이동할 때, 즉 파일 입출력시 사용한다.
-
메인 메모리와 I/O 모듈도 연결되어 있으므로 효율적인 데이터 처리를 위해 이 두 장치 사이에서 데이터와 명령어들이 CPU를 거치지 않고 바로 이동하는 것
-
CPU는 오직 전송의 처음과 끝에만 개입한다.
- 입력인지 출력인지 확인 (read or write)
- 어느 I/O device인지
- 메모리와 I/O buffer 시작 주소
- 정보의 길이 (끝 주소가 아닌 시작 주소와 길이가 들어가 있다.)
-
DMA도 Interrupt는 존재한다.
I/O device controller가 인터럽트를 걸어서 성공여부를 확인한다. -
Interrupt-driven이나 programmed I/O보다 효율적이다.
즉 DMA는 다른 I/O 작업보다 빠르게 작동할 수 있다. -
CPU 접근에서 bus가 요구될 때 전송 동안 CPU는 더 천천히 작동된다.
대용량 프로그램인 것을 확인한 CPU는 메인 메모리와 I/O 모듈들에게 서로 직접적으로 소통하라고 한 다음 다른 프로그램을 실행한다.
그런데 메인메모리에서 명령어를 가져올 때 메인메모리와 I/O가 소통중이면 System Bus를 사용할 수 없다.
⇒ 따라서 충돌이 일어나지 않도록 조절을 해주어야 한다.
그렇기에 CPU가 기다려야해서 느려질 수 있다.
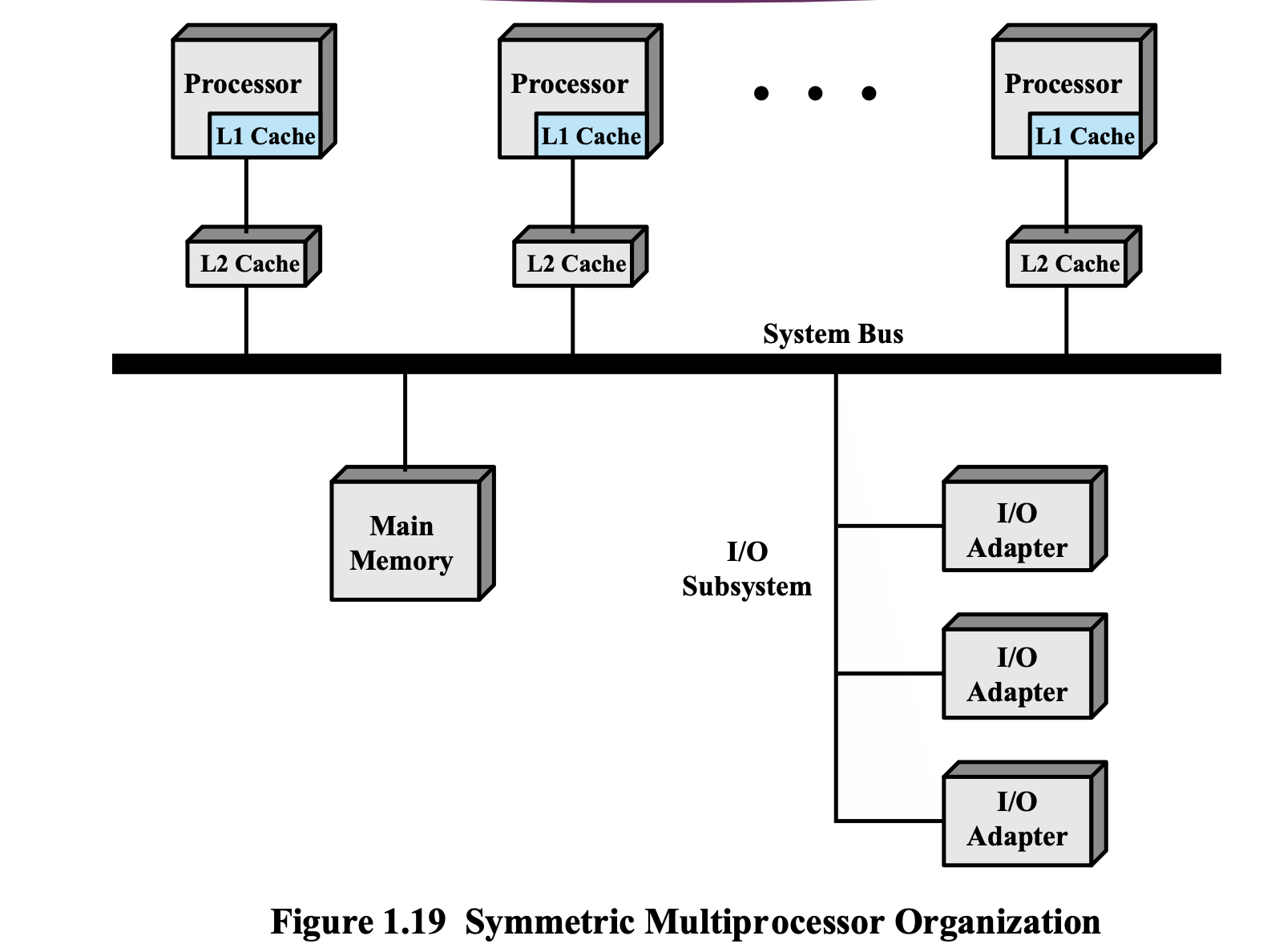
Symmetric Multiprocessors(SMP)
Multi Processor
하나의 시스템에 CPU가 하나인게 아니라 여러 개가 존재하는 것
-
메모리랑 I/O System은 공유한다.
CPU가 100개라고 키보드를 100개 달아 놓는 것이 아니다.
→ CPU가 1개일 때 보다 속도가 빨라진다. -
CPU가 10개 있더라도 1개일 때 보다 10배가 빨라지는 것은 아니다.
→ OS 때문이다.
Symmetric OS 때문
CPU가 100개이든 200개이든 시스템을 관리하는 것은 OS이다.
OS가 시스템을 잘 못 관리하면 CPU가 아무리 많아도 소용이 없다.
Symmetric의 뜻
대칭형 다중 처리(symmetric multiprocessing, SMP)는 두 개 또는 그 이상의 프로세서가 한 개의 공유된 메모리를 사용하는 다중 프로세서 컴퓨터 아키텍처이다.
-
각각의 CPU에 OS를 실행시킬 수 있다는 뜻이다.
→ OS가 동시에 실행된다는 것은 공유된 자원을 동시에 사용할 수 있게 된다는 의미이다. -
현재 사용되는 대부분의 다중 프로세서 시스템은 SMP 아키텍처를 따르고 있다.
-
SMP 시스템은, 작업을 위한 데이터가 메모리의 어느 위치에 있는지 상관없이 작업할 수 있도록 프로세서에게 허용한다.
운영체제의 지원이 있다면, SMP 시스템은 부하의 효율적 분배를 위해 프로세서간 작업 스케줄링을 쉽게 조절할 수 있다. -
그러나 메모리는 프로세서보다 느리다. 단일 프로세서라도 메모리로부터 읽는 작업에 상당한 시간을 소비한다. SMP는 이를 더욱 악화시키는데,
한 번에 한 개의 프로세서만이 동일한 메모리에 접근 가능하기 때문이다. 이는 다른 프로세서들을 대기하도록 만든다. -
OS가 시스템 안에 있는 중요한 자원에 access할 때는 마음대로 access하지 않고, rule을 정해서 순차적으로 작업을 해야한다.
→ 이 때 사용하는 여러 가지 도구들이 있다. -
중요한 것은 둘 중 하나는 기다려야 한다는 것이다.
즉, CPU가 10개이더라도 소용이 없다.
어차피 순차적으로 하나씩 처리되기 때문이다.
Multicore Computer
여러개의 CPU가 하나의 시스템 안에 있는 것을 말한다.
하나의 시스템이 아니라 하나의 칩 안에 굉장히 많은 칩들이 들어가 있다.
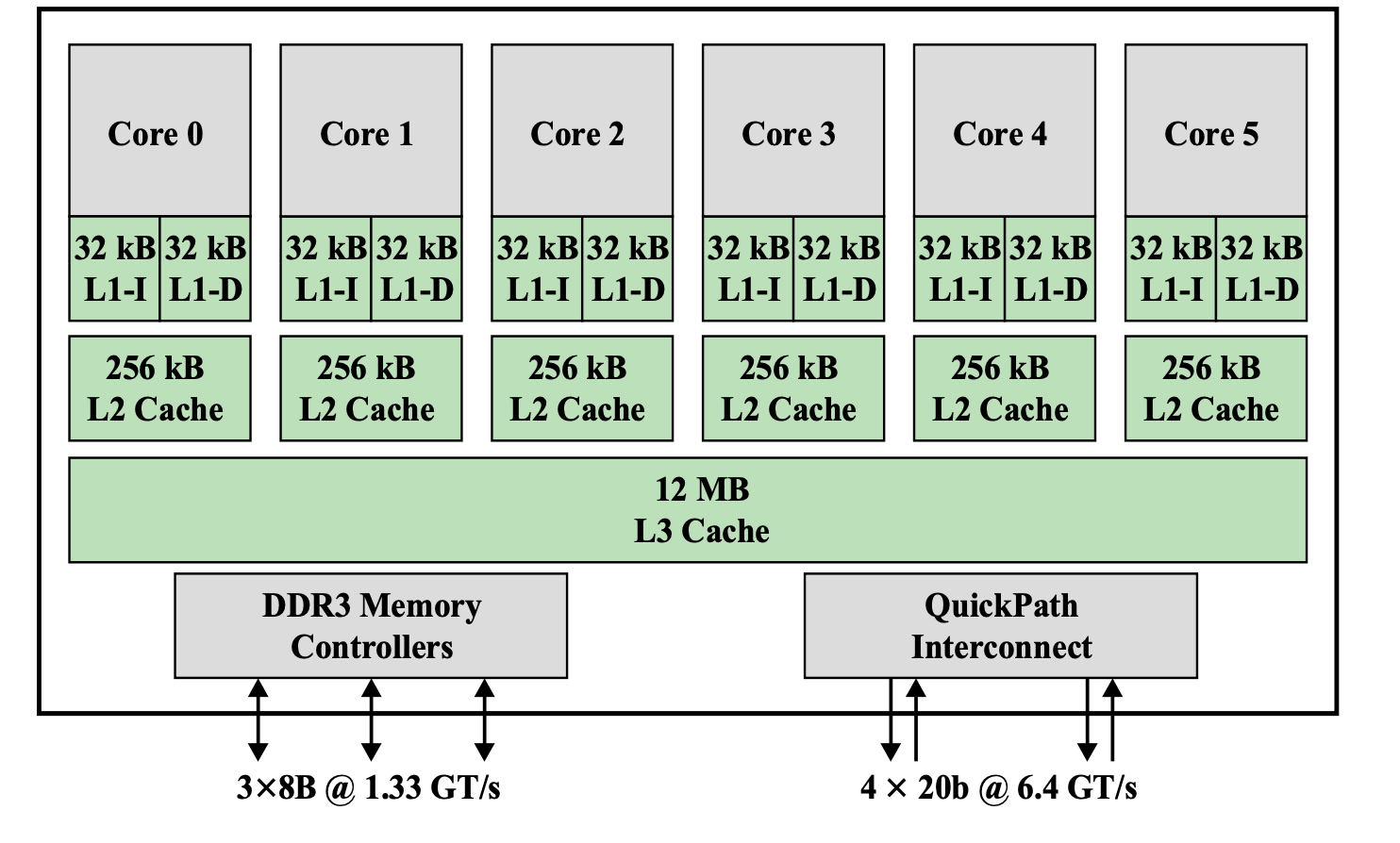
CPU들이 캐시들을 가지고 있다.
위에서는 캐시가 두 단계 캐시였는데, 여기서는 세 단계 캐시를 가진다.
두 단계 캐시까지는 각자 자기 캐시를 가지고 있는데 세 번째 단계 캐시는 공유 캐시이다.
→ 같은 칩이기 때문에 캐시도 공유할 수 있다.
