Disk Scheduling
1. First-in, First-out (FIFO)
큐에 먼저 들어온 request 부터 처리한다.
2. Shortest Service Time First
실행시간이 짧은 request 부터 처리한다.
3. SCAN
굉장히 공정한 방법이다. Starvation 발생 가능성이 거의 없다. (완벽하게 없진 않다. 특정 트랙에 계속해서 request 가 쏟아지면 진행을 못할 수도 있기 때문이다.) → 완벽하게 fair 하냐? X, 어떤 상황에서 완벽하게 fair 하지 않나?
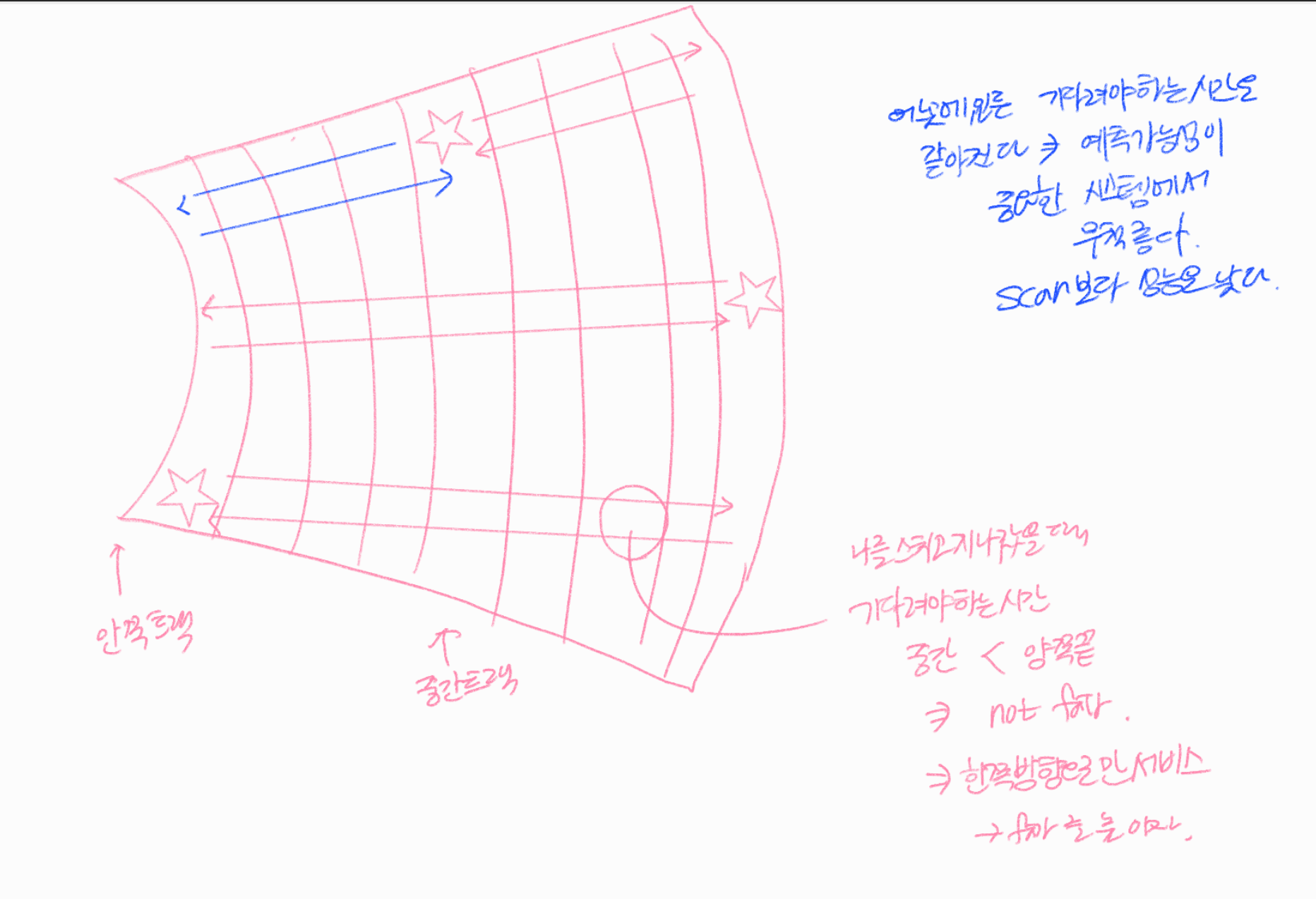
디스크 안에 여러 트랙이 있는데 중간 트랙에 있는 request가 있고 안쪽끝과 바깥쪽 끝에 있는 request가 있다.
request가 딱 도착을 했을 때 헤더가 그 트랙에 대한 서비스를 끝마치고 트랙을 막 떠난 상황이다. 끝까지 갔다가 다시 돌아올때까지 기다려야 한다.
얼만큼 기다리는가?
↳ 자기를 막 스치고 지나갔다고 했을 때 끝까지 갔다가 다시 돌아오는데 걸리는 시간 (내가 기다려야 하는 maximum 시간) = 바깥쪽 지점 > 중간 지점
⇒ 완벽하게 fair 하지 않다.
4. N-step-SCAN
Starvation 가능성이 완전히 없다.
↳ 추가로 도착하는 request 들을 나중에 처리하기 때문이다. 그러나 N 값이 1인 경우 FCFS 가 된다. 따라서 결국 N 값을 어떻게 정하느냐에 따라 성능이 SCAN 에 가까울 수도 있지만, FCFS 에 가까운 성능을 가지게 될 수도 있다.
5. FSCAN
- 큐 두개를 사용한다.
- 한 방향으로 끝까지 갔다가 다시 돌아오며 새로운 요청들을 처리한다.
Starvation 가능성이 완전히 없다.
C-SCAN
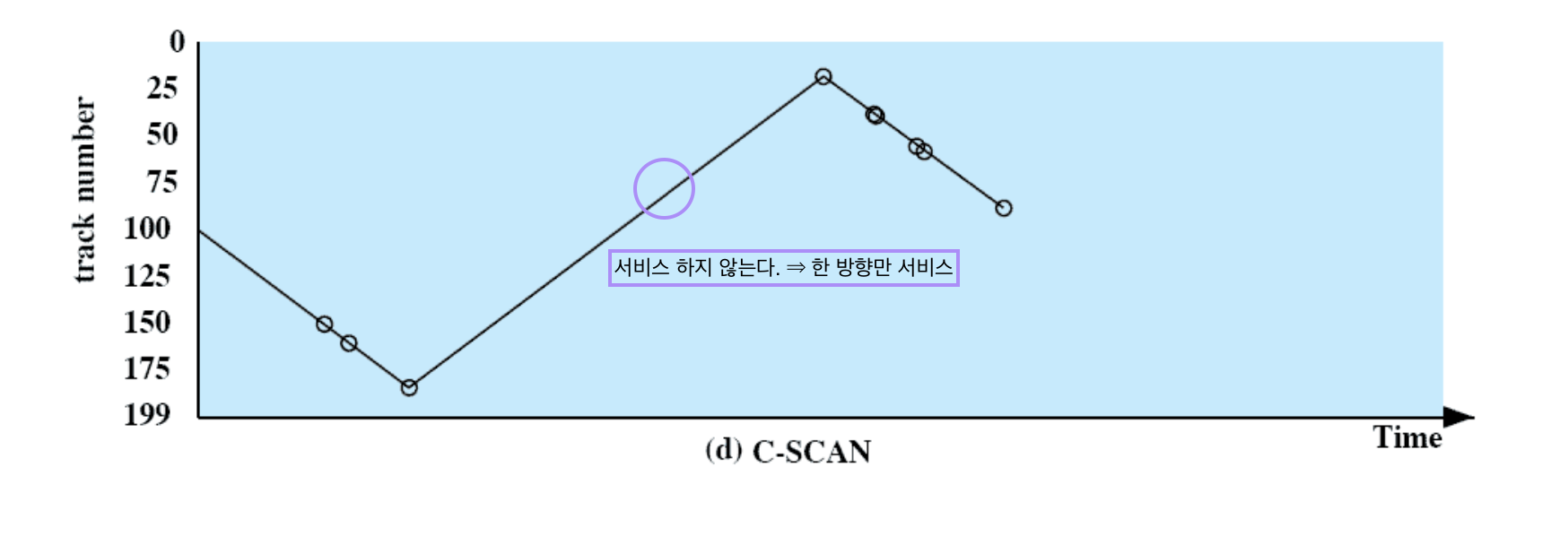
모든 request 들을 완벽하게 fair 하게 처리하겠다!
한쪽 방향으로만 서비스를 한다. 바깥쪽 끝까지 갔다가 방향을 바꿔 돌아올때는 서비스를 하지 않는다.
나를 스치고 지나갔을 때 기다려야 하는 시간 = 중간 지점 < 양쪽 끝 지점
⇒ not fair ⇒ fair 를 위해 C-SCAN은 한쪽 방향으로만 서비스한다.
↳ 반대 방향으로 갈때는 서비스하지 않는다.
어느 트랙에 있든 기다려야 하는 시간도 같아지게 된다.
⇒ 예측가능성 이 중요한 시스템에서 무척 좋다. 어떤 경우에도 어떤 request 든지 얘가 언제쯤 처리될지를 정확하게 예측해야 하는 real time system 같은 경우에 사용할 수 있는 기법이다.
⇒ CSCAN은 완벽하게 fair 한 기법이다.
단, SCAN 보다 성능은 낮다.
그 밖의 Disk Scheduling Policies
위의 Disk Scheduling 기법들은 head 의 움직임을 최소화하려고 했다.
Priority scheduling
- Short batch jobs and interactive jobs are given higher priority than jobs that require longer computation
- Not intended to optimize disk utilization, but to meet other objectives within the OS
Disk 의 Performance 를 생각하지 않고 request 를 보낸 프로세스의 종류 에 따라서
interactive 한 job이나 batch job 중에 실행시간이 짧은, 빨리 끝내야하는 프로세스들의 request를 먼저 처리하고,
일반 batch job 들, 실행시간이 느려도 되는 애는 나중에 처리한다.
⇒ 프로세스에 따라 다르게 우선순위를 맞추어 처리 준다.
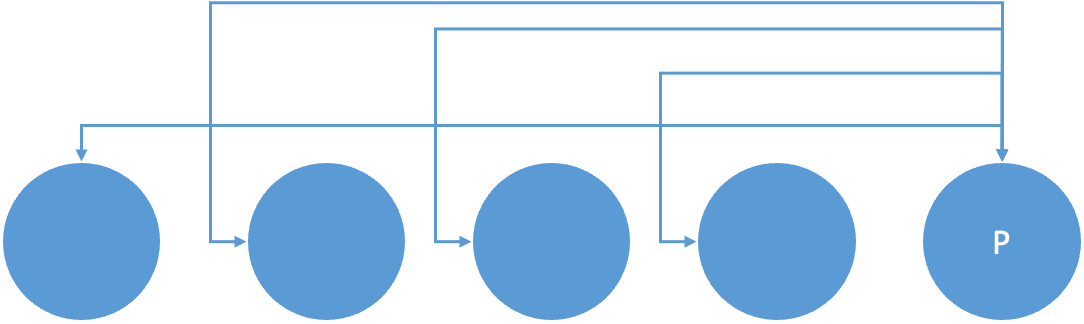
Last-In-First-Out 🌟
- A policy of always taking the most recent request has
some merit - Taking advantage of the locality improves throughput and reduces queue lengths
- Possibility of starvation
Queue 의 요청들이 있으면, 큐의 제일 끝에서부터 처리하겠다는 것이다.
앞이 아닌 뒤부터 처리한다. ⇒ 지금 실행하고 있는 프로세스의 request인, 가장 최신 요청부터 처리한다는 의미를 가지고 있다.
Locality
뒤에서부터 처리를 하게 되면 그 근처에 실행하고 있는 프로세스의 요청들이 모여 있을 것이므로 → 하드디스크 안에 같은 block, sector, track 위치에 원하는 데이터나 코드가 모여 있을 것이다.
문제점
한 번 밀리면 거의 starvation 이다.
RAID
Redundant Array of Independent Disks
- harddisk 1개 → data 들이 있을 때 1개에 저장한다. 내가 하나의 하드디스크를 쓸때는 큐의 길이가 100개이다.(큐에 요청을 100개하는 것)
- harddisk 10개 → data 를 나눠서 저장한다. 한 디스크당 큐의 길이는 10개가 되어 하드디스크가 1개일때보다 길이가 1/10으로 줄어들고 읽는 속도는 증가한다.
여러개의 디스크를 구입해서 하나의 디스크처럼 사용하는 것으로 실제로는 10개의 디스크를 구입해서 10개의 디스크의 데이터를 분산을 시켰고 user 입장에서는 어느 디스크에 어느 데이터가 있는지 알아야할 필요가 없다.
여러 디스크들을 하나의 디스크처럼 logical 하게 사용하는 시스템을 RAID System 이라고 한다.
- Set of physical disk drives viewed by the operating
system as a single logical drive - Data are distributed across the physical drives of an array
- Redundant disk capacity is used to store parity information which provides recoverability from disk failure
RAID 0 (non-redundant)
Disk 4개 ⇒ 돈 4배
내 파일들을 strip 단위로 나누어서 4개의 디스크에 분산 저장하는 것
⇒ 속도가 4배 빨라진다.
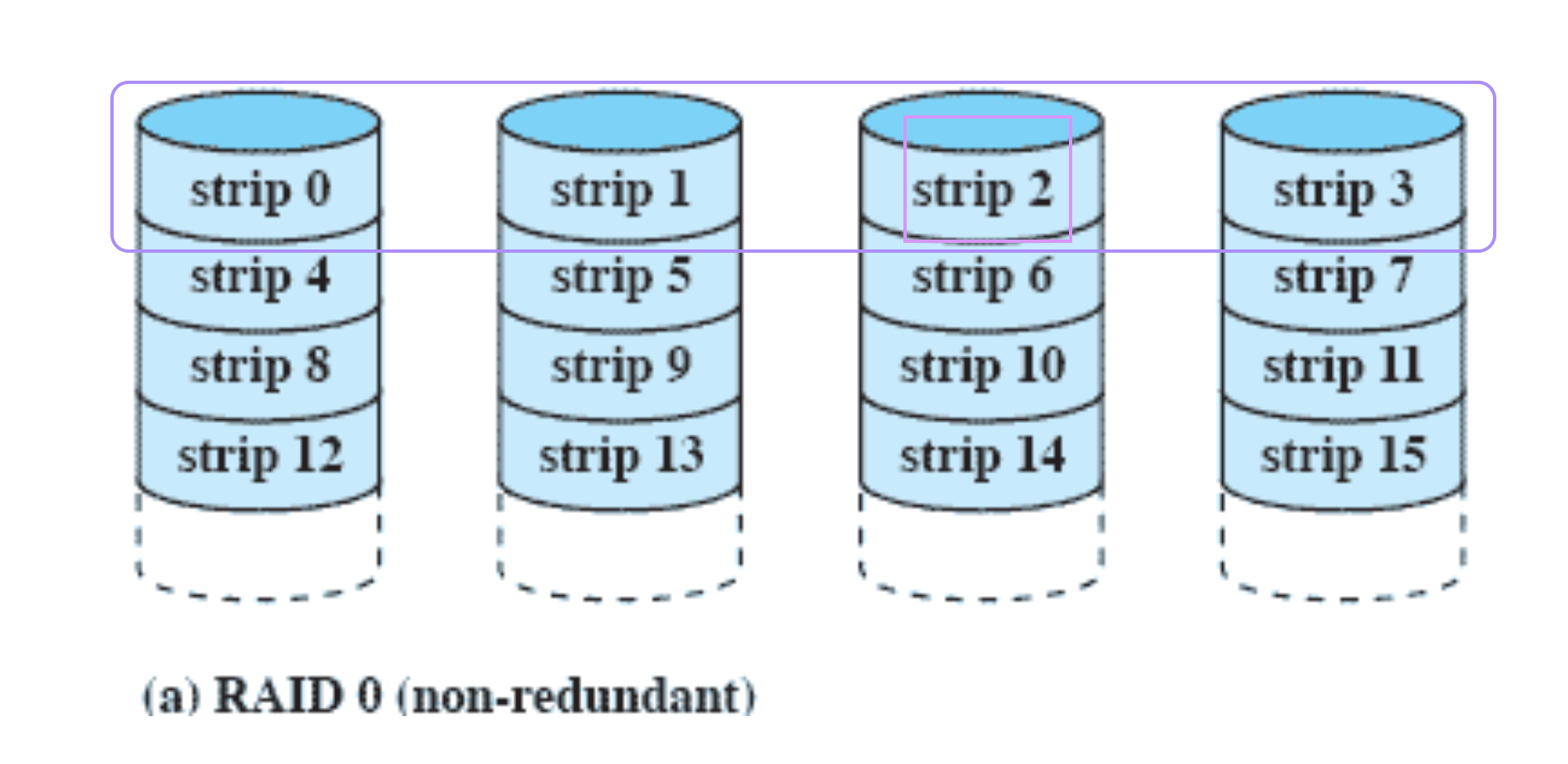
하지만 디스크 중 한개가 고장날 수도 있다.
위의 그림을 보면 보라색 네모가 하나의 파일이라고 할 때 strip2 가 사라지면 파일의 일부가 사라져서 아무것도 할 수 없게 된다.
RAID 1 (mirrored)
문제점
하드디스크가 1개일때보다 돈이 8배가 더 들어간다. 하지만 속도는 4배만 빨라진다.
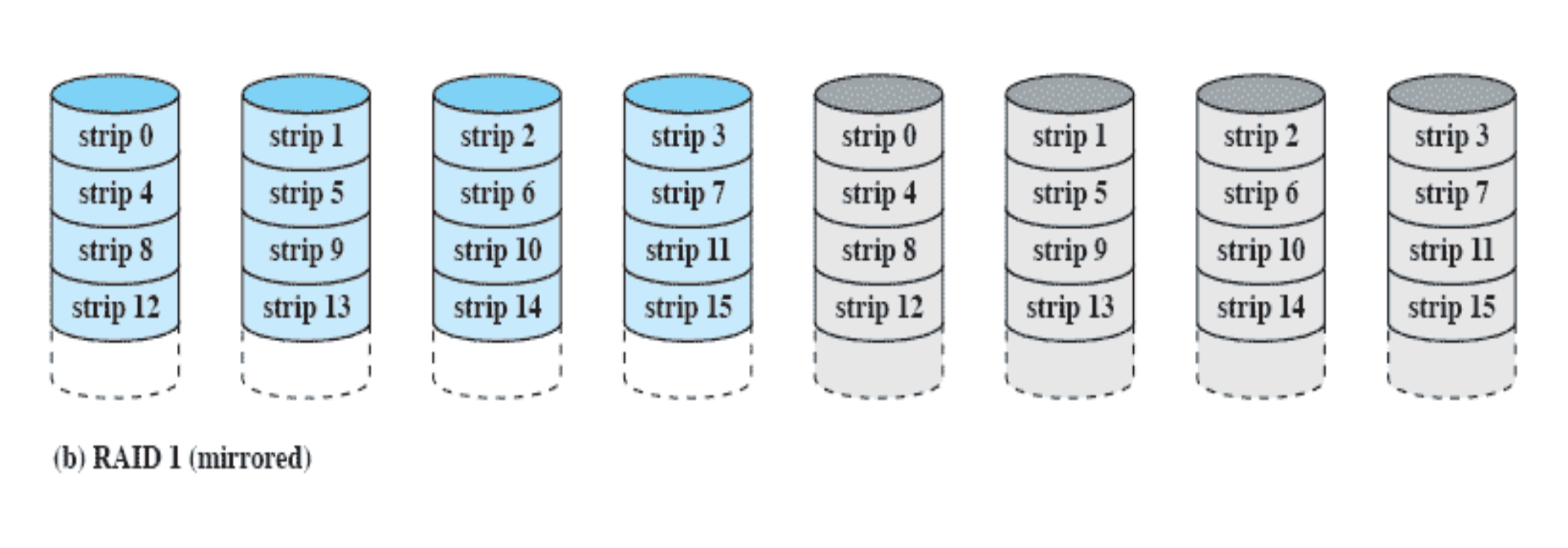
파란색 하드디스크
- 데이터를 strip 단위로 나누어서 저장
- 데이터를 읽을 때 여기서 읽으면 된다.
- 데이터를 쓸 때 여기도 써야하고 회색에도 써야한다.
회색 하드디스크
- 미러링한 하드디스크(copy 해놓은 것)
- 데이터를 써야 한다.
RAID 2 (redundancy through Hamming code)
복사본을 만들 때 code 를 사용하자!
스트립 단위가 아니라 bit 단위로 나누자!
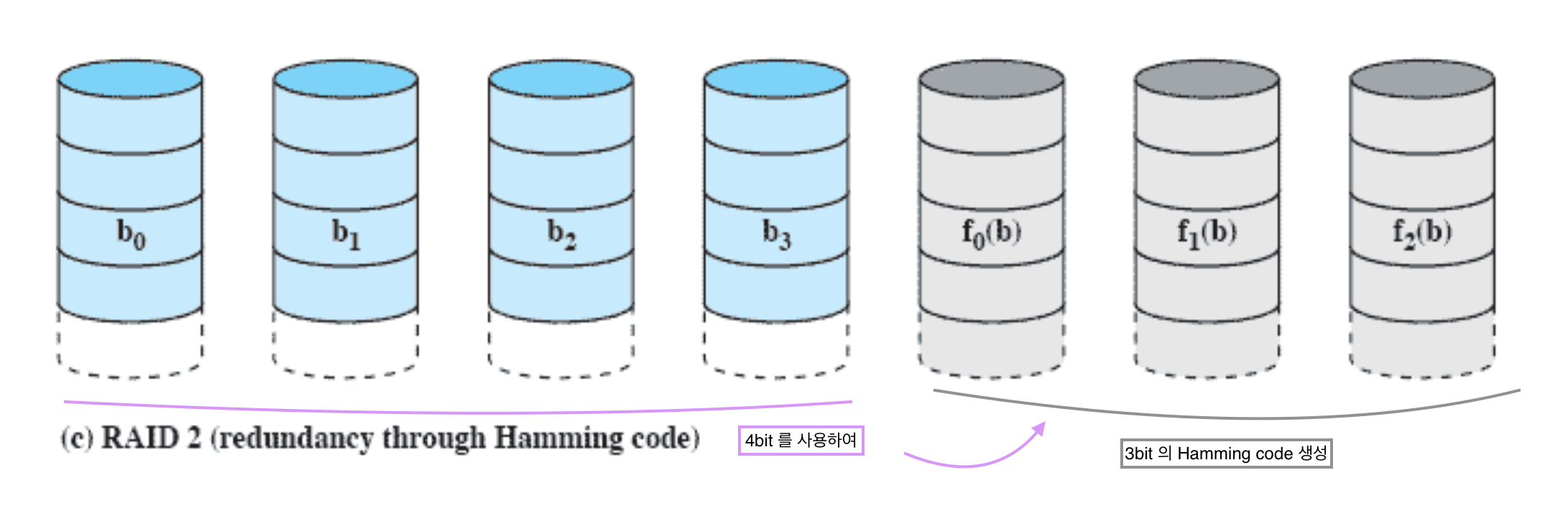
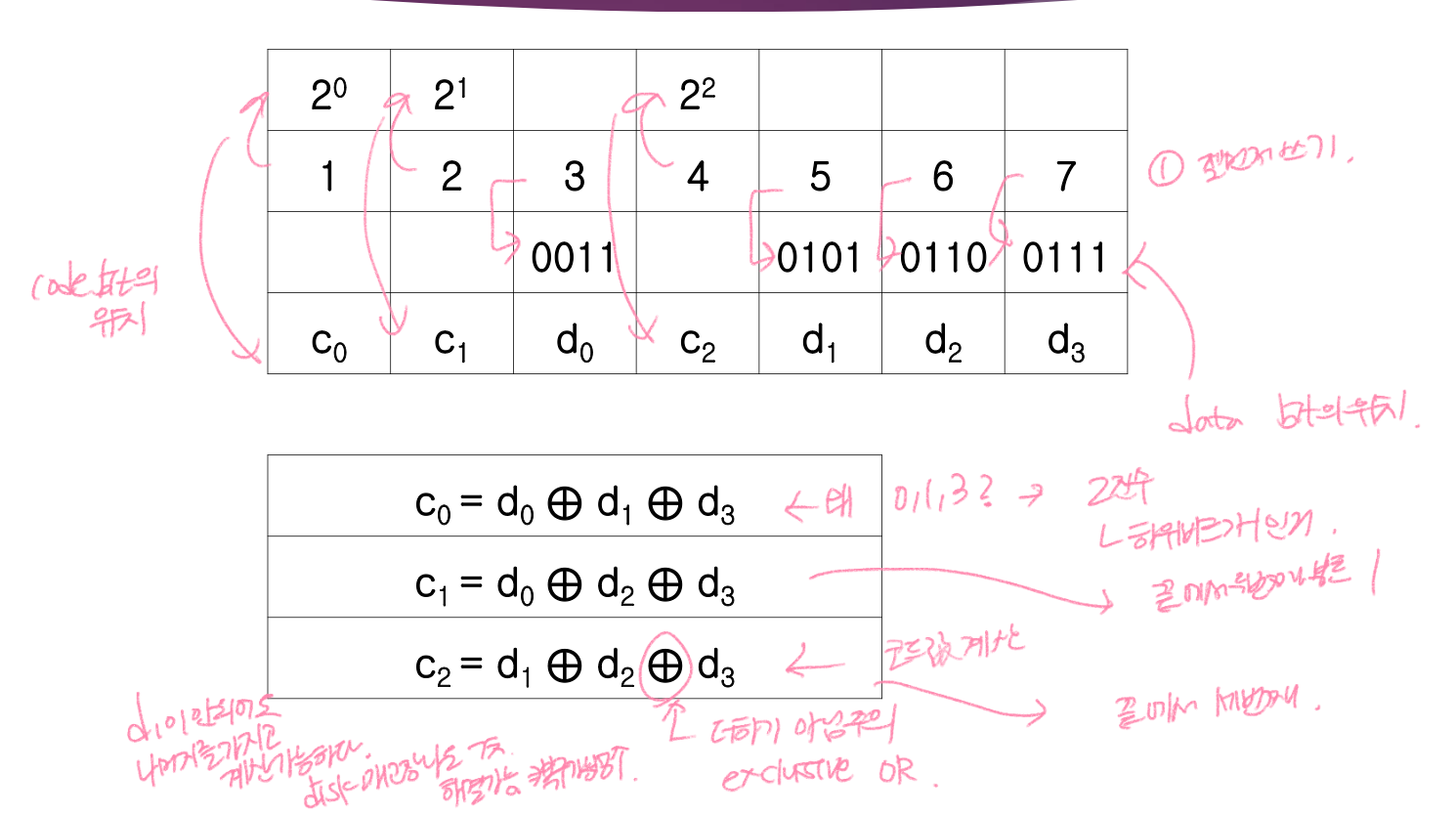
- 제일 먼저 1, 2, 3, ..., 7 까지 쓰기
- 이진수 위치에 code bit 가 놓인다.
- 나머지 수에는 data bit 가 놓인다.
- code bit 계산 방법:
- c0 → data bit 가 이진 수 제일 오른쪽 애가 1인 애들 exclusive or 하기 (같으면 0, 다르면 1)
- c1 → data bit 가 이진 수 제일 오른쪽에서 두번째인 애가 1인 애들 exclusive or 하기
- d1 이 안되어도 나머지를 가지고 계산이 가능하다.
- disk 가 두개 고장나도 해결이 가능하다. ⇒ 복구가능성이 높다.

data disk 가 14개 존재한다. → code disk 가 몇개가 필요한가?
code disk 는 2진수에 위치한다.
code 는 2^n 에만 필요하다. ⇒ 간격이 점점 커진다.
data disk 의 개수가 많아질수록 code disk 의 개수는 적게 필요하게 된다.
계산해보기
data disk 의 위치부터 결정해야 한다. 이 예제에서는 코드디스크가 5개가 필요하다. 이진수로 3~20까지 만들면, 5비트의 이진수가 만들어진다.
- C0: 제일 마지막 비트가 1인 애들을 모아서 exclusive or
- C1
- C2
- C3
- C4
RAID 3 (bit-interleaved parity)
parity 는 bit 를 사용한다.
Parity bit 는 data disk 개수에 상관 없이 딱 하나의 하드디스크만 더 있으면 된다.
⇒ 최소한의 비용으로 문제를 해결할 수 있다.
b0b1b2b3 P(b)
1 0 0 1 → Parity bit = 1 (홀수)
1 1 1 0 → Parity bit = 0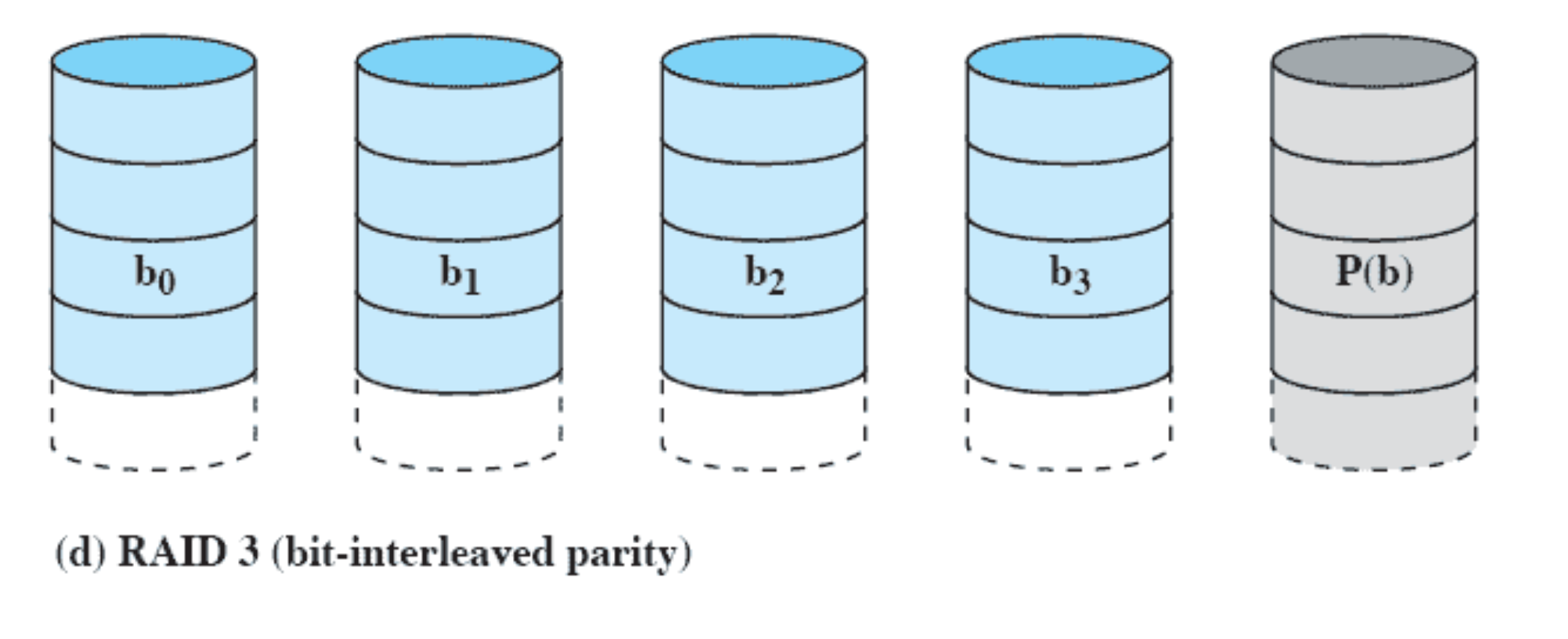
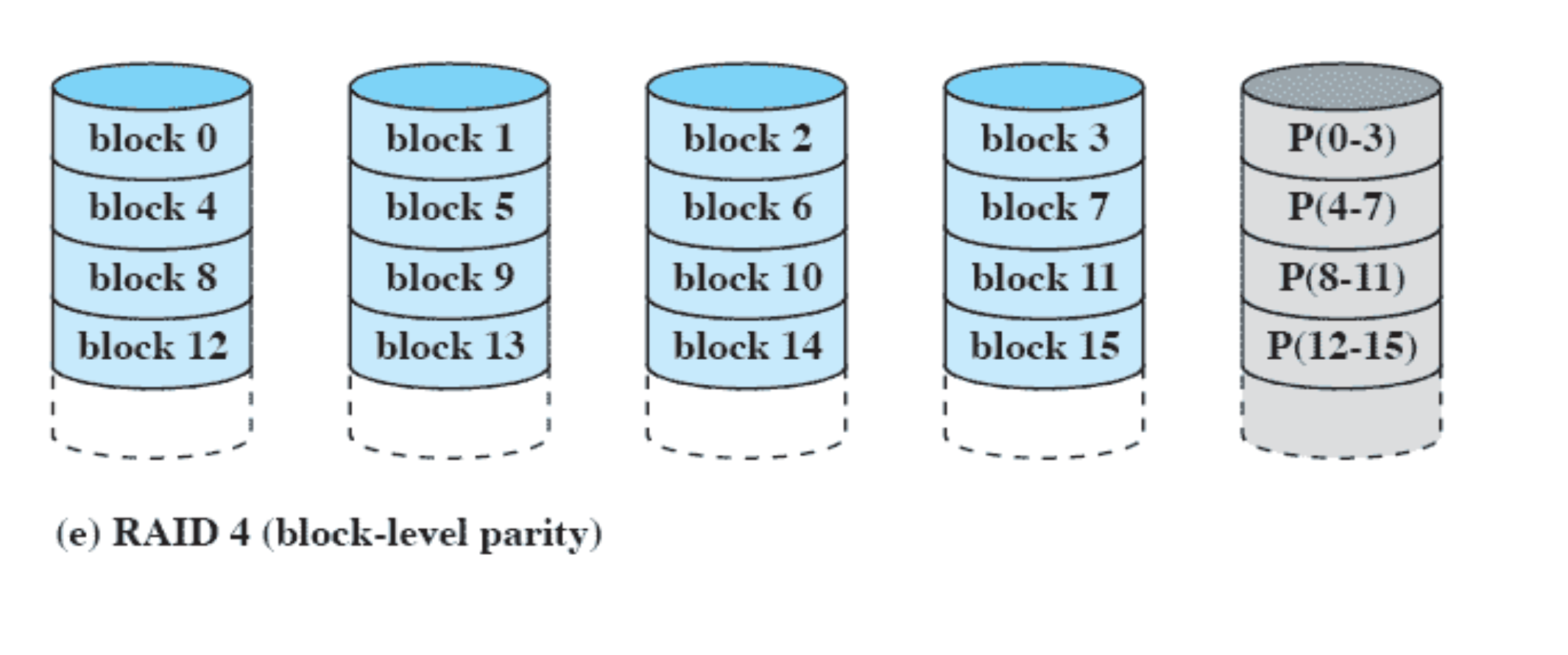
RAID 4 (block-level parity)
필요한 모든 file 들 을 block 단위로 나누고 parity block 을 만들어서 block 단위로 parity 를 계산한다.
data disk 에는 내가 수정한게 여기저기 분산되어 있어서 read 가 아니라 write 를 request 하는 경우 한번의 업데이트가 아니라 4개의 request 가 몰리게 된다. 여러번 업데이트를 해주어야 한다.
write request 가 parity disk 에 data disk 의 네배정도가 몰릴 수 있다.
RAID 5 (block-level distributed parity)
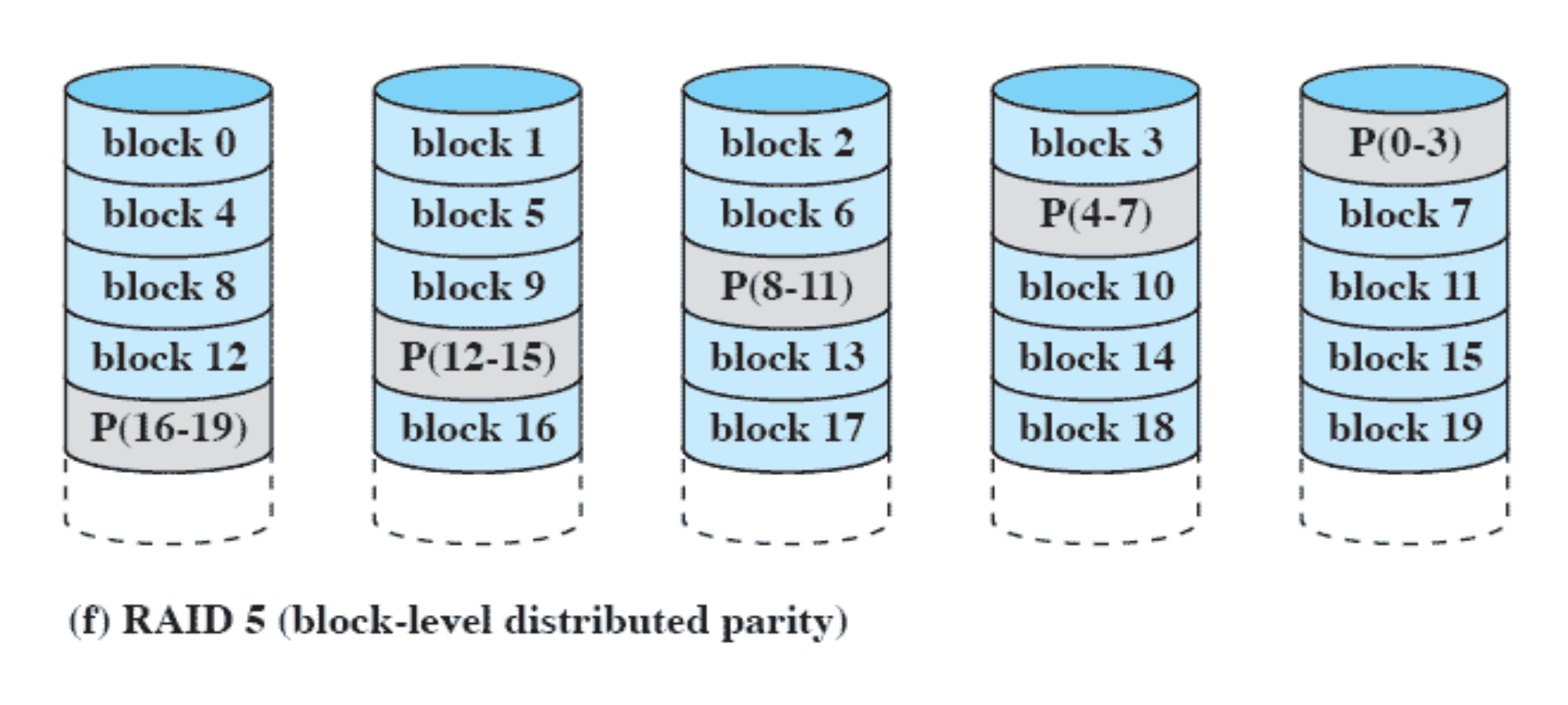
Parity 를 다섯개의 disk 에 골고루 분산해서 나누었다. Disk Queue 의 길이가 길어지지 않고 전체적으로 속도 향상이 이루어지게 된다.
Disk Cache
file 에서 정수 하나 읽어오라고 했을 때 정수 하나를 읽으려고 하더라도 하나의 block 을 가져온다.
↳ 하드디스크와 메모리 사이에서 데이터가 움직이는 단위는 block 이다.
아까 가져온 block 에 내가 다음에 필요한게 block 에 이미 있으면 하드디스크로 가서 다시 block 을 가져오는 시간을 save 할 수 있다.
Disk Cache: Disk 에서 가져온 block 들을 메인 메모리 buffer 에 저장
→ block 이 필요할 때 이 buffer 에 있는지 확인
→ 확인해서 없으면 disk 로 가서 가져오기
- Buffer in main memory for disk sectors
- Contains a copy of some of the sectors on the disk
- When an I/O request is made for a particular sector,
- a check is made to determine if the sector is in the disk
cache.
- a check is made to determine if the sector is in the disk
- A number of ways exist to populate the cache
main memory 크기에 한계가 있으므로 제한된 크기의 disk cache 를 이용할 수 있다. 이 disk cache 에 들어 있는 block 하나를 버릴 때 굉장히 주의해서 버려야 한다.
(다시는 사용하지 않을 것 같은 block 은 버리고 사용할 것 같은 건 버리면 안된다.)
↳ page replacement 와 비슷하다.
page replacement 중 성능이 LRU 가 가장 좋았지만 DISK Cache 에서는 LRU 방법이 제일 좋진 않다.
Least Recently Used (LRU)
최근에 사용하지 않고 오래전에 가져온 것을 버린다. ⇒ stack 을 사용한다.
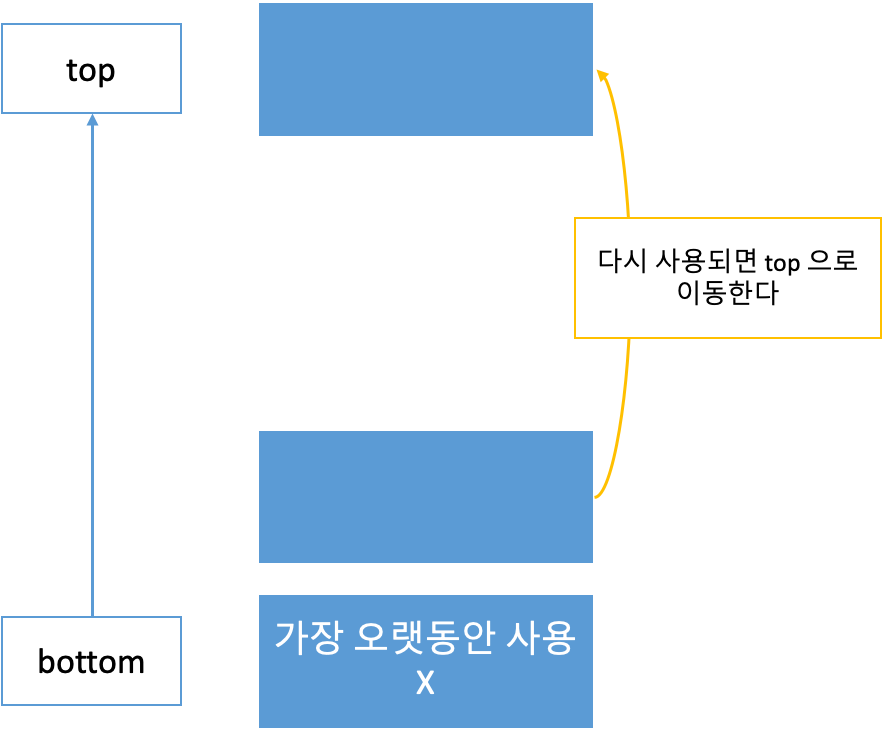
- top: 가장 최근에 사용한 block
- bottom: 가장 오랫동안 사용되지 않은 block
어떠한 block 이 다시 사용이 되면 stack 의 top 으로 올린다.
공간이 모자라서 block 을 버릴 때는 가장 밑에 애를 버린다. (Disk Cache 에서는 좋은 성능 X)
- A stack of blocks are cached
- Recently used block is on the top
- The block on the bottom of the stack is removed when a new block is brought in
Least Frequently Used
최근 사용 X
- O
- X
몇번 사용 O
- O
- X
각각의 block 마다 counter 를 만들어서 몇번 access 가 되었는지 몇번 사용되었는지 체크한다. 사용될 때마다 count 값을 하나씩 늘려준다.
block 을 버릴때는 count 값이 가장 적은 block 을 버린다.
LFU 가 LRU 보다 성능이 좋다.
Disk Cache의 경우에는 지금 당장 사용되어야 하는 block 이 중요한게 아니라 굉장히 오랜시간동안 계속해서 지속적으로 사용되는 block 을 disk cache 에 남겨 놓는 게 더 중요하다.
LFU의 문제점
방금 하드디스크에서 메모리로 올라온 애는 counte 값이 1이라 앞으로 사용될 수 있는데도 버려질 수 있다.
Frequency-based Replacement
stack 사용
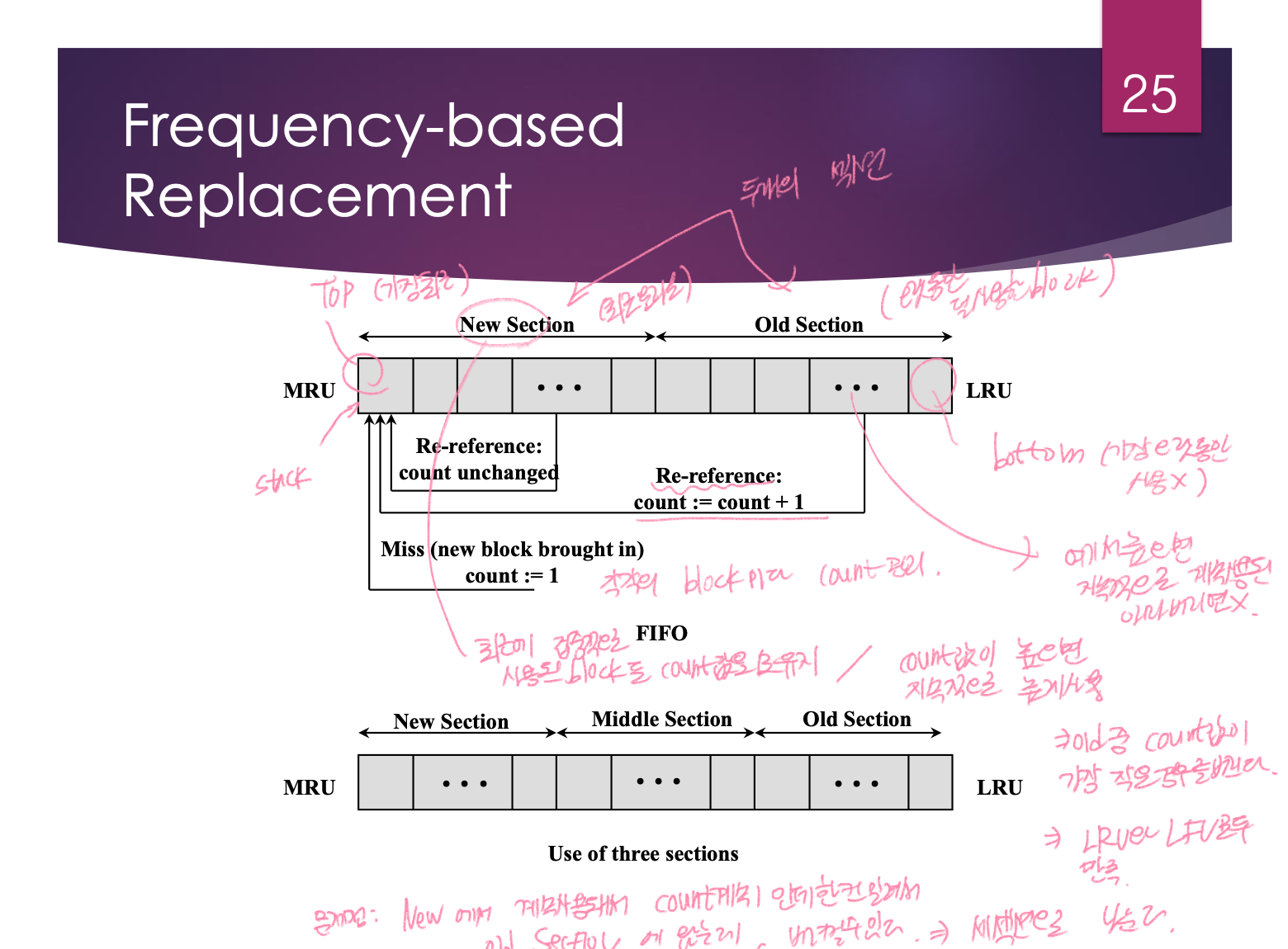
두가지 section 으로 나누기
1. New Section
최근에 메인 메모리로 올라온 block 들, 최근에 사용된 block 들이 모인 곳
2. Old Section
오랫동안 덜 사용된 block emf
- 가장 왼쪽이 top → 가장 최근에 들어오거나 쓰인 애들
- 가장 오른쪽이 bottom → 가장 오랫동안 사용하지 않은 애들
count 관리
각각의 block 마다 count 를 관리한다.
하드디스크에서 방금 올라온 새로운 block 은 count 값을 1로 둔다. 다시 사용되면 다시 top 으로 올려준다. new section 에서의 stack 위치 이동은 count 를 증가시키지 않는다.
↳ 최근에 집중적으로 사용되는 block 이라고 보기 때문이다.
new section 에 있는데 count 값이 굉장히 높다면 굉장히 오랜시간에 거쳐서 사용되고 있는 block 이고 지금도 집중적으로 사용되는 block 이다.
old section 에 있는데 count 값이 높으면 오랜시간을 거쳐서 지속적으로 높게 사용되는 block 이라는 의미이므로 절대 버리면 안되고,
old section 중 count 값이 1이라고 한다면 집중적으로 사용된 적이 있을지는 모르지만 오랫동안 사용된 애는 아니므로 old section 에서 count 값이 가장 작은 경우를 버린다. count 값이 같은 경우에는 bottom 쪽에 있는 애를 버린다.
⇒ LRU와 LFU 모두를 만족시킨다.
- LRU 적용: new section 에 있는 block 은 버리지 않는다.
- LFU 적용: old section 에 있는 block 중 count 값이 제일 작은 걸 버린다.
문제점
NEW 에서 계속 사용되어서 Count 값이 계속 1인데 한칸 밀려서 old section 에 와서 바로 버려질 수도 있다.
세가지 section 으로 나누기
- New
- 처음 하드디스크에서 메모리로 올라오면 여기로 들어온다.
- count = 1
- 다시 사용시 count 값은 변경되지 않는다.
- Middle
- Middle 에서 다시 호출되면 count 값이 1증가한다.
- Middle 에서는 block 을 버리지 않는다.
- Old Section
- 버려질 때는 old 중 count 값이 가장 작은 것을 버린다.
- 다시 호출되면 count 값이 1증가한다.

3개의 댓글

덕분에 운영체제 한 학기 동안 정리를 다시 할 수 있었고 A+라는 값진 선물을 주신 미니마우스 님께 감사의 말씀을 올립니다. 진짜 밥이라도 한 끼 사고 싶네요

2025년도에서도 한 명의 학생을 A+로 만들어 주셨습니다.
과제가 족보 싸움이었는데 덕분에 족보 없이도 좋은 성적 얻었네요
많은 도움이 되었습니다. 감사합니다!
덕분에 한 학기동안 도움 받았습니다 감사합니다