Operating System Design Objectives
I/O
I/O cannot keep up with processor and main memory speed ==> Efficiency is an important issue
I/O 에서는 속도가 매우 중요하다.
하드디스크 성능이 나쁘게 되면 아무리 CPU 나 메모리가 좋아도 성능이 올라갈 수 없다.
Uniform
Desirable to handle all I/O devices in a uniform manner ==> Generality is an important issue
I/O device 들을 access 하는데 uniform 한 방법으로 access 하고 싶다.
monitor이든 file 이든 입출력시 동일한 명령을 사용해서 같은 방식으로 입출력을 하고 싶으므로 같은 방법을 사용한다.
실제 시스템에서는 디바이스에 상관 없이 다 같은 명령을 사용해서 입출력을 하고 있다.
입출력 명령
System call X, I/O library 함수 O
→ 실제 OS 에게 I/O 요청할 때의 명령은 고정 Uniform 을 사용한다.
- 읽기 → Read()
- 쓰기 → Write()
Disk Performance Parameters
1. Access Time
Access Time is the sum of:
Seek Time
The time it takes to position the head at the desired track
헤드가 내가 원하는 트랙 까지 오는데 걸리는 시간
Rotational delay or rotational latency
The time its takes for the beginning of the sector to reach the head
헤드가 내가 원하는 섹터 까지 도달하는 데 걸리는 시간
2. Transfer Time
Transfer Time is the time taken to transfer the data.
Transfer Time 을 줄일 수 없기 때문에 Access time 둘 중 하나를 줄여야 하는데, 판을 돌리는 데 걸리는 시간은 얼마되지 않으므로 원하는 트랙에 도달하는 시간인 Seek time 을 줄여야 한다.
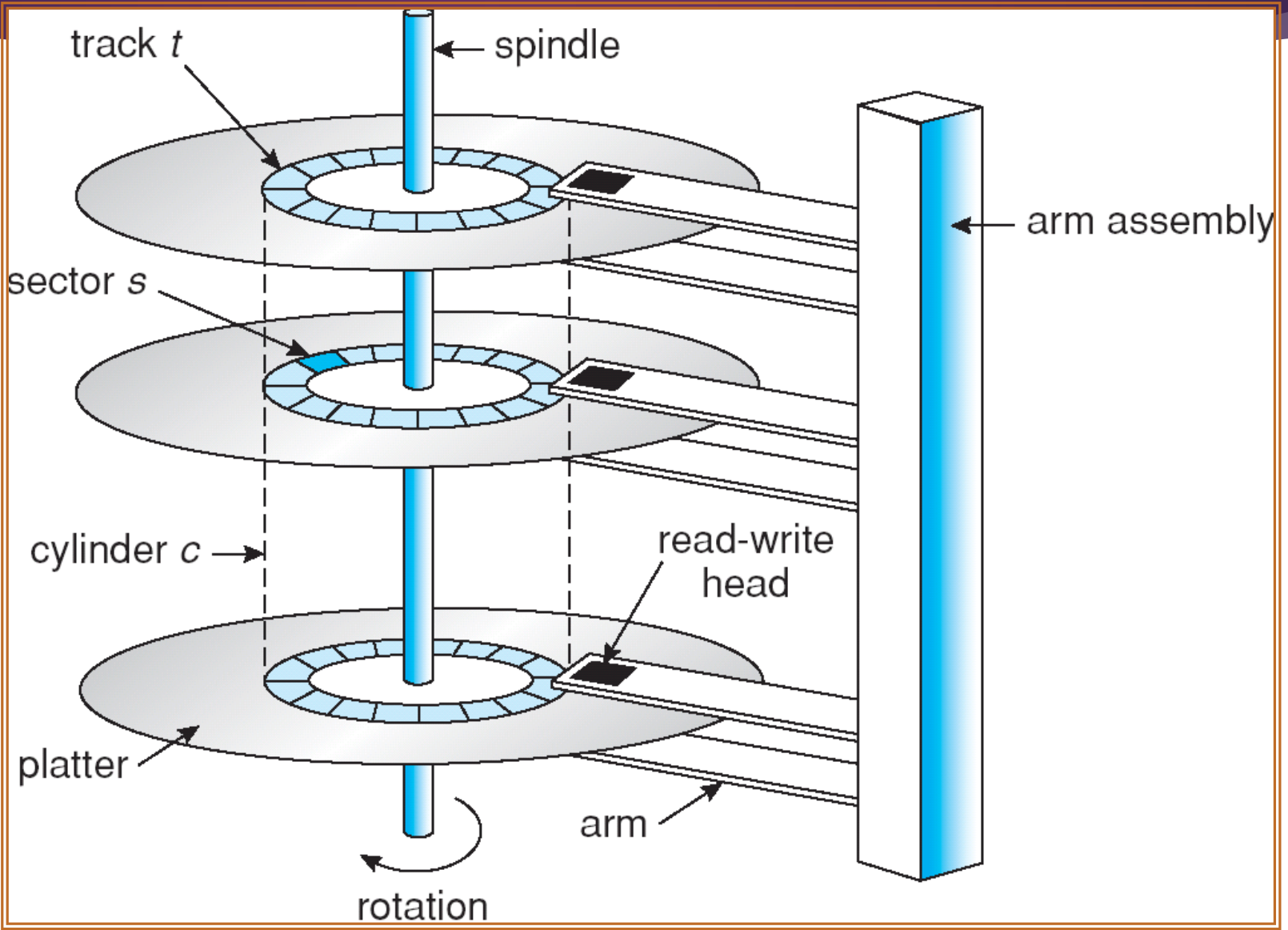
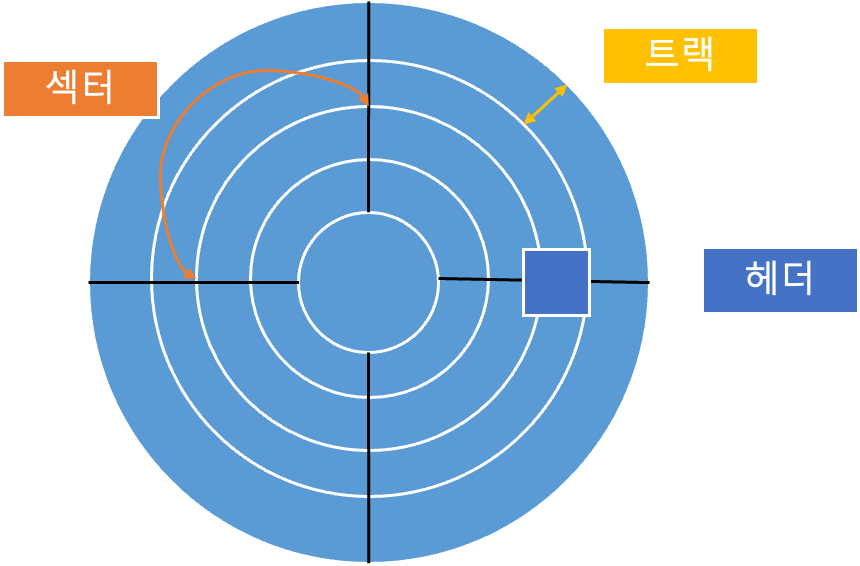
원을 따라 데이터 들이 쫙 써져 있다.
헤더가 존재하는데 헤더는 트랙의 안쪽과 바깥쪽을 왔다갔다 하며 데이터를 읽을 수 있다.
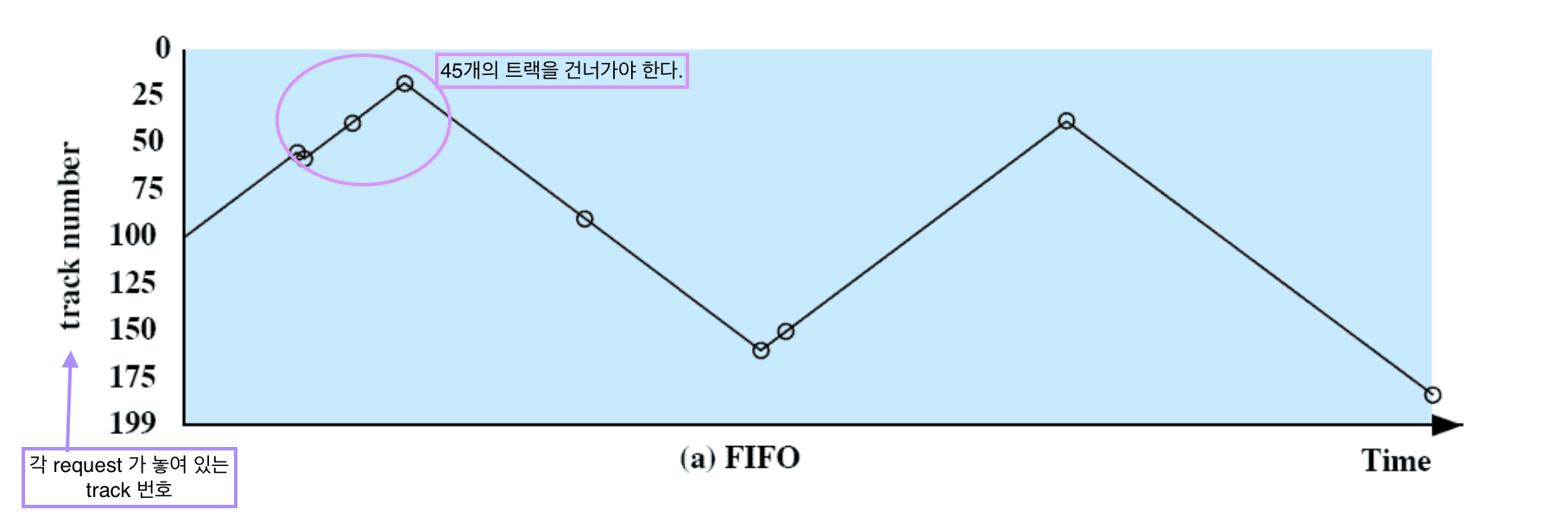
Disk Scheduling Policies
To compare various schemes, consider a disk head is initially located at track 100.
assume a disk with 200 tracks and that the disk request queue has random requests in it.
200개의 트랙이 있는 하드디스크가 있고 disk request queue 에서 무작위로 트랙 요청을 한다.
The requested tracks, in the order received by the disk scheduler, are
request 도착 → 55, 58, 39, 18, 90, 160, 150, 38, 184.
track 번호에 request 도착
First-in, first-out (FIFO)
Queue 에 들어온 순서대로 처리한다. ⇒ 성능이 최악이다.
- Process request sequentially
- Fair to all processes (가장 큰 장점)
- Approaches random scheduling in performance if there are many processes
Shortest Service Time First
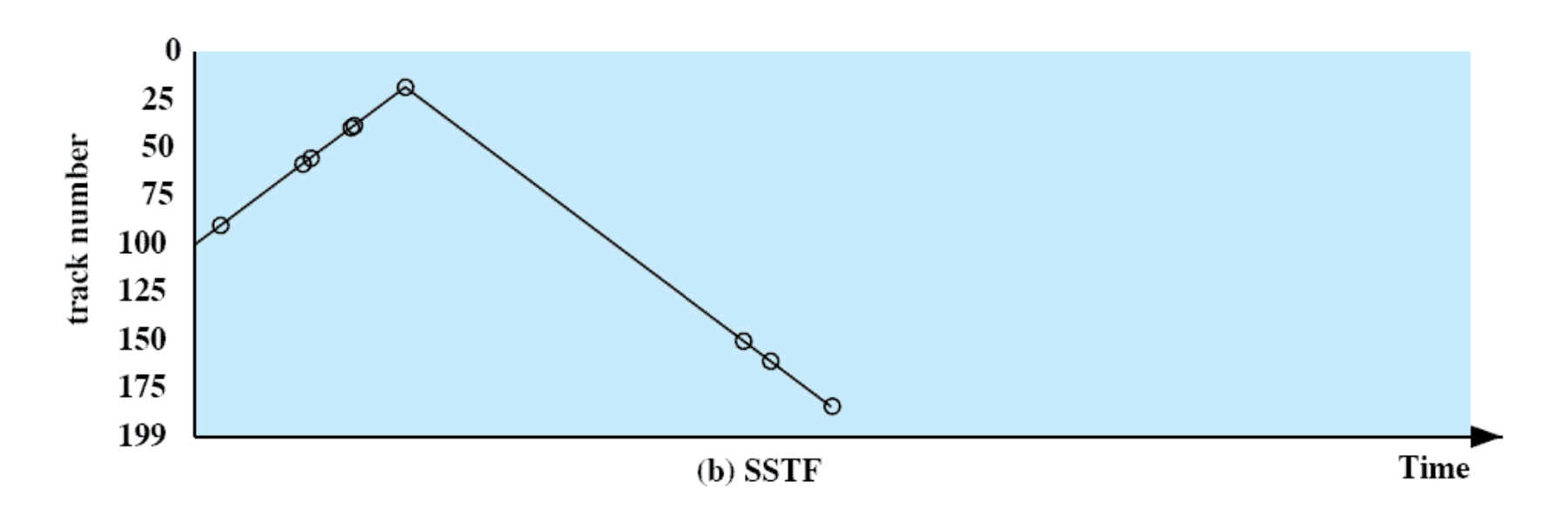
현재 head 위치에서 가장 가까운 거 부터 실행
- Select the disk I/O request that requires the least movement of the disk arm from its current position
- Always choose the minimum seek time
SSTF 는 성능적으로 가장 Optimal 하면 Starvation 발생가능성이 매우 높다 .
SCAN
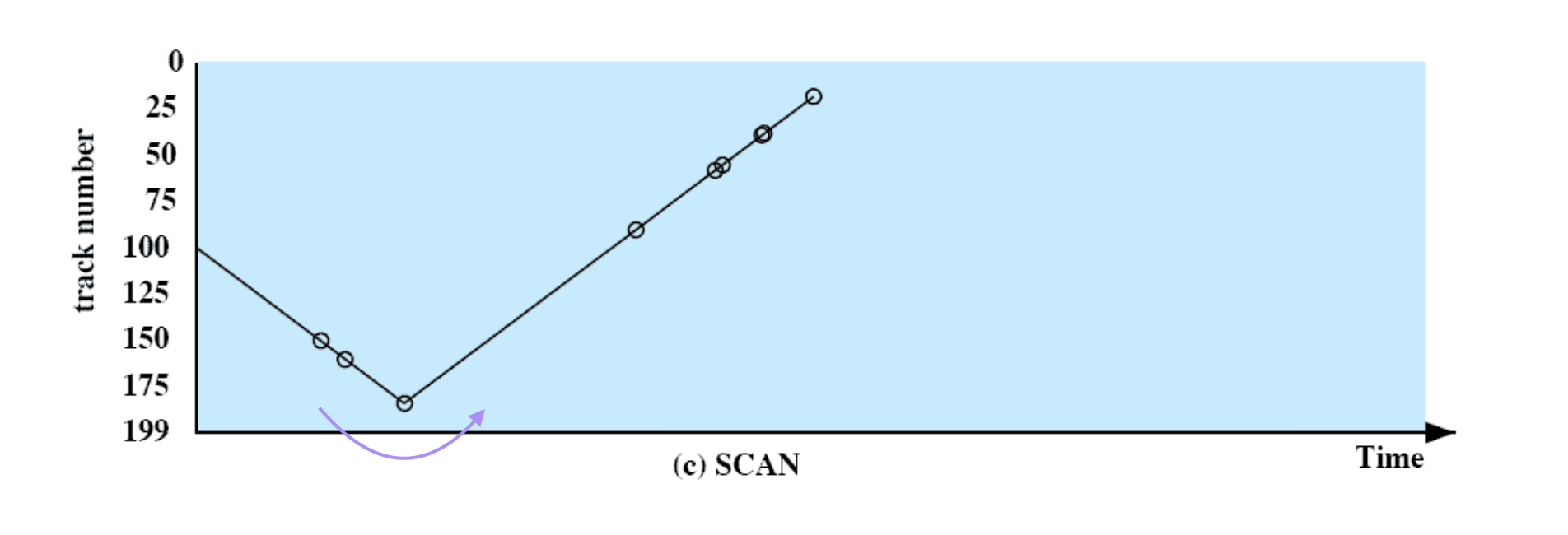
일단 한쪽 방향으로 끝까지 돌고 그 뒤, 다른 방향으로 돈다.
FIFO 보다 처리시간이 짧고 SSTF 보다는 길다. 그러나 Starvation 가능성이 매우 적다. → 거의 없다고 봐도 된다.
SCAN 의 문제점
- Starvation 이 완전히 없진 않다.
- Request
↳ 이 트랙의 여러 섹터들은 request 가 매우 많다. 어떤 섹터에 트랙이 너무 몰려 있으면 다른 섹터에 있는 request 들은 처리가 늦어지게 된다.
C-SCAN
Hard-Disk 접근 시, Starvation 이 발생하면 안된다.
예측가능성
내가 하드디스크에 어떤 request 를 보냈는데 다시 작업을 시작할 때까지 얼마나 시간이 걸릴까?
얼마나 시간이 걸릴지도 중요하지만,
track 중 어느 트랙이건 공정하게 예측 가능성이 같아야 하는데 SCAN 기법은 예측가능성이 track 에 따라 다르다.
- 안쪽 → 빠름
- 바깥쪽 → 느림
편차가 싫어서 C-SCAN 을 사용하는건데 성능이 더 좋지는 않다.
- Restricts scanning to one direction only
- When the last track has been visited in one direction, the arm is returned to the opposite end of the disk and the scan begins again

N-step-SCAN
- Segments the disk request queue into subqueues of length N
- Subqueues are processed one at a time, using SCAN
- New requests added to other queue when queue is processed
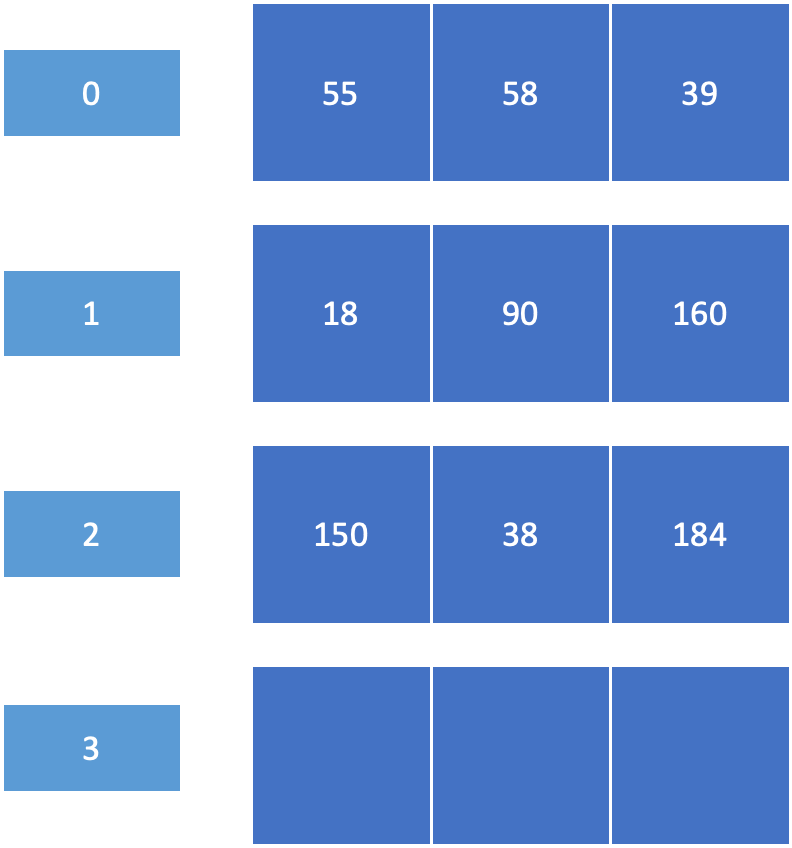
큐를 크기 N 인 서브 큐로 만든다. N개의 큐가 아니라 크기가 N 인 서브 큐로!
크기가 3인 서브큐를 두면, 특정 트랙에 request 가 들어와도 새로운 큐로 밑에 들어가 처리 속도가 느려지지 않는다.
⇒ N개씩 나눈다.
⇒ Starvation 가능성이 존재한다. → 큐가 몇개인지 알 수가 없다.
⇒ 따라서 request 가 굉장히 많아지면 큐가 굉장히 많아지게 된다.
N = 1 → FIFO 를 사용한다.
⇒ N 값에 따라 이 방법이 잘 작동되게 해준다.
⇒ SCAN, FIFO, ...
FSCAN
- Two subqueues
- When a scan begins, all of the requests are in one of
the queues, with the other empty. - All new requests are put into the other queue.
- Service of new requests is deferred until all of the old requests have been processed.
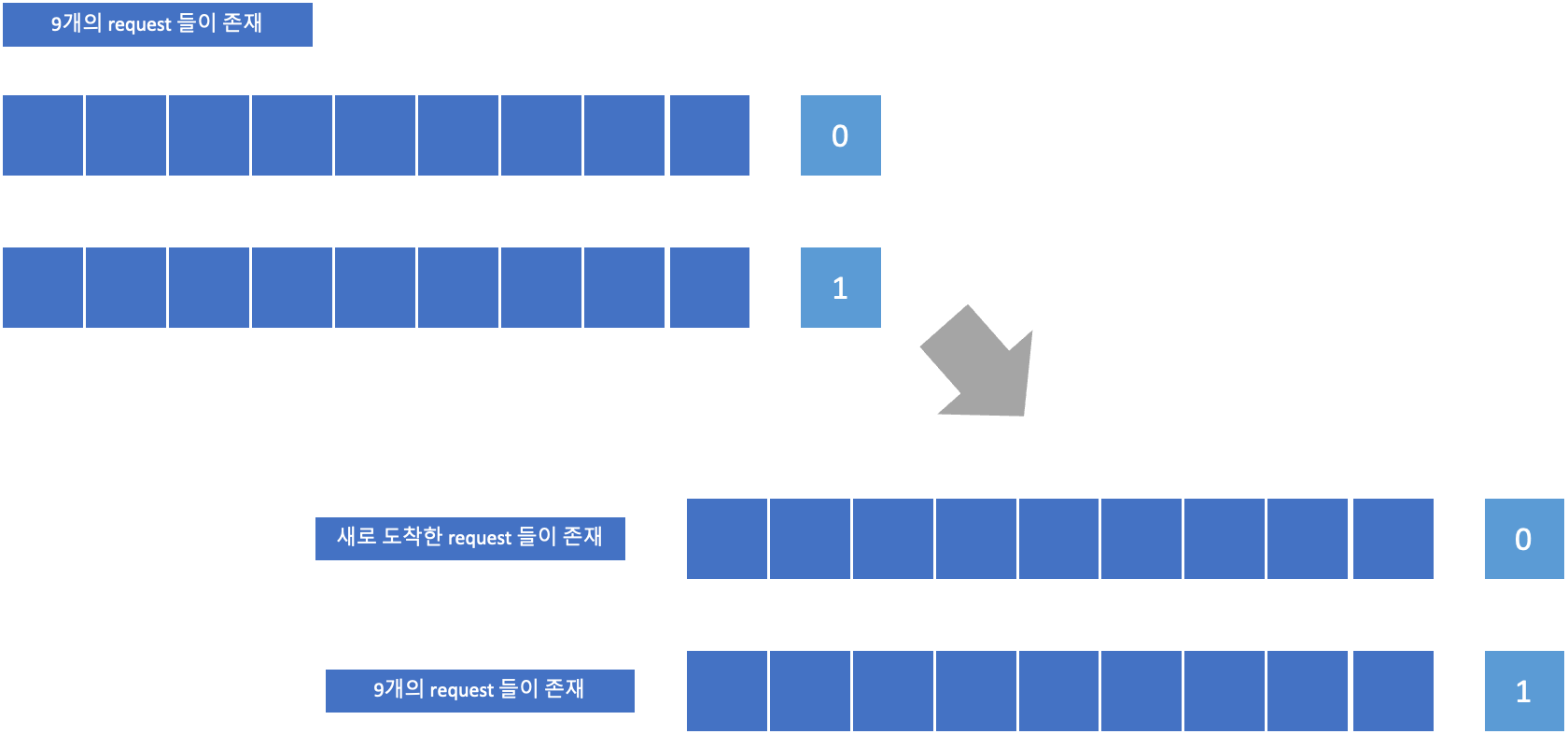
- 두개의 큐만 사용한다.
- Starvation 이 없다.
- SCAN 과 가깝다.
10시 이후에 도착하는 애들은 반대쪽에 쌓이게 된다. 나는 10시 이후에 도착하는 저 request 를 처리하며 지나갈 필요가 없다. 10시 전에 온 request 만 처리한다. 끝까지 다 가서 10시 30분이되면 방향을 바꿔서 올 때는 10시에서 10시 30분에 도착한 request 만 처리한다. 매번 내가 SCAN 으로 한쪽 방향으로 끝까지 갈때는 전 타임동안 도착한 requst 만 처리하면 된다. 새로운 request 가 와도 걔네들은 다른 큐에 쌓이는 것이기 때문에 어느 한 트랙에서 계속 해서 서비스를 하는 상황은 발생하지 않게 된다. Starvtaion 은 존재하지 않는다.
큐가 두개밖에 없지만, 큐의 길이가 다르다고 성능이 달라지진 않는다. 거의 SCAN 과 가까운 그러나 Starvation 은 없는 방식이다.
