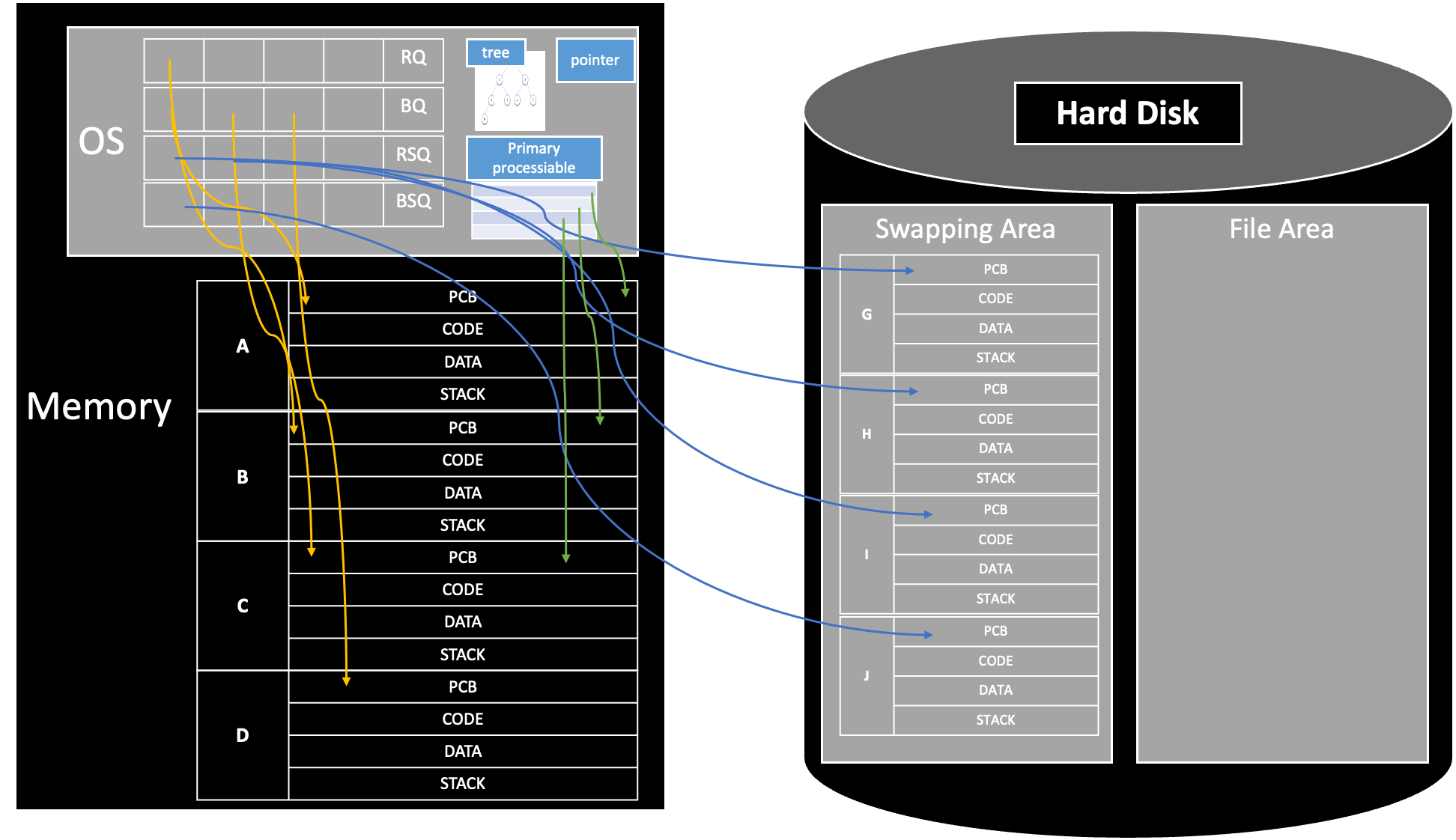
- OS 또한 Program이기에 Memory의 공간을 차지한다.
- tree가 pointer와 연결되어 있다.
- Primary Processiable 또한 OS에서 관리한다.
- Swapping Area에는 하드디스크일지라도 File Area에 들어 있는 실행 파일과 다르게 Code + Data + PCB + Stack이 모두 포함된 Process 상태로 저장되어 있다.
Process Description
OS가 Process를 어떻게 관리하는지가 중요하다.
Operating System Control Structure
1. 각각의 Process와 여러가지 Resource의 Current Status에 대한 정보를 관리한다.
2. OS는 System 내부자원관리를 위해 다음의 네가지 테이블을 만들어서 관리한다.
- Memory Table
- I/O Table
- File Table
- Process Table
당연히 OS가 프로그램이니까, 시스템 안에 있는 자원들을 관리하기 위해서 테이블 형태의 구조체 배열을 만들어서 관리를 한다.
(마치 우리가 프로그램을 작성할 때 입력 받은 데이터를 관리하기 위해서는 구조체 배열이 필요하듯이!)
전체적인 네가지 테이블들의 모양
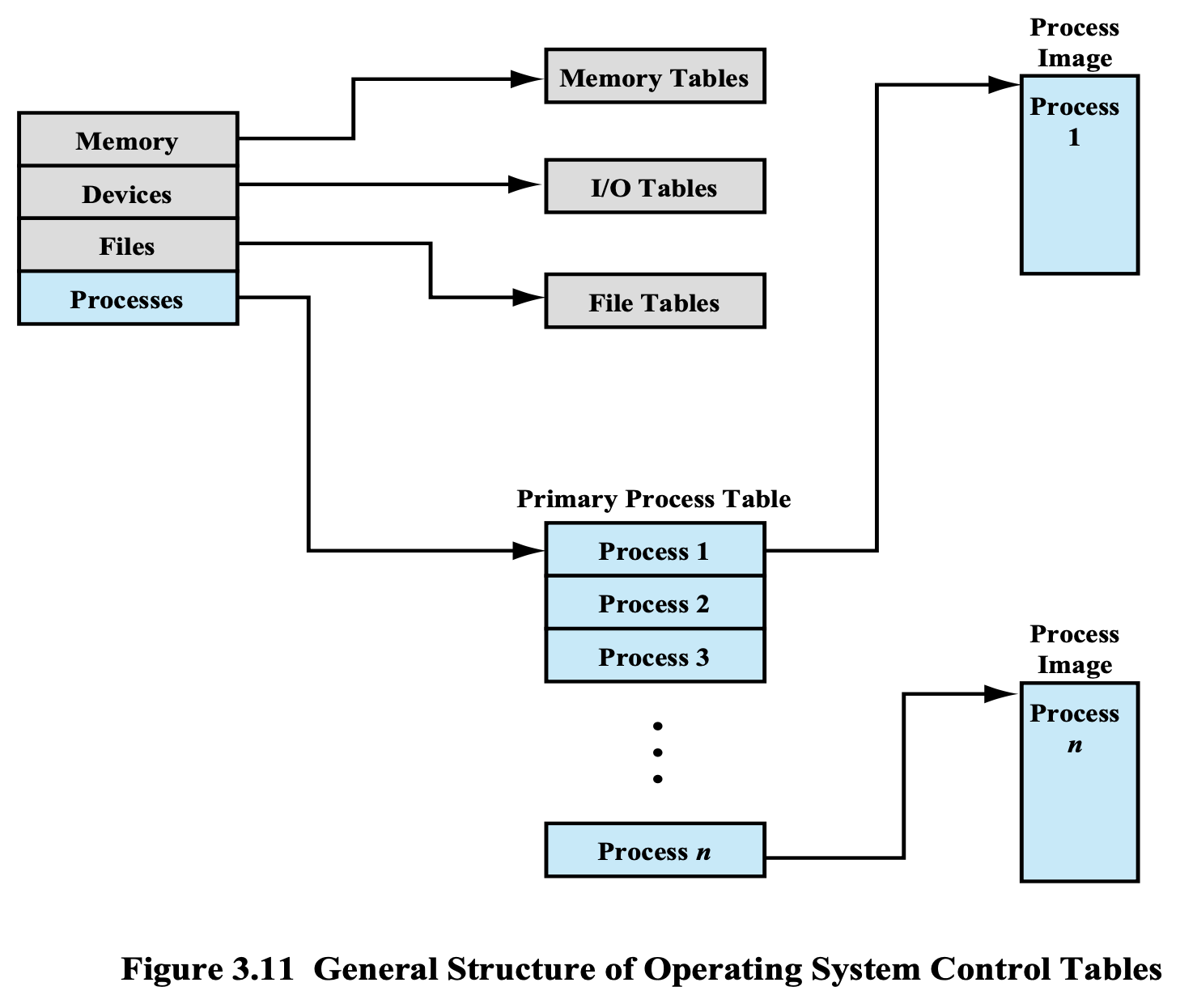
Memory Tables
1. Allocation of main memory to processes
Memory의 x번지 ~ y번지가 어떤 Process에게 할당되어 있는지 적혀 있다.
2. Secondary memory(Hard Disk)
-
Hard Disk의 x번지 ~ y번지가 어느 프로세스에 할당되어 있는지 정보가 적혀 있다.
-
실행파일은 File Table에서 다루고 Memory Table에서 다루는 것은 Process, Swapping Area이다.
⇒ 즉, Memory Table은 Swapping 이 이루어졌을 때 몇 번지~ 몇번지까지에 저장되어 있는지에 대한 정보를 관리한다.
메모리 관리는 진짜 메모리(Main Memory)와 하드 디스크의 Swapping Area 까지 포함한다.
3. Protection attributes for access to shared memory regions
시스템 안에는 Shared Memory Region 이 존재한다.
실제로는 몇개의 프로세스들이 데이터를 Share할 수 있다.
메모리 안에 있는 한 페이지가 여러 프로세스가 access할 수 있는 Shared Region일 수 있다.
→ 이 경우, 이 페이지에 접근할 수 있는 프로세스는 누구누구누구이고,
누구는 읽기도 할 수 있고 누구는 쓰기만 할 수 있고 이러한 정보들을 관리해야 한다.
당연히 이 Shared Region에는 Data 만 Share하는 것이 아니라,
Code 도 Share할 수 있다.
4. Information needed to manage virtual memory
Virtual meomry 관리에 필요한 여러가지 정보들이 담겨 있다.
I/O Tables
시스템 안에 있는 모든 I/O Devices들이 이 테이블에 올라가 있다.
I/O device if available or assigned
누가 있느냐, 누가 사용중이냐가 이 테이블에 올라와 있다.
Status of I/O operation
사용중인 경우, 누가 사용하고 있는지, 어디까지 사용했는지, ... Status 정보들이 들어 있다.
Location in main memory being used as the source or destination of the I/O transfer
출력
모든 I/O 작업은 메인 메모리 몇번지에 있는 데이터를 내가 출력할 때,
일단 I/O module 안에 있는 버퍼 몇 번지로 옮기고 그 다음에 출력한다.
데이터 출력:
Memory→I/O buffer→I/O module
입력
입력을 받을 때 입력 데이터를 I/O 모듈 몇번지로 옮긴 다음에 그거를 메모리로 옮긴다.
데이터 입력:
I/O module→I/O buffer→Memory
모든 I/O 작업은 메모리와 I/O Module안에 있는 I/O buffer 사이에서 왔다갔다 해야하기 때문에
→ 주소가 적혀있다.
ex) 어디에 있는 데이터를 어디로 옮긴다. File Tables
모든 파일들이 File Table 안에 들어 있다.
Existence of files
데이터 파일, 실행 파일, ... OS는 파일 유형을 구분하지 않는다.
⇒ 모든 파일들이 File Table 안에 들어 있다.
Location on Secondary memory(HDD)
당연히, Secondary Memory 안에 있으니까 하드디스크 몇번지에 있는지 정보를 가지고 있어야 한다.
Current Status
OPEN 가능 → 읽기, 쓰기
다음 번에 어느 위치를 읽을 것인지, 어느 위치에 쓸 차례인지
File Pointer를 관리해 주어야 한다.
Attributes
파일 크기, 누가 만든 파일인지와 같은 정보들을 관리해주어야 한다.
Primary Process Table
Attribute necessary for process management
지금 시스템 안에서 실행하고 있는 모든 프로세스가 전부 하나씩 Entry 로 들어가 있고,
실제 Process는 오른쪽에 Process Image 로 존재한다.
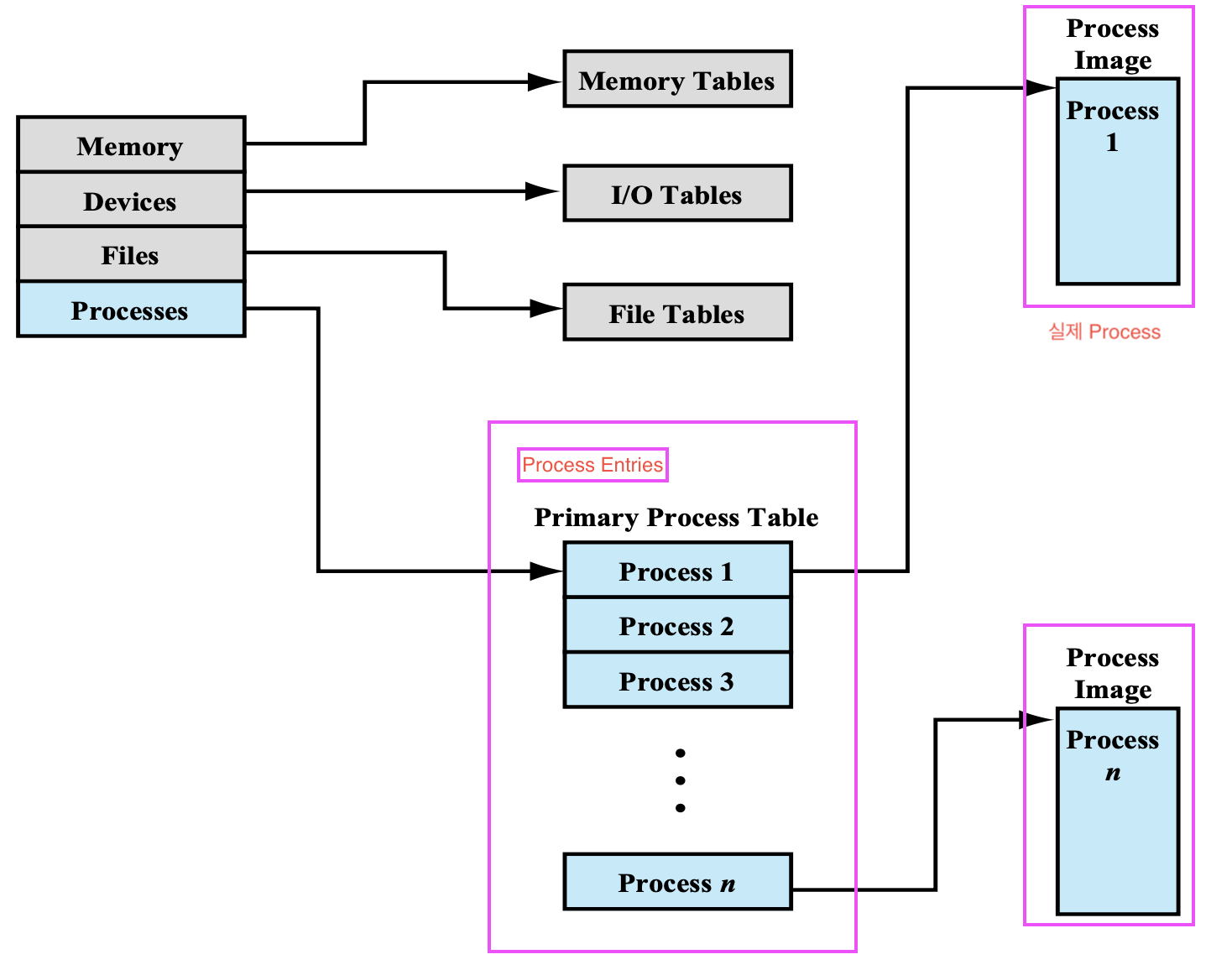
- 전체 프로세스 정보는 Process Image에 존재한다.
- Process Image는 Pointer를 통해서 접근한다.
- 프로세스 ID, ... 몇가지 정보들이 Primary Process Table에 존재한다.
Primary Process Table에 들어 있는 대표적인 정보
- ID
- Process Image에 대한 Pointer
- Process가 메모리 어디에 있는지 위치 정보
Q. Process "Image" 라는 용어를 사용하는 이유?
밑에 모든 것을 포함한 것을 Process Image라고 부른다.
하나의 Process는 Memory에 다 들어갈 수 없기 때문에,
Process의 일부만 들어가게 되는데, OS가 전체 Process가 Memory에 들어가 관리를 하는 것처럼 상상하여 사용하기 때문에 Process "Image" 라는 용어를 사용한다.
User Data
프로세스는 프로그램 코드와 데이터(User Data)로 이루어져 있는데,
여기서 User Data는 전역 변수, Static 변수 프로그램이 시작해서 끝날때까지 계속 존재하는 변수이다.
이 변수들은 Compile이 되어 Binary Code가 생성될 때,
공간이 같이 만들어지는 변수들이다.
User Program
실행해야 하는 프로그램
Stack
프로그램이 컴파일이 되어서 바이너리 코드로 만들어질 때,
전역 변수나 Static 변수를 저장하는 공간은 같이 만들어지지만,
Local 변수를 저장하는 공간은 해당하는 함수가 호출될 때 생성된다.
Q. 미리 만들어 놓지 않고, 그때 그때 호출할 때 만드는 이유?
→ 내가 모든 함수를 다 동시에 사용하지 않는데,
모든 함수에서 사용할 변수의 공간을 미리 만들어 둔다면,
프로그램의 크기가 너무 커질 것이다.
실제로 함수는 한 번에 하나씩 호출이 된다.
→ 그래서 호출 됐을 때 필요한 딱 최소한의 공간만 만들어야 한다.
그러기 위해서 Stack 을 사용한다.
당연히 Stack 에는 함수 호출이 끝나고 Return 할 주소가 함께 들어있다.
Process Control Block
OS가 프로세스들을 관리하는데 필요한 모든 정보들이 들어 있다.
PCB에 저장되는 정보
1. Process Identification
(1) Process Identifier (Process ID)
OS가 Process를 만들 때 ID부터 생성한다.
시스템 안에서 Process끼리 ID가 겹치면 안된다.
⇒ Process는 유효한 ID를 부여 받게 된다.
(2) Parent Process Identifier
우리가 프로그램을 실행
↳ 시스템 입장 → A Process 실행
→ OS에게 B Process 실행해달라고 요청 → B Process 실행
A: Parent Process
B: Chid Process
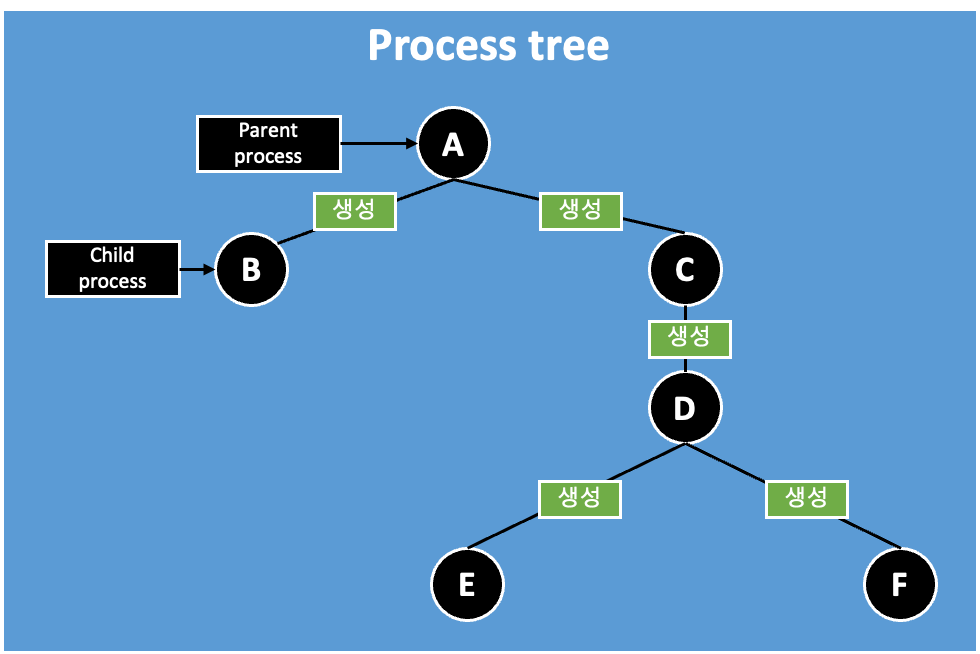
Q. Tree 형태로 Process를 관리하는 이유?
→ A Process는 B Process를 만들고 끝나는게 아니라,
B Process가 제대로 종료되었는지 확인하고 OS에게 보고할 의무가 있다.
⇒ 즉, Parent Process ID가 PCB안에 저장되어 있어야 한다.
(3) User Identifier
여러사람이 같이 사용하는 Process의 경우에는 각 프로세스가 어느 User의 Process인지 구분해주어야 한다.
ex) 예를 들면, 학사정보시스템 로그인 → 학생 User ID로 프로세스가 진행된다.⇒ 어느 User의 프로세스인지 User ID가 표시가 되어야 한다.
2. Processor State Information
여기서의 Information : Program Interrupt시, Control Stack에 저장하는 정보
프로그램이 실행을 하다가 인터럽트가 걸려 중단이 될 때,
자신의 현재 상태를 Control Stack에Save&Restore한다.
그 때,Control Stack에Save한 정보들 = Processor State Information
Q.Control Stack에 있는 정보를 Copy해서 PCB 안에 저장을 해두는 건가요?
→ CPU 안에 Register가 100개쯤 있다고 가정했을 때,
Register 값을 다 저장하면 100개의 정수값을 다 저장해야 한다.
그거를 Control Stack에 다 저장하고, Copy해서 여기에도 저장하고
이렇게 Copy를 반복할 이유가 없다.
⇒ 즉, Control Stack에 PCB Pointer를 저장하는 것이다.
PCB에는Save&Restore할 정보값이 들어 있다.
- 정보는 Control Stack 한군데에 Pointer로 저장되어 있다.
- Control Stack은 MainMemory(RAM)에 위치한다.
(1) User-Visible Registers
(2) Control & Status Registers
- PC (Program Counter)
- PSW (Program Status Word)
(3) Stack Pointers
3. Process Control Information
OS에게 가장 중요한 정보로,
OS가 프로그램을 실행시키면서 필요한 모든 관리 정보들을 Process Control Information 안에 넣어놨다.
Scheduling and State information
Scheduling Information
스케쥴링 정보: 프로세스의 우선순위, 우선순위를 계산하는데 필요한 여러가지 정보들
Time Sharing System : Process들을 번갈아 가면서 작업하는 것이다.
Ready Queue 는 먼저 들어간 프로세스가 먼저 나오는 큐라고 상상할 수 있지만,
실제로는 이렇게 간단하게 스케쥴링 하지 않고, 훨씬 더 복잡하게 스케쥴링을 진행한다.
- 프로세스마다 우선순위가 존재한다.
- 우선순위가 계산되는 방식이 시스템마다 다르다.
State Information
프로세스는 계속 상태가 바뀌는데, 현재 프로세스의 상태가 어떤 상태인지 나타내는 정보
Memory management
프로세스가 메모리의 어디서부터 어디까지 사용하고 있는지,
그러한 정보들이 들어있다.
Resource ownership and Utilization
Resource ownership
이 프로세스가 만든, 소유하고 있는 리소스들을 말한다.
프로세스가 리소스를 만드는 방법: Concurency Control(여러 프로세스들을 동시에 실행시킬 때 충돌을 막기 위해 시스템 안에서 세마포를 만들어서 활용한다. )
프로세스가 자기필요에 따라서 OS 영역에 세마포라고 하는 Resource를 만든다.
→ 누가 만든 세마포냐? = Ownership
ex) 다른 프로세스랑 통신을 하고 싶을 때, 통신용 메시지 Queue를 만들 수 있다.
이 메시지 큐도 당연히 OS 공간에 만든다.
A큐가 B, C, D 큐랑 통신하고 싶어 통신용 메시지 큐를 만들었을 때,
B, C, D도 이 큐를 이용할 수 있지만 주인은 A이다.
Utilization
Resource를 내가 어떻게 얼마나 사용했나를 전부 기록하여
OS가 모든 자원이 골고루 사용할 수 있도록 자원을 관리할 수 있게 해준다.
Resource 기록 → OS → 자원 공평하게 관리
Inter-process communication
메시지 큐뿐만 아니라 여러가지 파이프들을 만들어서 communication을 도와주는데,
실제로 communication은 OS가 한다.
A가 B에게 메시지를 보내고 싶을 때,
다이렉트로 A가 B에게 메시지를 보낼 수 있는 방법은 없다.
OS가 A의 메시지를 Copy하고 다시 B에게 메시지를 Copy해 주어야 한다.
(A Message → OS → B Message)
Process privileges
프로세스가 가진 여러가지 권한들
권한은 OS가 관리한다.
ex) 읽기, 쓰기, ...
Data Structuring
모든 프로세스는 굉장히 많은 Pointer를 관리해야 한다.
전체적인 프로세스 이미지
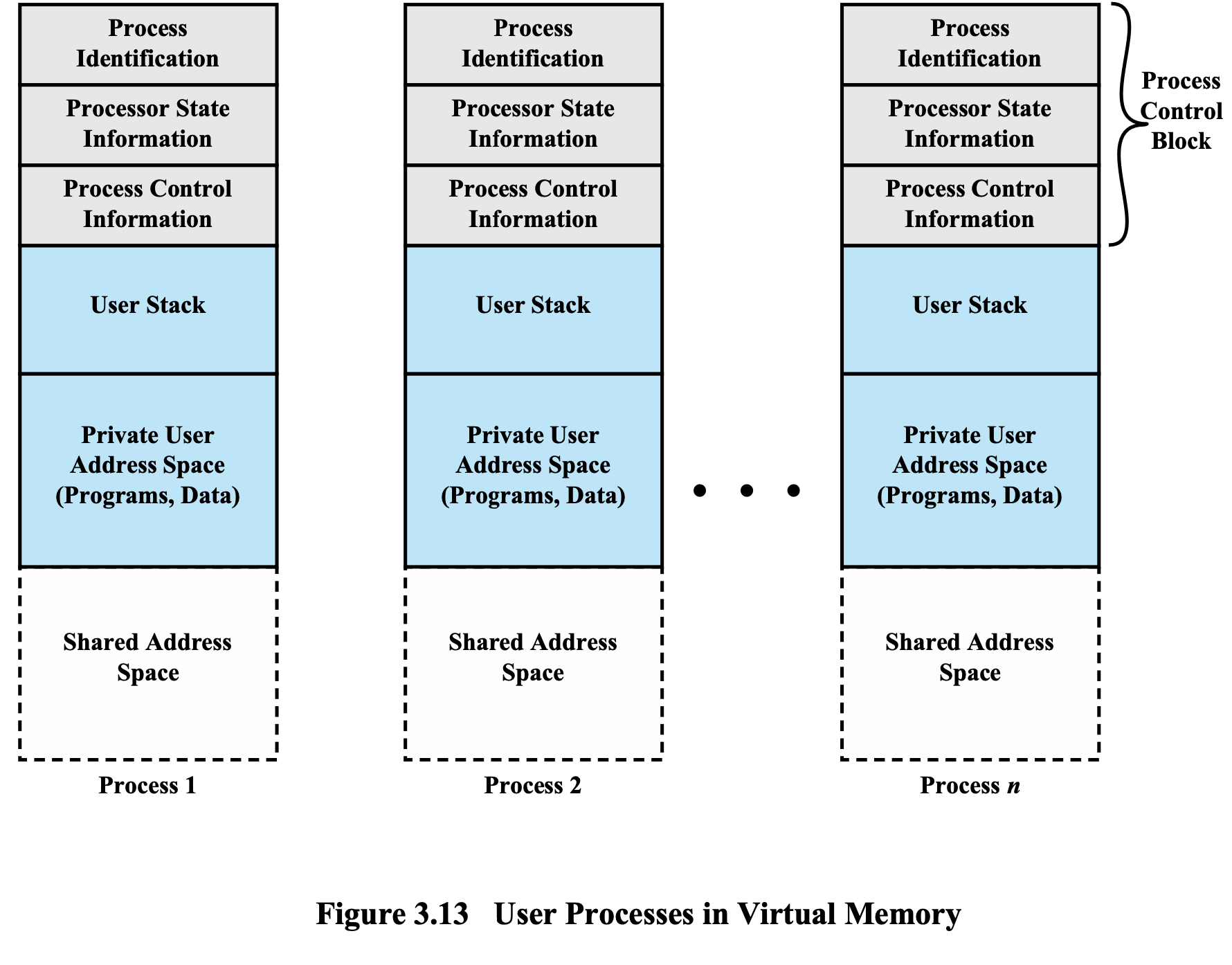
Private User Address Space
(= Programs + Data)
-
프로세스 본인만 사용하는 공간이다.
-
프로그램이 compile되어 binary code가 될 때 이 코드가 메모리의 몇번지부터 몇번지인지가 붙어서
User Address Space라는 이름이 붙게 된다.
Shared Address Space
다른 사람과 함께 사용하는 공간이다.
Process와 Process는 서로 data와 code를 공유할 수 있다.
OS가 해야하는 일들(Kernel)
OS는 프로그램이기 때문에 OS가 관리하는 모든 것은 구조체 형태를 가져야 한다.
1. Process Manegement
-
Process creation and termination
프로세스 생성, 프로세스 종료 후 없애는 과정도 함께 관리된다. -
Process scheduling and dispatching
실제로 CPU가 프로세스를 실행시킬 때는, 어떤 프로세스를 얼만큼 실행시킬지 계산한다.(dispatching) -
Process switching
프로세스가 바뀌는 상황
A → OS → B -
Process synchronization and support for interprocess communication
프로세스들이 혼자 작업하지 않고 관련된 프로세스들과 함께 작업을 진행한다.
⇒ 프로세스 동기화: 순서를 정하여 순차적으로 작업하는 것이 필요하다.
또한 OS가 중간에서 communication을 도와주어야 한다. -
Management of process control blocks (PCB)
2. Memory Management
-
Allocation of address space to processes
할당 관리 -
Swapping
-
Page and segment management
프로세스 → 메모리 자르는 단위 관리
3. I/O Management
-
Buffer management
-
Allocation of I/O channels and devices to processes
프로세스들이 서로 사용하려고 할 때 누구에게 줄 지 결정하는 역할을 한다.
4. Support Functions
- Interrupt handling
OS가 해야하는 작업들 중 가장 중요하다.
애플리케이션들은 OS의 도움을 받아야한다. 혼자서는 실행 X
OS가 끼어드는 상황은 딱 두가지이다.
- 끼어들어달라고 요청(System call)
- Interrupt
-
Accounting
시스템 안에 있는 모든 프로세스가 자원을 어떻게 얼마나 사용하는지 기록 -
Monitoring
시스템 전체 상황 모니터링하며, 문제가 생기면 해결한다.
Process Creation (중요)
Process를 만드는 작업
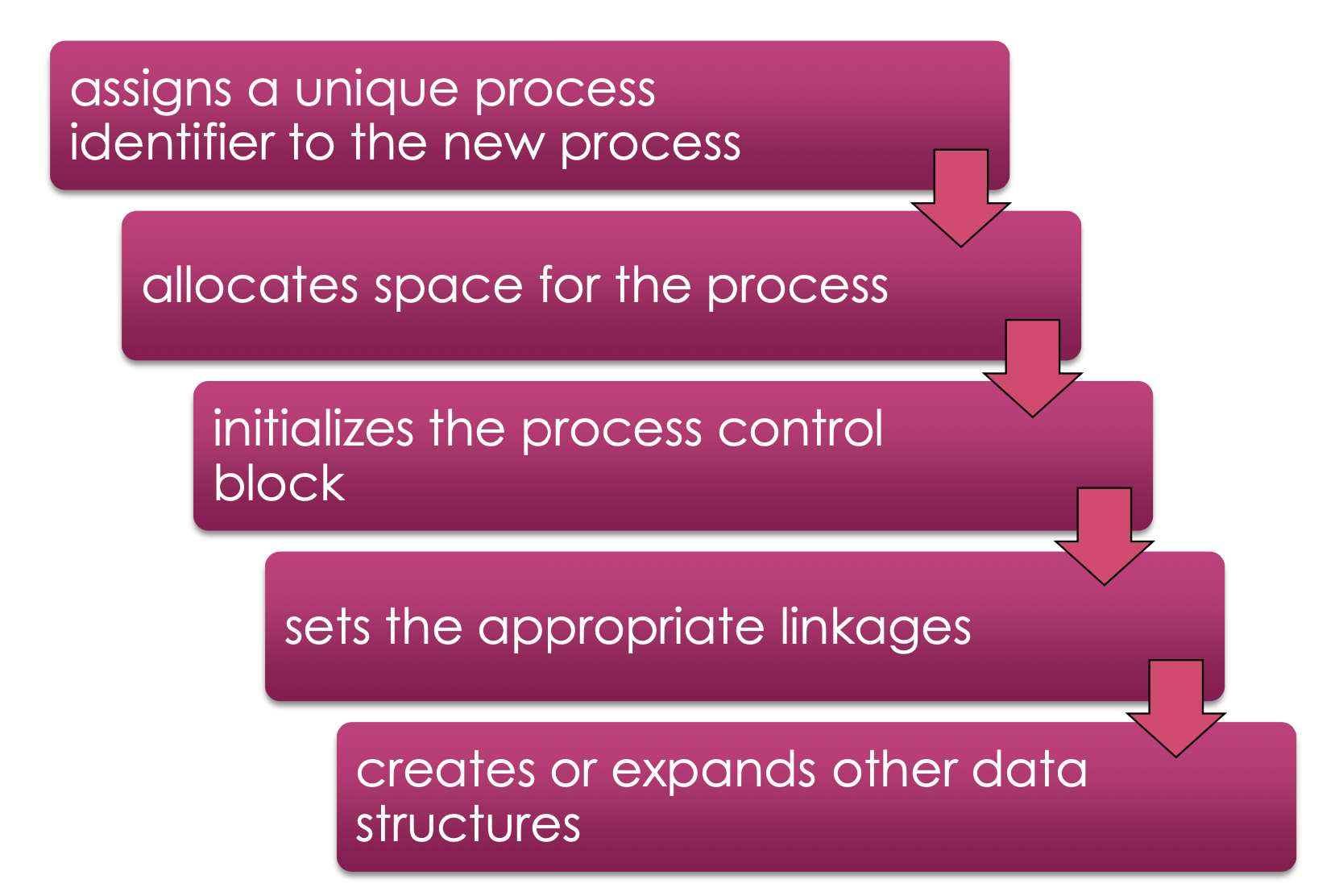
1. Assigns a unique process identifier to the new process
새로운 Process에게 제일 먼저 Identifier를 부여한다.
2. Allocates space for the process
Process를 실행하려면, 메모리 공간을 할당해주어야 한다.
3. Initializes the Process Control Block
(PCB)
PCB를 만들어 준다.
프로세스가 가지고 있는 네가지 정보 중에서 프로그램 코드와 데이터는 이 프로세스 것이다.
→ 얘네들은 그냥 파일에서 읽어서 채우면 된다.
그런데, 스택은 실행을 하면서 채워가는 공간이다.
프로세스가 처음 만들어졌을 때 PCB를 만드는 것이 중요하다.
프로세스는 갑자기 등장하지 않는다.
부모 프로세스의 PCB를 복사하여 자식 프로세스를 만들고, 이를 업데이트 하는 방법을 사용한다.
4. Sets the appropriate linkages
새로 만들어진 프로세스는 프로세스 테이블 어딘가에 존재하고,
어느 큐에 들어가게 된다.
여기 저기 구조체에 들어가며 링크를 계속 수정(update)해야 한다.
새로 만들어진 프로세스를 적절히 여러 Queue , Tree , Table 에 넣고
→ 링크설정을 다 한다.
5. creates or expands ohter data structures
- 이 프로세스에게 필요한 초기 자원들이 있으면 자원들을 할당해 준다.
- 관련된 Data Structure들을 만들어준다.
Process Switching
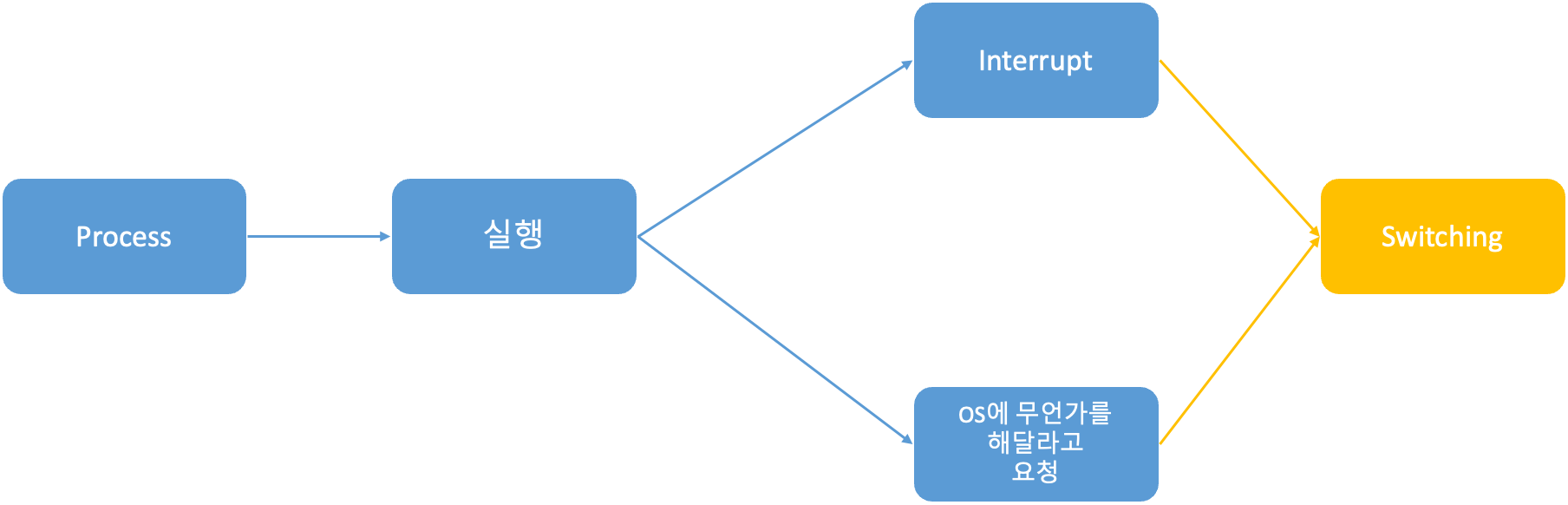
Switching : 실행 중이던 프로세스 일단 중단 → OS가 다른 프로세스를 실행한다.
Process를 언제 Switch하는가?
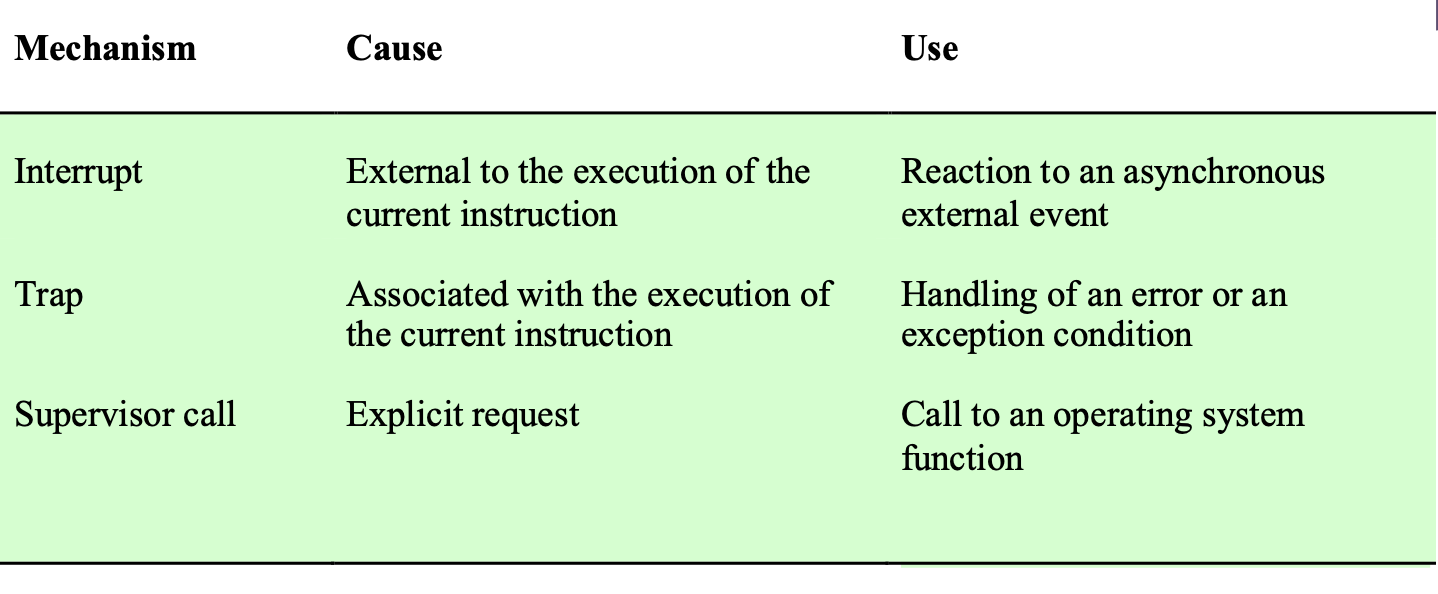
Interrupt와 Trap은 둘 다 일종의 Interrupt이다.
1. Hardware interrupt(장치에 의한 인터럽트)
2. Software interrupt(명령에 의해 발생, Trap )
대부분 Trap 은 오류상황이나 Excption Handling 을 해야하는 상황을 나타낸다.
Interrupt
1. Clock interrupt (→ ready state)
running → timeout → ready
2. I/O interrupt (→ running State / → ready state)
Process B가 I/O 요청 → B는 Blocked로 이동 → Process C 실행
→ B의 I/O 인터럽트 → Process C의 실행중단
Process C의 입장에서는 본인의 Timeout이 아닌데도 계속 중단해야 하는가?
OS가 I/O를 완료한 후,
- Ready로 이동할 수도 있고,
- Running으로 Timeout 될때까지 계속 진행할 수도 있다.
3. Memory Fault (→ blocked state)
프로그램의 페이지만 들어가서 실행해야 한다.
실행 중, 페이지의 마지막 줄의 다음줄이 필요한데 없을 경우 하드디스크에서 가져와야 한다.
이를 Memory Fault라고 한다.
일종의 인터럽트이다.
Trap (→ exit state / → running state)
오류가 발생하거나 Exception Handling이 필요해 종료해야 하는 경우
대부분의 경우 종료상태로 가지만,
오류가 난 줄 알았는데 OS가 확인했을 때 오류가 아니었을 경우 다시 running state로 돌아올 수도 있다.
Supervisor call (→ blocked state)
Supervisor call = System call
User Program이 OS에게 Service를 요청하는 것이다.
요청 이후 OS가 개입하게 되면, 실행중이던 프로세스는 중단, Block 상태가 된다.
→ I/O 라이브러리에 printf, scanf와 같은 함수를 실행시켜,
WRITE와 READ와 같은 System call을 OS에게 요청하는 것
Processor Excution Mode
여기서의 Mode 는 CPU의 실행 모드를 가르킨다.
Q. User Mode와 Kernel Mode에 대하여 설명하시오.
User Mode
- 현재 CPU가 User Program 명령을 1줄을 실행하는 모드.
- 권한에 제한이 많다.
Kernel Mode = System Mode = Control Mode
= Supervisor Mode
- 현재 CPU가 OS 프로그램 명령을 1줄 실행하는 모드.
- 권한에 제한이 적다.
Mode Switching vs.
Process Switching
Mode Swithching
User mode A → Kernel mode (OS의 개입) → User mode A
⇒ mode 변경이 존재한다.
Process Switching
= Context Switching
User mode A → Kernel mode (OS의 개입) → User mode B
⇒ mode 변경이 존재하고 Process의 변경도 존재한다.
즉, Mode Switching이 발생하더라도 Process Switching은 발생하지 않을 수 있다.
Process 상태 변화
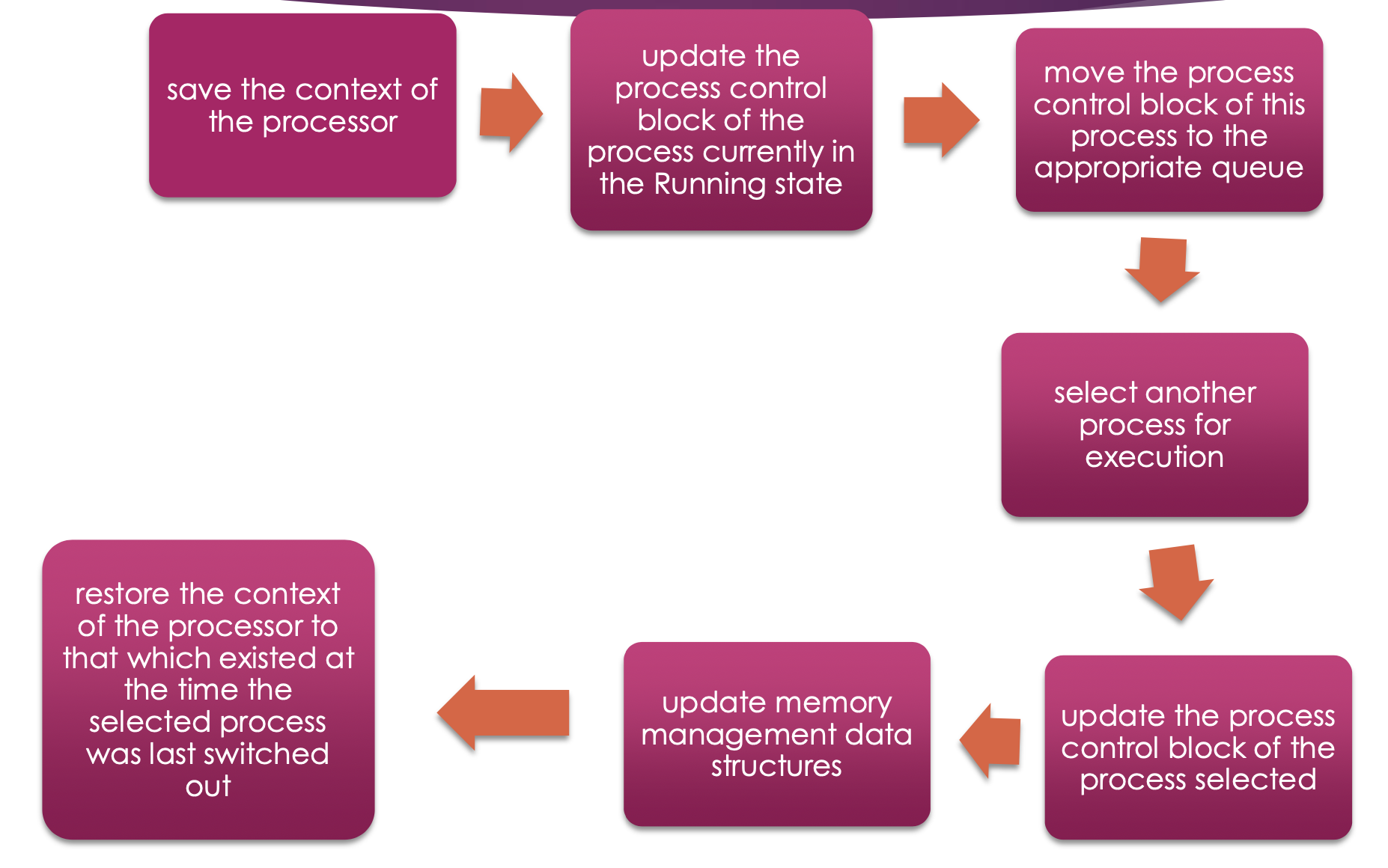
1. CPU의 상태 저장
A라고 하는 프로그램이 실행하고 있었는데 중단이 되고 OS가 끼어들어야 하니까,
지금 현재 A를 실행하고 있던 CPU의 상태를 저장해놓아야 한다.
= Processor의 Context를 Save한다.
CPU 안에 있는 Register 값들을 저장하는 것인데,
근사한 말로 Context를 저장한다고 한다.
- Register 값들 = Context
2. PCB 내용 업데이트
실행 중이던 Process의 PCB 값들을 Status, 프로세스가 access했던 자원 관련 정보들을 update 한다.
3. Process를 적절한 Queue로 이동
4. 다음에 실행할 Process 선택
5. 다음에 실행할 Process의 PCB 업데이트
(Ready 였을 것임 ← Blocked나 다른 상태에 있던 큐는 Running으로 실행시킬 수 없음)
6. 실행을 하기 위해서 필요한
Memory Data Structure Update
7. Process 상태 Restore
아까 저장해 놨었던 Context 값들 다시 CPU에 Restore
마지막에 PC Restore ⇒ 프로그램 시작
OS의 실행
I/O Interrupt
↳ I/O 인터럽트는 내가 I/O를 요청한 것이 아니다.
I/O 인터럽트가 끝나면
인터럽트 전에 실행중이던 프로세스가 OS의 계산에 의하여 Running이 유지될 수도, Ready로 이동할 수도 있다.
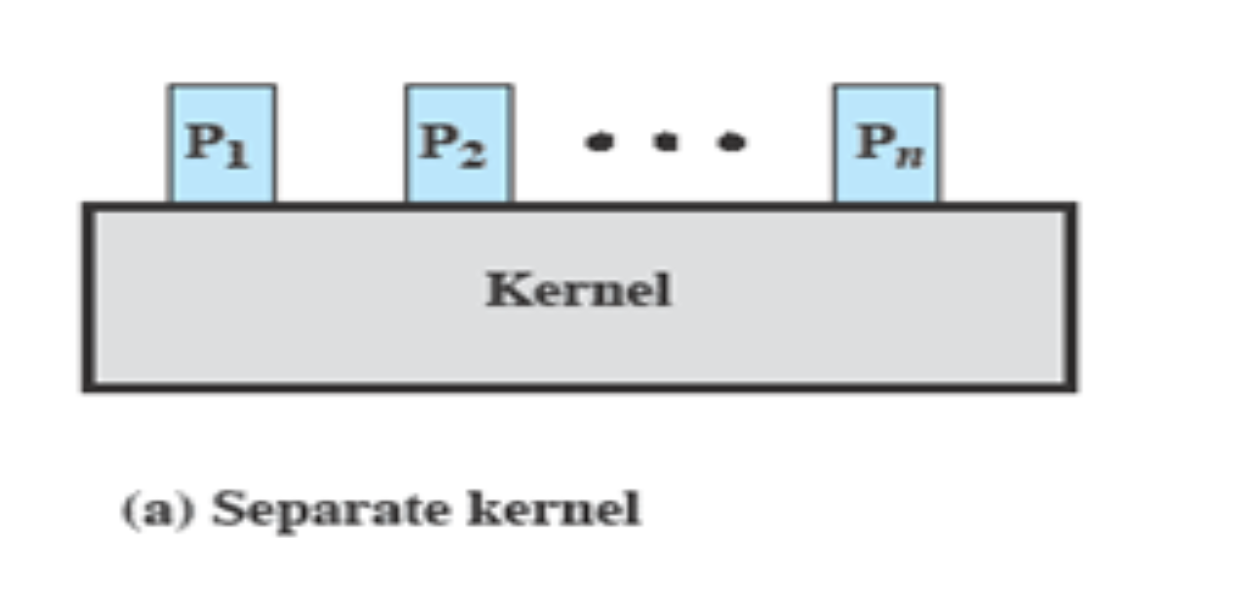
Non-process Kernel
- OS는 프로세스가 아니다.
- 프로세스가 아니므로 프로세스 이미지로 관리되지 않는다.
- 스케쥴링도 다른 방식으로, 메모리 관리도 다른 프로세스들과 다른 방식으로 관리한다.
→ 별도로 관리
⇒
Kernel은 프로세스 바깥에서 모든 권한을 갖는 개체이다.
↳ 요즘 잘 사용하지 않는다.
초기에 OS의 크기가 작아 Kernel = OS 일 때, 사용하던 방식이다.
Execution Within User Processes
⇒ User Program 안에서 OS를 실행시키는 방식
User Program이 실행
→ 인터럽트가 걸리거나 Supervisor call이 들어왔으면
→ OS를 실행한다.
↳ 이때, OS가 별도의 프로그램으로 만들어서 실행하는 것이 아니라,
User Process 안에서 실행하는 것
Q. 프로세스 안에서 실행한다?
⇒ 프로세스의 실행이 무엇이냐?
프로세스가 실행할 때, 프로그램의 코드와 데이터(전역 변수, static 변수의 개수, 공간의 변화)는 변화가 없다.
⇒ 즉, 공간이 계속 변하는 것은 Stack 밖에 없다.
⇒ 즉, 실행은 Stack이 쌓였다가 내려갔다가 값이 바뀌는 것을 말한다.
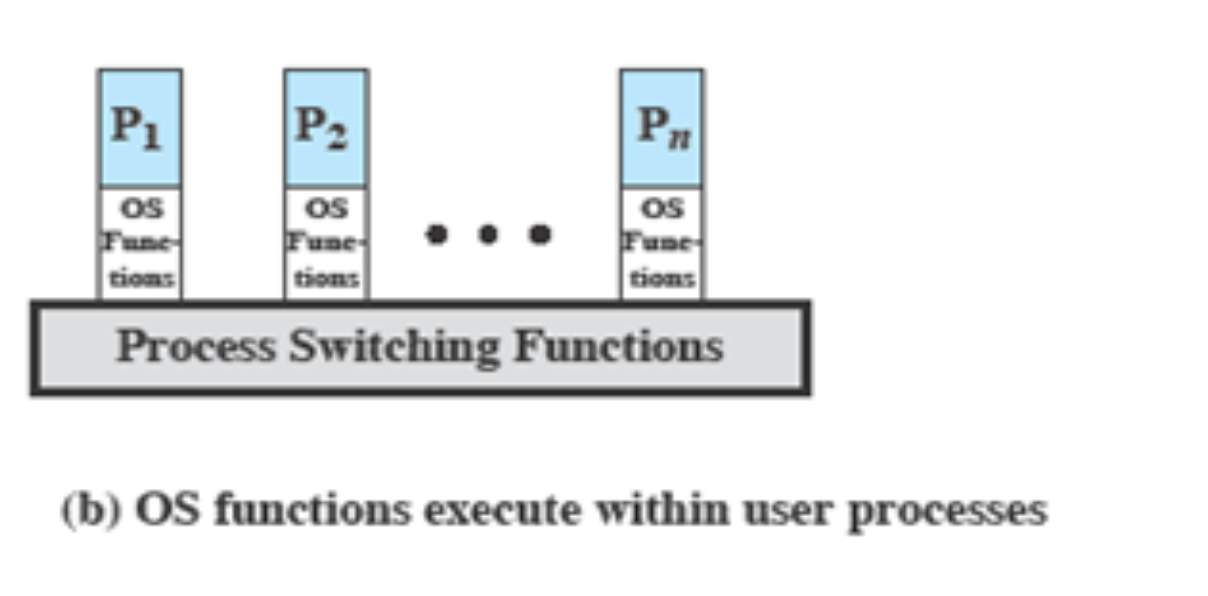
프로세스 안에서 실행이 된다는 것은,
프로세스 안에서 Kernel이 Stack을 쌓아가면서 실행을 하는 것을 말한다.
이런 경우 OS가 작업을 하는 동안 프로세스가 변하지 않는다.
- 만약에 Time Out이었다고 하면, 작업을 끝내면서 프로세스를 바꾼다.
- I/O Interrupt였다고 하면, 프로세스를 바꾸지 않고, 작업을 끝내고 계속 실행을 하면 된다.
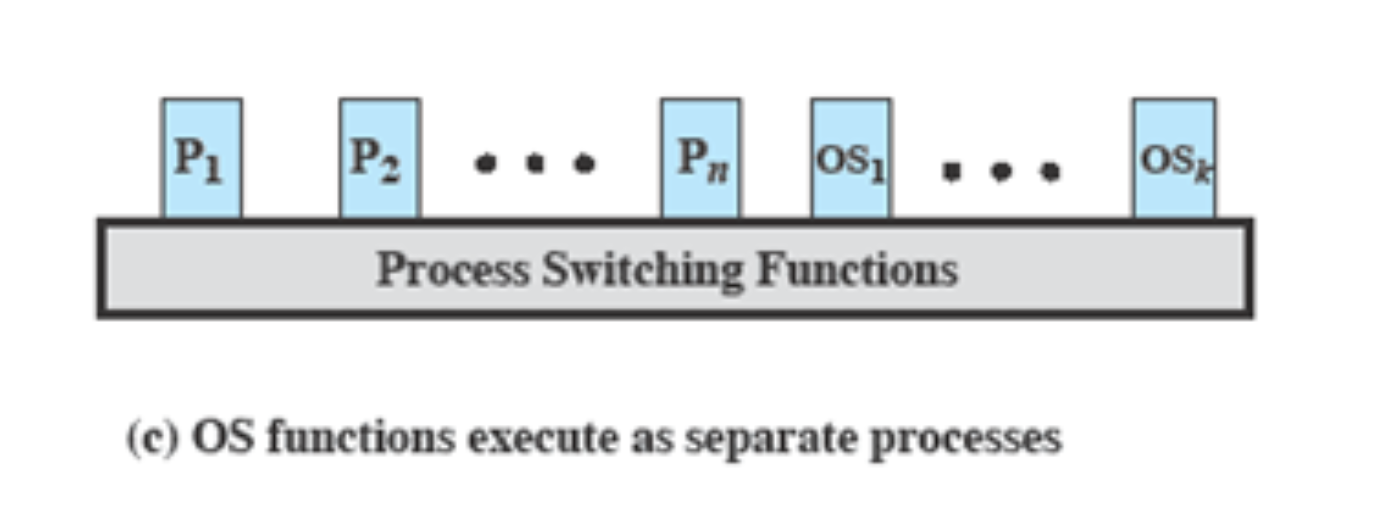
Process-Based Operating System
모든 OS 코드들을 별도의 프로세스로 관리한다.
P1 ~ Pn : 프로세스, 다시 OS1 ~ OSK : 프로세스
어떤 작업을 하든지간에, 일단 Switching 을 해야한다.
P1 실행하다 OS 작업이 시작되면 일단 P1을 다 저장해놓고 OS1을 실행한다.
이렇게 실행을 하면 일단 원래 작업하던 프로세스는 중단을 시키고 Ready 상태로 이동해야 한다.