OS의 실행방식 세가지
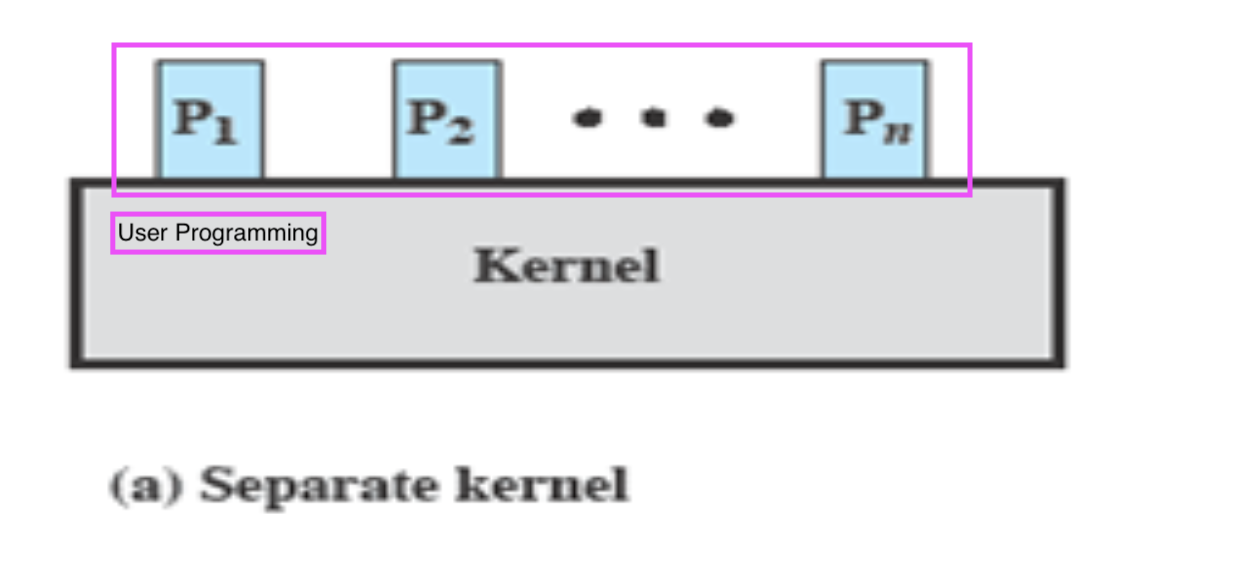
1. Non-process kernel
-
OS Kernel을 별개의 객체로 보는 방식이다.
-
각 Process 관리 방식 != OS kernel 관리 방식
- OS는 특별한 권한을 가지고 있다.
- OS는 별개의 entity로 시스템 안에서 실행되는 객체이다.
-
OS가 작아서 OS전체가 Memory에 올라갈 수 있던 옛날에 가능했던 방식이다.
-
OS가 작아서 전체가 Memory에 올라가, Virtual Memory를 사용할 필요가 없다.
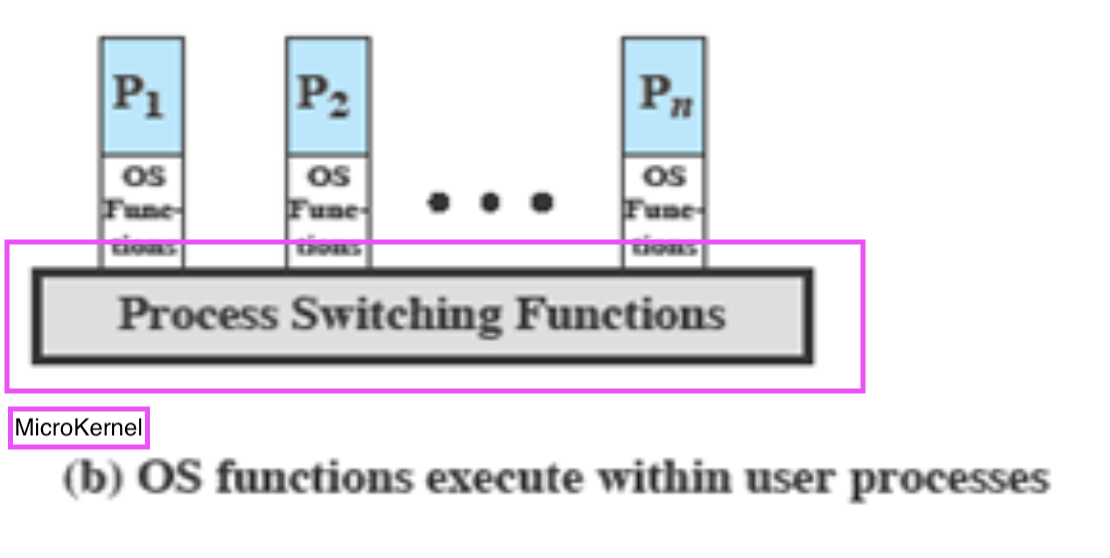
2. Execution Within User Processes
-
OS를 User Process 안에서 실행시키는 방식이다.
-
OS에서 굉장히 중요한 부분 빼고, 나머지 부분들을 Process 안에서 실행 시킨다.
-
P1 ~ Pn까지 User Process안에 OS function이 들어있다.
User Program
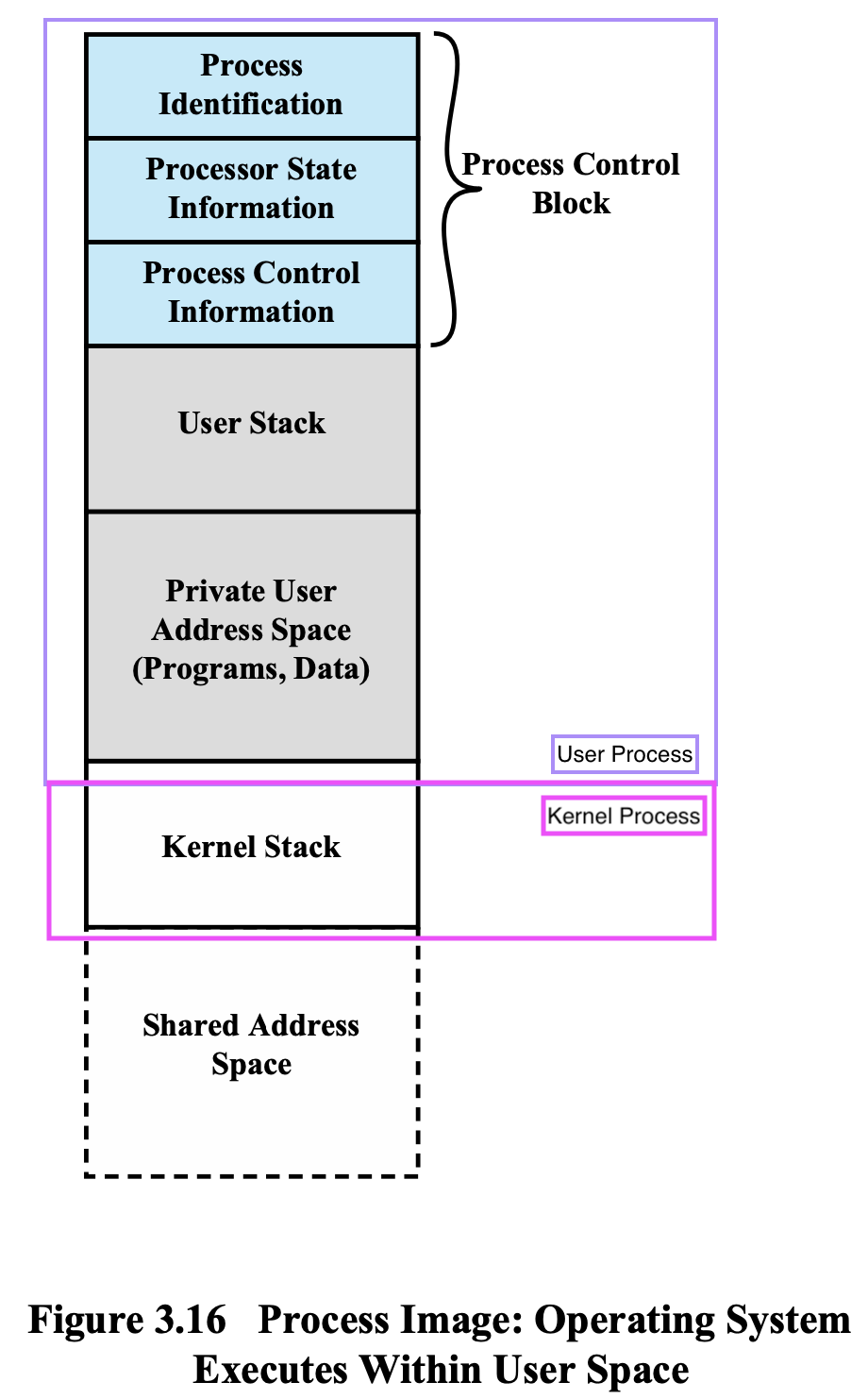
모든 프로세스 = Process Control Block + User Stack + Private User Address Space
실행 → 인터럽트 발생 → mode switching(process switching X)
PCB가 필요한 이유:
메모리가 한정적이기 때문에, Program이 끊겼다 다시 실행하다 반복하고, 메모리를 나누어 쓰기 때문에 PCB 정보가 필요하다.
PCB는 내가 다른 프로그램과 함께 실행하기 때문에 필요한 정보들이다.
혼자 메모리를 쓰면 필요가 없다. 자원을 공유해야하기 때문이다.
Kernel Stack
OS 실행 → Kernel Stack에 OS가 Stack을 쌓다 뺐다 하면서 실행한다.
Shared Address Space
모든 User Process는 OS코드, OS Data를 Share한다.
이 프로세스 안에 Shared Address Space가 들어 있고, Shared Address Space안에 OS 코드와 Data가 들어 있다.
프로그램 실행
→ 코드 변화 X, Data 영역 변화 O(데이터 영역의 값 변화 O, Data 모양 자체의 크기 변화 X), Stack 변화 O
⇒ Process Switching이 필요 없는 OS 실행 방식이다.
⇒ mode Switching만 발생한다. ⇒ 속도↑
위에서는 User Program 아래서는 Kernel Program이 실행될 수 있다.
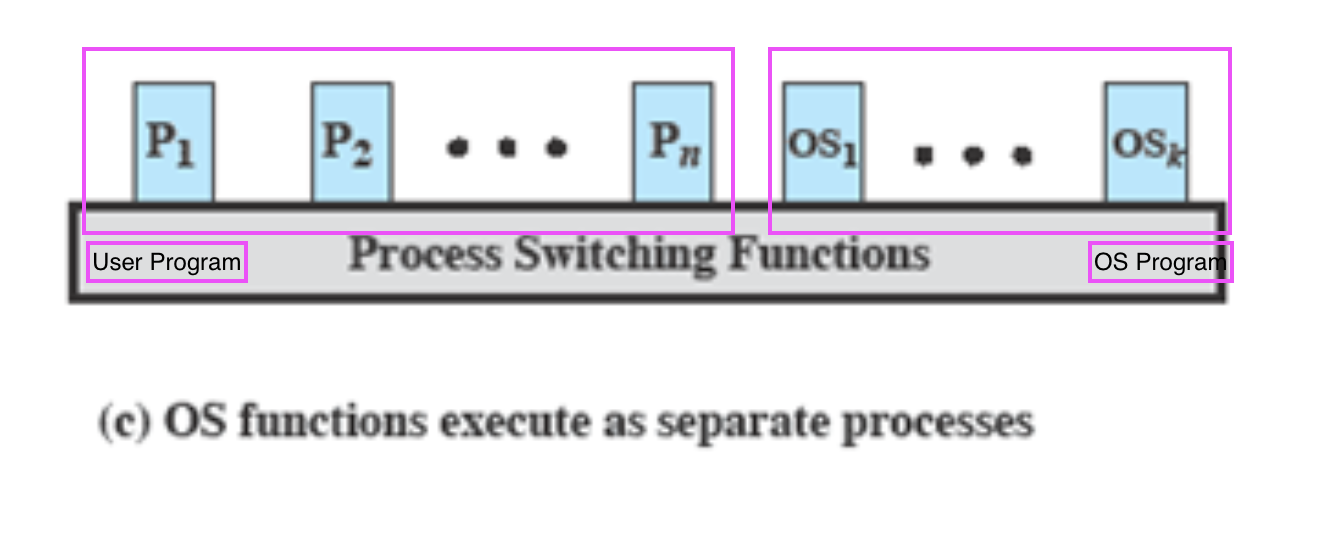
3. Process-Based Operating System
-
OS도 다른 프로세스랑 똑같이 별개의 Process로 관리한다.
-
OS = User Process
micro kernel을 제외하고 나머지는 Process 처럼 처리한다. -
CPU가 서로 다른 OS의 function들을 동시에 실행시킬 수 있다.
⇒ 확장성이 좋다. -
단점: OS도 프로세스이기에, 실행시키기 위해서는 Switching이 발생되어야 한다.
Switching이 발생하면 속도가 느려지게 된다.
P1 → OS1 입출력 요청 → OS2 호출
⇒ Switching이 많이 발생하게 된다. ⇒ 속도 ↓
UNIX SVR4 Process Management
1. OS의 실행방식:
Execution Within User Processes + Process-Based Operating System (위의 두번째 방식 + 세번째 방식)
대부분의 OS 프로그램들은 User process 안에서 실행시킨다.
2. 프로세스들의 두가지 카테고리
System Process
별도의 Process로 OS 관리
- 0: Swapper
- 1: init
- Process Tree
User Process
User Process 안에서 OS 관리
Process Description
프로세스 이미지
- Program Code
- Data
- Stack
- PCB
- Process ID
- Process State Information
- Process Control Information
PCB를 다음과 같이 나눈다.
User Level Context
- Process text
= program code - Process data
- User stack
- Share memory
여러 프로세스들이 같이 사용하는 공용 공간
UNIX에서는 User Process 안에서 OS가 실행되기 때문에,
User Stack 과 Kernel Stack 두가지 스택을 가지고 있다.
이 중, User Stack 은 User Level Context 에 속한다.
Kernel Stack 은 System Level Context 에 속한다.
Register Context
Process Image 기준으로 봤을 때,
PCB 안에 들어 있는 Processor State Information 이라고 볼 수 있다.
- Program Counter
- Processor status register
- Stack pointer
- General-purpose register
System Level Context
- Kernel Stack이 이에 속한다.
- Process ID, Process Control Information이 들어있어야 한다.
OS가 User Process 안에서 실행이 되는데, 별도의 Process로 실행되기도 한다.
User Process 안에서 실행이 되고 있는 동안, access해도 되는 정보와 나머지 정보를 분류해 놓는다.
-
U(user) area
→ OS가 User Process 안에서 커널이 실행이 될 때, access하는 정보들이다. -
Process table entry
나머지 Process control informaiton 들은 Process table entry에 별도로 저장을 해놓았다. -
Per process region table
→ 메모리 관리와 관련 O -
Kernel Stack
Unix에서의 프로세스 상태도
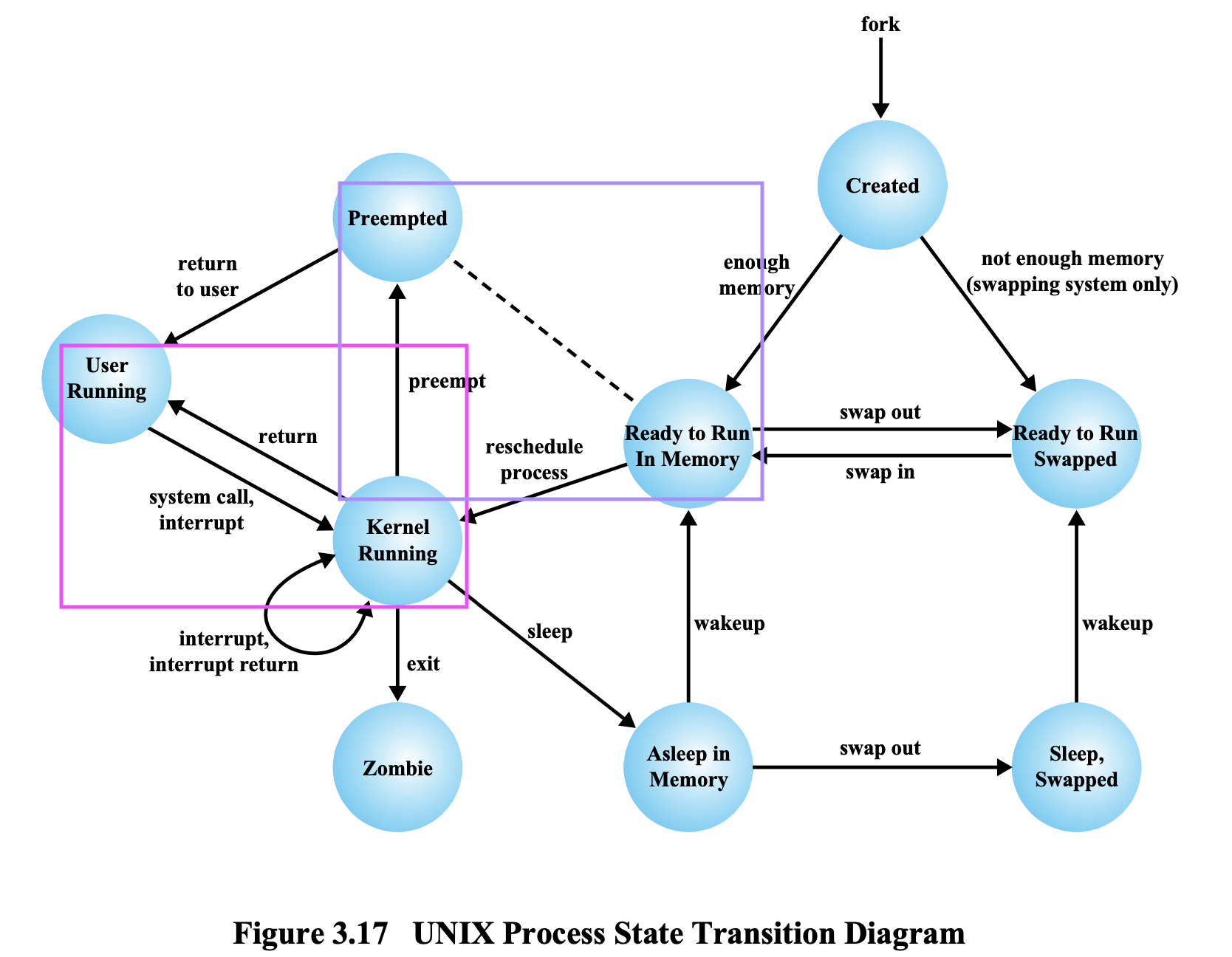
New → Created 상태
메모리 충분 → ready to run in memory
메모리 불충분 → ready to run swapped (ready/suspend)
ready → running
종료 → exit → Zombie
모든 시스템은 종료를 하면 시스템에서 사라지는 것이 아니라, 자기의 Parent의 Process 한테 자기가 어떻게 종료했는지 종료 상태를 보고해야 하는 의무가 있다.
프로세스가 사라지면, Memory도 다 반납하고, 자기가 받은 자원을 다 반납을 해도, 프로세스 테이블에 Entry 하나를 남겨둔다.
프로세스 ID + 종료 상태
이걸 자신의 Parent가 확인을 해주어야만 사라질 수 있다.
즉, 좀비 상태는 확인을 안해서 계속 남아있는 상태이다.
실행 → I/O 작업 → 프로세스 실행 불가 → Asleep in Memory(Blocked 상태) → Sleep, Swapped(Blocked/Suspend)
→ I/O 완료 → ready to run swapped (ready/suspend)
→ swap in → ready to run in Memory
앞에서의 모델과 다른 한가지는, Blocked/Suspend에서 Blocked 상태로 이동하는 모델이 있었는데, Unix에서는 없다.
한 번 하드디스크로 Swapped 되면, 다시 Swapped 될 때까지 Memory로 올라오지 못한다. Ready/Suspend를 거쳐서 Ready로 올라와야 한다.
Running 상태
= User Running + Kernel Running
Running이 2개 필요한 이유?
Kernel 코드가 User process 안에서 실행이 되는데,
User Process가 실행이 되는데
어떤 때 User Program를 실행하는 User Running 상태이고
어떤 때는 Kernel Program을 실행하는 Kernel Running 상태가 된다.
User Running
- User Program 코드가 실행이 된다.
- Process State: User Running 상태
- CPU mode: User mode
Kernel Running
- OS가 User Program 안에서 실행이 된다.
- Process State: Kernel Running 상태
- CPU mode: Kernel mode
항상 User Programming 실행을 하려면, Kernel 작업이 필요하다.
Kernel Running → User Running
User Running → Interrupt, System call → Kernel Running
- Time Interrupt → Ready 상태로 보냄
- I/O 작업을 위한 System call → Blocked 상태로 보냄
- 다시 Running 하는게 맞을 경우 → User Running 상태로 보냄
⇒ 불필요한 Switching이 존재하지 않는다.
(Mode Switching은 존재한다.)
Ready 상태
= Ready to Run In Memory + Preempted
Kernel이 작업을 막하다가,
Timeout Interrupt 발생 → Preemted 상태
--- 뜻
Ready to Run In Memory, Preempted 둘 다 Ready Quque에 들어 있다는 뜻이다.
Preempted
Running을 하다가 Preempted로 이동한다.
Preempted에는 원래 Running 상태로 실행하고 있던 Process 가 Timeout이 되면 이동하게 되는 곳이다.
원래 실행을 하고 있던 프로세스들이기 때문에 OS가 해줘야 하는 일들이 적다.
Ready to Run In Memory
이런 저런 이유로, 한동안 실행을 못하다가 다시 실행을 시작해야하는 프로그램이 들어 있다.
이런 경우에는 OS가 해줘야 하는 일들(메모리 관리, ...)이 많다.
⇒ 둘 다 Ready 상태이고 Ready Queue에 넣어 놓지만, 다시 실행할 때 해야하는 일들이 달라서 구분해 놓은 것이다.
Q. Preemted → User Running 이런 화살표가 존재하는 이유?
원래는 이런 화살표가 존재할 수가 없다.
User 프로그램이 실행이 되려면, 당연히 OS가 뭔가 작업을 해주어야 User Program이 실행이 된다.
OS의 작업 없이 User Program이 갑자기 실행을 시작할 수는 없다.
모든 프로그램은 실행을 시작하려면 Kernel Running 상태를 거쳐야 한다.
Preemted에서 User Running 로 갈때도 당연히 Kernel Running 상태를 거쳐야 한다.
근데 이 모델은 시스템 전체가 아닌, 하나의 프로세스에 대한 모델로,
하나의 프로세스가 어떻게 변화하는지 나타낸 그림이다.
Preemted에 존재하는 프로세스는 이미 Ready to Run In Memory에서 Kernel Running을 거쳐 User Running 상태에서 실행이 되다가 Time Interrupt를 거쳐 Preemted 상태로 오게 된 애들이다.
따라서 다시 실행될 때 문제가 없다면, Kernel을 거치지 않아도 바로 실행될 수 있는 것이다.
