- Process가 독립적으로 Ready Queue에 들어간다.
- OS가 Process를 실행시키는 순서를 계속 바꿀 수 있다.
→ 이는 Process가 독립적이고 별개이기에 가능한 것이다.
- Thread가 독립적으로 Ready Queue에 별개의 실행단위로 들어간다.
- OS가 Thread를 실행시키는 순서를 계속 바꿀 수 있다.
- Thread는 같은 프로그램 Set를 공유한다.
Processes and Threads
3장 Process
(3장에서 배운 프로세스 기반의 시스템 기준, Multi Threading을 지원하지 않는 시스템)
- Scheduling, Execution의 단위
- Resource Ownership의 단위 (자원 할당)
4장 Process
(Multi Threading을 지원하는 시스템)
-
Scheduling, Execution 은
Thread의 단위이다.
Thread=Light Weight Proces -
Resource Ownership 은
Process의 단위이다.
Process=task
⇒ 자원할당은 Process 기준이고, 실행은 Thread 기준이다.
Multithreading
Multithreading이 가능한 시스템은 언제부터 나오기 시작했는가?
OS는 기본적으로 하나의 프로세스에서 여러개의 스레드를 지원한다.
-
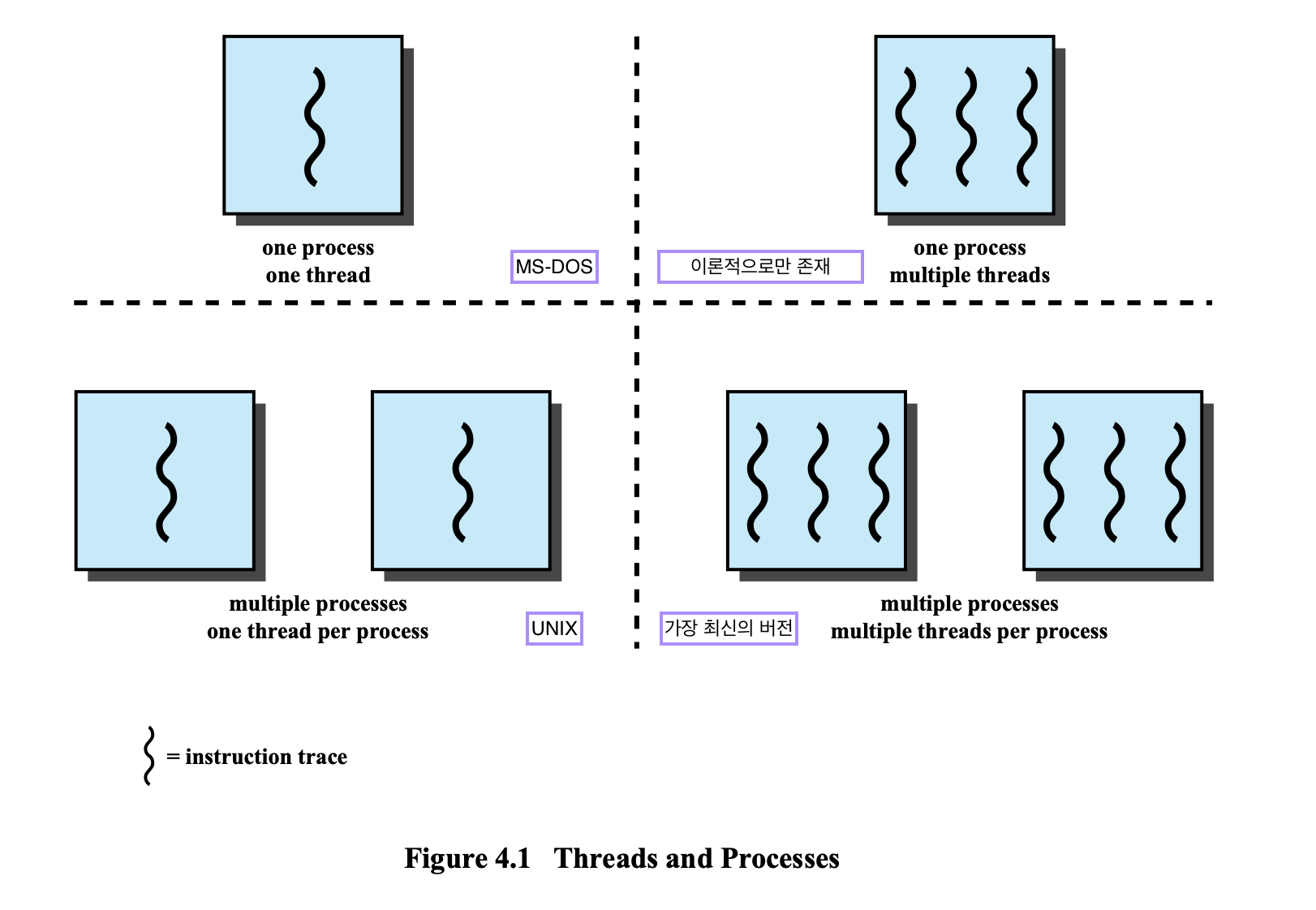
MS-DOS는 한 번에 하나의 Process에 하나의 Thead로 실행한다.
-
UNIX는 여러개의 Process에 하나의 Thread로 실행한다.
-
Windows, Solaris, modern version of UNIX는 여러개의 Process에 각각에 여러개의 Thread로 실행한다.
| Process | Thread | |
|---|---|---|
| MS-DOS | 1 | 1 |
| UNIX | N | 1 |
| Windows, Solaris, modern version of UNIX | N | N |
Threads and Processes
Processes
이전에 배웠던 Process Image 를 Multithreading 에서는 모양이 바뀌기 때문에 더이상 사용할 수 없다.
MultiThread가 가능한 환경에 놓여있는 Process
-
Process는 자원할당의 단위와 Protection의 단위이다.
⇒ 자원 → A Process에 할당 → A Process와 A의 Thread들만 자원에 접근이 가능하다. -
Process는 Process Image를 저장하는 virtual address space이다.
→ 즉, Process는 Process Image를 포함한다. -
Process는 CPU, 다른 Process들, file들 그리고 I/O 자원들에 대한 접근을 Protect 하는 단위가 된다.
→ 하나의 프로세스와 그 프로세스에 들어 있는 스레드끼리는 권한(READ, WRITE, ...)이 동일하지만 다른 프로세스와는 권한이 다르다.
Process A가 CPU를 얼만큼 쓰고 있다고 얘기하지,
Thread a가 CPU를 얼만큼 쓰고 있다고 얘기하지 않는다.
Threads
-
실행 단위이다. (running, ready, etc.)
Thread들의 상태는 각각 다를 수 있다. -
Running 상태가 아닐 때, Thread Context를 저장한다.
→ CPU의 상태를 Context로 저장한다.
⇒ Thread는 Thread Context를 각자 가지고 있어야 한다.
(Context는 PCB의 정보 중 하나이다.)Thread1 → Timeout, Thread1 Context 저장 → Thread2 → Timeout, Thread2 Context 저장 → Thread3 -
Execution Stack을 가진다.
(Execution Stack은 PCB의 정보 중 하나이다.)
⇒ 즉, Thread는 Stack 모양이 다 다르다.Thread1 → A 호출 → B 호출 Thread1은 Stack에 A, B에서 사용한 지역 변수 O != Thread2 → C 호출 Thread2은 Stack에 C에서 사용한 지역 변수 O -
Thread별로 지역 변수를 위한 static storage를 가진다.
multithreading을 할 때 스레드를 두 개 만들어서 A라는 함수를 호출하라고 할 때,
A에 스태틱 변수가 있으면,
스레드 a가 계산한 스태틱 변수의 값과 스레드 b가 계산한 스태틱 변수의 값이 같을 수가 없다. -
Thread의
memory공간 과resources공간 에 대한 접근을 할 수 있다.
→ Process의 모든 Thread들은 자원을 공유한다.
Single Threaded and Multihtreaded Process Mode
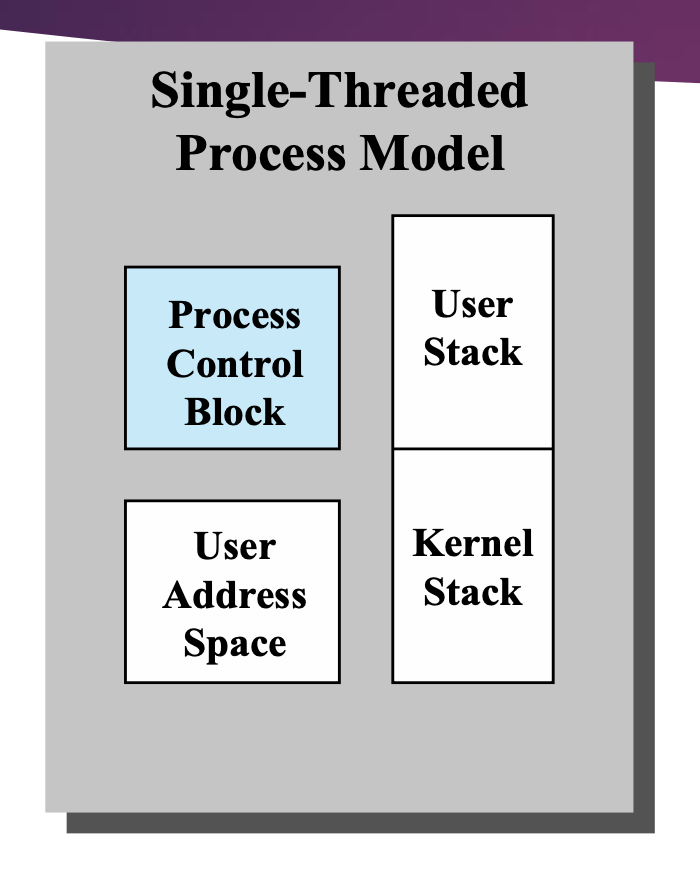
Single Thread Process Model
-
User Address Space에는 프로그램 데이터와 코드가 들어있다.
-
Kernel code가 User Process안에서 실행되는 시스템이다.
Multithread Process Model
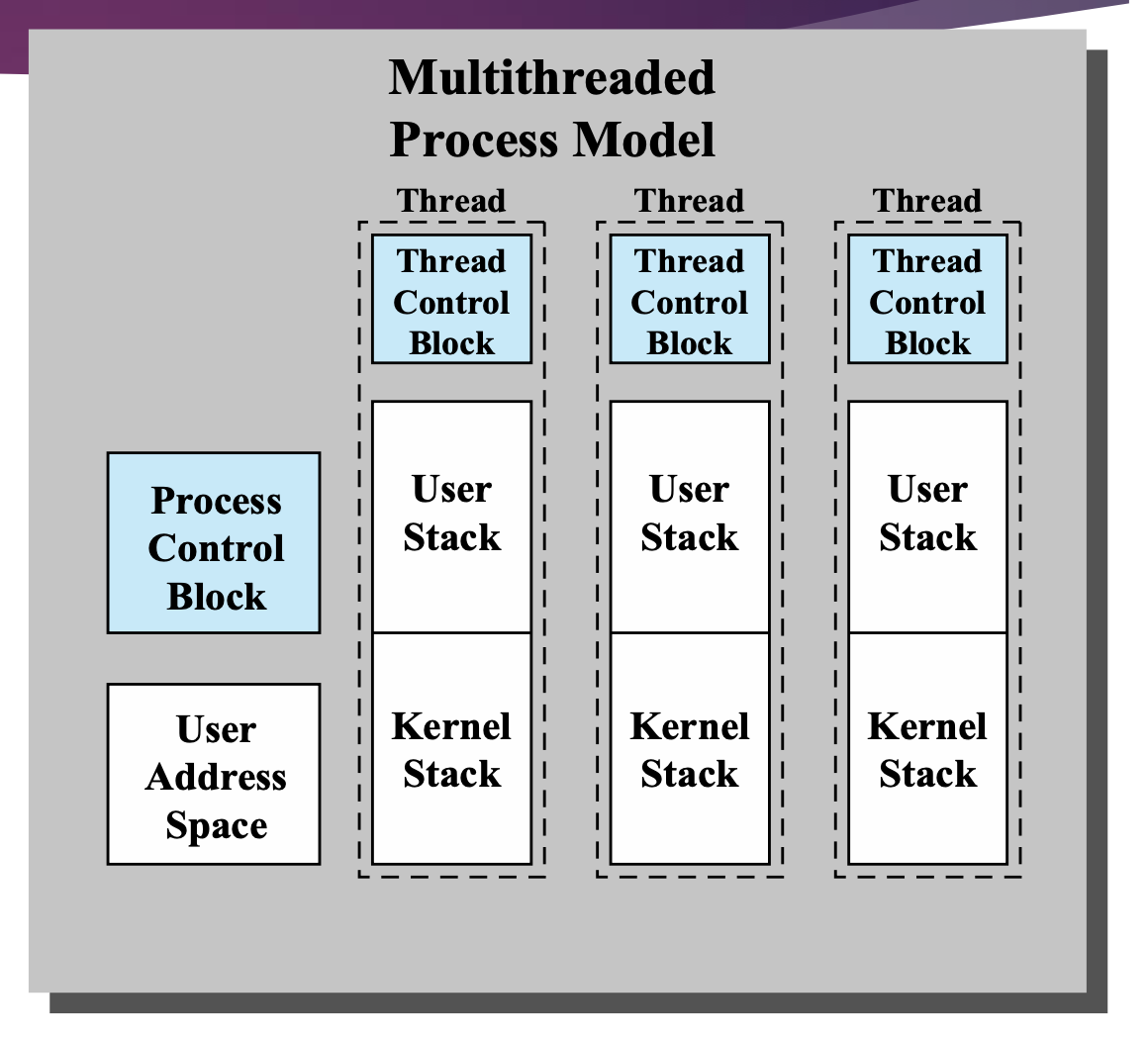
스레드 별로 관리가 되는 것
→ Stack
Process별로 관리가 되는 것
⇒ 스레드가 공유하는 것 (프로그램 코드와 데이터 영역)
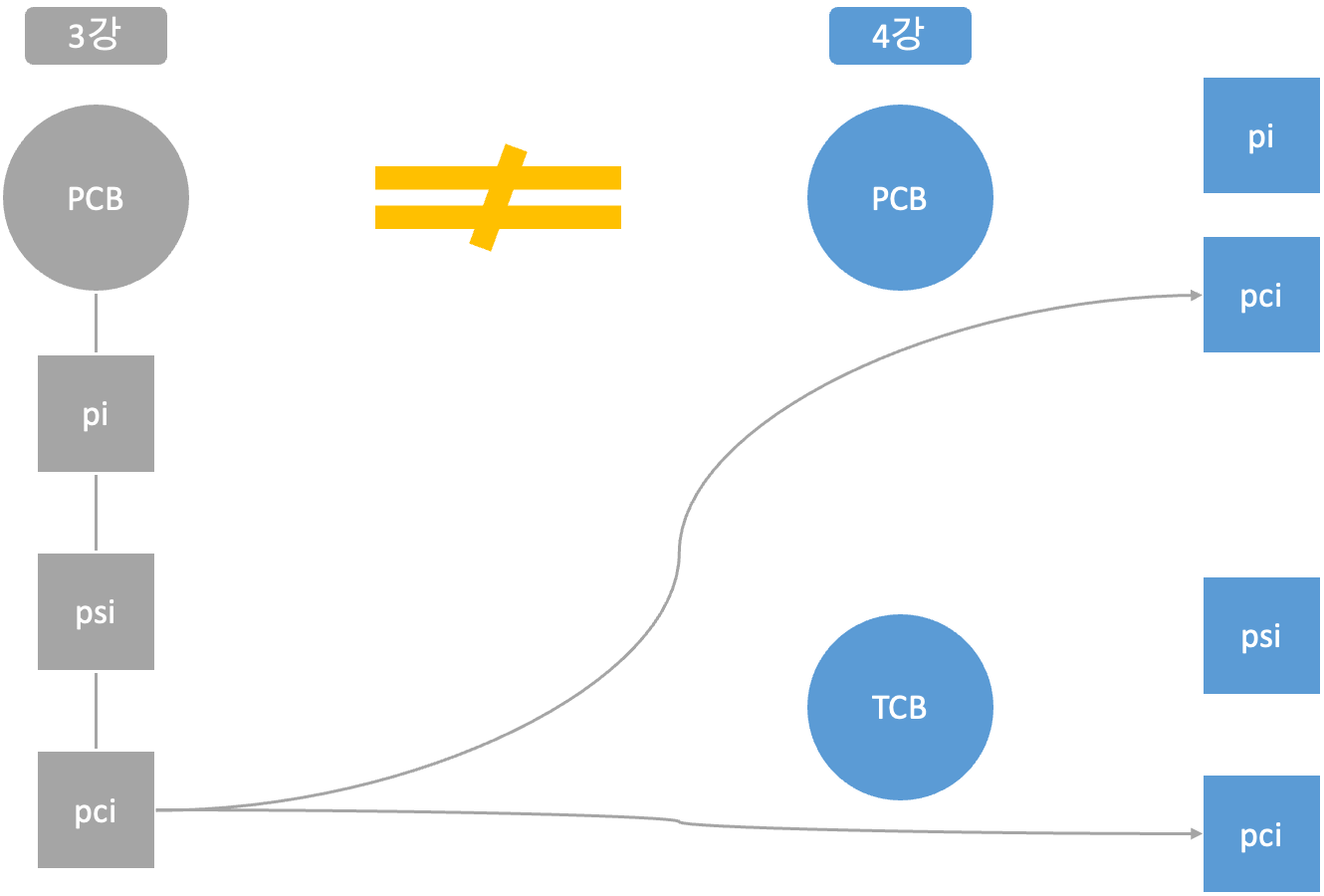
Single Thread PCB = Multithread PCB + TCB
-
3강의 Single Thread의 PCB ≠ 4강의 Multithread의 PCB
-
Single Thread의 PCB = 4강의 Multithread의 PCB + 4강의 Multithread의 TCB
PCI (Program Control Information)
Single Thread에서의 pci는 실행 시 관리돼야 하는 정보 와 자원관려하여 관리가 돼야 하는 정보 가 들어 있다.
프로세스를 실행시키고 관리하는데 필요한 모든 정보가 여기 들어 있다.
Multithread에서의 pci는 PCB와 TCB로 나누어 진다.
- PCB의 pci는 자원을 관리하게 되고,
ex: CPU를 얼만큼 사용했다, ... - TCB의 pci에서는 실행관련 정보를 관리하게 된다.
→ 스레드 단위로 관리된다.
ex: 스레드의 상태(Ready, etc...), scheduling할 때 우선순위, ...
PI(Program ID)
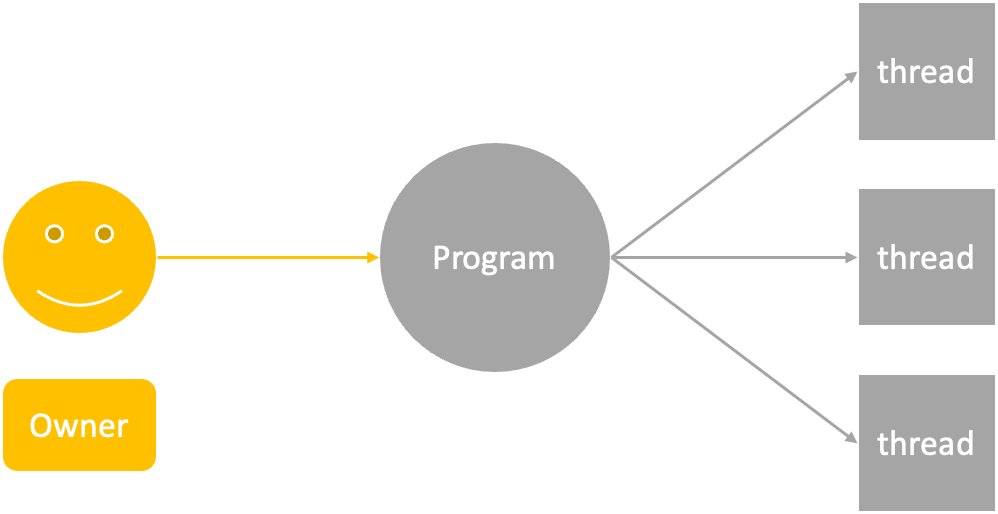
Program을 실행하게 되면 Process가 되어 여러 스레드를 관리하게 되는데,
이 때 생성되는 스레드들은 전부 Owner가 동일하다.
⇒ 스레드 하나하나마다 Owner가 다를 수가 없기에, PI는 Process 단위로 관리가 된다.
Remote Procedure Call Using Thread
Thread를 사용해야하는 이유?
→ 프로그램의 실행 속도 향상!
Q. 여러개의 child Process로도 동시 작업할 수 있는데 왜 Multi Thread 로 동시작업을 할까?
Process 생성 시간 > Thread 생성 시간
이유?
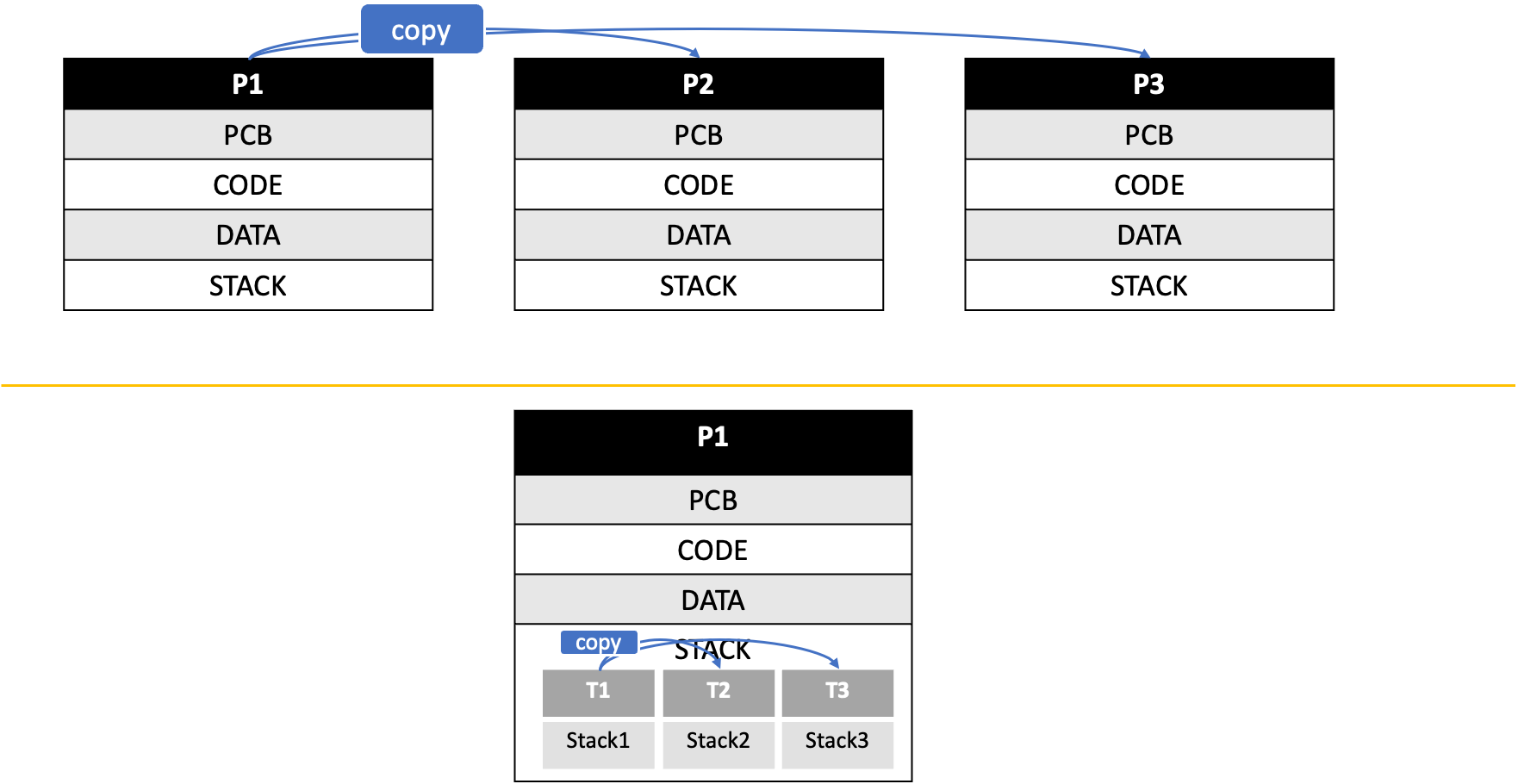
프로세스 생성 → 모든 것을 copy 해야한다.
프로세스는 별개의 독립된 구조체이다.
즉, 프로세스는 복사하게 되면 많은 양의 정보들을 복사해야하기 때문에 생성시간이 길어진다.
⇒ 생성시간도 길어지게 되고, 없앨 때도 메모리, 자원, 스위칭 시간 등등을 할당된 자원을 다시 반납해야 하기 때문에 소요시간이 길어지게 된다.
↔ 하지만, Thread는 프로그램 코드와 데이터를 Share 를 할 수 있기 때문에 모든 것을 copy할 필요가 없다.
⇒ 생성시간이 줄어들게 되고, 없앨 때도 소요시간이 줄어든다.
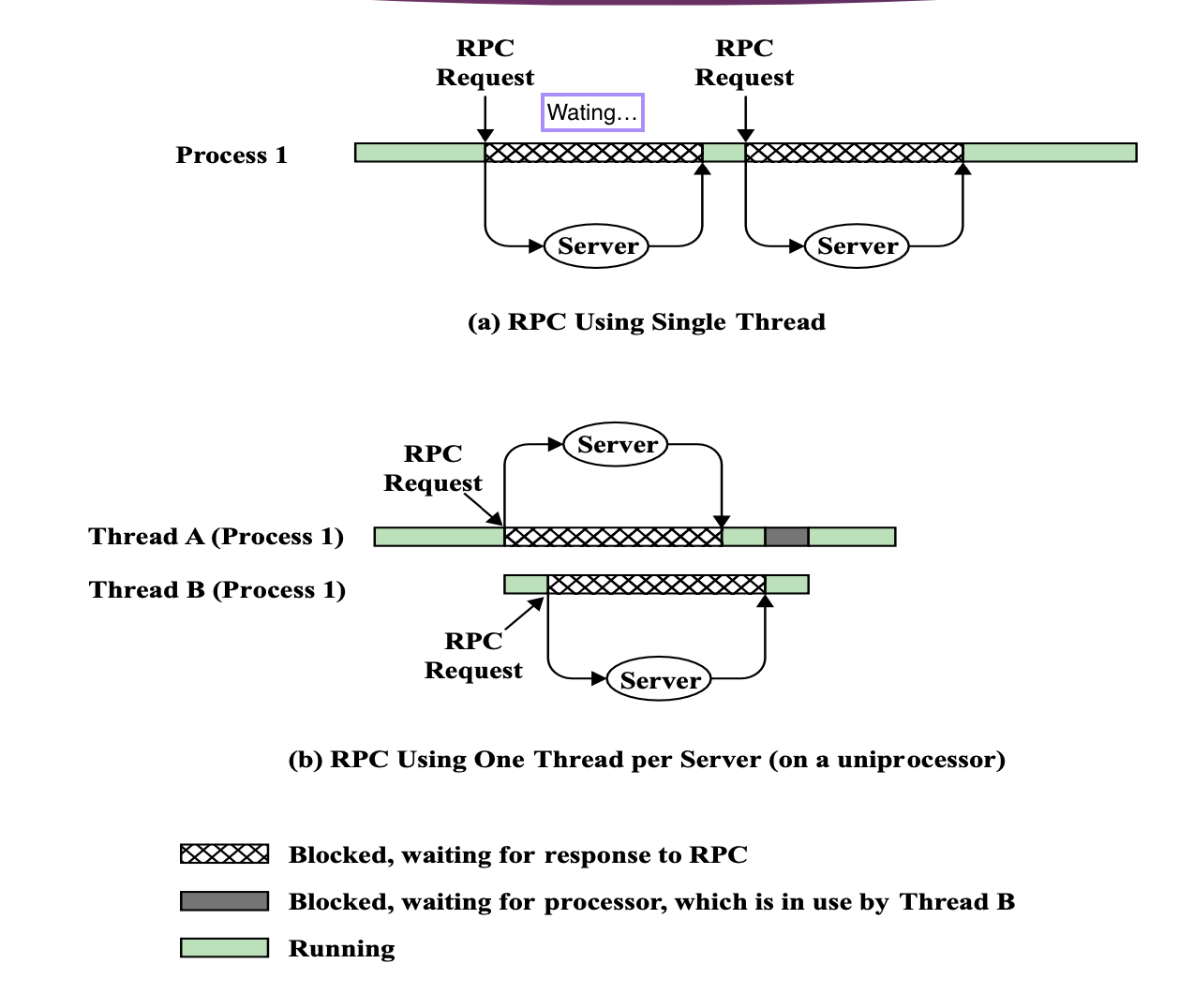
multi-threading 을 해도,
어차피 CPU가 하나라고 한다면, 1번 프로세스의 1번 스레드를 실행하다가 Timeout이 됐을 때, 그 다음에 2번 프로세스의 2번 스레드를 실행하면 당연히 프로세스 스위칭 을 해야 한다.
그런데, 1번 프로세스의 1번 스레드를 실행하다가 1번 프로세스의 2번 스레드를 실행하는 식으로 스레드만 바뀌는 경우인 스레드 스위칭 도 존재한다.
Thread1 → Timeout → Thread2
Thread 만 바뀌고 Process 는 변하지 않는다.
⇒ Thread 스위칭할 때가 Process 스위칭보다 저장정보가 적다.
Processor state information context 는 저장되어야 한다.
context말고도 다른 많은 정보들이 스위칭 할 때 저장되어야 한다.
스레드 스위칭을 하면, 프로세스 스위칭을 할 때 보다 다른 정보들을 저장하는 것이 줄어든다.
Thread의 장점 네가지
1. 프로세스 생성 시간 > 스레드 생성 시간 (🌟)
2. 프로세스 중단 시간 > 스레드 중단 시간
3. 프로세스 스위칭 시간 > 스레드 스위칭 시간 (🌟)
4. Kernel의 개입 X
Thread 는 같은 프로세스에서 메모리 와 파일 들을 공유 하기 때문에,
통신을 할 때 Kernel 이 끼어들 필요가 없다.
→ Kernel 이 끼어들게 되면, 시간 소요가 높아지게 된다.
Thread States
- Spawn
↳ Spawn another thread
(≒ new, 프로세스가 생성되는 것과 같이 스레드가 만들어지는 상태) - Ready
- Running
- Blocked
- Finish
↳ Deallocate register context and stacks
(thread가 종료한 상태)
Process 종료 ≠ Thread 종료
실행을 하려면, Process는 무조건 하나의 Thread는 있어야 한다.
→ Process가 하나의 Thread로 실행을 시작한다.
Q. 왜 Multi Thread는 7개의 State Model로 나타낼 수 없을까?
→ X
MultiThread는 3장의 상태도(5개의 모델)과 같지만, 7개의 모델 상태도로는 그릴 수 없다.
7개의 상태에서는 Swapping 에 의한 Suspend 상태가 존재한다.
이 Suspend 가 일어나는 여러 이유 중 가장 큰 이유가 Swapping 이다.
하지만
Thread는Swapping이 불가능 하다.
→Thread Suspend가 일어나Thread Swapping out이 일어나는 것은 불가능 하다.
스레드가 실행하고 있었는데, 얘(스레드의 stack)만 딱 띄어서 스와핑 area로 보내는 것은 의미가 없다.
⇒ Process 를 Swapping out 해야 한다.
→ Process 가 스와핑의 단위이다.
→ Suspension은 Process 단위로 이루어진다.
Thread State
vs. Process State
몇몇의 state들은 Process 단위에서 이루어진다.
-
프로세스가
Swapping out이 되어Suspend되면,
이 프로세스에 속한 모든 스레드들도Suspend되어swapping area에 놓여지게 된다.
→ 모든 스레드들이 같은address space를 공유 하기 때문이다. -
프로세스의
Temination은 프로세스 내부의 모든 스레드들을 멈추게 한다.
여러개의 스레드 중 1개가 외부 자원 접근 시도
↳ OS가 위험을 감지하고 이 스레드를 포함한 프로세스 전체를 강제 종료(termination)하게 된다.
⇒
Termination작업과Swapping작업은 Process의 단위 로 이루어지는 작업이고,
Thread의 상태가 아닌,Process의 상태로 이루어진다.
Suspend가 발생하는 이유 5가지
single thread의 경우
suspend가 발생하는 이유는 swapping만 있는 것이 아니다.
그 중, thread에 의해 suspend가 발생하기도 한다.
- 스레드 간의 동기화
어떤 스레드는 다른 스레드가 작업할 때 동안 잠깐 멈춰 있어야 한다. - User request
어떤 스레드는 다른 스레드가 작업할 동안 잠깐 멈춰 있어야 한다. - Sleep(1)과 같이 스레드가 1초동안 작업을 하지 않는 것
이런 문장들이 있으면 해당 스레드를 suspend 시킨다.
⇒ Suspend → 메모리에 있을 필요가 없다. ⇒ Swapped out
↔ process가 더 많은 스레드를 가지고 있다면 괜찮다.
스레드가 3개가 있는데, 3개의 스레드 중 하나가 동기화 때문에 suspend가 되어야 할 때, 아직 2개의 스레드를 더 실행할 수 있기 때문에 이 프로세스를 Swap out을 할 필요가 없다.
Suepend ← Process 단위
⇒ Suspension = swap out
Suepend ← Multi Thread 단위
⇒ 한 프로세스 안에 여러개의 스레드가 존재할 수 있다.
여러 스레드 중 1개 동기화로 인한 Suspension
→ 아직, 나머지 스레드들이 실행을 할 수 있다. ⇒ Swapout X
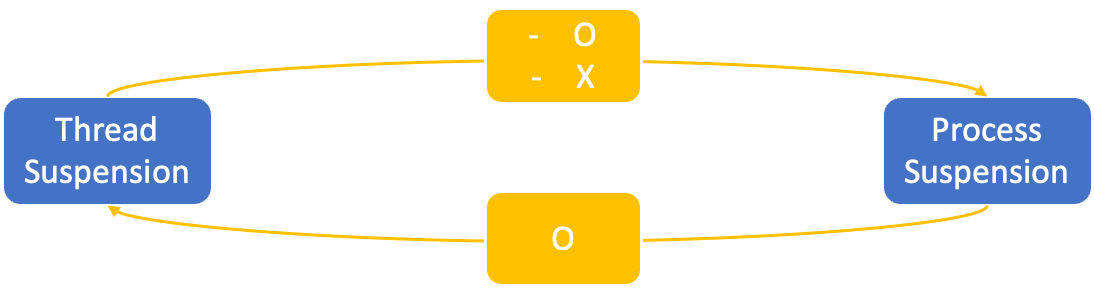
- Thread의 Suspend → Process의 Suspend가 될 수도 안 될수도 있다.
- Process의 Suspend → 이 Process에 포함된 모든 Thread의 Suspend 무조건 된다.
User-Level Threads
1. Thread Library 가 포함하는 코드
- 스레드를 생성 하고 삭제 하는 코드
- 스레드 간의 메시지와 데이터 전송 을 위한 코드
- 스레드 실행 스케쥴링 을 위한 코드
- 스레드 context를
save하고restore하는 코드
User level에서는 Library를 통해 Multi Thread가 가능하다.
User-Level Thread Library
User level 스레드는 실제로 시스템에서는 멀티 스레딩을 지원하지 않는데,
유저 레벨에서 스레드 라이브러리를 만들어서 여기서 스레드를 만들고 그 다음에 스케쥴링하고 스위칭하고 종료하고 하는 등의 관리를 한다.
→ User level에서 Thread Library를 만들어 스레드를 스케쥴링하고 Switching을 한다.
Q. 스레딩 관리를 한다?
→ 유저 레벨의 스레드 라이브러리에서 스레드를 관리한다.
스레드 관리 = 스레드를 만들고 종료하고 스케쥴링하고 스위칭하는 것.
2. 어떠한 application도 Thread Library 를 사용해 MultiThread 하게 프로그램되어질 수 있다.
3. Kernel은 Thread의 존재를 알지 못한다.
- Kernel Level에서는 Multi Threading을 지원하지 않는다.
- Kernel Level은 하나의 Process 단위로 관리된다.
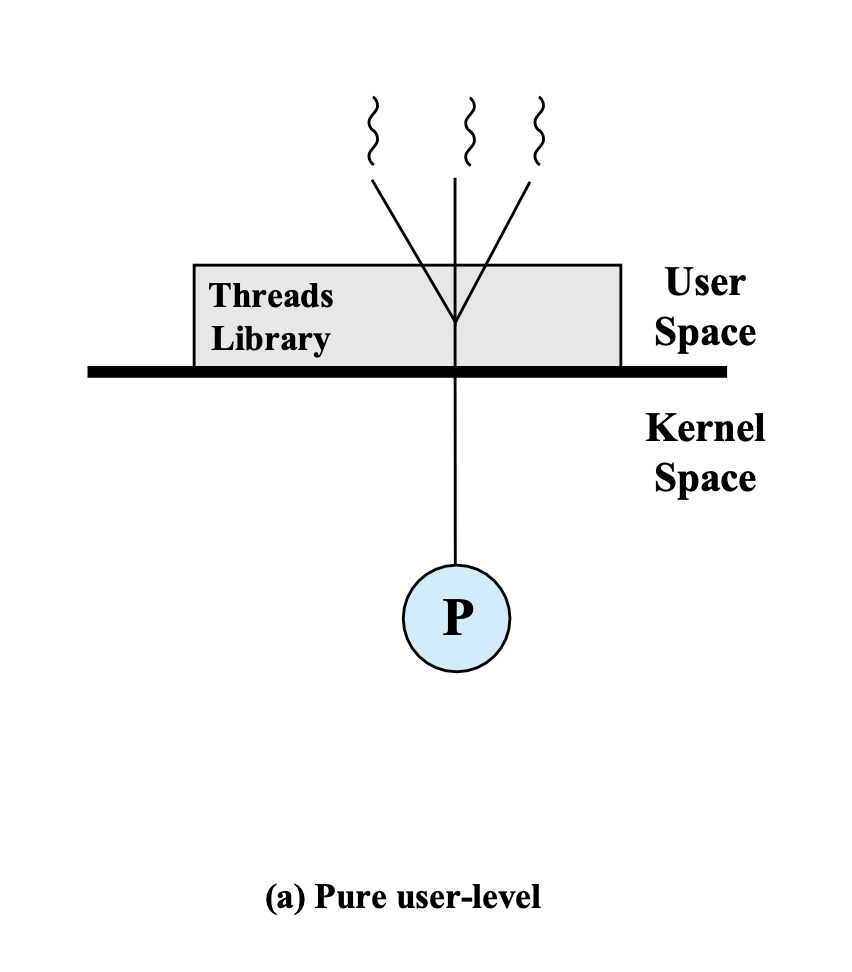
- 커널 레벨에서는 하나의 프로세스만 실행되는 것 처럼 보인다.
- 유저 레벨 프로그램 안에서는 스레드 라이브러리에서 멀티 스레딩이 되어 여러 개의 스레드가 돌아간다.
Relationships between User-Level Thread
실제 Kernel은 Process 단위로 지원한다.
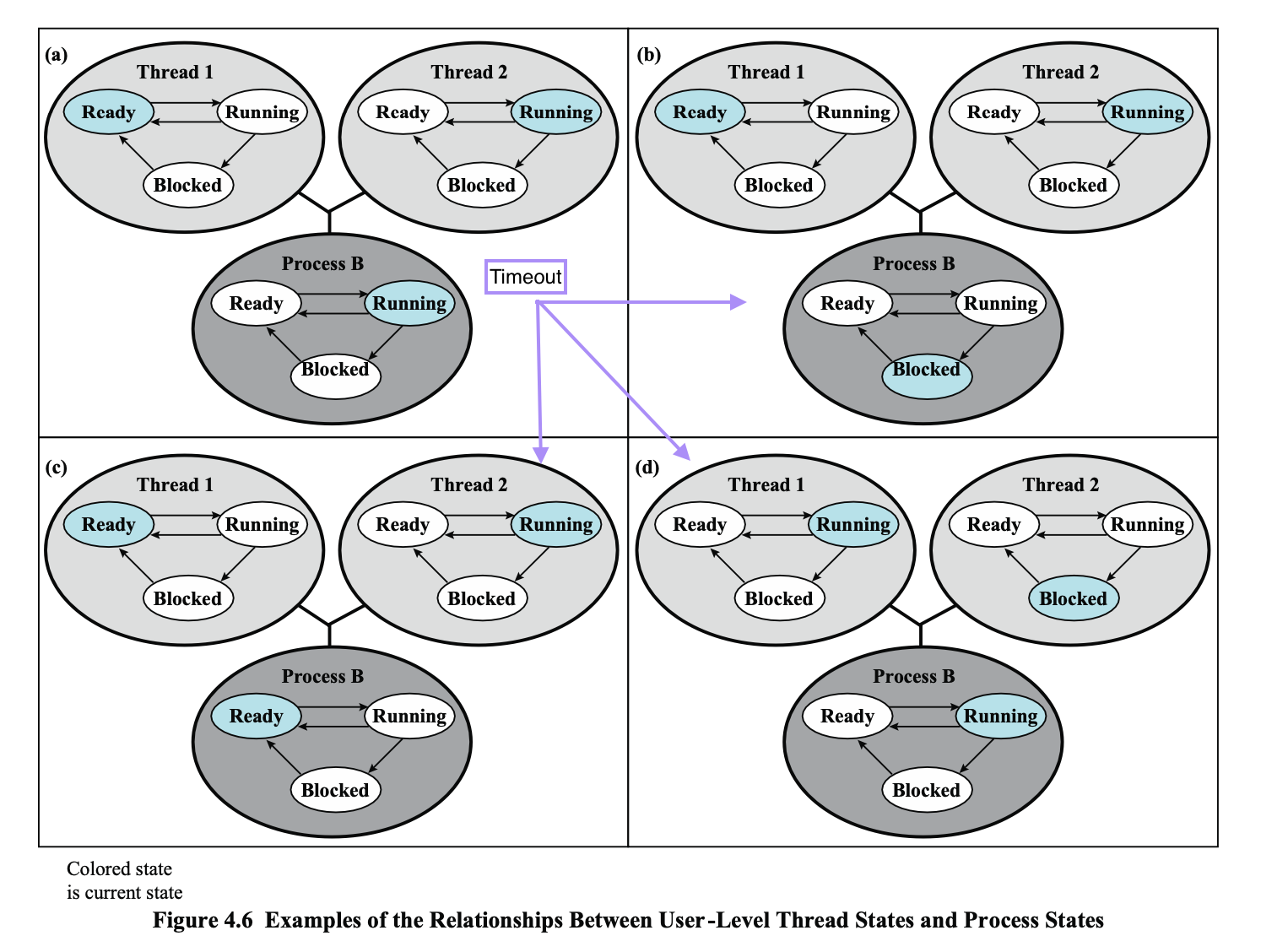
(a) Process Running
두 개의 스레드가 User level에서 관리된다.
하나는 Ready 상태, 하나는 Running 상태이다.
Kernel에서는 이 프로세스가 실행되고 있는 상태이다.
(b) Process Blocked
→ Thread 2가 실행중
→ Thread 2가 I/O 요청
→ Process B가 Blocked 상태가 된다.
↔ 그런데 Thread2는 여전히 Running 상태이다.
스레드는 User Level에서 진행된다.
⇒ 프로그램의 일부이다.
스레드 라이브러리에 가서 함수를 이용해서 상태변화를 시킬 수가 없다.
그냥 Process가 Blocked 된 것이다.
→ 나중에 실행을 재개할 때 스레드들의 상태를 수정하게 된다.
(c) Process Ready (Timeout)
Process의 Timeout
→ Thread2의 실행 중 Timeout
→ 당연히 Kernel에서는 이 프로세스를 Ready 상태로 옮긴다.
→ 그러나, 스레드 라이브러리는 실행을 하다가 갑자기 중단이 되어버렸으니까, 당연히 스레드의 상태변화를 수정을 할 시간이 없다.
→ 따라서 아직 상태변화가 안된 것 처럼 보인다.
→ 나중에 실행을 재개할 때 스레드들의 상태를 수정하게 된다.
(d) Process Running, Thread2 Blocked
실제로는 프로세스가 계속 실행을 하고 있고,
원래 Thread2가 I/O 작업등을 요청을 하려고 했는데, 스레드 라이브러리에서 명령을 받아보고,
이걸 받아주면 내가 Blocked 이 되겠구나 생각을 해서 Thread를 스위칭 한 것이다.
→ Thread2를 Blocked 상태로 옮기고, Thread1을 Running 상태에서 실행을 하게 만든다.
↳ Kernel에서는 Thread가 바뀐 것을 모른다.
⇒ Thread Switching 은 User Level 에서 진행된다.
Kernel과 상관 없이 User Level 에서
Thread Switching,Thread Scheduling이 가능하다.
Kernel-Level Threads
당연히 Multi-Threading을 OS가 지원한다.
OS가 지원하기 때문에, kernel에서 스레드를 생성, 삭제, 스케줄링하고 스위칭하는 작업이 가능하다.
Thread가 여러개라고 해도 CPU가 한 개이면, 어차피 번갈아가며 작업을 해야한다. ⇒ 멀티 스레드 시스템이 더 빠르다는고 확실히 말할 수 없다.
↔ CPU가 여러개라면 진짜로 동시 실행이 가능해진다.
⇒ Kernel-level thread와 User-level thread의 차이를 얘기할 때 꼭 여러개의 CPU를 갖는 시스템에서의 실행을 얘기해주어야 한다.
당연히 이 스레드들은 별개의 실행 단위이기 때문에 스레드 하나가 blocked이 되었다고 해도 다른 스레드가 계속 실행을 할 수 있고,
이러한 장점들이 있는 반면에 여기서의 Switching은 진짜 Switching이다.
-
모든 스레드 관리 작업은 kernel에 의해서 진행된다.
-
kernel은 여러개의 cpu에서 같은 프로세스로 부터 동시에 multiple thread를 scheduling 할 수 있다.
-
만약 프로세스의 하나의 스레드가 blocked되면, kernel은 이 프로세스의 다른 스레드를 schedule 할 수 있다.
-
스레드 스위칭은 kernel을 요구한다.
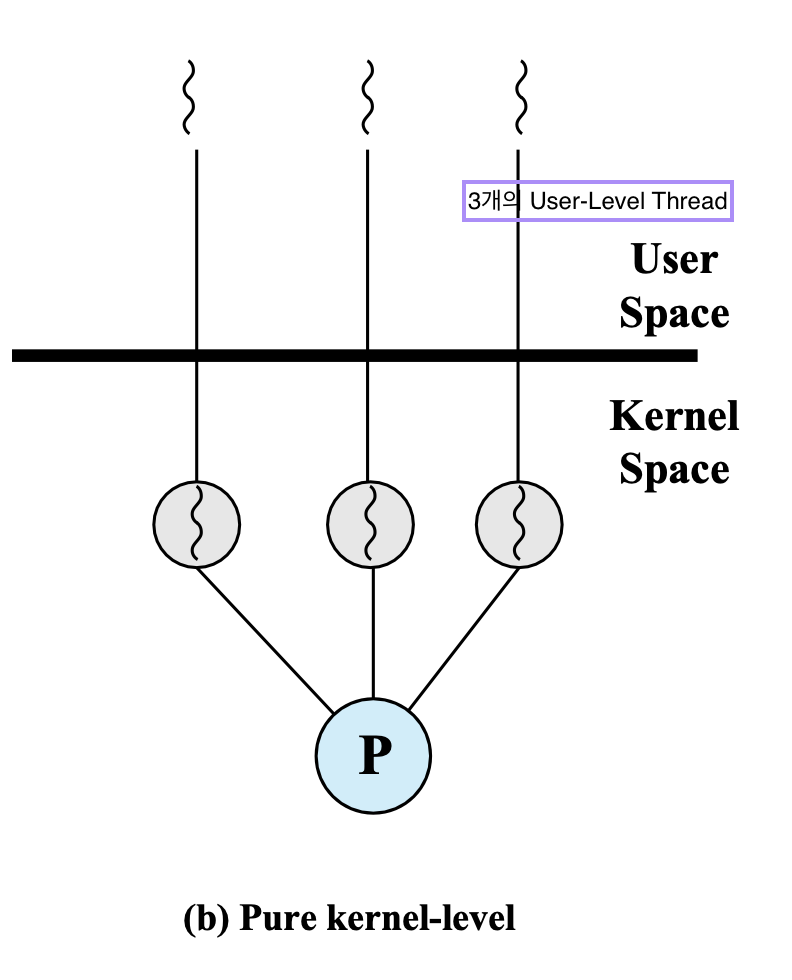
3개의 user level thread를 만들어서
kernel level에서 3개의 kernel thread를 만들어서 3개의 user level thread를 실행한다.
User-Level Threads
vs. Kernel-Level Threads

시스템에서 Multi-Threading 을 지원한다.
→ 당연히 Kenel-level 에서 Thread 를 사용하는 것이다.
시스템에서 Multi-Threading 을 지원하지 않는다.
→ 그런데 나는 프로그램을 Multi-Thread 를 사용해서 작성하고 싶다.
→ User-level 에서 Thread 를 사용할 수 밖에 없다.
그러나 시스템에서 Multi-Threading 을 지원한다 하고,
그런데 나는 Kenel level thread 를 안쓰고 User-level thread를 사용하겠다.
↳ User-Level 이 갖는 장점이 존재한다.
User-Level threads 장점
-
Thread Switching 할 때, kernel mode 권한을 요구하지 않는다.
↳ kernel이 아니라 User-level에서 스위칭을 한다.
진짜 스위칭 X, 스위칭하는 것 처럼 보이게 하는 것이다.
→ OS가 개입하지 않으므로 스위칭 하는 시간이 줄어든다. -
Scheduling은 application specific 할 수 있다.
↳ 시스템 단위의 스케쥴링이 존재한다.
어떤 경우에는 이 프로그램은 그렇게 스케쥴링하면 효율성이 떨어질 수 있다.
즉, 이 애플리케이션에 맞는 스케쥴링을 하고 싶을 때, User-level의 스레드를 사용할 수 있다. -
ULTs 는 어떠한 OS에서도 실행될 수 있다.
OS가 Multi-Thread를 지원하든, 안하든 상관 없이 항상 사용할 수 있다. 🌟
Kernel-Level threads 장점
- CPU가 여러개가 있으면, 정말로 동시에 실행이 될 수 있다. 🌟
- 만약 하나의 스레드가 blocked되면, 또 다른 스레드가 이용될 수 있다.
- Kernel 자체를 Multi-Threading 할 수 있다. 🌟
OS를 멀티스레드를 만들어서 SMP 머신에서 실행하는 것이 멀티 스레드의 원래의 목적이다.
→ 멀티 프로세서와 함께 나왔다.
→ 여러개의 CPU + OS를 여러군데에서 동시에 실행
→ 멀티 스레딩을 이용해서 OS를 동시에 실행시키는 것

- 포크하는데 걸리는 시간
- 통신하는데 걸리는 시간
단위 → 마이크로 세컨드
Combined Approached for Thread
System level에서 multi programming을 지원함에도,
user-level thread와 kernel level multi-thread를 함께 사용하는 것.
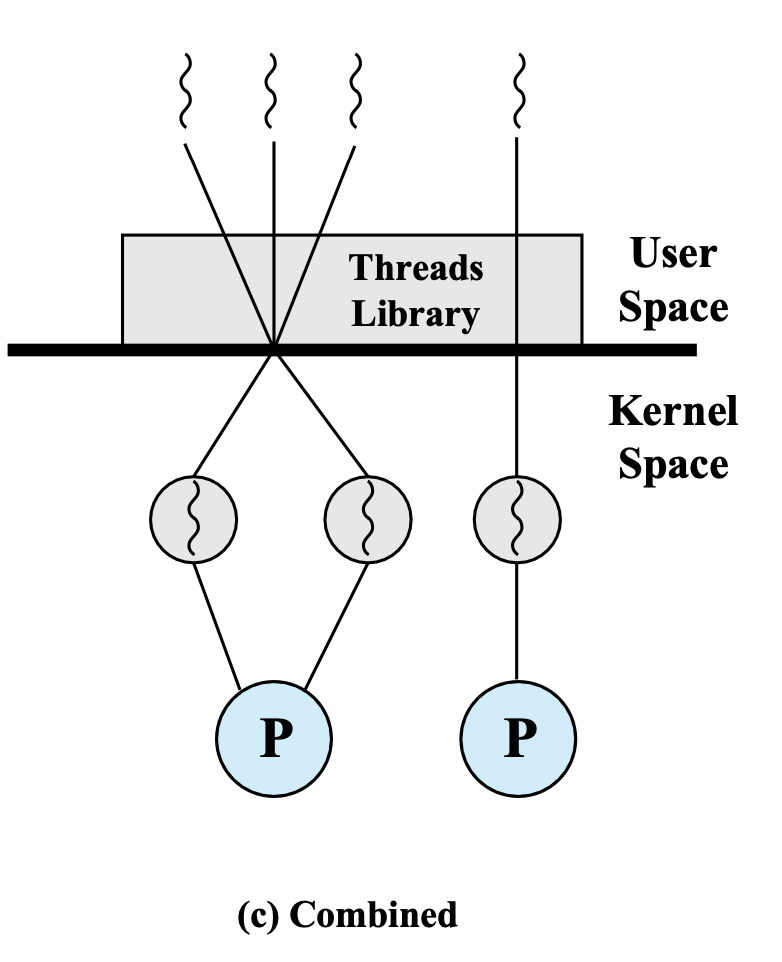
커널 입장: 프로세스 두개 실행 중
- 스레드 2개인 프로세스 A - User level thread 3개
- 스레드 1개인 프로세스 B - User level thread 1개
Q. 왜 이렇게 커널레벨과 유저레벨 스레드 두 가지를 다 사용하는가?
간단히 말하면, 커널레벨의 스레드의 장점과 유저 레벨 스레드의 장점을 둘 다 얻고 싶은 것이다.
- 커널레벨의 스레드의 장점
(여러개의 CPU를 갖고 있는 시스템에서 한 프로그램 안에 있는 여러 스레드를 진짜로 동시에 실행시킬 수 있다.) - 유저 레벨 스레드의 장점
(스위칭을 할 때, 소요시간이 적게 걸린다.)
Q. Combined Approached for Thread 을 사용하는 찐 이유?
멀티스레딩 → 스레드가 항상 동시에 실행되진 않음
User가 불필요하게 너무 많은 스레드를 만들 수 있는데, 이를 OS가 관리할 수 있다.
⇒ 불필요하게 많은 스레드를 만드는 것을 막기 위하여 이렇게 두 단계로 진행하는 것이다.
Relation Between Threads and Processes
| Threads : Processes | Description | Example System |
|---|---|---|
| 1 : 1 | ||
| M : 1 | ||
| 1 : M | ||
| M : N |
