Relationship Between Threads and Processes
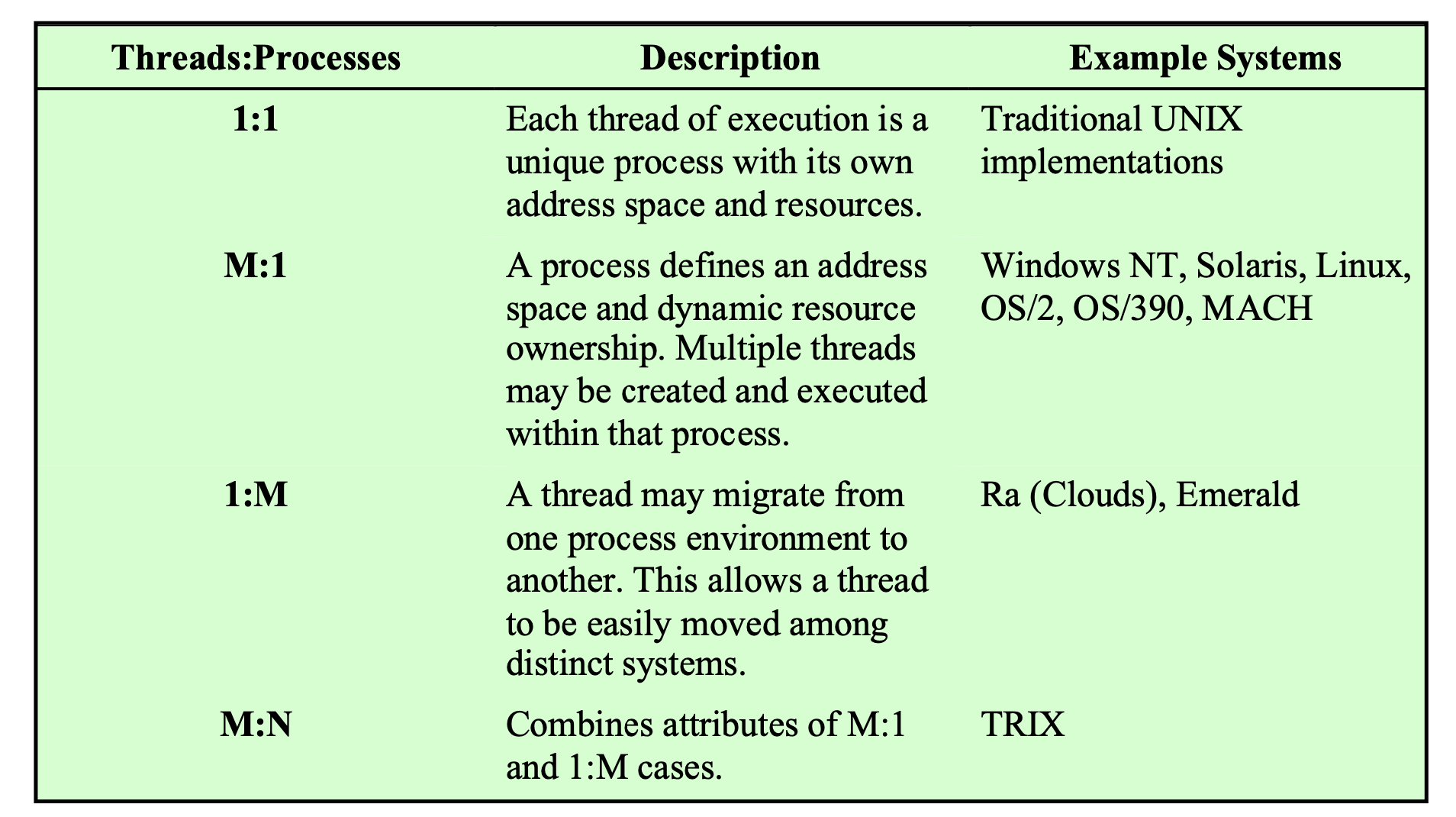
이 중, 주목해봐야할 관계는
Threads : Processes = 1 : M
스레드가 1개인데 프로세스가 여러개인 형태이다.
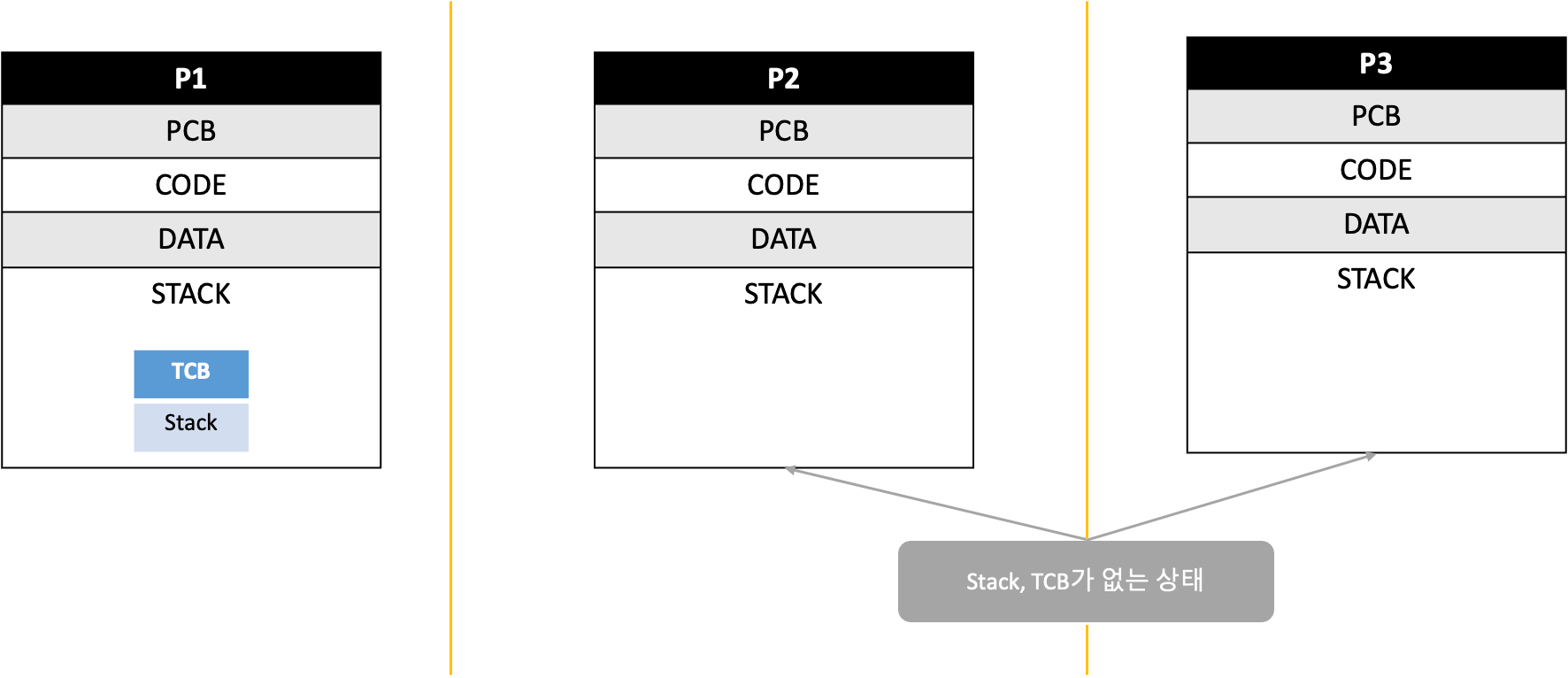
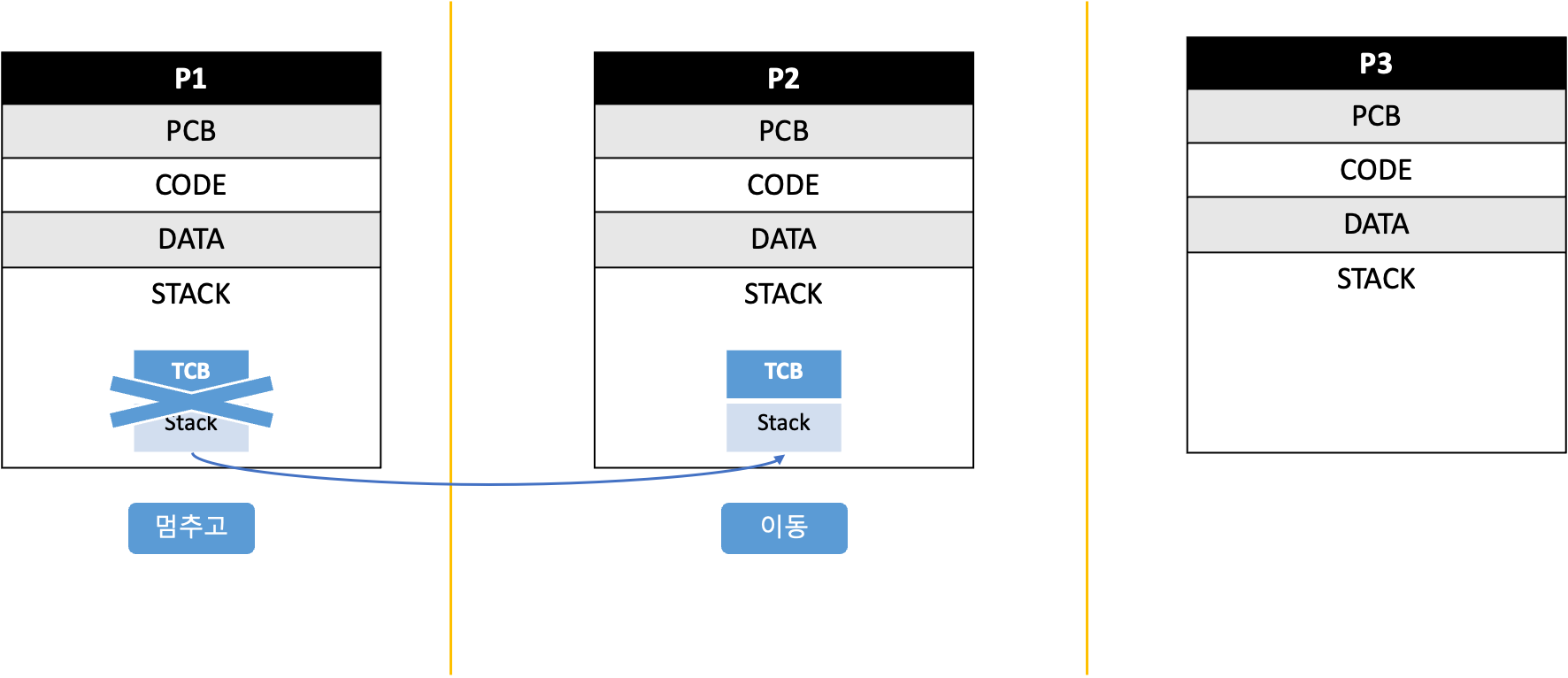
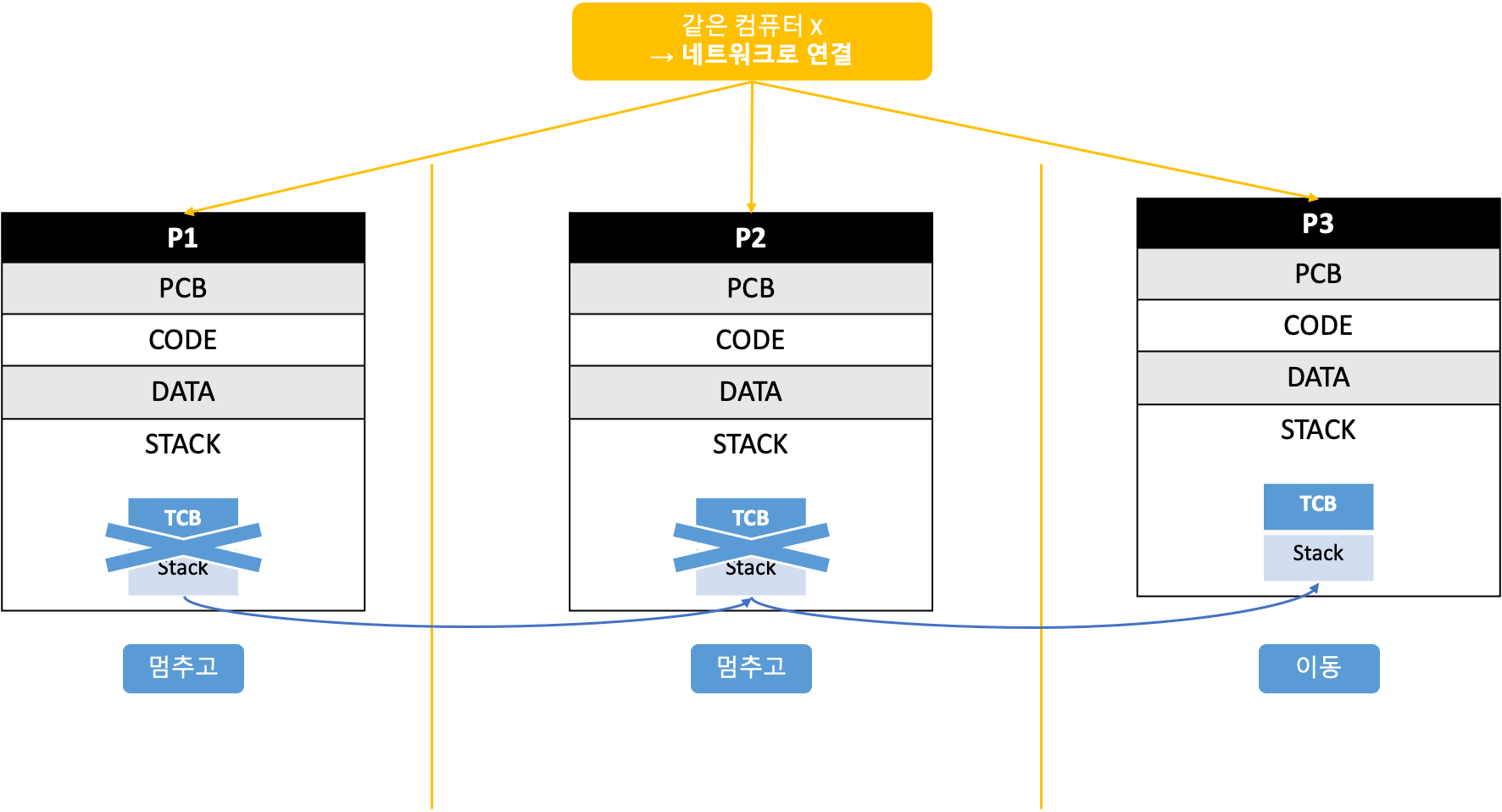
위의 시스템은 프로세스가 여러개인데, 스레드가 1개이다.
P1, P2, P3가 같은 컴퓨터 시스템 안에 있는 경우라면 이런 방식은 말이 안된다.
P1, P2, P3를 네트워크로 연결된 서로 다른 컴퓨터에서 각각의 프로세스를 관리하고 있고, 스레드는 P1에서 실행하다가 P2로 옮겨가고 P3로 옮겨가는 방식이다.
1 : N + M : 1 = N : M
Windows Process and Thread
Windows의 스레드 관리 방법
Multi-Threading System 을 거의 그대로 따르는, 기본이 되는 시스템이다.
각각의 OS별로 스레드 관리 방법이 어떻게 다른지 알아야 한다.
-
객체(Object)로 구현된다.
-
Windows는 새로운 Process가 만들어지기도, 기존의 Process가 복사본으로 만들어지기도 한다.
→ 둘 다 가능하다.
→ Unix는 반드시 기존의 부모 프로세스를 복제하여 자식 프로세스를 생성해야 한다.
⇒ 새로운 프로세스로 만들어질 수 없다. -
실행가능한 프로세스는 반드시 최소 하나 이상의 스레드를 가지고 있어야 한다.
스레드가 다른 스레드들을 만들며 스레드의 수가 변한다. -
스레드는
dispatchable한 작업의 단위이다.
→ 실행단위가 스레드이기 때문에 Dispatch도 스레드 단위로 한다.
dispatchable: ready queue에 스레드가 줄 서 있다는 의미
→ Process와 thread 둘 다 동기화 툴들을 가지고 있다.
Windows Process Object Attributes
Process의 Attribute들
프로세스는 자원 관리 단위 이다.
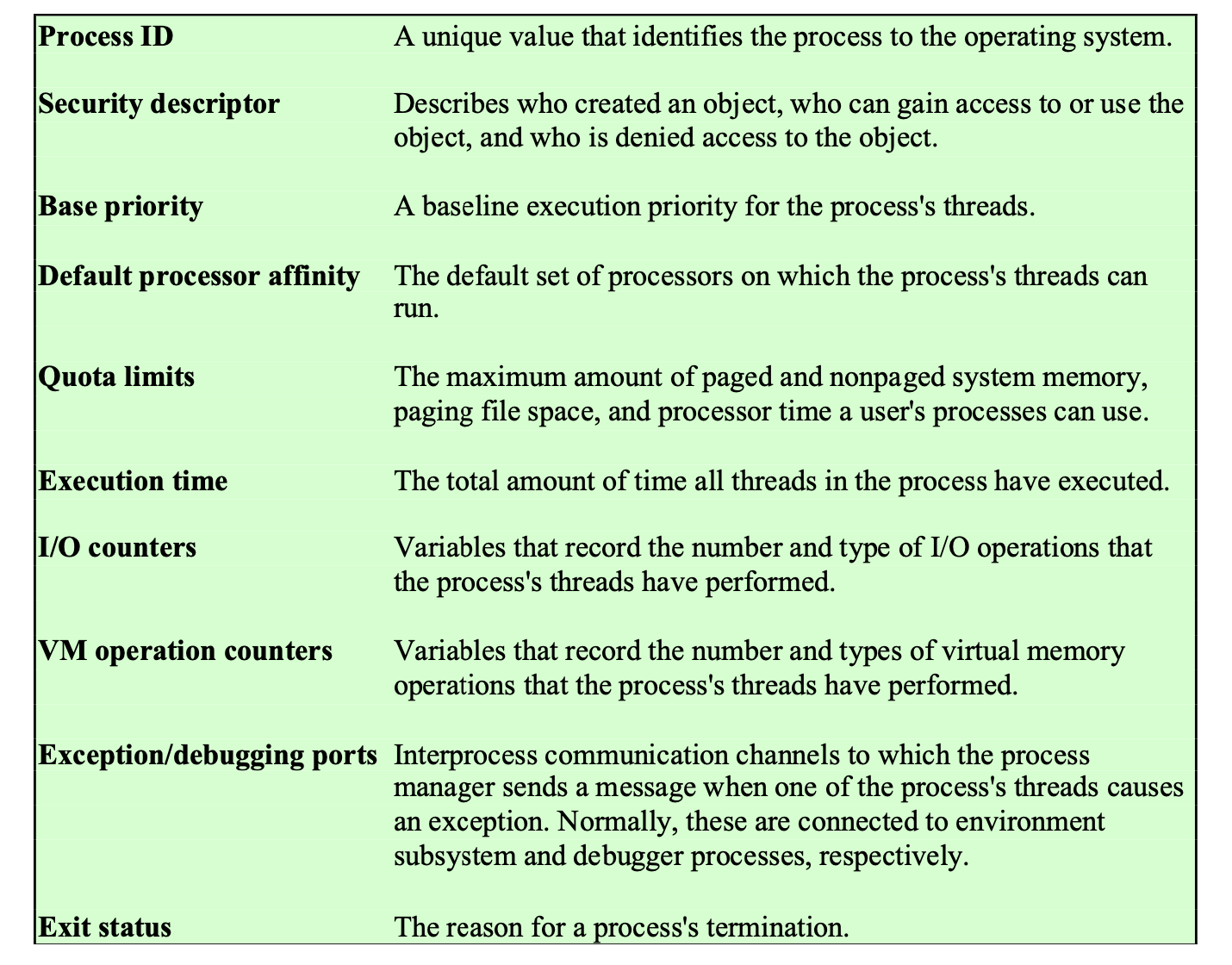
다 외울 필요는 없다.
Execution time
프로세스가 실행하는 게 아니다.
실제 실행은 프로세스 내부에 속해있는 스레드들이 한다.
⇒ Process 내부의 스레드들이 CPU가 얼마나 사용했는지? 를 적어 놓은 것이다.
I/O counters
⇒ Process 내부에 있는 스레드들이 어떤 I/O 작업을 몇 번이나 했는지? 를 적어 놓은 것이다.
VM operation counters
⇒ Process 내부에 있는 스레드들이 Virtual Memory 관련된 작업들을 몇번이나 했는지? 를 적어 놓은 것이다.
실제로 실행을 시키는 것이 아니라, 이 프로세스 안에서 실행을 하고 있는 스레드들이 실행을 하면서 자원을 얼만큼 사용했는지 하는 것들을 적어 놓은 부분이다.
Base Priority
스케쥴링 우선순위 : Ready Queue에서 스레드들이 줄을 서 있을 때, CPU를 먼저 차지하는 순위
Q.thread가 실행 단위이므로 thread가 우선순위를 가져야 하는데, Process는 실행도 안하는게 왜 우선 순위를 갖는가?
→ Base Priority 는 해당 프로세스에 속한 스레드들의 우선순위 minimun 값이다.
Default Processor affinity
교수님이 제일 재밌다고 한 기능
내가 좋아하는 CPU라는 뜻이다.
→ 시스템 안에 CPU가 하나만 있는 경우는 의미가 없고, CPU가 여러개 있는 프로세스가 있다고 할 때,
이 프로세스가 좋아하는 CPU는 1번, 3번, 5번 이라고 할 때,
이 프로세스에 속한 스레드들은 1번, 3, 5번에서 가능하다면 실행을 시키라는 의미이다.
Q. 왜 이 기능이 스레드 단위가 아니라 프로세스 단위로 존재할까?
→ 이 경우는 프로세스 단위로 관리되는 것이 맞다.
스레드 단위로 관리되는 정보가 아니다.
왜냐하면, Default Processor affinity 이 정보와 연관된 것은 Cache이다.
프로그램 → 스레드가 여러개 → 스레드 한 개를 CPU1에서 실행
↳ 이 프로그램의 code, data가 CPU1의 cache에 존재한다는 의미
→ 이 프로세스의 다른 스레드를 CPU3에서 실행
↳ 다시 이 프로그램의 code, data를 CPU3의 cache로 Copy 해야한다.⇒ 위의 상황의 경우, 계속 code, data(공유 데이터) Copy 해야하는 상황이 반복된다.
↔ 그게 아니라, 내가 이 프로세스의 다른 스레드를 CPU1에서 실행시키면, CPU1에 내 code, data가 이미 존재할 것이다.
⇒ 그럼 다시 caching 할 필요가 없다.
이 프로세스가 실행은 스레드 단위로 하지만,
실행한다는 말은 코드와 데이터를 읽는다는 뜻이므로
몇 번 CPU Cache 안에 내 code와 data가 있느냐에 따라서 가급적이면 그 CPU에서 다시 copy하지 않고 내 스레드가 실행 됐으면 좋겠다 라고 하는 것이 Default Processor affinity 정보들이다.
Windows Thread Object Attributes
Thread 는 실행의 단위이다.
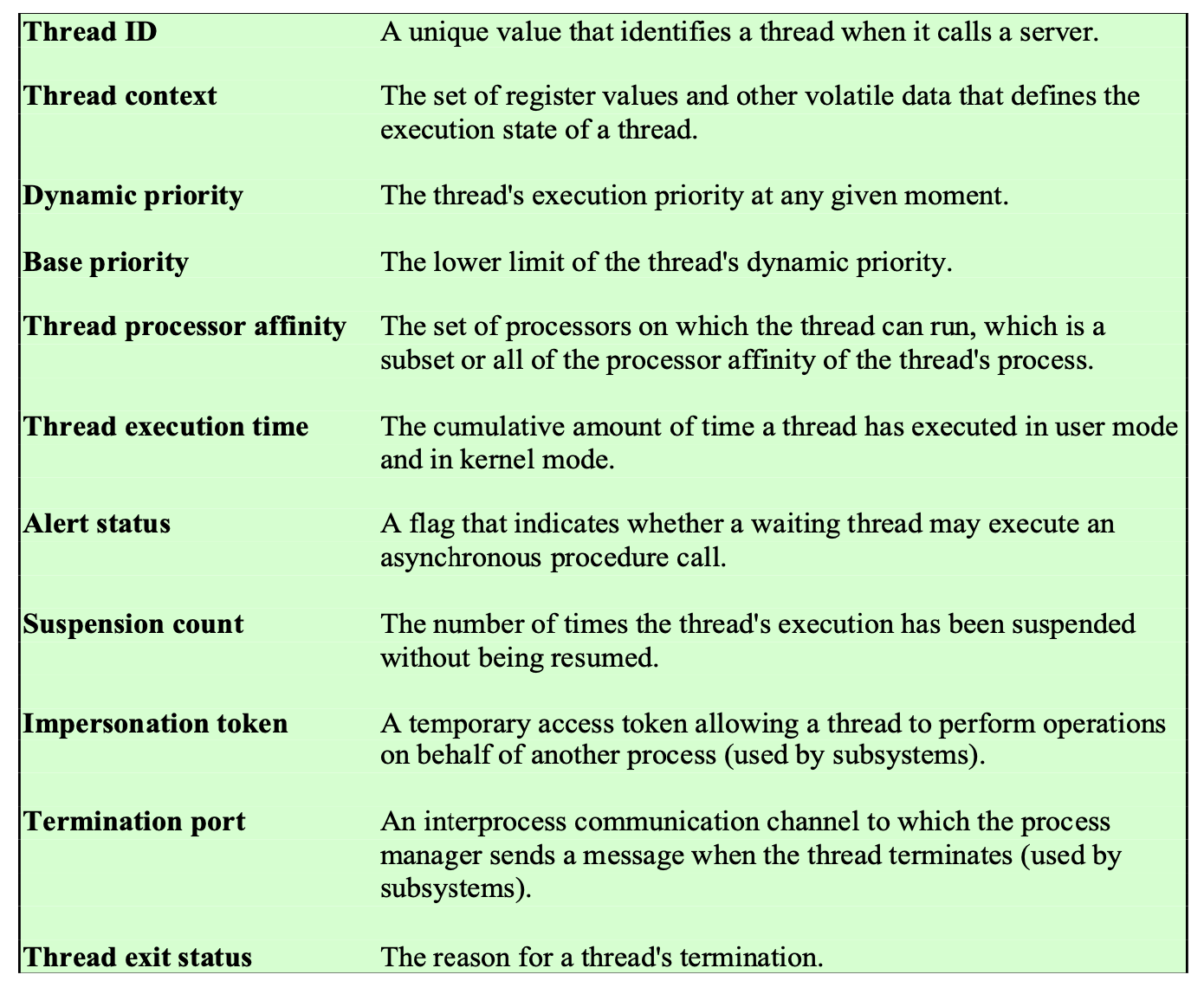
Thread Context
가장 중요한 스레드 속성이다.
스레드는 실행의 단위인데, 이 스레드가 실행이 됐다가 중단이 됐다가 하면서 중단된 지점의 CPU의 상태 를 저장하는 Thread Context 를 가지고 있다.
Dynamic Priority
스레드의 진짜 우선순위를 의미한다.
→ 스레드 별로 다 다르다.
Base Priority
스레드가 속한 프로세스에게 상속 받은 우선순위로 스레드의 minimum priority 이다.
Windows Thread States
Suspend 상태는 Process 단위의 상태인데,
스레드의 상태일 수도 있다.
⇒ Thread의 Suspend Vs. Process의 Suspend 를 구분할 줄 알아야 한다.
두 개의 Suspend를 갖는 프로세스 상태는 4장에서는 더 이상 사용하지 않는다.
→ 프로세스 상태와 스레드 상태를 구분해야하기 때문이다.
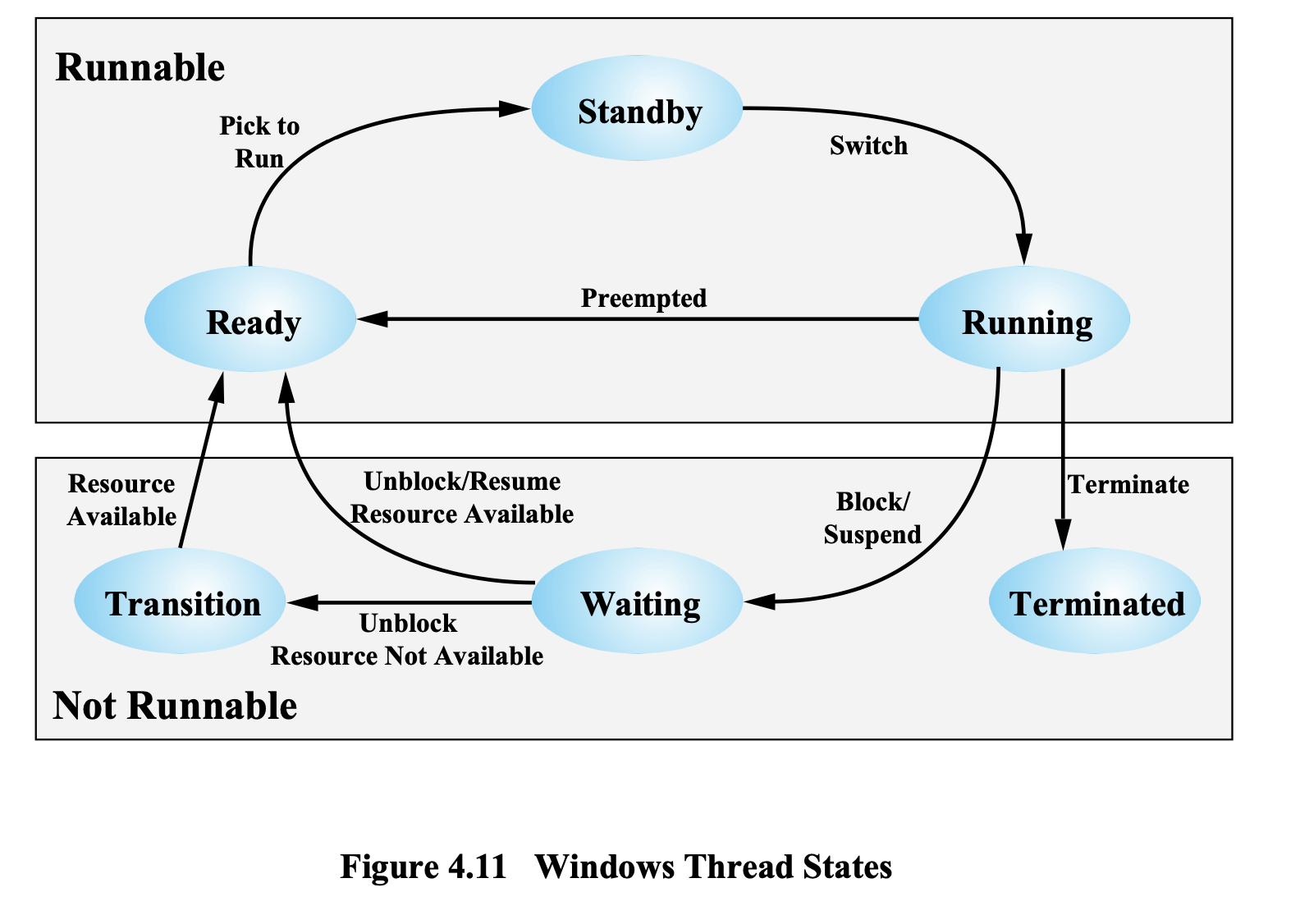
Runnable 상태
Ready → Standby → Running
-
Ready 상태
실행할 수 있는 상태 -
Running 상태
실행하고 있는 상태 -
Standby 상태
Ready Queue에 있는 스레드들 중에서 다음에 실행할 스레드를 하나 골라서 얘를 Standby 상태로 둔다.
그리고 나서 원래 Running 하고 있던 프로세스 스레드가 종료되면 상태를 바꾼다.
Running → Ready
두 가지 이유가 존재한다.
1. Timeout
CPU를 뺏긴다.
2. Priority
우선순위가 더 높은 스레드의 등장으로 인하여 실행 순서에서 밀려나 CPU를 뺏겨,
Ready 상태로 가게 되는 것
Preempted : CPU를 뺏긴다는 의미
Not Runnable
Running → Terminated
Running을 하고 있다가 종료하면 Terminated 상태가 된다.
Running → Waiting
Running을 하고 있다가 I/O 요청을 해서 Block이 된다.
Running을 하고 있다가 동기화이든지, User Request 이든지, 아니면 다른 여러가지 이유로 Thread가 Suspend가 될 수 있다.
Suspension이 발생하는 여러가지 이유 중,
Process 단위에서 발생하는 Swapping을 제외하면, 나머지 형태들은 실행하고 있던 Thread 한테 발생할 수 있는 Suspension 이다.
Windows에서는 Block 상태나 Thread의 Suspend 상태나 구분하지 않고 둘 다 Waiting 상태로 보낸다.
그런데, Waiting 상태라고 하지만, Queue 가 하나가 아니다.
3장에서도 Block 이 발생할 때도 왜 Block이 발생했느냐에 따라 Queue가 다 달랐다.
I/O 작업 → 키보드 입출력, 파일 입출력, .. 각각 다른 큐에 들어가 있다.
당연히 여기도 Block 상태나 Thread의 Suspend 상태 둘 다 Waiting 상태로 표현했지만, 얘네들은 다 다른 Queue에 들어가 있다.
→ Suspend가 발생한 이유에 따라서, Block이 발생한 이유에 따라서
🌟 Block이든 Suspend이든 실행 불가능하다.
그래서 스레드가 지금 당장 실행할 수 없다라는 의미에서 두 상태가 같은 상태에 있는 것을 문제없이 볼 수 있다.
Waiting → Ready
Unblcok/Resume Resource Available
Resume : 기다리고 있던 I/O 작업 종료했거나, 동기화 문제 해결이 되어 내가 실행할 차례가 다시 된 것
⇒ Suspend 가 되었다가 다시 실행상태가 된 것
↳ 코드가 없다.
Resource Available : Resource Available일 경우 Ready로 간다.
Waiting → Trasition
Unblcok Resource Not Available
Resource Not Available : Resource Not Available일 경우 Trasition 상태로 간다.
Trasition 상태에 있는 스레드는 이 스레드를 포함하는 프로세스가 하드디스크에 존재하므로, 한참 기다리다보면 메모리가 넉넉해져서 해당하는 프로세스를 다시 메모리로 가지고 오게 된다.
이렇게 되면 resource가 available 하게 되고, 해당하는 스레드는 Ready 상태로 다시 이동하게 된다.
Q. Waiting → Ready Vs. Waiting → Trasition 차이?
Resource ?
스레드가 suspend나 blcok으로 waiting에 있는데,
이 스레드를 포함하는 프로세스가 스레드를 3개 가지고 있었는데,
이 프로세스가 가진 스레드들이 모두 Block이나 Suspend되어 Waiting 상태에 가있게 되면 더 이상 실행할 스레드가 없게 된다.
이럴 때, MidTerm Scheduler 가 이 프로세스는 실행할 스레드가 하나도 없으니까 Swapping Area 로 옮겨야 되겠다 결정을 하게 된다.
⇒ 스레드들은 Block이나 Suspend된 채로 프로세스에 담겨 Swapping Area로 이동하게 된다.
⇒ Process 상태가 Swap out 되어서, 프로세스가 Suspend 상태 가 되게 된다.
이 상황에서 Waiting 상태에 있던 프로세스에 I/O 작업이나 동기화 작업이 끝 났는데 프로세스가 Swapping Area에 있어서 코드가 존재하지 않게 된다.
이 스레드는 메모리에 올라와 있지 않은 상태이다.
이럴 때 Resource Not Available 하다고 한다.
그렇지 않고, 해당하는 스레드를 포함하는 프로세스가 계속 메모리에 잘 있으면,
즉, 스레드가 한 두개 suspend나 block이 되어 있지만 나머지 스레드들이 계속 실행을 하고 있는 경우 ,
또는 OS가 메모리가 넉넉하다고 판단해 굳이 Swap out 하지 않은 경우 Resource Available 상태라고 한다.
즉, Resource Available 과 Resource Not Available 상태의 차이는,
해당하는 스레드를 포함하는 프로세스가 메모리에 있는지 아니면 Swapping Area(하드디스크)에 존재하는지?
→ 좀 더 정확히, 프로그램 데이터와 코드가 리소스이므로 이 프로그램 데이터와 코드를 사용할 수 있는지? (메모리에 있으면 사용 가능, 하드디스크에 있으면 사용 불가능)
Trasition → Ready
Unblcok Resource Not Available
Trasition 상태에 있는 스레드는 이 스레드를 포함하는 프로세스가 하드디스크에 존재하므로, 한참 기다리다보면 메모리가 넉넉해져서 해당하는 프로세스를 다시 메모리로 가지고 오게 된다.
이렇게 되면 resource가 available 하게 되고, 해당하는 스레드는 Ready 상태로 다시 이동하게 된다.
Windows에서는 프로세스의 suspension 과 스레드의 suspension 을 따로 분리 해서 관리한다.
스레드들은 suspend가 됐을 때, blocked된 스레드와 같이 waiting 상태에 포함이 된다.
그런데, 프로세스 상태와 스레드 상태가 따로 관리가 되다 보니,
스레드가 waiting 상태에서 깨어났을 때,
해당하는 스레드를 포함하는 프로세스가 메모리에 있을수도 있고 없을 수도 있는 상황이 일어날 수 있다.
⇒ 그것 때문에 Transition 이라고 하는 상태가 존재하는 것이다.
Sloaris Processes and Threads
Window System은 Kernel Level에서 Multi-Threading을 지원하지만,
Sloaris System은 Combined된 Approach 를 사용한다.
⇒ Sloaris에서는 User Level 에서 Multi-Threading 을 지원하는 User Level Library를 가지고 있고, Kernel 에서도 당연히 Multi-Threading 을 지원한다.
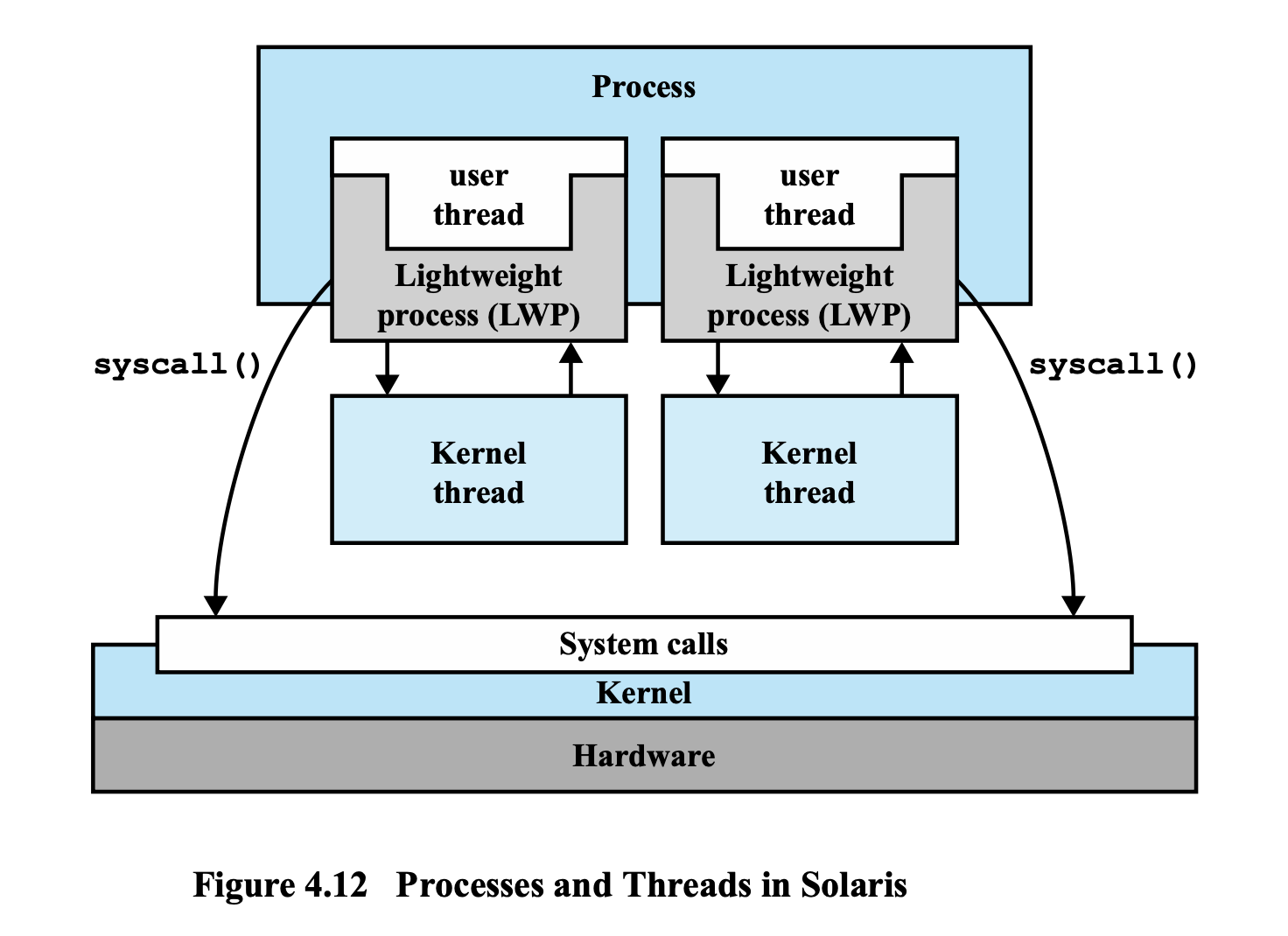
위의 그림을 보면 두 개의 user thread 를 포함하는 Process가 있다.
→ 이 프로그램이 User Thread 두 개로 만들어졌는데,
이 두 개의 User Thread 를 관리하는 것은 application-level thread-library 이다.
⇒ User Thread는 Kernel에서 안보이게 된다.
그런데, 얘네들이 실행을 하려고 Kernel Level 에 Thread 를 Create 한다라고 하는 명령을 사용하게 되면,
Kernel에서는 새롭게 스레드를 하나 만드는데,
스레드라고 부르지 않고, Kernel Level Thread 를 Light Weight Process 라고 부른다.
Kernel Level Thread → Light Weight Process
Light Weight Process 로 User 가 만든 User Thread들을 실행 한다.
그림을 보면, user thread가 하나의 Light Weight Process에 매핑이 되어서, 실행이 되고 있는 상황인 것을 확인할 수 있다.
쉽게 생각하면, 다음 그림과 같다.
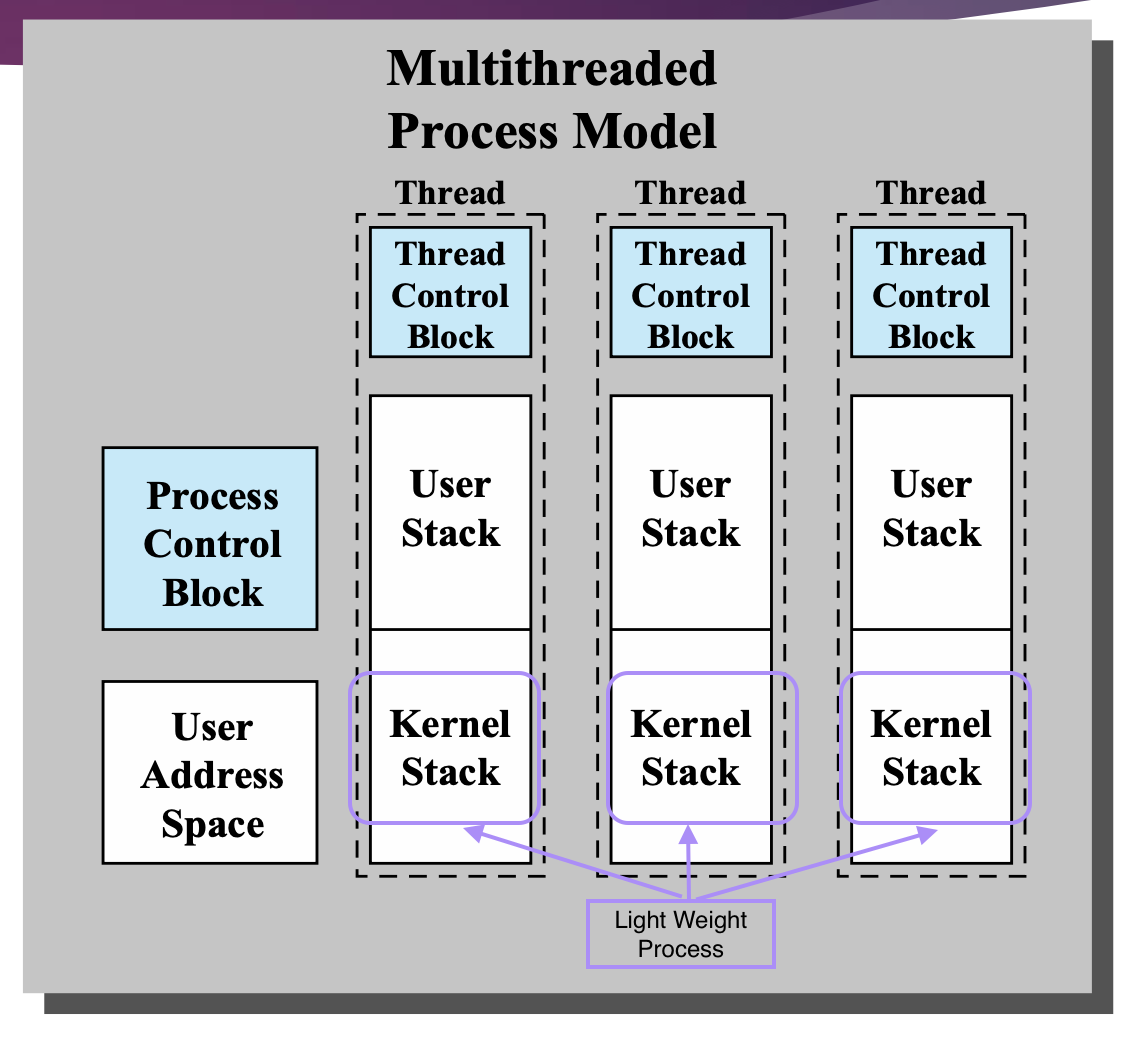
하나의 프로세스 안에 있는 커널에서 관리되는 프로세스는,
하나의 프로세스 안에 Light Weight Process 가 세 개 있는 모양으로 관리된다.
Sloaris 는 Combined된 Approach라 User-Level Thread가 있고,
Kernel-Level Thread가 있는데,
Kernel-Level Thread를 Kernel-Level Thread라고 안부르고
Light Weight Process 라고 부른다.
근데, 그림을 보면 Light Weight Process 에 Kernel Thread가 연결된 것이 보인다.
→ 사실 Solaris에서는 커널 스레드가 굉장히 많다.
이 중 일부는 Light Weight Process랑 매핑이 돼서 Light Weight Process를 실행시킨다. 이때는 Light Weight Process 가 Kernel Thread라고 봐도 무방하다.
문제는, Light Weight Process랑 매핑되지 않은 커널 스레드들이 존재한다는 것이다.
OS 작업을 하는 스레드들은 User Program의 Light Weight Process랑 매핑되지 않은 커널 스레드인채로 작업을 한다.
정리
Sloaris 는 Combined된 Approach이고,
User-Level Thread가 있고, User-Level Thread는 User-Level에서 Thread-Library에서 관리가 된다.
실제로 시스템에서는 만약, 세개의 User-Level Thread를 3개의 Kernel-Level Thread랑 매핑시켜서 실행을 하겠다라고 한다면,
세개의 Light Weight Process로 관리가 된다.
즉, 프로세스 이미지 안에는 Light Weight Process가 세 개 있는 것이다.
Light Weight Process가 실행을 할 때, 시스템 안에 있는 커널 스레드랑 매핑이 돼서 실행이 된다.
중요한 것은 Light Weight Process랑 매핑되지 않은 커널 스레드들이 존재한다.
Solaris Thread States
상태들의 이름을 희안하게 붙여 놨다.
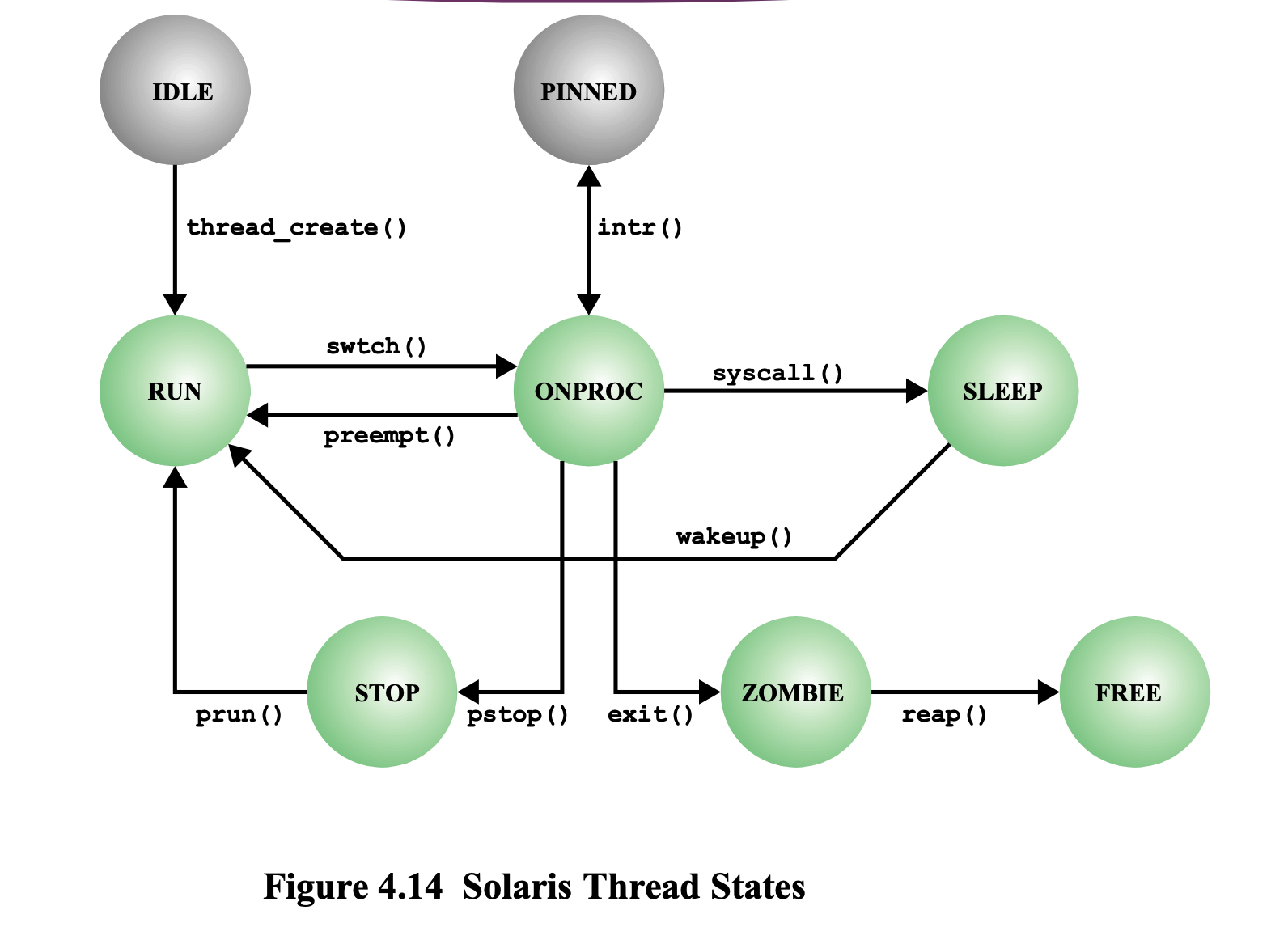
-
RUN상태 =READY상태 -
ONPROC(OnProcessor) 상태 =RUNNING상태 -
SLEEP상태 =BLOCKED상태 -
STOP상태 =SUSPEND상태
IDLE
IDLE 상태
IDLE 상태는 어떤 누구 하고도 매핑되지 않은 스레드의 상태이다.
실행을 시작하기 전의 상태이다.
IDLE → RUN
Ligth Weight Process 와 매핑이 되면,
얘가 READY 상태가 된다.
RUN → ONPROC
READY 상태에 있다가 Switching이 되면, Running 상태가 된다.
ONPROC → RUN
Running 상태로 있다가 다시 Ready 상태가 되는 이유가 두가지 존재한다.
- Timeout
- 우선 순위가 더 높은 스레드의 등장
위의 두가지 이유로 인하여 Running 상태에 있던 스레드가 CPU를 빼앗겨 Ready 상태가 된다.
ONPROC → SLEEP → RUN
실행을 하다가 I/O 요청과 같은 System call을 요청하면, Blocked 상태가 된다.
Blocked 상태에 있는 스레드는 Blocked Queue 에 들어가 있다가,
한참 지나서 I/O 작업이 완료되면, 다시 Ready 상태로 돌아가게 된다.
ONPROC → STOP → RUN
한참 실행을 하다가, 동기화라든지, User Request 라든지, 여러 다른 이유로 Suspend가 되면, STOP 상태로 가게 된다.
STOP 상태에 있던 스레드는 Suspension의 이유가 되었던 문제가 다 해결이 되면, 다시 READY 상태로 돌아오게 된다.
Windows와 Solaris의 다른점
Windows
Blocked인 경우, Suspend인 경우 다 Waiting이라고 하는 하나의 상태로 간주
Solaris
Blocked인 상태와 Suspend 상태를 별개의 형태로 관리한다.
→ 스레드의 상태와 프로세스의 상태는 둘 다 별개로 관리한다.
ONPROC → ZOMBIE → FREE
Running을 하고 있다가 스레드를 종료하게 되면,
ZOMBIE 상태로 가게 된다.
ZOMBIE
ZOMBIE 상태는 스레드는 종료했지만, 이 스레드를 만든 스레드 즉, 부모 스레드에게 전달될 정보가 남아있는 상태이다.
⇒ 그래서 스레드를 완전히 없애지 못하고 최소한의 정보들만 남겨 놓은 상태이다.
그러다가 정보들이 다 전달이 되고 나면, FREE 상태가 되게 된다.
PINNED
PINNED 상태
Running 을 하고 있다가 인터럽트 가 발생한다.
인터럽트가 발생하면, 인터럽트 처리를 하기 위해서 OS 코드 가 실행되게 된다.
근데 Light Weight Process 랑 매핑되지 않는 Kernel Thread 들을 가지고 있는데, 그 Kernel Thread 들이 시스템 작업 을 한다.
⇒ 즉, 스레드가 실행하다가 중단이 되면, 이 스레드를 READY Queue 로 보내는 것이 아니라,
PINNED 상태로 실행을 하고 있던 CPU에 꽂아 놓는다.
꽂아 놓은채, 스레드(OS 작업을 하는 커널 스레드)가 나타나서 필요한 인터럽트 처리를 한다.
이런 인터럽트 처리를 다하고 종료시키려면, 종료시키지만,
그렇지 않은 경우에는 해당하는 스레드를 다시 실행시킨다.
⇒ 인터럽트가 발생하면 PINNED 상태로 갔다가,
인터럽트 처리가 끝나면, 다시 Running 상태로 돌아가 실행할 수도 있다.
왜 PINNED 상태를 이용하여 처리를 할까?
(모든 시스템이 어떤 상태를 가지고 있다라는 말은 이유가 존재하는 거다.)
1. 불필요한 프로세스 스위칭을 막는다.
PINNED 상태로 가서 잠시 대기하다가 다시 실행하는 것이다.
Solaris 시스템은 최신 버전의 UNIX 계열의 시스템이다.
UNIX도 프로세스 내부에서 OS를 실행시켜, 불필요한 스위칭을 막는 방법을 사용한다.
Solaris 시스템도 비슷한 방법인데, 프로세스 내부에서 OS를 실행시키진 않는다.
→ 별개의 커널 스레드로 실행하지만, 이 실행하고 있던 스레드를 그냥 쫓아내진 않는다.
2. 불필요한 Caching 작업을 줄인다.
만약 스레드를 쫓아냈다가 커널 작업이 굉장히 오래 걸려서 Ready Queue 로 보내는데,
Ready Queue 로 가게 되면, (만약 시스템에 CPU가 하나밖에 없다면, 아무 의미가 없겠지만) 시스템 안에 CPU가 10개쯤 있다고 하면,
현재 스레드가 CPU1의 작업을 하다가 Ready Queue로 갔을 때 마침 CPU2가 비어있어서 Ready Queue로 가자마자 다시 작업을 한다.
↔ 하지만 이러한 처리는 캐싱을 다시 해야하기 때문에 좋지 않다.
CPU가 바뀌면 캐싱 작업을 다시 해야한다.
→ 당연히 시간이 어마어마하게 걸리게 된다.
캐시라는 것의 효과?
→ 100번 중 95번은 캐시에서 데이터와 코드를 읽어서 해결할 수 있고,
5번 정도만 메모리에 가서 해결하면 된다.
캐시는 CPU와 속도가 거의 비슷하고 메모리는 속도가 어마어마하게 느리다.
⇒ 캐싱의 유무 에 따라 프로그램 실행 속도의 차이 가 커지게 된다.
⇒ Ready Queue 로 갔다가 다른 CPU를 실행시키느니,
차라리 Kernel 작업 을 하는 동안, PINNED 상태로 대기를 하다가 실행을 계속하면, 이미 캐싱이 되어 있는 상태이기 때문에 더 빠르다.
Linux Tasks
Linux는 멀티스레딩을 제공한다고 볼수도 있고 제공하지 않는다고 볼수도 있다.
애매하다.
Linux에서 Process = Task
Task는 아래와 같은 데이터 구조를 갖는다.
- State
- Scheduling information
- Identifiers
- Interprocess communication
- And others
Linux Threads
Thread = Task = Process
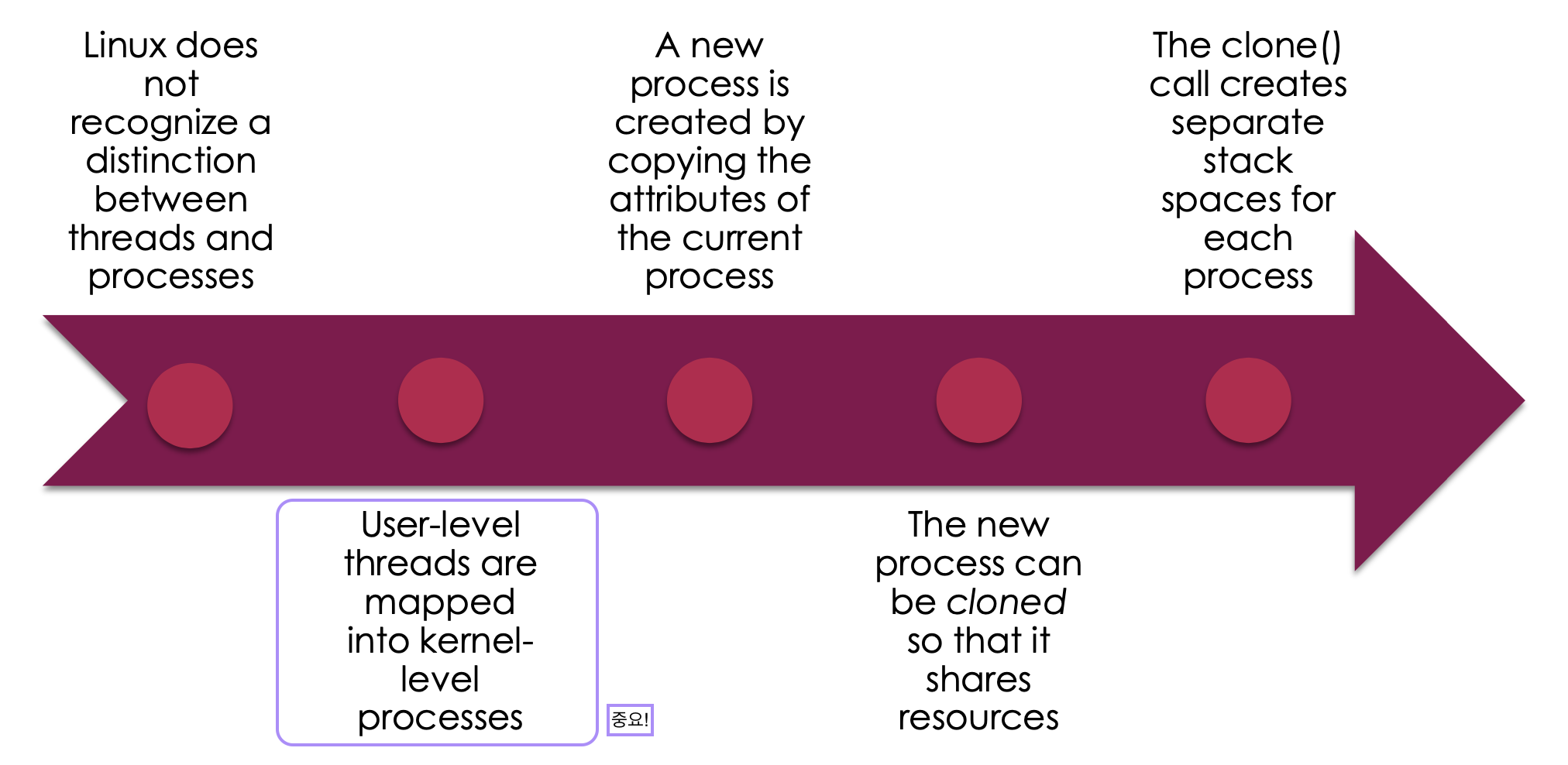
1. Linux는 Thread와 Process를 구분하지 않는다.
Task 안에 스레드가 존재하는 것이 아니다.
⇒ Thread = Task = Process
2. User-Level Thread들은 Kernel-Level Process 들과 매핑된다.
(🌟)
User-Level에서 Thread를 하나 만들 때, Kerenl에서는 Thread가 만들어진 것이 아니라 Process가 하나 만들어 진 것이다.
⇒ 즉, 내가 Thread를 5번 만든 것은 시스템에서는 Process가 5개 만들어진 것과 같다.
3. 새로운 프로세스는 기존의 프로세스의 Attiribute를 Copy해서 생성된다.
4. 새로운 프로세스는 Cloned라는 명령어로 만들어져서 Resources를 공유한다.
프로세스를 fork() 로도 만들 수 있고, clone() 으로도 만들 수 있는데
clone() 으로 만들면, Resources를 공유한다.
5. Clone() 은 Task 별로 별도의 Stack 공간을 만든다.
Linux에서 Clone() 과 Fork()
⇒ 자원과 실행을 구분한다.
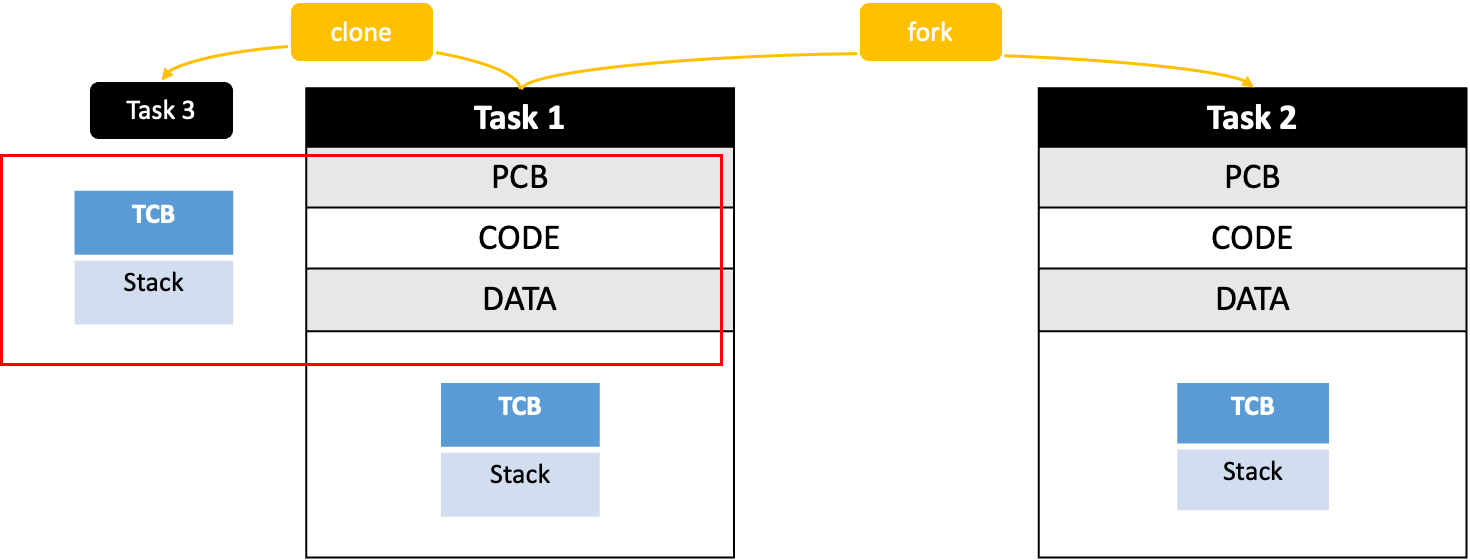
Fork()
Process 이미지 그대로 Copy하여 새로운 Task를 생성한다.
Clone()
Program code, data, ... 자원 과 관련된 정보는 Task1과 공유 하고,
실행 과 관련된 정보(Stack)만 새로 생성 한다.
Thread 가 생성된 것 같지만, OS는 Process와 Thread를 구분하지 않는다.
⇒ Kernel 입장에서는 프로세스(Task)가 3개 실행되고 있다.
⇒ 통신할 때 시간이 적게 든다.
↳ Multi-Threading 과 같은 효과가 있다.
Multi-Threading 을 지원한다고 봐도 무방하다. (같은 시간이 소요된다.)
Linux Process/Thread Model
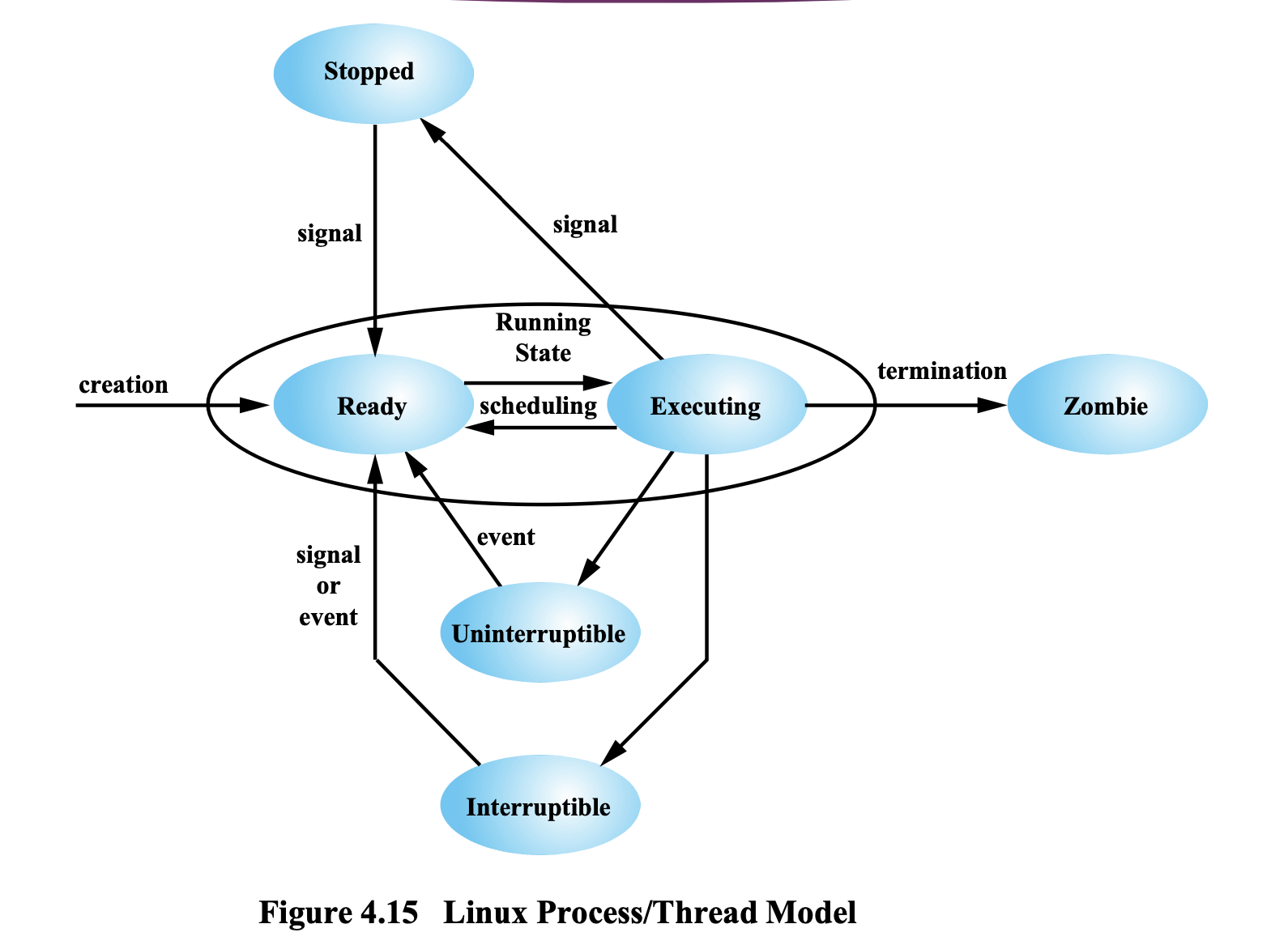
Ready ↔ Executing
Ready 상태로 대기하다가 Dispatching 이 되면,
Executing Running 상태가 된다.
Timeout에 의해서 또는 우선순위가 더 높은 Task에 의해서 다시 Ready 상태로 돌아간다.
Executing → Zombie
실행을 다 마치면 Zombie 상태가 된다.
Executing → Stopped
실행을 하다가 Suspend가 되면 Stopped 상태가 된다.
Blocked
Linux는 Blocked 상태를 두가지로 관리한다.
Uniterruptible 과 Iterruptible 은 둘 다 Blocked 상태이다.
→ 명령 과 Block의 이유 에 따라 달라진다.
프로그램을 실행하다가 scanf 명령어를 입력해서 입력을 받으려고 준비를 할 때,
내가 입력을 줘야하는데 ctrl C를 누르게 되면,
해당하는 Thread가 Blocked 상태에 있었다가 ctrl C 를 누르면 Blocked 에서 풀려나서 Ready 상태로 이동하게 된다.
그 뒤, 다시 실행을 하면 ctrl C 를 왜 눌렀는지에 따라서 실행이 되기도 하고, 종료가 되기도 한다.
Blocked → ctrl C → Ready → Running or Exit
↳ 중요한 건 입력을 받지 못했다는 것이다.
ctrl C: User Program에게 주는 명령어가 아니라 OS에게 보내는 명령어이다.
(OS에게 해당하는 프로세스로 시그널을 보내라는 명령어)
Iterruptible
Block 으로 대기하는 상태이다.
→ 내가 어떠한 목적으로 Blocked 되어 있는데, 외부 시그널이 오면 Blocked 된 상태에서 그냥 포기하는 것을 Interruptible 상태라고 한다.
Uninterruptible
Block 상태로 대기되어 있는데, 이 Block 문제가 해결되기 전까지는
절대 깨어나지 않는 상태이다.
