난 1학년이니까 아무것도 모를 수도 있지라고 생각한게 엊그제 같은데 벌써 3학년이 끝났다.
근데 여전히 아무것도 모른다.
하지만 졸업을 하려면 졸업작품을 만들어야하니까 이제부터 전공이랑 조금 더 친해지려고 velog도 가입했으니까ㅎㅎ
원래 시작이 반이랬다!
종강한 게으른 몸을 이끌고 어제 처음으로 이미지 크롤링을 시도해봤다.
오늘은 인스타그램에 있는 이미지를 다운로드하는 코드를 공부했다.
👇🏻 무지한 저에게 한줄기 희망같았던 영상
파이썬 인스타그램 크롤링 이미지 다운로드 beautifulsoup selenium 사용법
selenium, beautifulsoup4 설치
먼저 코드를 작성하기 전에 해야할 일
$ pip install selenium
$ pip install beautifulsoup4실습 준비
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
import time
import ssl인스타그램 해시태그 주소 확인하기
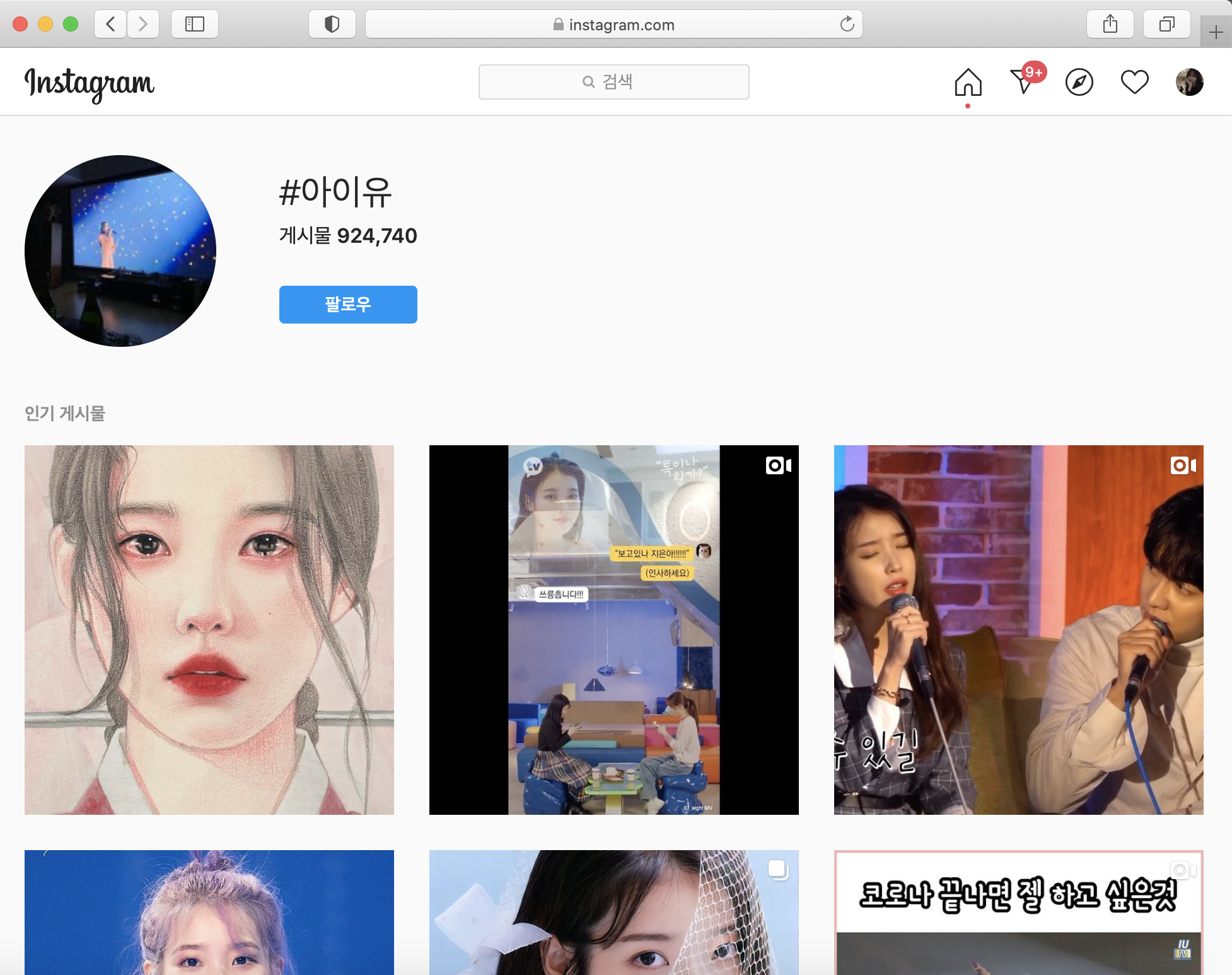
인스타그램에서 #아이유를 검색하면 이렇게 예쁜 아이유가 잔뜩 나온다.
하지만 아이유의 유혹에 넘어가지 않고 침착하게 주소를 가져온다.
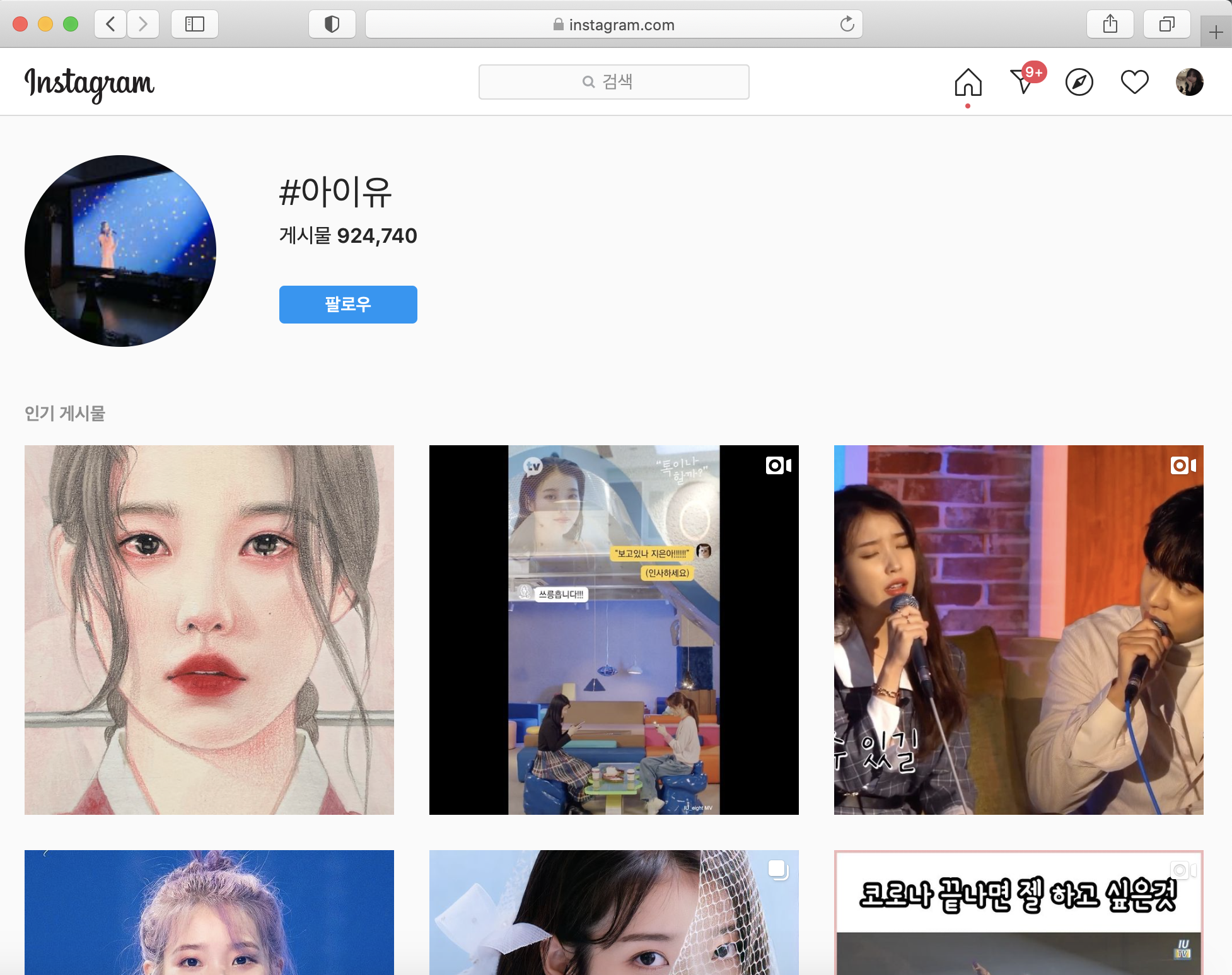
인스타그램 #아이유 주소
이 주소에서 /아이유/라는 부분은 컴퓨터가 알 수 없기 때문에 아스키코드로 변환해줘야한다.
이때 필요한 친구가 바로
from urllib.parse import quote_plus이 친구이다.
url 저장
우리가 원하는 태그의 url이 다 다르기 때문에 url은 계속 바뀌게 된다.
따라서 매번 코드에서 url을 바꿔주는 귀찮은 일을 피하기 위해 base가 될 url(https://www.instagram.com/explore/tags/) 우리가 원하는 태그의 url을 합친 url을 변수에 저장해둔다.
context = ssl._create_unverified_context()
search = input('검색할 태그 : ')
baseUrl = 'https://www.instagram.com/explore/tags/'
newUrl = baseUrl + quote_plus(search)원하는 페이지 가져오기
인스타그램에서 보이는 모든 게시글들은 아래와 같이 자바스크립트로 되어있기 때문에 단순히 beautifulsoup만으로는 페이지를 가져올 수 없다.
이때 사용하는 친구가
from selenium import webdriver강의에서는 크롬을 썼지만 난 사파리를 쓰기 때문에 크롬만 사파리로 스을쩍 바꿔줬다.
driver = webdriver.Safari()
driver.get(newUrl)이렇게 하면 인스타그램에서 내가 입력한 태그를 검색한 창을 가져오기까지가 끝났다.
beautiful과 urlopen을 이용할 때는 urlopen으로 url을 열고 read를 한 다음에 beautifulsoup으로 분석을 했다.
selenium을 사용할 때는 driver.page_source를 사용
-> driver의 페이지 소스를 불러와서 html에 저장
html = driver.page_source
soup = BeautifulSoup(html)이미지 가져오기
페이지 소스보기를 통해 이미지 하나를 나타내는 클래스를 찾아본다.
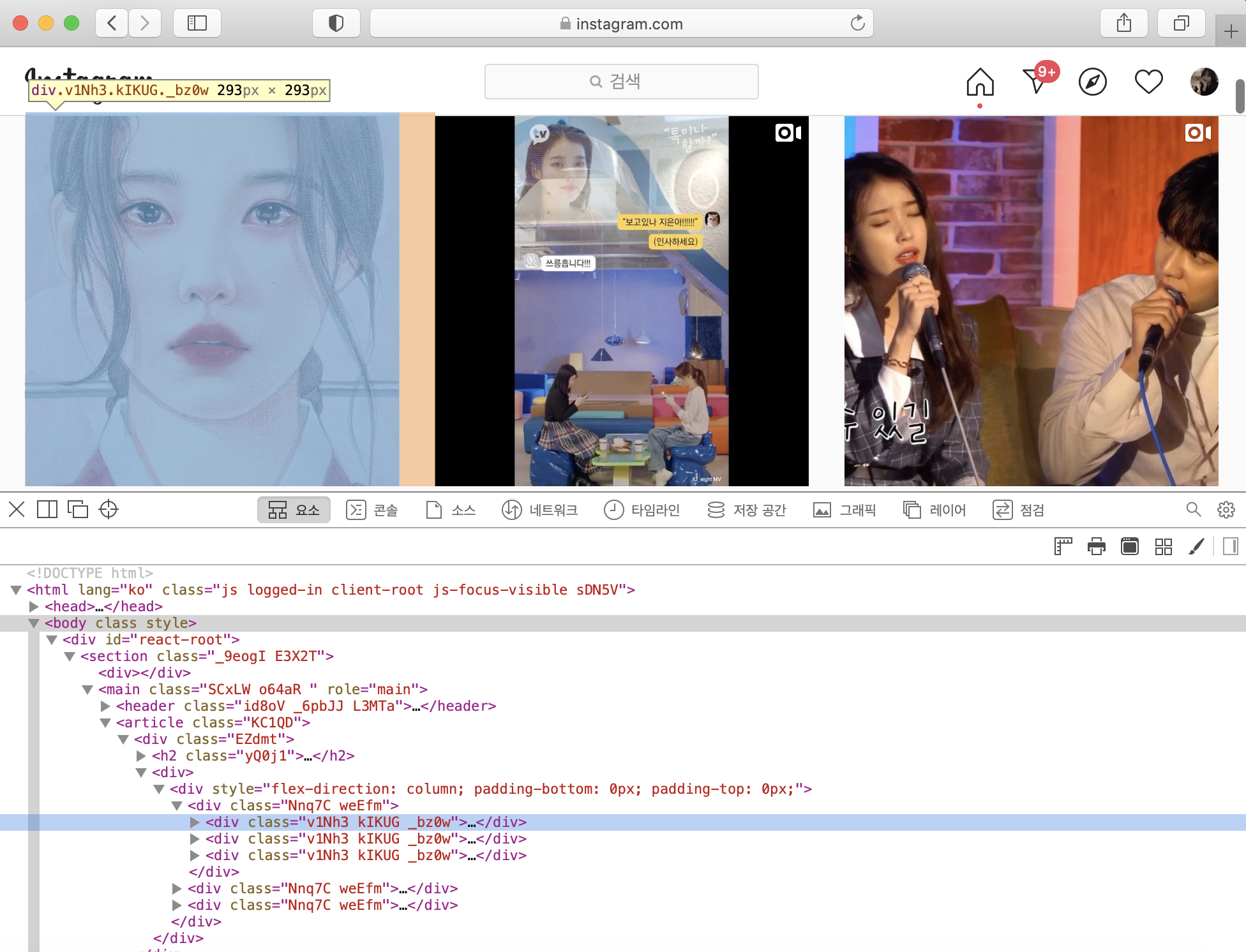
글씨가 작아서 잘 안보이겠지만
v1Nh3 kIKUG _bz0w
라고 쓰여있다.
soup에서 'v1Nh3 kIKUG _bz0w'를 찾아서 select를 한다.
이때 클래스를 가져와야 하니까 맨 앞에 .(마침표)를 찍어준다.
위와 같은 경우는 클래스를 띄어쓰기로 구분하고 있기 때문에 띄어쓰기를 지우고 .(마침표)로 바꿔서 insta라는 변수에 저장한다.
insta = soup.select('.v1Nh3.kIKUG._bz0w')-> 가져온 페이지에서 이러한 태그를 가진 거를 불러와서 저장함
time.sleep 사용
driver가 뜨는 시간이 좀 걸리기 때문에 몇초 쉬었다가 분석을 시작한다는 의미
driver = webdriver.Safari()
driver.get(newUrl)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html)driver를 열고 3초 쉬었다가 분석 시작
이미지 가져오기 및 저장
페이지 소스에서 태그를 타고 쭈우우욱 내려가보면 img alt라는 친구가 보인다. 이 친구가 이미지를 갖고 있다.
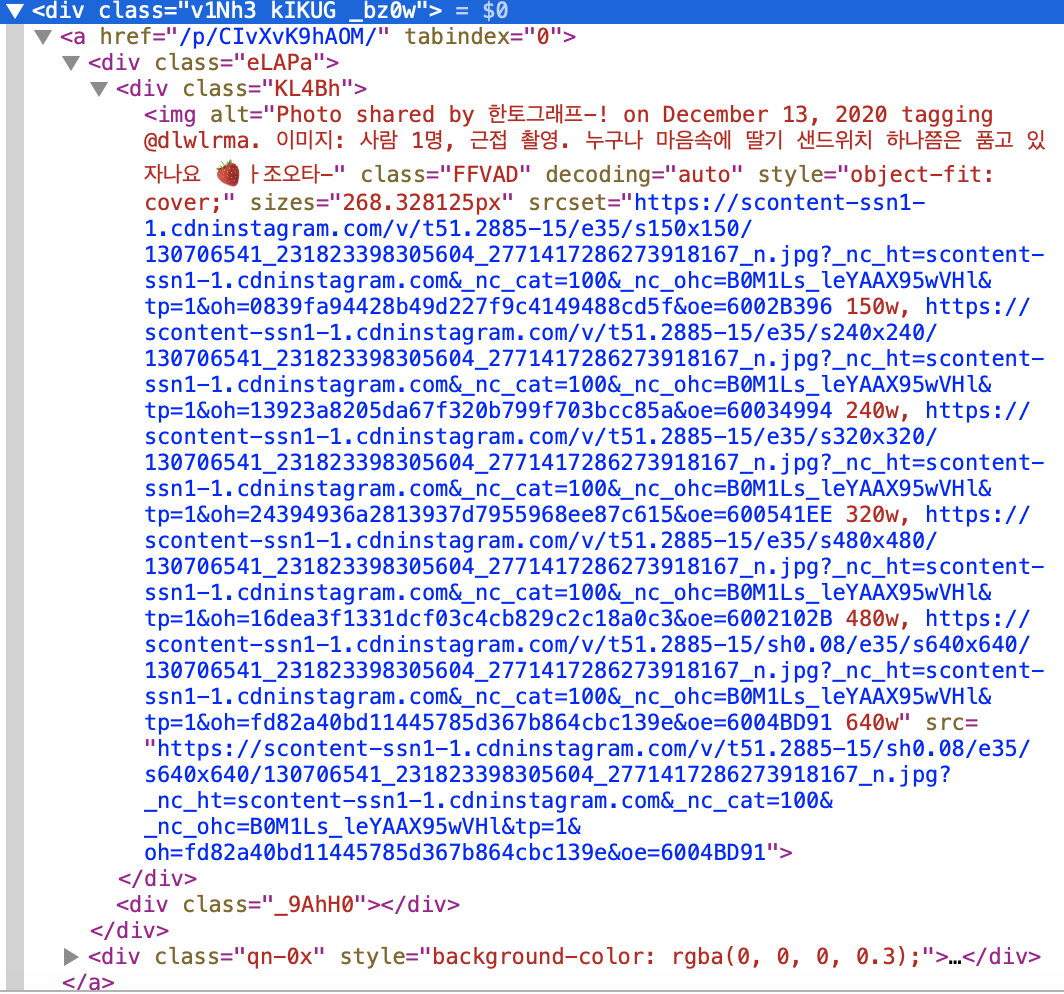
우리는 이 중에서 src를 가져오면 된다.
이미지를 저장할 img 폴더를 실행 파일이 있는 폴더에 미리 만들어 준다.
👇🏻이미지를 불러와서 저장하는 코드
for i in insta:
# 가져온 페이지에서 '.KL2Bh' 클래스를 가진 하나를 불러와 img 태그 중에서 src를 불러와 저장
imgUrl = i.select_one('.KL4Bh').img['src']
with urlopen(imgUrl) as f: # imgUrl을 f라고 부름
# img 폴더 아래 검색한태그1.jpg, 검색한태그2.jpg, ・・・ 순으로 저장
# 텍스트 파일이 아니기 때문에 w(write)만 쓰면 안되고 b(binary)를 같이 씀
with open('./img/' + search + str(n) + '.jpg', 'wb') as h:
img = f.read() # f를 읽어서 img에 저장
h.write(img) # h에 img 내용을 씀
n += 1💻 프로그램 코드
from urllib.request import urlopen
from urllib.parse import quote_plus
from bs4 import BeautifulSoup
from selenium import webdriver
import time
search = input('검색할 태그 : ')
baseUrl = 'https://www.instagram.com/explore/tags/'
newUrl = baseUrl + quote_plus(search)
driver = webdriver.Safari()
driver.get(newUrl)
time.sleep(3)
html = driver.page_source
soup = BeautifulSoup(html)
insta = soup.select('.v1Nh3.kIKUG._bz0w')
n = 1
for i in insta:
print('https://www.instagram.com' + i.a['href'])
imgUrl = i.select_one('.KL4Bh').img['src']
with urlopen(imgUrl) as f:
with open('./img/' + search + str(n) + '.jpg', 'wb') as h:
img = f.read()
h.write(img)
n += 1
print(imgUrl)
print()
driver.close()실행결과
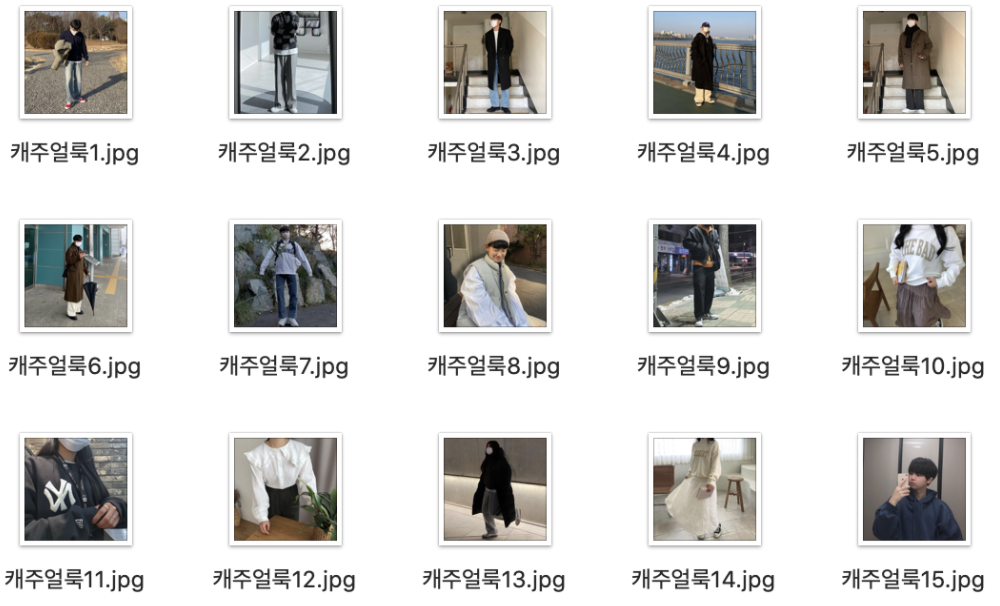
캐주얼룩을 검색했을 때 요렇게 이쁘게 저장된 걸 확인할 수 있다.