🎈 Intro
진행 중인 프로젝트는 프론트엔드 개발이 아직 완료되지 않아 실제 사용자에게 서비스 제공은 불가능한 상태였습니다.
이런 상황에서 내가 구현한 API가 트래픽 부하 상황에서 어떻게 반응하는지, 그리고 어떻게 처리해야 하는지 알아보기 위해 성능 테스트를 진행하였습니다.
성능 테스트를 진행, 병목 지점을 분석하고 개선하는 과정을 천천히 따라가봅시다.
🚀 서버 성능 테스트란 ?
API 요청이 많은 상황에서 서버가 어떻게 동작하는지, 얼마나 많은 트래픽을 처리할 수 있는지 확인하기 위해 수행하는 테스트입니다.
테스트의 목적에 따라
- smoke 테스트
- stress test
- load test
로 나눠집니다.
🔍 서버 성능 테스트의 목적
요청을 얼마나 잘 처리하고 시스템에서 병목 현상이 발생하는 지점을 식별하기 위해서
성능 테스트 결과를 기반으로 서버 또는 인프라 구조를 확장 또는 축소하는 결정을 내리기 위해서
⏰ 서버 성능 테스트는 언제 진행할까?
1. 기존 서비스의 트래픽 증가 예상
기존 기업의 서비스라면, 평소보다 트래픽을 훨씬 많이 받아야 하는 경우에 성능 테스트를 진행합니다.
2. 새로운 서비스 오픈
트래픽 유입이 많을 것으로 예상되는 새로운 서비스를 오픈할 때 성능 테스트를 진행합니다.
성능 테스트 종류
🔥 스모크(smoke) 테스트
시스템의 기본 기능이 정상적으로 동작하는지를 확인하는 것이 목적입니다.
큰 문제 없이 애플리케이션의 주요 기능들이 잘 작동하는지를 빠르게 확인합니다.
📊 부하(load) 테스트
부하 테스트는 병목 현상을 확인하고, 목표치까지 개선하는 것이 목적입니다.
💥 스트레스 테스트 ?
스트레스 테스트는 과부하 상태에서 어떻게 동작하는지 확인하고, 개선하는 것이 목적입니다. 서버가 최대 부하를 감당할 수 있는지 테스트합니다.
📈 성능 테스트 실행 결과
🔥 smoke 테스트
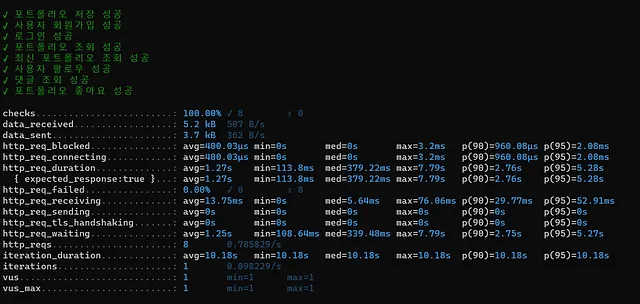
스크립트 및 결과
이 테스트는 k6를 이용하여 진행하며, 모니터링 도구로 Grafana,InfluxDB를 활용합니다.
smoke 테스트는 주요 기능들이 잘 작동하는지를 확인하는 것이기 때문에,
1명의 vuser을 설정하여, 로그인 api부터 포트폴리오 조회, 포트폴리오 좋아요, 최신 포트폴리오 조회, 회원가입 , 댓글 조회 , 사용자 팔로우 조회 api를 smoke 테스트 하였습니다.
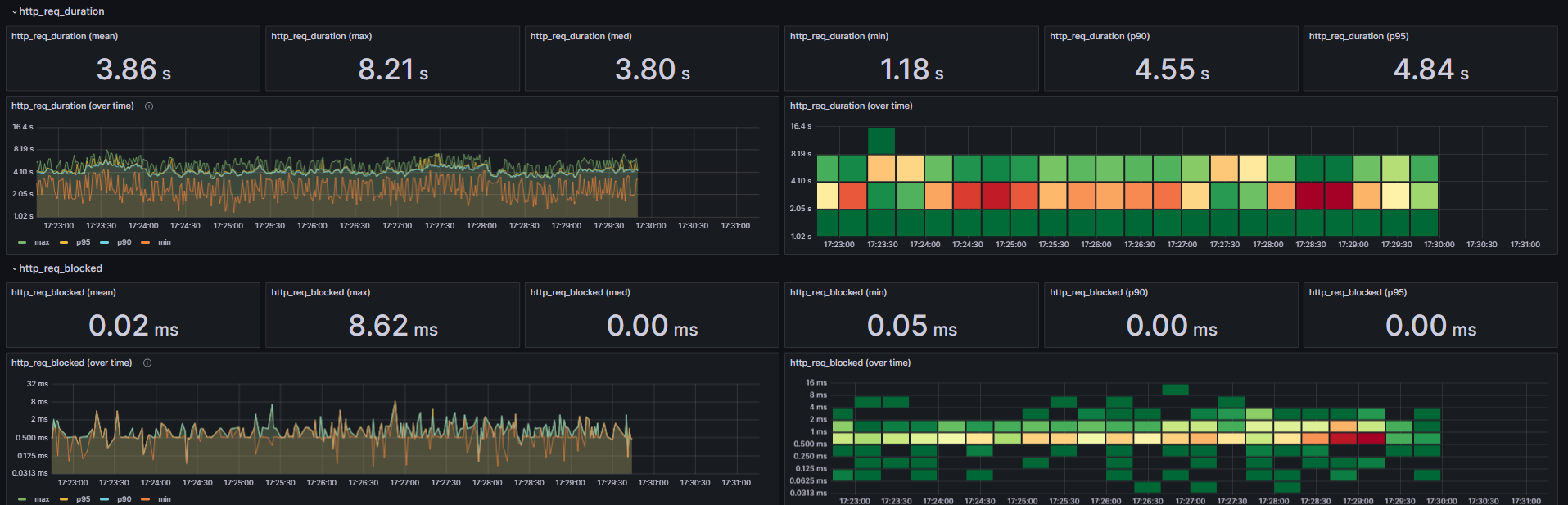
🔥 smoke test 결과
📊 load 테스트
📋 load 테스트 스크립트 및 결과 , 개선 과정
load 테스트 스크립트
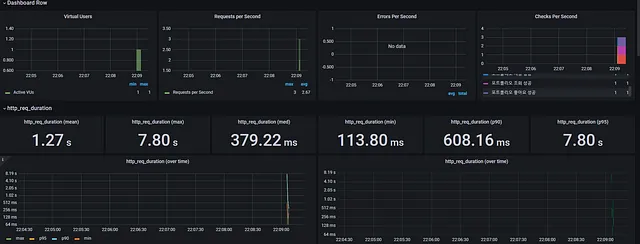
load 테스트는 약 10분간 200명의 vuser로 진행했습니다.
원래는 30분 이상 진행을 권장하지만, 시간 관계상 10분만 진행하였습니다.
stages: [
{ duration: '3m', target: 200 },
{ duration: '7m', target: 200 }
],테스트 스크립트를 실행시킨 후, Grafana를 통해 모니터링하였습니다.
그런데 Vuser가 70명일 때부터
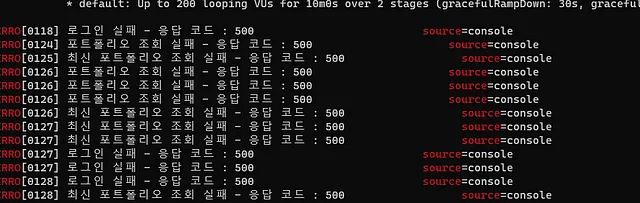
위 사진과 같은 에러가 나서, 로그를 확인해보니
Could not open JPA EntityManager for transaction;
nested exception is org.hibernate.exception.JDBCConnectionException:
Unable to acquire JDBC Connection이런 에러가 발생했습니다.
✳️ 댓글 조회 api 문제
이 에러가 발생한 건, 로그를 찾아보니, 댓글 조회 api에서 일어난 문제였습니다.
수정 전 코드:
// 댓글 조회 API
@Transactional(readOnly = true)
public Comments getCommentsByPortfolioId(Long portfolioId, Pageable pageable) {
PortfolioEntity portfolioEntity = portfolioService.getPortfolioEntityId(portfolioId);
List<Comment> commentList = commentRepository.findAllByPortfolio(portfolioEntity, pageable)
.map(Comment::fromEntity)
.toList();
if (portfolioEntity == null) {
throw new BadRequestException(ExceptionEnum.REQUEST_PARAMETER_INVALID, "Invalid portfolioId: " + portfolioId);
}
if (commentList.isEmpty()) {
throw new BadRequestException(ExceptionEnum.RESPONSE_NOT_FOUND, "댓글이 없습니다.");
}
Comments comments = Comments.builder()
.comments(commentList)
.totalPages(commentList.size())
.totalElements(commentList.size())
.total(commentList.size())
.build();
return comments;
}✅ 해결 방법
EntityGraph 어노테이션을 활용하여 쿼리를 수정해주니, 해당 에러는 사라지고, 다시 load test를 실행했을 때 위와 같은 오류는 발생하지 않았습니다.
수정 후 코드:
@Transactional(readOnly = true)
public Comments getCommentsByPortfolioId(Long portfolioId, Pageable pageable) {
List<Comment> commentList = commentRepository.findAllByPortfolioId(portfolioId, pageable)
.stream()
.map(Comment::fromEntity)
.collect(Collectors.toList());
if (commentList.isEmpty()) {
throw new BadRequestException(ExceptionEnum.RESPONSE_NOT_FOUND, "댓글이 없습니다.");
}
Comments comments = Comments.builder()
.comments(commentList)
.totalPages(commentList.size())
.totalElements(commentList.size())
.total(commentList.size())
.build();
return comments;
}
- 레파지토리 코드 - -
@EntityGraph(value = "Comment.portfolio", type = EntityGraph.EntityGraphType.LOAD)
List<CommentEntity> findAllByPortfolioId(Long portfolioId, Pageable pageable);댓글 조회 api를 수정한후, 다시 테스트를 진행했을 때는 위와 같은 오류는 발생하지 않았지만, 다른 오류가 발생했습니다.
🔒데드락 문제

데드락때문에 발생했던 오류였습니다.
https://techblog.woowahan.com/2664/
위 블로그를 참고하여 확인하여 커넥션 풀사이즈를 늘림으로써 에러를 해결할 수 있었습니다.
( 해당 오류에 대해서는 깊이 지식을 습득하지 못한 상태라서, 이와 관련된 포스팅은 추후에 보충해서 공부한 후 포스팅할 예정입니다.)
✳️ 최신 포트폴리오 조회 API 문제 발견
하지만 여전히 load test를 돌리면, 80명이후부터 timeout 오류가 발생했습니다.
각 api별로 분리해서 테스트하다보니 병목현상이 일어난 api를 찾았습니다.
"최신 포트폴리오 조회" api가 그 원인이였습니다.
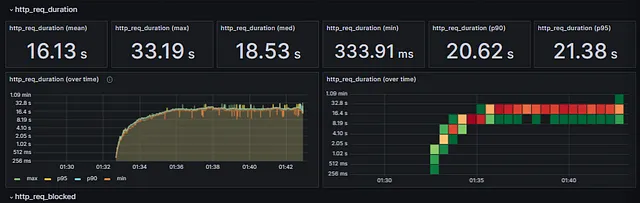
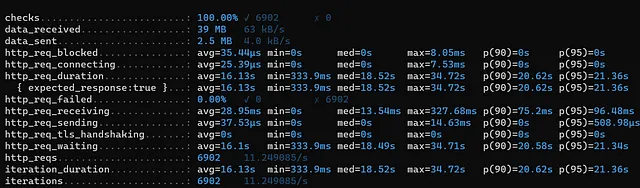
📈 문제 발생 시나리오
Load 테스트를 진행할 때, 200명의 Vuser가 동시에 이 API에 접근하면, 응답 시간이 최대 33.19초까지 길어져서 시스템이 Timeout 오류를 발생시킵니다.
최신 포트폴리오 조회 api
트위터 타임라인 캐시 과정을 참고하여 구현한 api로, 내가 팔로우한 사용자의 포트폴리오를 불러오는 api
팔로우한 사용자의 업데이트된 포트폴리오 id는 redis에 저장되어 캐싱되도록 구현했습니다.
이 API의 응답 시간 문제로 인해 전체 시스템의 성능이 저하되었습니다.
속도를 빠르게 하기 위해 일부러 redis를 도입하여 활용했던 것이였는데,
왜 하필 이 api에서 문제가 발생했던 걸까요??
🔍 문제 원인 탐색
Redis 모니터링
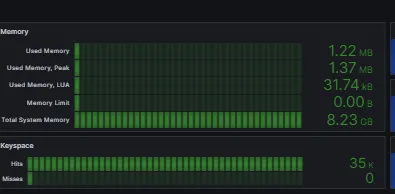
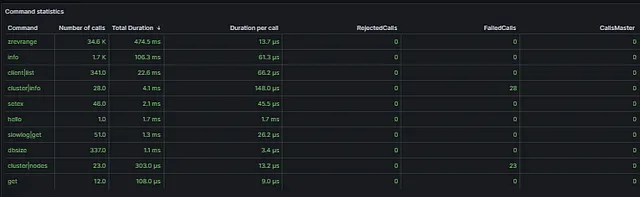
grafana를 통해 redis를 모니터링 해본 결과 redis에서는 문제가 없었습니다.
🔦 코드 검토
그렇다면 코드에 문제가 있을 것같아 코드를 뜯어보았습니다.
- 기존 코드
public List<Portfolio> getLatestPortfolios() {
UserEntity userEntity = userService.getMyUserWithAuthorities();
String redisKey = "user:" + userEntity.getId() + ":portfolios";
Set<String> portfolioIds = stringRedisTemplate.opsForZSet().reverseRange(redisKey, 0, -1);
if (portfolioIds != null && !portfolioIds.isEmpty()) {
List<Long> portfolioIdsLong = portfolioIds.stream().map(id -> Long.parseLong(id.toString())).collect(Collectors.toList());
List<PortfolioEntity> portfolioEntities = portfolioRepository.findByIdInOrderByCreatedAtDesc(portfolioIdsLong);
return portfolioEntities.stream().map(Portfolio::fromEntity).collect(Collectors.toList());
}else {
// 기존 저장소에서 마지막 수록된 포트폴리오 가져오고 Redis에 갱신하는 로직 추가
List<PortfolioEntity> latestPortfolios = portfolioRepository.findLatestPortfoliosByUserId(userEntity.getId());
if (latestPortfolios != null && !latestPortfolios.isEmpty()) {
Map<String, Double> portfolioIdsWithTimestamp = latestPortfolios.stream()
.collect(Collectors.toMap(portfolio -> String.valueOf(portfolio.getId()),
portfolio -> (double) portfolio.getCreatedAt().getTime()));
stringRedisTemplate.opsForZSet().add(redisKey, portfolioIdsWithTimestamp.entrySet().stream()
.map(entry -> new DefaultTypedTuple<>(entry.getKey(), entry.getValue()))
.collect(Collectors.toSet()));
return latestPortfolios.stream().map(Portfolio::fromEntity).collect(Collectors.toList());
}
}
return new ArrayList<>();
}
- - 레파지토리 코드
@Query("SELECT p FROM PortfolioEntity p WHERE p.id IN (:portfolioIds) ORDER BY p.createdAt DESC")
List<PortfolioEntity> findByIdInOrderByCreatedAtDesc(@Param("portfolioIds") List<Long> portfolioIds);
//
@Query("SELECT p FROM PortfolioEntity p WHERE p.user.id = :userId ORDER BY p.createdAt DESC")
List<PortfolioEntity> findLatestPortfoliosByUserId(@Param("userId") Long userId);기존코드에서는 트위터 타임라인 캐시 과정을 참고해서 구현했기 때문에Redis에서 유저의 타임라인에 저장되어있는 포트폴리오의 아이디를 set으로 가져오고,
포트폴리오 아이디가 존재할 경우, DB에서 시간순으로 포트폴리오 아이디를 파라미터로 이용해 List로 포트폴리오 엔티티를 찾아옵니다.
그후 dto로 변환하여 반환합니다.
만약 redis에 포트폴리오 id가 저장된 게 없다면, DB에서 마지막 수록된 포트폴리오 가져오고, Redis에 추가하여 redis와 db가 일관성을 유지하도록 구현했습니다.
🐞 문제점 분석
기존의 코드에서는 다음과 같은 문제점이 있었습니다.
-
페이징 미사용: 결과를 페이징 처리하지 않고 전체 데이터를 한 번에 가져오는 방식은 대량의 데이터에 대해 응답 시간이 느려질 수 있습니다.
-
DB 쿼리 성능: DB에서 포트폴리오를 시간 순으로 정렬하는 쿼리를 사용하고 있어, 성능 저하를 일으킬 수 있습니다.
-
DB 인덱스 부재: DB의 FOLLOW 테이블에 INDEX가 없어서 성능이 저하되고 있습니다.
🛠️ 문제 해결 및 개선
1. DB 인덱스 추가:
DB의 FOLLOW 테이블에 INDEX를 추가하여 성능을 향상시켰습니다.
create index follow_follower_idx
on portfoGram.follow (follower_id);
create index follow_following_idx
on portfoGram.follow (following_id);2. 페이징 처리:
"최신 포트폴리오 조회" API의 코드를 개선하여 페이징 처리를 하도록 수정하였습니다
- 바뀐 코드
public Page<Portfolio> getLatestPortfolios(UserEntity userEntity, Pageable pageable) {
String redisKeyForCurrentUserFollowings = "user:" + userEntity.getId() + ":portfolios";
Set<String> portfolioIds = stringRedisTemplate.opsForZSet().reverseRange(redisKeyForCurrentUserFollowings, 0, -1);
List<Long> followedUserIdsAsLong = portfolioIds.stream()
.map(Long::parseLong)
.collect(Collectors.toList());
Page<PortfolioEntity> portfolioEntityPage = portfolioRepository.findByIdIn( followedUserIdsAsLong , pageable);
Page<Portfolio> portfolio = portfolioEntityPage.map(Portfolio::fromEntity);
return portfolio;
}
- - 레파지토리 코드
Page<PortfolioEntity> findByIdIn(List<Long> Ids, Pageable pageable);Redis에서 타임라인 캐시를 찾아오는 로직은 동일하고,
Redis에서 찾아온 id 리스트들을 파라미터로 DB에서 찾아온 후 , 페이징 처리를 하였습니다.
3. DB 쿼리 성능 개선 :
order by 를 사용한 쿼리를 삭제한 이유는 정렬로 인한 성능 저하 이슈도 있지만
이미 redis에서 타임라인 캐시를 찾아올때, 유저가 팔로우한 포트폴리오 아이디를 역순(최신순)으로 찾아오기때문에 order by를 사용한 쿼리를 이용할 필요가 없었습니다.
🧹 문제점 개선 후 다시 load test 실행했을 때의 모니터링 결과
🔀 수정된 성능 테스트 스크립트
이전 스크립트는 10분동안 200명을 테스트하는것이기 때문에,
스트레스 테스트와 로드 테스트를 혼합해서 사용했다고 생각하여
스크립트를 수정해서 다시 측정하여 비교했습니다.
대상 시스템 범위
- 최신 포트폴리오 조회 API
목표값 설정
- Latency(지연시간): 500ms
- Throughput(처리량):
- 최대 rps: 일별 최대 부하는 보통 평균의 약 10배 정도라고 가정하면 최대 rps는 약 5.8rps
- T = (3 * Think Time) + Latency
Think Time은 사용자가 각 요청 사이에 얼마나 많은 "생각" 시간을 가질 것인지 나타내며, 여기서는 간단하게 평균적으로 요청 사이에 대략적으로 '3초'라고 가정
따라서, T = (3 * 3) + 0.5 = 9.5초
- VUser = (최대 rps * T)
따라서, VUser = (5.8rps * 9.5s) ≈ 55명
k6 스크립트 stages 설정
- 수정한 성능 테스트 스크립트에서는 k6의 stages 옵션을 아래와 같이 설정했습니다.
stages: [
{ duration: '3m', target: 55 },
{ duration: '7m', target: 55 },
],문제점 개선 후 결과 비교
기존 코드 ( 문제점 개선 전 ) 의 결과
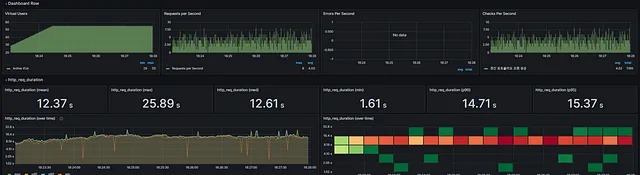
문제점들을 개선 한 후,수정한 코드의 결과 ( 수정한 스크립트 )
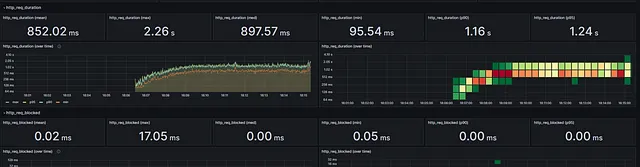
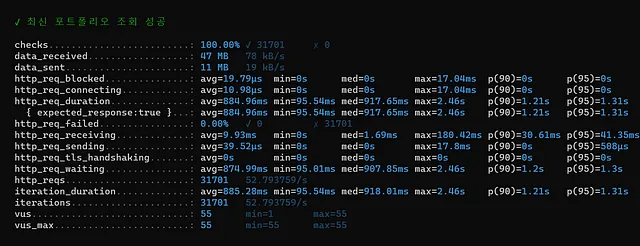
개선 후의 결과를 보면, 응답 시간이 줄어들고 초당 요청 수가 증가했습니다.
📝 성능 테스트를 진행하며 느낀점
성능 테스트를 진행하면서 얻은 경험은 개발에 대한 시야를 확장할 수 있었습니다.
개발이 완료되면 "끝"이라고 생각하기 쉽지만, 그렇지 않다는 것을 알게 되었습니다. 실제로 서비스가 동작할 때는 사용자들이 동시에 많은 요청을 보내게 되고, 이런 상황에서도 서버가 원활하게 작동해야 합니다.
포트폴그램 API를 설계하고 개발한 후에 Jenkins와 Docker를 활용하여 CI/CD 파이프라인을 구축하여 자동 배포 과정까지 마쳤습니다.
그러나 프론트엔드 개발이 아직 완료되지 않아 실제 사용자에게 서비스 제공은 불가능한 상태였습니다. 이런 상황에서 내가 만든 API가 트래픽 부하 상황에서 어떻게 반응하는지, 그리고 어떻게 처리해야 하는지 알아보기 위해 성능 테스트를 진행하였습니다.
성능 테스트 진행 경험을 통해 단순한 최대 성능 측정 너머로 병목 현상이 어디서 발생하는지 지속적으로 모니터링 하며, 이를 개선하기 위해 어떤 조치를 취해야 할 지 학습하는 과정도 경험할 수 있었습니다.
결과적으로, 성능 테스트는 개발 작업의 끝이 아닌 지속적으로 진행되어야 하는 필수적인 단계임을 깨달았습니다. 사용자에게 원활한 서비스를 제공하기 위해 서버 성능을 최적화하고 개선하는 노력이 계속되어야 한다는 것을 깨달았습니다.
앞으로의 개선점
1.성능 개선
개선한 코드도 성능 테스트를 해보면, 1s가 나오기 때문에 사용자들이 불편함을 느끼지 않도록 100ms가 되도록 더 성능을 개선할 계획입니다.
성능 테스트를 공부하면서 참고했던 동영상이 있었는데, 당근 sre 의 인프라 주제 세션 동영상입니다.

https://www.youtube.com/watch?v=8a2-b9X7Xno&t=1470s
여기서 개발자분은 얼마나 안정적으로 서비스를 오픈하고 운영하느냐는 얼마나 정확하게 성능 테스트를 했느냐와 직결이 된다.
단순히 최대 성능을 측정하는 형태의 테스트는 목적이 불분명하다고 말씀하셨습니다.
그래서 당근에서는 당근의 테스트의 목적을 정확하게 10분동안 정확하게 10분동안 테스트를 돌렸을 때, 99% 타일의 응답시간이 100m/s 구간내 일때의 최대 TPS가 우리 파드가 받아낼수있는 최대 tps다 라고 생각을 하자라고 목적을 정했습니다.
추후에 100ms로 성능을 개선한다면, 99% 타일의 응답 시간이 100ms 이하인 경우, 최대 TPS(초당 처리 요청 수)는 얼마인지를 계산하는 것도 목표입니다.
2. 성능 테스트 자동화
개발 후에, 진짜로 서비스를 개시하게 되어 트래픽이 많고, 서버 성능 측정을 해야 할 일이 잦아질 경우에는 성능 테스트 자동화를 도입할 계획입니다.
테스트 환경 구축 -> 성능 테스트 생성 및 수행 -> 테스트 결과 지표 관측 및 기록 과정을 Jenkins를 통해 자동화 할 계획입니다.
성능 테스트 자동화를 하게 되면 실수없이 같은 성능 테스트를 여러번 재현 할 수 있고, 불필요한 자원낭비를 줄이고, 모니터링을 통해 기록하며 지켜볼 필요 또한 사라집니다.
3. 단순히 Grafana와 InfluxDB를 이용해서 k6의 결과만 모니터링 하는 것이 아닌, Promethus를 결합하여, CPU , 메모리 등도 같이 모니터링 가능하도록 개선
현재는 grafana와 influxDB를 이용해서 k6의 테스트 결과와 redis 두개만 모니터링을 하고있었습니다.
추후에는 Promethus를 결합하여, 여러가지 metrcis도 모니터링이 가능하도록 개선할 계획입니다.
