모니터링 , Prometheus에 대해
모니터링이란 네트워크, 서비스, 시스템 또는 애플리케이션의 상태와 동작을 지속적으로 감시하고 평가하는 프로세스입니다.
주요 목적은 시스템의 성능, 가용성, 안정성 및 보안을 확인하여 문제를 식별하고 조치할 수 있도록 하는 것입니다.
그렇다면, 모니터링은 그냥 모니터링 툴이랑 서버 연결하면 바로 모니터링 할수있는거아니야???
아닙니다.
서버의 상태와 성능을 측정해야 서버를 객관적으로 볼 수 있습니다 .
이때, 서버의 상태를 측정한 항목(지표)를 메트릭(Metric)이라고 합니다.
Metric는 무슨정보들이 있을까요?
CPU 사용량, 메모리 사용량, 디스크 공간, 네트워크 트래픽, 요청 처리량, 응답 시간등이 존재합니다.
이 Metric들을 저장, 관리하는 도구 중 하나가 Prometheus입니다.
프로메테우스는 데이터, Metric을 저장하고 애플리케이션의 성능 및 상태 모니터링을 제공합니다.
다만, 여기서 헷갈리지 말아야하는 점이 프로메테우스는 메트릭을 받아서 저장만 하는것일뿐, 메트릭 자체를 수집하는 것은 아닙니다.
pull(데이터가 필요한 곳에서, 가진 곳에 접속하여 데이터를 긁어갑니다.) 기반 모니터링 시스템은 능동적으로 지표를 획득하는 모니터링 시스템으로, 모니터링이 필요한 오브젝트는 원격으로 접근할수있어야합니다.
분산형으로, 어떤 데이터를 수집할지 중앙에서 변경할 수 없습니다.
push(데이터를 가진 곳에서 -> 필요한 곳으로 보내줍니다.) 기반 모니터링 시스템은 모니터링이 필요한 오브젝트가 적극적으로 지표를 푸시합니다.
중앙집중형이기에, 중앙 모니터링 시스템이 데이터 수집 항목, 수집할 서버를 모두 관리하고 있습니다.
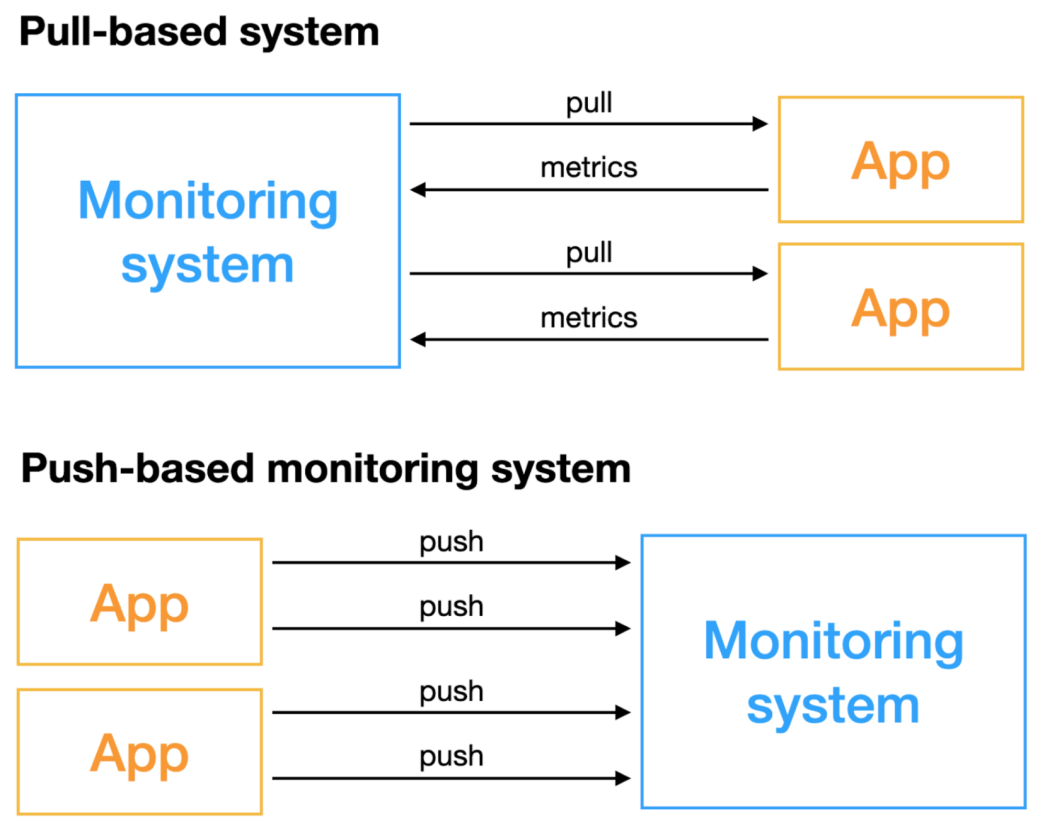
프로메테우스는 모니터링 주체(프로매테우스)가 모니터링 대상(서버)에게 HTTP 요청을 해서 metric을 가져오는 pull 방식을 사용합니다.
따라서 모니터링 주기의 경우 프로메테우스가 통제합니다.
즉, 프로메테우스가 설정한 주기에 따라 정기적으로 서버에 데이터를 요청하고 응답을 받아옵니다. 이 설정은 prometheus.yml 파일에서 정의됩니다.
global:
scrape_interval: 10s
evaluation_interval: 15sscrape_interval: 이 값은 프로메테우스가 서버에게 데이터를 요청하는 주기를 나타냅니다. 위의 설정에서는 10초마다 데이터를 스크랩(수집)하도록 설정되어 있습니다.
evaluation_interval: 이 값은 프로메테우스가 규칙을 평가하는 주기를 나타냅니다. 규칙 평가는 알림 생성 등의 작업을 수행할 때 사용됩니다. 위의 설정에서는 15초마다 규칙을 평가하도록 설정되어 있습니다.
모니터링 시스템 구축
docker-compose 를 이용해 프로메테우스와 그라나파를 docker container를 띄웠습니다.
저는 spring boot가 실행되는 서버에 프로메테우스와 그라나파를 같이 두려고했습니다.
하지만 운영서버가 터진다면, 모니터링 서버까지 같이 터지기 때문에 모니터링 서버를 따로 분리해야되지만, 이미 2개의 서버를 실행중인 상태라서, 일단 운영서버에 구축한 후, 실제로 서비스를 개시하게 될때 모니터링용 서버를 따로 구축할 계획입니다.
먼저, 프로메테우스가 어느 서버를 바라보도록 할 것인지 설정할 것입니다.
prometheus.yml에 해당 설정들을 입력합니다.
global:
scrape_interval: 10s
evaluation_interval: 15s # 15초마다 매트릭을 수집한다. 기본은 1분이다.
scrape_configs:
- job_name: 'PortfoGram'
metrics_path: '/actuator/prometheus'
static_configs:
- targets: ['host.docker.internal:8080']global : 전역 설정을 정의하는 섹션
scrap_interval : 목표 서버에서 메트릭을 가져오는 간격
evaluation_interval : 프로메테우스에서 규칙 평가 및 알람 생성을 실행하는 간격
scrip_configs : 수집 대상 및 대상별 구성을 정의하는 섹션
job_name : 프로메테우스에서 해당 작업을 식별하는 데 사용되는 이름
metrics_path : 메트릭 엔드포인트의 경로 지정
static_configs : 대상 서버를 정의하는 섹션
targets : 메트릭을 수집할 서버
Spring Actuator로 관리하는 스프링 서버만 일단 모니터링 할것이다. ( 현재 포스팅은 로컬에서 테스트 해보며, 기록하는 것이기 때문에, 로컬에서 테스트 성공 시, ec2서버로 모니터링 할 예정 )
docker-compose 파일을 통해 grafana와 prometheus와 애플리케이션을 띄워주면 Status -> Targets 메뉴에서

Application의 상태를 확인할수있습니다.
Prometheus에서 수집한 metric을 매번 쿼리를 실행하여 그래프를 보는 것은 비효율적이고 불편하기 때문에 grafana를 이용하여 시각화할것이다.
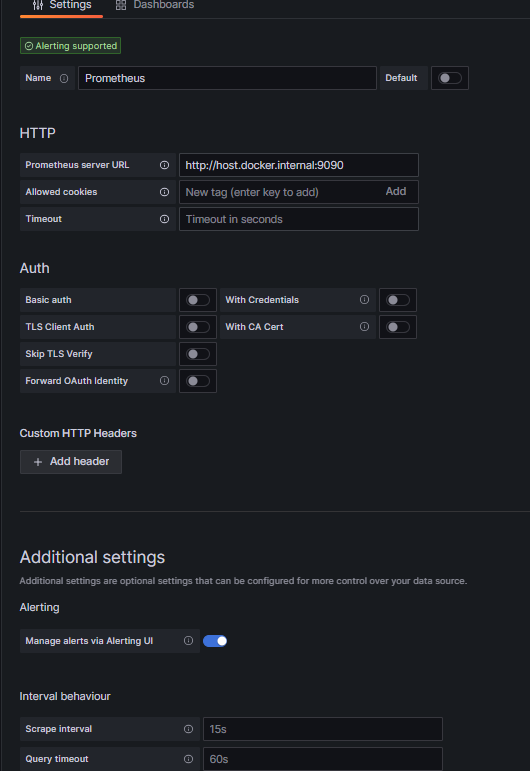
도커로 prometheus와 같이 띄워둔 grafana의 주소( localhost:3000)에 접속하여 DashBoard에서 Prometheus를 Data Source로 추가합니다.
이때 도커로 띄웠기 때문에, http://host.docker.internal:9090로 url을 설정했습니다.
이후 Dashboard에서 4701을 import 하여 생성하면
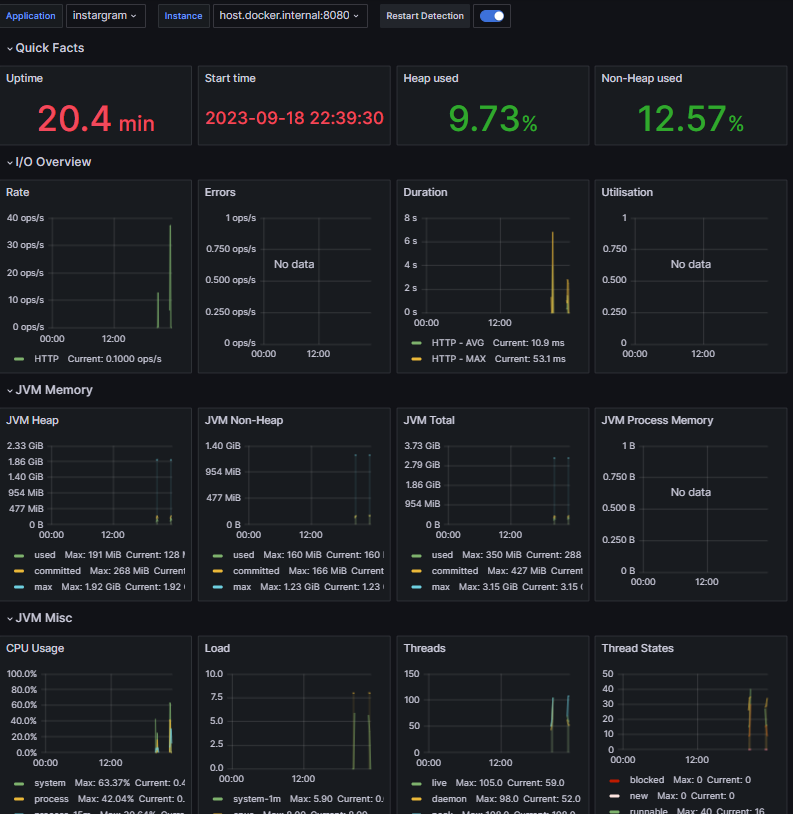
prometheus와 grafana를 이용해 모니터링 시스템을 구축할 수 있습니다.
개선점
promtheus에 대해 처음 알아보고, 조사해보고, 적용해보는 과정이였기 때문에 포스팅에서는 실서버가 아닌 로컬에서 진행하게 되었습니다.
이후 prometheus에 대해 더 깊게 공부하여 실서버에도 적용하여 모니터링 할예정입니다.
참고
https://tech.scatterlab.co.kr/spring-boot-monitoring-with-prometheus/
