
- 데이터 파이프라인 생성
- 다른 tool interact
- 다음 작업 진행 전에 file check
Operator란?
ex)
- cleaning data
- processing data
- 1개의 operator에 2개 이상의 tasks를 담으면 안된다.(1 operator - 1 tasks)
- 문제가 생기는 경우 이전 상태를 다시 수행하기 위해서 원자성을 띠도록 1-1구조.
3가지 종류의 Operator
- Action : execute an action
- Transfer : transfer data
- Sensor : Wait for a condition to be met
다중 분리, 연결 요소를 구성하는 것이 중요!
5가지 작업 수행
- 테이블 생성(
creating_table) - API 사용 가능 여부 확인(
is_api_available) - 원하는 user 데이터 추출(
extracting_user) - user 데이터 처리(
processing_user) - 위의 작업이 완료된 user 데이터 저장(
storing_user)
1. 테이블 생성(creating_table)
Airflow Web UI에서
Admin > Connections
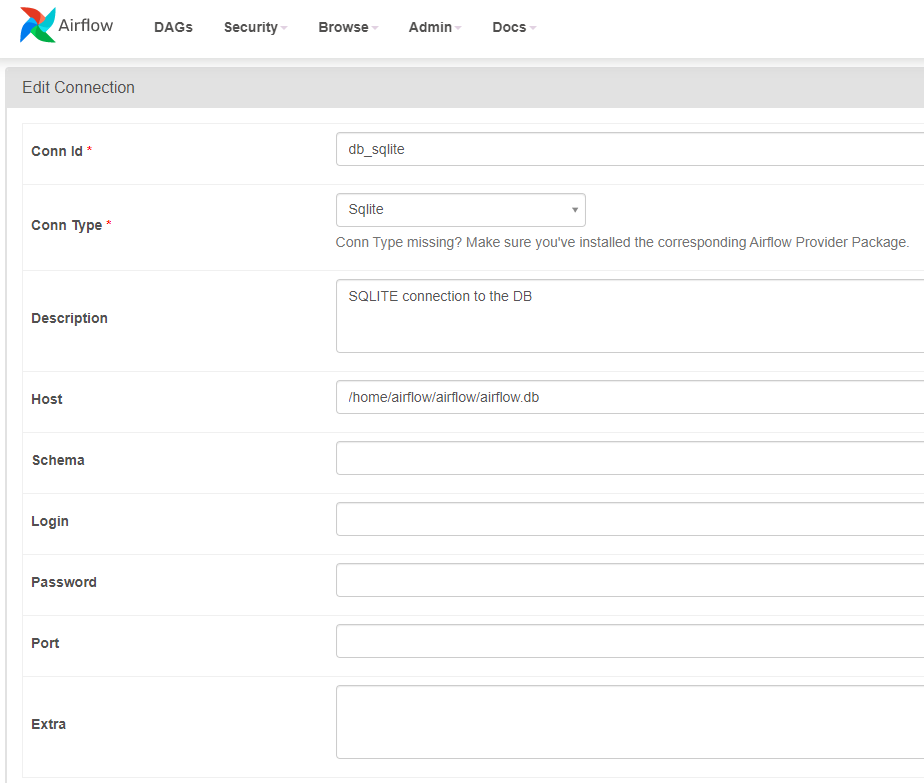
관련 코드 작성
# Import DAG object - 데이터 파이프라인 생성 시 사용
from airflow.models import DAG
# SQlite operator 사용 가능, sqlite DB와 interact
from airflow.providers.sqlite.operators.sqlite import SqliteOperator
default_args = {
'start_date': datetime(2020, 1, 1)
}
with DAG('user_processing', schedule_interval = '@daily',
default_args = default_args,
catchup = False) as dag:
creating_table = SqliteOperator(
# unique ID
task_id = 'creating_table',
sqlite_conn_id = 'db_sqlite',
sql = '''
CREATE TABLE users (
firstname TEXT NOT NULL,
lastname TEXT NOT NULL,
country TEXT NOT NULL,
username TEXT NOT NULL,
password TEXT NOT NULL,
email TEXT NOT NULL PRIMARY KEY
);
'''
)
Connection 설정 이후에 반드시 Test가 필요하다.
$ airflow tasks test user_processing creating_table 2020-01-01
Task 성공 여부를 보여준다.
-
Table이 sqlite3에 있는지 검사
$ sqlite airflow.db
sqlite> .table
sqlite> SELECT * FROM users테이블이 생성된 것을 확인할 수 있다.
2. API 사용 가능 여부 확인(is_api_available)
Airflow Web UI에서
Admin > Connections
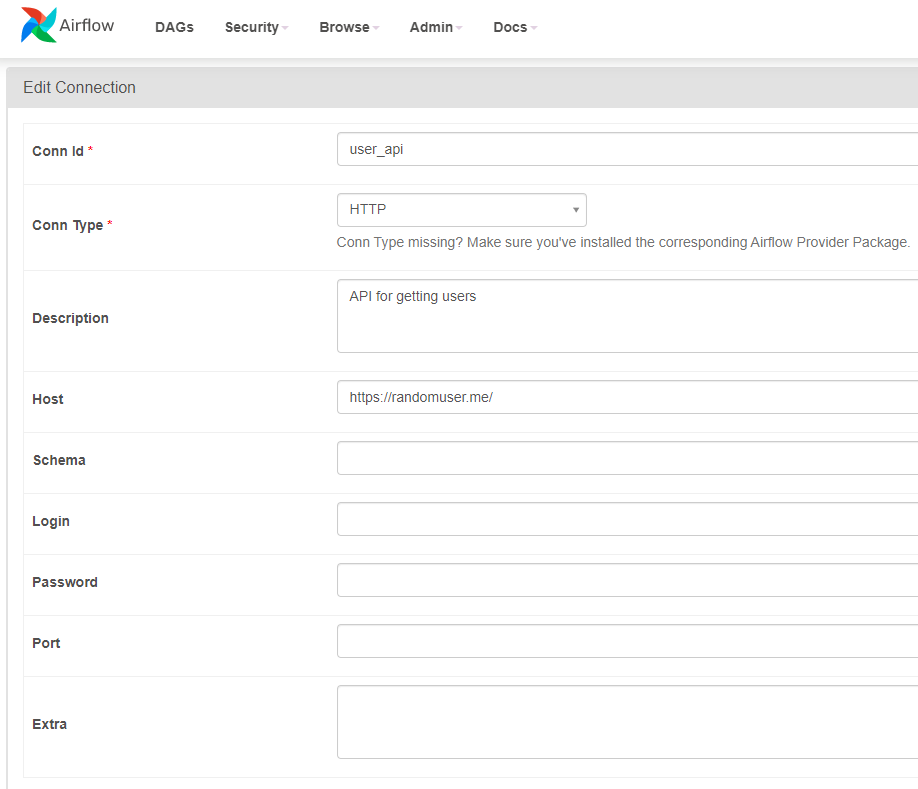
관련 코드 작성
# HTTP Sensor 사용해서 API가 동작 중인지 여부를 파악
from airflow.providers.http.sensors.http import HttpSensor
# HTTP에 의해 URL API가 Checked
# 앞에 user_api conn Id의 Host가 "https://randomuser.me/" 이므로 endpoint 'api/를 받으면
# "http://randomuser.me/api/" 가 된다.
is_api_available = HttpSensor(
task_id = 'is_api_available',
http_conn_id = 'user_api',
endpoint = 'api/'
)Test
$ airflow tasks test user_processing is_api_available 2020-01-01
is_available이 문제 없으며 이후에 workflow에서도 동작할 것임을 알 수 있다.
3. 원하는 user 데이터 추출(extracting_user)
- json 정보
'INFO - {"results":[{"gender":"male","name":{"title":"Mr","first":"Antoni","last":"Fure"},
"location":{"street":{"number":5350,"name":"Bjørndalsjordet"},
"city":"Eide","state":"Oppland","country":"Norway","postcode":"3714",
"coordinates":{"latitude":"52.3386","longitude":"-165.5425"},
"timezone":{"offset":"+5:00","description":"Ekaterinburg, Islamabad, Karachi, Tashkent"}},
"email":"antoni.fure@example.com",
"login":{"uuid":"13a81286-cbb5-4465-8eb9-a9ea2abe8d5b","username":"sadlion681","password":"toejam","salt":"UUTttzws","md5":"338976bcf8af9c57916fd12c1240fd4b","sha1":"8440422e3082d74fc60d9414beda93999a7b6f8a","sha256":"d3d0100c04d8df09eeb054145c3ff331fe8dc0a7e333ce86243a3791d0088103"},
"dob":{"date":"1975-08-28T19:10:39.412Z","age":46},
"registered":{"date":"2018-08-03T18:33:07.186Z","age":3},
"phone":"26795836",
"cell":"91278236",
"id":{"name":"FN","value":"28087545913"},
"picture":{"large":"https://randomuser.me/api/portraits/men/63.jpg","medium":"https://randomuser.me/api/portraits/med/men/63.jpg","thumbnail":"https://randomuser.me/api/portraits/thumb/men/63.jpg"},"nat":"NO"}],
"info":{"seed":"43fc9cf21da23c85","results":1,"page":1,"version":"1.3"}}관련 코드 작성
# fetch the result of a given page of a given url
from airflow.providers.http.operators.http import SimpleHttpOperator
import json
extracting_user = SimpleHttpOperator(
task_id = 'extracting_user',
http_conn_id = 'user_api',
endpoint = 'api/',
# 데이터의 변경을 하는 것이 아니라 가져오기만 하기 때문에
method = 'GET',
# response를 처리할 수 있도록 허락
response_filter = lambda response : json.loads(response.text),
# URL의 response를 확인할 수 있다.
log_response = True
)Test
$ airflow tasks test user_processing extracting_user 2020-01-01
4. user 데이터 처리(processing_user)
관련 코드 작성
- PythonOperator : table에 저장하길 원하는 user 정보를 extract하기 위해서 사용
- XCOM : 교차 통신의 줄임말로 기본적으로 작업이 완전히 다른 시스템에서 실행될 수 있기 때문에 작업이 서로 통신할 수 있도록 하는 매커니즘(XCOM은 key와 해당 key의 출처인 task_id 및 dag_id로 식별된다.)
# table에 저장하기를 원하는 user정보를 extract하기 위해서 사용
from airflow.operators.python import PythonOperator
from pandas import json_normalize
def _processing_user(ti):
users = ti.xcom_pull(task_ids = ['extracting_user'])
# output empty / output이 예상한 것이 아닌 경우(results가 안들어있는 경우)
if not len(users) or 'results' not in users[0]:
raise ValueError('User is empty')
user = users[0]['results'][0] # json 읽어오기
processed_user = json_normalize({
'firstname': user['name']['first'],
'lastname': user['name']['last'],
'country': user['location']['country'],
'username': user['login']['username'],
'password': user['login']['password'],
'email': user['email']
})
processed_user.to_csv('/tmp/processed_user.csv', index = None, header = False)
processing_user = PythonOperator(
task_id = 'processing_user',
# python operator로부터 호출하고 싶은 operator
python_callable = _processing_user
)Test
$ airflow tasks test user_processing processing_user 2020-01-01
/tmp/processed_user.csv 파일 생성
설정한firstname, lastname, country, username, password, email이 표시된다.
Joseph,Jones,Australia,brownduck393,1221,joseph.jones@example.com
5. 위의 작업이 완료된 user 데이터 저장(storing_user)
- 앞서 extract한 정보를 sqlite에 적재할 필요가 있다. (
BashOperator사용)
관련 코드 작성
# 앞서 extract한 정보를 sqlite에 저장하기 위해서 사용
from airflow.operators.bash import BashOperator
storing_user = BashOperator(
task_id = 'storing_user',
# ','로 분리, 해당 파일의 users를 import해서 airflow의 sqlite에 저장.
bash_command = 'echo -e ".separator ","\n.import /tmp/processed_user.csv users" | sqlite3 /home/airflow/airflow/airflow.db'
)Test
$ airflow tasks test user_processing storing_user 2020-01-01sqlite> SELECT * FROM users;
를 수행하면/tmp/processed_user.csv가/home/airflow/airflow/airflow.db에 저장된 것을 확인할 수 있다.
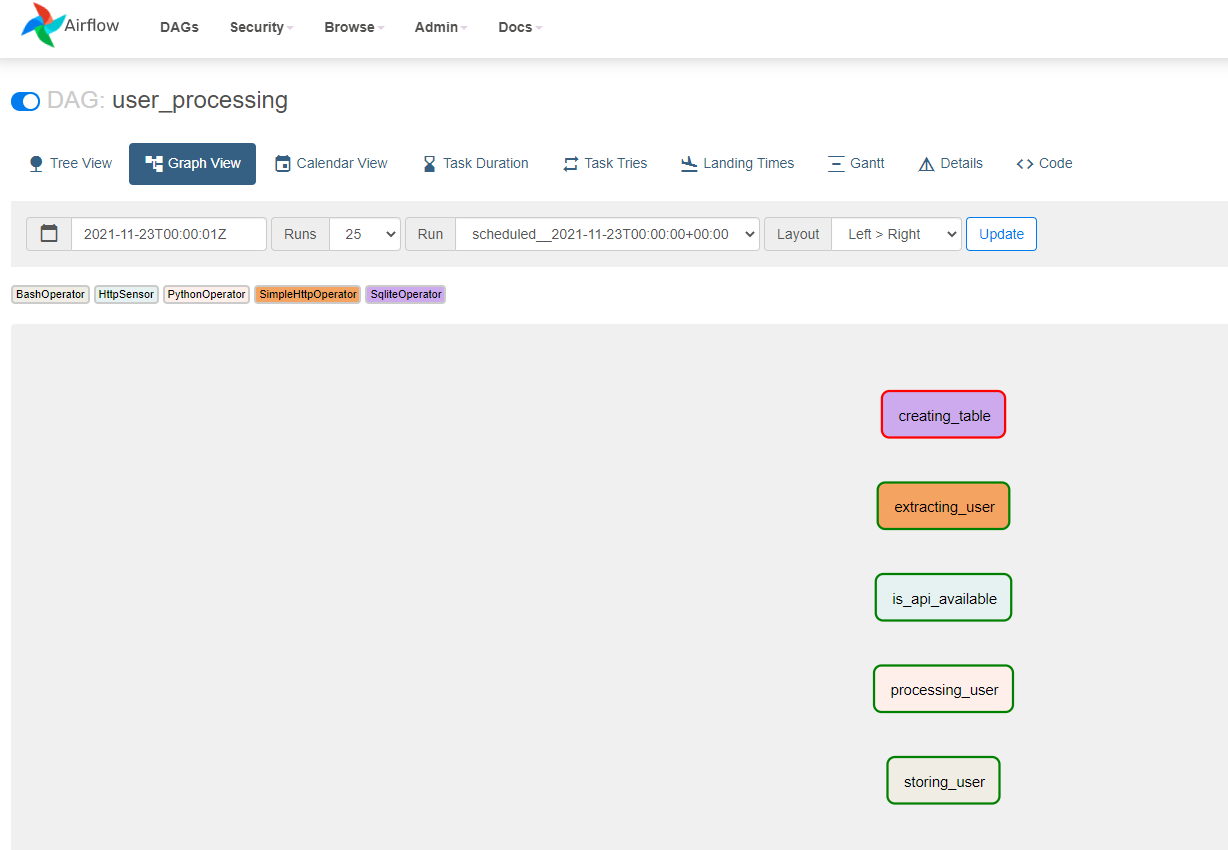
하지만 어떤 의존성(Dependency)이 존재하지는 않는 것을 확인할 수 있다.
Dependency 설정
- Dependency 설정하는 방법
>>command를 사용한다.
creating_table >> is_api_available >> extracting_user >> processing_user >> storing_user저장하고 Airflow Web UI를 새로고침하면 의존성이 갱신된 것을 확인할 수 있다.
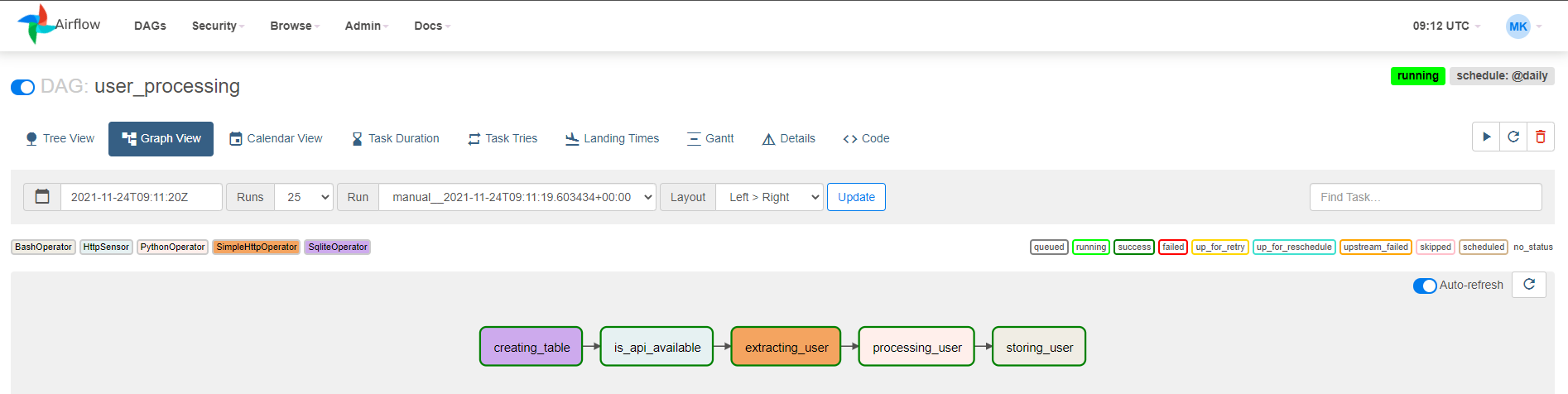
CREATE TABLE if not exists users로 수정하여 Table이 있는 경우에는 Table을 생성하지 않도록 한 후,
Workflow Trigger시 동작하는 것을 확인할 수 있다.
