
- Airflow를 왜 사용하는지?(Why?)
- Airflow란 무엇인지?(What?)
- Airflow를 어떻게 사용하는지?(How?)
- 실습
위의 3가지 질문에 대한 시작 단계에서의 답변
Why?
- 매일 10시에
Download -> Process -> Store를 수행한다.- Download시 API에 접근해야 하고
- Process는 Spark에서 수행하며
- Store시 DB에 Insert/Update를 통해 저장한다.
- 위의 작업에 에러가 발생한다면?
- 이런 데이터 파이프라인이 수백 개이며, 동시에 문제가 발생한다면?
Airflow를 사용하면
- 데이터 파이프라인을 관리할 수 있다.
- 모니터링할 수 있다.
- 자동적으로 이를 수행할 수 있다.
What?
- Opensource platform
- programmatically author, schedule and monitor
- 다른 많은 장치들과 상호작용하면서 작업을 제 시간에, 올바른 방법으로, 올바른 순서로 동작할 수 있도록 하는 오케스트레이터
이점
- Dynamic : Python으로 수행 가능
- Scalability : Kubernetes 사용 편리
- UI : Beautiful, Useful
- Extensible : 내 플러그인을 이용해서 커스터마이징 가능(얼마든지)
구성요소
- Web Server
- Web UI. DAG, user, connection, xcom, variable 등을 관리 - Scheduler
- 모든 작업과 DAG를 관리 및 실행시키는 역할을 한다. - Metastore(MetaDB)
- 실행 중인 데이터 파이프라인에 대한 Meta data를 저장 - Executor
- Worker의 동작 방식을 정의. Local, Sequential, Celery 등 다양한 Executor 방식을 제공 - Worker
- 실제 Task를 실행하는 주체
DAG(Directed Acyclic Graph)
DAG는 데이터 파이프라인을 나타내는 그래프 객체. 여러 Tasks와 그들의 의존성으로 구성되어 있다. (A DAG is basically a graph object representing your data pipeline composed of different tasks with their dependency)
How?
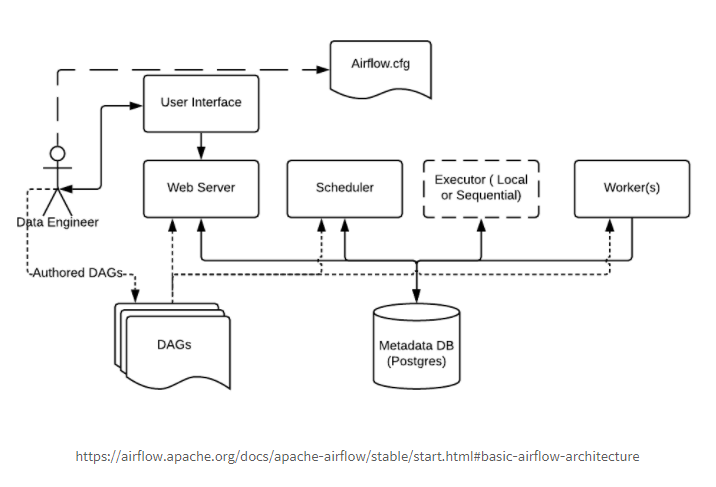
One Node Architecture
Web Server가Metastore에서 metadata를 fetchSchedulerMetastore와 Talk,Executor에 Task를 보낸다.
Executor가Metastore의 Task의 상태를 updateExecutor내에 Queue를 가지고 있는데, 실행될 Task의 순서가 담겨 있다.
Multi Node Architecture (Celery)
Web Server가Metastore에서 metadata를 fetchSchedulerMetastore와 Talk,Executor에 Task를 보낸다.
Executor가 trigger하고 싶은 Task를 Queue에 넣는다.(이 때 Queue는Executor밖에 있다.)Worker(s)가 Queue에서 이런 Task들을 빼와서 수행한다.
위와 같은 작업이 어떻게 수행되는지?
- 엔지니어가 dag.py를 추가 (
Folder DAGs) Web Server와Scheduler가Folder DAGs를 parse(새로운 데이터 파이프라인을 알기 위해서)Scheduler에서Metastore에DagRun Object생성(인스턴스 그 이상의 무엇은 아니다.)Scheduler가
1)Task Instance생성,
2)Scheduler가Executor로Task Instance를 보냄
3)Executor가Task Instance실행Task Instance수행 상태 변경(완료)Scheduler가 완료되었는지 체크
1) 완료되었다면DagRun Object의 상태 -> 완료
2) Update UI
실습
- 가상환경 세팅
$ python -m venv sandbox - 가상환경 실행
$ source bin/activate/sandbox - wheel 설치 (시간 절약)
$ pip install wheel - apache-airflow 2.1.0 version 설치
$ pip install apache-airflow==2.1.0 --constraint https://gist.github.com/marclamberti/742efaef5b2d94f44666b0aec020be7c
https://gist.github.com/marclamberti/742efaef5b2d94f44666b0aec020be7c는 contraint가 적힌 주소
명령어
airflow 초기 설정
$ airflow db init
- airflow 폴더 생성
- airflow.cfg : 설정 파일
- airflow.db : default로 사용하는 SQLite같은 DB
- logs : 로그
- unittests.cfg : air에 영향을 주지 않고 airflow의 일부 구성을 test하기 유용
- webserver_config.py : 웹 서버의 재구성 시 유용
$ airflow users create -u admin -p admin- airflow UI의 ID, PW 설정(ID : admin, PW : admin, 메일, 이름 등 추가 설정 가능)
$ airflow db upgrade- Airflow Version upgrade시 사용
$ airflow db reset- 위험, 동작 전에 무슨 짓을 하는지 알아야 한다(Metastore를 잃을 수 있다)
$ airflow webserver- Airflow UI 실행(localhost:8080 <- 내 경우)
$ airflow scheduler- airflow scheduler 실행
$ airflow dags list- DAGs list 출력
$ airflow tasks list 'DAG 이름(위의 DAGs list에서 나온 것 중 하나)'- 해당 DAG의 tasks list 출력
- tasks가 안나오면 error가 있는 것은 아닌지 점검 필요
$ airflow dags trigger ...- 데이터 파이프라인 트리거
Apache Web UI

왼쪽부터
- PAUSE/UNPAUSE DAG
- 태그명/태그를 통해 카테고리 설정 가능
- Owner(ex) 팀 명)
- DAG Run 상태
- Schedule(Trigger Frequency)
- Last Run
- Status of Recent Tasks
- run, refresh, delete(metastore 삭제, file을 삭제하는 것은 아님)
Tree View
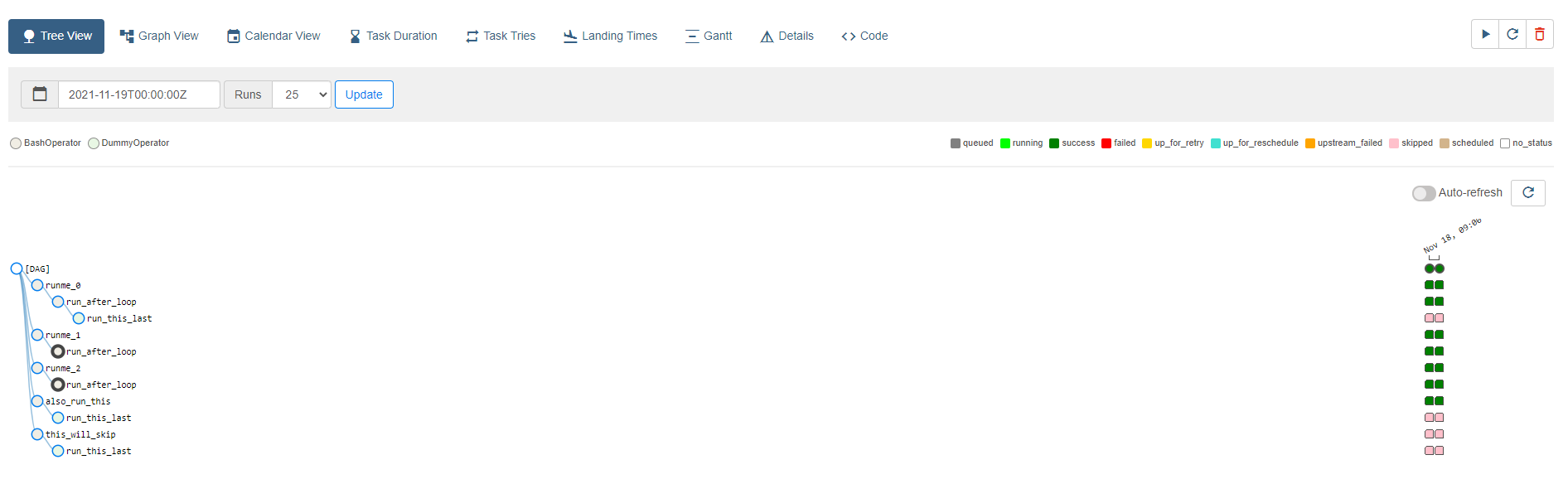
- DAG 상태, 진행 등 점검 가능
Graph View
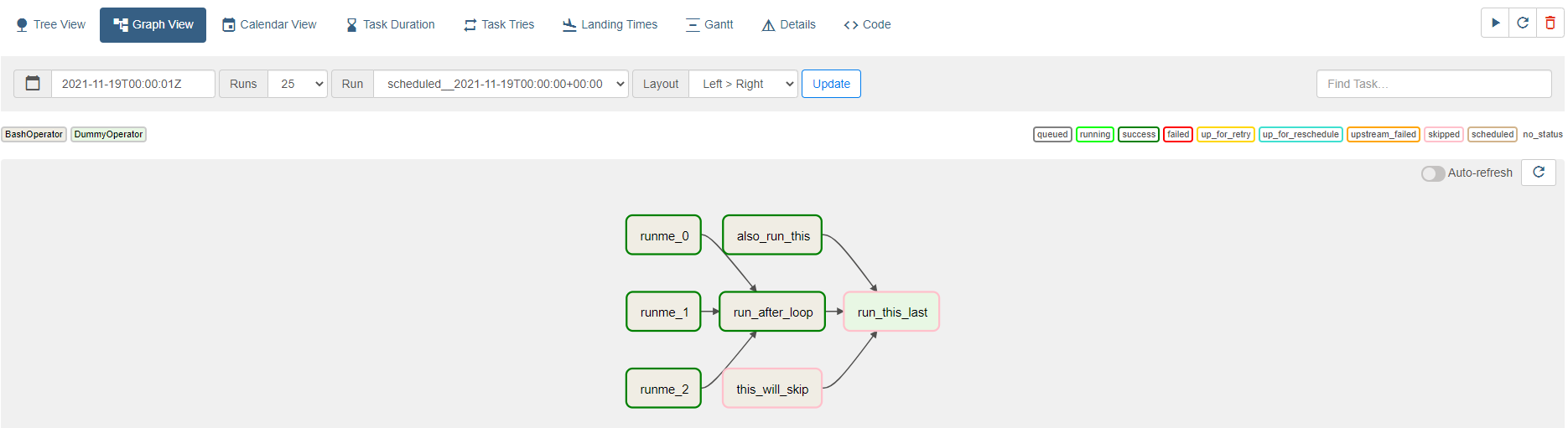
- 데이터 파이프라인의 Task 상태를 그림으로 한 눈에 파악할 수 있다.
- 해당 node 클릭 시 moduler view를 얻을 수 있다.
- 추가 정보(Instance Detail, Rendered, Log)
- 해당 Log를 통해 작업이 실패한 경우 파악 편리
- Mark Failed/Success를 이용해서 내가 현재 Task를 표시해서 정의할 수 있고, 이를 통해 다음 동작의 동작 여부, 문제 등에 참고할 수 있다.
- 추가 정보(Instance Detail, Rendered, Log)
Gantt

- bottleneck 위치를 알아내는데 유용하다
- Task의 작업이 너무 오래 걸릴 시에 확인할 때 유용한 View
출처 : Udemy The Complete Hands-On Introduction to Apache Airflow 강의 Section 2
