
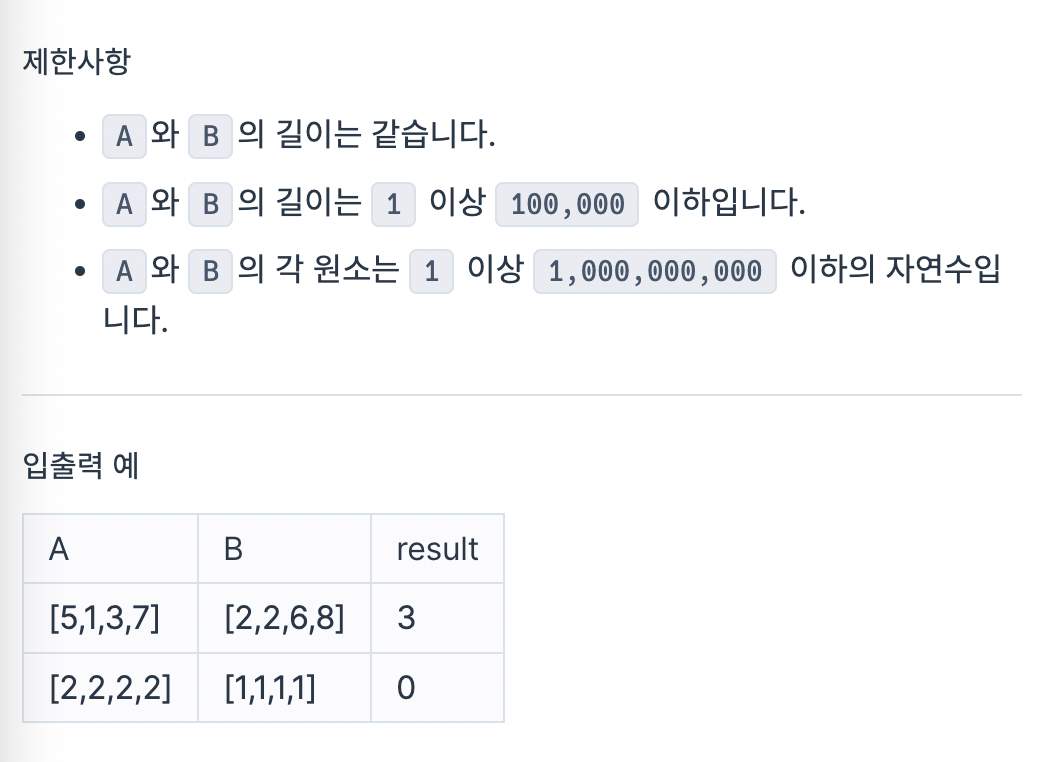
문제

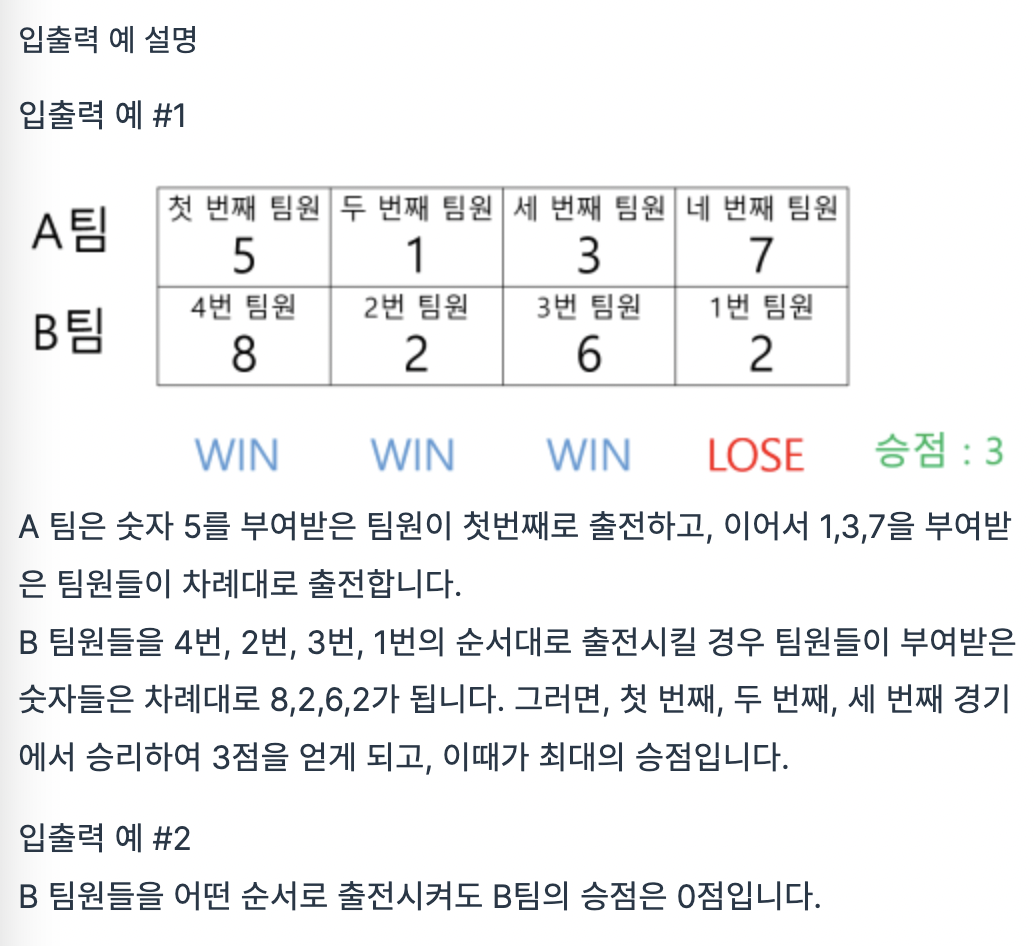
풀지 못한 이유
- 문제를 너무 단순하게 생각해서 리스트를 정렬한 후 각 자리의 원소만 비교하면 된다고 생각했다.
- 힙(heap)에 대해서 무지했다.
풀이 1) heapq 이용
heapq는 데이터를 정렬된 상태로 저장하기 위해 사용하는 파이썬 내장 모듈이다. 이진트리 기반으로 최소 힙 자료구조를 제공한다. 따라서 최댓값, 최솟값을 가져올 때 많이 사용한다. 주요 함수는 아래와 같다.
heap = [] # 힙 생성
heapq.heapify(heap) # 기존 리스트를 힙으로 변환
heapq.heappush(heap, 1) # 힙 원소 추가
heapq.heappop(heap) # 가장 작은 원소 삭제 후 그 값 리턴
heap[0] # 최솟값 삭제하지 않고 얻기힙은 리스트를 기반으로 하는데, 리스트와 다른 점을 정리해 보았다.
- 리스트에서 pop은 제일 오른쪽에 위치한(제일 마지막으로 들어온) 원소를 내보내지만, 힙에서 pop은 가장 작은 원소를 내보낸다.
- 리스트는 원소가 들어온 순서대로 차곡차곡 쌓이지만, 힙은 오름차순으로 정렬되며 쌓인다.
import heapq
def solution(a, b):
# 나중에 heappop으로 제일 작은 값을 꺼내기 위해서 부호 반전
a = [-i for i in a]
b = [-i for i in b]
# a, b 리스트를 힙으로 변환
heapq.heapify(a)
heapq.heapify(b)
answer = 0
# a, b 모두 원소가 있을 때까지 반복(한쪽이라도 비면 종료)
while b and a:
# a, b에서 각각 제일 작은 값 꺼내기(원소가 모두 음수라서 제일 큰 값을 꺼내는 격)
am = heapq.heappop(a)
bm = heapq.heappop(b)
# b에서 꺼낸 값이 더 크면 +1
if -am < -bm:
answer += 1
# b에서 꺼낸 값이 더 작으면 다시 넣기
else:
heapq.heappush(b, bm)
return answer위의 코드를 하나씩 살펴보자.
힙에서 pop은 제일 작은 값을 꺼낸다는 것을 역으로 사용하여 모든 원소의 부호를 반전시킨다. 양수일 때 제일 큰 값은 음수일 때 제일 작은 값이기 때문이다.
# 나중에 heappop으로 제일 작은 값을 꺼내기 위해서 부호 반전
a = [-i for i in a]
b = [-i for i in b]그러고 나서 각 리스트를 힙으로 변환한다.
# a, b 리스트를 힙으로 변환
heapq.heapify(a)
heapq.heapify(b)이제 a, b 힙에 원소가 한곳이라도 빌 때까지 다음을 반복한다.
a와 b에서 제일 작은 값을 꺼낸다.(pop)
다시 부호를 반전시켜(원래 값) 비교했을 때 b에서 꺼낸 값이 더 크면 +1, a에서 꺼낸 값이 더 크면 b에서 꺼낸 값을 다시 넣는다.(push)
# a, b 모두 원소가 있을 때까지 반복(한쪽이라도 비면 종료)
while b and a:
# a, b에서 각각 제일 작은 값 꺼내기(원소가 모두 음수라서 제일 큰 값을 꺼내는 격)
am = heapq.heappop(a)
bm = heapq.heappop(b)
# b에서 꺼낸 값이 더 크면 +1
if -am < -bm:
answer += 1
# b에서 꺼낸 값이 더 작으면 다시 넣기
else:
heapq.heappush(b, bm)풀이 1) 회고
이번 기회에 힙에 대해서 제대로 알고 넘어갔다. 제발 부족한 게 있다고 생각하면 바로 확인하고 넘어가려고 하자. 어차피 나중에 다 알아야 하는 것들이다.
풀이 2)
힙을 사용하지 않고 그대로 리스트로도 풀 수 있다. 먼저 두 리스트를 오름차순으로 정렬한다. 그리고 리스트 길이만큼 반복할 건데, A[j]와 B[i]를 비교할 것이다. 여기서 헷갈릴 수 있는데 j는 B가 더 커야지만 값이 증가하고 i는 한 루틴이 끝나면 무조건 증가한다.
def solution(A, B):
answer = 0
# 두 리스트 오름차순 정렬
A.sort()
B.sort()
j = 0
# 리스트 길이만큼 반복
for i in range(len(A)):
# B의 원소가 더 크면 answer와 j +1
if A[j] < B[i]:
answer = answer + 1
j = j+1
return answer문제의 입출력 예로 살펴보자.
# A와 B 오름차순 정렬
A = [1,3,5,7]
B = [2,2,6,8]
# A 리스트 길이만큼 반복(총 4번)
첫 번째 루틴 : A[j] = 1, B[i] = 2 # B의 원소가 더 크다 -> answer = 1, j = 1
두 번째 루틴 : A[j] = 3, B[i] = 2 # A의 원소가 더 크다 -> answer = 1, j = 1
세 번째 루틴 : A[j] = 3, B[i] = 6 # B의 원소가 더 크다 -> answer = 2, j = 2
네 번째 루틴 : A[j] = 5, B[i] = 8 # B의 원소가 더 크다 -> answer = 3, j = 3풀이 2) 회고
내가 처음에 접근했던 방식과 비슷하다.(리스트를 정렬해서 값을 비교하는) 하지만 나는 zip으로 두 리스트를 연결해서 각 자리의 값만 비교했다. 입출력 예는 통과했지만 당연히 채점할 땐 많이 틀렸다. 생각이 너무 짧았다. 충분히 반례를 생각하며 풀자.
