데이터베이스 기본 개념
데이터베이스와 테이블
- 관계: 테이블들 ⊂ 데이터베이스
테이블?
- row: 행
- column: 열 (속성)
데이터베이스 생성하기
- DBMS(DataBase Management System)
- SQL(Structured Query Language)
CREATE DATABASE 데이터베이스명 -- 데이터베이스 생성하기테이블 생성하기
SQL문으로 테이블 생성하기
- SQL문 실행 단축키:
Ctrl+Shift+Enter - 컬럼의 구조 살펴보기: 테이블 (
member)에 마우스를 올려서 나타나는 두번째 아이콘을 클릭하면 column, datatype, pk, default 등의 정보가 나타남
이 때,id라는 컬럼을 확인할 수 있음 ← member 테이블에서 회원을 식별하기 위해 인위적으로 추가한 식별자 컬럼 (Primary Key)임
→PK,NN(자동으로 체크됨, Not Null의 줄임말) 밑의 체크박스를 체크해서 명시적으로 식별자 컬럼으로 설정해주기
Primary Key의 종류
- Natural Key: 실제로 어떤 개체가 갖고 있는 속성을 나타내는 컬럼이 Primary Key가 된 경우
- Surrogate Key: 앞서 설정했던 id 컬럼같은 인위적으로 지정된 식별자
Not Null이란?
-Null은 빈 문자열 ("")이나 0과는 다른 개념
Primary Key의 Auto Increment 속성이란?
PK를 설정할 때AI옵션의 체크박스를 체크하면, 이후에 사용자가 row를 삽입할 때 회원의 실제 속성을 나타내는 컬럼의 값만 직접 작성하고 id 컬럼에는 신경쓸 필요가 없도록 자동으로 +1씩 증가시켜서 중복을 방지해주는 속성
날짜 관련 컬럼은 DATE 타입
birthday,sign_up_day등의 날짜타입들은 자동으로 TEXT의 데이터타입을 부여받지만, 그보다는 DATE 타입이 더 적절함
INT: 정수형DOUBLE: 실수형DATE: 날짜형TEXT: 문자열
member 테이블과 Workbench
memeber테이블 이름 위에 마우스를 올리고 가장 오른쪽의 아이콘을 누르면 멤버테이블 전체가 보임
SELECT * FROM copang_main.member; -- 테이블의 데이터 조회Workbench 사용법
https://www.codeit.kr/topics/data-analysis-using-sql/lessons/3158
데이터 조회로 기본 다지기
SELECT, WHERE
SELECT: 테이블의 데이터를 조회할 때 사용
SELECT 컬럼(들) FROM 데이터베이스.테이블명; -- 테이블의 데이터 조회데이터베이스.테이블명으로 기재하는 것이 번거롭다면, 아래와 같이USE를 사용할 수도 있음
USE coupang_main -- 데이터베이스명
SELECT 컬럼(들) FROM member; -- 테이블명WHERE: 조건문
SELECT email FROM coupang_main.member;
WHERE email = "minzikx@gmail.com";조건을 나타내는 방법들
- 27살 이상인 회원 조회하기
SELECT * FROM coupang_main.member;
WHERE age >= 27; - 30대인 회원 조회하기 →
BETWEEN(꼭 숫자가 아니어도 날짜 등에도 적용 가능)
SELECT * FROM coupang_main.member;
WHERE age BETWEEN 30 AND 39;- 30대인 회원을 제외하고 조회하기 →
NOT
SELECT * FROM coupang_main.member;
WHERE age NOT BETWEEN 30 AND 39;- 가입일자가 2019년 이후인 회원 조회하기
SELECT * FROM coupang_main.member;
WHERE sign_up_day > '2019-01-01';- 가입일자가 2018년도인 회원 조회하기
SELECT * FROM coupang_main.member;
WHERE sign_up_day BETWEEN '2018-01-01' AND '2018-12-31';문자열 패턴 매칭 조건
- 서울에 사는 회원 조회
SELECT * FROM coupang_main.member;
WHERE address LIKE '서울%'; -- 서울로 시작하는 모든 문자열- 고양시(경기)에 사는 회원 조회
SELECT * FROM coupang_main.member;
WHERE address LIKE '%고양시%'; -- 고양시가 들어가는 모든 문자열-
이스케이핑: 만약
100%와 같이 검색하고자 하는 문자열 안에%가 들어간다면,LIKE 100\%처럼%앞에 역슬래쉬\를 적어줘야 함 -
대소문자: 만약
yummy가 포함된 row들을 조회하되, 대문자가 아닌 오로지 소문자만으로 구성된yummy만 포함하고 싶다면,LIKE BINARY '%yummy'라고 적어줘야 함
조건 표현식
- 같지 않음 :
!=,<>
- 여성 고객만 조회
SELECT * FROM coupang_main.member;
-- 두가지 방법
WHERE gender != 'm';
WHERE gender <> 'm'- 이 중에 있는~ :
IN
- 나이가 정확히 스무살, 혹은 서른살인 회원들 조회
SELECT * FROM coupang_main.member;
WHERE age IN (20, 30); - 한 글자를 나타내는
_
- 이메일 주소가 c로 시작하고, 그 뒤에 여섯 글자가 있는 row들을 조회
SELECT * FROM coupang_main.member;
WHERE email LIKE 'c______@%'; DATE 데이터타입 관련 함수
- 연도, 월, 일 추출하기:
YEAR(),MONTH(),DAY() - 날짜 간의 차이 구하기:
DATEDIFF(날짜1, 날짜2)
예:DATEDIFF(’2018-01-05’, ’2018-01-03’)는 2 - 오늘 날짜를 구하는 함수:
CURDATE() - 날짜 더하기 빼기:
DATE_ADD(),DATE_SUB() - UNIX Timestamp 값
https://www.codeit.kr/topics/data-analysis-using-sql/lessons/3165
여러개의 조건 걸기
-
AND와OR의 우선순위는 같고, 먼저 등장하는 것이 먼저 실행됨.
되도록 혼동을 피하기 위해 원하는 조건을 괄호로 묶는 것이 좋음 -
남자이면서 서울에 사는 회원 조회 -
AND
SELECT * FROM coupang_main.member;
WHERE gender = 'm'
AND address LIKE '서울%'
AND age BETWEEN 25 and 29;- 봄 또는 가을에 가입한 회원 조회 -
OR
SELECT * FROM coupang_main.member;
WHERE MONTH(sign_up_day) BETWEEN 3 AND 5 -- 봄?
OR MONTH(sign_up_day) BETWEEN 9 AND 11; -- 가을?- 남자회원 중 키가 180 이상이거나, 여자회원 중 키가 170 이상인 회원 조회
SELECT * FROM coupang_main.member;
WHERE (gender = 'm' AND height >= 180) -- 남자 180 이상
OR (gender = 'f' AND height >= 170); -- 여자 170 이상데이터 정렬: ORDER BY
- 데이터 정렬? row들을 특정 컬럼을 기준으로 순서대로 출력하는 것
- 회원들을 키 순서로 출력하기
SELECT * FROM copang_main.member
ORDER BY height ASC; -- ASC는 생략 가능(디폴트이므로)ASC는 오름차순,DESC는 내림차순- 남자 회원 중 몸무게가 70kg 이상인 회원 중 키 순서로 정렬해서 출력
SELECT * FROM copang_main.member
WHERE gender = 'm' -- 조건문으로 먼저 필터링 가능
AND weight >= 70
ORDER BY height ASC; - 여러개의 기준 컬럼으로 정렬하기
- 가입년도를 기준으로 내림차순 정렬, 만약 같은 연도 가입자가 있다면 그들끼리는 나이순으로 오름차순 정렬
SELECT * FROM copang_main.member
ORDER BY YEAR(sign_up_day) DESC, age ASC; - 만약
data가 숫자인데 문자열 타입이라서 부정확한 정렬이 일어나고 있다면?
예: 230과 27을 비교할 때 문자열의 경우 앞부터 하나씩 비교하기 때문에 맨 앞글자 2는 동일하고, 뒤에 3과 7을 비교해서 230이 더 작다고 판별해버림 CAST사용
예:CAST(data AS signed)←signed: 양수와 음수를 포함한 모든 정수를 나타낼 수 있는 데이터 타입 (정수의 경우)
←decimal(소수의 경우)
데이터 일부만 추리기: LIMIT
- 최근에 가입한 회원 10명만 추려서 출력하기
SELECT * FROM copang_main.member
ORDER BY YEAR(sign_up_day) DESC
LIMIT 10; -- 10개의 행만 추려서 출력하기- 최근 기준으로 9번째, 10번째로 가입한 회원 출력하기
SELECT * FROM copang_main.member
ORDER BY YEAR(sign_up_day) DESC
LIMIT 8, 2; -- 8번째(포함), 9번째 이렇게 2개의 행 출력- 이 때, LIMIT에 쓰이는 행(row) 번호는 0번부터 시작하므로 9번째 행의 행 번호는 8이 된다.
- 키워드 작성 순서:
FROM-WHERE-ORDER BY-LIMIT
데이터 분석
데이터의 특성 구하기: COUNT, MAX, MIN, AVG
COUNT
- 만약 특정 속성 (여기서는 email)의 행의 개수 (null값 제외된 결과)를 알고 싶다면?
SELECT COUNT(email) FROM copang_main.member- 만약 행의 전체 개수를 구하고 싶다면?
SELECT COUNT(*) FROM copang_main.memberMAX: height 컬럼의 값 중 가장 큰 값(195.2) 출력하기
SELECT MAX(height) FROM copang_main.memberMIN: weight 컬럼의 값 중 가장 작은 값 (48.2) 출력하기
SELECT MIN(weight) FROM copang_main.memberAVG: weight 컬럼의 평균값 구하기
이 때, null값은 포함되지 않음!
SELECT AVG(weight) FROM copang_main.member -- 67.xxx집계함수와 산술함수
- 집계함수들: 특정 컬럼의 여러 row의 값들을 동시에 고려해서 실행되는 함수
- SUM() 함수 - 합계
SELECT SUM(age) FROM copang_main.member;- STD() 함수 - 표준편차
SELECT STD(age) FROM copang_main.member;- 산술함수들: 특정 컬럼의 각 row의 값마다 실행되는 함수
- CEIL() 함수 - 올림 함수
SELECT CEIL(height) FROM copang_main.member;-
FLOOR() 함수 - 내림 함수
-
ROUND() 함수 - 반올림 함수
-
ABS() 함수 - 절대값을 구하는 함수
-
SQRT() 함수 - 제곱근을 구하는 함수
NULL을 다루는 법
- 특정 컬럼 (여기서는 address)에 null이 들어있는 경우만 조회하기
SELECT * FROM copang_main.member
WHERE address IS NULL;- 컬럼 a나 b나 c가 비어있는 회원들 조회하기
SELECT * FROM copang_main.member
WHERE address IS NULL
OR weight IS NULL
OR height IS NULL;✨ 주의: IS NULL은 = NULL로 대체될 수 없음!! 즉, NULL과는 앞서 배운 비교기호들인 =, !=, <> 등을 모두 사용할 수 없음.
NULL을 다른 단어로 바꾸기 (대체하기)
null이 뭔지 모르는 다른 직군의 사람들과 데이터를 함께 봐야 할 경우
SELECT
COALESCE(height, '####')
-- height 컬럼의 null값은 '####'로 대체
COALESCE(weight, '---')
COALESCE(address, '@@@')
FROM copang_main.member;NULL에는 어떤 연산을 해도 결국 자기자신임
예:NULL+ 5 =NULL
이상치 제거하기
- 만약 age의 평균을 구했는데 300이 나왔다고 해보자. 이런 말도 안되는 오류가 생기는 이유가 무엇일까?
확인하기 위해 데이터를 읽어보니 몇몇 회원이 장난삼아 지나치게 큰 수를 나이로 설정한 모양이다. 이러한 말도 안되는 값들을 제거하는 방법을 알아보자.
SELECT AVG(age) FROM copang_main.member -- 평균 구하기
WHERE age BETWEEN 5 AND 100; -- 정상치만 추리기- 이번에는 주소값을 보니 몇몇 회원들이 안드로메다 239 행성 등 장난으로 유효하지 않은 주소값을 적어둔 것을 확인할 수 있음
정상주소의 특징을 잡아내서 (이 경우에는 ~호로 끝난다) 필터링해주기
SELECT * FROM copang_main.member -- 평균 구하기
WHERE adress NOT LIKE '%호'; -- 정상치만 추리기- 이상한 주소들만 나왔으니 이메일을 보내서 정상주소로 수정해달라고 요청하기
컬럼끼리 계산하기
- Bmi를 이용해서 각 회원의 비만 여부 판별
- Bmi 공식 = 몸무게 / (키) ** 2
SELECT email, height, weight, weight / ((height/100) * (height/100)) — bmi에서 키 단위가 미터이므로 센티 단위의 키를 100으로 나눠줘야 함
FROM copang_main.member;- 컬럼끼리의 산술계산이 가능함!!
+,-,*,/,%등의 연산자 사용가능- Height 컬럼과 weight 컬럼의 산술계산을 통해 bmi 컬럼을 만들어봄
- 이 때, 두 컬럼의 값 중 하나라도 null인 행은 bmi 도 null이 됨!!
컬럼에 alias 붙이기
SELECT
email,
weight / ( (height/100) * (height/100)) AS BMI
FROM copang_main.member;- as 대신 그냥 공백으로 대체하는 것도 가능함
컬럼의 값 변환해서 보기
만약 두 열을 합치고 제목을 하나로 만들고 싶다면? Concat!!
SELECT
emaiL,
CONCAT (height, ' cm' weight, 'kg') AS '키와 몸무게',
weight / (height/100)) * (height/100)) AS BMI
FROM copang_main. member;결과>
키와 공무게
165.7cm, 67.3kg
- case문
CASE
WHEN blahblah THEN blahblah
WHEN blahblah THEN blahblah
WHEN blahblah THEN blahblah
ELSE blahblah
- 예시:
- pizza_price_cost 테이블의 name, price, price/cost(원가 기준 가격의 비율) 컬럼을 조회하세요.
- 대신 마지막 price/cost 컬럼을 사용해서 그 값이
1 <= 값 < 1.5 인 경우, 'C. 저효율 메뉴'
1.5 <= 값 < 1.7 인 경우, 'B. 중효율 메뉴'
1.7 <= 값 인 경우, 'A. 고효율 메뉴'
라고 그 값을 변환해서 표시하는 추가적인 컬럼도 함께 조회하고 대신 이 컬럼에는 efficiency라는 alias를 붙여주세요. - 그리고 전체 row를 efficiency 컬럼을 기준으로 내림차순, 그 다음 기준으로 price 컬럼을 기준으로 오름차순 정렬하세요.
- 이 중에서 가장 첫 번째 row 부터 6개만 추리세요.
SELECT name,
price,
price/cost,
(CASE
WHEN price/cost >= 1 AND price/cost < 1.5 THEN 'C. 저효율 메뉴'
WHEN price/cost >= 1.5 AND price/cost < 1.7 THEN 'B. 중효율 메뉴'
WHEN price/cost >= 1.7 THEN 'A. 고효율 메뉴'
END) AS efficiency
FROM pizza_price_cost
ORDER BY efficiency DESC, price ASC
LIMIT 6;a < x < b불가,a < x AND x < b로 풀어서 적어야 함
고유값만 보기: DISTINCT
DISTINCT: 컬럼값들의 중복을 제거해줌
예: 성별 컬럼의 값들이 m m m m f f m f m f … 등 m과 f만이 연달아 나온다면 distinct(성별) 의 결과로는 m, f만 나오게 됨!
SELECT DISTINCT(gender) FROM copang_main.member;- 그런데 adress 같은 컬럼의 경우에는 어떻게
DISTINCT를 이용해서 고유값을 뽑을 수 있을까?
광역시 기준으로 뽑아보자!
SELECT DISTINCT(SUBSTRING(address, 1, 2)) FROM copang_main.member;SUBSTRING(대상컬럼, 시작인덱스(1부터), 끝인덱스): 대상컬럼의 문자열을 시작인덱스부터 끝인덱스까지만 각각 출력하도록 함
문자열 관련 함수들
LENGTH()함수: 문자열의 길이를 구해줍니다.UPPER()함수: 문자열을 모두 대문자로 바꿔서 보여주는 함수LOWER()함수: 문자열을 모두 소문자로 바꿔서 보여주는 함수LPAD(컬럼, 채울개수, 특정문자열): LEFT(왼쪽) + PADDING(채우기)의 줄임말
문자열의 왼쪽을 특정문자열로 채워줌RPAD(컬럼, 채울개수, 특정문자열): RIGHT(오른쪽) + PADDING(채우기)의 줄임말
문자열의 오른쪽을 특정문자열로 채워줌LTRIM(): 왼쪽 공백 삭제RTRIM(): 오른쪽 공백 삭제TRIM(): 왼쪽, 오른쪽 양쪽 다 공백 삭제
그루핑하기
- 그루핑이란?
- gender 컬럼 기준으로 그루핑해보기!
SELECT gender, COUNT(*)
FROM copang_main.member
GROUP BY gender이 때 count 함수는 전체에 적용되는 것이 아니라 GROUP BY 함수로 묶인 각 그룹에 적용됨
각 그룹의 row 개수가 출력됨
만약 count 함수 자리에 AVG(height) 를 넣어도 각 그룹 별 평균을 구하게 됨
동일하게 MIN 등도 사용가능
GROUP BY 이후에 SELECT 절에서 함수들을 사용하면 이제는 전체 컬럼에 대해 적용되는 것이 아니라 그룹별로 적용되게 됨!
- address 컬럼 기준으로 그루핑!
- 지난번처럼 광역시 기준으로 그루핑해주고 싶음
SELECT
SUBSTRING(address, 1, 2) AS region,
COUNT(*) — 광역시 별 회원수 출력
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2);- 기존 컬럼을 가공해서 더 적절한 그루핑 기준를 만들 수 있음
- 여러개의 컬럼을 기준으로 그루핑하기
- address, gender를 기준으로 삼기
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*) — 광역시 별 회원수 출력
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2),
gender; 그러면 이제
서울 | 남자
서울 | 여자
경기 | 남자
경기 | 여자등으로 분류되게 됨!
- 그루핑의 조건문?
- 이 때 그루핑의 조건문은 WHERE이 아닌 HAVING으로 작성함!
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*) — 광역시 별 회원수 출력
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2),
gender
HAVING region = ‘서울‘ — 조건문
AND gender = ‘m’ — 조건문 여러개 가능- 가시성을 위해 region 컬럼을 기준으로 오름차순 정렬하고 같은 region 에서는 gender 컬럼을 기준으로 내림차순정렬하자
- 그리고 region 컬럼의 null값들을 지우자
SELECT
SUBSTRING(address, 1, 2) AS region,
gender,
COUNT(*) — 광역시 별 회원수 출력
FROM copang_main.member
GROUP BY SUBSTRING(address, 1, 2),
gender
HAVING region IS NOT NULL — region 컬럼의 null 값 제거
ORDER BY
region ASC,
gender DESC;- GROUP BY 주의사항
- GROUP BY 뒤에 쓰지 않은 컬럼 이름을 SELECT 뒤에 쓸 수는 없음
- 대신 SELECT 절 뒤에서 집계 함수에 그 외의 컬럼 이름을 인자로 넣는 것은 허용됨
WITH ROLLUP
SELECT SUBSTRING(address, 1, 2) as region,
gender,
COUNT(*)
FROM member
GROUP BY SUBSTRING(address, 1, 2), gender
WITH ROLLUP --
HAVING region IS NOT NULL
ORDER BY region ASC, gender DESC;- 가장 상위
GROUP BY컬럼을 기준으로 전체 합을 출력해줌

WITH ROLLUP은GROUP BY뒤에 나오는 그루핑 기준의 등장 순서에 맞춰서 계층적인 부분 총계를 보여줌
GROUP BY뒤에 나오는 그루핑 기준의 등장 순서에 따라 WITH ROLLUP이 출력하는 결과가 달라짐 (제일 앞에 나오는 컬럼에 따라서 부분총계를 출력함)GROUPING(): NULL을 보았을 때 원래 있던 NULL인지, 부분 총계임을 나타내기 위해 쓰인 NULL인 건지를 구분하기 위해서 사용함 → 부분총계를 나타내기 위해 NULL이 쓰인 곳에는 1이 출력됨
SELECT문의 실행순서
- 쿼리문 작성 순서: SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT
- 실제 실행 순서: FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY → LIMIT
- FROM: 어느 테이블을 대상으로 할 것인지를 먼저 결정합니다.
- WHERE: 해당 테이블에서 특정 조건(들)을 만족하는 row들만 선별합니다.
- GROUP BY: row들을 그루핑 기준대로 그루핑합니다. 하나의 그룹은 하나의 row로 표현됩니다.
- HAVING: 그루핑 작업 후 생성된 여러 그룹들 중에서, 특정 조건(들)을 만족하는 그룹들만 선별합니다.
- SELECT: 모든 컬럼 또는 특정 컬럼들을 조회합니다. SELECT 절에서 컬럼 이름에 alias를 붙인 게 있다면, 이 이후 단계(ORDER BY, LIMIT)부터는 해당 alias를 사용할 수 있습니다.
- ORDER BY: 각 row를 특정 기준에 따라서 정렬합니다.
- LIMIT: 이전 단계까지 조회된 row들 중 일부 row들만을 추립니다.
테이블 조인
Foreign Key란?
- 부모 테이블의 Primary Key를 참조함
다른 종류의 테이블 조인하기 1
LEFT OUTER JOIN: 왼쪽 테이블을 기준으로 합쳐짐
왼쪽 테이블에는 있지만 오른쪽 테이블에는 없는 row는 null로 표현됨RIGHT OUTER JOIN: 오른쪽 테이블을 기준으로 합쳐짐
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item LEFT OUTER JOIN stock -- 병합 방식
ON item.id = stock.item_id; -- 병합 기준alias 붙이기
- 컬럼의 alias
- 테이블의 alias: 붙이고 나면 반드시 SQL문의 다른 부분들도 모두 alias로 수정되었는지 확인하기
SELECT
i.id,
i.name,
s.item_id,
s.inventory_count
FROM item AS i LEFT OUTER JOIN stock AS s -- 병합 방식
ON item.id = stock.item_id; -- 병합 기준다른 종류의 테이블 조인하기 2
INNER JOIN: 기준이 되는 테이블이 따로 없이, 두 테이블 전부에서 값이 있는 경우 (not null)에만 나타남 → 교집합!
SELECT
item.id,
item.name,
stock.item_id,
stock.inventory_count
FROM item INNER JOIN stock -- 병합 방식
ON item.id = stock.item_id; -- 병합 기준- 만약 두 테이블이 부모 자식 관계이고 Foreign key를 기준으로 해서 join하는 경우, 자식테이블을 기준으로 join하면 (left나 rignt OUTER JOIN을 통해), INNER JOIN과 동일한 결과를 얻음
- 그러나 그 외의 경우에는 대부분 inner join과 outer join의 결과는 달라짐
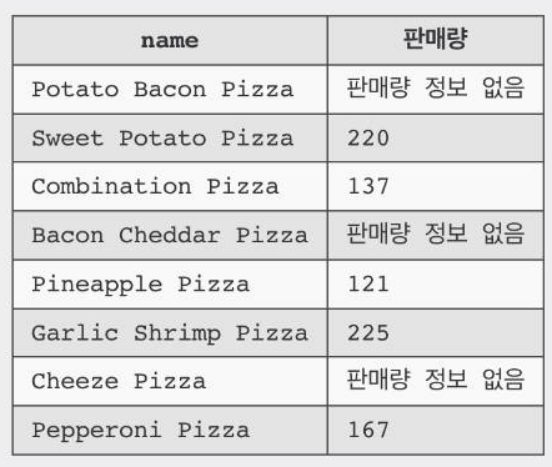
SELECT p.name,
COALESCE(s.sales_volume, '판매량 정보 없음') AS '판매량'
FROM pizza_price_cost AS p LEFT OUTER JOIN sales AS s ON p.id = s.menu_id;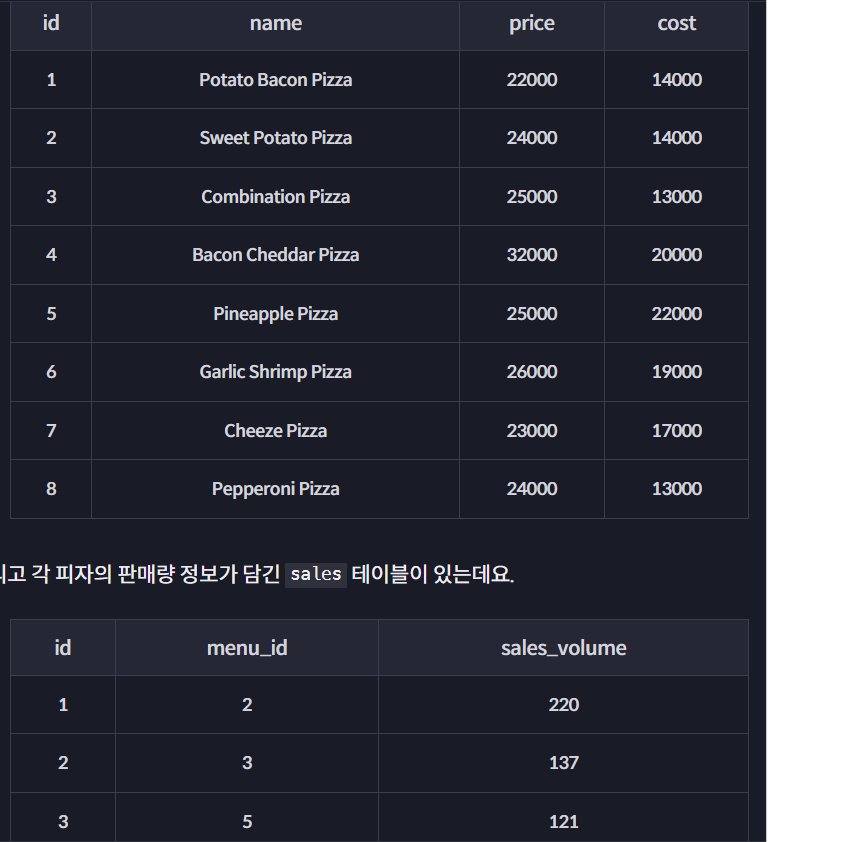
결합연산, 집합연산
- A ∩ B :
INTERSECT - A - B :
MINUS,EXCEPT - A U B :
UNION
ON (= USING)
ON:ON old.id = new.idUSING:USING(id)← 두 테이블에서 조인 조건으로 사용되는 컬럼들의 이름이 같은 경우 사용 가능!
UNION
- 제약: 컬럼 구조가 같은 테이블끼리만 UNION 연산이 가능함
✨ 그러나, 만약 SELECT절로 구조가 같은 컬럼들만 각각 선정해서 불러와준다면 컬럼구조가 완전히 일치하지 않아도 같은 컬럼이 있는 테이블끼리도 UNION 연산이 가능해짐
SELECT id, nation, count FROM t1
UNION
SELECT id, nation, count FROM t2 -
이 때 t1과 t2의 나머지 컬럼들은 일치하지 않아도 괜찮음
-
UNION은 중복을 제거하고 정렬한 결과를 반환함, UNION ALL은 중복을 포함한 결과를 반환함
서로 다른 3개의 테이블 조인하기
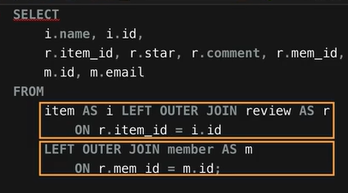
- 위와 같이 두차례에 이어서 각각 조인해줌
유의미한 데이터 추출하기
https://www.codeit.kr/topics/data-analysis-using-sql/lessons/3226
실습: member 테이블, item 테이블, review 테이블을 조인해서 남녀 공용 상품의 등록 연도별 평균 별점 확인하기
-- 남녀 공용 상품의 등록 연도별 평균 별점
SELECT YEAR(i.registration_date) AS '등록 연도',
COUNT(*) AS '리뷰 개수',
AVG(star) AS '별점 평균값'
FROM review AS r INNER JOIN item AS i ON r.item_id = i.id
INNER JOIN member AS m ON r.mem_id = m.id
WHERE i.gender = 'u'
GROUP BY YEAR(i.registration_date)
HAVING COUNT(*) >= 10
ORDER BY AVG(star) DESC;다른 종류의 조인들
서브쿼리와 뷰를 활용한 유연한 데이터 분석
서브쿼리란?
SELECT i.id, i.name, AVG(star) AS avg_star
FROM item AS i LEFT OUTER JOIN review AS r
ON r.item_id = i.id
GROUP BY i.id, i.name
-- 별점평균이 전체 평균보다 작은 경우만 필터링하려면?
-- 전체평균을 구하는 식을 서브쿼리로 작성해서 조건문에 넣어주면 됨
HAVING avg_star < (SELECT AVG(star) FROM review)
ORDER BY avg_star DESC;SELECT절에 있는 서브쿼리
- 원래의 테이블에는 없던 새로운 컬럼을 추가하는 용도로 주로 사용됨
SELECT id, name, price,
(SELECT AVG(price) FROM item) AS avg_price
FROM table.itemWHERE절에 있는 서브쿼리
- 조건문에 들어갈 값 (예: 평균값 이상인 값을 가진 컬럼들만 출력 등)을 구하는데에 연산이 필요한 경우에 주로 사용됨
- 서브쿼리의 반환값이 하나 이상인 경우도 존재함
SELECT * FROM item
WHERE id IN -- IN: 괄호 안의 하나라도 조건믈 만족하면 만족
( -- review 수가 3개 이상인 모든 상품의 id들을 반환
SELECT item_id
FROM review
GROUP BY item_id HAVING COUNT(*) >= 3
);ANY(SOME), ALL
FROM절에 있는 서브쿼리
- 서브쿼리는 단일값, 다중값 뿐만 아니라 테이블을 결과로 반환하기도 함
이 때, 반환된 테이블(derived table)에는 반드시 alias가 붙어야 함
서브쿼리의 종류
EXISTS, NOT EXISTS, 상관 서브쿼리
서브쿼리 VS 조인
서브쿼리의 중첩의 문제점
- 서브쿼리의 중첩: 서브쿼리 안에 서브쿼리를 또 삽입하는 것
뷰
- 뷰: 조인 등의 작업을 해서 만든 결과 테이블 (주로 서브쿼리의 결과)이 가상으로 저장된 형태
- 서브쿼리의 중첩을 해결할 수 있음
