그래프
그래프는 정점과 정점을 연결하는 간선으로 이루어진 자료구조를 말한다.
프로그래밍에서 그래프는 크게 2가지 방법으로 표현할 수 있는데, 인접 행렬 방식과 인접 리스트 방식이 있다.
인접 행렬
인접 행렬방식은 2차원 배열에 각 노드가 연결된 형태를 기록하는 방식이다.
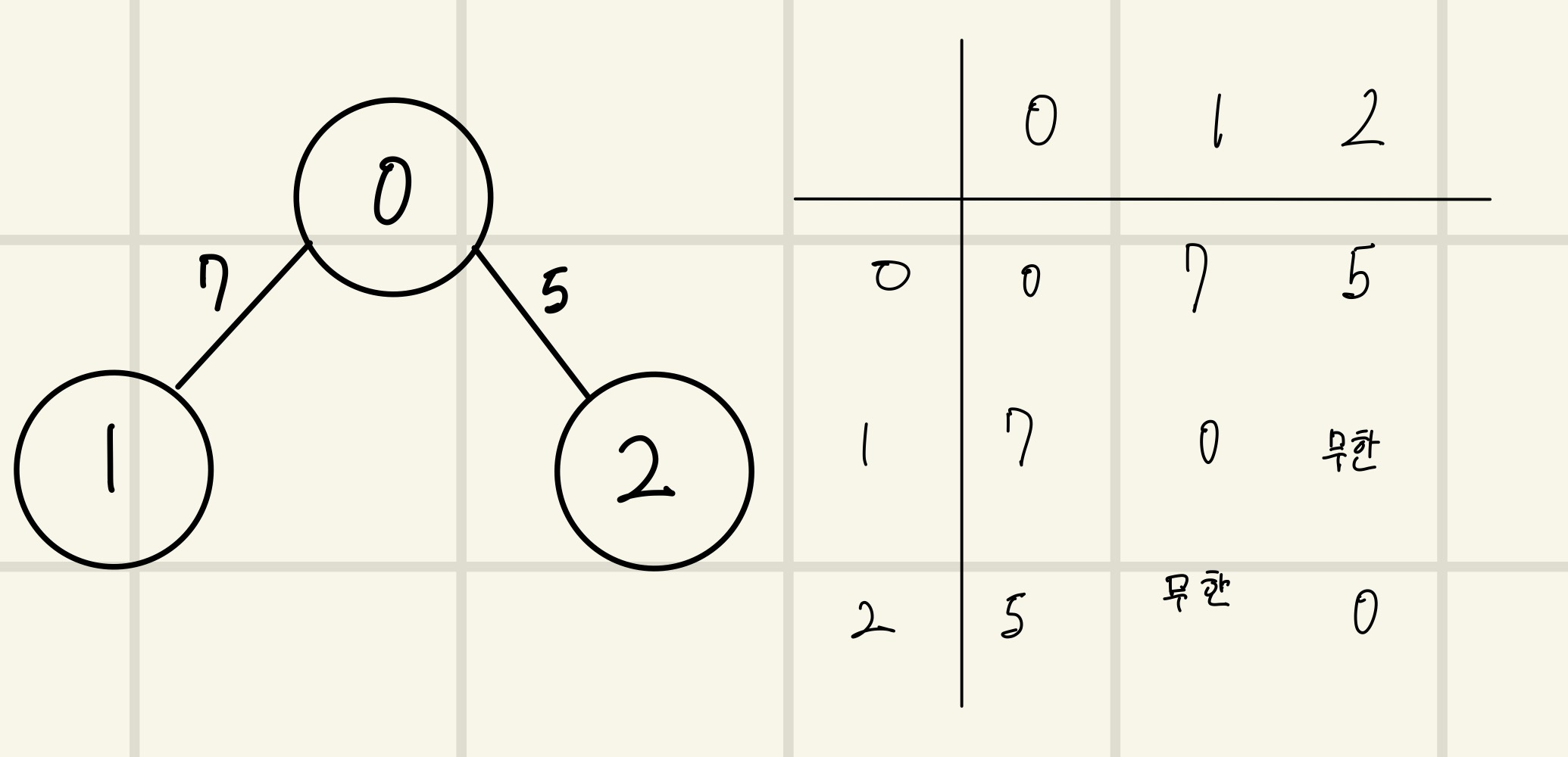
연결된 노드는 가중치값을 (가중치가 없다면 1), 연결되지 않는 노드는 무한값으로 설정한다.
무한값은 실제 코드에선 논리적으로 정답이 될 수 없는 가장 큰 값 중에 설정한다. ex)999999999
인접 리스트
인접 리스트 방식은 연결 리스트를 이용해 모든 노드에 연결된 노드에 대한 정보를 차례대로 저장한다.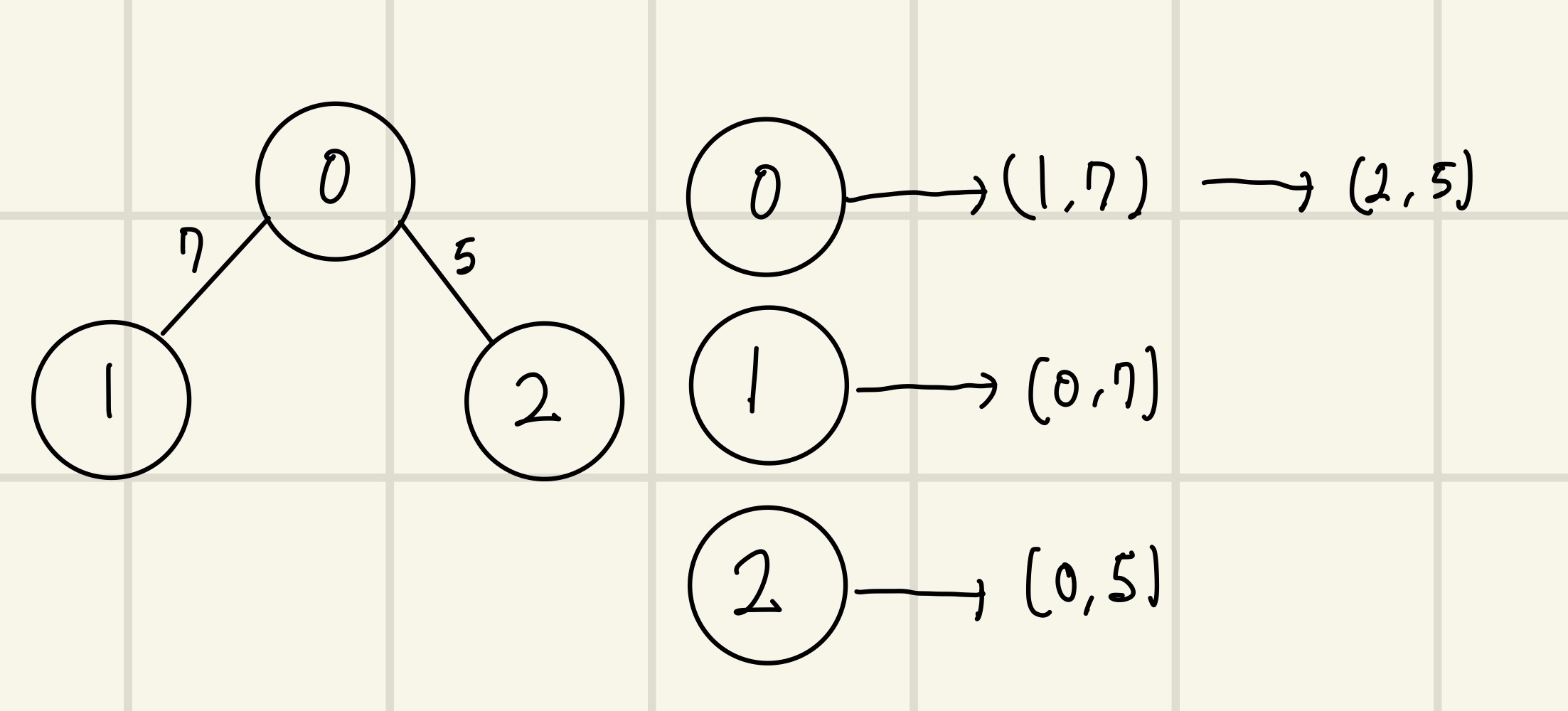
각 정점에 연결된 모든 노드를 저장한다. 가중치가 없다면, 뒤의 가중치를 때고 정점의 번호만 저장한다.
차이
인접 행렬 방식은 모든 관계를 저장하기 때문에 정점의 개수가 많아지면 많아질수록 메모리 낭비가 커진다. 하지만 인접 행렬 방식은 두 노드가 연결되어 있는지에 대한 정보 접근이 빠르다.
인접 리스트 방식은 메모리 낭비가 없지만 두 노드가 연결되어 있는지에 대한 정보 접근이 느리다.
그래프 탐색 알고리즘
이러한 그래프를 효율적으로 탐색하기 위해서, 여러가지 탐색 알고리즘 중 DFS(깊이 우선 탐색)과 BFS(너비 우선 탐색)을 가장 많이 사용한다.
DFS
DFS (Depth-First Search)는 깊이 우선 탐색이라는 뜻이다. 어쩌다 깊이 우선 탐색이라는 이름이 붙은걸까? 아래의 탐색과정을 살펴보면 바로 이해할 수 있다.
DFS는 스택 자료구조를 이용한다. DFS의 구체적인 동작 방식은 이러하다.
- 시작 노드를 스택에 삽입하고 방문처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접노드가 있다면 스택에 넣고 방문처리를 한다.방문하지 않은 인접노드가 없다면 스택에서 최상단 노드를 꺼낸다.
- 2번의 과정을 더 이상 수행항 수 없을 때까지 반복한다.
임의로 만든 그래프에 직접 이 과정을 반복해보자
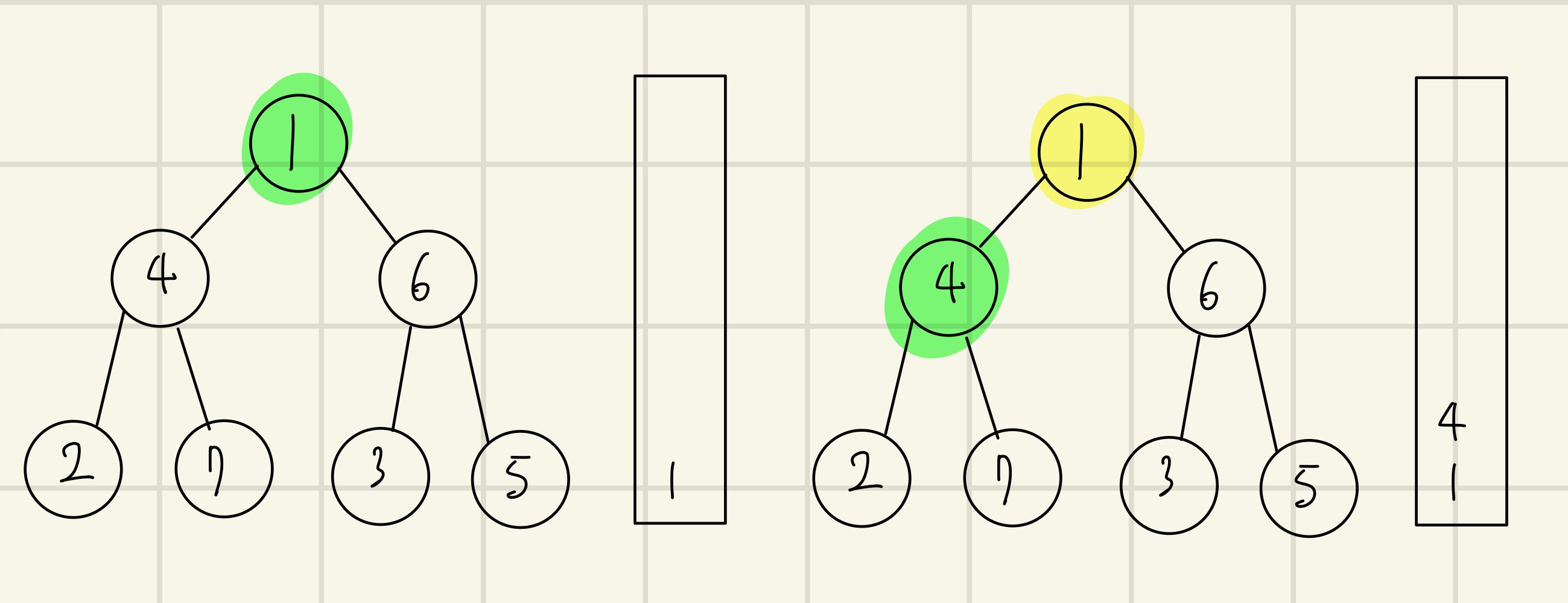
(왼) 노드 1을 스택에 넣고 방문처리를 한다.
(오) 최상단 노드인 1의 방문하지 않은 인접노드인 4를 스택에 삽입하고 방문처리를 한다.
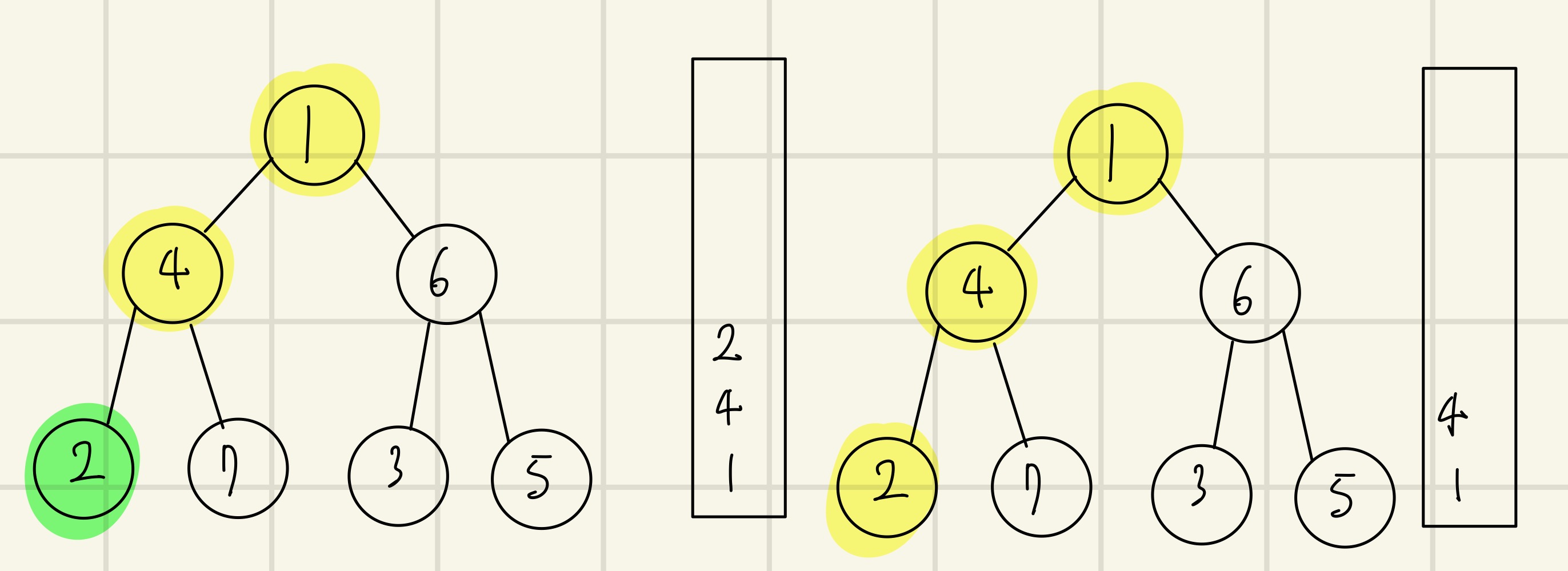
(왼) 최상단 노드인 4의 방문하지 않은 인접노드인 2를 스택에 삽입하고 방문처리를 한다.
(오) 최상단 노드인 2는 방문하지 않은 인접노드가 없으므로 스택에서 노드 2를 꺼낸다.
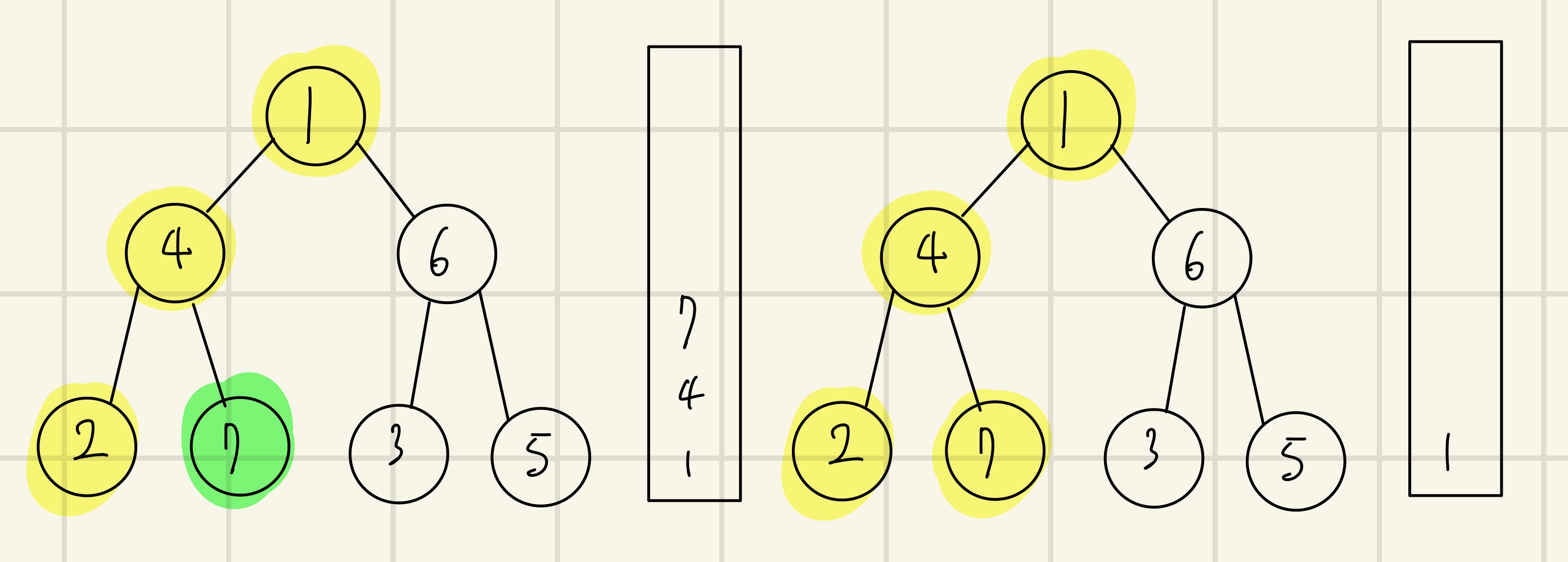
(왼) 최상단 노드인 4의 방문하지 않은 인접노드 7을 스택에 삽입하고 방문처리를 한다.
(오) 최상단 노드인 7은 방문하지 않은 인접노드가 없으므로 7을 꺼낸다.
그 다음 최상단 노드인 4 또한 방문하지 않은 인접노드가 없으므로 4를 꺼낸다.
이런식으로 계속 이어가면,
1 - 4 - 2 - 7 - 6 - 3 - 5 의 순서로 탐색을 마치게 된다.
장점
DFS는 스택 구조에 기초하기 때문에 구현이 매우 간단하다. 실제로 스택 자료구조를 쓰지 않아도 되며 데이터의 개수가 N개일 때 O(N)이 소요된다.
해당 도서를 참고했습니다.
DFS 구현은 다음 시간에 BFS를 같이 구현하는 BOJ 문제에서 올리도록 하겠습니당.~
2편 링크<<
