BFS
BFS(Breadth First Search)는 너비 우선 탐색이라는 뜻이다. 이번에는 또 왜 너비 우선일까..?
BFS는 큐(Queue) 자료구조를 이용한다. BFS의 구체적인 작동방식은 다음과 같다.
- 탐색 시작 노드를 큐에 삽입하고 방문처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문처리를 한다.
- 2의 과정을 더 이상 수행할 수 없을 때까지 반복한다.
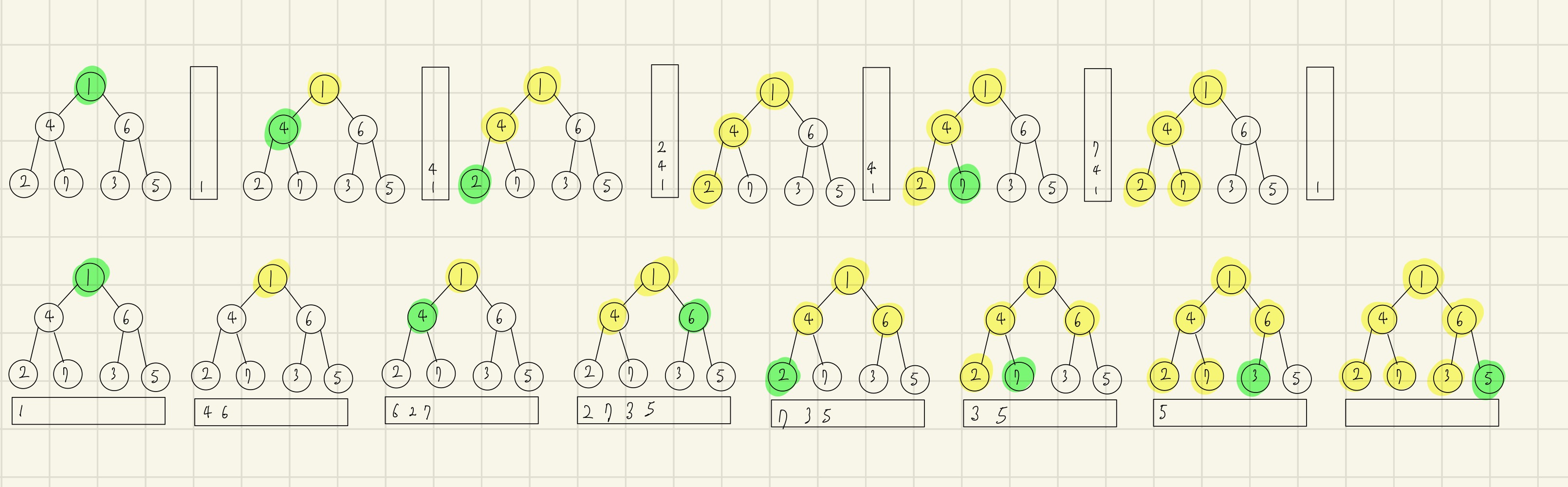
임의의 그래프로 이 과정을 반복해보자
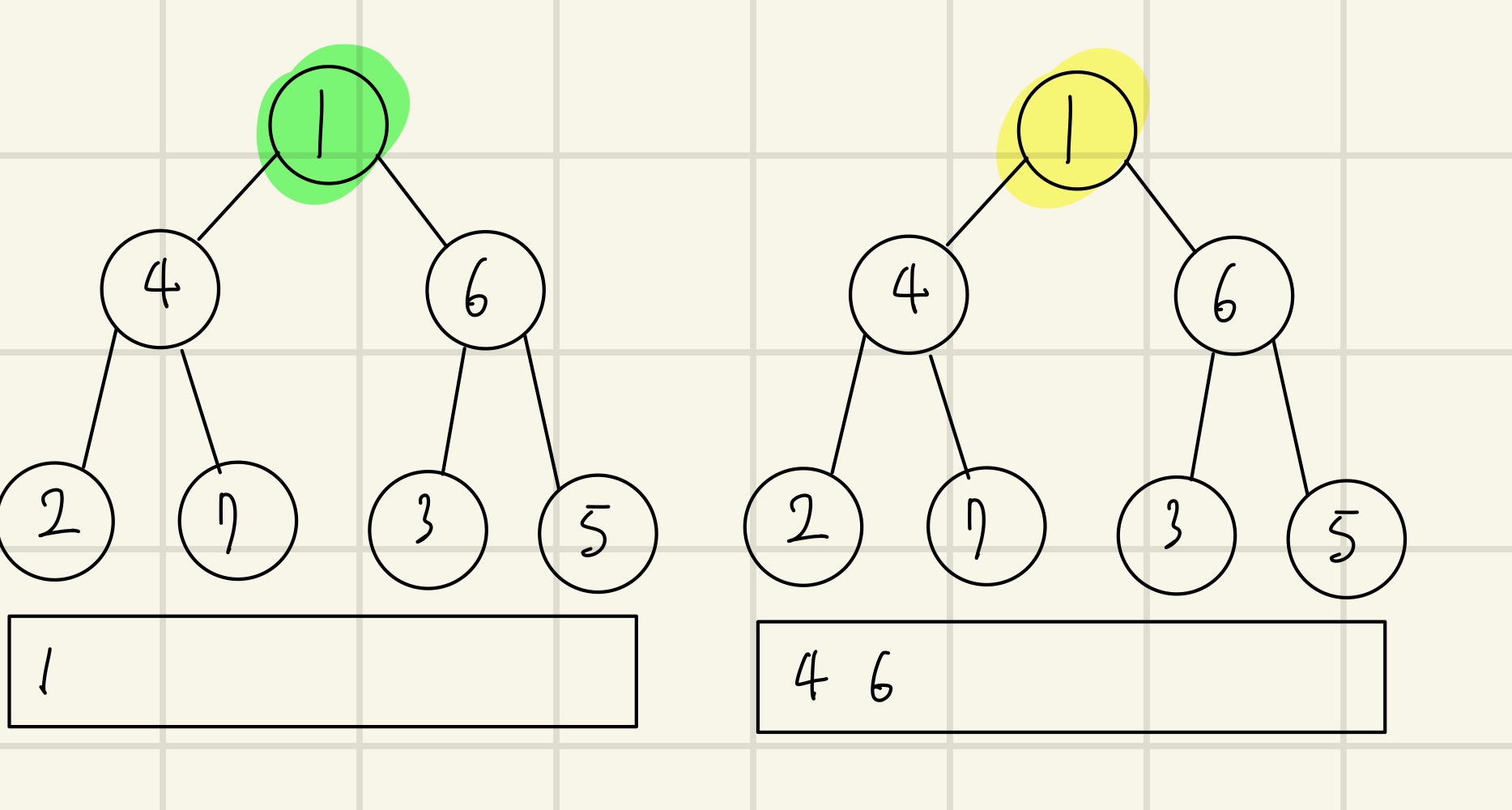
(왼) 탐색 시작 노드 1을 큐에 삽입하고 방문처리를 한다.
(오) 큐에서 1을 꺼내 1의 인접 노드 중 방문하지 않은 노드인 4, 6을 큐에 삽입한다.
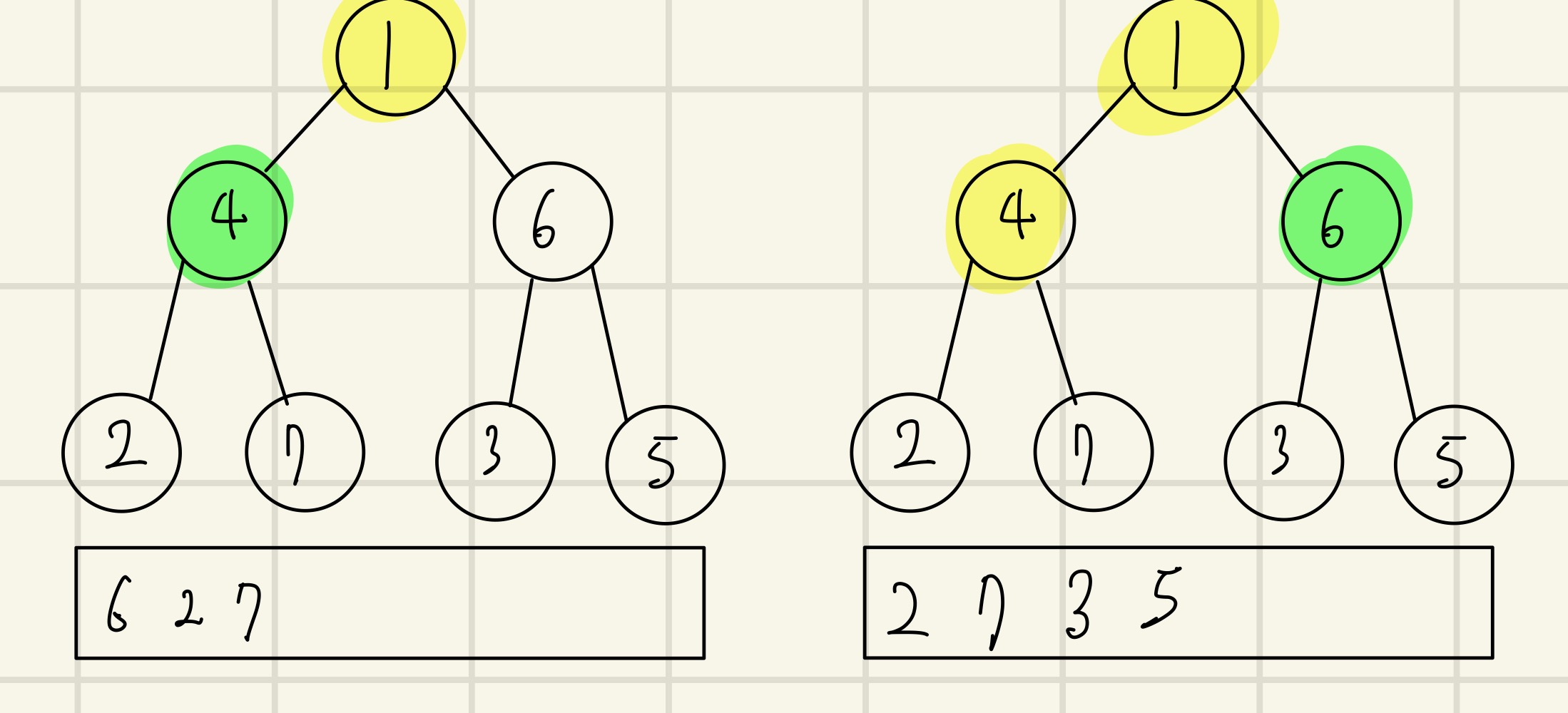
(왼) 큐에서 4를 꺼내 4의 인접 노드 중 방문하지 않은 노드인 2, 7을 큐에 삽입하고 4를 방문처리한다.
(오) 큐에서 6을 꺼내 6의 인접 노드 중 방문하지 않은 노드인 3, 5를 큐에 삽입하고 6을 방문처리한다.
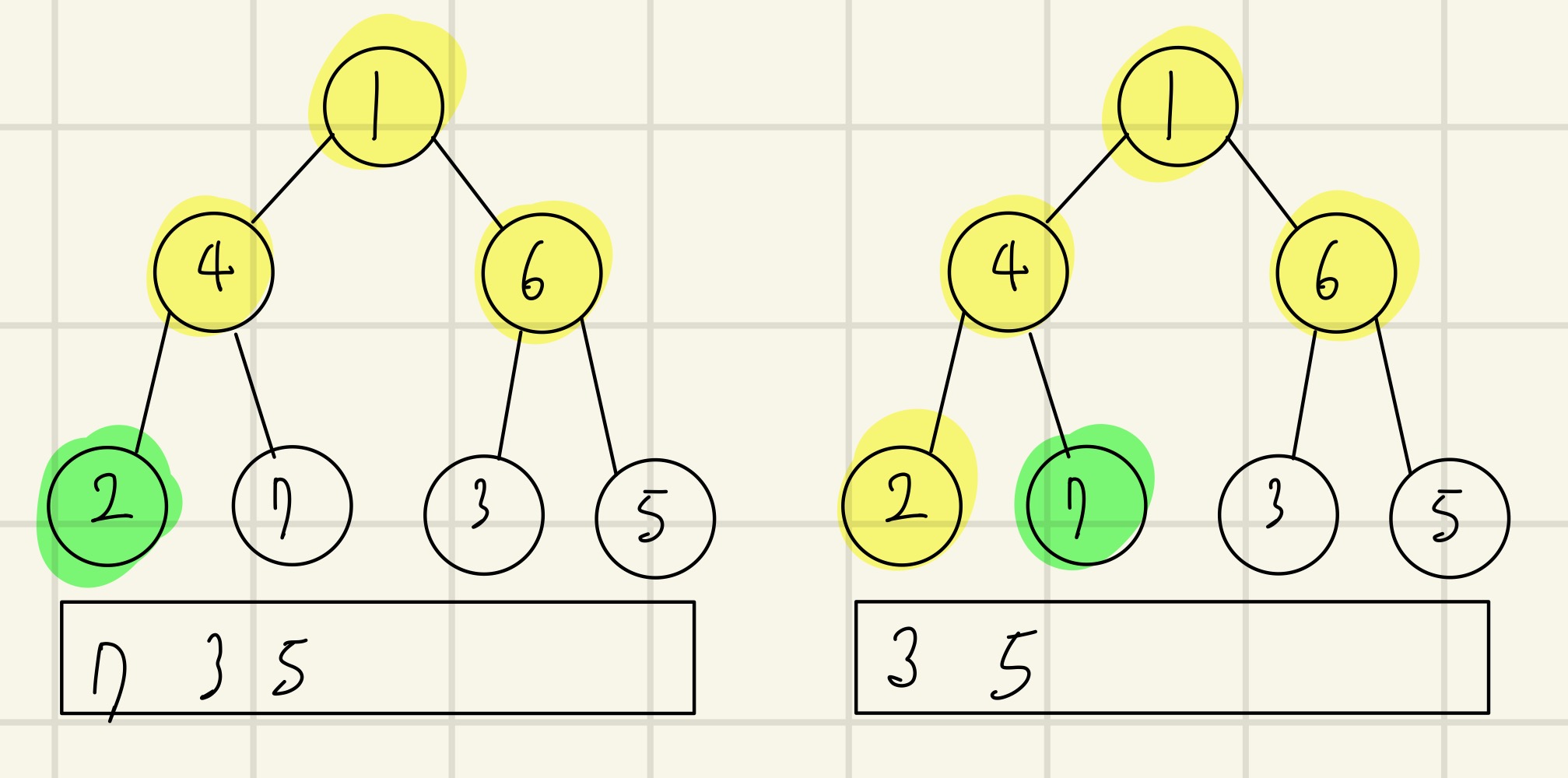
(왼) 큐에서 2를 꺼내 방문처리한다.
(오) 큐에서 7을 꺼내 방문처리한다.
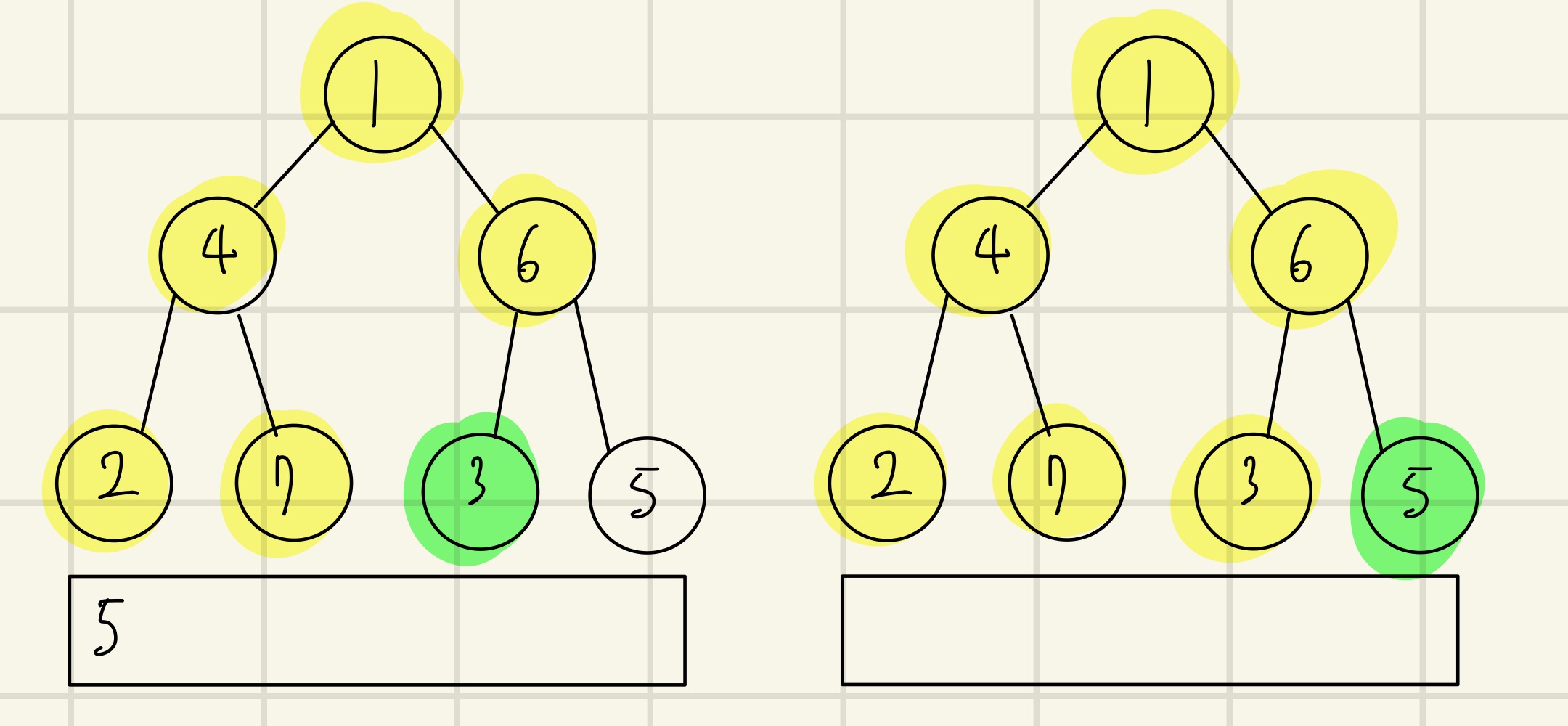
(왼) 큐에서 3을 꺼내 방문처리한다.
(오) 큐에서 5를 꺼내 방문처리한다.
계속 이어가면,
1 - 4 - 6 - 2 - 7 - 3 - 5
의 순서로 탐색을 진행하게 된다.
장점
BFS는 큐 자료구조에 기초하기에 구현이 어렵지 않다. DFS와 달리 실제로 자료구조를 구현해야 하기 떄문에, Python에서는 deque 라이브러리, C++에서는 Queue STL을 이용해 구현한다.
시간복잡도는 DFS와 마찬가지로 O(N)이나, 일반적인 경우에 실제로 DFS보다 더 빠른 편이다.
BOJ 1260번: DFS와 BFS
이 문제로 두개의 알고리즘을 다 구현해 보겠다.
인접 행렬 방식으로 구현하였다.

import sys
from collections import deque
input = sys.stdin.readline
n, m, v = map(int, input().split())
graph = [[0 for _ in range(n + 1)] for _ in range(n + 1)] # 인접행렬 방식으로 저장
for i in range(m):
x, y = map(int, input().split())
graph[x][y] = 1
graph[y][x] = 1
# DFS
vis = [0 for i in range(n + 1)]
def dfs(x): #재귀를 이용해 스택 자료구조 구현
vis[x] = 1 #방문처리
print(x, end=' ')
for i in range(1, n + 1):
if graph[x][i] == 1 and vis[i] == 0:
dfs(i) #방문하지 않은 인접한 노드 재귀호출.
# BFS
q = deque() #deque로 큐 자료구조 구현
vis = [0 for i in range(n + 1)]
def bfs(x):
q.append(v) # 시작노드 먼저 큐에 삽입
while q:
top = q.popleft()
if vis[top] == 0:
print(top, end=' ')
vis[top] = 1 #방문처리
for i in range(1, n + 1):
if graph[top][i] == 1 and vis[i] == 0:
q.append(i) #방문하지 않은 인접노드 큐에 삽입.
dfs(v) #함수 호출~~~~
print()
bfs(v)
짠. 완성입니당~
노가다 쉽지 않았어......
DFS BFS 다까먹어서 다시공부하기 쉽지않았어.........
이 책<< 을 참고했습니다.

좋은 글 잘 보고 갑니다 ^_^ ~~