1. Introduction
- few-shot 성능은 모델의 파라미터 크기와 학습 데이터가 크기와 관련이 있다고 가정할 수 있음
- 그러나 few-shot learning의 성능이 in-parameter memorisation과 동의어는 아니고
- few-shot learning이 어느 정도의 방대한 모델 파라미터와 데이터를 요구하는지, 그 효율적인 정도도 매우 unclear한 상태
- 따라서 본 논문에서는 파라미터 메모리에 저장되어 있는 기억을 가져와서 사용하는 것에 대한 조사를 진행하는 한편, non-parametric knowledge를 이용하기 위해서 retrieval-augmented architecture를 제안한다.
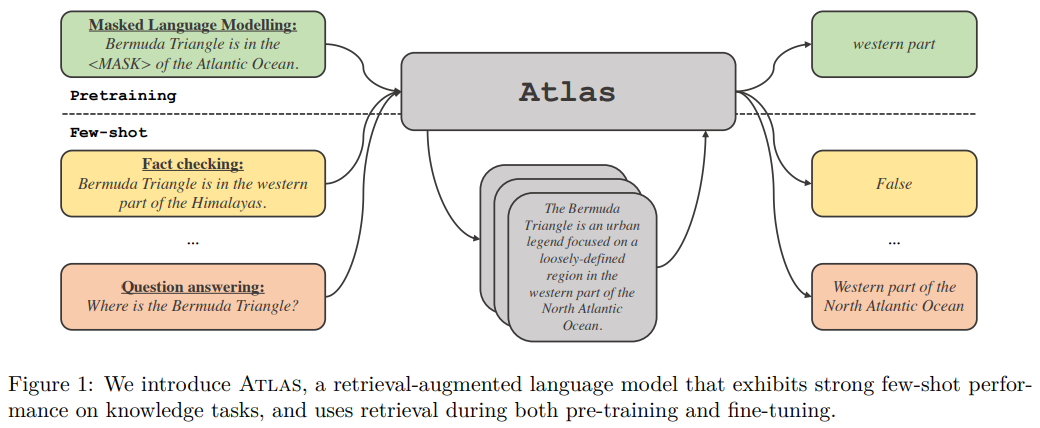
- 제시하는 모델은 ATLAS, a retrieval-augmented language model capable of strong few-shot learning, despite having lower parameter counts than other poweful recent few-shot learners
- ATLAS
- relevant documents를 찾는 retrieval 단계 (dual-encoder architecture)
- sequence-to-sequence로 답변을 생성하는 단계
- pretrain과 finetuning단계에서 모두 retrieval - generation을 통해서 학습이 진행됨
- question answering 과 fact checking에서 성능을 측정했을 때 (few-shot / resource-rich) 11B 만으로도 PaLM 모델을 능가하기도 했음
- main contributions
- retrieval-augmented language model 구축 방법
- pretrain / finetuning strategy
- 실험 결과 좋은 성능을 보임
2. Method
- text-to-text framework 를 따르고 있음
- input과 output이 모두 text이기 때문에 query와 그에 해당하는 output은 모두 텍스트로 구성되어 있음
- 대부분의 language processing 테스트가 knowledge를 필요로 하고 있기 때문에 retrieval을 함께 함으로써 모델의 few-shot 성능을 높일 수 있을 것이라고 가정함
2.1. Architecture
- 2개의 서브 모듈: retriever와 language model로 이루어짐
- retriever에 의해 top-k relevant documents가 찾아지고
- 이후에 document는 language model에 query와 함께 입력으로 들어가게 되어서
- 최종적으로 output이 생성됨
- retriever와 language model은 모두 pretrained transformer network에 기반을 두고 있음
Retriever
- 검색 모듈은 Contriever를 기반으로 하고 있음
- information retrieval technique based on continuous dense embeddings
- dual-encoder- architecture: query와 document가 독립적으로 transformer encoder에 의해 임베딩
- average pooling을 거쳐서 최종 임베딩이 나옴
- query와 document의 유사도는 두 임베딩 간 dot product를 계산함으로써 얻어짐
- Contriever model은 MoCo contrastive loss로 pre-train되었고, unsupervised data만 사용하였음
- dense retriever의 장점은 documnet annotation없이 gradient descent나 distillation만으로 학습될 수 있다는 점
Language model
- T5 sequence-to-sequence architectur를 따르고 있음
- Fusion-in-Decoder modification을 sequence-to-sequence model에 적용하였음
- 인코더에 독립적으로 각각의 document를 넣고, 그 결과로 나온 인코더의 output을 decoder에 넣어서 cross-attention을 수행하였다.
- query는 각가의 document에 대해서 concatenate하여 집어넣었다
- 또 다른 방법으로는 하나의 쿼리에 대한 모든 문서를 다 concat하는 방법도 있지만, scale 문제로 실정하지 못했다. (인코더의 self-attention은 document 숫자에 quadratic complexity 를 가지기 때문)
2.2. Training objectives for the retriever
- retriever를 language model과 jointly 학습하는 방법에 대해 논의할 것이다.
- language model를 사용하는 loss functions 은 retriever를 학습하는 데에 있어서 supervisory signal 로 활용된다.
- 이 말의 뜻은, language model이 output을 생성하는 데에 retriever가 찾은 문서를 유용하다고 생각했다면, retriever objective는 retriever가 그 문서에 대한 rank를 올리도록 장려해야 한다.
- 이 방식을 통해서 query와 output pair만 있고, document annotation은 없더라도 학습이 잘 진행될 수 있도록 한다.
- 예를 들어 fact checking task라고 한다면, 모델은 claims과 verdicts만 잇으면 되고 그에 해당하는 document는 없어도 된다.
- 이 방식은 few-shot 뿐 아니라, self-supervising 방식에 모두 활용가능해서 모델의 활용 확장성이 매우 높다고 할 수 있다.
- experimental section에서 보여질 것과 같이, few-shot 성능에는 pre-training이 매우 critical하다.
discussion of 4 different loss function
- Attention Distillation (ADist)
- language model의 cross-attention score에 기초를 둔 방식
- retriever가 검색한 문서들에 대해서 1) query와 document 벡터들 간의 dot-product 유사도의 softmax 분포와 2) input documents와 output의 cross attention 값에 대한 softmax 분포에 대해서 KL-divergence를 minimize하는 loss이다.
1) p_RETR 를 정의한다.
- p_RETR는 아래의 수식으로 정의된다.
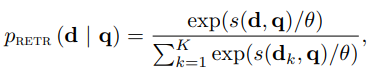
- d_k는 retriever에 의해 검색된 top-k documents들이다.
- 이는 query와 document 벡터들 간의 dot-product 유사도를 구하고, 그것들의 softmax 분포를 나타낸다.
2) p_ATTN (d_k) 를 구한다.
- 먼저 attention 함수는 다음과 같이 정의된다.
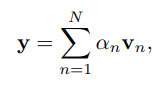
- particular token n에 대한 attention output y는 attention score a_n과 norm of value v_n이 필요하다.
- 따라서 이곳에서는 다음의 수식을 token n에 대한 relevance를 측정하는 데에 사용한다.
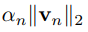
- 이후 이 score를 모든 attention heads와 layers, tokens에 대해서 문서에 대한 평균을 내서 구한다.
- 그 socre에 SOFTMAX 연산을 적용하여 pAATN(dk를 구한다.
3) 1) 과 2) 분포의 차이를 줄일 수 있도록, KL-divergence를 최소화하는 수식을 정의한다.
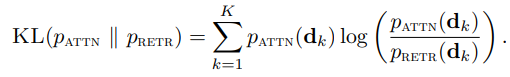
- 이 loss는 only retriever를 최적화 하는 데에만 활용되고, language model을 최적화하지는 못한다.
- 따라서 p_AATN을 구할 때는 STOPGRADIENT 함수를 사용한다.
2. End-to-end training of Multi-Document Reader and Retriever (EMDR2)
- expectation-maximization algorithm
- retrieved documents를 latent variable로 다룬다.
- query q가 주어졌을 때 이에 해당하는 output a와 retriever가 찾아온 top-k의 문서 d_k가 있다고 할 때, EMDR2 loss는 다음과 같다.
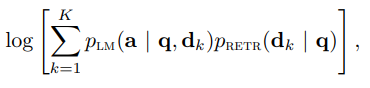
- 위의 log-likliehood 를 maximize하는 방식으로 학습이 진행된다.
- EMDR2 loss fuction은 token level에 적용되고, sequence level에는 적용되지 않는다.
3. Perplexity Distillation (PDist)
- 위의 2가지 loss 함수로부터 영감을 얻은 simpler loss function
- retriever가 각 문서가 얼만큼 language model의 output의 ppl을 개선시키는지 예측하게끔 학습시키는 것이 목표
- KL-divergence를 minimize하는 것이 목표
- 1번 loss 함수에서 정의했던 p_RETR (retriever가 찾은 문서와 쿼리의 dotproduct 에 대한 softmax 분포)와
- p_k (query와 각 document가 주어졌을 때 ouput a가 나올 확률 softmax 분포 )에 대한
- KL-divergence를 minimize하게끔 학습
- 여기서의 p_k는 query와 d_k가 주어졌을 때의 output a 가 나올 확률에 비례한다고 보고,
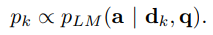
- 동일하게 softmax operator를 사용한다.
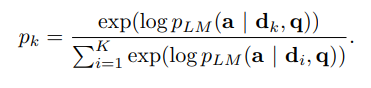
4. Leave-one-out Perplexity Distillation (LOOP)
-
이 loss 함수는 top-k retrieved document 중 문서 하나씩을 지워나갈 때마다 얼마나 language model이 나쁜 결과를 얻게 되는지를 측정한다.
-
이를 계산하기 위해서 k-1 documents subset에 대해서 log probability를 계산하고, each document에 대한 relevance score에 음수를 사용한다.
-
이전 loss 함수들과 동일하게, 이곳에 softmax 함수를 사용해서 documents의 distribution을 측정한다.
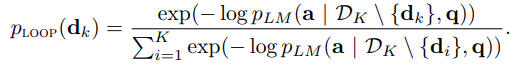
-
이 loss는 앞의 loss들에 비해 expensive하지만, language model에 보다 closer 한 방식이다.
-
모든 loss 들에 대해서 temperature hyper-parameter를 조절할 수 있다.
-
또한 PDist 나, LOOP에 대해서 ppl값은 특히 long output에 대해서는 document 별로 많이 달라지지 않는 문제점이 있었다.
2.3. Pretext tasks
- 이 section에서는 retriever와 language model를 jointly pre-train할 때 사용한 pretext tasks에 대해서 이야기한다. (using only unsupervised data)
Prefix language modeling
- N개의 토큰이 있는 sequence에 대해서, 이를 반으로 나누어서 N/2개의 시퀀스 두 개로 만든다.
- 첫 번째 시퀀스는 query, 두 번째 시퀀스는 output으로 사용한다.
- 따라서 첫 번째 시퀀스로 relevant한 document를 찾아서 두 번째 시퀀스를 생성하게끔 하는 방식으로 output을 생성한다.
Masked language modeling
- T5에서 사용한 MLM과 같은 방법
- N개의 words가 있는 시퀀스에 대해서 average length가 3인 k sapn (마스킹될 스팬)을 뽑느다.
- masking ratio는 15%가 되게끔 한다.
- 각 span은 difference special token으로 놓고, 모델은 마스킹된 span을 generate하게 하는 것이 목표이다.
- retrieve에 사용되는 query는 masked된 query를 상요하는데, retriever vcab에 의해 support되는 speical mask token을 사용한다.
Title to section generation
- abstractive generation task를 고려하였다.
- Wikipedia articles 데이터셋에서
- query는 article 제목과 section 제목을 사용하고
- output은 그에 해당하는 text section이 되게끔 한다.
- “see also”, “references”, “further reading”, “external links”는 제외
2.4. Efficient retriever fine-tuning
-
Retrieval 모델 학습 과정의 recomputation은 too expensive
- retrieval은 document index를 fresh하게 유지해야 한다.
- 그 말은 즉슨 retriever와 language model을 jointly training을 할 때, retrieval corpus에 해당하는 document embedding도 전부 다 업데이트 되어야 한다는 것을 의미한다.
- recompute the document embedding은 large indices에 대해서 너무 expensive한 단점이 있다.
- 특히 fine-tuning 단계에서도 똑같이 적용된다.
- 비교적 적은 example을 사용하고 있지만,
- 여전히 retriever 모델을 학습하는 것은 computational overhead가 standard language model finetuning보다 오래 걸릴 수 밖에 없다.
- 따라서 문서의 embedding을 re-compute하는 것을 완화할 수 있는 방법에 대해서 소개한다.
Full index update
-
과정과 계산을 통해서, 정해진 스텝마다 일정한 batch size에 대해서 모든 문서에 대한 임베딩을 업데이트 한다고 하면 overhead가 ~30% 까지 늘어날 수 있다.
Re-ranking
- retriever로 larger number의 document를 찾아놓고, 그 document들에 대해서만 re ranking과 re embedding을 진행하는 방식
- 만약에 이전보다 10배 많은 document만 임베딩을 다시 한다고 하면, ~10%의 overhead가 발생할 수 있다.
- 그러나 여러 문서들이 다 업데이트가 되어야 하는 상황도 있다 (예를 들어 true top-k document가 top-L에 포함되지 않은 경우 등)
- 실제 구현에서는 top-K를 top-L안에서 reranking을 하고 그 중에서 update해야 하는 인덱스를 찾는 방식 등이 필요하다.
Query-side fine-tuning
- 마지막 방법은 document의 임베딩은 update하지 않고, query의 임베딩만 업데이트 하는 방식이다.
- 이 방식은 task 별로 성능의 차이가 큰 편인데
- 매우 큰 데이터셋이 있는 현재의 고려 상황에서는 크게 성능저하가 없고 심지어 성능이 더 좋을 때도 있었다.
3. Related work
3.1 Retrieval in natural language processing
- Retrieval for knowledge intensive tasks
- question answering, fact checking, dialogue, citation recommendataion 등에서 사용
- 예전에는 주로 TF-IDF나 BM25를 사용하였음
- dense retriever가 인기를 얻으면서, dual-encoder architecture가 인기를 얻었음
- Retriever training
- Retrieval-augmented language models
- Retrieval-Augmentation with Search Engines → 서치 엔진에 검색할 쿼리를 작성하는 등의 방식으로 서치 엔진에서 가져오기도 함
3.2 Few shot learning
- In-context Learning with Large Language Models
- GPT가등장하면서 in-context learning 이 주목을 받기 시작함
- Few-shot finetuning and prompt-based learning
- prompts를 어떻게 설계하느냐에 따라서 성능이 달라지기도 함
- few-shot만 가지고 fine-tuning해서 일부 model의 파라미터만 업데이트 하는 방법론도 있음
4. Experiments
4.1 Benchmarks
- Knowledge-Intensive Language Tasks (KILT): fact checking, question answering, dialog generation, entity linking and slot-filling
- TriviaQA, HotpotQA, Zero Shot RE, t-reX, aida cOnll-YAGO, WoW, FEVER
- Massively-Multitask Language Understanding (MMLU)
- zero-shot setting
- multi-task few-shot
- transfer learning: MMLU가 아닌 다른 multiple choice 데이터셋으로 train하고 성능을 측정
- Additional benchmarks
- original versions of NaturalQuestions, TriviaQA, FEVER
- TempLMA
4.2 Technical details
Pre-training
- initializing the retriver module: unsupervised Contriever model
- BERT-base architecture
- initializing the language model: T5 pre-trained weight
- original T5 pre-trained model이 supervised data를 포함하고 있기 때문에, unlabeled text만으로 학습된 version1.1 model을 사용
- T5-lm-adapt variant로 초기화해서 stability 를 높이고자 했다.
- ablation study는 T5-XL 3B 모델을 사용했다.
- 모든 모델은 10,000 iteration 만큼 학습했고
- AdamW
- bach size 64
- learning rate of 10^-4 for the reader and 10^-5 for the retriever linear decay and 1,000 warmup steps
- refresh the index every 1,000 steps
- index는 10번 계산되었다는 것이고, 30% 정도의 overhead가 발생하였다.
- retrieved documents는 20개로 설정하였다.
Fine-tuning
- downstream task를 위해서는 fine-tuning을 진행하였다.
- fixed number의 fine-tuning iteration을 진행하였다.
Unlabeled datasets
- Dec. 10, 2021 Wikipedia dump
- 37M passages
- 2020-10 common crawl dump, CCNet pipeline
- 350M passages
4.3 Pre-training loss and tasks
- ablation study
- pre-training tasks와 objective functions를 비교
- 2가지 question에 대답하는 것이 목표
- jointly pre-training the whole model lead to better few-shot performance?
- What is the best objective function for the retriever, and the best pretext task?
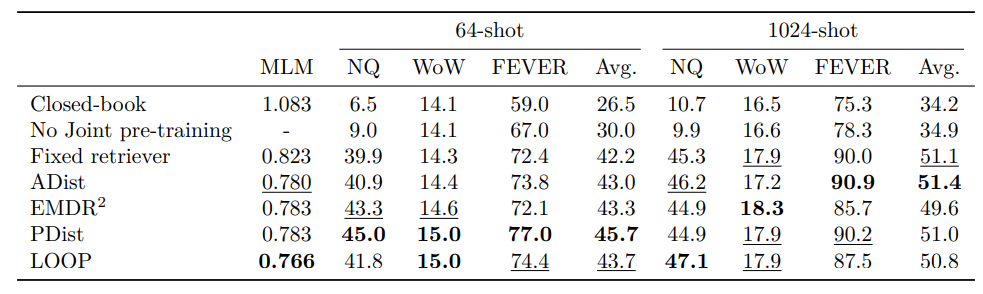
Table1
-
retriever training objectives: 4가지를 비교
-
pretext-tasks: masked language modelling task
-
baselines 모델 설명
- closed-book baseline: non-augmented T5 (즉 retriever가 달려있지 않은 그냥 language model T5)
- No Joint pre-training: MLM을 진행할 때 jointly하게 학습하지 않은 것
- Fixed retriever: retriever에 대한 추가 학습을 하지 않은 것 (mlm에서 쿼리로 가져오는 jointly 학습은 진행했지만, retrieval training object를 통한 추가적인 학습은 없었던 것)
-
Closed-book과 No Joint pre-training의 결과 해석
- closed-book baseline을 보면 retrieval-augment가 필요함을 알 수 있음
- 또한 few-shot 성능을 위해서 retrieval 모델이 있는 것이 매우 중요하다는 것을 알 수 있음
-
Fixed retriever와 4가지 retriever training objectives 비교
- MLM validation metric을 보면 joint로 pretrain을 진행한 맨 위의 두줄 (joint pretrain 안 한 것) 보다 성능이 향상되었음을 알 수 있음
- 사실 retriever training objective 사이의 성능 차이는 크게 나타나지 않았음
- 그 이유는 pre-training의 biggest impact는 retrieved document에서 information을 aggreagte하는 language model에 있기 때문인 것 같음
- 또한 retriever training objectives 간 큰 시스템적 차이는 없었기 때문에
- 본 연구에서는 PDist가 EMDR^2나 ADist보다 성능이 stable하고, LOOP보다 computationally efficient 하기 때문에 PDist를 선택함
Table2

- comparing different self-supervised pretext tasks
- MLM이 좀 더 성능이 좋았기 때문에 채택
Table3
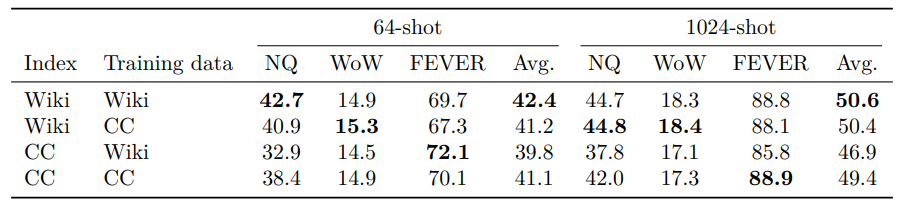
- consider different combinations of data sources for the index and training data during pre-training
- Wikipedia-based index leads to better downstream perofrmance
- wikipeida 데이터를 few-shot task에서 사용하기 때문에 같은 데이터로 pretrain을 했을 때 성능이 좋아질 것이다.
- wkikipedia 가 더 knowldge 측면에서 higher quality일 것이다.
- common crawl index를 상요할 때 wikipedia data를 pretraining을 하면 성능이 떨어지는 것을 확인했다.
- 두 도메인 사이에서의 distribution mismatch가 원인이 되었을 것이다.
- 따라서 both domain에서 both index과 pre-training data를 사용하기로 결정
4.4 Fine-tuning
- 이번 섹션에서는 모델을 downstream tasks에 적용하여 finetuning할 때 적용하는 방법론에 대한 ablation study를 진행한다.
- 특히 다음의 질문에 대해서 대답하고자 한다.
- How to efficiently fine-tune ATLAS on tasks with limited training data?
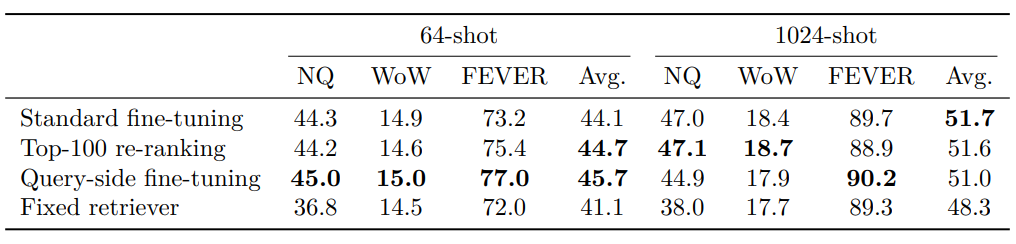
- pretraining 에서와 같이 retriever를 fix 시키는 것 보다는 fine-tuning을 하는 것이 성능이 더 좋게 나오는 것을 확인할 수 있었음
- query encoder만 학습하는 것은 꽤 좋은 성능을 기록하는 것을 확인할 수 있었음
- 64-shot에서는 query-side fine-tuning이 효과적이었고, 1024-shot 에서는 standard fine-tuning이 성능이 더 좋았음
4.5 Training and evaluating Atlas
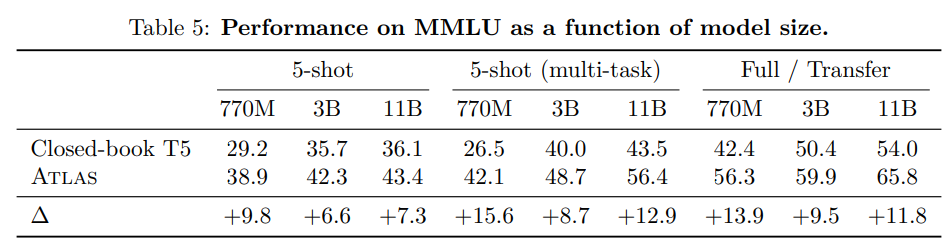
4.5.1 MMLU Results
- MMLU 학습에는 4가지 setting이 존재
- 1) a zero-shot setting: pretrained model을 no few-shot finetuning으로 진행
- 2) a 5-shot setting: 57개의 domain에 대해서 각각의 모델을, 5개의 training example을 학습시킴
- 3) a 5-shot multitask setting: single model을 5*57개 domain 데이터로 finetuning을 시킴
- 4) a setting with acces to a number of auxiliary datasets : 95K dataset. 즉 train 데이터 모두와 나머지 transfer learning에 사용될 데이터셋을 모으는 단계??
- 모델이 A,B,C,D 를 생성하도록 train 시켜놓음
De-biasing

- finetuning을 진행할 때 answer option을 permutation하는 방법을 사용하여음
- inference 과정에서도 de-bias가 필요함
- A를 B로, B를 C로 바꾸는 하나씩 밀리는 permutation을 4번 진행
- 4개의 probability들을 sum해서 final prediction을 얻는다. (똑같은 answer에 대한 정답을 얻기 위해서)
- zero-shot과 5-shot 에서는 de-biasing 성능이 매우 좋은 것을 확인, 데이터셋이 많아질 경우에는 성능이 크게 향상되지는 않음
Comparison to published works
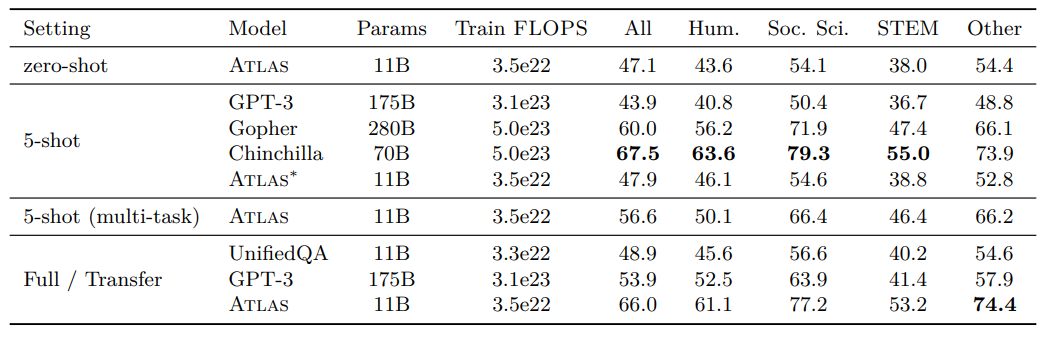
- ATLAS가 zero-shot, de-biased inference에서 GPT3의 5-shot 성능보다 좋게 나온 것을 확인할 수 있다.
- 5-shot에서도 gopher와 비슷한 수준의 성능을 볼 수 있었다.
- full/transfer에서도 좋은 성능을 보였다. (SOTA에 근접)
4.5.2 Open-domain Question Answering Results
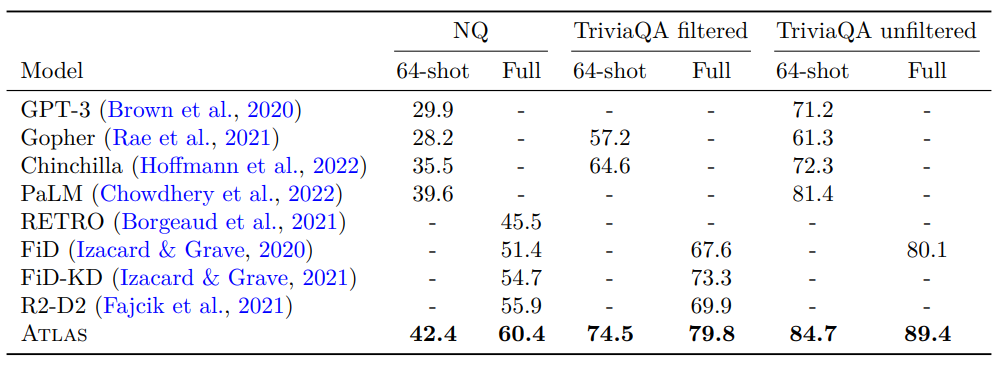
- 64shot에 대해서는, 64개의 데이터에 대한 fine-tuning을 진행함
- SOTA를 달성함
4.5.3 FEVER Results
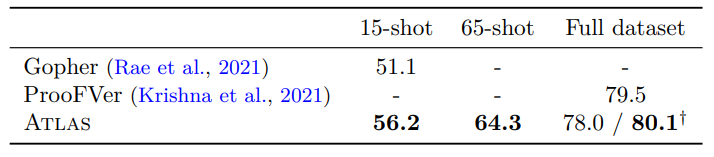
- data가 imbalanced하기 때문에 3가지 label을 동등하게 5개씩 뽑아서 few-shot setting을 하고 fine-tuning도 한 결과.
- SOTA 달성
4.5.4 KILT Results
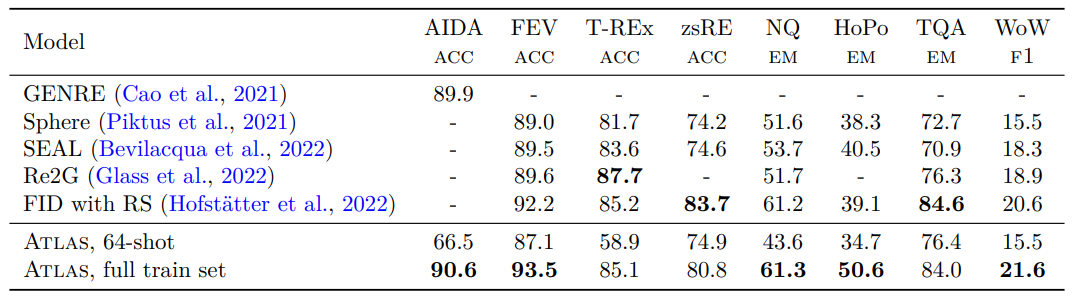
5. Analysis
5.1 Interpretability and Leakage
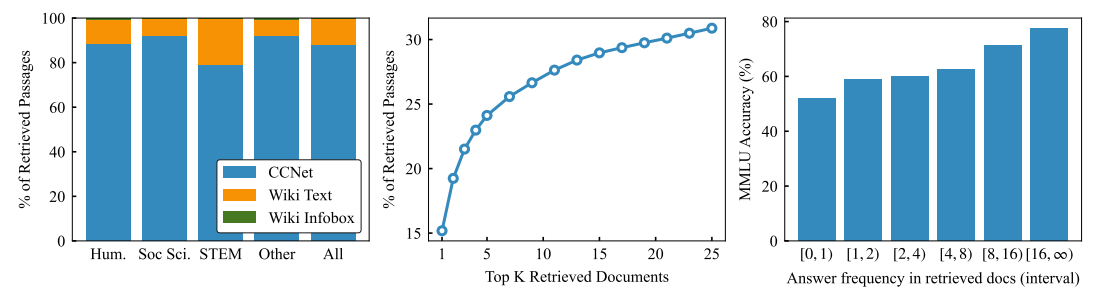
- 맨 오른쪽은 retrieved docs에 answer가 얼마나 많이 포함되었는지에 따른 MMLU ACC이다.
- 위키피디아 db는 index 측면에서 10% 정도만 있었음에도 불구하고 15% 정도나 찾아지는 것으로 보아서 위키피디아에 많은 정보가 들어있음을 알 수 있다.
5.2 Temporal Sensitivity and Updateability
-
시간이 지남에 따라 답이 바뀔 수 있는 질문들로 이루어진 TempLAMA 데이터셋으로 평가를 진행
-
2017년과 2020년에 정답이 달라질 수 있는 데이터셋을 뽑아서 실험을 진행
-
248 training set, 112 dev set, 806 test set qeustion을 구성
-
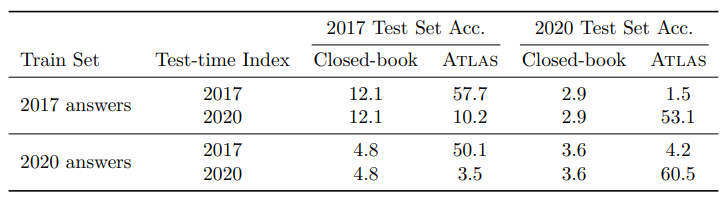
첫 번째 실험 (temporal effct for templama)
- ATLAS 와 T5를 2017년 데이터로 학습 시켰을 때
- 2017년 test set에 대해서는 성능이 좋게 나왔음
- 그러나 2020년 데이터에 대해서는 당연히 성능이 ㅇ나 좋게 나옴
- ATLAS 를 2020년 index로 retrieve할 문서를 바꾸고 따로 retrain을 하지 않은 결과
- 53.1%로 거의 57.7%까지 올라왔다.
- 이 점을 통해서 atlas가 index에 faithful하고 condition strong하다는 것을 알 수 있다.
- 2020년 데이터로 학습시켰을 때
- T5 (closed book)은 성능이 떨어지는데, 이는 pre-train 데이터 자체가 2020년 보다 이전의 것이기 때문인 것으로 보임
-
두 번째 실험 (temporal effects for NaturalQuestions)
- NaturalQeustions은 2018년이라는 시기적인 bias가 많은 데이터셋
- index 데이터를 시기별로 바꾸었을 때 성능이 더 높았다는 것을 확인할 수 있었음

6. Discussion
- ATLAS, a large retrieval-augmented language model
- jointly pre-training the retriever module and the language model
- ATLAS shows strong few-shot learning capabilities on a wide range of knowledge intensive tasks
- 또한 fine-tuning을 full로 했을 때 성능이 더 좋았으며
- updatability가 높다는 것도 확인이 되었다.
