
retriever-read model pipeline를 완성하는 실습과정을 공유해보고자 합니다! 특히 인코더 모델 학습하는 코드와 과정을 정리해봤습니다!
1. 인코더 계열 모델 직접 학습 (Local GPU)
-
GPU 자원 중 사용할 수 있는 것이 있어서 실제 학습 공부할 겸,, 도전!
-
max_length 2048 기본 / 모델은 longformer, deberta
- longformer 모델은 4096 까지 max length로 받을 수 있음
- deberta도 max length 512를 넘길 수 있음
-
finetuning 학습 데이터셋 (1000개)
- stem 1k 데이터셋만 사용 → 우리 retriever와 가장 맞는 fit한 데이터셋이라고 판단
- 시간적, 자원적으로 많은 데이터로 학습하는 것이 어려웠음 (GPU 사용시간 등)
- 조금 더 STEM이나 과학관련 데이터셋을 모았다면 좋지 않았을까 아쉬움
- (다른 공개된 데이터셋을 몇 개 넣어서 같이 학습했을 때는 오히려 성능이 저하되는 것을 확인할 수 있었다. 증강된 데이터셋의 퀄리티가 좋지 않아서, 오히려 다른 qa모델로 학습된 것을 가져와서, 그 체크포인트에다가 추가로 학습하는 것이 낫다고 판단하였다.)
-
학습 에포크 (최대 5에퐄)
- 5 에퐄 안쪽에서 best 성능이 나오는 것으로 확인하여 5에퐄만 돌림
- 특히 학습 데이터셋이 많지 않기 때문에 더 많은 에퐄은 필요가 없다고 생각하였다.
-
학습 코드는 팀 깃헙에 공유한 multiplechoice model training 코드를 사용
-
huggingface trainer 모듈은 acclerate를 지원해서 여러개의 GPU를 가지고 분산 학습하는 것이 가능!
-
모델 학습 결과 저장 파일
-
각 에포크마다 저장하게 하였는데, 대회 제출해보면 실제 test set에는 어떤 것이 가장 좋게 나올지 알 수 없기 때문! (다 제출해보겠다는 의지로 저장..ㅋㅋㅋㅋㅋㅋ)
-
실제로 qna 모델을 만든다고 한다면 best ckpt만 저장하는 것이 효율적일 것이라고 생각함
2. sentencetransformer + encoder reader 파이프라인 완성
- 팀 깃헙에 공유한 STEM-focused-wiki 데이터셋에서 retrieve 하는 코드 를 바탕으로, dev set 200개에 대하여 context를 뽑아서 넣어주고 그것을 test 하게끔 하여 파이프라인으로 구성 (wiki Retreival-augmented Reader)
- loss 확인을 위한 wandb 사용 → 강력한 프레임 워크 강추합니당!!
- wandb는 간단한 코드만으로 모델의 학습 상태, 성능 등을 확인할 수 있게 해주는 프레임 워크
pip install wandb를 통해서 깔고, 바로 간단하게 사용할 수 있다.- 기존 코드에서 wandb로 리포팅 할 수 있게끔 작은 코드 추가! (팀 깃헙 코드에서 확인 가능!)
wandb.init(project='multiple-choice-model-training')- loss 확인을 위한 wandb 사용 → 강력한 프레임 워크 강추합니당!!
- wandb는 간단한 코드만으로 모델의 학습 상태, 성능 등을 확인할 수 있게 해주는 프레임 워크
- `pip install wandb`를 통해서 깔고, 바로 간단하게 사용할 수 있다.
- 기존 코드에서 wandb로 리포팅 할 수 있게끔 작은 코드 추가! (팀 깃헙 코드에서 확인 가능!)- deberta-base 학습 시 이렇게 로그를 뽑아준다.
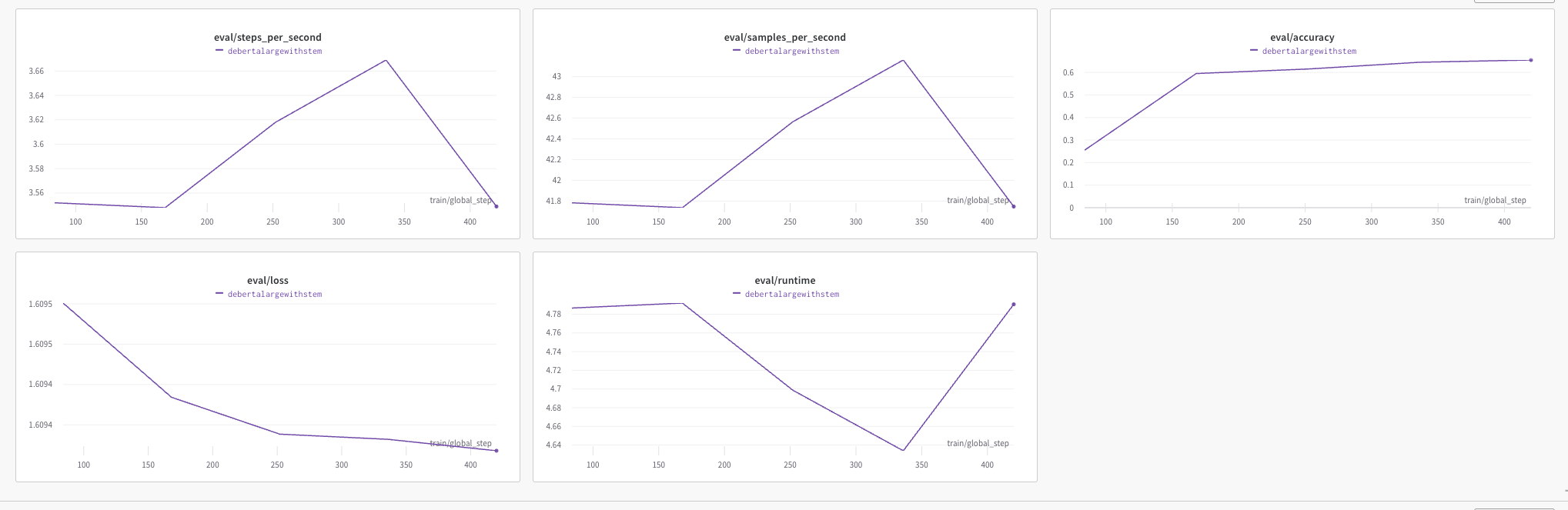
→ 1000개면 사실상 거의 few-shot fintuning 수준이라 학습을 거의 못한 건데도, retriever 없는 모델(50%대의 성능) 에 비하면 retriever로 context를 넣어준 것이 아주 큰 성능 향상을 가져온 것을 알 수 있음!
→ 다만 현재 리더보드에 기록되고 있는 성능에는 못미치다보니 아쉬운 마음 양질의 데이터 / 큰 모델이 NLP에서는 더욱 중요해지는 것 같다. (돈이 없으면 연구하기 어려워진다!!ㅠㅠ)
3. 결론
- 같은 read 모델이 있을 때, retriever를 붙이는 것이 큰 폭의 성능 향상을 가져온다는 것 확인!
- 그러나 역시, 같은 retriever가 있을 때, 좋은 read model을 갖는 것이 성능을 크게 좌우한다.
- 그리고 좋은 model이라는 것은 1) 파라미터가 크거나 (LLM) 2) (양질의) 데이터가 많아야 한다.
- 이번에는 아쉽게 학습 데이터 1000개로만 실험했지만, retriever - read model pipeline을 직접 코드를 짜고, 로컬 환경에서 구축해본 것에 의의를 둔다!
- 앞으로 이 파이프라인에 LLM을 가져와서 붙여서 로컬에서 완성해보는 것도 의의가 있겠다
- 캐글 환경,,, 너무 어렵다😂

NLP 엔지니어,,,,? 가 될 수,,,? 나도,,,,?