abstract
- IR을 single transformer에서 하는 방식을 제안한다.
- 그 말은 즉, information이 model의 파라미터에 저장된다는 것을 의미한다.
- Differentiable Search Index (DSI) : text-to-text model을 사용해서 string query를 relevant docid로 연결하는 방법론을 제안한다.
- 그 말은, DSI는 쿼리에 대한 정보에 대한 답을 오직 parameter안에서 제공한다는 것이다.
- retrieval process를 드라마틱하게 단순화했다.
- 이 방법론에 대한 스터디를 상세하게 제공한다.
- identifier를 어떻게 represented해야 하는지
- training procedure를 어떻게 다르게 해야하는지
- model과 corpus 사이즈가 변함에 따라 어떤 변화가 나타나는지
- 실험을 통해서 DSI가 dual encoder 기반의 베이스라인을 넘은 것을 보였고, zero-shot setting에서도 BM25를 넘어서는 generalization capabilities를 보여줬다.
1. Introduction
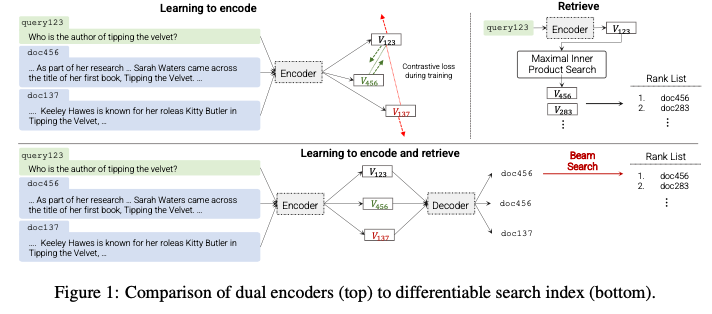
- information retrieval 의 기존 방식
- query를 document에 매핑시키는 것
- 대부분 retrieve and rerank strategy를 사용한다.
- Dual encoder (DE) 로 index로부터 nearest neighbor search를 한다.
- 제안 하는 방식 : DSI
- sequence-to-sequence learning system으로 query q를 바로 docid에 직접적으로 연결하는 것이다.
- pre-train generative transformer를 사용하여 all information이 모델의 파라미터에 저장되게 한다.
- DE보다 simple한 architecture를 가진다. DE는 search process가 필요하지만, DSI는 그냥 모델을 inference 하기만 하면 되기 떄문에)
- inference 시에,
- 학습된 모델은 text qeury q를 input으로 받고, output으로 docid j를 반환한다.
- 필요할 시 beam search를 rank system으로 이용할 수 있다. (뒤에서 나오지만, 토큰의 확률 logit 값도 rank system으로 이용할 수 있다.)
- small corpus에서 특히 더 잘 작동하고, 큰 모델일수록 성능 향상이 커지는 gain이 있다.
- 또한 zero-shot setting에서 BM25룰 뛰어넘었다.

-
DSI는 기존의 IR ML task에 well-understood 하게 맵핑될 수 있다.
-
예를 들어서 DE에서 index를 업데이트하려고 training 하는 것은, DSI에서는 model을 update하는 방식으로 볼 수 있다.
-
DSI는 from 10k부터 320k 까지의 document 에 대해서 적용되었다. (NQ dataset)
→ sacailing DSI 에 관하여는 future work로 남겨둔다.
2. Related Work
-
autoregressive entity linking 태스크
- question을 entity에 mapping하는 것 (여기서 entity는 wikipedia page title이 될 수 있다.)
- 이러한 점에서 일종의 Generative retrieval과 비슷하다고 할 수 있음
- 차이점 : autoregressive entity linking은 semantically meaningful name 을 넣어주는 반면, DSI는 arbitrary docid를 연결한다.
- 이런 점에서 docid representation과 indexing strategies에 대한 New question을 제공한다.
- autoregressive entity linking에서 constrained generation을 사용해서, output 을 fixed set에서 제공한다. → DSI에서 현재 사용하지는 않았지만 성능 향상을 위해서 충분히 사용할 수 있을 것으로 보임
-
retrieval augmented generation
- question-answering에서 유용하게 쓰이는 방식으로, retriever는 DE를 사용한다.
- 그러나 여기서는 generation을 retrieval process를 대신 하는 것으로 쓰는 것이다.
-
Dual encoders
- well-established paradigm for retrieval
- query와 document embedding을 각각 만든 다음에, vector space에서의 similarity를 구하는 방식으로 진행한다.
- 학습은 contrastive loss로 이루어진다.
-
Large Transformer model as a memory store
- closed-book QA에서도 이미 학습된 fact들을 사용할 수 있다는 것을 보여줄 수 있었음
- pretrained LM은 already contain relational knoweldge를 가지고 있다.
- 이러한 연구들을 통해서 Transformer가 직관적인 면에서 memory store나 Search index로 쓰일 수 있다는 가능성을 드러낸다.
3. Differentiable Search Index
- DSI의 core idea는 multi-stage였던 기존의 retrieve-then-rank pipeline을 single neural model로 합치는 것이다.
- 그렇기 때문에 아래의 2가지 operation을 포함해야 한다.
- 1) Indexing : document content - docid 쌍을 매칭할 수 있어야 한다. 본 논문에서는 seq2seq approach로 document content를 input, docid를 output으로 매칭한다.
- 2) Retrieval : query - candidate docids 쌍을 매칭할 수 있어야 한다. autoregressive generation을 사용한다.
→ 2가지 Operation을 학습하기 위해서 query와 labeled document를 가지고 학습을 진행한다.
→ 기존의 retrieve-then-rank approaches 들 보다, 이런 형태의 모델은 더 단순한 End-to-end training이 가능하게 하고, 또한 더 크고 복잡한 neural model의 differentiable sub-component가 될 수 있게 한다는 장점이 있다.
3.1 Indexing Strategies
- indexing 이라는 것은 document와 그들의 identifier들을 연결짓는 것이다.
Indexing Method
→ “how to index?”
- Inpusts2Target
- seq2seq task : doc_tokens → docid
- advantages : 1) identifier를 denosing 하는 task이기 때문에, prediction process와 비슷하다. 2) inference 때 보는 input-target sequence length balance를 맞출 수 있게 해준다.
- potential weakness : document tokens는 denoising이 되지 않기 때문에, document token에 대한 general한 pre-training이 일어나기 어렵다는 것
- Targets2Inputs
- seq2seq task : docid → doc_tokens
- 직관적으로 설명하자면, docid를 주고 content를 생성하게 하는 autoregressive language modeling과 동일하다.
- Bidirectional
- Inputs2Targets와 Targets2Inputs를 co-training setup으로 놓는 것이다.
- prefix toekn을 사용해서 어떤 task인지 구분해주었다.
- Span Corruption
- docid token뿐 아니라 document의 토큰들을 span masking하는 t5의 방식을 따른 것
- advantage : 1) document tokens에 대한 pretrain도 시행할 수 있고 2) docid를 input그리고 target으로 쓰는 balance를 맞출 수 있다.
Document Representation Strategies
→ “what to index?” 즉, doc_tokens을 어떻게 representation 하는 것이 좋을 것인가
- Direct Indexing
- document 그 자체를 representatoin (문장의 단어들이나 순서들이 그대로 유지가 된다.)
- Set Indexing
- stop words나 반복되는 단어들이 많을 수 있기 때문에, python의 set 연산처럼 중복이나 stopwords를 뺀 다음에 representation 하는 것
- Inverted Index
- random하게 k개의 chunk token을 뽑아낸다음에 그것을 docid에 연관시키는 것
- advantage : allow looking beyond the first k tokens
3.2 Representing Docids for Retreival
- seq2seq에서 retrieval task 라는 것은 input query가 주어졌을 때 적절한 docids 를 찾는 것이다.
- 이를 위해서는 identifier를 어떻게 디자인하는 것이 좋은지에 대한 논의가 필수적이다. → 실제로, generative retrieval 연구에서 identifier 디자인이 하나의 분야로 자리잡아 있기도 하다.
Unstructured Atomic Identifiers
- 가장 navie한 방법으로, document id를 arbitray(and possibly random)한 unique integer identifier로 배정해주는 것이다.
- decoding objective formulation은, query가 들어왔을 때, target에서 나올 각 unique docid에 대한 토큰에 대한 logit을 계산해서 가장 확률이 높은 것을 뽑아내는 것이다.
- 이는 standard language model의 output layer와 비슷하고, docid를 포함한다는 점에서 확장되었다고 볼 수 있다.
- 기존의 language model의 output layer function을 살짝 바꾸어서, 아래와 같이 쓴다.
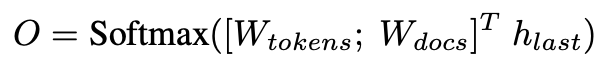
- h_last뿐만 아니라, token 임베딩과 docs 임베딩을 concat하고 h_last와 내적한 다음에 뽑아낸다는 점이 다르다.
- ouput logits을 뽑고 최댓값부터 정렬해서 뽑아낼 수 있고, 이는 기존의 rank 방식과 유사하다고 볼 수 있다.
Naively Structure String Identifiers
- docid를 토크나이징이 가능한, 즉 더 나누어질 수 있게끔 구성하는 것을 의미한다.
- 이 방식에서 retrieval은 docid string을 sequential하게 decoding해가면서 완성된다.
- advantages: 1) unstructured atomic identifiers에서 필요한 large softmax output space를 없앨 수 있다. 2) 또한 모든 individual docid에 대한 embedding을 각각 배워야 한다는 단점을 없앤다.
- beam search가 best docid를 찾는 방식으로 활용된다. → we use the partial beam search tree to construct top-k retrieval scores
Semantically Structured Identifiers
- 위에서 언급한 방법들은 모두 identifier가 arbirary하게 배정되었다.
- 의미를 살려서, 구분하여 identifier를 구성하는 방식을 사용한다.
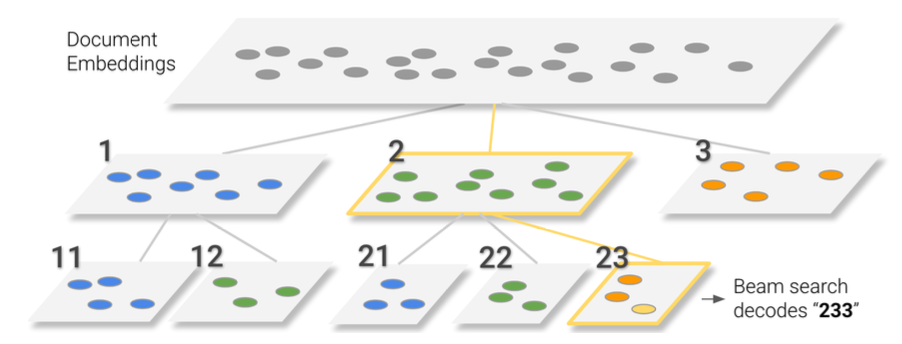
- 왜냐하면, 1) docid는 document의 sementic한 정보를 담는 것이 필요하다고 생각하고 2) 그 의미들이 structure하게 연결되어 있으면 search space를 각 decoding step마다 줄일 수 있기 때문이다.
- sturctured identifier를 만들기 위해서 unsupervised pre-precossing step을 거쳤다.
- 구조 별로 10개의 클러스터로 나누고, 모든 클러스터가 c개 이상의 document를 가지고 있으면 반복적으로 계속 진행한다.

3.3 Training and Optimization
- DSI는 seq2seq cross entropy loss, teacher forcing으로 학습되었다.
- 2가지의 학습 방법을 탐구
- 1) indexing (document_content → doc_id)부터 학습한 후 retrieval (query → docid) finetuning
- 2) multi-task setup으로 2가지 task를 함께 학습을 하는 것. T5-style co-training (using task prompts to differentiate them)
- document, 즉 검색해야 하는 DB의 개수가 많을수록 2번째 multi-task learning의 성능이 더 좋았다.
- 기존의 multi task learning과의 다른 점
- retireval task is completely dependent on the indexing task
- 서로 전이 학습 된다기 보다는, 하나의 태스크가 다른 하나에 완전히 종속된다는 것이 특징적이다.
4. Experiments
- dataset : Natural Questions
- NQ10K, NQ100K, NQ320K로 query-document pair의 개수를 다르게 주어 테스팅을 진행하였고, NQ320K가 full dataset이다.
- Metrics : Hits@N
- Implementation Details : t5 모델들로 initialization, 1M steps, batch size 128
4.1 baselines
- dual encoder (t5-encoder)
- BM25
- Sentence T5 (zero-shot retrieval)
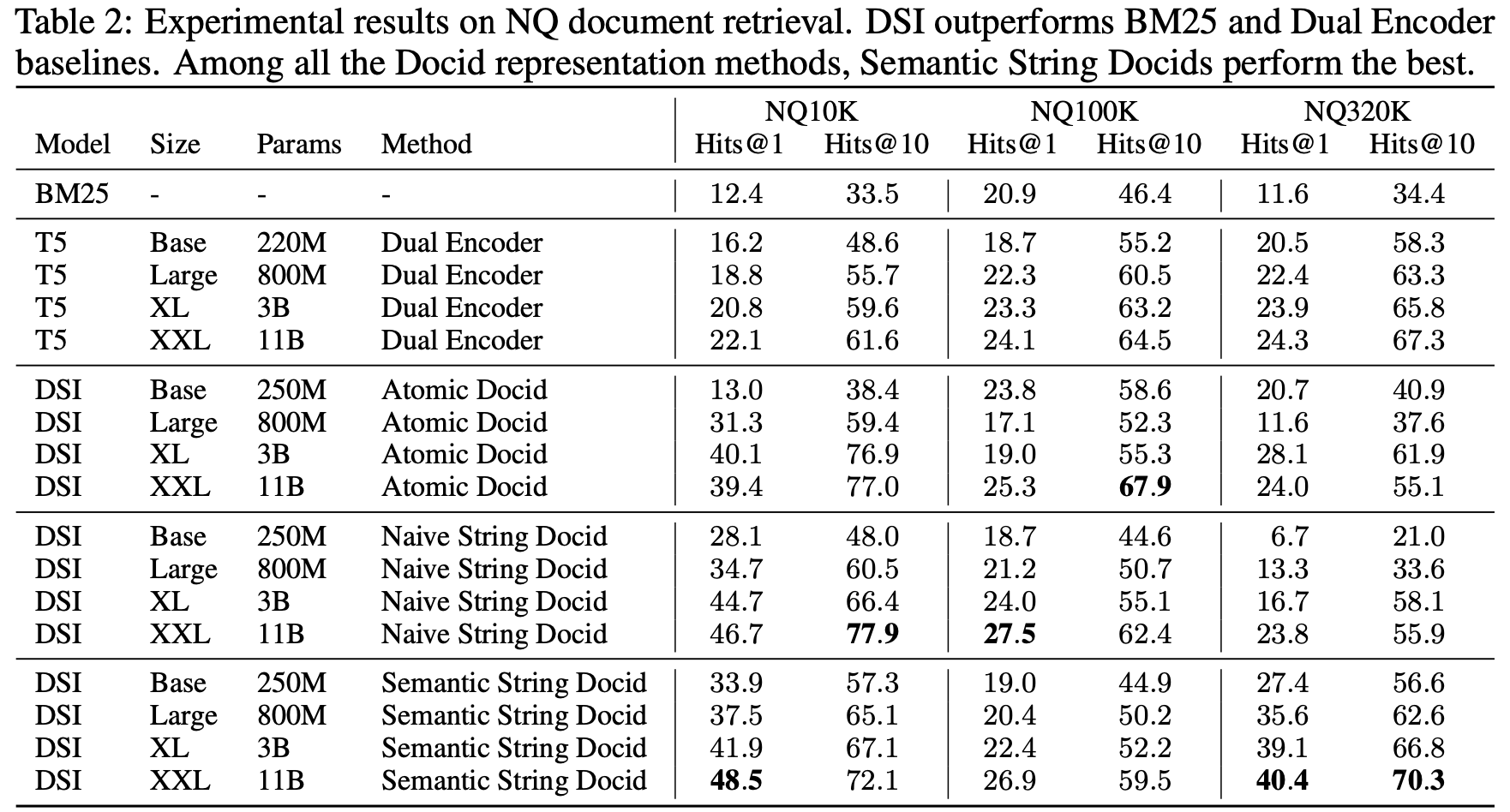
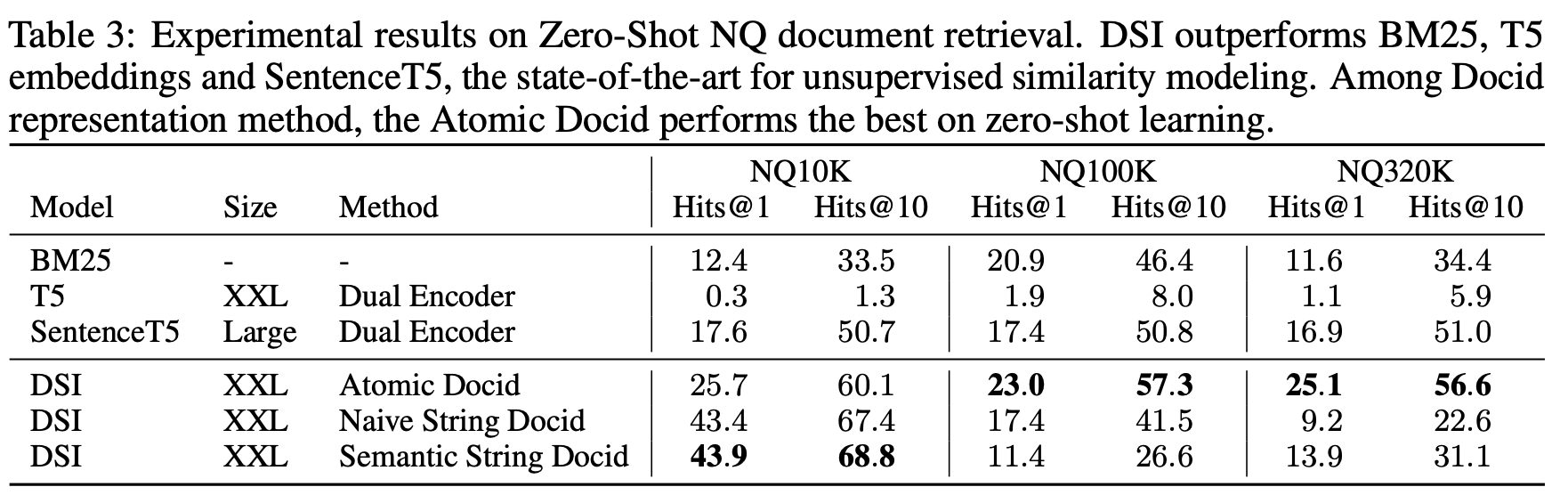
4.2 Experimental Results
-
supervised finetuning results
- DE 보다 DSI가 모두 다 성능이 좋았다.
- 모델 크기가 커질수록 성능이 좋아졌다.
- DB의 크기가 커지면 성능이 (당연히) 떨어진다.
-
zero-shot results
- zeroshot retreival 학습은 document_content → doc_id만 학습하고, query → doc_id는 학습하지 않았다. (zero shot이라서 XXL만 쓴 것으로 보인다.)
- zero-shot에서 BM25를 이기기 쉽지 않은데 높은 성능을 보였다.
- 데이터셋이 커질 때 zero-shot은 성능이 훨씬 더 급격히 떨어지는 것을 볼 수 있고, 오히려 이때는 atomic docid가 더 잘나왔는데, 이것은 아마도 sequential로 docid를 생성하다 보면 비슷하게 가다가 성능이 떨어질 가능성이 크기 때문일 것으로 보임.
-
Document Identifiers
- key RQ : “how to represent docids?”
- structured semantic identifier가 가장 좋을 것이라고 생각을 했다. searching 범위를 줄일 수 있고, 그로 인해 최적화나 representation learning이 잘 될 것이라고 생각했기 때문에
- 반대로 atomic identifier는 optimizing 하는 데에 시간이 좀 더 걸렸다. → 이 문제 해결을 위해서는 아예 softmax layer를 새로운 것을 넣거나, 혹은 scratch로 학습해서 이미 pretrain checkpoint에서 가지고 있던 bias를 mitigating 하는 것이 필요할 것이라고 생각했기 때문이다. → future work으로 identifier design 제시
-
Indexing Strategies
-
1) indexing task를 하지 않으면 성능이 0%가 나온다 (Hits@1 기준). 따라서 문서→ 문서 아이디 학습이 매우 중요하다는 것을 알 수 있다.
-
2) inputs2targets와 bidirectoinal formulation 이 성능이 좋았다.
-
3) targets2inputs와 span corrpution 은 0%의 accuracy를 보이며 의미 없다는 것을 보였다.
→ indexing strategies를 다양하게 하는 것이 이 태스크를 성공시키느냐, 아니냐의 중요한 key가 된다는 것을 보여준다.
-
-
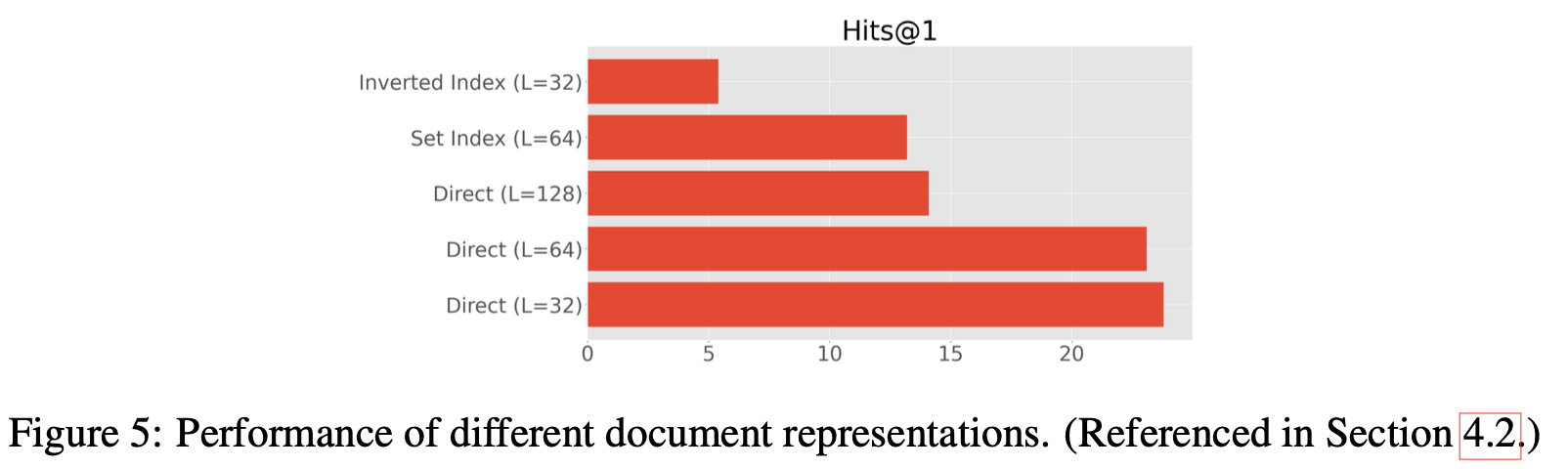
Document Representations
-
direct indexing이 성능이 가장 좋았고
-
inverted token에서는 성능이 안 좋았는데, 왜냐하면 doc_id가 different tokens에 노출되기 때문에 성능이 안 좋았다.
-
set processing에서 얻는 gain이 없다는 결과를 확인했고,
-
document의 길이를 짧게 가져가서 direct로 주는 것이 성능을 향상시킬 수 있었다. → 검색을 문단 단위로 하는 것보다, 문장 단위로 하는 것이 더 쉬울 수 있지!
-
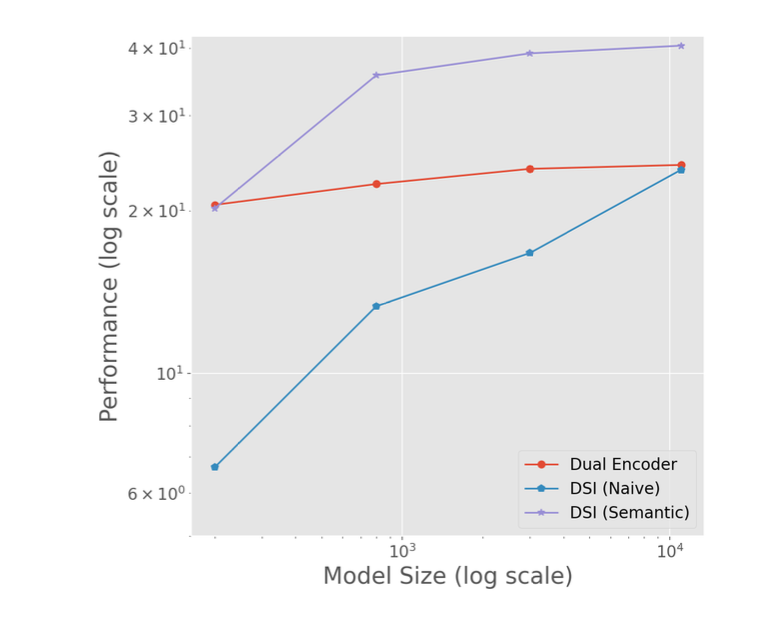
Scaling Laws
-
DSI가 DE에 비해서, 크기를 키울 때에 어떻게 다를지 확인하고자 했다.
-
우리는 그동안 트랜스포머의 크기를 키울수록 더 많은 정보를 저장할 수 있다는 것을 확인했다.
-
특히, 모델 파라미터가 커질수록 얻는 이득이 DE보다 DSI에서 컸다는 것을 확인할 수 있었다.
-
Interplay Between Indexing and Retreival
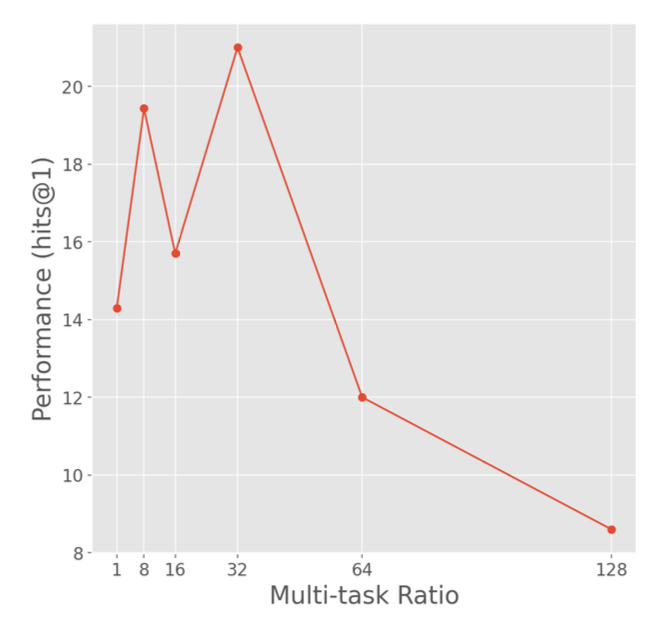
- multi-task로 DSI를 학습하는 것이 좋다는 것을 확인했으므로, multi-task ratio를 어떻게 잡는 것이 좋은지 탐구했다.
- 하나의 배치 안에서 co-training ratio를 조정하는 r 비교 실험 (128배치 안에서, r이 32라면 indexing을 32하고, retrieval을 64한다는 뜻)
- 당연히 둘중 하나에 치우치면 성능이 좋지 않았고, 32가 베스트였다.
5. Conclusion
- DSI를 제안했고, 이는 search system을 end-to-end로 결합 (인코더 학습하고, 각각 벡터에 저장한다음에, 그 벡터들의 유사도를 찾게끔 하는 걸 한큐에 해결) 하는, generation search의 스텝을 제시했다.
- future research 제안
- alternative strategies for representing documents and docids
- investigating mixture-of-expert models
- scaling the memory capacity of DSI
- how such models can be updated for dynamic corpora
- unsupervised representation learning method and/or memory store 방식
🧐 읽으면서 느낀 Generative Retrieval의 특징
- 현재까지는 제한된 크기에서만 잘하고 있음. 모델 파라미터에 더 많은 양 (320k 이상) 의 데이터를 저장할 수 있을까? ChatGPT 등을 보면 더 큰 크기의 모델을 사용하면 저장할 수는 있을 것으로 보이나, 그렇게 되면 vector index를 DE 모델에서 저장하는 것보다 오히려 더 큰 저장 공간을 활용하는 것은 아닐까?
- label된 데이터가 다수 있어야 학습이 가능할 것이다. → 그런데 이것은 dual encoder도 결국 어떤 방식으로는 label을 주게 되므로 비슷한 것 같다.
- generative retrieval에 instruction tuning을 적용할 수 있을 것인가? 여기에서 prefix로 다양하게 하는 것이 UGR일 것이고, 그 다음 단계는 아직 안 나왔는데, 나는 이것이 언어모델 흐름에서 t5 가 unified 하는 걸로 연구되고, 그 다음에 instruction tuning flan-t5 가 나온 것과 비슷하다고 생각이 든다. 그러나 insturction tuning은 기본적으로 다양한 것을 할 때 잘 통하는 것인데, 이걸로 tuning 하는게 작은 크기의 모델에서 중요하긴 한건지… 궁금하다. 7B나 11B 정도에서 실험해볼 수 있으면 좋을 것 같다.
- 원자성 label vs structured label : 원자성 label이 단순하긴 해도 오히려 잘할 수도 있을 것 같다. 왜냐하면 structure label은 한번에 맞추는게 아니라 sequential하게 생성을 다해서 맞춰야 하니까, 일종의 확률 곱셈인 셈이지. 그래서 학습이 잘 되면 structured가 더 잘 나오는 것이 맞는 것 같고, 성능이 stable하다는 설명도 이해가 간다. 다만 임의로 붙인 원자성의 label이 막 찍기? 에서는 성능이 더 잘 나올 것 같다고 생각했다.
- 그리고 이는 일종의 end-to-end로 가는 패러다임의 일종이기 때문에 당장 현업에 적용한다기보다도 research area에서 더 활발하게 연구될 것 같다. (거기서 성능이 잘 나오는 것이 확인되면, 현업에 적용이 되겠지….?)
