CNN - 합성곱 신경망(Convolutional Neural Network)
- 이미지 분류, 객체 감지, 얼굴 인식 등 다양한 컴퓨터 비전 작업에서 뛰어난 성능
- CNN의 목표는 입력 이미지의 특징을 추출하는 것
- 특징 추출 후 완전 연결 계층(Fully-Connected Layer)을 거친 결과를 분류 문제에 사용하여 예측 값을 도출
- 구성 요소
- 합성곱층(Convolutional Layer)
- 활성화 함수(Activation Function)
- 풀링층(Pooling Layer)
- 완전 연결층(Fully Connected Layer)
CNN 응용되는 다양한 컴퓨터 비전 영역
Image Classification (이미지 분류)
- 입력된 이미지가 어떤 라벨에 대응되는지 이미지에 대한 분류(Classification)
2. Object Detection(물체 검출)
- 이미지 안의 Object(물체)들의 위치를 찾고 어떤 물체인지 분류하는 작업
- Localization : 이미지 안에서 하나의 Object의 위치와 Class 분류
- Dection: 이미지 안의 여러 개의 Object의 위치와 Class 분류
3. Image Segmentation (세분화)
- 이미지를 입력 받아서 픽셀별로 분류
- Semantic segmentation(의미 기반 세분화) : 클래스 단위로 구분
- Instance segmantation(인스턴스 기반 세분화) : 각 객체 단위로 구분
4. Image Captioning
- 이미지에 대한 설명문을 자동으로 생성
5. Super Resolution
- 저해상도의 이미지를 고해상도의 이미지로 변환
6. Neural Style Transfer
- 입력 이미지와 스타일 이미지를 합쳐 합성된 새로운 이미지 생성
7. Text Dectection & OCR
- Text Dectection : 이미지 내의 텍스트 영역을 Bounding Box로 찾아 표시
- OCR : Text Detection이 처리된 Bounding Box 안의 글자들이 어떤 글자인지 찾음
8. Keypoint Detection (특징점 검출)
- 인간의 특징점(Keypoint)들을 추정
- Human Pose estimation, Face keypoint detection, Hand detection
영상처리에서 Feature Exctractor를 Dense Layer사용했을 때 문제점
- Dense layer(Fully connected layer)는 이미지의 공간적(spatial) 구조를 학습하는 것이 어려움 → 같은 형태가 전체 이미지에서 위치가 바뀌었을 때 다른 값으로 인식
- 이미지를 input으로 사용하면 weight의 양이 이 매우 큼 → 최적화 대상이 많아지기 때문에 학습이 잘 안됨
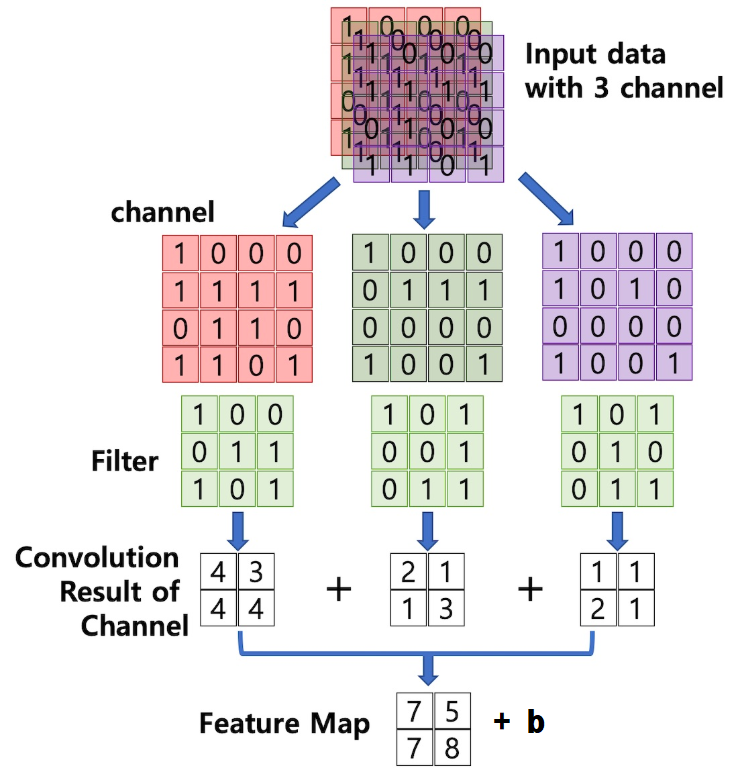
Convolution(합성곱) 연산
- 이미지와 필터간의 Convolution(합성곱) 연산을 통해 이미지의 특징 추출
- 합성곱 연산은 input data와 weight간의 가중합을 구할 때 한번에 구하지 않고 작은 크기의 Filter를 이동시키면서 가중합을 구함
- 필터와 부분 이미지의 합성곱 결과가 값이 나온다는 것은 그 부분 이미지에 필터가 표현하는 이미지특성이 존재한다는 것
- Convolution Layer도 여러층을 쌓는다
- 입력층(Bottom)과 가까운 Convolution 레이어일 수록 input image의 작은 영역에서의 특징들을 찾음 → 이미지의 엣지나 경계선등 일반화가 쉬운 이미지의 기초적인 표현을 찾음
- 출력층(Top)과 가까운 Convolution 레이어일 수록 input image의 넒은(큰) 영역에서의 특징들을 찾음 → 일반화가 곤란한 구체적인 이미지의 표현을 찾음
Convolutional Layer 생성 및 작동방식
tensorflow.keras.layers.Conv2D
- Hyper parameter
- filters : 레이어를 구성하는 filter(kernel)의 개수. Feature map output의 깊이
- kernel_size : Filter의 크기(height, width), 보통 홀수 크기(주로 3 * 3 필터)
- padding : input tensor의 외곽에 특정 값(보통 0)
- stride : 연산시 Filter의 이동 크기
- Feature Map
- Filter를 거쳐 나온 결과물
- Filter당 한 개가 생성
- 크기(shape)는 Filter의 크기(shape), Stride, Padding 설정에 따라 달라짐
- Feature 추출 연산
- Padding
- 이미지 가장자리의 픽셀은 convolution 계산에 상대적으로 적게 반영
- 이미지 가장자리를 0으로 둘러싸서 가장자리 픽셀에 대한 반영 횟수를 늘림
- Padding을 이용해 Feature map의 size를 조절
- "valid" padding
- Padding 적용하지 않음
- Output(Feature map)의 크기가 줄임
- "same" padding
- Input과 output의 이미지 크기가 동일하게 되도록 padding 수를 결정
- 보통 same 패딩 사용
- Output의 크기는 Pooling Layer 이용해 줄임
- Strides
- Filter(Kernel)가 한번 Convolution 연산을 수행한 후 옆 혹은 아래로 얼마나 이동할 것인가
- onvolution layer에서는 일반적으로 1
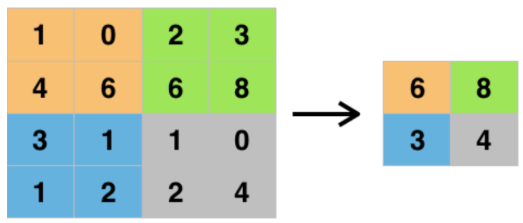
Max Pooling Layer
- 입력 데이터의 공간적인 해상도를 줄이고, 특징 맵(Feature Map)에서 가장 중요한 정보를 추출
- 특징 맵의 크기를 감소시키는 과정 → 계산 비용 줄임, 특징 맵에서 나타나는 노이즈나 불필요한 세부 정보 제거 ⇒ 네트워크의 복잡성을 줄이는 효과
- 각 특징 맵에서 정해진 크기의 윈도우(예: 2x2 또는 3x3)를 이동시키면서 윈도우 내의 가장 큰 값을 선택
- 특징 맵의 크기가 줄어들어 계산량을 감소시키고, 과적합을 방지하면서도 일반화 능력을 향상시키는 효과
- 일반적으로 2*2 크기에 stride는 2를 사용
- 강제적인 downsampling 효과
- 학습할 weight가 없음: 일반적으로 convolutional layer + pooling layer를 하나의 레이어로 취급
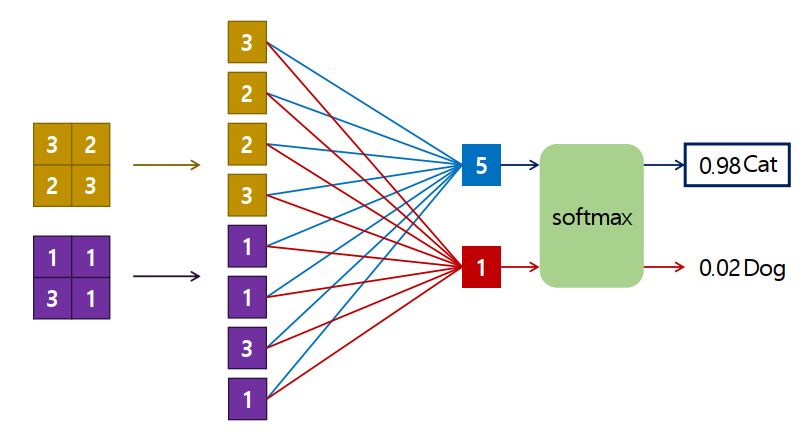
추론기
- 해결하려는 문제에 맞춰 Layer를 추가
- Feature Extraction layer을 통과해서 나온 Feature map을 입력으로 받아 추론한 최종결과를 출력