.jpg)
투빅스 14기 김민경
1.ResNet
- 모델이 깊어질수록 Gradient Vanishing 문제 또는 Gradient Exploding 문제 발생
- ResNet은 Skip connection을 이용해 매우 깊은 네트워크(152 Layer) + 성능 향상시킴
1) Residual block
-
Skip connection이 있는 블록을 Residual block이라고 함.
-
그리고 이 Residual block들을 여러층 쌓아 깊은 신경망 ResNet을 만듦.
-
원래 의 정보가 로 흐르기 위해서는 main path 과정들을 다 거쳐야 함.
-
ResNet에서는 을 복제해서 신경망의 더 먼 곳까지 단번에 가게 만든 뒤, ReLU 비선형성을 적용해주기 전에 을 더해줌.
-
이것을 short cut(=skip connection)이라고 함.
-
그러면 main path를 따르는 대신, short cut(=skip connection)을 따라서 신경망의 더 깊은 곳으로 갈 수 있다.
-
가 더해져서 마지막 식이 변경됨.
-
그리고 은 선형연산 뒤, ReLU 연산 전(비선형 적용해주기 전)에 들어감.
-
정리하자면 short cut(=skip connection)은 이 (더 깊은 곳으로) 정보를 전달하기 위해 층을 뛰어넘는 걸 의미함.
2) Plain Network vs. ResNet
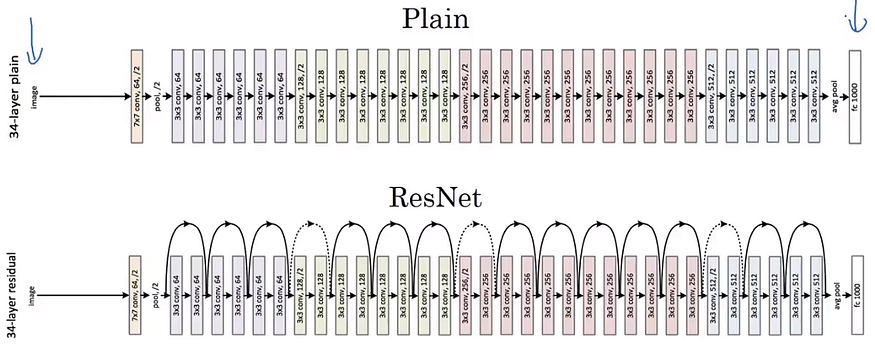
- plain network에 skip connection을 추가한 게 ResNet
- plain network의 경우, 층의 개수를 늘릴수록 training error는 감소하다가 다시 증가함.
- 원래 이론상으로는 신경망이 깊어질수록 training error가 점점 낮아져야 하지만
- 실제로는 training error가 감소하다가 성능이 포화상태에 이르면 급격히 증가함.
-> Vanishing/Exploding 문제로 초반 계층부터 학습이 잘 안 됨. (degradation problem)
- 하지만 ResNet은 Residual block을 활용해 층의 깊이가 깊어져도(100층 이상이더라도) training error가 계속 감소하는 성능을 가질 수 있음.
3) Skip connection
- 입력 X를 거대한 신경망에 넣고 활성값 출력.
- 그리고 2개의 layer 더한 뒤 short cut을 추가해 residual block으로 만듦.
- 신경망 전반에 걸쳐서 ReLU 활성화 함수를 사용하기 때문에 입력값인 X를 제외하고는 모든 활성값이 0보다 크거나 같음.
- 은 추가한 skip connection.
- 그리고 overfitting을 방지하기 위해 weight decay 또는 L2 regularization를 사용하면 이 되고, (도 될 수 있음.)
- 그럼 초록색 부분은 이 되어 사라지게 되어 이 됨.
- 그리고 ReLU에 의해 모든 활성화 함수값이 양수기 때문에 임.
- 그래서 가 됨.
-> identity function(identity mapping)을 의미 - 신경망에 위의 2개의 layer를 추가해도 그 2개의 layer가 없는 더 간단한 네트워크만큼의 성능을 갖는 이유가 identity function를 학습하여 에 를 대입하면 되기 때문
- identity function을 학습하는 것은 쉽기 때문에 신경망의 성능이 저하되지 않는다는 것을 보장할 수 있고, 성능 증가도 가능함.
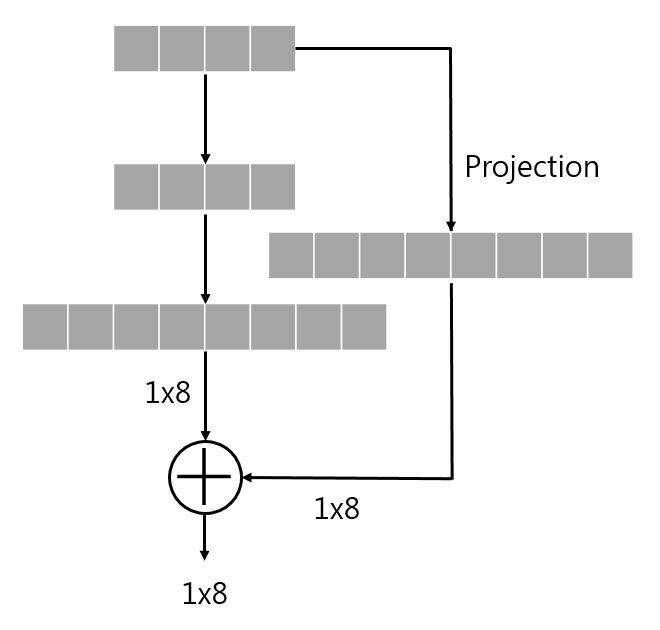
- 그리고 dimension matching의 용도로 행렬 추가해줌.
- 는 (1)학습된 변수를 가진 행렬일 수도 있고, (2)제로 패딩으로 고정값을 가진 행렬일 수도 있음.
 (출처 : Aroddary's Personal Lab)
(출처 : Aroddary's Personal Lab)
4) 전체적인 구조
- 아주 많은 3x3 conv layer가 있는데, 그 중 대부분이 same 패딩임.
그래서 같은 차원의 벡터를 더해주는 것 - 가끔 strides=2인 conv layer를 통한 downsampling을 거쳐서 차원이 달라질 경우, 이용해서 차원 조정
2.Network In Network(NIN)
1) 1x1 convolution = NIN
- CNN을 구축할 때 1x1 conv를 사용하는 것은 매우 유용함.
(1) 채널의 수 조정
- 1x1x192 필터를 32개 사용해서 채널 수 조정
(2) 비선형성 추가
- 1x1x192 필터 192개 사용해서 채널의 수 유지
- 1x1 conv는 비선형성을 추가함으로써 더 복잡한 함수를 학습할 수 있게 함.
2) Inception Network IDEA
- CNN을 디자인할 때 1x1, 3x3, 5x5 필터 중 무엇을 사용할지 또는 pooling을 사용할지 결정해야 함.
- Inception Network는 필터의 크기를 정하지 않고 conv layer 또는 pooling layer 모두 사용
-> 네트워크가 스스로 원하는 파라미터나 필터 크기의 조합을 학습하게 됨. - 네트워크가 복잡해지기는 하지만 성능은 뛰어남.
- 1x1, 3x3, 5x5 conv는 크기를 맞추기 위해 same 패딩 사용
- max pooling에서도 크기를 맞추기 위해 same 패딩 사용 (보기 드문 형태)
- 이후 모두 concatenation해줘서
-> output : 32 + 32 + 128 + 64 = 256
3) Inception Network의 계산 비용 문제
- 5x5 conv의 계산 비용을 알아보자.
- 5x5x192 필터 (same 패딩) 32개이므로 (28x28x32)x(5x5x192) = 1억 2천만 정도
- 1x1 conv 사용해서 1/10정도로 계산 비용을 줄일 수 있음.
- 1x1 conv 사용함으로써 192개 채널 -> 16개 채널
- 이 결과에 5x5 conv해주면 최종 output
- 즉, 크기를 키우기 전에 병목층 (bottleneck layer)을 이용해 이미지를 줄임.
- 계산 비용
-> (28x28x16)x(1x1x192) + (28x28x32)x(5x5x16) = 1200 만 정도 (약 1/10 감소)
- 병목층을 적절하게 구현할 수 있다면 표현 크기를 줄이는 것은 성능에 큰 지장을 주지 않음.
3.Inception Network
1) Inception Module
- pooling layer에서 크기를 맞추기 위해 same 패딩을 적용했는데, output이 28x28x192의 크기를 가짐.
-> 채널이 너무 많음
-> 1x1 conv layer 추가해서 채널 수 줄여 28x28x32로 만듦. - Inception Network는 이런 module들을 하나로 모아놓은 것.
- 많은 블록들이 반복되고, 보기에 복잡해 보이지만 하나의 블록을 살펴보면 Inception module
- 차원을 바꾸기 위한 max pooling layer 추가
- 독특한 점으로 Auxiliary classifier가 있음.
- 맨 마지막 softmax층 하나 + 중간중간 softmax => Inception Network에 정규화 효과 & overfitting 방지
- Inception Network는 Google의 일원에 의해 개발되어 GoogLeNet이라고 불림.
4.Data Augmentation
- 성능을 향상시키는 기술
- 컴퓨터 비전은 이미지와 픽셀들을 입력 받아서 이미지에 있는 것을 식별해야 하는데 꽤 복잡한 함수를 학습해야 함.
1) Common Augmentation 방법
(1) 수직 축 대칭 (Mirroring)
- 가장 간단한 방법
- 이미지를 뒤집어 오른쪽 이미지로 만드는 것. (단, 인식하려는 것을 보존해야 함)
(2) Random Cropping
- random으로 여러 부분을 잘라 서로 다른 sample 생성
-
완벽한 방법은 아니지만 실제로는 잘 작동함.
-
(1), (2) 이외에 Rotation, Shearing, Local warping 등이 있지만 복잡해서 실제로 많이 사용되지 않음.
2) Color Shifting (색변환)
- 두 번째로 많이 사용되는 기법
- R, G, B 채널 각각에 서로 다른 수를 더해주는 방식
- 이러한 색변환을 통해 학습 알고리즘이 색의 변화에 더 잘 반응할 수 있게 해줌.
3) Implementing distortions during training
- 데이터의 전처리는 CPU에서 이루어지며 모델은 GPU / TPU / CPU에서 학습함.
- CPU 스레드는 계속해서 데이터를 불러오는 동시에 변형이 필요할 때 구현해 줌으로써 mini-batch를 형성
5. Reference

3개의 댓글

투빅스 14기 장혜림
Coursera Convolutional Neural Networks 14~22강 리뷰로 ResNet, Inception, Data Augmentation에 관하여 김민경님께서 강의를 진행해주셨습니다.
- ResNet: Skip connection을 이용한 Residual block을 통해 매우 깊은 신경망을 학습시킬 수 있다. 일반적으로 레이어의 수가 많아지면 학습이 되지 않는 optimization problem이 발생하지만 ResNet은 identity function을 학습함으로써 성능이 저하되지 않고 오히려 성능이 증가할 수 있다.
- Inception: Inception module을 통해 1x1, 3x3, 5x5, max-pool을 병렬적으로 사용하고, 네트워크가 스스로 조합을 학습하게 된다. 또한 1x1 conv를 병목층으로 이용해 채널 수를 조정하고 비선형성이 추가됨으로써 더 복잡한 함수를 학습할 수 있다.
- Data Augmentation: Mirroring, Random cropping, Color shifting 등을 통해 모델의 성능을 향상시킬 수 있다.
주요 모델의 구조에 대해서 다시 한번 공부할 수 있는 시간이었습니다! 유익한 강의 감사합니다!
투빅스 14기 김상현
이번 강의는 coursera convolutional neural networks 14~22강 review로 김민경님께서 진행해주셨습니다.
ResNet
NIN & Inception Network
Data Augmentation
Coursera 강의에 나오는 부분들을 자세히 설명해주셔서 다시 공부할 수 있어 유익했습니다.
좋은 강의 감사합니다!