[Object Detection] You Only Look Once: Unified, Real-Time Object Detection : YOLO v1 논문 리뷰
Tobigs1415 Image Semina
.jpg)
투빅스 14기 서아라
1. Introduction
-
기존의 detection 모델 : classifier을 재정의하여 detector로 사용
- Classification: 이미지를 보고 이미지가 어떤 것인지 판단하는 문제 (Only 분류)
- Objectdection : 이미지 내에서 특정 물체가 어디에 있는 지 판단하는 문제 (분류 + 객체의 위치정보)
-
Ex) R-CNN
- bounding box 생성 후 classifacation 적용 후 bounding box를 조정하고, 중복된 객체를 검출. 또, 객체에 따라 box의 점수를 재산정 해주기 위하여 post-processing을 함
- 위와 같이 복잡한 과정을 거쳐야 하므로 느리다는 단점이 있고, 따라서 optimize도 어려움.
-
Single regression problem
- 이미지의 픽셀로부터 bounding box의 위치(coordinates), class probabilities를 구하기 까지의 일련의 과정을 하나의 회귀 문제로 재정의
- 이미지 내에 어떤 물체가 있고, 그 물체가 어디에 있는 지 하나의 파이프 라인으로 빠르게 구해줌
-
빠른 속도를 가진다는 장점이 있음
- 기존의 복잡한 object detection proble을 Single regression proble으로 바꾸었기 때문에 빠르게 object detection이 가능
Titan X GPU에서 batch processin없이 1초에 45 frame을 처리
Fast YOLO는 1초에 150 frame을 처리
- 기존의 복잡한 object detection proble을 Single regression proble으로 바꾸었기 때문에 빠르게 object detection이 가능

-
예측을 할 때 이미지 전체를 봄
- Sliding Window나 region proposal 방식과 달리 이미지 전체를 봄
- Fast R-CNN 같은 경우 주변 정보까지 처리를 하지 못하기 때문에 background error가 생김.
- YOLO는 이미지 전체를 처리하기 때문에 background error가 Fast R-CNN에 비해 약 ½ 정도로 적음
-
물체의 일반적인 부분을 학습함
- 따라서 DPM이나 R-CNN과 같은 모델에 비하여 새로운 이미지에 대하여 더 accuract가 높음
-
하지만 SOTA object detection model에 비해 다소 accuracy가 떨어짐
- 속도와 정확성은 trade-off 관계에 있기 때문
2. Unified Detection
-
Object detection의 개별 요소를 single neural network로 통합하고, bounding box를 예측하기 위해 이미지 전체의 특징을 활용
-
높은 정확성 유지 및 end-to-end 학습과 실시간 객체 검출이 가능
-
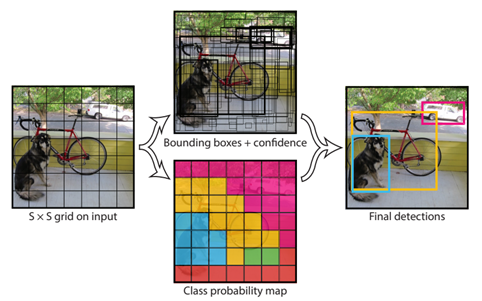
Input image를 S X S grid로 나눔
- 여기서, 어떤 objec의 중심이 특정 grid cell에 있다면 해당 grid cell이 해당 object를 검출해야함

-
각각의 grid cell은 B개의 bounding box와 그 해당 bounding box에 대한 confidence score을 예측
- Confidence score : bounding box가 object를 포함한다는 것이 얼마나 믿을만한지, 예측한 bounding box가 얼마나 정확한지를 나타내는 score
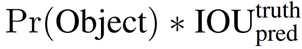
- 각각의 bounding box는 5개의 예측치로 구성 (x, y, w, h, confidence)
- (x,y) : bounding box의 중심을 표시하며 grid cell 내의 상대 위치
- (w,h) : bounding box의 상대 너비와 상대 높이
- Confidence : 앞에서 언급한 Confidence score
-
각각의 grid cell은 Conditional class probabilities(C)를 예측
- Conditional class probabilities : grid cell 안에 객체가 있다는 조건 하에 그 객체가 어떤 class인지에 대한 조건부 확률
- Grid cell에 몇 개의 bounding box가 있는지와는 무관하게 오직 하나의 class만 예측
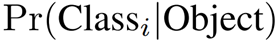
-
Class-specific confidence score : Test 단계에서 Conditional class probabilities(C)와 개별 bounding box의 confidence score을 곱한 값
- Bounding box에 특정 class의 object가 나타날 확률과 예측된 bounding box가 그 class objec에 얼마나 잘 맞는지를 나타냄
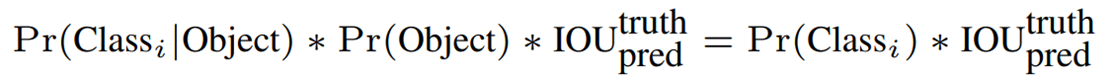
- Bounding box에 특정 class의 object가 나타날 확률과 예측된 bounding box가 그 class objec에 얼마나 잘 맞는지를 나타냄
-
YOLO 연구진은 PASCAL VOC dataset을 이용하여 실험을 진행
- S=7, B=2로 세팅, PASCAL VOC는 총 class가 20개인 dataset이므로 C=20
- S=7이므로 input image는 7 X 7 grid로 나뉨
- B=2 라는 것은 하나의 grid cell에서 2개의 bounding box를 예측하겠다는 의미
- 결과적으로 S X S X (B*5 + C) 텐서를 생성하므로, 최종 예측 텐서의 dimensio은 (7 X 7 X 30)
2. 1. Network Design
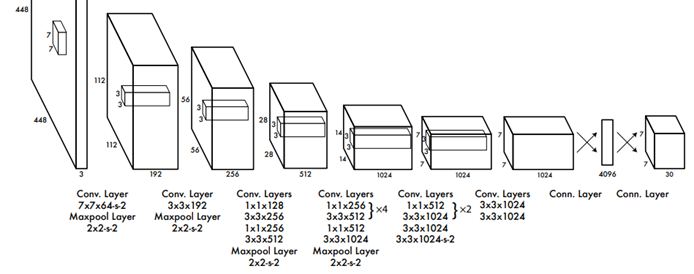
- 하나의 CNN 구조로 되어있음
- Convolutional layer : 이미지로부터 feature을 추출
- Fully connected later : class probabilities와 bounding box의 좌표를 예측
- GoogLeNet에서 구조를 따옴
- Inception 구조 대신에 1 X 1 reduction layer과 3 X 3 convolution layer의 결합을 이용
- 모델의 최종 아웃풋은 7 X 7 X 30 의 prediction tensors
2.1. Training
-
ImageNet dataset으로 convolution layer을 pretrain
- 24개의 convolution layer중 20개의 convolution layer만 사용, 뒤에는 fully connected layer을 연결 (accuracy : 88%)
- ImageNet은 classification을 위한 dataset이므로 object detection 모델로 바꾸기 위해 20개의 conv layer 뒤에 4개의 conv layer 및 2개의 fc layer을 추가하여 성능을 향상 및 weight 임의 초기화
- 입력 이미지의 해상도를 224 X 224 에서 448 X 448 로 증가시킴
-
최종 output : class probabilities 및 bounding box 위치 정보
- Bounding box 위치 정보 : bounding box의 width & height, 중심좌표 (x,y)
- (w,h,x,y)를 모두 0~1 사이의 값으로 normalize 하였음
-
Final layer에는 linear activation function을 적용, 나머지 layer에는 leaky ReLU 적용
-
Loss는 SSE(sum-squered error)를 기반
- SSE가 optimize하기 쉽기 때문에 이용
-
YOLO의 loss에는 localization loss와 classification loss로 구성
-
이미지 내 대부분의 grid cell에는 object가 없음
- Grid cell에 object가 없다면 Confidence score=0
- 따라서 대부분의 grid cell의 confidence score=0이 되도록 학습하게 되고, 이는 모델의 불균형 초래
- 이를 해결하기 위해 object가 존재하는 bounding box에 대한 loss의 가중치는 증가시키고, objec가 존재하지 않는 bounding box에 대한 confidence loss의 가중치는 감소시킴
-
SSE에서 큰 bounding box와 작은 bounding box에 대해 모두 동일한 가중치로 계산
- 하지만 작은 bounding box가 큰 bounding box보다 작은 위치 변화에 민감
- 이를 개선하기 위해 bounding box의 width와 height에 square root를 취해줌
-
YOLO는 하나의 grid cell당 여러 개의 bounding box를 예측
- Object 하나 당 하나의 bounding box와 매칭을 시켜줘야함
- 따라서 예측된 여러 bounding box 중 실제 object를 감싸는 ground-truth bounding box와의 IOU가 가장 큰 것을 선택함

-
PASCAL VOC 2007, 2012 train & validation data set을 활용
-
135 epoch
-
Batch size=64
-
Momentum0.9
-
Decay=0.0005
-
첫 epoch에는 learning rate를 0.001에서 0.01로 천천히 상승시킴
- 초반부터 큰 learning rate를 사용하면 Gradient explosion이 발생하기 때문
- ~75 epoch : learning rage = 0.01
- ~105 epoch : learning rage = 0.001
- ~135 epoch : learning rage = 0.0001
-
Overfitting을 막기 위해 dropout과 data augmentation을 이용
- Dropout 비율 : 0.5
- Data augmentation : 원본 이미지의 20% 까지 random scaling 및 random translation이용
2.3. Inference
-
PASCAL VOC data set에 대해서 한 이미지당 98개의 bounding box를 예측해주고, bounding box마다 class probabilities를 구해줌
-
Grid design의 단점
- 하나의 객체를 여러 grid cell이 예측하는 경우가 있으며, 이를 다중 검출(multiple detections) 문제라고 함
- 비 최대 억제(non-matimal suppression)이라는 방법을 통해 개선할 수 있고, 이를 통해 mAP를 2~3%가량 증가시킴
2.4. Limitations of YOLO
-
하나의 grid cell마다 두 개의 bounding box를 예측하고, 하나의 grid cell마다 오직 하나의 object만 검출할 수 있음
- 이는 공간적 제약(spatial constraints)을 일으킴
- 공간적 제약(spatial constraints) : 하나의 그리드 셀에 두 개 이상의 객체가 붙어있다면 이를 잘 검출하지 못하는 문제
-
YOLO 모델은 데이터로부터 bounding box를 예측하는 것을 학습함
- 따라서 새로운 종횡비(aspect ratio)를 마주하면 이를 잘 처리하지 못할 수도 있음
-
큰 bounding box와 작은 bounding box에 대해 동일한 가중치를 둠
- 부정확한 localization 문제를 일으킴
3. Experiments
-
Comparison to Other Real-Time Systems
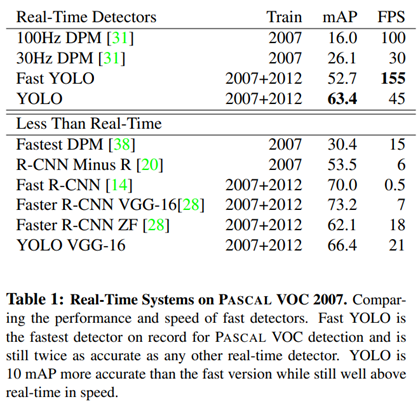
-
VOC 2007 Error Analysis
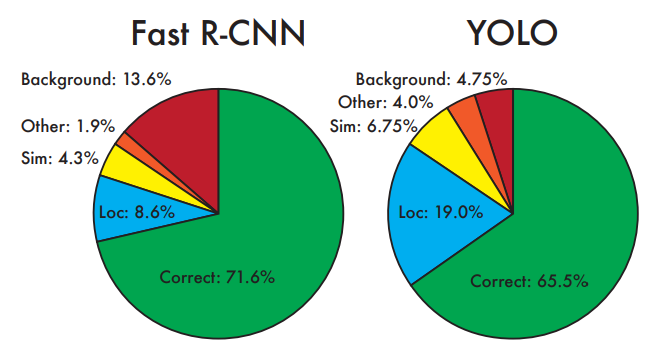

- Combining Fast R-CNN and YOLO
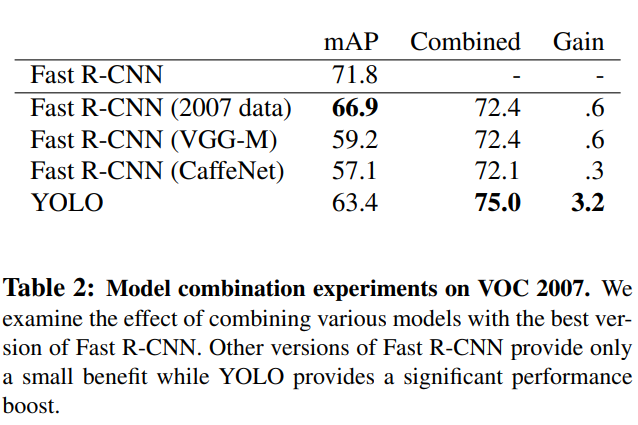
-
VOC 2012 Results
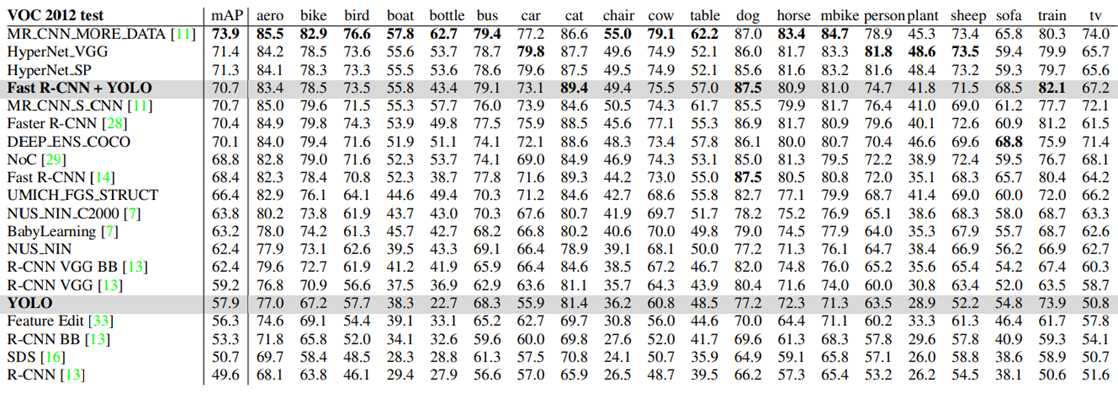
-
Generalizability: Person Detection in Artwork

4. Real-Time Detection In the Wild

5. Conclusion
- YOLO는 단순하면서도 빠르고 정확한 object detection model
- YOLO는 training에서 보지 못한 새로운 이미지에 대해서도 object detection을 잘 함
- 새로운 이미지에 대해서도 성능이 좋기 때문에 application에서도 활용할 만한 가치가 있음
6. Reference
https://arxiv.org/pdf/1506.02640.pdf
https://norman3.github.io/papers/docs/google_inception.html
https://deep-learning-study.tistory.com/430
https://bkshin.tistory.com/entry/%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0-YOLOYou-Only-Look-Once

3개의 댓글

투빅스 14기 장혜림
YOLOv1
- end-to-end 모델로서 하나의 파이프라인으로 이미지 내 물체 분류 및 위치 출력이 가능하다. 기존 detection 모델인 R-CNN과 달리 속도가 빠르다는 장점이 있다.
- 이미지 전체를 처리하기 때문에 반점이나 noise를 object로 인식하는 background error가 다른 R-CNN 계열의 모델들과 달리 적으며 새로운 이미지에 대한 정확도가 높다.
- input image를 SxS size의 grid로 구분한 후 각 grid cell마다 B개의 bounding box와 물체가 있을 확률, 해당 객체가 어떤 class인지에 대한 확률을 예측한다.
- loss는 localization loss와 classification loss로 구성되어 있으며 object의 유무에 따라 loss의 가중치를 다르게 준다.
- 하나의 객체를 여러 grid cell에서 예측하는 다중 검출을 막기 위해 비 최대 억제를 적용한다.
- 다만 한계점은 하나의 grid cell은 오직 하나의 object만 검출할 수 있기 때문에 한 grid cell에 두 개 이상의 object 중심점이 존재한다고 하더라도 이를 잘 검출하지 못한다.
YOLO 알고리즘에 대해서 자세하게 알 수 있었던 시간이었습니다! 좋은 강의 감사합니다:)
투빅스 14기 김민경
- YOLO는 기존의 detection 문제를 single regression 문제로 재정의하고 하나의 네트워크를 통해 bbox의 좌표와 객체 class 확률을 예측한다.
- YOLO의 아키텍처의 순서는 다음과 같다.
- 이미지를 개의 그리드로 분할 (여기서 어떤 객체의 중심이 특정 그리드 셀에 있다면 해당 그리드 셀이 그 객체를 detection 해야 한다.)
- 각 그리드 셀별로 개의 bbox의 좌표와 그에 대한 confidence score를 예측한다. & 각 그리드 셀별로 조건부 class 확률()을 예측한다.
- YOLO는 regression 문제에 주로 사용되는 SSE(Sum of Squared Error)를 사용하며, Loss는 Localization loss, Confidence loss, Classification loss의 합으로 구성되어 있다.
- Loss Function을 이용해 학습 후, 예측 시 "비 최대 억제"라는 방법을 통해 multiple detections 문제를 개선할 수 있다.
- YOLO는 당시 SOTA 모델들의 정확도보다는 상대적으로 낮은 결과를 보였지만 매우 빠른 속도를 보여준다. 그리고 전체 이미지를 보기 때문에 새로운 이미지에 대해서도 성능이 좋다.
object detection의 대표적인 모델인 YOLO의 version 1을 리뷰해 주셔서 YOLO의 기본적인 아이디어를 알 수 있었습니다. 감사합니다:)
투빅스 14기 김상현
이번 강의는 YOLO v1 논문 리뷰로 서아라님께서 진행해주셨습니다.
YOLO v1에 대해 자세하게 설명해주셨습니다. YOLO에서 사용되는 confidence score에 대해 잘 이해할 수 있었습니다.
유익한 강의 감사합니다.