- ResNet에서 제기한 문제점은 layer가 깊은 모델은 train 성능이 낮아진다는 것임. (train데이터 조차도 이해 못함,overfitting과는 다른 문제_)
skip connection(short cut)이 그래디언트 소실(VGP)을 막는 이유
- 활성화 함수 tanh 나 sigmoid를 사용하면 VGP가 더 심해짐
- 내 수준에서 수식으로 설명하기 어렵지만 보통 그래디언트 소실이 생기는 이유는 chain rule 때문이다.
- 0.5 x 0.5 = 0.25 -> 0.5 x 0.25 = 0.125 와같이 layer가 깊어질수록 gradient가 작아짐
- gradient가 작아지면 발생할 수 있는 문제점. weight가 10인데 0.0125가 들어오면 변화가 없는거나 마찬가지
- 따라서 f(x)+x와 같이 skip connection을 이용하면 1 + 잔차이므로 정보가 1 이하가 되지 않음 -> chain rule에 따라 layer가 깊어져도 그래디언트 소실이 안됨.
- 즉 1.xxx * 1.xxx = 1.xxx 와 같이 1이상이 됨.(개념적으로 정보가 1이상이라 했지만 gradient가 1이상이 되는 것임)
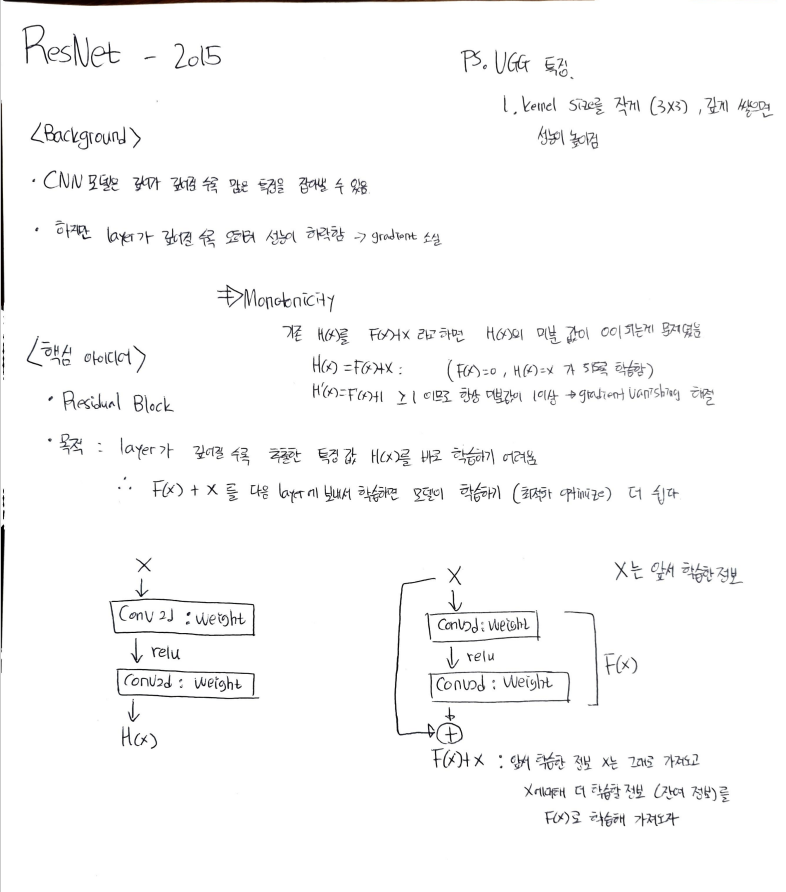
- 기존 Plain 방법은 Representation을 학습하도록 H(x)를 바로 학습했다.
- Residual Learning은 F(x) + x = H(x)의 F(x)만 학습하도록 부담을 덜어줌 => 학습이 잘 되더라!
- x는 이전 레이어의 Feature
- F(x)는 레이어가 깊어질 수록 0을 학습할 것 임.
- 즉, 이전 정보에서 파악하지 못한 잔차(residual)을 학습하는 것이 F(x) , Residual Learning
나중에 할 일 : 수식으로 증명하기

(1+gradient)이기 때문에 그래디언트 소실은 그래디언트가 0에 가까워지고 깊어지면 생기는데 1에 가까우므로 소실 해결
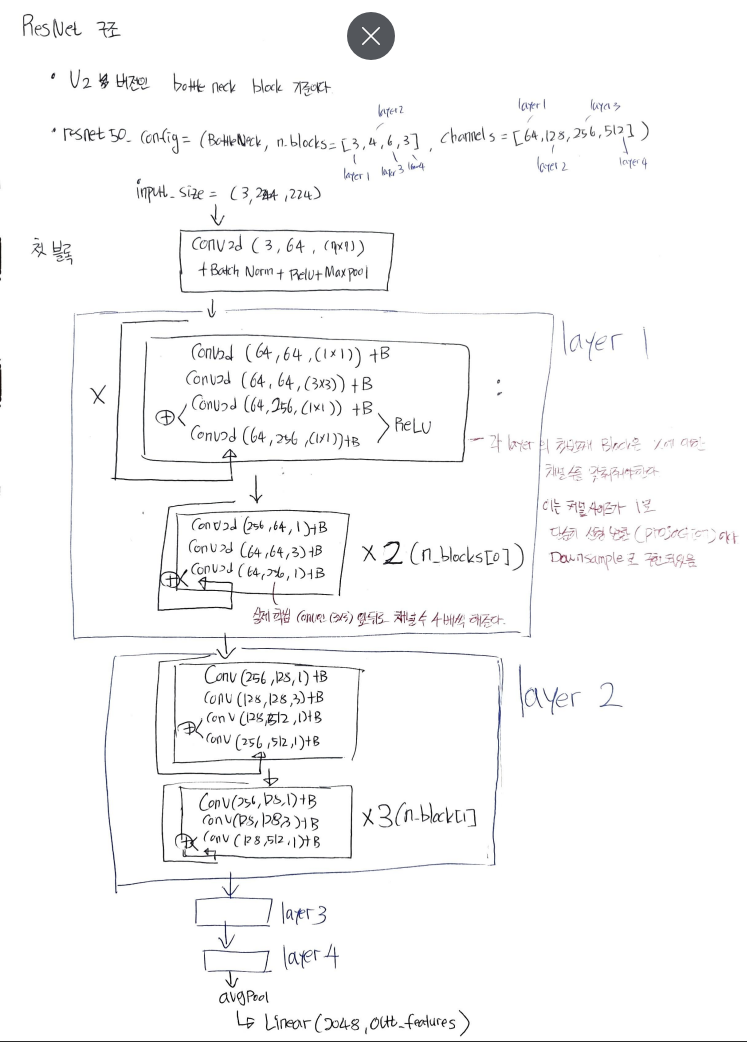
- 1x1 convolution (input channel = output channerl) 효과
- 비선형성 증가 , 채널간의 상호작용

Trendy AI Developer