코드 분석
gradio를 기반으로 작성된 코드임
from share import *
import configimport cv2
import einops
import gradio as gr
import numpy as np
import torch
import randomfrom pytorch_lightning import seed_everything
from annotator.util import resize_image, HWC3
from annotator.canny import CannyDetector
from cldm.model import create_model, load_state_dict
from cldm.ddim_hacked import DDIMSampler
cv2.canny
apply_canny = CannyDetector()
CannyDetector는 cv2.Canny(img, low_threshold, high_threshold)와 완전 동일
역할 : 히스테리시스 임계값(Hysteresis Thresholding)에 의해 Edge를 구분
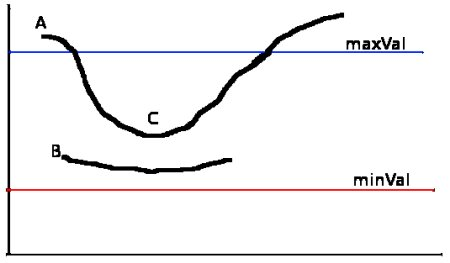
maxVal : high_threshold / minVal : low_threshold
Edge A : maxVal보다 높으므로 "sure edge"
Edge B : (minVal<Edge B<maxVal) and sure-edge에 연결되어 있지 않으므로 무시
Edge C : (minVal<Edge B<maxVal) and sure-edge에 연결되어 있으므로 valid-edge
즉, high_threshold로 엣지를 찾고 확실한 엣지와 연결된 low_threshold이상의 엣지를 검출한다.
cv2.Canny 파라미터 설명
모델 선언
model = create_model('./models/cldm_v15.yaml').cpu()
model.load_state_dict(load_state_dict('./models/control_sd15_canny.pth', location='cuda'))
model = model.cuda()
ddim_sampler = DDIMSampler(model)
create_model() : instantiate_from_config(config.model)와 동일
instantiate_from_config()는 ldm.util.py에 있는 함수로 config가 옳바른지 검사 후 조건에 만족하지 않으면 KeyError출력 , 만족하면 return getattr(importlib.import_module(module, package=None), cls)으로 module 임포트
즉, './models/cldm_v15.yaml'파일에 'target'으로 설정된 모듈을 불러옴
model.load_state_dict()
create_model()과 마찬가지로 cldm.model.py에 들어있는 함수로 확장자를 safetensors인지 아닌지 구분후 safetensors파일이면 load_file 그외는 torch.load로 가중치파일(?) 로드
DDIMSamler(model)
cldm.ddim_hacked.py에 정의되있음
Denoising Diffusion Implicit Models의 약자
기존의 DDPM(Denoising diffusion probabilistic models)방법이 마르코프 체인을 이용하여 모델을 학습하고 추론하기 위해 많은 step(거의 수천)을 거쳤음
DDIM는 마르코프 체인을 사용하지 않으며 Implicit(절대적인) Probabilistic(확률적) Model을 제안
요놈 때문에 (아마도?) 20~50 step으로 Image generation이 가능한듯
[paper]Denoising Diffusion Implicit Models
[youtube]DDIM설명
process
def process(input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, guess_mode, strength, scale, seed, eta, low_threshold, high_threshold):
with torch.no_grad():img = resize_image(HWC3(input_image), image_resolution) #image_resolution은 원하는 이미지 해상도 #원본 이미지의 높이 , 너비 중 작은 부분을 image_resolution의 값으로 변경 #+기존의 이미지 비율은 유지H, W, C = img.shape detected_map = apply_canny(img, low_threshold, high_threshold) #경계선 검출 detected_map = HWC3(detected_map) #경계션 이미지를 넘기고 & 이미지의 채널 확인후 채널을 3으로 맞춤 #채널이 3개이면 그대로 반환 , 1개면 3채널 이미지로 변환 #4개면 색상+알파로 나눈 후 가중평균으로 RGB변환control = torch.from_numpy(detected_map.copy()).float().cuda() / 255.0 #RGB이미지 텐서로 보냄 , 정규화 control = torch.stack([control for _ in range(num_samples)], dim=0) #torch.stack을 이용하여 num_samples 개수만큼 이미지를 쌓아서 하나의 텐서로 만듦 #num_samples는 하이퍼파라미터로 몇장의 이미지를 생성할거냐(????)인듯 #따라서 똑같은 이미지(control)이 num_samples개 존재함 0차원에 control = einops.rearrange(control, 'b h w c -> b c h w').clone() #einops 모듈은 einsum과 비슷한 느낌(텐서 차원 조작) #텐서의 축 순서를 변경 (이미지를 torch 모델로 다룰 때 b c h w 순서로 다룬다고 봄 feat.딥러닝 파이토치 마스터)if seed == -1: seed = random.randint(0, 65535) seed_everything(seed) #시드 고정 if config.save_memory: #config.py의 save_memory는 False로 초기화되있음 #vram이 낮은 경우 True로 변경 model.low_vram_shift(is_diffusing=False) #low_vram_shift()는 cldm.cldm.py에 존재하는 함수로 model과 control_model은 cpu로 first_stage_model과 cond_stage_model은 cuda로 돌림 #is_diffusing=True면 위와 반대로 model과 control_model은 cuda 나머지 두 모델은 cpucond = {"c_concat": [control], "c_crossattn": [model.get_learned_conditioning([prompt + ', ' + a_prompt] * num_samples)]} #get_learned_conditioning()함수는 ldm.models.diffusion.ddpm.py에 있는 함수 un_cond = {"c_concat": None if guess_mode else [control], "c_crossattn": [model.get_learned_conditioning([n_prompt] * num_samples)]} #guess_mode는 UI에서 선택 가능 shape = (4, H // 8, W // 8) #ControlNet의 입력으로 들어가는 이미지의 shape정의 #8로 나누는 이유는 이미지의 크기를 줄여 모델의 Inference와 Quality를 향상 시키기 위해if config.save_memory: model.low_vram_shift(is_diffusing=True)model.control_scales = [strength * (0.825 ** float(12 - i)) for i in range(13)] if guess_mode else ([strength] * 13) #Magic number. IDK why. Perhaps because 0.825**12<0.01 but 0.826**12>0.01 #guess_mode가 True면 scale은 약 0.1 strength ~ strength까지의 0.825배의 분포를 갖고 #False면 동일하게 strength를 갖음 samples, intermediates = ddim_sampler.sample(ddim_steps, num_samples, shape, cond, verbose=False, eta=eta, unconditional_guidance_scale=scale, unconditional_conditioning=un_cond)if config.save_memory: model.low_vram_shift(is_diffusing=False)x_samples = model.decode_first_stage(samples) x_samples = (einops.rearrange(x_samples, 'b c h w -> b h w c') * 127.5 + 127.5).cpu().numpy().clip(0, 255).astype(np.uint8) #einops.rearrange로 모델에서 처리된 차원을 우리가 쓰는 이미지 차원으로 변경 #127.5 는 픽셀값을 -1 ~ +1에서 0 ~ 255 사이로 바꿈 results = [x_samples[i] for i in range(num_samples)] return [255 - detected_map] + results
밑은 gradio이므로 일단 pass
block = gr.Blocks().queue()
with block:
with gr.Row():
gr.Markdown("## Control Stable Diffusion with Canny Edge Maps")
with gr.Row():
with gr.Column():
input_image = gr.Image(source='upload', type="numpy")
prompt = gr.Textbox(label="Prompt")
run_button = gr.Button(label="Run")
with gr.Accordion("Advanced options", open=False):
num_samples = gr.Slider(label="Images", minimum=1, maximum=12, value=1, step=1)
image_resolution = gr.Slider(label="Image Resolution", minimum=256, maximum=768, value=512, step=64)
strength = gr.Slider(label="Control Strength", minimum=0.0, maximum=2.0, value=1.0, step=0.01)
guess_mode = gr.Checkbox(label='Guess Mode', value=False)
low_threshold = gr.Slider(label="Canny low threshold", minimum=1, maximum=255, value=100, step=1)
high_threshold = gr.Slider(label="Canny high threshold", minimum=1, maximum=255, value=200, step=1)
ddim_steps = gr.Slider(label="Steps", minimum=1, maximum=100, value=20, step=1)
scale = gr.Slider(label="Guidance Scale", minimum=0.1, maximum=30.0, value=9.0, step=0.1)
seed = gr.Slider(label="Seed", minimum=-1, maximum=2147483647, step=1, randomize=True)
eta = gr.Number(label="eta (DDIM)", value=0.0)
a_prompt = gr.Textbox(label="Added Prompt", value='best quality, extremely detailed')
n_prompt = gr.Textbox(label="Negative Prompt",
value='longbody, lowres, bad anatomy, bad hands, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality')
with gr.Column():
result_gallery = gr.Gallery(label='Output', show_label=False, elem_id="gallery").style(grid=2, height='auto')
ips = [input_image, prompt, a_prompt, n_prompt, num_samples, image_resolution, ddim_steps, guess_mode, strength, scale, seed, eta, low_threshold, high_threshold]
run_button.click(fn=process, inputs=ips, outputs=[result_gallery])
block.launch(server_name='0.0.0.0')