
1. 0verview 🎯
Pullim(프로그래밍 Q&A 사이트)을 개발하며 마주했던 가장 도전적인 과제 중 하나는, 'AI 응답에 대한 대기시간을 최소화하는 것'이었습니다.
Chat GPT, Claude, Gemini와 같은 훌륭한 AI 어시스턴트 서비스가 이미 많음에도 프로그래밍 Q&A 사이트를 개발한 이유는 '사람의 답변'에 있습니다. 사람은 구체적인 상황과 제약사항을 더 잘 이해합니다. AI는 평균에 가까운 답변은 잘 생성하지만, 실제 운영 환경에서의 함정이나 edge case는 놓칠 수 있습니다. AI의 빠르고 신속한 정보 제공과 더불어 인간만이 제시할 수 있는 뾰족한 해결책을 하나의 서비스에서 구현하고 싶었습니다.
기존 구조에서는, 사용자가 '질문 등록하기' 버튼을 클릭하는 순간 AI 모델이 답변을 생성하기 시작했습니다. 버튼에서는 '질문 등록하기'라는 문구가 사라지고 로딩 스피너가 돌아가며 AI의 답변을 기다리는 형태가 되었죠.
AI가 긴 답변을 생성하는 경우, 그 모든 과정을 다 기다린 후에야 상세 페이지로 넘어갔기 때문에, 사용자가 질문 등록 페이지에서 평균적으로 2분간 기다려야 하는 문제가 발생했습니다.
버튼을 클릭하는 시점에서 전체 답변을 기다리는 것이 아니라, 상세 페이지 내부에서 스트리밍 방식을 적용하여, 답변을 chunk 단위로 지속적으로 사용자에게 제시하는 편이 낫겠다는 아이디어가 떠올랐습니다. 스트리밍 방식으로 개선한 후, 아무리 긴 답변도 10초 이내에 사용자게 제시할 수 있게 되었습니다.
2. SSE(Server-Sent Events) 🎯
SSE(Server-Sent Events)는, 서버에서 클라이언트로 실시간으로 데이터를 전송할 수 있는 웹 표준 기술입니다.
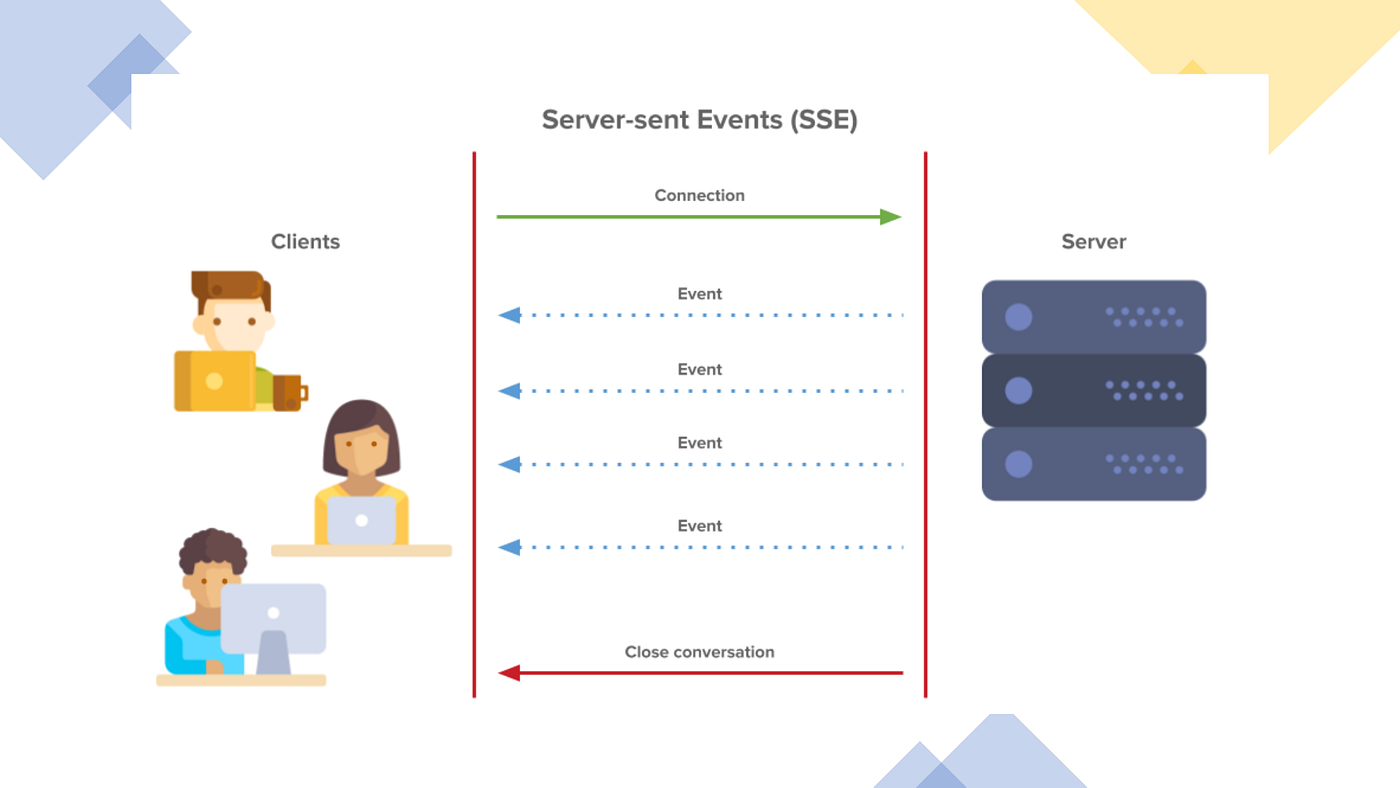
HTTP(Hypertext Transfer Protocol) 통신 방식은 요청과 응답이 1대1로 매핑됩니다. 즉 하나의 요청에 대해서 서버가 하나의 응답을 전송했다면, 그 즉시 연결이 끊기게 됩니다.
SSE(Server-Sent Events) 통신 방식은, 하나의 요청에 대해 N개의 응답이 실시간으로 이루어집니다. 서버에서 클라이언트 방향으로(단방향 통신) 지속적인 데이터 스트리밍이 가능하다는 특징이 있습니다.

엄청난 서비스를 개발해서 부자가 된 후, 안성재 셰프의 모수에서 식사를 하게 되었다고 가정해 보죠. 서빙되는 음식이 8가지 정도 되는 것으로 알고 있는데요, 8가지 음식을 한 번에 다 조리한 후 서빙하지 않죠. 도토리 국수, 장어구이 등 작은 chunk 단위로 지속적으로 제공할 것입니다. 순댓국 가게에 가면 어떤가요. "이모 순댓국 하나 주세요"라는 요청을 전달하면 '한 그릇의 순댓국'이 그 즉시 제공될 뿐입니다.
순댓국 가게의 통신 시스템이 HTTP라면, 모수의 통신 시스템은 SSE입니다. 별로 어려운 것 같지도 않는데 이렇게 장황하게 설명을 하는 데에는 이유가 있습니다.
아이디어 자체에 집중하자는 것입니다. SSE 방식은 2000년대 초반에 세상에 알려지게 되었다고 알고 있습니다. 하지만 Pullim뿐만 아니라, 다양한 AI 어시스턴트에서도 SSE의 아이디어를 차용하고 있습니다. 트렌드를 쫓는 것도 중요하지만, 어떤 문제를 마주했을 때 떠오르는 해결책들은 원론적인 내용들에서 약간 변형된 경우가 훨씬 많기에 깊이 있는 공부를 지향하려고 노력하자는 이야기를 전달하고 싶었습니다.
3. Frontend - EventSource - Consumer 🎯
개인 프로젝트 AI 답변에 스트리밍 방식을 적용하게 된 이유와 SSE에 대해 간략하게 소개했습니다. 그렇다면 프론트엔드는 모수에 입장하게 된 손님이겠네요. 모수에서 우리가 식사를 요청하는 방식은 EventSource에서 시작됩니다.
useEffect(() => {
if (question && !loading) {
fetchAiAnswer(question.id);
}
}, [question, loading, fetchAiAnswer]);질문 등록하기 버튼을 클릭하고 유저가 상세 페이지에 도달했을 때 즉시 실행되는 함수는 fetchAiAnswer()입니다. 해당 함수에 질문의 고유한 id 값을 전달합니다.
서버 상태 관리를 위해 useMutation을 활용했는데요. 최종적으로는 아래의 코드가 실행됩니다.
export const streamAiAnswer = ({
questionId,
onData,
onComplete,
onError,
}: StreamAiAnswerProps): Promise<void> => {
return new Promise((resolve, reject) => {
const eventSource = new EventSource(
`${API_URL}api/ask-ai/stream/${questionId}`
);
eventSource.onmessage = (event) => {
try {
const parsedData = JSON.parse(event.data);
if (parsedData.type === "DATA") {
onData(parsedData.payload);
} else if (parsedData.type === "COMPLETE") {
onComplete(parsedData.payload);
eventSource.close();
resolve();
}
} catch (e) {
onError?.(new Error("서버로부터 유효하지 않은 데이터를 수신했습니다."));
eventSource.close();
reject(e);
}
};
eventSource.onerror = (error) => {
onError?.(
new Error("스트리밍 중 오류가 발생했거나 연결이 종료되었습니다.")
);
eventSource.close();
reject(error);
};
});
};처음 보는 코드는 크게 크게 이해하려고 노력하는 것이 좋습니다. 잘 모르겠지만 질문 id와 onData / onComplete / onError라는 함수를 받아서, eventSource.onmessage와 eventSource.onerror라는 두 개의 큰 틀 내부에서 사용하고 있네요.
const fetchAiAnswer = useCallback(async (questionId: number) => {
if (!questionId) return;
if (streamRef.current) {
streamRef.current();
}
setAiLoading(true);
setAiError(null);
setAiAnswer(null);
startStream({
questionId,
onData: (chunk) => {
setAiLoading(false);
setAiAnswer((prev) => {
if (!prev) {
const now = new Date().toISOString();
return {
id: "ai-answer-streaming",
questionId: questionId.toString(),
userId: "ai-assistant",
content: chunk,
createdAt: now,
updatedAt: now,
isAiAnswer: true,
};
}
return {
...prev,
content: prev.content + chunk,
};
});
},
onComplete: (finalAnswer) => {
console.log("스트리밍 최종 완료, 상태 업데이트:", finalAnswer);
setAiAnswer({
...finalAnswer,
isAiAnswer: true,
});
setAiLoading(false);
streamRef.current = null;
},
onError: (error) => {
setAiError(error.message);
setAiLoading(false);
},
});
}, []);onData는 eventSource의 onmessage에서 실행되는 함수입니다. streamAiAnswer와 fetchAiAnswer를 동시에 비교해서 보면, event.data를 json으로 파싱한 값을 chunk라는 단위명으로 onData 함수에 전달하게 됩니다. chunk를 기존 content에 계속해서 붙여나가는 역할을 수행하는 함수입니다.
onComplete는 파싱된 데이터의 타입이 complete라면, 해당 파싱 데이터를 전달받는 함수입니다. streamRef.current의 값을 null로 변경하며, 스트리밍 작업이 종료되었을 경우를 처리하는 함수라고 이해할 수 있습니다.
onError는 에러 처리를 위한 함수입니다. 만약 SSE 통신에서 문제가 발생했을 경우, eventSource를 close 하고 reject 함수에 error를 전달하게 되죠.
그런데 저야 이 내용을 구현한 사람이니까 이제는 쉽게 이해할 수 있지만, 처음에는 이 과정이 굉장히 복잡하게 느껴질 것이라 생각합니다. 그래서 SSE 요청이 어떤 흐름으로 전개되는지 그림으로 표현해 봤습니다.
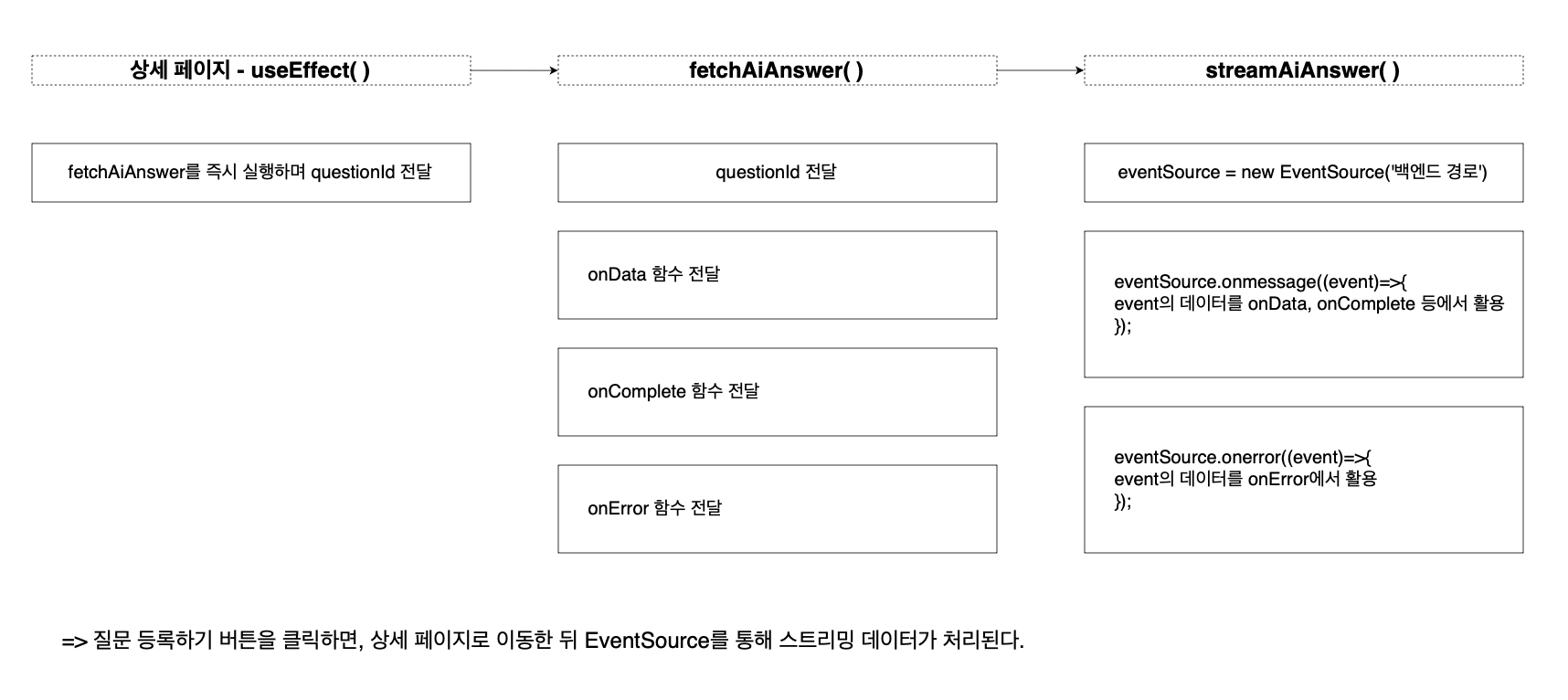
프론트엔드에서 백엔드로 스트리밍 데이터를 요청하는 과정이었습니다.
4. Backend - Observable - Producer 🎯
백엔드의 Observable은 모수 예약 타임에 일어나는 일들의 집합입니다. 14시부터 16시까지 식당을 이용하도록 예약했다고 생각해 보죠.
@Sse('ask-ai/stream/:questionId')
async streamAskAiById(
@Param('questionId') questionId: string,
): Promise<Observable<MessageEvent>> {
const id = Number(questionId);
if (isNaN(id)) {
throw new HttpException(
'유효한 questionId가 아닙니다.',
HttpStatus.BAD_REQUEST,
);
}
const existing = await this.aiService.findByQuestionId(id);
if (existing) {
return new Observable<MessageEvent>((subscriber) => {
subscriber.next({
data: JSON.stringify({ type: 'COMPLETE', payload: existing }),
});
subscriber.complete();
});
}
const question = await this.aiService.findQuestionById(id);
if (!question) {
throw new HttpException('질문을 찾을 수 없습니다.', HttpStatus.NOT_FOUND);
}
return this.aiService
.generateAnswerStream(question.title, question.content, id)
.pipe(
map((event) => ({ data: JSON.stringify(event) })),
tap((event) => console.log('SSE로 전송될 이벤트:', event.data)),
);
}@Sse 데코레이터를 통해, 프론트엔드에서 발생한 EventSource 요청을 연결합니다. 손님이 들어왔을 때, 모수의 직원이 그 사실을 인지하는 상황이라고 볼 수 있습니다.
일단 최초에 요청이 들어오면 existing이 없을 테니 aiService의 generateAnswerStream 함수가 실행될 것입니다.
generateAnswerStream(
title: string,
content: string,
questionId: number,
): Observable<{ type: 'DATA' | 'COMPLETE'; payload: string | AiAnswer }> {
const plainContent =
new JSDOM(content).window.document.body.textContent || '';
const prompt = this.buildPrompt(title, plainContent);
return new Observable((subscriber) => {
const runStream = async () => {
try {
const result = await this.model.generateContentStream(prompt);
let fullAnswer = '';
for await (const chunk of result.stream) {
const chunkText = chunk.text();
fullAnswer += chunkText;
subscriber.next({ type: 'DATA', payload: chunkText });
}
if (fullAnswer.trim()) {
const savedAnswer = await this.saveAnswer(
questionId,
title,
fullAnswer.trim(),
);
subscriber.next({ type: 'COMPLETE', payload: savedAnswer });
}
subscriber.complete();
} catch (error: any) {
console.error('[generateAnswerStream] Gemini API 호출 실패', error);
subscriber.error(this.handleApiError(error));
}
};
runStream();
});
}우선 질문 내용이 HTML일 수도 있으니, DOM을 파싱하여 순수 텍스트만 추출합니다. 그렇게 추출된 plainContent와 질문 제목의 조합을 통해 프롬프트를 생성합니다. 프롬프트 생성에 대한 코드는 하단에 첨부하겠습니다.
generateAnswerStream 함수는 결국 Observable을 반환합니다. Observable은 시간의 흐름에 따라 여러 값이나 이벤트를 발행(produce)하는 객체입니다. 즉 Observable은 하나의 '상황'입니다.
이 Observable 내에서, Gemini AI의 generateContentStream을 호출하여 실시간으로 생성되는 답변 chunk를 순차적으로 emit합니다. 각 chunk는 'DATA' 타입으로 반환되고, 모든 답변이 완료되면 데이터베이스에 저장한 후 'COMPLETE' 타입으로 반환됩니다.
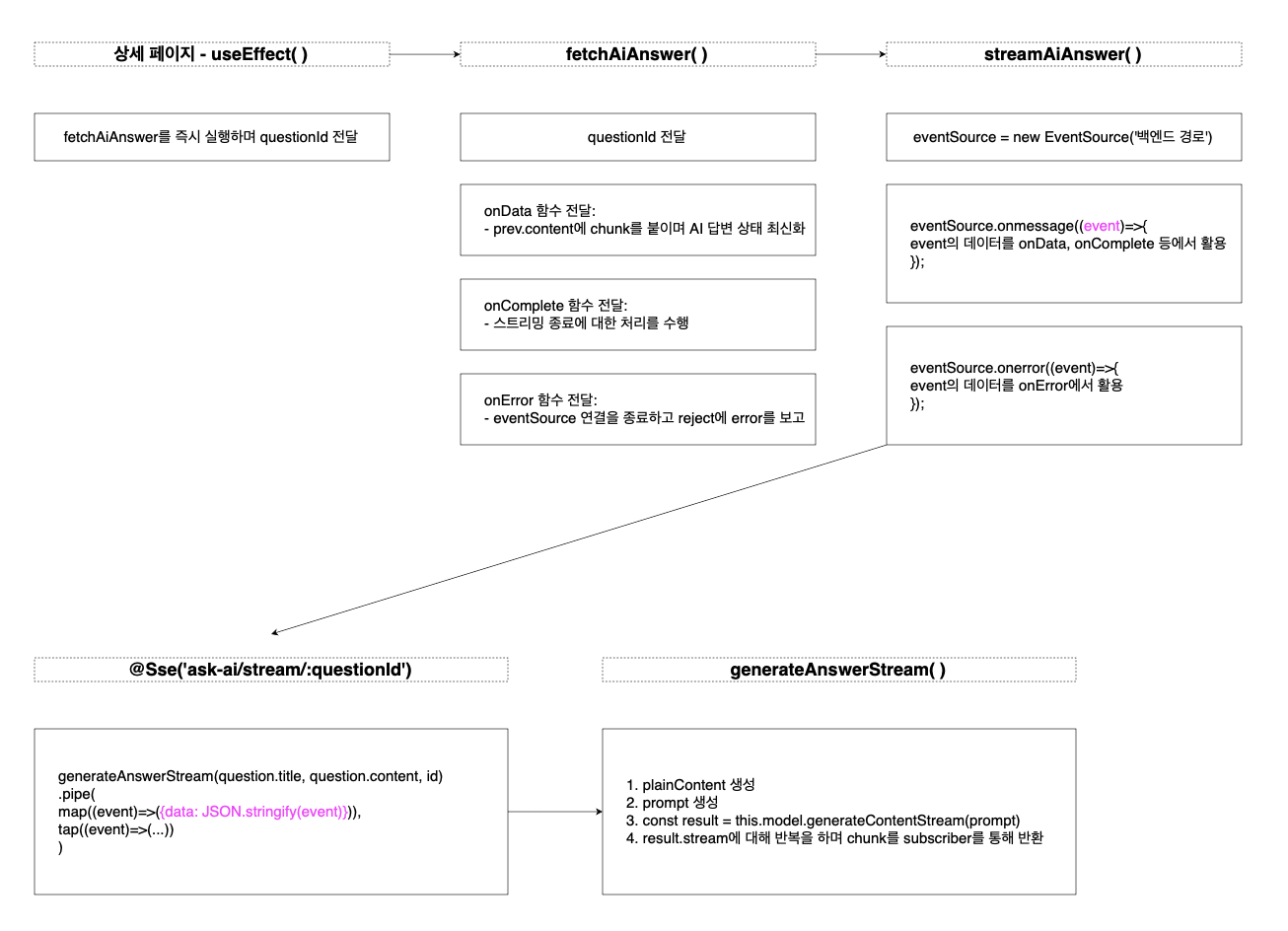
다시 컨트롤러의 반환값을 확인해 보겠습니다. generateAnswerStream의 반환값은 '상황'입니다. 그 상황에 대한 처리를 위해 pipe를 연결하는 것이 아래의 코드입니다. map 또는 tap에서 받는 event가 개별 스트리밍 데이터에 대한 이벤트입니다.
return this.aiService
.generateAnswerStream(question.title, question.content, id)
.pipe(
map((event) => ({ data: JSON.stringify(event) })),
tap((event) => console.log('SSE로 전송될 이벤트:', event.data)),
);익숙하지 않아서 어렵게 느껴지실 수 있습니다. 전체 과정을 이미지로 정리해 봤습니다.
아래의 코드는 제가 개발한 프롬프트 생성 함수입니다.
private buildPrompt(title: string, content: string): string {
return `
당신은 개발자들을 위한 전문적인 Q&A 어시스턴트입니다.
다음 질문에 대해 정확하고 도움이 되는 답변을 제공해주세요.
질문 제목: ${title}
질문 내용:
${content}
답변 시 다음 사항을 고려해주세요:
1. 기술적인 질문의 경우 구체적인 예시 코드나 단계별 설명을 포함해주세요
2. 최신 기술 동향과 베스트 프랙티스를 반영해주세요
3. 가능한 한 실용적이고 실행 가능한 솔루션을 제시해주세요
4. 답변은 한국어로 작성해주세요
5. 마크다운 형식을 사용해서 읽기 쉽게 구조화해주세요
6. 글자 수는 1000자 이내로 제한해주세요
답변:`;
}5. Result 🎯
위 과정을 통해, AI 답변을 얻기까지의 대기 시간을 평균 120초에서 10초 이내로 대폭 개선했습니다. velog에서조차 AI와 SSE를 결합한 내용을 다룬 글은 거의 찾아볼 수 없었습니다. AI 활용 능력이 크게 강조되는 요즘, 실무에서 반드시 마주할 수밖에 없는 주제라고 생각합니다. 이 글이 조금이나마 도움이 되었길 바랍니다.
