0. 4개의 이미지로 인터넷을 이해 🎯
DNS의 원리와 TCP/IP 통신, 브라우저 렌더링 작동 방식과 JavaScript 엔진의 동작 등 인터넷의 개념은 분절되어 있지 않습니다. 그래서 개별적인 주제에 대한 정보를 학습했다 한들, 개념을 통합하는 과정이 없다면 인터넷을 제대로 이해할 수 없습니다.
레오나르도 다빈치는, "단순함이란 궁극의 정교함이다."라는 말을 남긴 적이 있죠. 저는 정교함을 '손실과 반복의 최소화'로 정의합니다. 손실과 반복 없이 정리하기 위해 노력했습니다. 반복은 최소화했지만, 손실에 대해서는 자신이 없습니다. 인터넷이라는 개념을 빠르게 파악하기에 유리한 자료 정도로 보시고, 유실된 내용에 대해서는 너그러이 이해해 주시면 감사하겠습니다.
1. DNS 이해하기 🎯
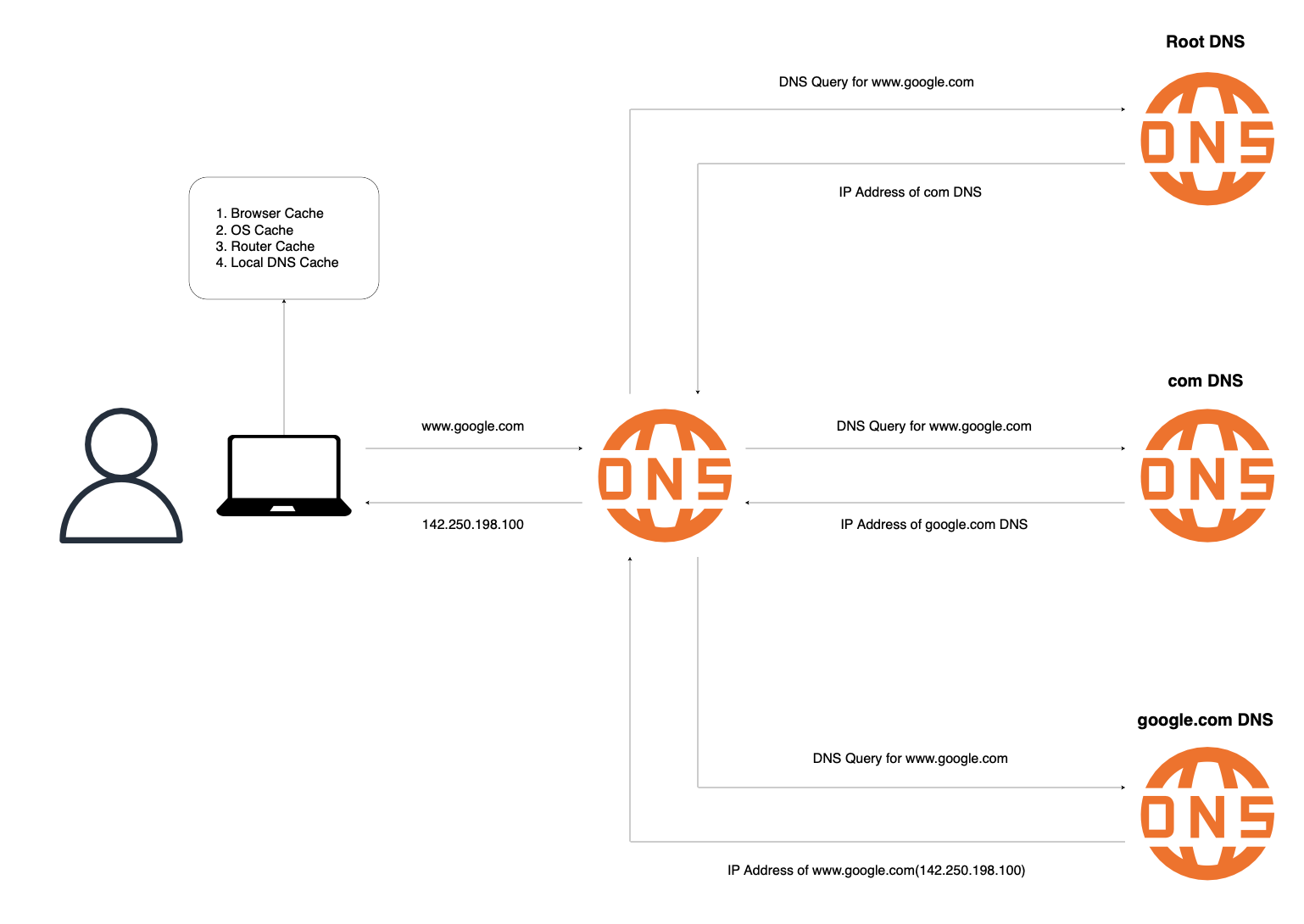
사용자가 www.google.com을 입력하면, 브라우저는 도메인 이름을 실제 서버의 IP 주소로 변환해야 합니다. 인간의 편리를 위해 IP 주소를 도메인 이름으로 치환했을 뿐이고, 컴퓨터는 도메인 이름이 아니라 숫자로 된 IP 주소를 통해 서버와 통신하기 때문이죠. 이러한 변환 작업을 담당하는 시스템을 DNS(Domain Name System)라고 합니다.
1-1. Chace check ✅
DNS 조회를 시작하기 전에, 브라우저는 효율성을 위해 여러 단계의 캐시를 확인합니다.
먼저 브라우저 자체의 DNS 캐시를 확인하여, 최근에 방문한 도메인의 IP 주소가 저장되어 있는지 살펴봅니다. 만약 브라우저 캐시에 없다면, 운영체제(OS)의 DNS 캐시를 확인합니다. 그다음으로는 라우터의 DNS 캐시를 거쳐 로컬 DNS 서버의 캐시까지 순차적으로 확인합니다. 자주 방문하는 웹 사이트는, 매번 DNS 조회 과정을 거치지 않고도 빠르게 접속할 수 있게 됩니다.
1-2. Recursive Query ✅
캐싱되어 있는 IP 주소가 없다면, 본격적인 DNS 조회를 시작합니다. 전 과정은 재귀적 질의(Recursive Query) 방식을 따릅니다.
먼저 로컬 DNS 서버가 루트 DNS 서버에 질의를 보냅니다. 이때, 루트 DNS 서버는 .com 도메인을 관리하는 TLD(Top Level Domain) DNS 서버의 주소를 알려줍니다.
로컬 DNS 서버는 다시 TLD DNS 서버에 질의하여 google.com 도메인을 관리하는 권한 DNS 서버의 주소를 받습니다.
마지막으로 권한 DNS 서버에 질의하면 www.google.com의 실제 IP 주소인 142.250.198.100을 받게 됩니다. 해당 IP 주소는 다시 사용자의 컴퓨터로 전달되며, 동시에 각 단계의 캐시에 저장되어 다음 조회 시 빠른 응답을 가능케 합니다.
2. Encapsulation / Decapsulation 이해하기 🎯
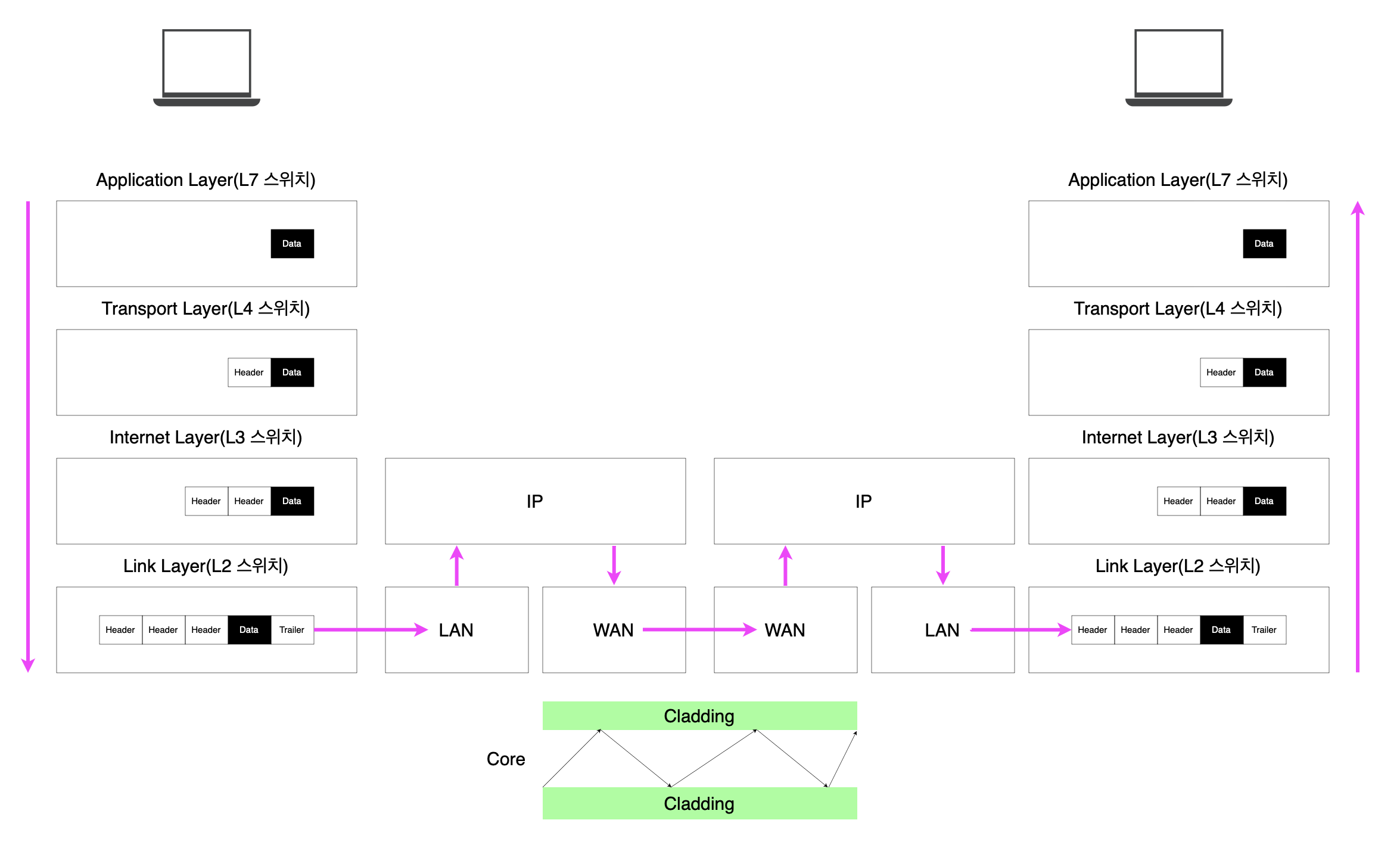
IP 주소를 얻었으니, 브라우저는 구글 서버에 HTTP 요청을 보내야 합니다. 요청 데이터는 네트워크를 통해 전송되는 과정에서 캡슐화와 역캡슐화 과정을 겪게 됩니다.
2-1. Encapsulation ✅
사용자 컴퓨터에서 데이터를 전송할 때는 계층적 캡슐화 과정을 거칩니다.
애플리케이션 계층에서 시작된 HTTP 요청 데이터가 먼저 생성되겠죠. 애플리케이션 계층에서의 데이터 단위를 보통 메세지라고 부릅니다.
해당 데이터는 전송 계층으로 내려가면서 TCP 헤더가 추가됩니다. 메세지에 TCP 헤더가 추가된 형태의 데이터 단위를 세그먼트라고 합니다. TCP 헤더에는 출발지와 목적지의 포트 번호, 시퀀스 번호 등이 포함됩니다.
다음으로 인터넷 계층에서는 세그먼트에 IP 헤더가 추가됩니다. 세그먼트에 IP 헤더가 추가된 형태의 데이터 단위를 패킷이라고 합니다. IP 헤더에는 출발지와 목적지의 IP 주소가 담깁니다.
마지막으로 링크 계층에서는 이더넷 헤더와 트레일러가 추가됩니다. 패킷에 이더넷 헤더와 트레일러가 추가된 데이터 단위를 프레임이라고 합니다. 프레임에는 MAC 주소 정보가 포함됩니다.
2-2. Optical Fiber ✅
완성된 프레임은 물리적 전송 매체를 통해 전달됩니다. 우리에게 익숙한 LAN을 벗어나면, 데이터는 광케이블을 통해 먼 거리를 이동합니다.
데이터는 전기 신호에서 빛 신호로 변환되어 광섬유를 통과하며, 여러 라우터를 거쳐 구글의 데이터 센터까지 도달합니다. 이 과정에서 WAN 구간을 통과하며, 코어 네트워크의 고속 광케이블을 따라 전송됩니다.
광케이블의 클래딩 구조는 빛의 전반사를 이용하여, 신호 손실을 최소화하면서 먼 거리까지 데이터를 전송할 수 있게 되는 것이죠.
2-3. Decapsulation ✅
구글 데이터 센터에 도착한 데이터는 역캡슐화 과정을 거칩니다.
우선 링크 계층에서 이더넷 헤더와 트레일러를 제거하고 MAC 주소를 확인합니다. 그다음 인터넷 계층에서 IP 헤더를 제거하며, 목적지 IP 주소가 올바른지 검증합니다. 전송 계층에서는 TCP 헤더를 분석하여 포트 번호를 확인하고 데이터의 순서를 재조립합니다. 최종적으로 애플리케이션 계층에서 순수한 HTTP 요청 데이터가 추출되어 웹 서버 애플리케이션으로 전달됩니다.
3. Critical Rendering Path 이해하기 🎯
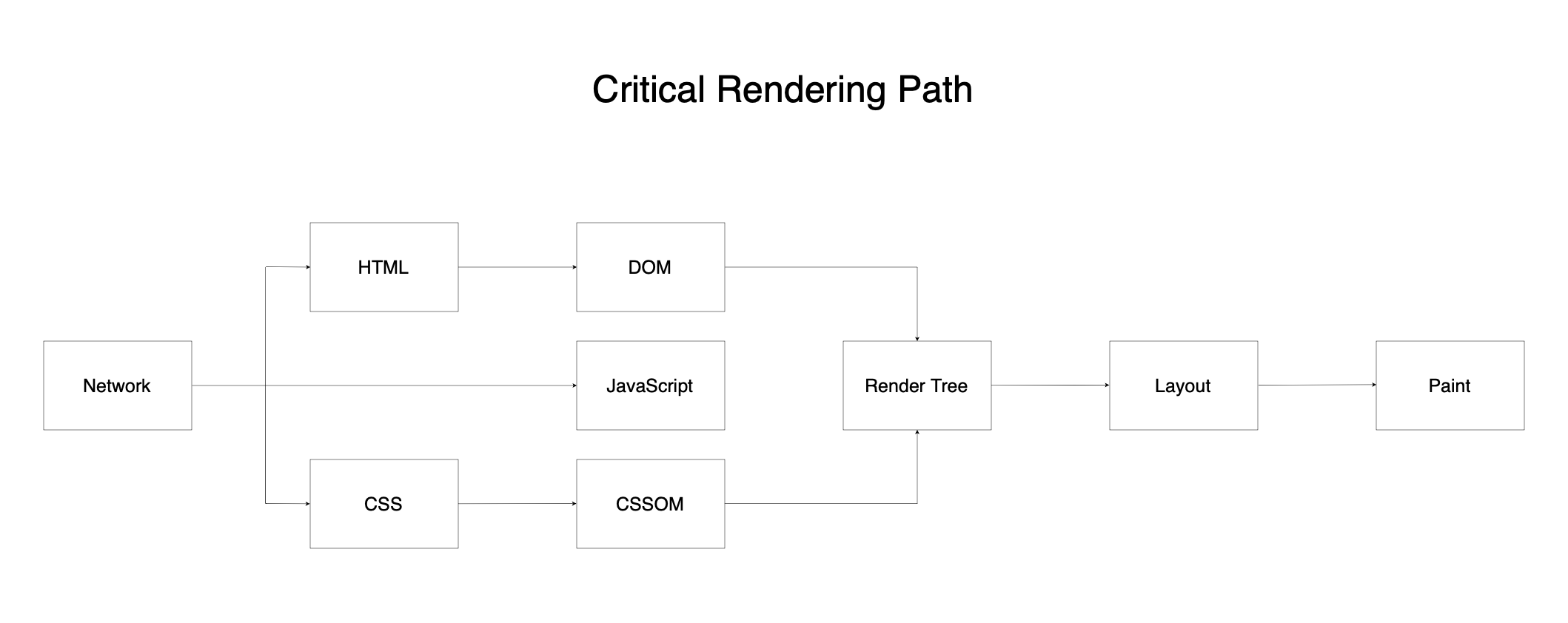
구글 서버는 다시 사용자의 컴퓨터로 응답 데이터를 보낼 것입니다. 사용자 컴퓨터가 캡슐화와 역캡슐화를 거쳐 HTML, CSS, JavaScript 파일을 받았습니다. 이제 이 파일들을 화면에 띄우는 렌더링 과정을 수행해야 합니다. 브라우저의 렌더링 엔진이 이를 처리하는데요, 이러한 렌더링 처리 과정을 Critical Rendering Path라고 표현합니다.
3-1. DOM Tree ✅
브라우저는 우선 HTML 문서를 파싱합니다. 파싱 과정에서 HTML 태그를 읽어가며 DOM(Document Object Model) Tree를 구성합니다. 각 HTML 태그는 DOM 노드로 변환되며, 이 노드들은 트리 구조로 연결됩니다.
가령, html 태그는 루트 노드가 되고, head나 body는 그 자식 노드가 됩니다. DOM Tree는 문서의 구조적 표현입니다. JavaScript를 통해 동적으로 조작할 수 있는 객체 모델이 된 것이죠.
3-2. CSSOM Tree ✅
HTML 파싱과 동시에 브라우저는 CSS 파일을 다운로드하고 파싱합니다. CSS 파서는 스타일 규칙을 읽어 CSSOM(CSS Object Model) Tree를 생성합니다. CSSOM Tree는 각 DOM 노드에 어떤 스타일이 적용되어야 하는지를 나타냅니다.
CSS의 C는 Cascade입니다. Cascade 특성에 따라 상위 요소의 스타일이 하위 요소로 상속되며, 선택자 우선순위에 따라 최종 스타일이 결정되죠. CSSOM Tree 역시 DOM Tree와 마찬가지로 계층적 구조를 가집니다.
3-3. Render Tree ✅
DOM Tree와 CSSOM Tree가 모두 생성되면, 브라우저는 이 둘을 결합하여 Render Tree를 생성합니다.
Render Tree는 실제로 화면에 표시될 요소들만 포함합니다. display: none으로 설정된 요소는 렌더 트리에서 제외됩니다. 각 렌더 트리 노드에는 해당 요소의 최종 계산된 스타일 정보가 포합됩니다. JavaScript 파일이 있다면 이 단계에서 실행되며, DOM이나 CSSOM을 동적으로 수정할 수 있습니다. 만약 JavaScript가 DOM을 변경하면 렌더 트리도 다시 구성될 것입니다.
3-4. Reflow ✅
Reflow는 레이아웃 단계라고도 합니다. 렌더 트리가 완성되면 Reflow 단계가 시작됩니다. 브라우저는 뷰포트 크기를 기준으로 각 요소의 정확한 위치와 크기를 계산합니다.
박스 모델에 따라 margin, border, padding, content 영역을 계산하고, 요소들이 서로 어떻게 배치되어야 하는지 결정합니다. Reflow 단계는 계산 비용이 크기 때문에, JavaScript로 스타일을 자주 변경하면 성능 문제가 발생할 수 있습니다. 요소의 위치나 크기가 변경되면, 주변 요소들의 레이아웃도 다시 계산해야 하는 경우가 많기 때문이죠.
3-5. Paint ✅
브라우저는 계산된 레이아웃을 기반으로, 실제 픽셀을 화면에 그립니다. 이 과정을 Paint 단계라고 합니다.
텍스트, 색상, 이미지, 테두리, 그림자 등 시각적 요소들이 순차적으로 렌더링 됩니다. 복잡한 페이지의 경우 여러 레이어로 나누어 그린 후 합성하는 과정을 거칩니다. 이를 컴포지팅이라고 합니다. GPU 가속을 사용하면 일부 레이어를 GPU에서 처리하여 성능을 향상시킬 수 있다고 합니다.
페인트가 완료되면 사용자는 비로소 구글의 검색 페이지를 화면에서 볼 수 있게 됩니다.
4. JS Engine 이해하기 🎯
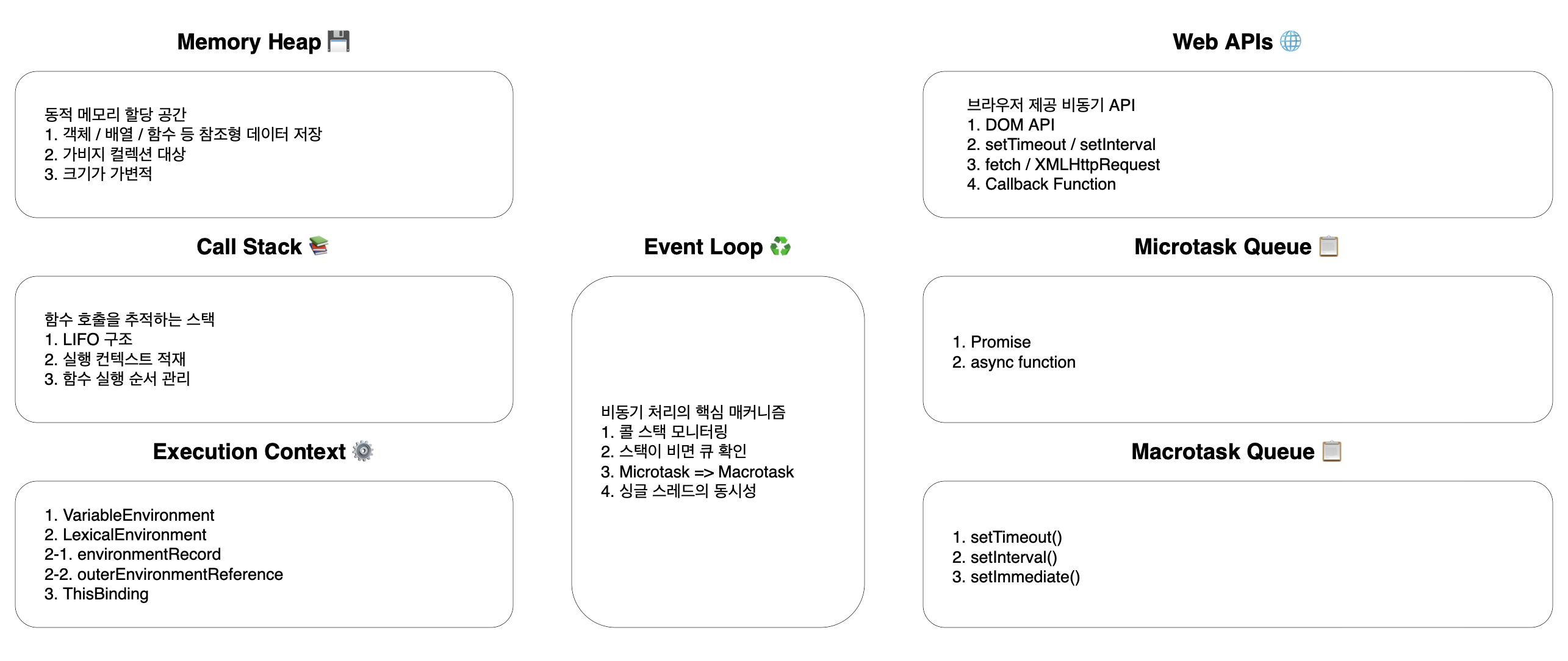
페이지가 렌더링 된 후에도 JavaScript는 계속 실행되며 사용자의 상호작용에 반응합니다. JavaScript Engine 덕분입니다.
4-1. Single Thread ✅
JavaScript는 싱글 스레드 언어입니다. 한 번에 하나의 작업만 처리할 수 있다는 뜻이죠.
콜 스택이라는 자료구조를 통해 함수 호출을 관리하는데, 이는 LIFO(Last In First Out) 방식으로 동작합니다. 함수가 호출되면 콜 스택에 쌓이고, 함수 실행이 끝나면 콜 스택에서 제거됩니다.
더 정확히 표현하면 콜 스택에는 함수가 아니라 실행 컨텍스트가 적재됩니다. 실행 컨텍스트는 함수가 실행될 때의 환경 정보를 의미합니다. 실행 컨텍스트는 VariableEnvironment, LexicalEnvironment, This Binding으로 구성됩니다. LexicalEnvironment는 다시 environmentRecord와 outerEnvironmentReference로 구성되며, 이를 통해 스코프 체이닝과 클로저가 구현됩니다.
4-2. Event Loop ✅
한 번에 하나의 작업만 처리할 수 있는 싱글 스레드 언어임에도 불구하고, JavaScript가 비동기 작업을 처리할 수 있는 것은 이벤트 루프 덕분입니다.
이벤트 루프는 콜 스택이 비어있는지 지속적으로 모니터링합니다. 콜 스택이 비면 태스크 큐에서 대기 중인 작업을 꺼내어 콜 스택으로 옮깁니다. Promise는 마이크로태스크 큐에 들어가고, setTimeout이나 setInterval은 매크로태스크 큐에 들어갑니다. 마이크로태스크 큐가 매크로태스크 큐보다 우선순위가 더 높습니다. 따라서 이벤트 루프는 모든 마이크로태스크 큐의 작업을 처리한 후에 매크로태스크 큐의 작업을 처리하는 방식으로 동작하게 됩니다. 이러한 매커니즘 덕분에 콜 스택이 블로킹되지 않으면서도 순차적인 실행 순서를 보장할 수 있습니다.
4-3. Non-Blocking I/O ✅
라멘 주문이라는 함수가 있다고 가정하죠. 동기 방식은 화구가 하나여서 A 주문 조리가 끝날 때까지 B 주문 조리를 시작할 수 없는 일 처리 방식입니다. 비동기 방식은 화구가 두 개여서 A 주문에 대한 냄비를 올려놓고, B 주문에 대한 조리도 처리할 수 있는 방식이죠.
블로킹은 요리사가 조리하는 동안 손님이 주방 앞에서 계속 기다리는 상황입니다. 요리사가 동기 방식으로든 비동기 방식으로든 조리를 하는 것과 상관없이, 손님은 계속해서 주방 앞에서 기다리는 상황입니다. 논블로킹은 요리사가 조리하는 동안 손님이 자리에 가서 친구랑 대화를 나누는 상황입니다.
동기 + 블로킹
function workSyncBlocking() {
console.log("A 작업 시작");
for (let i = 0; i < 2000; i++) {} // Blocking
console.log("A 작업 완료");
console.log("B 작업 시작"); // A 끝나야 실행됨
}
workSyncBlocking();동기 + 논블로킹
let isDone = false;
// 1초 후 작업이 완료된다고 가정
setTimeout(() => {
isDone = true;
}, 1000);
// 주기적으로 상태를 확인 (polling)
const interval = setInterval(() => {
console.log("작업 완료됐나?");
if (isDone) {
console.log("✅ 작업 완료 확인!");
clearInterval(interval);
}
}, 300);비동기 + 블로킹
function asyncTask() {
return new Promise((resolve) => {
setTimeout(() => {
console.log("비동기 작업 완료");
resolve();
}, 1000);
});
}
async function workAsyncBlocking() {
console.log("시작");
await asyncTask(); // 여기서 멈춤 (await은 논리적 Blocking)
console.log("다음 작업 실행");
}
workAsyncBlocking();비동기 + 논블로킹
function asyncTask() {
setTimeout(() => {
console.log("비동기 작업 완료");
}, 1000);
}
function workAsyncNonBlocking() {
console.log("시작");
asyncTask(); // 기다리지 않음
console.log("다음 작업 실행");
}
workAsyncNonBlocking();장황했지만, 결국 자바스크립트 엔진은 비동기 작업을 백그라운드로 넘긴 후 멈추지 않고 다음 코드를 실행하는 이벤트 루프의 특성 덕분에, Non-Blocking I/O 방식으로 작업을 처리할 수 있습니다.
5. 마치며 🎯
화면에 페이지가 표시되고 JavaScript가 실행되기까지의 전체 과정을 살펴보았습니다. DNS 조회부터 시작하여 네트워크 계층을 통한 데이터 전송, 브라우저의 렌더링 과정, 그리고 JavaScript 엔진의 실행 메커니즘까지 각 단계는 서로 유기적으로 연결되어 있으며, 이 모든 과정이 불과 수백 밀리초 안에 완료됩니다.
