
데이터 분석을 시작하기 전에 알아야할 통계 지식을 정리함.
코드를 쉽게 이해하기 위해서 영문도 같이 이해하면 좋을듯 함.
관련 pandas 코드를 본문 끝에 같이 정리하였음.
데이터의 종류
-
수치형(Numerical)
- 연속형(Continuous): 실수 값, 무한히 세분화 가능 (예: 키, 몸무게, 온도)
- 이산형(Discrete): 정수 값, 개수 단위 (예: 학생 수, 동전 던지기 결과)
-
범주형(Categorical)
- 명목형(Nominal): 순서 없음 (예: 성별, 혈액형)
- 순서형(Ordinal): 순서 있음 (예: 학년, 만족도 등급)
→ 데이터 유형에 따라 통계 기법과 시각화 방식 달라짐
중심 경향 지표
- 평균(Mean): 전체 합 ÷ 개수 → 극단값에 민감함
- 중간값(Median): 크기 순 정렬 후 중앙값 → 이상치 영향 적음
- 최빈값(Mode): 가장 자주 등장하는 값 → 범주형 데이터 분석에 유용
이상값(Outlier)과 결측치(Missing Value)
- 이상값: 일반적 패턴에서 벗어난 값, 분석에 큰 영향
- 결측치: 누락된 값 → 제거하거나 평균/중간값 등으로 대체 가능
평균 vs 중간값
-
데이터가 치우친 경우 차이 발생
- 평균: 극단값 민감 (비정상적으로 큰/작은 데이터가 있는 경우 평균값의 오류 발생)
- 중간값: 안정적인 대표값
분위수 (Quartiles)와 중간값 계산
- Q1 (25%), Q2 (50% = 중간값), Q3 (75%), Q4 (100% = 최대값)
- 홀수 개 데이터: 중앙값 기준으로 좌·우 분할
- 짝수 개 데이터: 중앙 두 값의 평균
→ 박스플롯(Boxplot)으로 분위수와 이상치 확인 가능
모집단(Population)과 표본(Sample)
- 모집단: 전체 데이터 집합
- 표본: 모집단에서 추출한 일부 데이터
→ 표본을 통해 모집단을 추정하는 것이 추론통계의 핵심
(예시) 전교 남학생 500명의 키에 따른 체중 분석 → 전국 남학생의 키에 따른 체중 추정
데이터 분포의 모양
-
정규분포 (Normal Distribution)
- 종 모양(Bell-shaped), 대칭적
- 평균 = 중간값 = 최빈값
-
치우친 분포 (Skewed Distribution)
- Right/Positive Skewed: 오른쪽 꼬리 길다 → 왜도 > 0
- Left/Negative Skewed: 왼쪽 꼬리 길다 → 왜도 < 0
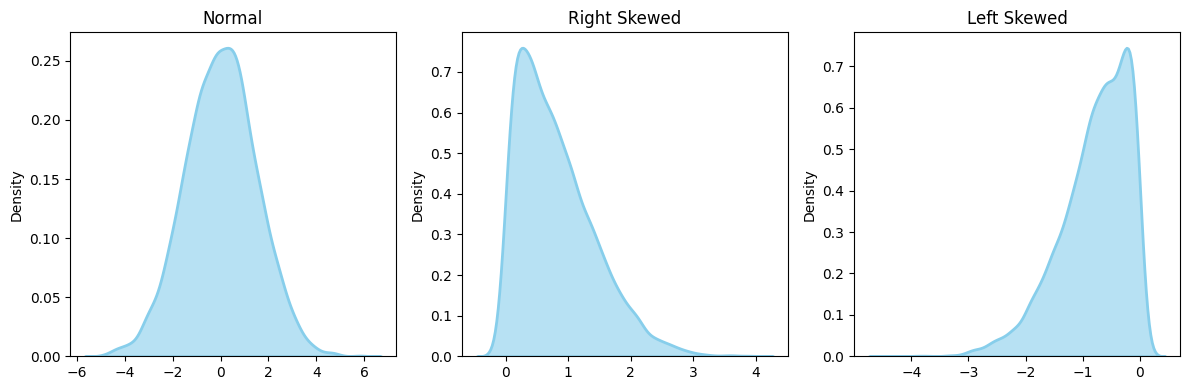
왜도 (Skewness)
- 데이터 분포의 비뚤어진 정도
- 정규분포: 왜도 = 0
- 양의 왜도(>0): 평균 > 중간값
- 음의 왜도(<0): 평균 < 중간값
- 절대값이 클수록 비뚤어진 정도 큼
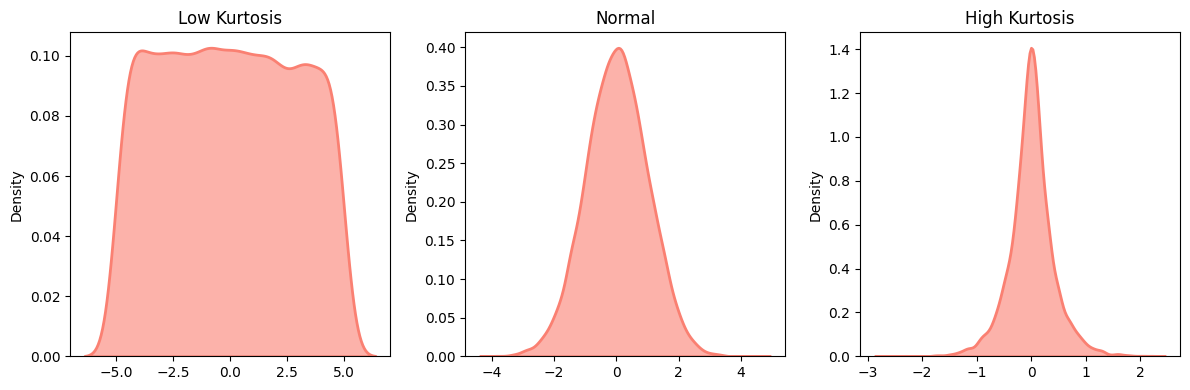
첨도 (Kurtosis)
- 데이터 분포가 얼마나 뾰족/평평한지 지표
- 정규분포: 첨도 = 3 (Excess Kurtosis = 0)
- 첨도가 높음 (Leptokurtic): 중앙 집중 강하고 꼬리 두꺼움
- 첨도가 낮음 (Platykurtic): 완만하고 평평, 꼬리 얇음
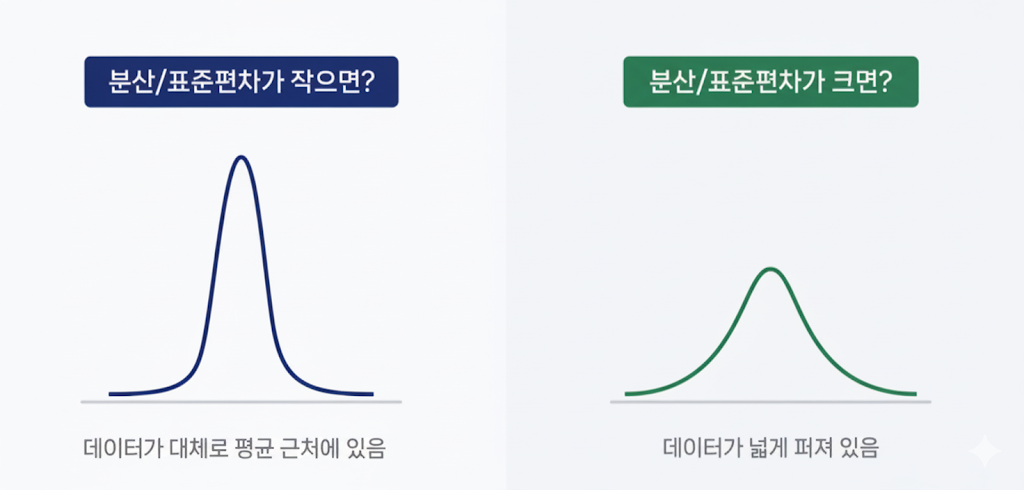
분산(Variance)과 표준편차(Standard Deviation)
- 편차(Deviation): 각 데이터가 평균에서 얼마나 떨어져 있는지 나타냄
- 분산(Variance): 편차를 제곱하여 평균한 값, 데이터가 평균에서 얼마나 퍼져 있는지 파악
- 표준편차(Standard Deviation): 분산의 제곱근, 원래 데이터 단위와 동일 → 데이터의 퍼짐 정도 직관적 이해 가능
-
모집단의 분산 vs 표본 집단의 분산
-
모집단 분산(Population Variance): 모든 데이터를 포함한 분산 계산
→ 분모는 데이터 개수 N
→ 편차 제곱의 평균을 구하는 방식 -
표본 분산(Sample Variance): 모집단 일부 데이터(표본)로 분산 추정
→ 분모는 n-1 (자유도)
→ 표본이 모집단의 분산을 과소평가하지 않도록 보정
*데이터 규모가 더 큰 모집단의 편차가 더 클 것이라고 예측하여 보정하는 방법
→ n-1을 사용하면 불편분산(unbiased variance)이 됨
-
누적값 (Cumulative Sum)
- 데이터를 순차적으로 더한 값
- → 시계열 분석, 누적 추세 관찰에 유용
누적 곱 (Cumulative Product)
- 개념: 데이터의 순차적 곱을 누적해서 계산한 값
- 시계열 데이터, 성장률 계산, 복리 계산 등에 활용 가능
기술통계 vs 추론통계
-
기술통계(Descriptive Statistics)
- 데이터 요약 및 탐색
- 예: 평균, 중간값, 표준편차, 히스토그램, 박스플롯
- 주로 EDA(Exploratory Data Analysis) 단계에서 사용
-
추론통계(Inferential Statistics)
- 표본 기반 모집단 추정 및 가설 검증
- 예: 신뢰구간, t-test, 회귀분석, 카이제곱 검정
- 주로 모델링, 연구 가설 검증 단계에서 사용
관련 pandas 코드
0. import 및 예시 데이터 생성
import pandas as pd
import numpy as np
# 예시 데이터 생성
data = {
"Height": [165, 170, 155, 180, 175, 160, 168, 172],
"Weight": [62, 70, 55, 80, 75, 58, 65, 68],
"Score": [90, 85, np.nan, 88, 92, np.nan, 80, 87]
}
df = pd.DataFrame(data)
### 결측치 확인
```python
df.isna() # 각 요소가 NaN인지 True/False 반환
df.isna().sum() # 컬럼별 결측치 개수2. 중심 경향 지표
df.mean() # 평균값 (NaN 무시)
df.median() # 중앙값
df.mode() # 최빈값3. 편차, 분산, 표준편차
df['Height'].sub(df['Height'].mean()) # 각 값에서 평균 뺀 편차
df.var() # 표본 기준 분산 (n-1)
df.std() # 표준편차4. 분위수 계산
df.quantile([0.25, 0.5, 0.75]) # Q1, Q2(중앙값), Q35. 누적합, 누적곱
df.cumsum() # 각 컬럼별 누적합 계산
df.cumprod() # 각 컬렴벌 누적곱 계산6. 기술통계 요약
df.describe() # 평균, 표준편차, 최소/최대, 4분위수 등 요약7. 모집단과 표본 분산
s.var() # 기본 ddof=1 → 표본 분산
s.var(ddof=0) # 모집단 분산
# 기본 var()는 표본 분산(n-1) 계산
# ddof는 “delta degrees of freedom”의 약자로, 분산 계산 시 분모에서 뺄 값을 의미함코드 요약
- 결측치:
isna(),sum() - 평균/중간값/최빈값:
mean(),median(),mode() - 편차/분산/표준편차:
sub(),var(),std() - 분위수:
quantile() - 누적합:
cumsum() - 기술통계 요약:
describe() - 모집단 vs 표본 분산:
var(ddof=0),var()

AI 엔지니어 노트