0. 서론
EDA를 처음 배우면서 간단하게 타이타닉 생존률 분석에 대한 EDA 예시를 학습하였다. (주로 캐글 또는 블로그에 EDA 예시를 서칭하였다.)
이후 직접 실습을 통해 데이터 분석을 시도해보았다.
해당 EDA는 GPT 에게 난이도를 기준으로 입문자가 접근하기 좋은 데이터셋 목록을 추천받아 그 중에서 1개를 취사하여 진행하였다.
(처음에는 캐글에서 찾은 데이터셋 - '2024년 스택오버 플로우 개발자 설문조사'를 통해 실습해보았으나, 난이도가 높아 데이터셋을 변경하였다.)
EDA는 코딩보다 사고 과정과 데이터에서 어떻게 인사이트를 얻는지가 중요하므로, 코딩 자체는 AI(Chat GPT) 의 도움을 받았으나, 가설 설정이나 시각화 부분에서는 최대한 스스로 생각해보고, 직접 실행해보면서 수정을 하는 과정을 거쳤다.
- 가설 설정: 어떤 변수가 영향을 줄것인가 예측
- 시각화 방법 결정: 해당 데이터를 어떤 식으로 시각화할지
*주피터 노트북을 통해 EDA 실습한 내용을 마크다운 파일로 변환 후 이미지를 추가 첨부하였다.
Red Wine Quality 데이터셋 분석
1. 데이터셋 소개
이 데이터셋은 포르투갈 "Vinho Verde" 레드 와인의 화학적 특성(physicochemical properties) 과 품질 점수(quality score) 를 포함하고 있다.
- 출처: Kaggle
- 샘플 수: 약 1,600개 (red wine)
- 컬럼 수: 12개 (11개 독립 변수 + 1개 종속 변수)
- 특징: 이 데이터셋은 포르투갈 "Vinho Verde" 와인의 레드와 화이트 품종에 관련된 것이다. 개인정보 보호 및 물류 문제로 인해 포도 품종, 와인 브랜드, 가격 등은 제공되지 않고, 화학적 특성(입력 변수) 과 관능 품질 점수(출력 변수) 만 포함되어 있다.
2. 변수 설명
| 컬럼명 | 설명 |
|---|---|
| fixed acidity | 고정 산도 (타르타르산 등, 와인의 기본 산도) |
| volatile acidity | 휘발성 산도 (아세트산 등, 높은 값은 식초 맛 유발) |
| citric acid | 구연산 함량 (와인의 신선함, 풍미와 관련) |
| residual sugar | 잔여 당분 (발효 후 남은 당분, 단맛과 관련) |
| chlorides | 염화물 (소금 농도, 맛에 영향) |
| free sulfur dioxide | 자유 이산화황 (박테리아 억제, 보존제 역할) |
| total sulfur dioxide | 총 이산화황 (자유 + 결합, 높은 값은 산화 억제) |
| density | 밀도 (알코올과 당분에 의해 결정) |
| pH | 산도 (낮을수록 산성, 보통 2.5 ~ 4.0) |
| sulphates | 황산염 (항산화제, 풍미와 보존성 관련) |
| alcohol | 알코올 도수 |
| quality | 와인 품질 점수 (0~10, 전문가 평가) |
- 11개의 독립변수(입력 변수): 와인의 화학적 특성
- 1개의 종속변수(출력 변수): 와인 품질 점수(0~10점)
- 와인 품질 점수에 영향을 미치는 화학적 특성들이 어떤 것들인지 상관 관계를 분석해보고자 한다.
*와인의 화학적 특성에 대해 잘 알지 못하므로, 각 컬럼에 대한 설명은 GPT를 통해 정리하였다.
3. 데이터 분석 목표
- 이 프로젝트의 주요 목표는 EDA(탐색적 데이터 분석) 를 통해 와인 품질과 화학적 특성 간의 관계를 이해하는 것이다.
- 즉, 어떤 화학적 특성이 와인 품질 점수에 높은 영향을 끼치는지 분석한다.
4. 가설
데이터 변수에 대한 정의(간단한 설명)를 GPT를 통해 진행하고, 해당 내용을 바탕으로 와인 품질 점수에 대해 영향을 끼칠 요소들을 예측하였다.
-
가설 1. 휘발성 산도 수치가 높을수록 품질 점수는 낮을 것이다. (높을 수록 식초 맛을 유발하므로 품질 점수와 연관성이 높을 것으로 예측함)
-
가설 2. 구연산 함량 수치가 특정 범위에서 높은 품질 점수를 보일 것이다. (풍미와 관련된 수치이므로, 풍미가 적절하게 높은 구연산 함량 범위가 있을 것으로 예측함)
-
가설 3. 황산염 함량 수치가 높을수록 품질 점수는 높을 것이다. (수치가 클수록 풍미와 보존성이 커져 높은 품질 점수를 받을 것으로 예측함.)
-
가설 4. 알코올 도수가 높을 수록 높은 품질 점수를 보일 것이다. (통상 도수가 높을 수록 가격이 비싸진 다는 점에서 높은 품질 점수를 받을 것으로 예측함)
5. 데이터 확인(결측치 탐색)
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
wine = pd.read_csv('data/winequality-red.csv')
wine.head()| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
| 1 | 7.8 | 0.88 | 0.00 | 2.6 | 0.098 | 25.0 | 67.0 | 0.9968 | 3.20 | 0.68 | 9.8 | 5 |
| 2 | 7.8 | 0.76 | 0.04 | 2.3 | 0.092 | 15.0 | 54.0 | 0.9970 | 3.26 | 0.65 | 9.8 | 5 |
| 3 | 11.2 | 0.28 | 0.56 | 1.9 | 0.075 | 17.0 | 60.0 | 0.9980 | 3.16 | 0.58 | 9.8 | 6 |
| 4 | 7.4 | 0.70 | 0.00 | 1.9 | 0.076 | 11.0 | 34.0 | 0.9978 | 3.51 | 0.56 | 9.4 | 5 |
print(wine.shape)
wine.info()(1599, 12)
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1599 entries, 0 to 1598
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 fixed acidity 1599 non-null float64
1 volatile acidity 1599 non-null float64
2 citric acid 1599 non-null float64
3 residual sugar 1599 non-null float64
4 chlorides 1599 non-null float64
5 free sulfur dioxide 1599 non-null float64
6 total sulfur dioxide 1599 non-null float64
7 density 1599 non-null float64
8 pH 1599 non-null float64
9 sulphates 1599 non-null float64
10 alcohol 1599 non-null float64
11 quality 1599 non-null int64
dtypes: float64(11), int64(1)
memory usage: 150.0 KB데이터 점검
- 데이터는 총 1,599개 rows * 12개 columns 으로 구성되어있다.
- 데이터 정보를 조회했을 때, 결측치를 가진 컬럼은 없음을 확인하였다.
- 따라서 결측치에 대한 처리 없이 가설 검증을 진행한다.
6. 가설 검증
가설 1. 휘발성 산도 수치가 높을 수록 품질 점수는 낮을 것이다.
- 와인 품질 점수는 1~10 점, 1점 단위로 평가됨을 확인하였다.
- 휘발성 산도의 최솟값과 최댓값을 비교한 뒤, 범주(구간)별로 와인 품질 점수를 산점도로 나타낸다.
max = wine['volatile acidity'].max()
min = wine['volatile acidity'].min()
print(f"휘발성 산도 수치의 최댓 값: {max}, 최소 값: {min}, 차이: {max-min}")휘발성 산도 수치의 최댓 값: 1.58, 최소 값: 0.12, 차이: 1.46- 휘발성 산도 수치의 범위를 확인했으므로, 0.1 ~ 1.6 의 범위를 5개의 구간으로 나누어 산점도를 시각화해본다.
- 구간별 와인 품질 점수의 평균을 막대 그래프를 통해 비교하여 두 요소 간 상관관계를 확인한다.
# 구간화
bins = [0.1, 0.4, 0.7, 1.0, 1.3, 1.6]
labels = ["0.1~0.4", "0.4~0.7", "0.7~1.0", "1.0~1.3", "1.3~1.6"]
wine["va_bin"] = pd.cut(wine["volatile acidity"], bins=bins, labels=labels, include_lowest=True)# 구간별 평균 품질 점수 계산
grouped = wine.groupby("va_bin")["quality"].mean().reset_index()
print(grouped) va_bin quality
0 0.1~0.4 6.069663
1 0.4~0.7 5.533835
2 0.7~1.0 5.262376
3 1.0~1.3 4.611111
4 1.3~1.6 4.333333#시각화 (막대그래프)
sns.barplot(x="va_bin", y="quality", data=grouped)
plt.title("Average Wine Quality by Volatile Acidity Range")
plt.xlabel("Volatile Acidity Range")
plt.ylabel("Average Quality Score")
plt.show()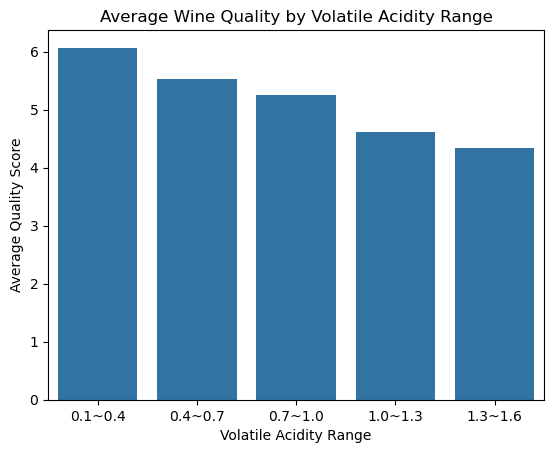
가설 1 평가.
- 휘발성 산도 수치가 높을 수록 와인 품질 점수의 평균이 소폭 낮아짐을 확인할 수 있다.
- 구간별 이상치에 대한 점검이 되지 않았으므로, 평균 값의 오류가 발생할 여지가 있다.
가설 2. 구연산 함량 수치가 특정 범위에서 높은 품질 점수를 보일 것이다.
- 특정 범위에서 높은 품질 점수를 보일 것으로 예측했으므로, 구연산 함량별 구간을 나누고, 점수 평균을 피봇테이블로 확인한다.
# 구연산 함량 수치 범위 확인
print(wine["citric acid"].min(), wine["citric acid"].max())
# 구연산 구간 나누기 (예: 0.0 ~ 1.0을 5등분)
wine["citric_bin"] = pd.cut(wine["citric acid"], bins=5)
# 피벗테이블 (구간별 평균 품질 점수)
pivot = wine.pivot_table(index="citric_bin", values="quality", aggfunc="mean")
# 순위 추가 (평균 점수가 높은 순 = 1위)
pivot["rank"] = pivot["quality"].rank(method="dense", ascending=False).astype(int)
# 결과 출력 (순위순 정렬)
print(pivot.sort_values("rank"))0.0 1.0
quality rank
citric_bin
(0.6, 0.8] 6.012987 1
(0.4, 0.6] 5.865753 2
(0.2, 0.4] 5.632381 3
(-0.001, 0.2] 5.462758 4
(0.8, 1.0] 4.000000 5가설 2 평가.
- 구연산 함량 수치 0.6 ~ 0.8 에서 가장 높은 품질 평균 점수를 보여주었으며,
- 0.8을 초과하는 경우 가장 낮은 품질 평균 점수를 확인할 수 있다.
- 다만 데이터 분산에 대한 추가 분석이 필요해보인다.
가설 3. 황산염 함량 수치가 높을수록 품질 점수는 높을 것이다.
- 황산염(sulphates)의 분포가 품질 점수에 따라 어떤 차이를 보이는지 확인하기 위해 박스 플롯을 그려본다.
# 황산염 함량 수치 범위 확인
print(wine["sulphates"].min(), wine["sulphates"].max())
plt.figure(figsize=(8, 5))
sns.boxplot(
data=wine, x='quality', y='sulphates'
)
plt.title('Sulphates by quality (box plot)')
plt.xlabel('quality'); plt.ylabel('sulphates')
plt.tight_layout(); plt.show()0.33 2.0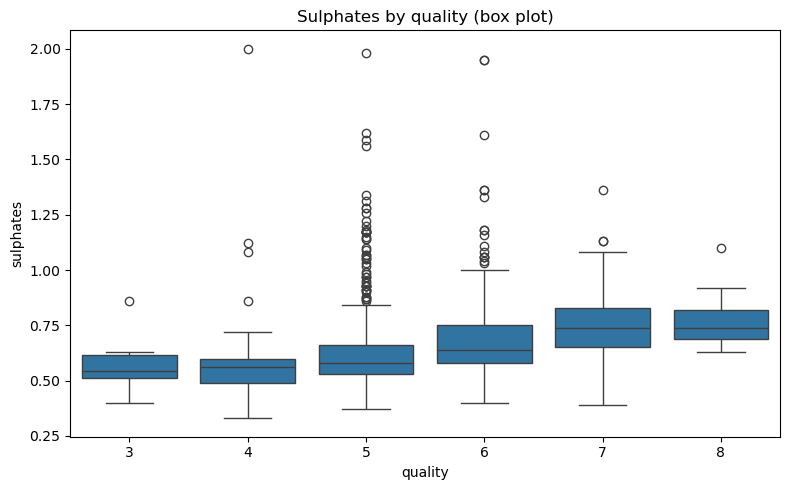
가설 3 평가.
-
시각화된 박스 플롯에서, 두 변수 간 연관성은 찾기 어렵다.
-
등급이 올라갈수록 중앙값이 약간 오르긴 하지만, 차이가 작고 등급 간 분포가 많이 겹친다.
-
각 품질 등급의 IQR과 중앙값이 서로 비슷해 변별력이 낮다. 같은 황산염 수준에서도 여러 품질 등급이 뒤섞여 나타난다.
-
특히 중간 등급(5~7) 구간에 높은 이상치가 다수 존재해 평균과 변동을 키우며, “높을수록 품질이 향상된다”라는 인상을 과장할 수 있다.
가설 4. 알코올 도수가 높을 수록 높은 품질 점수를 보일 것이다.
- 와인의 알코올 도수(alcohol)와 품질 점수(quality) 간의 관계를 확인하기 위해 산점도(Scatter plot)와 회귀선(Regression line)을 함께 시각화한다.
- 이를 통해 알코올 도수가 증가할수록 품질 점수가 상승하는 경향이 있는지 직관적으로 파악할 수 있다.
*회귀선: 점들의 분포를 종합해 전반적인 경향(패턴)을 나타냄
sns.scatterplot(x="alcohol", y="quality", data=wine, alpha=0.5)
plt.ylim(1, 9)
plt.show()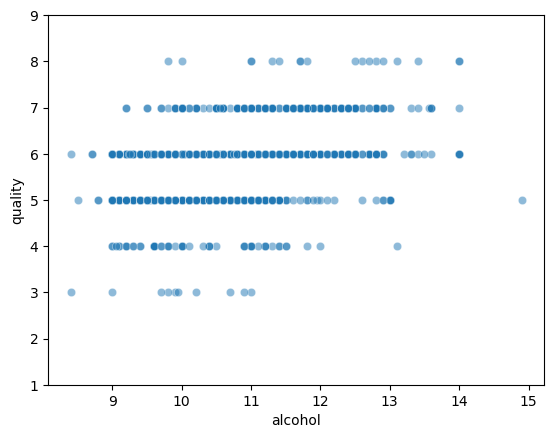
sns.regplot(x="alcohol", y="quality", data=wine, scatter_kws={"alpha":0.5})
plt.ylim(1, 9)
plt.title("Alcohol vs Wine Quality")
plt.show()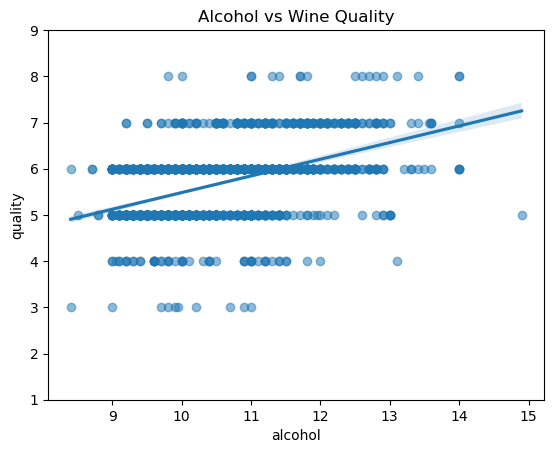
가설 4 평가.
- 점들이 넓게 퍼져 있어 예측 오차는 존재하지만, 전체적인 패턴은 상승 방향이다.
- 일부 저품질·고알코올, 고품질·저알코올 사례가 있어 알코올만으로 품질을 완전히 설명하기는 어렵다.
+α. 피어슨 상관 계수 확인
- 각 화학적 특성별 품질 점수와 상관 계수를 확인하여, 컬럼별로 상관 계수를 확인할 수 있다.
- 피어슨 상관 계수는 0에 가까울 수록 두 변수 간 연관성이 떨어지고, 1 또는 -1에 가까울 수록 연관성이 높다.
*차라리 피어슨 상관 계수를 가설 설정 전에 확인 했더라면, 높은 연관성을 띠는 변수에 대한 예측을 쉽게할 수 있었을 것으로 보인다...
wine_corr = wine.corr(method='pearson', numeric_only=True).round(2)
wine_corr| fixed acidity | volatile acidity | citric acid | residual sugar | chlorides | free sulfur dioxide | total sulfur dioxide | density | pH | sulphates | alcohol | quality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| fixed acidity | 1.00 | -0.26 | 0.67 | 0.11 | 0.09 | -0.15 | -0.11 | 0.67 | -0.68 | 0.18 | -0.06 | 0.12 |
| volatile acidity | -0.26 | 1.00 | -0.55 | 0.00 | 0.06 | -0.01 | 0.08 | 0.02 | 0.23 | -0.26 | -0.20 | -0.39 |
| citric acid | 0.67 | -0.55 | 1.00 | 0.14 | 0.20 | -0.06 | 0.04 | 0.36 | -0.54 | 0.31 | 0.11 | 0.23 |
| residual sugar | 0.11 | 0.00 | 0.14 | 1.00 | 0.06 | 0.19 | 0.20 | 0.36 | -0.09 | 0.01 | 0.04 | 0.01 |
| chlorides | 0.09 | 0.06 | 0.20 | 0.06 | 1.00 | 0.01 | 0.05 | 0.20 | -0.27 | 0.37 | -0.22 | -0.13 |
| free sulfur dioxide | -0.15 | -0.01 | -0.06 | 0.19 | 0.01 | 1.00 | 0.67 | -0.02 | 0.07 | 0.05 | -0.07 | -0.05 |
| total sulfur dioxide | -0.11 | 0.08 | 0.04 | 0.20 | 0.05 | 0.67 | 1.00 | 0.07 | -0.07 | 0.04 | -0.21 | -0.19 |
| density | 0.67 | 0.02 | 0.36 | 0.36 | 0.20 | -0.02 | 0.07 | 1.00 | -0.34 | 0.15 | -0.50 | -0.17 |
| pH | -0.68 | 0.23 | -0.54 | -0.09 | -0.27 | 0.07 | -0.07 | -0.34 | 1.00 | -0.20 | 0.21 | -0.06 |
| sulphates | 0.18 | -0.26 | 0.31 | 0.01 | 0.37 | 0.05 | 0.04 | 0.15 | -0.20 | 1.00 | 0.09 | 0.25 |
| alcohol | -0.06 | -0.20 | 0.11 | 0.04 | -0.22 | -0.07 | -0.21 | -0.50 | 0.21 | 0.09 | 1.00 | 0.48 |
| quality | 0.12 | -0.39 | 0.23 | 0.01 | -0.13 | -0.05 | -0.19 | -0.17 | -0.06 | 0.25 | 0.48 | 1.00 |
plt.figure(figsize=(9, 9))
sns.heatmap(wine_corr_2, annot=True, annot_kws={"size": 9}, square=True)
plt.tight_layout()
plt.show()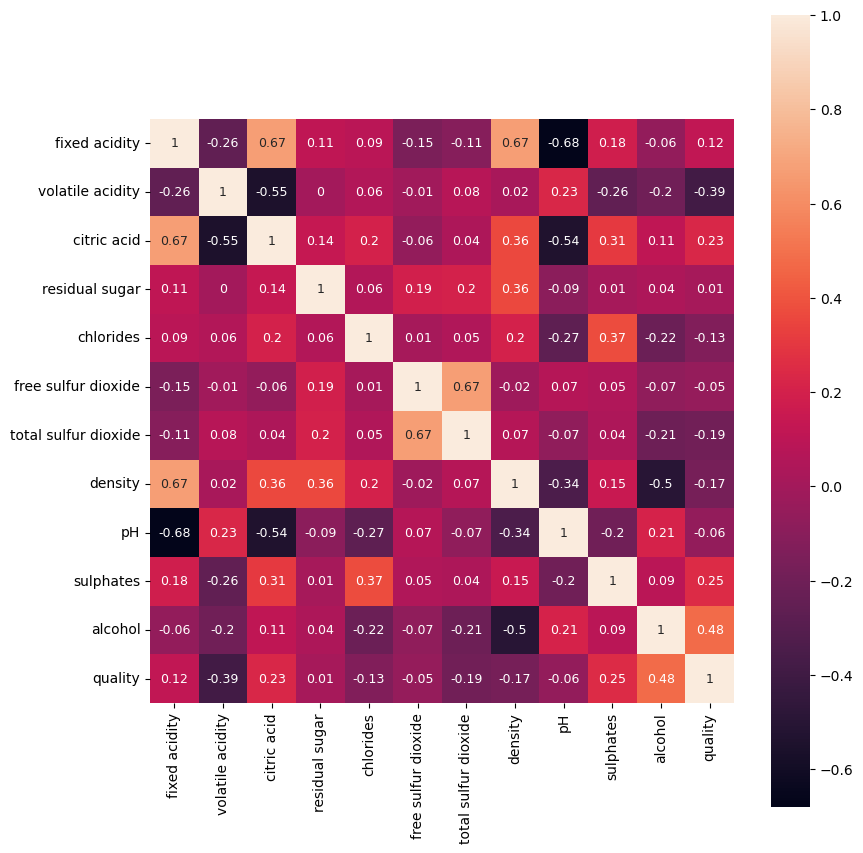
-
와인의 화학적 특성에 따른 품질 점수의 피어슨 상관계수를 히트맵으로 표현하였다.
*quality 와 나머지 변수 간 상관계수를 파악할 것이므로, 해당 히트맵에서는 가장 오른쪽 열의 수치만 확인하면 된다. -
그 결과, 양의 상관계수 중 알코올(alcohol)이 가장 높은 0.48을 보였고, 나머지 변수들은 대체로 약한 수준을 보였다.
-
음의 상관계수 중에서는 휘발성 산도(volatile acidity)가 -0.39 로 품질 점수와 보다 높은 상관관계를 나타냈다.
7. 결론
이번 Red Wine Quality 데이터셋 EDA를 통해 다음과 같은 인사이트를 얻을 수 있었다.
(1) 휘발성 산도(Volatile Acidity)
- 수치가 높을수록 와인 품질 점수가 낮아지는 경향을 확인.
- 피어슨 상관계수 -0.39로 품질과 부정적 상관을 나타냄.
- 가설 1과 일치하는 경향이 나타남.
(2) 구연산(Citric Acid)
- 0.6~0.8 범위에서 평균 품질 점수가 가장 높음.
- 특정 구간에서 품질이 높게 나타나, 풍미와 관련된 적정 구연산 함량이 존재함을 시사.
- 일부 구간에서 가설 2와 부합하는 결과를 확인하였음.
(3) 황산염(Sulphates)
- 박스 플롯 상에서는 품질별 변별력이 낮아 뚜렷한 패턴 확인 어려움.
- 이상치 존재로 평균 품질 점수 해석 시 주의 필요.
- 데이터 상 가설 3의 명확한 패턴은 확인되지 않음.
(4) 알코올(Alcohol)
- 알코올 도수가 높을수록 품질 점수가 상승하는 경향 관찰.
- 피어슨 상관계수 0.48로 가장 높은 양의 상관관계 확인.
- 분석 결과 가설 4와 일관된 경향이 나타남.
(5) 종합 평가
- 와인 품질 점수에 가장 큰 영향을 미치는 변수는 알코올과 휘발성 산도임을 확인하였음.
- 다른 화학적 특성들은 상대적으로 영향력이 낮거나 변동성이 커, 단독으로 품질을 설명하기에는 한계가 있음.
- EDA 과정에서 데이터의 분포, 이상치, 구간화, 시각화를 활용해 변수 간 관계를 직관적으로 파악할 수 있었음.
마무리
이번 실습을 통해, EDA는 단순 코딩보다 데이터의 특성을 이해하고 인사이트를 도출하는 사고 과정이 중요함을 다시 한번 확인할 수 있었다.
특히, 시각화를 통해 변수 간 상관 관계를 한눈에 파악할 수 있었고, 가설 검증 과정에서 의미 있는 결론을 도출할 수 있었다.
다만, 해당 EDA는 전문성(사전 지식) 없이 예측한 데이터 셋이므로 가설을 설정함에 있어서 다소 설득력이 떨어질 우려가 있다. 이처럼 데이터 분석은 코딩 지식을 떠나 데이터셋에 대한 도메인 지식이나 흥미가 있어야 분석에 더 유리할 것으로 판단된다.
또한, EDA 연습용 데이터셋이 아닌 실제 상황에서 이를 어떻게 활용할 것인지 고민해보게 된다.
실제 데이터를 통해 어떠한 인사이트를 얻고자 하는가, 어떠한 사업적/실무적 이득을 얻고자하는가에 대한 방향성에 따라서 무엇을 분석할지가 결정될 것이다.
이러한 관점에서, 실무에서는 '어떤 데이터 셋을 분석할 것인가?'가 중요한 질문이 될 것이라 생각한다.
