
점점 문제가 어려워져서 데이터리안 실전반 강의를 다시 듣고 돌아왔습니다!!!
그랬더니 바로 이 문제에서 사용했지요 😃
답 쿼리입니다.
WITH T AS (
SELECT ID
, RANK() OVER (ORDER BY SIZE_OF_COLONY DESC) rk
, COUNT(*) OVER () total
FROM ECOLI_DATA
)
SELECT ID
, CASE WHEN rk <= total * (1/4) THEN 'CRITICAL'
WHEN rk <= total * (2/4) THEN 'HIGH'
WHEN rk <= total * (3/4) THEN 'MEDIUM'
ELSE 'LOW' END COLONY_NAME
FROM T
ORDER BY IDRANK, DENSE_RANK 중에 어떤 함수를 써야하는지 고민이 필요했던 문제였습니다.
그리고 다른 분들의 답안을 보니까 PERCENT_RANK() 라는 함수가 존재했습니다..
WITH RANK_DATA AS (
SELECT
ID
, PERCENT_RANK() OVER(ORDER BY SIZE_OF_COLONY DESC) SIZE_RANK
FROM
ECOLI_DATA
)
SELECT
ID
, CASE
WHEN SIZE_RANK <= 0.25 THEN 'CRITICAL'
WHEN SIZE_RANK <= 0.50 THEN 'HIGH'
WHEN SIZE_RANK <= 0.75 THEN 'MEDIUM'
ELSE 'LOW'
END COLONY_NAME
FROM
RANK_DATA
ORDER BY
ID이렇게 작성하셔서 GPT에서 도움 요청!!!
PERCENT_RANK() 함수에 대해 알려줘~
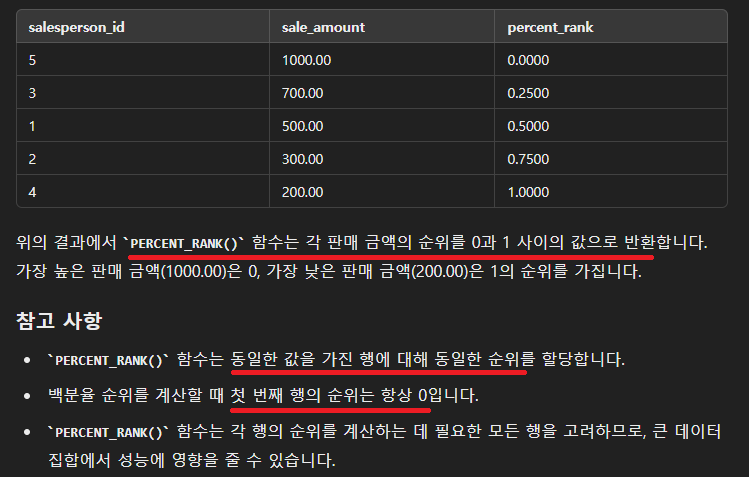
이번 문제가 동일한 값을 가진 행에 같은 순위값을 주어야하는게 포인트였는데
PERCENT_RANK() 함수가 이것까지 고려해주네요... 스고이 👍

SQL 끄적끄적