[논문 리뷰] coIOMMU: A Virtual IOMMU with Cooperative DMA Buffer Tracking for Efficient Memory Management in Direct I/O (USENIX ATC'20)
Paper Review
목록 보기
1/1
문제
- Direct I/O 기술을 사용하면 가상머신에서도 장치를 native 환경과 똑같은 성능으로 사용할 수 있다.
- 하지만 대부분의 장치가 DMA fault를 허용하지 않기 때문에, Direct I/O 기술을 사용하기 위해서는 가상머신의 전체 메모리 공간을 호스트의 물리 메모리에 pinning 해야한다.
- 즉, 가상머신의 장점 중 하나인 memory overcommitment를 활용할 수 없게된다.
- 이를 해결하기 위해, vIOMMU라는 기술이 등장했다.
- 그러나 vIOMMU는 IOMMU의 기능을 emulation하는 비용때문에, 성능에 악영향을 준다.
- 이 때문에 상용 클라우드 환경에서 대부분은 이 기능을 사용하지 않는다.
- 즉, memory overcommitment를 활용할 수 있도록 fine-grain하게 가상머신의 메모리를 pinning하면서도, 성능에 악영향을 주지 않는 기술이 필요하며, 본 논문에서 그 방법을 제안한다.
배경 지식
- Direct I/O
- 이것은 성능이 매우 좋은 I/O 가상화 기술로, Guest OS와 I/O device가 서로 직접 통신할 수 있도록 하는 기술이다.
- 네트워크 카드 (NIC)를 예로 들어보자.
- 기존에는 패킷을 받기 위해 호스트의 드라이버가 먼저 장치와 소통한 후, 이를 다시 가상머신에게 전달하는 방식이었다.
- 그러나 Direct I/O를 사용하면 가상머신의 드라이버가 직접 NIC와 소통하여 패킷을 처리하게 된다.
- 중간에 호스트가 가상머신에게 데이터를 전달해주는 과정이 생략될 수 있기 때문에, 현재 I/O 가상화 기술 중에서 제일 성능이 좋다고 할 수 있다.
- 이 기술은 SR-IOV (Single-Root I/O Virtualization) 기술의 등장으로 널리 사용되게 되었다.
- SR-IOV는 장치 하나를 여러개처럼 보일 수 있도록 만들어주는 기술이고, device-side virtualization 기술이라고도 부른다.
- 장치 하나로 여러 개의 가상머신에게 Direct I/O를 사용할 수 있도록 하기 때문에, Direct I/O 기술의 상용화에 필수적인 요소라고 할 수 있다.
- IOMMU
- 장치가 임의의 메모리 주소에 접근하지 못하도록 하기위해 등장한 기술이다.
- IOMMU가 있으면, 장치도 자신만의 가상 주소 공간을 가지게 된다.
- 이는 보통 DVA (Device Virtual Address)라고 한다.
- IOMMU는 IOMMU page table (IOPT)에 DVA to DPA (Device Physical Address) 매핑을 관리한다.
- 그러므로, 만약 매핑이 없는 경우, CPU에서와 마찬가지로 page fault가 발생할 수 있으며, 이를 DMA fault라고 한다.
- 하지만 대부분의 장치는 DMA fault를 지원하지 않는다.
- 그러므로, 장치가 접근할 수 있는 메모리는 메인 메모리에 pinning 되어야 한다.
- 이때, 가상 머신의 어떤 메모리가 장치를 위한 것인 지는 호스트가 알 수 없다.
- 그러므로, 가상 머신의 전체 메모리를 메인 메모리에 pinning 해야 하는 것이다.
해결 방법
전체 메모리를 pinning하지 않기 위해서는, 어떤 메모리가 장치의 메모리(이를 보통 DMA 영역이라고 함)인지를 알아야 한다. 이 논문에서는 성능 오버헤드를 최소화하면서 가상머신의 어떤 영역이 DMA 영역인 지를 알아내는 방법을 제안한다.
- coIOMMU 기술
- shared memory 인터페이스를 사용하여 Host와 Guest가 서로 통신할 수 있도록 한다.
- shared memory에는 DMA tracking table (DTT)을 저장한다.
- DTT의 정보를 Host가 읽고, 이를 이용해서 필요한 부분만 pinning을 한다.
- coIOMMU 아키텍처
- 아래 그림에 coIOMMU의 아키텍처가 나와있다.
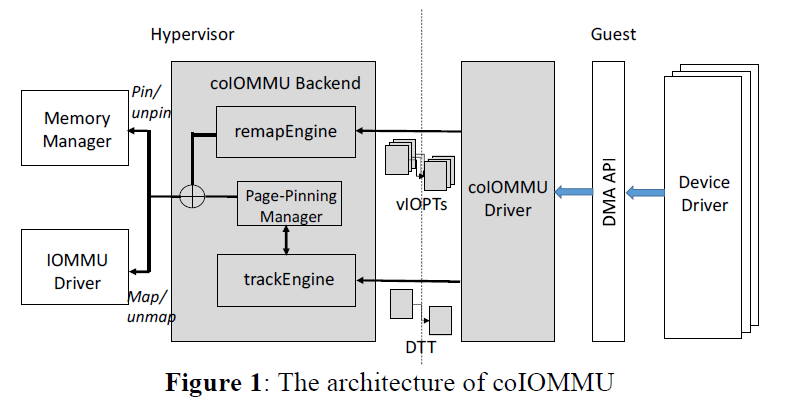
- 우선 remapEngine도 지원하여 사용자가 기존 vIOMMU를 사용할 지, coIOMMU의 DTT를 활용할 지, 아니면 둘 다 사용할 지를 선택할 수 있게 해준다.
- Guest OS의 수정을 최소화하기 위해 DMA API는 건들지 않고, 장치 드라이버 형태로 guest OS를 수정하였다.
- coIOMMU Driver는 DMA engine을 등록하여 DMA mapping관련 정보를 인터셉트하며, 이를 통해 얻은 정보를 DTT에 기록한다.
- trackEngine은 DTT에 직접 접근하여 관련 정보를 해독하며, 이를 다른 모듈에서 사용하기 쉽도록하는 자신만의 api를 제공한다. 이러한 디자인은 추후에 page pinning 목적이 아닌 다른 목적으로 DTT를 사용하기 쉽도록 하기 위해 선택되었다.
- Page-pinning Manager (pManager)는 trackEngine으로부터 DTT 관련 정보를 얻어 fine-grained pinning을 어떤 방식으로 수행할 지를 결정한다.
- 아래 그림에 coIOMMU의 아키텍처가 나와있다.
- DTT 구조
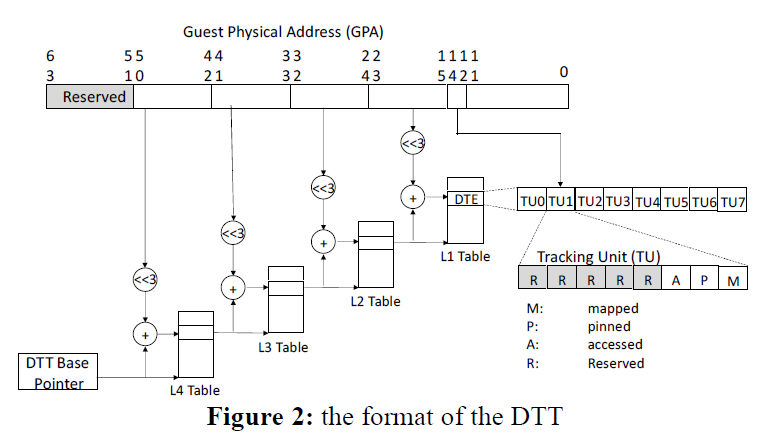
- DTT는 4-레벨 페이지 테이블처럼 구성된다. 이 때 다른점은 L1 Table의 엔트리가 페이지 주소를 가르키는 것이 아니라 8개의 페이지의 8비트짜리 Tracking Unit(TU)를 저장한다는 것이다.
- 즉, 48비트가 테이블 워킹에 쓰이는 것이 아닌, TU를 구분하기 위한 추가 3비트까지 총 51비트가 워킹에 사용된다.
- TU의 5비트는 추후 기능 확장에 사용하기위해 예약되어 있으며, 지금은 3개의 비트만 사용한다.
- M (mapped): guest에 의해서만 수정될 수 있는 비트로, 해당 페이지가 DMA 영역인 지를 나타낸다.
- P (pinned): Host만 수정할 수 있는 비트로, 해당 페이지가 pinning 되어 있는 지를 나타낸다.
- A (accessed): DMA로 사용된 적이 있었는 지를 나타낸다. guest가 M 비트를 set할 때 같이 set되며, Host가 추후에 설명할 lazy unpinning 정책을 수행할 때 clean한다.
- DTT는 4-레벨 페이지 테이블처럼 구성된다. 이 때 다른점은 L1 Table의 엔트리가 페이지 주소를 가르키는 것이 아니라 8개의 페이지의 8비트짜리 Tracking Unit(TU)를 저장한다는 것이다.
- Fine-grained Pinning 정책
- coIOMMU는 fine-grained pinning 정책으로 Smart-Pinning과 Lazy-Unpinning, 두 가지를 제안한다.
- Smart-Pinning
- guest page의 pinning을 세 가지 방식으로 수행한다.
1) instantly pinning: guest가 DMA mapping을 수행할 때 즉시 pinning을 수행한다. 이는 호스트를 바로 호출해야하므로 오버헤드가 들어간다.
2) precise notification: 위에서 호스트를 호출해야 한다고 했는데, 이러한 동작을 notification이라고 한다. DTT를 통해 guest는 어떤 페이지가 이미 pinning되어 있는 지를 알 수 있고, 따라서 pinning이 되어있지 않은 페이지만 notification을 수행함으로써 이로인한 성능 오버헤드를 최소화한다.
3) speculatively pinning: DTT의 A bit를 주기적으로 scan 및 clear하면서 페이지마다 얼마나 자주 DMA에 사용되는 지를 파악한 후, 자주 사용되는 페이지들은 guest가 말하지 않아도 host가 직접 pinning을 결정한다. - 2, 3 방법을 통해 notification으로 인한 오버헤드를 99.9992% 줄였다고 한다.
- guest page의 pinning을 세 가지 방식으로 수행한다.
- Lazy Unpinning
- 백그라운드에서 DTT를 scan하면서 M 비트는 0이지만 P 비트가 1인 페이지를 찾고, 이들을 모아서 batch 방식으로 unpinning을 수행한다.
- speculatiely pinning에서 A bit를 스캔하는 과정에서 Lazy unpinning도 같이 수행한다.
- unpinned page는 물리 메모리에서 회수되어 free 페이지를 늘리고, memory overcommitment 효율을 증가시킨다.
구현 방법 및 성능 평가
- 아직 이 부분에 대해서는 관심이 없어 정리하지 않음. 추후에 읽게되면 추가 예정.

리눅스 커널 개발자를 꿈꾸는 대학원생