Chapter 2. Describing Physical Memory

이 글은 Gorman 책 "Understanding the Linux Virtual Memory Manager"의 Chapter 2를 번역한 글입니다.
수많은 아키텍처들이 리눅스를 사용하기 때문에, 메모리를 특정 아키텍처와 상관없이 독립적으로 설명할 수 있는 방법이 필요하다. 이 장에서는 메모리 뱅크, 페이지 및 VM(Virtual Memory) 동작에 영향을 미치는 플래그를 설명하는 데 사용되는 구조체에 대해 설명한다.
VM에서 첫 주요 개념은 Non-Uniform Memory Access(NUMA)이다. 큰 스케일의 머신의 경우, 프로세서로부터의 '거리'에 따라 접근 비용이 다른 여러 메모리 뱅크로 구성될 수 있다. 예를 들어, 각 CPU에 할당된 메모리 뱅크가 있거나, Device에 가까워서 DMA(Direct Memory Access)를 하기에 매우 적합한 메모리 뱅크가 있을 수 있다.
각 뱅크는 노드(node)라고 불리며, 이 개념은 아키텍처가 UMA인 경우에도 리눅스에서는 struct pglist_data 를 통해 표현된다. 이 구조체는 항상 이것의 typedef인 pg_data_t 로 참조된다. 시스템의 모든 노드는 pgdat_list라고 하는 NULL로 종료되는 리스트에 보관되며, 각 노드는 pg_data_t→node_next 필드를 통해 다음 노드와 연결된다. PC 데스크톱과 같은 UMA 아키텍처의 경우, contig_page_data 라고 하는 단일 정적 pg_data_t 구조체만 사용된다. 노드에 대한 논의는 2.1절에서 더 자세히 다룰 예정이다.
각 노드는 메모리 내 범위를 나타내는 '존(zone)'이라고 불리는 여러 블록으로 나뉜다. 존은 존 기반 할당자와 혼동되어서는 안 되며, 이들은 서로 관련이 없다. 존은 struct zone_struct로 설명되고, zone_t로 typedef되며, ZONE_DMA, ZONE_NORMAL, 그리고 ZONE_HIGHMEM 타입으로 구성된다. 각 존 타입은 다른 유형의 사용에 적합하다. ZONE_DMA는 특정 ISA 장치가 필요로 하는 하위 물리 메모리 범위 내의 메모리이다. ZONE_NORMAL 내의 메모리는 커널에 의해 선형 주소 공간의 상위 영역으로 직접 매핑되며, 이는 4.1절에서 더 자세히 논의된다. ZONE_HIGHMEM은 시스템의 나머지 메모리로, 커널에 의해 직접 매핑되지 않는다.
x86에서의 존의 모습은 아래와 같다:
- ZONE_DMA: 메모리의 첫 16MiB
- ZONE_NORMAL: 16MiB - 896MiB
- ZONE_HIGHMEM: 896MiB - 끝
중요한 사실은 많은 커널 동작들이 ZONE_NORMAL만을 사용할 수 있기 때문에, 이것이 가장 성능에 중요한 존이라는 것이다. 존은 2.2절에서 더 자세히 논의된다. 각 물리 페이지 프레임은 struct page로 표현되며, 모든 페이지 구조체들은 전역 mem_map 배열로 관리된다. mem_map 배열은 보통 ZONE_NORMAL의 시작 부분에 저장되거나 메모리가 작은 머신에서는 커널 이미지를 위해 예약된 메모리 바로 다음 부분에 저장된다. struct page, mem_map 배열은 각각 2.4, 3.7절에서 보다 구체적으로 논의된다. 이 모든 구조체들의 관계가 Figure 2.1에 나타나있다.

커널에 의해 직접 접근될 수 있는 메모리(ZONE_NORMAL)의 양이 제한적이기 때문에, 리눅스는 2.5절에서 더 자세히 논의될 High Memory 라는 개념을 지원한다. 이 장은 노드, 존, 그리고 페이지가 어떻게 표현되는 지 논의하고, 그 다음으로 high memory 관리에 대해 소개할 것이다.
2.1 노드
위에서도 언급했듯이, 메모리의 각 노드는 struct pglist_data의 typedef인 pg_data_t로 표현된다. 페이지를 할당할 때, 리눅스는 프로세스가 돌고 있는 CPU에서 가장 가까운 노드로부터 메모리를 할당하기 위해 node-local allocation policy 를 사용한다. 프로세스들은 같은 CPU에서 돌고자 하는 경향이 있으므로, 현재 노드의 메모리가 사용될 확률이 높다. 구조체는 다음과 같이 <linux/mmzone.h>에 선언된다:
129 typedef struct pglist_data {
130 zone_t node_zones[MAX_NR_ZONES];
131 zonelist_t node_zonelists[GFP_ZONEMASK+1];
132 int nr_zones;
133 struct page *node_mem_map;
134 unsigned long *valid_addr_bitmap;
135 struct bootmem_data *bdata;
136 unsigned long node_start_paddr;
137 unsigned long node_start_mapnr;
138 unsigned long node_size;
139 int node_id;
140 struct pglist_data *node_next;
141 } pg_data_t; 각 필드에 대한 간단한 설명은 아래와 같다:
- node_zones: 이 노드의 존들, ZONE_HIGHMEM, ZONE_NORMAL, ZONE_DMA.
- node_zonelists: 할당이 선호되는 존의 순서. free_area_init_core()가 호출하는 build_zonelists() 함수에서 순서를 세팅함. ZONE_HIGHMEM에서 실패한 할당 시도는 ZONE_NORMAL 또는 ZONE_DMA로 폴백(fall back)함.
- nr_zones: 이 노드의 존의 개수 (1에서 3사이). 모든 노드가 3개를 가지는 것은 아님. 예를 들어 CPU bank는 ZONE_DMA를 가지지 않을 수 있음.
- node_mem_map: 노드의 각 물리 프레임을 나타내는 struct page 배열의 첫번째 페이지임. 전역 mem_map 배열의 어딘가에 위치해 있을 것임.
- valid_addr_bitmap: 실제 메모리가 존재하지 않는 메모리 노드의 "holes"를 표시하는 비트맵. Sparc과 Sparc64 아키텍처에서만 쓰임.
- bdata: 5장에서 논의될 boot memory allocator에서만 사용함.
- node_start_paddr: 노드의 시작 물리 주소. unsigned long은 PAE(Physical Address Extension)가 있는 ia32에서 문제를 일으키기 때문에 제대로 작동하지 않음. PAE는 2.5절에서 다뤄질 것임. 더 적절한 해결방법은 PFN(Page Frame Number)로 이를 기록하는 것임. PFN는 단순히 페이지 크기 기준으로 물리 메모리를 나눴을 때의 인덱스를 나타냄. 물리 메모리의 PFN은 단순히 (page_phys_addr >> PAGE_SHIFT)로 정의할 수 있음.
- node_start_mapnr: 전역 mem_map 배열에서의 page offset을 나타냄. 이 값은 free_area_init_core()에서 계산하며, mem_map과 lmem_map이라고 불리는 local mem_map사이의 페이지 개수를 셈으로써 계산함.
- node_size: 노드에 존재하는 전체 페이지 수.
- node_id: 노드의 식별 번호. 줄여서 NID라고 하며, 0부터 시작함.
- node_next: 다음 노드에 대한 포인터. 다음 노드가 없을 경우 NULL.
시스템의 모든 노드들은 pgdat_list라고 불리는 리스트로 관리된다. 노드들은 init_bootmem_core() 함수에 의해 초기화될 때 pgdat_list에 삽입되며, 자세한건 5.2.1절에서 다룰 것이다. 2.4.18 버전 이전의 커널에서는, pgdat_list를 순회하는 코드는 다음과 같이 짜여진다:
pg_data_t * pgdat;
pgdat = pgdat_list;
do {
/* do something with pgdata_t */
...
} while ((pgdat = pgdat->node_next));더 최근의 커널에서는, for loop처럼 사용할 수 있는 for_each_pgdat()이라는 매크로가 제공되어 코드의 가독성을 높인다.
2.2 Zones
존은 struct zone_struct로 기술되며 대개 이것의 typedef인 zone_t로 참조된다. 이것은 페이지 사용 통계치, free 영역 정보, 그리고 락들에 대한 정보를 유지한다. 이것은 <linux/mmzone.h>에 아래와 같이 선언되어 있다:
37 typedef struct zone_struct {
41 spinlock_t lock;
42 unsigned long free_pages;
43 unsigned long pages_min, pages_low, pages_high;
44 int need_balance;
45
49 free_area_t free_area[MAX_ORDER];
50
76 wait_queue_head_t * wait_table;
77 unsigned long wait_table_size;
78 unsigned long wait_table_shift;
79
83 struct pglist_data *zone_pgdat;
84 struct page *zone_mem_map;
85 unsigned long zone_start_paddr;
86 unsigned long zone_start_mapnr;
87
91 char *name;
92 unsigned long size;
93 } zone_t;각 필드에 대한 간단한 설명은 아래와 같다:
- lock: 존에 대한 동시 접근을 보호하기위한 spinlock.
- free_pages: 존의 free page 개수.
- pages_min, pages_low, pages_high: 다음 절에서 설명될 존 워터마크 값
- need_balance: kswapd에게 존을 balance하라고 말해주는 flag. 존의 free page 개수가 존 워터마크 값 중 하나에 닿을 경우, balance가 필요하다고 얘기함. 워터마크는 다음 절에서 다룸.
- free_area: 버디할당자가 사용하는 free area 비트맵.
- wait_table: 페이지가 해제될 때까지 대기하는 프로세스들의 대기 큐의 해시 테이블임. 이는 wait_on_page()와 unlock_page()에 중요함. 모든 프로세스가 하나의 큐에서 대기할 수는 있지만, 이렇게 하면 깨어난 후에도 여전히 잠긴 페이지를 두고 모든 대기 프로세스가 경쟁을 벌이게 됨. 이렇게 공유 자원을 두고 많은 프로세스가 경쟁하는 상황을 때때로 'thundering herd'라고 함. wait table은 2.2.3절에서 다룸.
- wait_table_size: 2의 거듭제곱인 해시 테이블의 큐 수.
- wait_table_shift: long의 비트 수에서 wait_table_size에 대한 이진 로그를 뺀 값으로 정의됨.
- zone_pgdat: 부모 pg_data_t를 가리키는 포인터.
- zone_mem_map: 이 존이 참조하는 global mem_map의 첫번째 페이지.
- zone_start_paddr: node_start_paddr과 같은 원리임.
- zone_start_mapnr: node_start_mapnr과 같은 원리임.
- name: 존의 string형의 이름, "DMA", "Normal", 또는 "HighMem"
- size: 존의 페이지 수.
2.2.1 Zone Watermarks
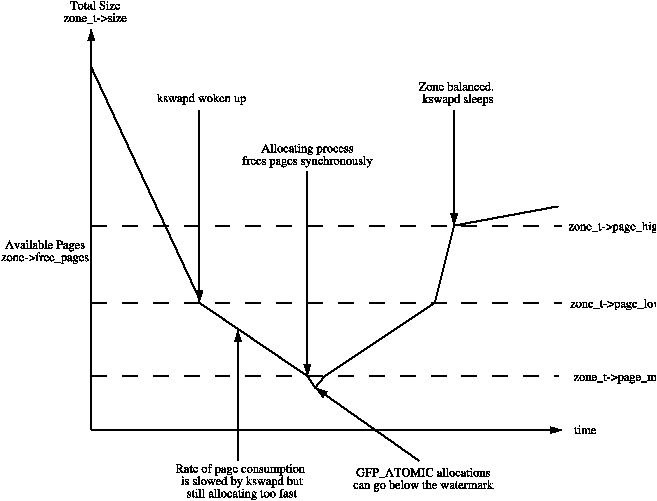
시스템의 사용가능한 메모리가 적은 경우, pageout 데몬인 kswapd가 깨어나서 페이지를 해제하기 시작한다 (10장 참조). 만약 메모리 압력이 높다면, 프로세스가 직접 동기적으로 메모리를 해제하는데, 이 과정을 direct-reclaim path라고 부른다. pageout 동작에 영향을 주는 인자값은 FreeBSD와 Solaris의 그것과 비슷하다.
각 존은 해당 존이 얼마나 큰 메모리 압력을 받고있는 지를 판단하는 데 도움을 주는 pages_low, pages_min, 그리고 pages_high, 총 3개의 워터마크를 가진다. 이들 사이의 관계는 Figure 2.2에 나타나있다. pages_min의 크기는 메모리 초기화 과정에서 free_area_init_core() 함수가 존의 페이지 수에 대한 일정 비율로 계산한다. 초기에는 ZoneSizePages / 128로 계산된다. 가장 낮은 값은 20 페이지(x86의 경우 80K)이고 가능한 가장 높은 값은 255 페이지(x86의 경우 1M)이다.
-
pages_low: free 페이지가 pages_low에 도달하면, 버디 할당자에 의해 kswapd가 깨어나 페이지를 해제한다. 이는 Solaris에서 lotsfree에 도달하거나, FreeBSD에서 freemin에 도달한 것과 동일하다. 기본값은 pages_min의 2배로 설정된다.
-
pages_min: pages_min에 도달한 경우, 할당자는 kswapd가 하는 일을 동기적으로 할 것이며, 이는 direct-reclaim path라고 불린다. Solaris에는 완전 동일한 개념은 없지만 pageout scanner가 얼마나 자주 깨어날 지를 결정하는 desfree 또는 minfree와 가장 유사하다.
-
pages_high: kswapd는 한번 깨어나면 free 페이지의 수가 pages_high에 도달하기 전까지는 존이 "balanced" 됬다고 판단하지 않는다. free 페이지의 수가 pages_high에 도달한 이후에 kswapd는 다시 sleep 상태가 된다. Solaris와 FreeBSD에서 이 값은 각각 lotsfree와 free_target이라고 불린다. 기본값은 pages_min의 3배로 설정된다.
각 운영체제에서 pageout 인자값들이 어떻게 불리는 지와 상관없이, 그 의미는 같다. 이것은 pageout 데몬 또는 프로세스가 얼마나 열심히 페이지를 해제할 것인지를 결정하는 데 도움을 준다.
2.2.2 Calculating The Size of Zones

PFN은 physical memory map에서 page 기준으로 셌을 때의 offset이다. 시스템이 사용할 수 있는 첫번째 PFN은 min_low_pfn으로, 로드된 커널 이미지의 마지막 pfn인 _end 뒤에 위치한 첫 페이지의 PFN과 같다. 그 값은 boot memory allocator가 사용할 수 있도록 mm/bootmem.c에 file scope 변수로 저장되어있다.
시스템의 마지막 page frame의 PFN인 max_pfn 값이 계산되는 방법은 아키텍처에 의존적이다. x86의 경우, find_max_pfn()이 e820 map을 통해 마지막 page fram을 찾는다. 그 값은 또한 mm/bootmem.c에 file scope 변수로 저장된다. e820은 BIOS가 제공하는 테이블로, 어떤 물리 메모리가 이용가능한 지, 예약되어있는 지, 또는 존재하지 않는 지를 알려준다.
x86에서 max_low_pfn의 값은 find_max_low_pfn() 함수를 통해 계산되며, 이는 ZONE_NORMAL의 끝을 의미한다. 이 것은 커널이 직접 접근 가능한 물리 메모리이며, PAGE_OFFSET으로 표시되는 linear address space에서의 kernel/userspace의 분리와 관련이 있다. 다른 값들과 마찬가지로 이 값 또한 mm/bootmem.c에 저장된다. 메모리가 작은 머신에서는 max_pfn이 max_low_pfn과 같을 수 있음에 유의하라.
min_low_pfn, max_low_pfn, 그리고 max_pfn, 이 세가지 변수를 통해 high memory의 시작과 끝은 쉽게 계산할 수 있으며, 이 값은 highstart_pfn과 highend_pfn으로 arch/i386/mm/init.c에 file scope 변수로 저장되어있다. 이 값들은 추후에 물리 메모리 할당자를 위해 high memory page를 초기화하는데에 사용되며, 자세한건 5.5절에서 다루게될 것이다.
2.2.3 Zone Wait Queue Table
page에 대한 IO가 수행되고 있는 경우, 예를 들어 page-in 또는 page-out이 발생하면, 일관적이지 못한 데이터에 대한 접근을 막기 위해 해당 page는 락이 걸린다. 해당 page에 접근하려는 프로세스들은 접근하기 전에 우선 wait_on_page()를 호출하여 wait queue에서 대기해야한다. IO가 완료되고나면, page는 UnlockPage()를 통해 락이 해제될 것이고 queue에서 대기중인 모든 프로세스가 깨어날 것이다. 각 page가 wait queue를 가지도록 구현할 수도 있지만, 이는 너무나 많은 별도의 queue를 저장해야하므로 메모리 관점에서 굉장히 비싸다. 그래서 그 대신에 wait queue는 zone_t에 구현된다.
zone에 단 하나의 wait queue만을 구현하는 방식도 가능하겠지만, 이는 zone의 아무 page에 대해 기다리고 있던 모든 프로세스들이 어떤 한 page가 unlock될 때 깨어난다는 것을 의미한다. 즉, 이는 심각한 'thundering herd' 문제를 야기한다. 이렇게 구현하는 대신, wait queue들의 해시테이블이 zone_t->wait_table에 저장된다. 해시 충돌이 발생하면 프로세스들이 여전히 불필요하게 깨어나게 되겠지만, 충돌은 그렇게 자주 발생하지는 않는다.
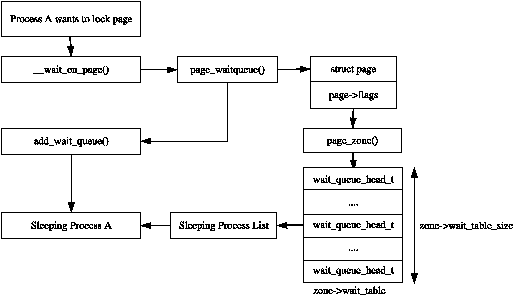
wait table은 free_area_init_core() 함수에서 할당된다. table의 크기는 wait_table_size()에서 계산되며, zone_t->wait_table_size에 저장된다. 최대 크기는 4096개의 wait queue이다. 더 작은 테이블의 경우, 테이블의 크기는 NoPages / PAGES_PER_WAITQUEUE 개의 큐를 저장할 수 있도록하는 2의 거듭제곱 중 최솟값이다 (NoPages: 존의 페이지 개수, PAGES_PER_WAITQUEUE: 256으로 정의된 상수). 즉, 테이블의 크기는 아래의 수식의 정수 부분으로 계산된다:
wait_table_size = log2((NoPages * 2) / PAGES_PER_WAITQUEUE - 1)zone_t->wait_table_shift는 table의 인덱스로 쓰이기 위해 page address가 right shift되어야하는 비트 수이다. page_waitqueue() 함수는 존의 페이지가 어떤 wait queue를 사용해야하는 지를 계산한다. 이 함수는 페이지의 가상 주소를 기반으로 간단한 multiplicative 해싱 알고리즘을 사용한다.
이것은 단순히 GOLDEN_RATIO_PRIME 상수값만큼 가상 주소에 곱하고 그 결과를 zone_t->wait_table_shift 비트 수만큼 오른쪽으로 shift하여 해시 table의 인덱스를 계산한다. GOLDEN_RATIO_PRIME은 아키텍처가 표현할 수 있는 가장 큰 정수의 황금비에 가장 가까운 가장 큰 소수이다.
2.3 Zone Initialisation
존은 커널 페이지 테이블이 paging_init()을 통해 완전히 초기화된 이후에 초기화된다. 페이지 테이블 초기화 과정은 3.6절에서 다룬다. 당연하게도, 각 아키텍처별로 이 작업을 수행하는 과정이 서로 다르지만, 목적은 UMA의 경우 free_area_init()에, NUMA의 경우 free_area_init_node()에 어떤 인자값을 전달할 지 결정하는 것으로 항상 같다. UMA의 경우 인자로 zones_size 하나만 필요하다. 전체 인자는 아래와 같다:
- nid: 존들을 초기화할 노드의 ID값.
- pgdat: 노드의 pg_data_t. UMA에서는 항상 contig_page_data임.
- pmap: free_area_init_core()에 의해 초기화되며, 해당 노드의 lmem_map 배열의 시작부분을 가리킴. NUMA에서는 mem_map을 PAGE_OFFSET에서 시작하는 가상 배열로 다루기 때문에 이 변수는 무시됨. UMA에서는 이 포인터는 global mem_map 변수를 가리킴.
- zones_sizes: 노드에 속한 각 존들의 페이지 수를 저장하고 있는 배열.
- zone_start_paddr: 첫번째 존의 시작 물리 주소.
- zone_holes: 각 존들의 memory holes 총 크기를 저장하고 있는 배열.
핵심 함수는 free_area_init_core()로, zone_t를 관련된 정보로 채워넣고 노드의 mem_map 배열을 할당할 책임이 있다. 존들의 어떤 페이지들이 free한 지는 이 시점에 결정되지 않음에 유의하라. 이 정보는 boot memory allocator가 할일을 끝마치기 전까지는 알 수 없으며, 이는 5장에서 논의된다.
2.3.1 Initialising mem_map
mem_map 영역은 시스템 시작 과정동안 둘 중에 하나의 방식으로 형성된다. NUMA 시스템에서는, global mem_map은 PAGE_OFFSET에서 시작하는 가상 배열로 다루어진다. free_area_init_node()는 각 active 노드에 대해 호출되어, 노드에 해당하는 mem_map의 일부분을 할당한다. UMA 시스템에서는, free_area_init()이 contig_page_data를 노드로 사용하고 global mem_map을 이 노드의 "local" mem_map으로 사용한다. 각 함수의 call graph는 Figure 2.5에 나타나있다.

핵심 함수인 free_area_init_core()는 초기화되고있는 노드의 local lmem_map을 할당한다. 배열의 메모리는 boot memory allocator의 alloc_bootmem_node() 함수를 통해 할당된다 (5장 참조). UMA의 경우 새로 할당된 이 메모리가 global mem_map이 되지만, NUMA는 이와 약간 다른 점이 존재한다.
NUMA 아키텍처는 해당 노드의 메모리에 lmem_map을 위한 메모리를 할당한다. global mem_map은 절대 명시적으로 할당되지 않으며, 대신 PAGE_OFFSET에 설정되어 가상 배열로 다루어진다. local map의 주소는 pg_data_t->node_mem_map에 저장되며, 동시에 가상배열인 mem_map의 어딘가에 존재한다. 노드에 존재하는 각 존의 zone_t->zone_mem_map에는 가상 배열 mem_map에서 존에 해당하는 주소가 저장된다. 이후의 다른 모든 코드에서는 mem_map을 실제 배열처럼 접근하는데, 이는 각 노드가 실제로 유효한 영역만 접근할 것이기 때문이다.
2.4 Pages
시스템의 모든 물리 페이지 프레임은 상태를 추적하기 위해 사용되는 자신만의 struct page를 가지고 있다. 2.2버전의 커널에서는, 이 구조체가 System V의 그것과 유사했지만 다른 UNIX variants와 마찬가지로 상당히 변화했다. 이것은 <linux/mm.h>에 다음과 같이 선언되어있다:
152 typedef struct page {
153 struct list_head list;
154 struct address_space *mapping;
155 unsigned long index;
156 struct page *next_hash;
158 atomic_t count;
159 unsigned long flags;
161 struct list_head lru;
163 struct page **pprev_hash;
164 struct buffer_head * buffers;
175
176 #if defined(CONFIG_HIGHMEM) || defined(WANT_PAGE_VIRTUAL)
177 void *virtual;
179 #endif /* CONFIG_HIGMEM || WANT_PAGE_VIRTUAL */
180 } mem_map_t;각 변수에 대한 간략한 설명이다:
- list: 페이지들은 많은 리스트들에 속할 것이고 이 변수는 list head로 사용된다. 예를 들어, 매핑이 있는 페이지들은 address_space에 의해 유지되는 3개의 circular linked list주에 하나에 속할 것이다. 3개의 리스트는 각각 clean_pages, dirty_pages, 그리고 locked_pages이다. slab allocator에서 이 필드는 페이지가 속한 slab과 cache에 대한 포인터를 저장하는 데 쓰인다. 이는 또한 free 페이지들을 묶어서 관리하는 데에도 쓰인다.
- mapping: 파일이나 장치가 메모리 매핑된 경우, 그들의 inode는 관련된 address_space를 가진다. 페이지가 파일에 속한 경우 이 필드는 address_space의 주소를 저장할 것이다. 만약 페이지가 anonymous이고 mapping이 설정된 경우, address_space는 swap address space를 관리하는 변수인 swapper_space이다.
- index: 이 필드는 두 가지 용도가 있으며, 이는 페이지의 상태에 의존한다. 만약 페이지가 file mapping에 해당한다면, 이것은 file내에서의 오프셋을 의미한다. 만약 페이지가 swap cache에 해당한다면, 이것은 swap address space(swapper_space)를 위한 address_space에서의 오프셋을 의미한다. 두번째로, 만약 페이지 블록이 특정 프로세스를 위해 해제되는 중이라면, 블록의 order 값(블록의 페이지 수의 2의 지수값)이 index에 저장된다. 이는 __free_pages_ok()함수에서 수행된다.
- next_hash: file mapping에 속한 페이지들은 inode와 offset으로 해싱된다. 이 필드는 같은 hash bucket을 공유하는 페이지들을 연결한다.
- count: 페이지에 대한 참조 카운트. 0으로 떨어진다면 이 페이지는 해제될 것이다. 0보다 크다면 이 페이지는 하나 또는 그 이상의 프로세스들로부터 사용되고 있거나 IO에 기다릴때처럼 커널에 의해 사용되고 있을 것이다.
- flags: 페이지의 상태를 표현하는 flag들. 모든 flag는 <linux/mm.h>에 선언되어 있고, Table 2.1에 나열되어있다. 이 비트들을 test, clear 그리고 set 하기위한 매크로들이 존재하며, 이는 Table 2.2에 나열되어있다. SetPageUptodate()의 경우, 특이하게도 비트를 설정하기 전에 아키텍처 특정 함수 arch_set_page_uptodate()를 호출한다.
- lru: page replacement 정책을 위해, swap out 될 수 있는 페이지들은 page_alloc.c에 선언되어있는 active_list 또는 inactive_list에 속해있다. 이 필드는 LRU list들을 위한 list head이다. 두 리스트는 10장에서 자세히 논의된다.
- pprev_hash: next_hash와 상호보완적으로 동작하여 hash가 doubly linked list처럼 동작하도록 한다.
- buffers: 만약 페이지가 이와 관련된 block device를 위한 buffer를 가지고 있다면, 이 필드는 buffer_head를 추적하는데 사용된다. 프로세스에 의해 매핑된 anonymous page는 swap file로 백업되었을 경우에는 연관된 buffer_head를 가질 수도 있다. 이 필드는 페이지가 filesystem에 의해 정의된 블록 사이즈의 chunk 단위로 백업 스토리지와 동기화되어야하므로 필수적이다.
- virtual: 정상적으로는 오직 ZONE_NORMAL의 페이지들만이 커널에 의해 직접 접근될 수 있다. ZONE_HIGHMEM의 페이지들에 접근하기 위해, 커널에 페이지를 매핑하기 위해 9장에서 논의될 kmap() 함수가 사용된다. 매핑될 수 있는 페이지의 수는 고정되어있다. 페이지가 매핑된 후, 이 필드에 매핑된 가상 주소가 저장된다.
mem_map_t 타입은 mem_map 배열에서 쉽게 참조될 수 있도록 도와주는 struct page의 typedef이다.
| Bit name | 설명 |
|---|---|
| PG_active | 이 비트는 page가 active_list에 속해있을 때 set되고, 제거될 때 clear된다. page가 hot함을 표시한다. |
| PG_arch_1 | PG_arch_1은 아키텍처 특수 페이지 상태 비트이다. generic 코드는 어떤 페이지가 page cache에 처음 들어간 경우 이 비트가 clear됨을 보장한다. 이 비트는 아키텍처가 page가 프로세스에 의해 매핑될 때까지 D-cache를 flush하는 것을 미룰 수 있게해준다. |
| PG_checked | Ext2 파일시스템에 의해서만 사용된다. |
| PG_dirty | 이 페이지가 디스크에 flush 될 필요가 있는 지를 알려준다. disk에 백업본이 있는 페이지에 write이 발생한 경우, 해당 데이터는 disk에 즉각 flush 되는 대신 이 비트가 set되어 해당 page가 flush되기 전에는 해제되지 않게 해준다. |
| PG_error | 만약 disk I/O를 처리하는 동안 에러가 발생하면, 이 비트가 set된다. |
| PG_fs_1 | 파일시스템이 자기 입맛대로 사용할수 있도록 예약된 비트. 현재 오직 NFS만이 사용중임. |
| PG_highmem | high memory의 페이지들은 영구적으로 커널에 의해 매핑될 수 없다. mem_init()이 high memory에 속한 페이지들의 이 비트를 set한다. |
| PG_launder | 이 비트는 page replacement 정책에서만 사용된다. VM이 페이지를 swap out하기를 원할 때 이 비트를 set하고 writepage() 함수를 호출한다. scan할 때, 이 비트가 set된 페이지를 만났고 PG_locked가 set되어 있다면, I/O가 완료될 때까지 기다린다. |
| PG_locked | 이 비트는 page가 disk I/O를 위해 lock이 잡혀야하는 경우 set된다. I/O가 시작될 때 이 비트가 set되고, 완료되면 clear된다. |
| PG_lru | 페이지가 active_list 또는 inactive_list에 속해있다면 이 비트가 set된다. |
| PG_referenced | 만약 페이지가 매핑되어있고 매핑을 통해서 참조된다면 set된다. 이것은 page replacement 정책에서 LRU list간에 페이지를 이동할 때 사용된다. |
| PG_slab | slab allocator에 의해 페이지가 사용될 때 set한다. |
| PG_skip | 물리 메모리가 존재하지않는 주소 공간을 스킵하기 위해 어떤 아키텍처들이 사용한다. |
| PG_unused | 말그대로 사용되지 않는 비트이다. |
| PG_uptodate | disk에서 페이지가 오류없이 읽혀졌다면, 이 비트가 set된다. |
| Bit name | Set | Test | Clear |
|---|---|---|---|
| PG_active | SetPageActive() | PageActive() | ClearPageActive() |
| PG_arch_1 | n/a | n/a | n/a |
| PG_checked | SetPageChecked() | PageChecked() | n/a |
| PG_dirty | SetPageDirty() | PageDirty() | ClearPageDirty() |
| PG_error | SetPageError() | PageError() | ClearPageError() |
| PG_highmem | n/a | PageHighMem() | n/a |
| PG_launder | SetPageLaunder() | PageLaunder() | ClearPageLaunder() |
| PG_locked | LockPage() | PageLocked() | UnlockPage() |
| PG_lru | TestSetPageLRU() | PageLRU() | TestClearPageLRU() |
| PG_referenced | SetPageReferenced() | PageReferenced() | ClearPageReferenced() |
| PG_reserved | SetPageReserved() | PageReserved() | ClearPageReserved() |
| PG_skip | n/a | n/a | n/a |
| PG_slab | PageSetSlab() | PageSlab() | PageClearSlab() |
| PG_unused | n/a | n/a | n/a |
| PG_uptodate | SetPageUptodate() | PageUptodate() | ClearPageUptodate() |
2.4.1 Mapping Pages to Zones
2.4.18 커널 버전까지는, struct page가 page->zone을 통해 자신이 속한 존에 대한 참조를 저장했다. 그러나 struct page 구조체는 수천개가 존재하기 때문에 이 작은 포인터 하나가 엄청난 양의 메모리를 차지하게 되므로 낭비라고 여겨졌다. 더 최근의 커널에서는, zone 필드가 사라졌고 대신에 page->flags의 ZONE_SHIFT개의 top bit가 page가 속한 zone을 결정하는데 사용된다. 첫번째로 zone들의 zone_table이 초기화된다. 이는 mm/page_alloc.c에 선언된다:
33 zone_t *zone_table[MAX_NR_ZONES*MAX_NR_NODES];
34 EXPORT_SYMBOL(zone_table);MAX_NR_ZONES는 노드에 존재할 수 있는 최대 존의 개수이다. MAX_NR_NODES는 존재할 수 있는 최대 노드 수이다. EXPORT_SYMBOL()은 zone_table이 커널 모듈에 의해 접근될 수 있도록 해준다. 이 테이블은 다차원 배열처럼 다뤄진다. free_area_init_core() 동안, 노드의 모든 페이지들이 초기화된다. 먼저 이는 table의 값을 설정한다.
733 zone_table[nid * MAX_NR_ZONES + j] = zone;nid는 노드 ID이고, j는 zone index이며, zone은 zone_t 구조체이다. 각 페이지마다 set_page_zone()이 다음과 같이 호출된다:
788 set_page_zone(page, nid * MAX_NR_ZONES + j);인자값 page는 세팅되고있는 존의 page이다. 이때, zone_table의 인덱스가 page에 저장된다.
2.5 High Memory
커널에 의해 사용될 수 있는 주소공간(ZONE_NORMAL)의 크기가 제한적이기 때문에, 커널은 High Memory의 개념을 지원한다. 32비트 x86 시스템에서 high memory에는 4GiB와 64GiB, 두 개의 임계값이 존재한다. 4GiB limit은 32 비트 물리 주소를 통해 접근될 수 있는 메모리 양과 관계가 있다. 1GiB에서 4GiB 사이의 메모리에 접근하기위해서, 커널은 high memory의 페이지를 kmap()을 통해 임시적으로 ZONE_NORMAL에 매핑한다. 이는 9장에서 더 논의한다.
두번째 limit인 64GiB는 Physical Address Extension(PAE, 32비트 시스템에서 더 많은 RAM을 사용할 수 있도록 고안된 intel의 기술)과 관련이 있다. 이는 4개의 추가 비트가 메모리 주소에 사용될 수 있도록하며, 이를 통해 2^36 바이트 (64GiB)까지의 메모리가 접근될 수 있도록한다.
PAE는 이론적으로는 프로세서가 64GiB까지 접근가능하도록 하지만, 현실적으로는 가상 주소 공간이 여전히 4GiB이기 때문에 여전히 그 정도의 RAM에는 접근할 수 없다. 이는 한 프로세스의 malloc()을 통해 모든 RAM을 할당하려고 했던 유저에게 실망감을 안겨주었다.
두번째로, PAE는 커널 자신도 이렇게 많은 RAM을 이용가능하게 하지는 않는다. struct page는 44 바이트를 차지하며 이는 ZONE_NORMAL의 커널 가상 주소 공간을 차지한다. 이것은 1GiB 메모리에 대해서 struct page를 위해 대략 11MiB의 커널 메모리가 필요하다는 것을 의미한다. 따라서 16GiB는 176MiB의 메모리가 사용되고, 이는 ZONE_NORMAL에 상당한 압력을 가한다. ZONE_NORMAL을 사용하는 다른 구조체들을 고려하기 전에는, 이것이 그렇게 나쁜 소식은 아닌 것처럼 들린다. 그러나 심지어 매우 작은 구조체인 PTE(Page Table Entry)들도 최악의 경우 대략 16MiB를 필요로 한다. 이는 현실적으로 x86의 리눅스가 사용가능한 물리메모리의 크기를 16GiB로 제한한다. 만약 더 많은 메모리를 사용해야한다면, 답은 간단하다, 64비트 머신을 사라.
2.6 What's New in 2.6
Nodes
언뜻 보기에는 메모리가 설명되는 방법에 많은 변화가 없어보이지만, 겉으로 보기에는 작은 변화들이 광범위하게 나타나고 있다. 노드 디스크립터인 pg_data_t는 아래와 같은 몇가지 새로운 필드들을 가진다:
- node_start_pfn: node_start_paddr 필드를 대체했다. 다른 점은 물리 주소대신 PFN을 사용한다는 점이다. PAE 아키텍처가 32비트 이상을 메모리 주소로 필요로 하였고, 이전 필드로는 4GiB보다 큰 주소에서 시작하는 노드는 표현할 수 없었기에 이처럼 바뀌었다.
- kswapd_wait: kswapd를 위한 새로운 wait queue이다. 2.4에서는 page swapper daemon을 위한 전역 wait queue가 존재했다. 2.6에서는 각 노드마다 kswapdN(N은 노드ID)이 있고, 각 kswapd는 이 필드에 자신만의 wait queue를 가진다.
node_size 필드는 제거되었고 대신 두개의 필드로 대체되었다. 이 변화는 노드들이 실제 물리메모리가 없는 "holes"가 있을 수 있음을 인지하기 위해 소개되었다.
- node_present_pages: 노드의 물리 페이지 개수
- node_spanned_pages: hole을 포함하여 노드의 주소 공간에 포함되는 모든 페이지의 개수
Zones
언뜻 보기에도 존은 굉장히 달라졌다. 이제 존은 더이상 zone_t로 참조되지않고, 대신 그냥 struct zone으로 사용된다. 두번째로 주요한 차이점은 LRU list이다. 10장에서 보겠지만, kernel 2.4는 페이지가 해제되거나 page out되는 순서를 결정하는 페이지의 전역 리스트를 관리한다. 이 리스트들은 이제 struct zone에 저장된다. 관련 필드는 다음과 같다:
- lru_lock: zone의 LRU list를 위한 spinlock이다. 2.4버전에서는 전역 lock이였으며 pagemap_lru_lock이라 불렸다.
- active_list: zone의 active list이다. 10장에서 설명하는 것과 동일하지만, 이젠 global이 아니라 per-zone이라는 것만이 다르다.
- inactive_list: zone의 inactive list이다. 2.4에서는 global이다.
- refill_counter: 한 pass에서 active_list에서 제거된 페이지의 개수. page replacement 과정에서만 사용된다.
- nr_active: active_list에 속한 페이지 수
- nr_inactive: inactive_list에 속한 페이지 수
- all_unreclaimable: pageout daemon이 zone의 모든 페이지를 두번 scan하였는데도 충분한 페이지를 해제하는데 실패한 경우, 1로 set된다.
- pages_scanned: 마지막 대량 페이지 묶음이 회수된 이후로부터 scan된 페이지 수. 2.6에서는 2.4처럼 페이지 하나하나 개별적으로 해제하는 것이 아니라, 페이지 여러개를 한번에 묶어서 해제한다.
- pressure: 이 존에 대한 scan 강도를 측정한다. 감쇠하는 평균값으로 page scanner가 얼마나 열심히 페이지를 회수하려고 하는 지에 영향을 미친다.
다른 3개의 필드들도 새롭게 등장했지만, 이들은 존의 범위와 관련이 있다:
- zone_start_pfn: 존의 시작 PFN. zone_start_paddr과 zone_start_mapnr 필드를 대체하였다.
- spanned_pages: hole까지 포함하여 zone에 해당하는 페이지의 수이다.
- present_pages: zone에 포함하는 실재하는 페이지 수이다. 대다수의 아키텍처에서, 이 값은 spanned_pages와 같다.
또 다른 추가는 struct per_cpu_pageset으로 spinlock 경쟁을 줄이기 위해 각 CPU의 page 리스트를 관리하는데 사용된다. zone->pageset 필드는 NR_CPU 크기의 struct per_cpu_pageset 배열이고, NR_CPU는 시스템의 CPU 개수의 최대 한도값으로 컴파일된다. per-cpu 구조체는 마지막 절에서 더 이야기하겠다.
struct zone에 대한 마지막 추가는 zero padding의 포함이다. 2.6 VM의 개발 과정에서 어떤 spinlock들에 대한 경쟁이 굉장히 심하고 자주 락이 걸리는 것을 확인했다. 어떤 락들은 항상 쌍으로 획득되기 때문에, 이들은 서로 다른 캐시라인들 사용하도록 보장되어야하며, 이는 흔하게 사용되는 캐시 프로그래밍 트릭이다. struct zone의 패딩은 ZONE_PADDING() 매크로로 표시되어있으며, zone->lock, zone->lru_lock, 그리고 zone->pageset 필드가 서로 다른 캐시 라인을 사용하도록 보장한다.
Pages
첫번째 눈에 띄는 변경사항은 관련 항목이 동일한 캐시 라인에 있을 가능성이 높도록 필드의 순서가 변경되었다는 것이다. 필드들은 두가지 추가를 제외하면 본질적으로 같다. 첫번째는 PTE chain을 생성하기 위해 사용되는 새 union이다. PTE chain은 페이지 테이블 관리와 관련이 있으므로 3장의 마지막에서 논의할 것이다. 두번째는 page->private으로, 매핑에 대한 private 정보를 포함한다. 예를 들어, 페이지가 buffer page인 경우, 이 필드는 buffer_head에 대한 포인터를 저장한다. 이것은 page->buffers 필드가 사라졌다는 것을 의미한다. 마지막 중요한 변경사항은 page->virtual이 high memory 지원을 위해 필수적이지 않게 되었고, 아키텍처가 요구하는 경우에만 이를 포함한다는 것이다. High memory가 지원되는 방법은 9장에서 더 자세히 논의한다.
Per-CPU Page Lists
2.4에서는 Slab Allocator만이 모든 object에 대한 per-cpu list를 관리하려고 시도했다 (8장 참조). 2.6에서는 이 개념이 훨씬 더 광범위해지고 hot, cold page에 대한 공식화된 개념이 생겨났다.
<linux/mmzone.h>에 선언된 struct per_cpu_pageset은 per_cpu_pages라는 타입의 두 요소를 가진 배열만을 필드로 가진다. 이 배열의 0번째 요소는 hot page를 위한 것이고, 1번째 요소는 cold page를 위한 것이다. 여기서 hot, cold는 이 캐시에 있는 page가 얼마나 "active"한가를 나타낸다. IO readahead와 같은 예시처럼, page들이 최근에 접근되지않았다는 것이 사실로 판명되면, 해당 page들은 cold page로써 할당될 것이다.
struct per_cpu_pages는 리스트에 속해있는 page 수를 관리하고, 해당 리스트가 언제 채워져야할 지 아니면 페이지들을 언제 해제해야할 지를 결정하는 high와 low 워터마크를 관리한다. 또한 얼마나 많은 페이지들이 한 블록에 할당되어야하는 지를 결정하는 변수와 page들의 실제 list head도 포함한다.
per-cpu page list를 기반으로, per-cpu page accounting 메커니즘도 있다. struct page_state에는 이 CPU에 할당된 페이지 수를 추적하는 pgalloc 필드와 swap readin 수를 추적하는 pswpin과 같은 여러 accounting 변수가 있다. 이 구조체는 <linux/page-flags.h>에서 많은 주석을 달고 있다. 실행중인 CPU의 page_state 필드를 업데이트하기 위한 함수로 mod_page_state()가 제공되며, inc_page_state(), dec_page_state(), sub_page_state()라는 3개의 도우미 매크로가 제공된다.
