Chapter 3. Page Table Management

이 글은 Gorman 책 "Understanding the Linux Virtual Memory Manager"의 Chapter 3를 번역한 글입니다.
리눅스는 머신-독립/의존적 계층을 다른 OS들과는 다른 방식으로 나눈다. 다른 OS들은 물리 페이지를 관리하기위한 객체를 가진다 (BSD의 경우 pmap 객체). 리눅스는 대신에 3-level page table의 개념을 아키텍처 독립적인 코드에 도입한다 (심지어 머신의 아키텍처가 이를 지원하지 않더라도 말이다!). 이것은 개념적으로는 이해하기 쉬우나, 서로 다른 페이지들 간의 구분이 흐려지며, 페이지가 속한 객체가 아닌, 페이지의 플래그, 어떤 리스트에 속해있는 지와 같은 간접적인 정보를 통해 페이지의 타입을 구분해야함을 의미한다.
다른 방식으로 MMU (Memory Management Unit)을 관리하는 아키텍처들은 3-level page table을 흉내내야할 것이다. 예를 들어, PAE가 disable된 x86의 경우, 2-level page table만이 이용가능한데, 이 경우에 PMD (Page Middle Directory)는 크기가 1로 정의되어 PGD (Page Global Directory)에 "접히게" 되고, 이는 컴파일 타임에 최적화되어 사라지게된다. 불행하게도, 캐시나 TLB (Translation Lookaside Buffer)를 직접 관리하지않는 아키텍처들을 위해, TLB나 CPU cache가 변경되어야 하거나 flush되어야하는 경우, 머신 의존적인 코드에 대한 hook가 코드에 명시되어야한다 (해당 hook이 필요없는 아키텍처의 경우 hook들은 아무 동작도 하지않는다). 이러한 hook에 대해서는 3.8절에서 논의한다.
이 장은 먼저 페이지 테이블의 배열 방법과 테이블의 세 가지 별도의 레벨을 설명하는 데 사용되는 타입을 설명하며, 테이블 탐색을 위해 가상 주소가 어떻게 각 요소로 분리되는 지를 설명한다. 그 다음, 가장 낮은 레벨의 엔트리인 PTE (Page Table Entry)의 어떤 비트가 어떻게 하드웨어에 의해 사용되는 지를 설명한다. 이후에는 페이지 테이블을 탐색하고, 속성을 세팅하고 체크하기위해 사용되는 매크로들을 설명한 후, 페이지 테이블이 채워지는 방식, 페이지 테이블을 위한 메모리가 어떻게 할당 및 해제되는 지에 대해 설명한다. 그런 다음 페이지 테이블이 부팅 과정에서 어떻게 초기화되는 지를 설명한다. 마지막으로는, TLB와 CPU cache가 어떻게 활용되는 지 살펴본다.
3.1 Describing the Page Directory
각 프로세스는 물리 페이지 프레임 하나를 차지하고 있는 자신만의 PGD (Page Global Directory)에 대하여 mm_struct->pgd라는 포인터를 가지고 있다. 이 프레임은 pgd_t 타입의 배열로 이루어져있고, pgd_t 타입은 아키텍처 의존적인 타입으로 <asm/page.h>에 정의되어있다. 페이지 테이블은 아키텍처에 따라 다른 방식으로 로드된다. x86의 경우, mm_struct->pgd를 cr3 레지스터에 복사하는 방식으로 프로세스 페이지 테이블을 로드하며, 이는 TLB를 flush해야한다는 단점이 있다. 사실 이 방법은 아키텍처 의존적인 코드인 __flush_tlb() 함수를 구현하는 방법이기도 하다.
PGD 테이블의 유효한 엔트리는 pmd_t 타입의 PMD (Page Middle Directory) 엔트리의 배열을 포함하는 페이지 프레임을 가리키며, PMD 엔트리는 다시 pte_t 타입의 PTE (Page Table Entry) 엔트리의 배열을 포함하는 페이지 프레임을 가리키며, PTE 엔트리는 최종적으로 실제 유저 데이터를 포함하는 페이지 프레임을 가리킨다. 스토리지로 페이지가 스왑 아웃되는 경우에는, PTE에 swap entry가 저장되며, 페이지 폴트 처리시에 do_swap_page()가 페이지의 데이터를 저장하고 있는 swap entry를 찾는데에 사용한다. 페이지 테이블의 레이아웃은 Figure 3.1에 나타나있다.
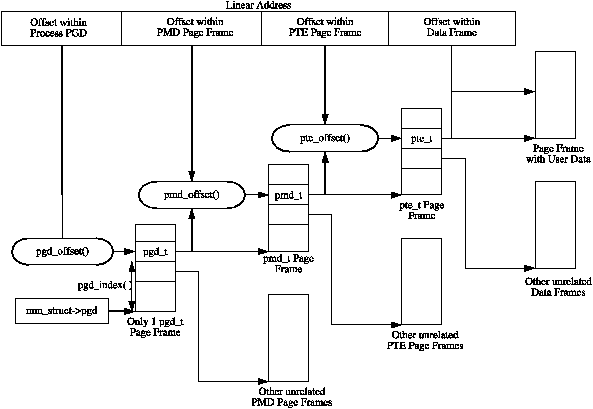
주어진 linear address의 각 부분들은 세 레벨의 페이지 테이블 또는 실제 페이지 내에서의 오프셋을 나타내도록 쪼개진다. linear address를 쪼개는 과정을 쉽게 할 수 있도록, SHIFT, SIZE, 그리고 MASK 매크로가 각 페이지 테이블 레벨마다 제공된다. Figure 3.2에 나와있듯이, SHIFT 매크로는 각 페이지 테이블 레벨에 의해 매핑된 비트의 길이를 지정한다.
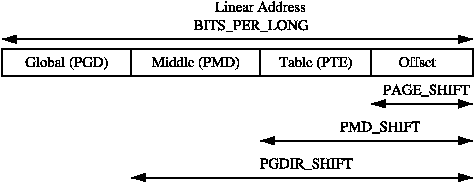
MASK는 linear address와 AND 연산을 취함으로써 모든 상위 비트를 마스킹할 수 있으며, linear address가 페이지 테이블 레벨에 맞게 align 되어있는 지를 판단할 때 자주 사용된다. SIZE 매크로는 각 레벨의 개별 엔트리가 매핑할 수 있는 영역의 크기를 바이트 단위로 나타낸다. SIZE와 MASK 매크로의 관계는 Figure 3.3에 나타나있다.
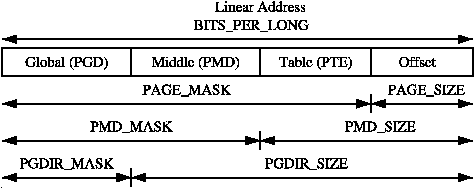
세 값을 계산할 때는 오직 SHIFT 값만이 중요한데, 그 이유는 나머지 두 값은 SHIFT 값을 기반으로 계산되기 때문이다. 예를 들어, x86에서 page level을 위한 세 매크로든 다음과 같다:
5 #define PAGE_SHIFT 12
6 #define PAGE_SIZE (1UL << PAGE_SHIFT)
7 #define PAGE_MASK (~(PAGE_SIZE-1))PAGE_SHIFT는 linear address space에서 offset 부분의 비트 수이고, x86에서는 12 비트이다. 페이지의 크기는 위의 코드처럼 2^PAGE_SHIFT로 쉽게 계산할 수 있다. 마지막으로 MASK는 (PAGE_SIZE - 1)으로 계산된 비트에 부정 연산을 취하여 계산한다. 만약 페이지가 페이지 경계만큼 align될 필요가 있다면, PAGE_ALIGH()이 사용된다. 이 매크로는 주소값에 (PAGE_SIZE - 1)만큼 더한 후 PAGE_MASK와 AND를 취하여 page offset 비트를 0으로 만든다.
PMD_SHIFT는 테이블의 두번째 레벨에 의해 매핑되는 linear address의 비트 수이다. PMD_SIZE와 PMD_MASK는 페이지 레벨 매크로와 비슷한 방식으로 계산된다.
PGDIR_SHIFT는 페이지 테이블의 첫번째 레벨에 의해 매핑되는 linear address의 비트 수이다. PGDIR_SIZE와 PGDIR_MASK는 위와 같은 방식으로 계산된다.
중요한 마지막 세 매크로는 PTRS_PER_x로, 각 페이지 테이블 레벨의 엔트리 개수를 결정한다. PTRS_PER_PGD는 PGD에 속한 포인터 수로, x86 without PAE에서는 1024이다. PTRS_PER_PMD와 PTRS_PER_PTE는 각각 PMT, PTE의 엔트리 수로, x86 without PAE에서 각각 1, 1024이다.
3.2 Describing a Page Table Entry
이전에 언급했듯이, PTE, PMD, 그리고 PGD의 엔트리들은 각각 pte_t, pmd_t, 그리고 pgd_t 구조체를 통해 표현된다. 이들은 그저 unsigned integer일 뿐이지만, 두가지의 이유로 구조체로 정의된다. 첫번째는 타입 보호를 통해서 부적절한 사용을 방지하기 위함이다. 두번째는 4GiB 이상의 메모리에 접근할 때 추가적인 4비트가 사용되는 x86의 PAE와 같은 기능을 위해서이다. protection bit들을 저장하기 위해, 관련 flag들을 저장하는 pgprot_t가 정의되고, 이는 보통 페이지 테이블 엔트리의 낮은 비트에 저장된다.
type casting을 위해, asm/page.h에 4개의 매크로가 제공되는데, 이들은 위의 타입들을 인자로 받아서 구조체의 관련 부분을 반환한다. 매크로는 pte_val(), pmd_val(), pgd_val(), 그리고 pgprot_val()이다. type casting을 되돌리기 위해서 , __pte(), __pmd(), __pgd(), 그리고 __pgprot() 매크로가 지원된다.
정확히 어느 위치에 protection bit들이 저장되는 지는 아키텍처에 의존적이다. 설명을 위해 우리는 PAE가 enable되지 않은 x86 아키텍처를 가정하고 설명하겠지만, 모든 아키텍처에 같은 원리가 적용된다. PAE가 없는 x86에서, pte_t는 단순히 32비트 정수 하나로 구성된 구조체이다. 각 pte_t는 페이지 프레임의 주소를 가리키며, 가리키는 주소는 page aligned 됨을 보장받는다. 그러므로, 페이지 테이블 엔트리의 32비트 중에서 PAGE_SHIFT (12) 비트는 status 비트를 저장하는데 사용할 수 있다. protection과 status 비트는 Table 3.1에 나열되어 있으나, 어떤 비트가 실재하고 무엇을 의미하는 지는 아키텍처마다 다를 수 있다.
| Bit | Function |
|---|---|
| _PAGE_PRESENT | 페이지가 메모리에 존재하고 스왑 아웃되지 않았다면 set됨 |
| _PAGE_PROTNONE | 페이지가 메모리에 존재하나 접근 불가능하면 set됨 |
| _PAGE_RW | 페이지에 write이 가능하면 set됨 |
| _PAGE_USER | 유저 공간에서 접근 가능하면 set됨 |
| _PAGE_DIRTY | 페이지가 수정되면 set됨 |
| _PAGE_ACCESSED | 페이지가 접근되면 set됨 |
더 논의할 _PAGE_PROTNONE을 제외하면 이름을 통해 그 의미를 알 수 있다. Pentium III 이전의 아키텍처에서는 reserved 비트였던 이 비트는 Pletium III 또는 그 이상의 x86에서 PAT (Page Attribute Table)이라고 불린다. PAT 비트는 PTE가 참조하는 페이지의 크기를 나타내는 데 사용된다. PGD 엔트리에서 같은 비트를 PSE (Page Size Exception) 비트라고 부르며, 이 비트들은 함께 사용되도록 의도되어졌다.
리눅스는 PSE 비트를 유저 페이지에 대해 사용하지 않기 때문에, PTE의 PAT 비트는 다른 목적으로 사용이 가능하다. PROT_NONE flag로 mprotect()를 수행하여 보호되는 영역처럼, 메모리에 상주하지만 유저 공간에서는 접근할 수 없는 페이지가 필요하다. 어떤 영역이 보호되어야 한다면, _PAGE_PRESENT 비트는 clear되고 _PAGE_PROTNONE 비트가 set된다. pte_present() 매크로는 두 비트 중 하나라도 set 되었는 지를 체크하기 때문에, 유저 공간에서 접근 불가능하더라도 커널은 PTE가 present함을 알 수 있는데, 이는 미묘하지만 중요한 사실이다. 하드웨어 비트인 _PAGE_PRESENT가 clear 되었기 때문에, 해당 페이지에 접근이 발생하면 page fault가 발생한다. 이를 이용하여 리눅스는 스왑 아웃이 필요하거나 프로세스가 종료하면, 페이지를 메모리에 상주시키면서도 protection을 강제할 수 있다.
3.3 Using Page Table Entries
<asm/pgtable.h>에 페이지 테이블 엔트리를 탐색하고 검사하는데 중요한 매크로들이 정의되어있다. 페이지 디렉토리를 탐색하기위해, linear address space를 구성요소로 쪼개는데 사용되는 3개의 매크로가 제공된다. pgd_offset()은 주소와 프로세스의 mm_struct를 인자로 받아, 요청받은 주소에 대한 PGD 엔트리를 반환한다. pmd_offset()은 PGD 엔트리를 받아서 해당하는 PMD를 반환한다. pte_offset()은 PMD 엔트리를 받아 관련된 PTE를 반환한다. linear address space의 나머지 부분은 page 내에서의 오프셋으로 사용된다. 각 필드 사이의 관계는 Figure 3.1에 나타나있다.
두번째 종류의 매크로는 페이지 테이블 엔트리가 present한 지, 또는 사용될 수 있는 지를 결정한다.
- pte_none(), pmd_none(), 그리고 pgd_none()은 해당 엔트리가 존재하지않는 경우 1을 반환한다.
- pte_present(), pmd_present(), 그리고 pgd_present()는 해당 엔트리의 PRESENT 비트가 set 되어있을 경우 1을 반환한다.
- pte_clear(), pmd_clear(), 그리고 pgd_clear()은 인자로 받은 엔트리를 clear한다.
- pmd_bad()과 pgd_bad()는 어떤 함수가 인자로 받은 엔트리의 값을 변경하고자하는 경우, 변경전에 엔트리를 체크하기위해 사용된다. 이 매크로들이 1을 반환하는 조건은 아키텍처마다 다르지만, 엔트리의 presetn, accessed 비트가 set 되어있음을 확인하는 것은 꼭 보장해줘야한다.
VM의 많은 부분에 page table walk 코드가 포함되어있으며, 이를 인지하는 것은 중요하다. 가장 간단한 예시로는 mm/memory.c의 follow_page() 함수가 있다. 다음은 해당 함수에서 page table walk과 관련있는 코드만 발췌한 코드이다:
407 pgd_t *pgd;
408 pmd_t *pmd;
409 pte_t *ptep, pte;
410
411 pgd = pgd_offset(mm, address);
412 if (pgd_none(*pgd) || pgd_bad(*pgd))
413 goto out;
414
415 pmd = pmd_offset(pgd, address);
416 if (pmd_none(*pmd) || pmd_bad(*pmd))
417 goto out;
418
419 ptep = pte_offset(pmd, address);
420 if (!ptep)
421 goto out;
422
423 pte = *ptep;3개의 offset 매크로를 사용하여 페이지 테이블을 순회하고, _none()과 _bad() 매크로를 사용하여 valid한 엔트리임을 확인한다.
세번째 종류의 매크로는 엔트리의 권한을 검사 및 업데이트한다. 권한은 유저 프로세스가 특정 페이지에 대해서 무엇을 할 수 있는 지를 결정한다. 예를 들어, 커널 페이지 테이블 엔트리는 유저 프로세스가 절대 읽을 수 없다.
- 엔트리의 읽기 권한은 pte_read(), pte_mkread(), 그리고 pte_rdprotect()를 통해 각각 test, set, clear된다.
- 쓰기 권한은 pte_write(), pte_mkwrite(), pte_wrprotect()를 통해 test, set, clear된다.
- 실행 권한은 pte_exec(), pte_mkexec(), pte_exprotect()를 통해 test, set, clear된다. x86 아키텍처에서는 페이지의 실행 권한을 설정할 수단이 없기때문에, 이 매크로들은 read 매크로와 같은 기능을 한다.
- 권한들은 pte_modify() 매크로를 통해서도 새로운 값으로 수정될 수 있으나, 이는 거의 사용되지않는다. 이는 오직 mm/mprotect.c의 change_pte_range() 함수에서만 사용된다.
네번째 종류의 매크로는 엔트리의 상태를 검사하고 설정한다. 리눅스에는 상태를 나타내는 비트로 dirty와 accessed 비트가 있다. 이 비트의 검사는 pte_dirty()와 pte_young() 매크로가 수행한다. 비트의 set은 pte_mkdirty()와 pte_mkyoung()이 수행한다. clear는 pte_mkclear()와 pte_old()가 수행한다.
3.4 Translating and Setting Page Table Entries
이 절에서 소개할 매크로와 함수들은 주소 또는 페이지와 PTE 사이의 매핑과 개별 엔트리의 설정을 처리한다.
mk_pte() 매크로는 struct page와 protection 비트를 인자로 받아, 이들을 결합하여 페이지 테이블에 쓰여질 pte_t를 생성한다. 비슷한 매크로인 mk_pte_phys()는 struct page 대신 페이지의 물리 주소를 인자로 받는다.
pte_page() 매크로는 PTE 엔트리가 가리키는 struct page를 반환한다. pmd_page()는 PMD 엔트리가 가리키는 페이지, 즉 PTE 테이블을 저장하고 있는 페이지를 반환한다.
set_pte() 매크로는 mk_pte()와 같은 함수를 통해 생성한 pte_t를 인자로 받아, 프로세스의 페이지 테이블에 넣는다. pte_clear()는 프로세스 페이지 테이블의 엔트리를 clear 한다. ptep_get_and_clear()는 pte_clear()와 같은 일을 함과 동시에 clear한 원본 pte_t를 반환한다. 이 기능은 PTE의 protection, 또는 pfn 같은 일부 영역만 수정하고자 할 때, 나머지의 원본을 읽어오기 위해 사용한다.
3.5 Allocating and Freeing Page Tables
이 절에서는 페이지 테이블의 할당과 해제와 관련된 함수들을 소개한다. 페이지 테이블은, 설명했듯이, 엔트리들의 배열을 저장하고 있는 물리 페이지이다. 그리고 물리 페이지의 할당과 해제는 시간이 오래걸리고, 페이지 할당을 하는 동안 인터럽트를 비활성화한다는 점에서 상대적으로 비싼 동작이다. 어느 레벨이던, 페이지 테이블의 할당과 해제는 굉장히 자주 발생하므로, 이를 최대한 빨리 처리하는 것은 중요하다.
그러므로 페이지 테이블을 위한 페이지들은 quicklists라고 불리는 리스트에 캐싱된다. 아키텍처마다 이 리스트를 구현하는 방식은 다르나, 그 원칙은 동일하다. 예를 들어, 모든 아키텍처가 PGD들을 캐싱하지는 않는데, 그 이유는 이들의 할당과 해제는 프로세스의 생성과 종료 과정에서만 수행되기 때문이다. 이 둘 모두 굉장히 비싼 작업이기 때문에, 한 페이지를 할당하는 오버헤드는 무시할 수 있다.
PGD, PMD, PTE 테이블 모두 각각을 위한 할당과 해제를 위한 함수를 가진다. 할당을 위한 함수는 pgd_alloc(), pmd_alloc(), 그리고 pte_alloc()이며, 충분히 예측 가능하겠지만, 해제를 위한 함수는 pgd_free(), pmd_free(), 그리고 pte_free()이다.
일반적으로 3개의 페이지 테이블 레벨은 각각 pgd_quicklist, pmd_quicklist, 그리고 pte_quicklist라고 불리는 세 캐시를 사용하여 캐싱을 구현한다. 아키텍처들은 서로 다른 방식으로 이들을 구현하며, 그 중 한가지는 LIFO 타입의 구조를 사용하는 방법이다. 보통은 페이지 테이블 엔트리는 페이지 테이블이나 데이터를 포함하는 다른 페이지를 가리킨다. 하지만 캐싱되어있는 동안에는, 테이블의 첫번째 엔트리가 캐싱된 다음 테이블 페이지를 가리킨다. 테이블을 할당할때는 리스트에서 한 페이지를 꺼내게되고, 해제할때는 헤재된 페이지가 리스트의 새로운 head가 된다. 또한 캐시에 얼마나 많은 페이지가 존재하는 지도 카운트한다.
pgd_quicklist를 이용한 할당 함수는, 아키텍처 외부에 정의되어있지는 않지만, 일반적으로 get_pgd_fast()라는 이름을 사용한다. PMD와 PTE의 quicklist를 이용한 할당 함수는 public하게 정의되며, 각각 pmd_alloc_one_fast(), pte_alloc_one_fast()라고 불린다.
만약 페이지가 캐시로부터 할당될 수 없다면, 페이지는 물리 페이지 할당자로부터 할당될 것이다 (6장 참조). 이때 사용되는 함수는 get_pgd_slow(), pmd_alloc_one(), 그리고 pte_alloc_one()이다.
캐싱되는 페이지 수가 너무 커질 수 있기 때문에, 이를 pruning하는 메커니즘 또한 존재한다. 캐시가 커지거나 작아질 때마다, counter는 증감한다. 이에 대한 high, low 워터마크가 존재하는데, check_pgt_cache()를 통해 이를 체크한다. 만약 count가 high 워터마크에 도달한 경우, 캐시 크기가 low 워터마크에 도달할 때까지 캐시의 크기를 줄인다. 이 함수는 두 곳에서 불리는데, clear_page_tables()의 직후와 system idle task에서 불린다.
3.6 Kernel Page Tables
시스템이 처음 시작할 때에는 페이지 테이블이 존재하지 않기때문에 페이징을 사용할 수 없다. 페이지 테이블의 초기화는 아키텍처마다 다르게 구현하기 때문에, 여기서는 x86의 방식을 다루겠다. 페이지 테이블 초기화는 두가지 단계로 나뉜다. bootstrap 단계에서는 페이징 유닛을 활성화할 수 있도록 8MiB에 대한 페이지 테이블만 초기화한다. 두번째 단계에서는 나머지 페이지 테이블을 초기화한다. 아래에서 두 단계에 대해 설명한다.
3.6.1 Bootstrapping
arch/i386/kernel/head.S에 있는 어셈블러 함수인 startup_32()가 페이징 유닛을 활성화한다. vmlinuz의 모든 일반적인 커널 코드들은 PAGE_OFFSET + 1MiB를 base address로 사용하도록 컴파일되며, 실제 커널 이미지는 물리 메모리의 첫 메가바이트 (0x00100000)에 로드된다. 0~1MiB까지의 메모리는 일부 장치와 BIOS 사이의 통신 채널로 사용되므로 스킵된다. bootstrap 코드는 페이징 유닛이 활성화되기 전까지 모든 주소에서 PAGE_OFFSET만큼 뺌으로써, 1MiB를 base address로 사용한다. 또한 페이징 유닛을 활성화하기 위해, 8MiB의 물리 메모리을 가상 주소 PAGE_OFFSET에 매핑하는 페이지 테이블을 초기화한다. (역자: 가상 주소 공간은 유저와 커널이 사용하는 공간으로 나뉘는데, 커널이 사용하는 공간이 더 위에 있음. PAGE_OFFSET은 커널의 가상 주소 공간의 시작 지점을 나타냄.)
초기화는 swapper_pg_dir이라는 배열을 정적으로 정의하는 것으로 시작하며, 링커 지시문을 사용하여 0x00101000 위치에 배치한다. 그런 다음 두 페이지 pg0과 pg1에 대한 페이지 테이블 엔트리를 설정한다. 프로세서가 PSE (Page Size Extension) 비트를 지원하는 경우, 이 비트가 설정되어 일반적인 크기 4KiB가 아닌, 4MiB 페이지로 변환된다. pg0과 pg1에 대한 첫번째 포인터는 1-9MiB 영역을 커버하기 위해 배치되고, 두번째 포인터는 PAGE_OFFSET + 1MiB에 배치된다. 이는 페이징이 활성화되면, 커널 이미지에 대해서만 물리 또는 가상 주소를 통해 올바른 페이지로 매핑됨을 의미한다. 커널 페이지 테이블의 나머지는 paging_init()에 의해 초기화된다.
이 매핑이 설정되면, cr0 레지스터에 비트를 설정하여 페이징 유닛을 활성화하며, 즉시 점프가 발생하여 Instruction Pointer (EIP register)가 올바른지 확인한다.
3.6.2 Finalising
paging_init()은 페이지 테이블의 완성을 담당하는 함수이다. x86에서 이 함수의 call graph는 Figure 3.4에서 볼 수 있다.

이 함수는 먼저 pagetable_init()을 호출하여, ZONE_DMA와 ZONE_NORMAL의 모든 물리 메모리의 접근에 필요한 페이지 테이블을 초기화한다. ZONE_HIGHMEM에 해당하는 메모리는 직접 접근될 수 없으므로, 이에 대한 매핑은 임시적으로 설정된다는 것을 기억하라. 커널의 각 pgd_t에 대해서, boot memory allocator를 호출하여 PMD 테이블을 위한 페이지를 할당하며, PSE 비트가 지원되면 이 비트를 설정하여 4KiB대신 4MiB TLB 엔트리를 사용한다. 만약 PSE 비트가 지원되지 않는 경우, 각 pmd_t 엔트리에 대해서 PTE 테이블 페이지가 할당될 것이다. 만약 CPU가 PGE flag를 지원할 경우, 이 비트 또한 설정되어, 페이지 테이블 엔트리를 모든 프로세스들이 볼 수 있게 만든다.
다음으로, pagetable_init() 함수는 fixrange_init()을 호출하여 FIXADDR_START에서 시작하는 가상 주소 공간 끝에 고정된 주소 공간 매핑을 설정한다. 이러한 매핑은 로컬 APIC 및 kmap_atomic()에 의해 요구되는 FIX_KMAP_BEGIN과 FIX_KMAP_END 사이의 원자적인 kmapping 등의 목적으로 사용된다. 마지막으로, 이 함수는 kmap()을 통해 일반 high memory 매핑에 필요한 페이지 테이블 엔트리를 초기화하기 위해 fixrange_init()을 다시 호출한다.
pagetable_init()이 반환된 후, 커널 공간의 페이지 테이블은 완전히 초기화된 상태이다. 따라서 정적 PGD 테이블 (swapper_pg_dir)이 CR3 레지스터에 로드되어, 페이징 유닛이 이제 해당 테이블을 사용하게 된다.
paging_init()의 다음 작업은 각 PTE를 PAGE_KERNEL protection flag로 초기화하기 위해 kmap_init()을 호출하는 것이다. 마지막 작업은 모든 zone 구조체를 초기화하는 zone_sizes_init()을 호출하는 것이다.
3.7 Mapping addresses to a struct page
리눅스는 자신의 가상 주소를 물리 주소로, struct page를 페이지의 물리 주소로 빠르게 변환할 수 있어야한다. 리눅스는 mem_map 배열의 가상 및 물리 메모리 상의 위치를 알고 있음으로써 이를 달성한다 (mem_map 배열은 전역 배열로, 시스템의 물리 메모리를 표현하는 모든 struct page에 대한 포인터들을 저장한다). 아키텍처마다 이를 달성하는 방식이 다르므로, 설명의 편의를 위해 x86에 대해서만 다루겠다. 이 절에서는 먼저 물리 주소가 커널 가상 주소로 어떻게 매핑되는 지 설명하고, 이것이 mem_map 배열에 어떤 의미를 가지는 지 논의할 것이다.
3.7.1 Mapping Physical to Virtual Kernel Addresses
3.6절에서 보았듯이, 리눅스는 0부터 시작하는 물리 주소를 PAGE_OFFSET(x86의 경우 3GiB)부터 시작하는 가상 주소에 매핑한다. 이는 모든 가상 주소가 단순히 PAGE_OFFSET만큼 뺌으로써 물리 주소로 변환될 수 있음을 의미하며, 이는 정확히 virt_to_phys() 함수가 __pa() 매크로로 하는 일과 동일하다:
/* from <asm-i386/page.h> */
132 #define __pa(x) ((unsigned long)(x)-PAGE_OFFSET)
/* from <asm-i386/io.h> */
76 static inline unsigned long virt_to_phys(volatile void * address)
77 {
78 return __pa(address);
79 }반대로 변환하는 작업은 단순히 PAGE_OFFSET을 더하면 되며, 이는 phys_to_virt() 함수가 __va() 매크로를 사용하여 수행한다. 다음으로 우리는 이것이 struct page를 물리 주소로 매핑하는 데 어떤 도움을 주는 지 살펴볼 것이다.
3.7.2 Mapping struct pages to Physical Addresses
3.6.1절에서 보았듯이, 커널 이미지는 물리 주소 1MiB에 위치하여 가상 주소 PAGE_OFFSET + 0x00100000로 변환되며, 8MiB가 이미지를 위해 예약된다. 이 때문에 커널이 사용가능한 메모리가 0xC0800000부터 시작한다고 생각할 수 있지만, 이는 사실이 아니다. 리눅스는 16MiB의 메모리를 ZONE_DMA를 위해 예약하므로, 커널은 0xC1000000부터 메모리를 할당할 수 있다. 이곳에 보통 mem_map 배열이 위치한다. ZONE_DMA 메모리도 여전히 사용될 것이지만, 무조건 필요할 때만 할당된다.
우리는 물리 주소를 mem_map 배열의 인덱스로 사용하여 struct page로 변환할 수 있다. 물리 주소를 PAGE_SHIFT 비트만큼 right shift를 취하면 PFN을 구할 수 있는데, 이는 또한 mem_map 배열에서의 인덱스로 사용할 수 있다. 이는 정확히 <asm-i386/page.h>의 virt_to_page()가 하는 일이다:
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))virt_to_page() 매크로는 가상 주소인 kaddr를 인자로 받아, __pa()로 물리주소로 변환하고, 물리 주소를 PAGE_SHIFT 비트만큼 right shift를 취하여 PFN을 구한 다음, PFN을 mem_map의 인덱스로 사용하여 struct page의 주소를 반환한다. struct page를 물리 주소로 변환하는 매크로는 제공되지 않지만, 어떻게 구현할 수 있을 지는 여러분도 생각할 수 있을 것이다. (역자: struct page의 주소에서 mem_map의 주소를 뺀 값이 PFN일 것이다.)
3.8 Translation Lookaside Buffer (TLB)
프로세서가 가상 주소를 물리 주소로 변환하기 위해서는, 원하는 PTE를 찾기 위해 모든 레벨의 페이지 테이블 탐색이 필요하다. 이는 각 명령어들이 메모리를 참조할 때, 실제로는 페이지 테이블 순회를 위한 추가적인 메모리 접근이 발생함을 의미한다. 상당한 오버헤드가 발생하는 것을 막기 위해, 아키텍처들은 대부분의 프로세스들의 reference locality, 즉 대부분의 접근이 소수의 페이지에 해당한다는 특성을 활용한다. 그들은 이 특성을 활용하기 위해, 가상 주소의 변환 자체를 캐싱하는 작은 메모리인 TLB를 제공한다.
리눅스는 대부분의 아키텍처가 TLB를 지원한다고 가정한다. 그러나, 아키텍처 독립적인 코드는 TLB의 동작을 알 수 없기 때문에, 코드 여기저기서 TLB 관련 동작을 필요로 할때 아키텍처 의존적인 TLB 동작을 수행하는 hook를 사용한다. 예를 들어, page fault가 수행되어 페이지 테이블이 수정된 경우, 프로세서는 변경된 가상 주소 매핑을 TLB에 갱신해줘야 할 수도 있다.
모든 아키텍처가 이러한 hook를 필요로 하는 것은 아니지만, 필요로 하는 아키텍처가 존재하기 때문에 hook는 필요하다. 만약 hook를 필요로 하지 않는 경우, hook는 null operation으로 정의되어 컴파일 타임에 최적화되어 사라지게된다.
TLB API hook들은 대부분 <asm/pgtable.h>에 선언되며, Table 3.2와 Table 3.3에서 확인할 수 있다. 또한 API들은 Documentation/cachetlb.txt에 잘 설명되어 있다. 단 하나의 TLB flush 함수만을 사용하는 것도 가능은 하지만, TLB flush와 TLB refill은 굉장히 비싼 작업이기 때문에, 가능하다면 불필요한 TLB flush는 무조건 피해야한다. 예를 들어, context switch 과정에서, 리눅스는 4.3절에서 더 논의될 Lazy TLB Flushing 기법을 사용하여 새로운 페이지 테이블을 TLB에 로드하는 것을 미루려고 할 것이다.
| 함수 | 설명 |
|---|---|
| void flush_tlb_all(void) | 가장 비싼 TLB flush 작업으로, 시스템의 모든 프로세서들의 TLB 전체를 flush한다. 작업이 완료되면, 페이지 테이블에 대한 모든 수정이 global하게 동기화된다. vfree() 또는 PKMap의 flush 이후 커널 페이지 테이블이 수정된 경우, 전역에서 접근가능한 테이블이기 때문에 이 함수가 필요하다. |
| void flush_tlb_mm(struct mm_struct *mm) | 인자로 받은 mm_struct의 유저 공간 부분 (PAGE_OFFSET 밑의 주소)에 해당하는 모든 TLB 엔트리를 flush한다. MIPS와 같은 몇몇 아키텍처에서는 모든 프로세서에 대해 flush를 해야하지만, 대부분은 로컬 프로세서에 대해서만 수행한다. fork를 위해 dup_mmap()이 모든 주소 매핑을 복제했거나, exit_mmap()에 의해 모든 매핑이 삭제된 경우와 같이, 전체 주소 공간에 영향을 주는 작업이 수행된 경우에만 이 함수가 호출된다. |
| void flush_tlb_range(struct mm_struct *mm, unsigned long start, unsigned long end) | 이름에서 알 수 있듯이, 이 함수는 mm의 주어진 주소 범위에 해당하는 엔트리들을 flush한다. mremap()이 region을 옮겼거나, mprotect()가 권한을 변경한 경우처럼, 일부 region이 옮겨졌거나 변경된 경우 이를 사용한다. munmap()으로 region을 unmap하는 경우 tlb_finish_mmu()를 호출하는데, 이는 flush_tlb_range()를 똑똑하게 사용하기 위해 노력한다. 이 API는 단순히 flush_tlb_page()를 반복하는 것보다 특정 범위의 TLB 엔트리들을 flush하는 것이 더 빠른 아키텍처에서만 제공된다. |
| 함수 | 설명 |
|---|---|
| void flush_tlb_page(struct vm_area_struct *vma, unsigned long addr) | 예상했겠지만, 이 API는 TLB에서 한 페이지를 flush한다. 가장 많이 사용하는 두가지 케이스가 존재하는데, 하나는 page fault가 발생한 경우이고, 나머지는 page out된 경우이다. |
| void flush_tlb_pgtables(struct mm_struct *mm, unsigned long start, unsigned long end) | 이 API는 페이지 테이블이 해체되고 해제될 때 호출된다. 일부 플랫폼에서는 가장 낮은 레벨의 페이지 테이블 (i.e. PTE 테이블을 저장하는 페이지) 자체를 캐싱하는데, 해당 페이지들이 삭제된다면 이또한 flush되어야 한다. region이 unmap되거나, 페이지 디렉토리 엔트리들이 회수되는 경우 이 함수가 호출된다. |
| void update_mmu_cache(struct vm_area_struct *vma, unsigned long addr, pte_t pte) | 이 API는 page fault가 완료된 후에만 호출된다. 이는 아키텍저 의존적인 코드에게 pte에 가상 주소 addr에 대한 변환이 저장되었음을 알려준다. 이 정보를 어떻게 사용할 지는 아키텍처가 결정한다. Sparc64의 경우, 이 정보를 사용하여 로컬 CPU가 D-Cache를 flush 해야하는 지, 또는 원격 프로세서에 IPI를 전송해야하는 지를 결정한다. |
3.9 Level 1 CPU Cache Management
리눅스는 CPU Cache를 TLB와 매우 비슷한 방식으로 관리하는데, 이 절에서는 리눅스가 CPU Cache를 어떻게 활용하고 관리하는 지 다룬다. CPU Cache는 TLB와 마찬가지로 프로그램의 접근 locality를 활용한다. CPU는 데이터를 메인 메모리에서 가져오는 빈도를 줄이기 위해, 작은 양의 데이터를 CPU Cache에 캐싱한다. 대부분 CPU에는 2 레벨의 캐시가 존재하지만, 리눅스에서는 L1 cache에만 관심을 가진다 (L1 cache, L2 cache라고 불리며, L2 cache는 L1 cache보다 느리지만 큰 용량을 가진다).
CPU cache는 라인으로 구성된다. 각 라인은 보통 32 바이트로 크기가 작으며, 라인의 크기로 align된다. 즉, 32B의 캐시라인은 32B로 주소가 align된다. 리눅스에서는 L1_CACHE_BYTES가 라인의 크기를 나타내며, 각 아키텍처마다 그 값을 정의한다.
주소가 캐시라인에 매핑되는 방식은 아키텍처마다 다르지만, 보통 direct mapping, associative mapping, 그리고 set associative mapping 중 하나의 방법이 사용된다. Direct mapping은 가장 간단한 방법으로, 각 주소는 오로지 하나의 캐시라인에만 매핑될 수 있다. Associative mapping에서는, 모든 주소가 모든 캐시라인에 매핑될 수 있다. Set associative mapping은 하이브리드 방식으로, 주소가 특정 집합의 캐시라인에만 매핑될 수 있지만, 그 안에서는 어떤 캐시라인에든 매핑될 수 있다. 어떤 방식을 사용하느냐에 상관없이, 한 가지 공통점이 존재하는 데, 그것은 캐시라인 크기로 align되고, 인접한 두 주소는 서로 다른 캐시라인을 사용할 확률이 높다는 것이다. 그러므로 리눅스는 캐시 히트율을 높이기 위하 간단한 트릭들을 사용한다:
- 구조체의 자주 사용되는 필드를 구조체의 시작부분에 몰아넣어서, 인기있는 필드가 한 캐시라인에 포함될 확률을 높인다.
- CPU끼리의 false sharing을 최소화하기 위해, 한 구조체내의 관련없는 필드들끼리는 최소 캐시라인 크기만큼은 떨어져있도록 한다.
- mm_struct cache와 같은 general cache의 object들은 L1 CPU cache에 align하여 false sharing을 피한다.
만약 CPU가 캐시에 없는 주소를 접근하면, 캐시 미스가 발생하고, 메인 메모리에 접근하게 된다. 캐시에 대한 접근은 10ns 이내에 수행되지만, 메인 메모리에 대한 접근은 100ns에서 200ns사이의 시간이 걸리기 때문에, 캐시 미스의 오버헤드는 꽤 큰 편이다. 기본적인 목표는 가능한 한 많은 캐시 히트를 얻고 캐시 미스는 최소화하는 것이다.
어떤 아키텍처는 TLB을 자동으로 관리하지 않는 것처럼, 일부는 그들의 CPU cache를 자동으로 관리하지 않는다. 따라서 TLB와 마찬가지로 캐시 관리를 위한 hook을 사용하는데, 이들은 페이지 테이블을 업데이트하는 것과 같이, 가상/물리 주소 매핑이 변경되었을 때 사용된다. 일부 CPU는 캐시에서 가상 주소가 flush될 때 가상/물리 주소 매핑이 필요하므로, 캐시 flush는 항상 먼저 수행되어야 한다. 적절한 순서가 중요한 세가지 작업은 Table 3.4에 나열되어 있다.
| Flushing Full MM | Flushing Range | Flushing Page |
|---|---|---|
| flush_cache_mm() | flush cache_range() | flush_cache_page() |
| 모든 페이지 테이블을 수정 | 페이지 테이블 범위를 수정 | PTE 1개 수정 |
| flush_tlb_mm() | flush_tlb_range() | flush_tlb_page() |
캐시를 flush하는 데 사용되는 API는 <asm/pgtable.h>에 선언되어 있으며, Table 3.5에 나열되어 있다. 여러 측면에서 이 API는 TLB flush API와 매우 유사하다.
| 함수 | 설명 |
|---|---|
| void flush_cache_all(void) | 가장 비싼 캐시 flush API로, 시스템의 모든 CPU cache를 flush한다. 커널 페이지 테이블에 대한 수정이 필요한 경우 사용된다. |
| void flush_cache_mm(struct mm_struct mm) | 특정 주소 공간에 대한 모든 캐시라인을 flush한다. 작업 완료 후에 mm과 관련된 캐시라인은 없을 것이다. |
| void flush_cache_range(struct mm_struct *mm, unsigned long start, unsigned long end) | 주소 공간의 주어진 범위에 해당하는 캐시라인을 flush한다. TLB와 마찬가지로, 개별 페이지에 대한 flush보다 범위에 대한 flush가 더 빠를 때에만 이 API가 제공된다. |
| void flush_cache_page(struct vm_area_struct *vma, unsigned long vmaddr) | 한 페이지에 속한 캐시라인만 flush한다. vma->vm_mm을 통해서 mm_struct를 쉽게 접근할 수 있기 때문에 VMA를 인자로 받는다. 추가적으로, VM_EXEC flag를 테스트하여 명령어를 위한 캐시와 데이터를 위한 캐시를 구분하는 아키텍처가 해당 영역이 실행가능한 지를 판단할 수 있게 해준다. VMA는 4장에서 더 자세히 다룬다. |
여기서 끝이 아니다. virtual aliasing 문제를 피하기 위해서는 추가적인 API들이 필요하다. 캐시라인을 가상 주소 기반으로 매핑하는 경우, 한 물리 주소에 대해서 여러 캐시라인이 존재할 수 있게되는데, 이로 인한 캐시 일관성 문제를 virtual aliasing 문제라고 한다. 이 문제가 있는 아키텍처는 shared mapping이 주소를 임시 조치로만 사용하도록 보장하려고 시도할 수도 있다. 그러나, 이 문제를 다루기 위한 적절한 API 또한 제공되며, Table 3.6에서 확인할 수 있다.
| 함수 | 설명 |
|---|---|
| void flush_page_to_ram(unsigned long address) | 2.6부터 완전히 제거되어 더이상 사용되지 않는 낡은 API이다. 여기서 다루는 이유는 이전 버전에서는 여전히 사용되기 때문이다. 이 함수는 새로운 물리 페이지가 프로세스의 주소공간에 매핑되려고 할 때 사용된다. 매핑이 발생한 후 커널 공간에서의 쓰기가 유저 공간에서 보이지 않는 것을 방지하기 위해 이 API가 요구된다. |
| void flush_dcache_page(struct page *page) | 커널이 page cache를 쓰거나 복사할 때 이 API를 사용하는데, 그 이유는 page cache는 여러 프로세스에 의해 매핑되었을 가능성이 높기 때문이다. |
| void flush_icache_range(unsigned long address, unsigned long endaddr) | 커널 모듈이 로드된 경우와 같이, 커널이 실행될 가능성이 높은 데이터를 쓴 경우 이 API를 호출한다. |
| void flush_icache_user_range(struct vm_area_struct *vma, struct page *page, unsigned long addr, int len) | 유저 공간이 영향을 받았을 때 호출된다는 것을 제외하고는 flush_icache_range()와 유사하다. 현재, 이것은 ptrace()에서 주소 공간이 access_process_vm()에 의해 접근되는 경우에만 사용된다. |
| void flush_icache_page(struct vm_area_struct *vma, struct page *page) | page cache가 매핑되려고 할 때 호출된다. 일부 아키텍처는 VMA flag를 사용하여 I-Cache와 D-Cache 중 어떤 것을 flush할 지 결정한다. |
3.10 What's New In 2.6
페이지 테이블 관리의 대부분의 메커니즘은 2.6에서 본질적으로 동일하지만, 도입된 변경사항은 매우 광범위하며 심도있는 구현이 존재한다.
MMU-less Architecture Support
mm/nommu.c라는 새로운 파일이 등장했다. 이 소스파일은 mmap()과 같이 MMU의 존재를 가정하고 구현된 코드의 대체 코드를 포함한다. 해당 코드는 microcontroller와 같이 MMU가 없는 아키텍처를 지원한다. 이 작업은 uCLinux 프로젝트에 의해 대부분 개발되었다 (http://www.uclinux.org).
Reverse Mapping
페이지 테이블에 있어서 가장 방대하고 중요한 변화는 바로 Reverse Mapping (rmap)의 등장이다. "rmap"이라는 용어는 의도적으로 사용되고 있다. 이것은 이 용어의 일반적인 사용법을 반영하며, reverse mapping만이 아니라 다양한 변경 사항을 포함하는 Rik van Riel의 -rmap 트리와 혼동하지 않아야 한다.
rmap은 주어진 struct page에 대해서 이를 가리키는 모든 PTE들을 찾을 수 있게 해준다. 2.4에서는, (shared library와 같은) 공유 페이지를 가리키는 모든 PTE를 찾기 위해서는, 모든 프로세스의 모든 페이지 테이블을 탐색해야했다. 이 과정은 너무 오래걸리기 때문에 리눅스는 swap cache를 이용하여 오버헤드를 줄이고자 했다 (11.4절 참조). 이것은 공유 페이지가 많이 사용되는 경우, 페이지의 age 또는 사용 패턴과 상관없이 프로세스 전체를 swap out 할 수도 있다는 것을 의미한다. 2.6은 이러한 방법 대신에 struct page마다 PTE chain을 둬서 페이지를 가리키는 모든 PTE들을 엮어둔다. PTE chain은 추후에 해당 페이지를 페이지 테이블로부터 지우고 싶을 때 순회될 것이다. 이를 통해, 전체 프로세스를 swap out하는 대신 LRU 방식으로 똑똑하게 페이지를 swap out할 수 있다.
이 간단한 개념의 구현은 여러분이 상상할 수 있듯이 조금 복잡하다. 구현을 이해하기위해서는 먼저 struct page의 필드인 union pte를 알아야한다. 이 유니온은 두 개의 필드, struct pte_chain에 대한 포인터인 chain, 그리고 pte_addr_t 타입의 direct로 구성된다. 유니온을 사용하는 이유는 page를 가리키는 PTE가 하나만 있을 경우 chain 대신에 pte 주소를 direct에 저장함으로써 메모리를 아끼기 위함이다. pte_addr_t 타입은 아키텍처마다 서로 다르지만, 이것이 무슨 타입이든 간에 PTE를 찾기위해 사용될 수 있으므로 우리는 편의를 위해 이것을 pte_t처럼 사용할 것이다.
struct pte_chain은 조금 더 복잡하다. 구조체 자체는 굉장히 단순하지만 과부화된 변수가 빽빽히 모여있고, 더 작고 효율적으로 만들기 위한 수많은 노력이 들어가있다. 다행히도, 이러한 최적화가 구조체를 이해할 수 없게 만들지는 않는다.
먼저, struct pte_chain들은 slab allocator가 할당 및 관리하는데, slab allocator가 이러한 작업을 제일 잘하기 때문이다. 각 struct pte_chain은 PTE 구조체에 대한 포인터를 NRPTE개까지 보유할 수 있다. 많은 PTE들이 채워진 경우, 새로운 struct pte_chain이 할당되고 chain에 추가된다.
struct pte_chain은 두개의 필드를 가진다. 첫번째는 unsigned long next_and_idx로 두가지의 목적을 가진다. NRPTE와 AND 연산을 취하는 경우, 그 값은 struct pte_chain에 몇 개의 PTE가 채워져있는 지를 의미하며, 즉, 다음 free slot의 인덱스를 의미한다. next_and_idx가 (~NRPTE)와 AND 연산을 취한 경우에는, chain상에서 다음 struct pte_chain의 포인터를 반환한다. 이것이 PTE chain을 구현하는 기본적인 방식이다.
rmap의 복잡함을 맛보기위해, 새로운 PTE가 page를 매핑하는 경우에 대해서 생각해보자. 먼저 할일은 pte_chain_alloc()을 이용하여 새로운 pte_chain을 할당하는 것이다. 할당된 pte_chain은 struct page, PTE와 함께 page_add_rmap()의 인자로 들어간다. 이 함수는 해당 페이지의 PTE chain에 free slot이 있는 struct pte_chain이 있는 경우, 해당 pte_chain이 사용하고 새로 할당되었던 pte_chain을 반환한다. 만약 빈 자리가 없다면, 할당되었던 pte_chain을 PTE chain에 추가하고 NULL을 반환한다.
chain을 생성하고, PTE를 chain에 추가하고 제거하는 일을 도와주는 상당한 양의 API가 있지만, 이를 모두 나열하는 것은 이 절의 범위를 벗어난다. 다행히도, 해당 API는 mm/rmap.c에 정제되어 있으며 주석이 자세하게 달려있어, 그 목적을 명확하게 알 수 있다.
Reverse mapping은 pageout과 관련된 두가지 이점을 가져다준다. 첫번재는 페이지 테이블의 생성과 해체와 관련된 것이다. 11.4절에서 다루겠지만, page out된 페이지들은 swap cache에 위치하며, 해당 페이지들을 다시 가져오기 위해서는 위치에 대한 정보가 PTE에 기록되어야 한다. 이로 인해 페이지가 swap cache에 들어갔다가 다시 프로세스에 의해 참조되면서 여러 번의 minor fault가 발생할 수 있다. rmap을 사용하면 PTE의 설정과 제거가 원자적으로 이루어진다. 두 번째 주요 장점은 페이지를 page out할 때 해당 페이지를 참조하는 모든 PTE를 찾는 것이 간단하지만, 버전 2.4에서는 불가능했기 때문에 swap cache를 사용해야 했다는 점이다.
그러나 Reverse mapping에도 단점은 있다. 첫번째는 명백한 것이지만, PTE chain에 필요한 추가 공간이다. 두번재는 논쟁의 여지가 있지만, reverse mapping과 관련된 CPU 비용이다. 이는 큰 영향이 있다고 증명되지는 않았다. 중요한 것은 page out이 자주 발생할 때에만 reverse mapping이 이득이 된다는 것이다. 시스템의 작업량이 적어 page out이 거의 발생하지 않거나 메모리가 충분하면, reverse mapping은 비용만 발생하고 이점이 거의 없다. 작성 당시에도 rmap의 장단점은 계속 논의되고 있다.
Object-Based Reverse Mapping
Reverse mapping을 모든 페이지별로 저장하는 것은 메모리를 많이 요구한다. 더욱 문제인 것은 VMA의 reverse mapping된 많은 페이지가 실질적으로 동일하다는 것이다. 이 문제를 해결하는 한가지 방법은 개별 페이지 단위가 아니라 VMA 단위로 reverse mapping을 관리하는 것이다. 즉, 각 페이지 단위로 reverse mapping을 가지는 대신, 해당 페이지를 매핑하고 있는 VMA를 탐색하여 페이지를 찾게 될 것이다. 여기서의 객체는 VMA를 말하는 것이지, 객체 지향 프로그래밍에서의 객체가 아님에 주의하라. 글을 쓰는 시점에서, 이 기능은 아직 merge되지 않았으며 kernel 2.5.68-mm1에서 마지막으로 보였다. 그러나 이것은 관련된 문제들만 해결된다면 강한 이점을 가지고 있다. 궁금한 사람들은, file/device backed objrmap에 대한 패치를 확인해보아라.
페이지를 매핑하고 있는 모든 PTE를 접근해야하는 작업은 두가지가 있다. 첫번째는 page_referenced()로, 페이지가 최근에 접근되었는 지를 확인하기위해 페이지를 가리키는 모든 PTE들을 체크한다. 두번째는 try_to_unmap()으로, 모든 프로세스로부터 페이지를 unmap하기 위해서 모든 PTE를 접근한다. 더 복잡한 이야기를 하자면, reverse mapping을 필요로하는 매핑에는 file/device-backed page와 anonymous page로 두가지 타입이 존재한다. 두 경우 모두 특정 페이지를 매핑하고 있는 모든 VMA를 순회하고, VMA의 페이지 테이블을 walk하여 PTE를 얻는 것이 목적이지만, 구현된 방식이 서로 다르다. file과 같은 것으로 백업되어있는 케이스가 제일 다루기 쉬운 케이스이므로 구현이 먼저 되었고, 여기서도 먼저 설명하겠다. 구현을 설명하기 위한 목적으로, 우리는 page_referenced()가 어떻게 구현되었는 지를 논의할 것이다.
page_referenced()는 페이지를 매핑하고 있는 VMA의 모든 PTE를 찾아주는 top-level 함수인 page_referenced_obj()를 호출한다. 페이지가 file이나 device를 위해 매핑되었다면, page->mapping은 유효한 address_space를 가리킨다. address_space에는 address_space->i_mmap 및 address_space->i_mmap_shared 필드를 통해 매핑을 사용한는 모든 VMA를 포함하는 두 개의 linked list가 있다. 이 리스트에 속한 모든 VMA에 대해서, VMA와 page를 인자로 page_referenced_obj_one() 함수가 호출된다. page_referenced_obj_one()은 페이지가 VMA에 의해 관리되는 address에 속해있는 지를 확인하며, 만약 그렇다면 VMA가 속한 mm_struct의 페이지 테이블을 순회하여 PTE 엔트리를 찾아낸다.
Anonymous page의 추적은 좀 더 까다로우며 더 많은 단계로 구현되어 있다. 해당 구현은 잠깐 등장했다가 다른 변경사항들과 충돌이 있어 2.5.65-mm4에서 다시 삭제되었다. 구현의 첫번째 단계는 page->mapping과 page->index를 사용하여 mm_struct와 address 쌍을 추적하는 것이다. 이 필드들은 swapper_space와 swp_entry_t에 대한 포인터를 저장했었다 (11장 참조). 이에 대한 자세한 설명은 이 절의 범위를 벗어나지만, 요약하자면 swp_entry_t는 page->private에 저장된다.
try_to_unmap_obj() 또한 비슷한 방식으로 동작하고, 개별 페이지를 reverse mapping할 필요 없이 해당 페이지를 참조하는 모든 PTE를 처리할 수 있다. 하지만 심각한 검색 복잡성 문제가 있어 이 기능이 통합되지 못하고 있다. 그 문제는 다음과 같은 시나리오에서 나타난다.
한 파일을 매핑하는 100개의 VMA를 가진 100개의 프로세스가 있다고 가정하자. object-based reverse mapping을 사용하여 단 한개의 페이지를 unmap하기 위해서는 10,000개의 VMA들이 탐색되어야 하며, 이 중 대부분은 불필요한 탐색이 될 것이다. page 기반 reverse mapping 방식에서는, 총 100개의 pte_chain 슬롯만이 탐색되어야하며, 프로세스당 1개만 탐색하면 된다. address_space의 VMA를 가상 주소로 정렬하는 최적화 기법이 제안됬지만, 여전히 merge되기에는 오버헤드가 너무 크다.
PTEs in High Memory
커널이 페이지 테이블 워킹을 하는 동안 그들을 직접 접근할 수 있어야하기 때문에, 2.4에서는 페이지 테이블을 ZONE_NORMAL에 저장했다. 그러나 메모리가 많은 머신에서는 페이지 테이블 엔트리개수가 많기 때문에 문제가 된다. 2.6에서는 이를 해결하기위해 PTE를 high memory에 저장한다.
9장에서 얘기하겠지만, high memory에 대한 매핑 정보는 제한적이기 때문에, PTE를 high memory에 옮기는 것은 컴파일 타임 configuration 옵션이다. high memory의 페이지에 접근하기 위해서 커널은 낮은 주소 공간에 이를 매핑해야하는데, 이러한 매핑을 위한 자리가 굉장히 부족하기 때문에 골치아픈 병목현상이 발생한다. 그러나 PTE가 매우 많은 어플리케이션에게는 다른 옵션이 없다. 글을 쓰고있는 시점에, 프로세스마다 private하게 할당되는 커널 주소 공간인 User Kernel Virtual Area (UKVA)가 제안되었지만, 이것이 2.6에 merge될 지는 미지수다.
High memory 매핑을 고려하기 위해, pte_offset() 매크로는 2.6에서 pte_offset_map()으로 대체된다. 만약 PTE가 low memory에 위치한다면, 이 매크로는 pte_offset()과 동일한 방식으로 PTE의 주소를 반환한다. 만약 PTE가 high memory에 있다면, 먼저 PTE를 kmap_atomic()을 통해 low memory에 매핑하여 커널이 접근할 수 있게 한다. 이 PTE는 최대한 빨리 pte_unmap()을 통해 다시 unmap되어야한다.
프로그래밍 관점에서 이는 페이지 테이블 워크 코드의 생김새가 약간 달라졌음을 의미한다. 주어진 주소에서 PTE를 찾는 코드는 이제 다음과 같다 (mm/memory.c):
640 ptep = pte_offset_map(pmd, address);
641 if (!ptep)
642 goto out;
643
644 pte = *ptep;
645 pte_unmap(ptep);추가적으로, PTE 할당 API도 바뀌었다. pte_alloc() 대신에, 커널 PTE 매핑은 pte_alloc_kernel()을, 유저 매핑은 pte_alloc_map()을 사용한다. 둘의 차이점은 pte_alloc_kernel()은 절대로 high memory에서 PTE를 할당하지 않는다는 점이다.
메모리 관리 관점에서, high memory에 PTE를 매핑하는 오버헤드는 무시할 수 없다. CPU당 PTE의 매핑은 동시에 한 개만 수행할 수 있다. 비록 두번째 PTE의 매핑은 pte_offset_map_nested()로 수행할 수도 있지만, 이러한 사실은 모든 PTE를 검사해야할 때 큰 오버헤드를 야기한다.
글을 쓰고있는 현재, 동일한 방식으로 PMD를 high memory에 저장하는 패치가 제출됬고, 이는 아마 merge될 것이다.
Huge TLB Filesystem
대부분의 최신 아키텍처는 2개 이상의 페이지 크기를 지원한다. 예를 들어, 많은 x86 아키텍처들은 4KiB 또는 4MiB 페이지를 사용할 수 있다. 전통적으로 리눅스는 large page를 실제 커널 이미지를 매핑하는 데에만 사용할 뿐 다른 목적으로는 사용하지 않았다. 그러나 TLB는 매우 한정된 자원이므로, 특히 대형 메모리 시스템에서는, large page의 이점을 잘 활용하는 것이 중요하다.
2.6에서는 프로세스가 HPAGE_SIZE 크기의 "huge page"를 사용할 수 있다. 사용가능한 huge page의 수는 시스템 관리자가 proc 인터페이스인 /proc/sys/vm/nr_hugepages를 통해 조절할 수 있으며, 이는 결국 set_hugetlb_mem_size() 함수를 호출하게된다. 할당의 성공 여부는 물리적으로 연속된 메모리의 양이 결정하므로, 시스템의 시작 과정에서 할당해야만 한다.
구현의 핵심은 Huge TLB Filesystem (hugetlbfs) 로, fs/hugetlbfs/inode.c에 pseudo-filesystem으로 구현되어 있다. 기본적으로, 이 파일시스템의 각 파일들은 huge page로 매핑된다. 초기화 과정에서, init_hugetlbfs_fs()는 파일시스템을 등록하고 kern_mount()를 통해 내부 파일시스템에 마운트한다.
프로세스가 huge page에 접근하는 방법에는 두 가지가 있다. 첫 번째는 shmget()을 사용하여 huge page들에 매핑된 shared region을 생성하는 것이고, 두 번재는 huge page 파일시스템의 파일에 대해서 mmap()을 호출하는 것이다.
shared memory 영역을 huge page에 매핑하기 위해서는, shmget()을 SHM_HUGETLB 플래그와 함께 호출해야한다. 그러면 hugetlb_zero_setup()이 호출되어 hugetlb 파일시스템에 새로운 파일을 생성하게 된다. 파일은 해당 파일시스템의 루트에 생성되며, 파일의 이름은 shared region이 생성될 때마다 증가되는 atomic counter인 hugetlbfs_counter 값으로 지어진다.
huge page로 매핑되는 파일을 생성하기 위해서는, 시스템 관리자가 먼저 hugetlbfs 타입의 파일시스템을 마운트해야 한다. 자세한 방법은 Documentation/vm/hugetlbpage.txt에 설명되어있다. 파일시스템을 마운트하고나면, 파일은 open() 시스템 콜을 통해 일반 파일과 같이 생성할 수 있다. open된 파일에 대해 mmap()을 호출하면, file_operations로 등록된 hugetlbfs_file_operations 구조체의 hugetlbfs_file_mmap() 함수가 호출되어, 해당 영역을 적절히 초기화한다.
Huge TLB 페이지들에 대해서 페이지 테이블 관리, 주소 공간 동작, 파일시스템 동작을 위한 별도의 함수들이 제공된다. 페이지 테이블 관리를 위한 함수들은 모두 <linux/hugetlb.h>에서 확인할 수 있으며, 일반 페이지를 위한 것과 유사한 이름을 가지는 것을 확인할 수 있다. hugetlb 함수들의 구현은 normal page의 동일한 기능의 함수와 가까이 위치해있으니 쉽게 찾을 수 있다.
Cache Flush Management
변경사항은 적다. flush_page_to_ram() API가 완전히 제거되었으며, flush_dcache_range() API 함수가 새롭게 등장하였다.
