롤케이크 자르기
문제 설명
철수는 롤케이크를 두 조각으로 잘라서 동생과 한 조각씩 나눠 먹으려고 합니다. 이 롤케이크에는 여러가지 토핑들이 일렬로 올려져 있습니다. 철수와 동생은 롤케이크를 공평하게 나눠먹으려 하는데, 그들은 롤케이크의 크기보다 롤케이크 위에 올려진 토핑들의 종류에 더 관심이 많습니다. 그래서 잘린 조각들의 크기와 올려진 토핑의 개수에 상관없이 각 조각에 동일한 가짓수의 토핑이 올라가면 공평하게 롤케이크가 나누어진 것으로 생각합니다.
예를 들어, 롤케이크에 4가지 종류의 토핑이 올려져 있다고 합시다. 토핑들을 1, 2, 3, 4와 같이 번호로 표시했을 때, 케이크 위에 토핑들이 [1, 2, 1, 3, 1, 4, 1, 2] 순서로 올려져 있습니다. 만약 세 번째 토핑(1)과 네 번째 토핑(3) 사이를 자르면 롤케이크의 토핑은 [1, 2, 1], [3, 1, 4, 1, 2]로 나뉘게 됩니다. 철수가 [1, 2, 1]이 놓인 조각을, 동생이 [3, 1, 4, 1, 2]가 놓인 조각을 먹게 되면 철수는 두 가지 토핑(1, 2)을 맛볼 수 있지만, 동생은 네 가지 토핑(1, 2, 3, 4)을 맛볼 수 있으므로, 이는 공평하게 나누어진 것이 아닙니다. 만약 롤케이크의 네 번째 토핑(3)과 다섯 번째 토핑(1) 사이를 자르면 [1, 2, 1, 3], [1, 4, 1, 2]로 나뉘게 됩니다. 이 경우 철수는 세 가지 토핑(1, 2, 3)을, 동생도 세 가지 토핑(1, 2, 4)을 맛볼 수 있으므로, 이는 공평하게 나누어진 것입니다. 공평하게 롤케이크를 자르는 방법은 여러가지 일 수 있습니다. 위의 롤케이크를 [1, 2, 1, 3, 1], [4, 1, 2]으로 잘라도 공평하게 나뉩니다. 어떤 경우에는 롤케이크를 공평하게 나누지 못할 수도 있습니다.
롤케이크에 올려진 토핑들의 번호를 저장한 정수 배열 topping이 매개변수로 주어질 때, 롤케이크를 공평하게 자르는 방법의 수를 return 하도록 solution 함수를 완성해주세요.
제한사항
1 ≤ topping의 길이 ≤ 1,000,000
1 ≤ topping의 원소 ≤ 10,000
입출력 예
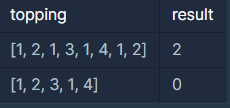
롤케이크를 [1, 2, 1, 3], [1, 4, 1, 2] 또는 [1, 2, 1, 3, 1], [4, 1, 2]와 같이 자르면 철수와 동생은 각각 세 가지 토핑을 맛볼 수 있습니다. 이 경우 공평하게 롤케이크를 나누는 방법은 위의 두 가지만 존재합니다.
입출력 예 #2
롤케이크를 공평하게 나눌 수 없습니다.
첫번째 풀이
> def solution(topping):
answer = 0
for i in range(1,len(topping)):
a=set(topping[:i])
b=set(topping[i:])
if len(a)==len(b):
answer+=1
return answer
> 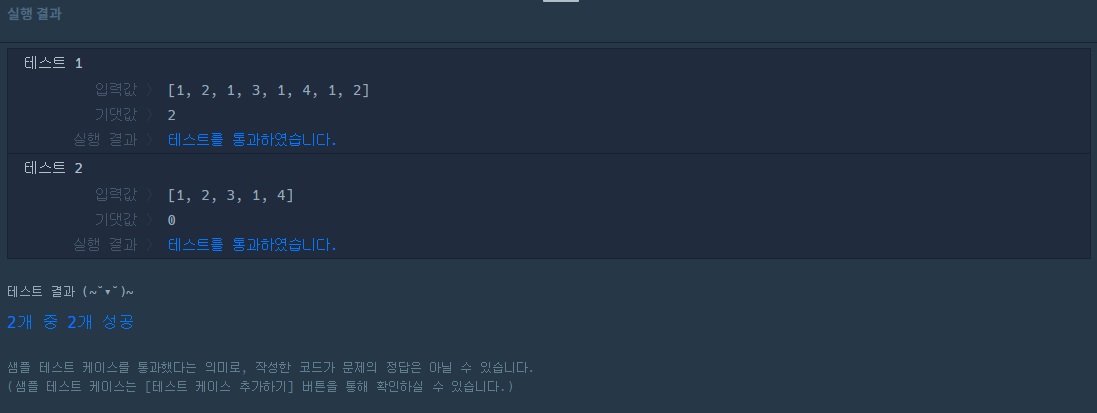
쉽고 간단하게 풀렸다.
-
토핑 리스트 크기만큼 반복하고
-
a, b 변수에 topping을 점차 슬라이싱하여
set으로 묶어줬다. (중복 제거하기 위함) [1,2,3,3,4] -> [1,2,3] -
왼쪽 오른쪽 토핑 수를 비교하여 토핑 수가 갖다면 공평하게 나눈 것이니
나누는 방법인 answer에 1을 더해주었다.
하지만....
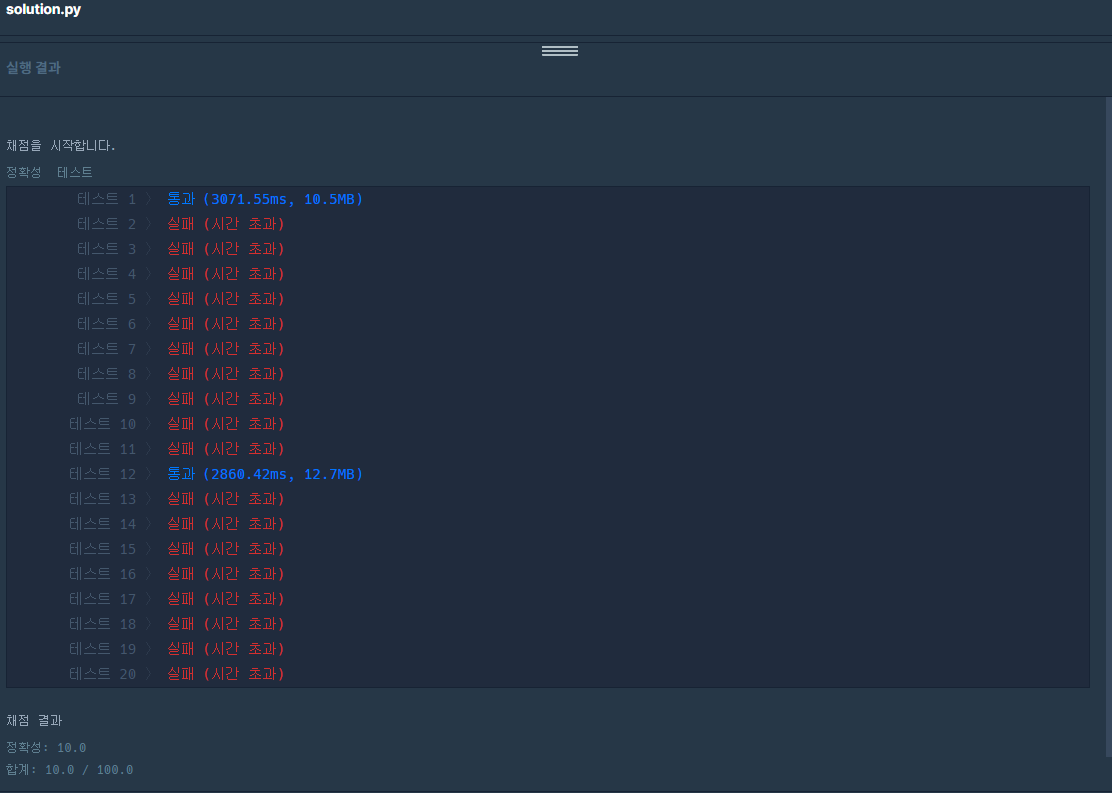
정확성 테스트에서 실패했다.
아직 부족한 나는 다른 방법으론 접근하지 못 해서
다른 사람의 풀이를 참고했다.
정답 코드
from collections import Counter
def solution(topping):
dic = Counter(topping)
set_dic = set()
res = 0
for i in topping:
dic[i] -= 1
set_dic.add(i)
if dic[i] == 0:
dic.pop(i)
if len(dic) == len(set_dic):
res += 1
return rescollections 모듈의 Counter 클래스를 사용하였다.
Counter는 파이썬의 기본 자료구조인 사전(dictionary)를 확장하고 있다.
a = Counter("min mong")
print(a["i"], a["m"])
(1, 2)
해당 값의 개수를 반환해준다.
그리고 특정 키의 값을 갱신할 수도 있고, 사전처럼 사용 가능하다.
Counter("hello world")
Counter({'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1})
dic을 사용하여 처리하지 않았기 때문에 정확성 테스트가 느렸나보다...
위 코드에서 따로 슬라이싱하지 않고
for i in topping:
dic[i] -= 1
set_dic.add(i)for문으로 topping을 꺼내
dic에서는 빼주고
set_dic에는 추가해주면서
topping 리스트 크기만큼 비교해준다.
첫번째 반복에선 dic[i]는 dic[1]이 되고
dic[1]은 4개이므로 하나 뺀 값인 3이 된다.
set_dic에는 1이 추가된다.
이런 식으로 슬라이싱을 사용하지 않고도
저장공간 두개를 활용하여
하나엔 넣고 다른 하나에선 빼면서 나눴다.
if len(dic) == len(set_dic):
res += 1반복할 때마다 넣은 값들을 비교하게 되며
토핑 수가 같다면 res를 하나씩 증가시킨다.
이렇게 하면
테스트 성공이다.