Ⅰ. 논문 요약
KIMI LINEAR: AN EXPRESSIVE, EFFICIENT ATTENTION ARCHITECTURE / Kimi Team
(251101) Kimi Linear - An Expressive, Efficient Attention Architecture.pdf
1. Introduction
LLM이 점차 유능한 ‘에이전트’로 발전함에 따라, Inference 시의 계산 요구사항 - 특히 장기 수평선(long-horizon) 및 강화학습(RL) 환경에서 - 이 중심적인 병목 지점이 되고 있다. 강화학습 테스트 타임 스케일링으로의 이러한 전환, 즉 모델이 추론 시점에 확장된 궤적, 도구 사용 상호작용, 복잡한 의사결정 공간을 처리해야 하는 상황은 표준 어텐션 메커니즘의 근본적인 비효율성을 드러낸다. 특히, 소프트맥스 어텐션의 이차 시간 복잡도와 선형적으로 증가하는 키-값(KV) 캐시는 상당한 계산 및 메모리 오버헤드를 초래하여, 처리량, 컨텍스트 길이 확장, 실시간 상호작용성 등을 저해한다.
반면 선형 어텐션은 계산 복잡도를 줄이는 원칙적 접근법을 제시하지만, 표현력의 제한으로 인해 역사적으로 언어 모델링 - 심지어 짧은 시퀀스에서조차 - 에서 소프트맥스 어텐션에 미치지 못하는 성능을 보였다. 그러나 최근의 발전은 주로 두 가지 혁신 - ‘게이팅/디케이 메커니즘’과 ‘델타 규칙’ - 을 통해 이 격차를 크게 좁혀 나갔다. 이러한 발전들이 함께 작용함으로써 선형 어텐션이 중간 길이 시퀀스에서 소프트맥스 수준에 가까운 성능을 보이도록 끌어올렸다. 그럼에도 불구하고, 순수한 선형 구조는 유한한 상태 용량에 의해 근본적인 제약이 있으며, 긴 시퀀스의 모델링과 문맥 내의 검색을 이론적으로 어렵게 만든다.
이에 소프트맥스와 선형 어텐션을 결합한 하이브리드 아키텍처 - 즉, 주로 빠른 선형 레이어와 함께 몇 개의 전역적 어텐션 레이어를 사용하는 방식 - 가 품질과 효율성 간의 실용적인 절충안으로 부상했다. 그러나 이전의 하이브리드 모델들은 제한된 규모에서만 작동하거나, 다양한 벤치마크에 걸친 포괄적인 평가가 부족했다. 즉, 핵심 과제는 ‘풀 어텐션’과 동등하거나 혹은 그를 능가하는 품질을 유지하면서도 속도와 메모리 모두에서 실질적인 효율성 향상을 달성하는 어텐션 아키텍처를 개발하는 것이며, 이는 차세대 에이전트형, 디코딩 중심 LLM을 가능하게 하는 필수적인 단계이다.
이 연구에서 Kimi Team은 ‘Kimi Linear’를 제시한다. 이는 품질을 저하시키지 않으면서 에이전트 지능과 테스트 타임 스케일링의 효율성 요구를 충족하도록 설계된 하이브리드 선형 어텐션 아키텍처이다. 그 핵심에는 Kimi Delta Attention(KDA)가 있으며, 이는 Gated DeltaNet(GDN)을 더욱 세밀한 게이팅 메커니즘으로 확장한 하드웨어 효율적인 선형 어텐션 모듈이다. GDN이 (Mamba2와 비슷하게) 헤드별(head-wise)로 ‘거친’ 망각 게이트를 사용하는 반면, KDA는 각 특징 차원이 독립적인 망각률을 유지하는 채널별(channel-wise) 변형을 도입하며, 이는 Gated Linear Attention(GLA)과 유사하다. 이와 같은 세밀한 설계는 유한 상태의 RNN 메모리에 대해 더욱 정밀한 조절을 가능하게 하여, 하이브리드 아키텍처 내에서 RNN 스타일 모델의 잠재력을 발휘한다.
결정적으로 KDA는 Diagonal-Plus-Low-Rank(DPLR) 행렬의 특화된 변형으로서 전이 동역학(transition dynamics)을 매개변수화하여, 일반적인 DPLR 공식화에 비해 계산을 실질적으로 줄이는 맞춤형 청크별 병렬 알고리즘을 가능하게 하면서도 고전적 델타 규칙과의 일관성을 유지한다.
Kimi Linear는 KDA를 3:1 비율로 주기적인 풀 어텐션 레이어와 교차 배치한다. 이러한 하이브리드 구조는 긴 시퀀스 생성 중 메모리 및 KV 캐시 사용량을 최대 75%까지 줄이면서, 동시에 풀 어텐션 레이어를 통한 전역 정보 흐름을 보존한다. 동일 규모의 사전학습 및 평가를 통해, Kimi team은 Kimi Linear가 단문맥, 장문맥, RL 스타일의 post training 작업 전반에서 풀 어텐션 베이스라인과 동등하거나 능가하는 성능을 보이면서도, 1M 컨텍스트 길이에서 최대 6배 더 높은 디코딩 처리량을 달성한다는 것을 보여주었다.
Contributions
- Kimi Delta Attention(KDA) : 개선된 순환 메모리 관리 능력과 하드웨어 효율성을 나타내는 ‘gated delta rule’을 정제한 선형 어텐션 메커니즘
- Kimi Linear 아키텍처 : 3:1의 비율로 KDA 대 풀 어텐션을 배치한 하이브리드 설계로, 풀 어텐션 구조의 성능을 능가하면서도 메모리 사용량은 감소시킴
2. Preliminary
이 섹션에서는 Kimi Delta Attention과 관련된 기술적 배경을 정리한다.
2.1. Notation
수학적 표기를 위한 정의
- 기본 벡터 표기
- 또는 : t번째 시간 단계의 벡터
- 는 q(쿼리), k(키), v(값), o(출력), u, w 등의 변수를 대표
- 예: 는 t번째 쿼리 벡터, 는 t번째 키 벡터
- : 행렬 형태의 메모리 상태
- : 키 차원, : 값 차원
- 이 행렬이 키-값 연관성을 저장하는 "메모리"
- 또는 : t번째 시간 단계의 벡터
- 마스크 표기
-
: 대각선을 포함한 하삼각 마스크(Tril)
- 현재 및 이전 시간 단계만 참조 가능(인과적 마스킹)
-
: 대각선을 제외한 하삼각 마스크(StrictTril)
- 이전 시간 단계만 참조 가능이 마스크들은 미래 정보를 보지 못하게 하는 "인과성 제약"을 구현함
-
Chunk-wise Formulation
- 왜 청크가 필요한가?
- 전체 시퀀스를 한 번에 처리하면 메모리 부족 또는 비효율적
- 시퀀스를 작은 "청크"로 나누면 병렬 처리 가능
- 청크 분할: 길이 L인 시퀀스를 길이 C인 청크 L/C개로 분할
- 청크 내 표기
-
: 번째 청크 내의 모든 벡터를 쌓은 행렬
- 예: 는 번째 청크의 모든 쿼리 벡터들
-
: t번째 청크 내 번째 요소
- 전역 인덱스 을 청크 기반으로 표현
-
: 청크의 초기 상태는 이전 청크의 마지막 상태
책을 장으로 나누듯, 시퀀스를 청크로 나눠서 각 청크를 처리하되 이전 청크의 "기억"을 다음 청크로 전달
-
Decay Formulation
- 누적 감쇠의 개념
- 시간이 지나면서 정보가 점차 희미해지는 현상을 수학적으로 모델링
- 기본 정의
- : 부터 까지의 누적 감쇠
- : 각 시간 단계의 망각 게이트(0과 1 사이 값)
- 곱셈으로 누적되므로 시간이 지날수록 값이 작아짐
- : 청크 시작부터 까지의 누적 감쇠(약칭)
- : 부터 까지의 누적 감쇠
- 행렬 형태
- : 감쇠 비율 행렬
- 요소 :
- 에서 로의 상대적 감쇠를 표현
- : 감쇠 비율 행렬
- 세밀한 감쇠 표기
- : 채널별 세밀한 감쇠 (대각 행렬)
- : 누적 감쇠의 대각 행렬 형태
- : 부터 까지 쌓은 행렬
스칼라 감쇠(Mamba2) : 전체 메모리에 동일한 "흐릿함" 적용
채널별 감쇠(GLA, KDA) : 메모리의 각 차원마다 다른 속도로 "페이드 아웃"
2.2. Linear Attention and the Gated Delta Rule
온라인 학습으로서의 선형 어텐션
- 기본 메커니즘
(상태 업데이트)
(출력 계산)- 해석
- : 키-값 연관성을 저장하는 "연관 메모리(associative memory)"
- 빠른 가중치(fast-weight) 관점 : 는 일시적인 매핑을 저장하는 빠르게 변하는 메모리
- 해석
- 온라인 학습 목표
- 무제한 상관관계(unbounded correlation) 목표
- 최근 키-값 쌍을 계속 강화
- 문제점 : 어떤 메모리를 지워야 할지 기준이 없어 간섭(interference) 발생
계속 새로운 내용만 추가하고 지우지 않는 노트처럼, 나중에는 중요한 정보를 찾기 어려워짐
DeltaNet : 재구성 손실에 대한 온라인 경사 하강
- 개선된 목표 함수
- 재구성(reconstruction) 목표
- "가 에 가까워지도록" 유도
- 델타 규칙 유도
- 학습률 로 경사 하강을 수행하면
= =
- 수학적 의미
- : 일반화된 하우스홀더 변환 / k_t 방향의 이전 연관성을 "교정"
- 랭크-1 업데이트 구조 : 하드웨어 효율적인 청크별 병렬화 지원
- 학습률 로 경사 하강을 수행하면
노트에 새로운 내용을 추가할 때, 관련된 이전 내용을 수정(업데이트)하는 것과 같음
단순히 추가만 하는 것보다 정확한 기억 유지가 가능
가중치 감쇠로서의 Gated DeltaNet
- 문제 인식 : DeltaNet도 여전히 오래된 연관성을 무한정 유지
- 해결책 : 스칼라 망각 게이트 도입
=
- α_t의 역할
- 가중치 감쇠(weight decay) 형태의 정규화
- 데이터 의존적 L2 정규화와 유사
- 메모리 수명을 제어하고 간섭 완화
- 장점
- 안정성 향상
- 장문맥 일반화 개선
- DeltaNet의 병렬화 가능 구조 보존
위치 인코딩으로서의 해석
- RoPE와의 연결
- GDN을 다음과 같이 해석 가능
=
- 이는 RoPE의 곱셈적 위치 인코딩과 유사한 형태
- GDN을 다음과 같이 해석 가능
- 차이점
- RoPE : 고정된 회전 행렬 (직교성 유지)
- GDN : 데이터 의존적, 학습 가능 (직교성 제약 완화)
- 잠재적 이점
- RoPE의 고정 주파수는 훈련 중 본 컨텍스트 길이에 과적합 가능
- GDN의 동적 전이는 더 나은 외삽(extrapolation) 가능성 제시
RoPE가 "시계처럼 규칙적으로 회전"한다면, GDN은 "상황에 따라 유연하게 변형"하며, 이는 더 복잡한 위치 관계를 학습할 수 있도록 함
3. Kimi Delta Attention : Improving Delta Rule with Fine-grained Gating
Kimi Delta Attention(KDA)은 GDN의 스칼라 감쇠를 개선한 새로운 Gated Linear Attention 변형으로, 세밀한 Diagonalized Gate 를 도입하여 메모리 감쇠와 위치 인식에 대한 세밀한 제어를 가능하게 한다.
여기서는 먼저 KDA의 청크별 병렬화를 소개하면서, diagonal gating 하에서 안정성을 유지면서도 일련의 랭크-1 행렬 변환이 어떻게 조밀한(dense) 표현으로 압축될 수 있는지를 정리한다. 그리고 KDA가 표준 DPLR(Diagonal-Plus-Low-Rank) 공식화에 비해 얻는 효율성의 향상을 강조한다.
=
=
- GDN : 전체 메모리에 하나의 볼륨 조절기(스칼라 )
- KDA : 메모리의 각 채널마다 독립적인 볼륨 조절기()
→ 각 정보 차원이 자신만의 속도로 희미해지거나 유지될 수 있어, 훨씬 더 정밀한 메모리 관리가 가능
3.1. Hardware-Efficient Chunkwise Algorithm
핵심 아이디어는 KDA의 순환 형태(recurrent form)를 청크 단위로 부분 전개하면 병렬 처리가 가능한 형태로 변환할 수 있다는 것이다.
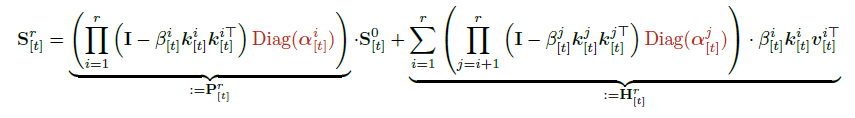
- : 번째 청크 내 번째 위치의 상태
- 첫 번째 항 : 이전 청크에서 전달된 초기 상태 에 적용되는 누적 변환
- 두 번째 항 : 현재 청크 내부에서 생성되는 key-value 업데이트 집합
WY 표현법(WY Representation)
Householder-like rank-1 업데이트를 매번 곱하는 것은 비효율적이다. ‘WY 표현법’은 연속된 rank-1 Householder 형태의 업데이트를 하나의 압축된 표현으로 묶어주는 방법이다. KDA는 Comba[40]의 P 형식을 따라, 이후 계산에서 추가적인 역행렬이 필요 없도록 구성한다.
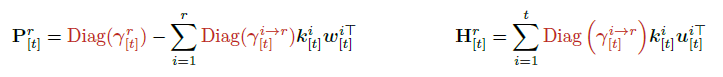
여기서 보조 벡터 , 는 다음 점화식으로 계산된다.
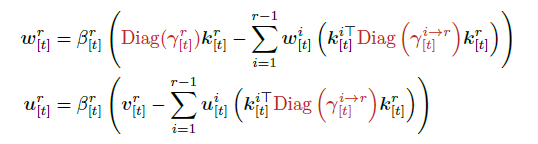
순차적 형태인 RNN의 업데이트를 GPU에서 병렬화하기 위해 Householder-like rank-1 업데이트를 WY 방식으로 묶어 벡터·행렬 연산 형태로 변환함으로써 매우 긴 시퀀스를 빠르게 처리할 수 있다.
UT Transform
UT transform은 행렬 곱(MatMul)이 아닌 연산의 FLOPs을 줄인다. 이것은 하드웨어(특히 GPU Tensor Cores) 활용도를 높이기 위한 핵심이다.
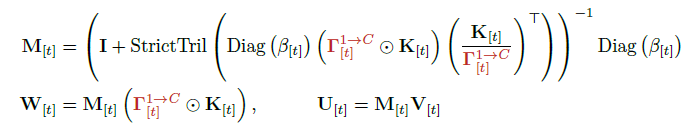
여기에서 StrictTril은 상삼각 제외 하삼각(triangular) 를 의미한다. 하삼각 행렬은 앞에서부터 순차적으로 계산하는 전방 대입(forward substitution) 으로 빠르게 역행렬을 구할 수 있다.
최종적으로, 상태는 다음과 같이 갱신된다.
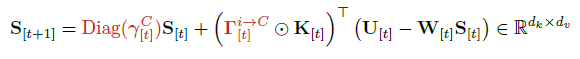
GPU는 큰 매트릭스 곱에는 빠르지만, 작은 행렬의 스칼라 연산이나 for-loop 형태에서는 느린 속도를 보인다. UT는 행렬을 삼각 구조로 변환해 연산량을 대폭 감소시킴으로써 전체 KDA 커널의 계산 속도를 크게 향상시킨다.
3.2 Efficiency Analysis
DPLR 방식의 문제점
KDA는 표현력 측면에서 일반화된 DPLR(Diagonal-Plus-Low-Rank) 구조와 정렬된다. 즉, 다음 형태의 상태 업데이트를 공유한다:
두 방식 모두 fine-grained decay(세밀한 감쇠) 행동을 보이지만, 계산 효율과 수치 안정성 면에서 중요한 차이가 존재한다.
DPLR 기반의 감쇠는 청크 내부 계산에서 ‘감쇠 누적 분석 형태(e.g. 분모)’와 ‘청크 내부 나눗셈(intra-chunk division)’을 사용하는데, 이로 인해 FP16 환경에서 수치 정밀도 문제를 일으키기가 쉽다.
이를 완화하기 위하여 GLA에서 ‘log-domain 계산’과 ‘full-precision secondary chunking(2차 청크 분할)’ 등을 도입했으나, 이는 계산 비용의 증가로 이어졌다.
즉, GLA나 일반적인 DPLR은 빠른 연산이 어렵고 FP16의 성능을 온전히 활용하지 못한다는 문제가 있다.
KDA의 해결 방식
KDA는 이러한 문제를 해결하기 위해 변수 와 를 모두 와 묶음으로써(binding) 이러한 보틀넥을 효과적으로 감소시킨다. 즉, 2차 청크 행렬의 계산 개수를 4개에서 2개로 감소시키고, 이에 더하여 추가적인 행렬곱 3개를 제거한다. 그 결과 KDA의 연산자(operator) 효율은 DPLR 대비 100% 수준으로 향상된다.
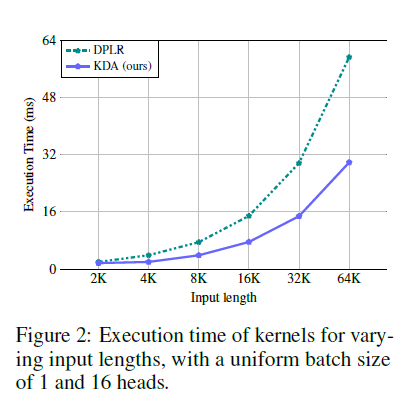
KDA는 다음의 조합을 통해 DPLR 대비 약 2× 효율 개선을 달성한다.
- a, b 변수를 k로 묶어 DPLR 구조 단순화
- second-level chunking 제거
- 3개의 추가 행렬 곱셈 제거
- FP16 환경에서도 안정적인 decay 계산
결과적으로 KDA는 연산량 감소 + 하드웨어 효율 최적화라는 두 가지 목표를 동시에 달성한다.
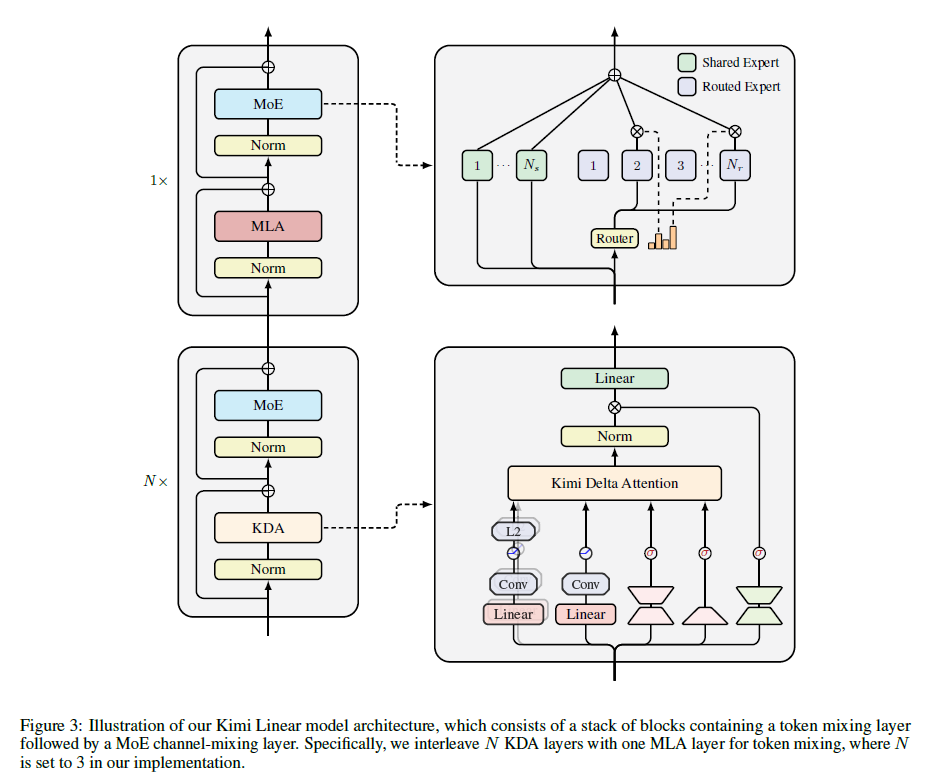
4. The Kimi Linear Model Architecture
Kimi Linear 모델의 기본 백본(backbone)은 Moonlight 아키텍처를 따르며, 세밀한 게이팅(fine-grained gating)에 더해 표현력을 강화하기 위한 여러 구성 요소를 추가적으로 활용하고 있다.
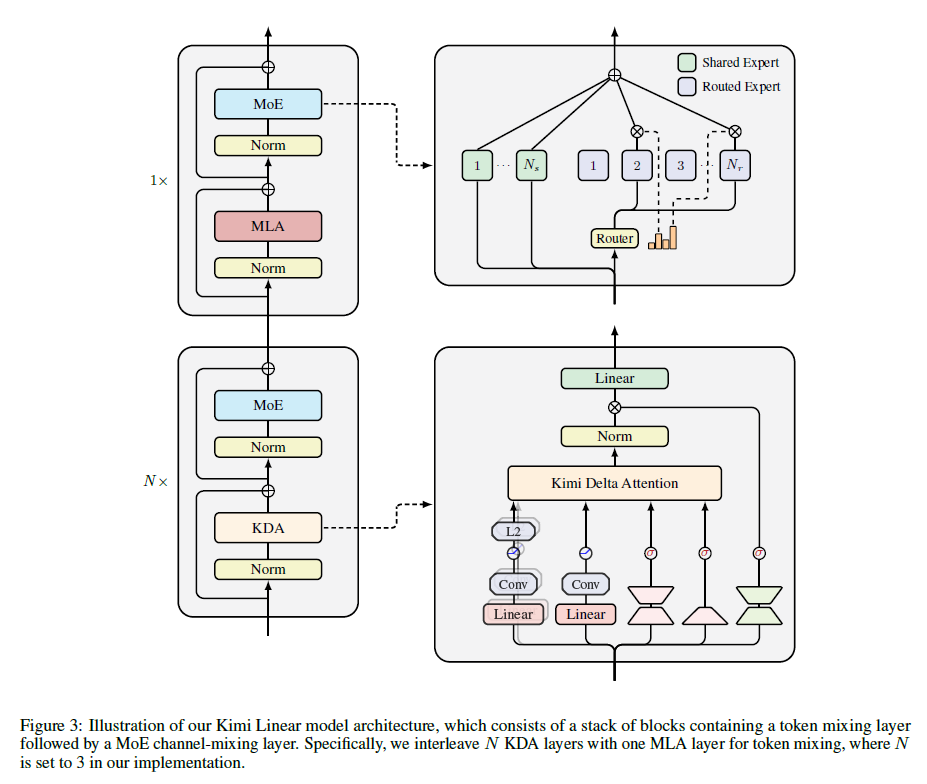
Neural Parameterization
입력 토큰을 라고 할 때, 각 head 에서 KDA로 들어가는 입력은 아래와 같이 계산된다.
- Query/Key : , = L2Norm(Swish(ShortConv()))
- Value : = Swish(ShortConv())
- 채널 단위의 decay gate : = ()
- 학습률(Learning-rate 스타일) 게이트 : = Sigmoid()
여기서
- , 는 head별 Keym Value 차원이며, 모든 실험에서 128로 설정된다.
- q, k, v는 모두 ShortConv → Swish 조합을 사용한다(GDN, Mamba와 동일한 설정).
- q, k에는 L2 정규화를 적용하여 고윳값 안정성(eigenvalue stability)을 확보한다.
- 는 lpw-rank 투영 구조 , 을 사용해 채널 단위의 decay를 생성한다.
- 함수 (·)는 GDN/Mamba에서 사용된 decay 함수와 유사한 형태이다.
출력을 투영하기 전 head-wise RMSNorm을 적용하고, 이후 데이터 기반 게이트(data-dependent gate)를 적용한다. 여기서 output gate는 forget gate와 같이 low-rank parameterization을 선정하여 매개변수 수를 공정하게 비교하면서도 Full-rank 게이트와 비교해도 유사한 성능을 유지하면서 Attention Sink 문제를 완화하였다.
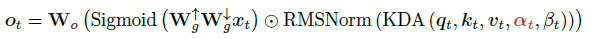
Hybrid Model Architecture
순수한 Linear Attention은 긴 문맥에서의 Retrieval 성능이 상대적으로 제한되므로, Kimi Linear는 KDA 레이어와 Full Attention(Multi-head Latent Attention, MLA) 레이어가 3:1로 반복되는 구조를 채택하였다. 이는 인프라 구조를 간단하게 하면서도 안정적인 학습과 최고의 품질 성능을 가능케 한다.
No Position Encoding(NoPE) for MLA Layers
Kimi Linear에서는 모든 full attention(MLA) 레이어에 Positional Encoding을 적용하지 않는다. 이러한 구조는 하기와 같은 이유에서 채택되었다.
- KDA가 사실상 전체 Positional mechanism의 중심 역할을 수행하여 위치 정보와 recency bias를 반영하며, short convolution이나 SWA보다도 더 강력한 위치 인식 기능을 제공할 수 있다.
- MLA 레이어는 NoPE로 인해 추론 시 효율적으로 Multi-Query Attention(MQA) 형태로 변환된다.
- 문맥 길이의 확장(Long-Context training)이 쉽다.
- RoPE 파라미터 조정(Frequency base tuning이나 YaRN 등의 방법)이 필요하지 않음
이는 기존의 연구 결과(NoPE + 별도의 Position-aware 레이어의 조합이 매우 강력하다는 내용)와도 일치한다.
5. Experiments
Main results
Pre-training / SFT / Long-context / RL 네 영역에서 Kimi Linear가 MLA(Full Attention) 및 GDN-H 대비 어떤 성능을 보였는지 종합적으로 정리한다.
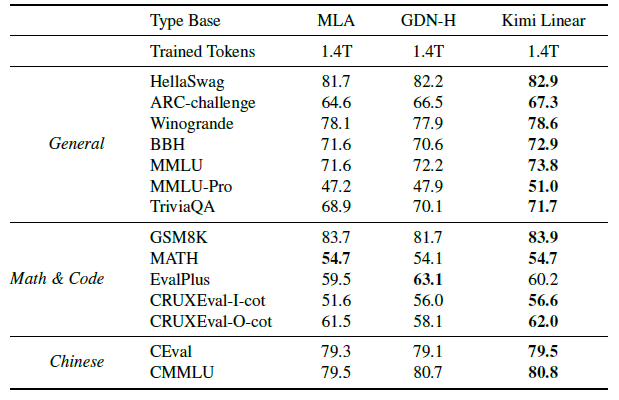
Pretrain Results(사전학습 성능)
Kimi Linear 모델을 MLA 및 Hybrid GDN-H와 비교하였으며, 모두 1.4T의 사전학습 데이터를 사용해 동일한 설정으로 학습되었다.
- General Knowledge Benchmarks
- HellaSwag, BBH, MMLU, TriviaQA 등 주요 벤치마크에서 Kimi Linear가 가장 높은 점수를 기록하였다.
- Reasoning(Math&CodE)
- GSM8K, MATH, EvalPlus, CRUXEval(I-cot, O-cot) 등 대부분의 평가에서 Kimi Linear가 가장 우수하며, MATH 등 일부 평가는 MLA와 비슷한 수준을 보였다.
- Chinese Benchmarks
- CEval, CMMLU에서 Kimi Linear가 최고 성능을 달성하였다.
SFT Results(Instructionn Tuning)
모든 모델에 대하여 동일한 SFT(Instruction tuning) 방법을 적용해 미세조정 후 테스트를 진행하였다.
- General Tasks
- Kimi Linear는 대부분의 일반 태스크에서 MLA 및 GDN-H보다 높은 점수를 기록하였으며, 특히 MMLU-Pro, GPQA-Diamond 같은 고난도 벤치마크에서 큰 차이를 보였다.
- Math&Code
- AIME, HMMT, PolyMath-en, LiveCodeBench 등에서 Kimi Linear가 최고 성능을 보였다.
- MATH500, EvalPlus에서는 MLA 또는 GDN-H가 약간 앞섰으나, 전체적으로는 Kimi Linear가 가장 일관된 우위를 보였다.
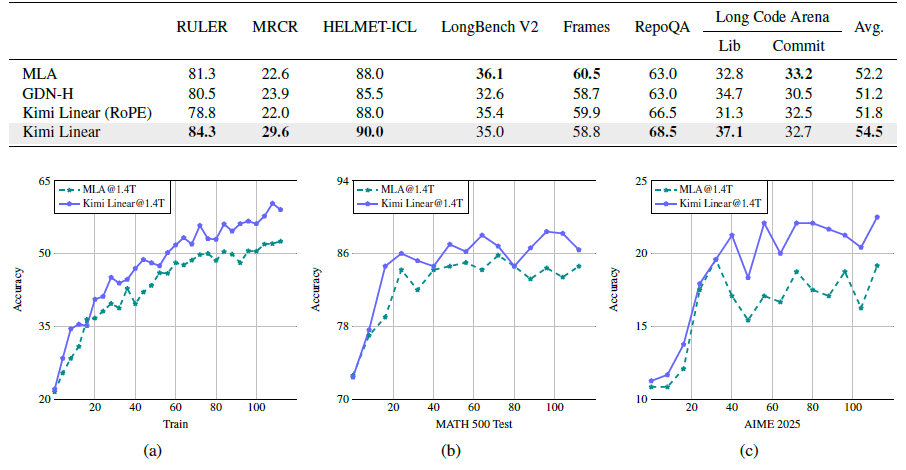
Long-Context Results
128k의 Context 길이를 기준으로 평가하였으며, RULER, LongBench V2, RepoQA 등의 주요 테스트셋을 활용하였다. 그 결과 Kimi Linear가 전체 평균에서 가장 높은 점수를 기록하였으며, 특히 RULER와 RepoQA에서는 큰 격차로 1위를 기록하였다.
RL results
수학 중심의 RLVR을 이용해 MLA와 Kimi Linear의 RL 수렴 특성을 비교하였다.
- 학습 과정
- 초기 성능은 MLA와 비슷하게 시작하나, Kimi Linear의 정확도 상승 속도가 더 빠르고 이는 시간이 지날수록 격차가 확대되는 양상을 보였다.
- 테스트 평가
- MATH500, AIME 2025에서 Kimi Linear가 일관되게 MLA를 능가하는 모습을 보였다.
Summary
평가를 통해 Pretrain → SFT → Long-context → RL의 모든 단계에서 Kimi Linear가 MLA 및 GDN-H보다 강력한 성능을 보이고 있음을 입증하였으며, 특히 long-context retrieval, math reasoning, deep reasoning에서 큰 차이를 보였다. 이는 NoPE 기반 MLA + fine-grained gated KDA 조합이 매우 효과적이라는 설계적 근거를 실험적으로 확인한 것이라고 할 수 있다.
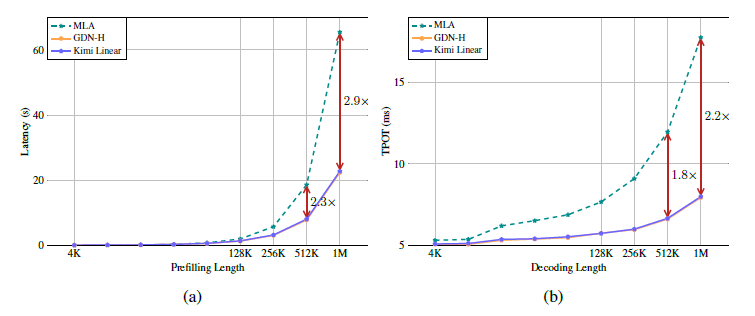
Efficiency Comparison
여기서는 Kimi Linear, MLA(full attention), hybrid GDN-H 세 가지 모델의 효율성(속도·메모리) 을 비교한다. 평가는 Prefill(입력 채우기) 단계와 Decoding(생성 단계) 두 부분으로 나뉜다.
Prefilling Speed(입력 채우기 속도)
Kimi Linear는 fine-grained decay gate()를 포함함에도 불구하고 GDN-H와 거의 동일한 수준의 Latency를 보였다. 이는 성능을 높이기 위해 추가한 게이트 구조가 속도 오버헤드를 거의 유발하지 않음을 의미한다.
MLA와 대비하여 성능 면에서 비교하면
- 4k~16k 길이에서는 MLA와 비슷하거나 약간 빠른 수준
- 128k 이상에서는 큰 격차를 보임
- 512k에서는 약 2.3배, 1M에서는 약 2.9배의 속도 차를 보임
이는 MLA가 O(L) KV cache 관리와 softmax attention 계산으로 인해 입력 길이 증가에 매우 취약한 반면, Kimi linear는 상태 크기가 고정되어 증가하지 않기 때문이다.
Decoding Speed(생성 단계 속도)
디코딩(autoregressive generation)에서는 길거나 큰 배치에서 실제 사용자가 느끼는 성능 차이가 드러난다.
- Time Per Output Token(TPOT)
- 128k 이상의 매우 긴 Context에서는 MLA 대비 월등히 낮은 TPOT(토큰당 출력 시간)을 유지함
- GDN-H와 매우 유사한 속도
- MLA는 길이가 증가할수록 decoding latency가 크게 증가
- 1M context 기준 비교
- Kimi Linear는 MLA 대비 최대 6.3배 더 빠른 decoding
이와 같은 성능 차를 보이는 이유는, KDA의 경우 고정된 상태(state) 크기를 유지하므로 메모리의 증가가 없으며, KV Cache를 거의 사용하지 않아 I/O 병목도 최소화되기 때문이다. 즉, 매우 긴 Context 환경에서는 Kimi Linear가 실제 처리량(throughput) 측면에서 절대적인 우위를 보인다.
6. Conclusion
Kimi Team은 본 논문을 통해 Kimi Linear를 소개하였다. 이 모델은 Agentic Intelligence와 Test-time Scaling 요구를 충족하면서도 성능을 희생하지 않는 새로운 Hybrid Linear attention 아키텍처이다.
본 아키텍처의 핵심 구성 요소는 아래와 같이 정리할 수 있다.
- Kimi Delta Attention(KDA)
- KDA는 채널 단위의 세밀 게이팅(channel-wise gating)을 적용한 고급 linear attention 모듈이다.
- 이를 통해 메모리 제어 능력(memory control) 이 크게 강화되며, RNN-style 구조가 hybrid 모델 안에서 효과적으로 기능할 수 있도록 한다.
- Hybrid Architecture(KDA + Global Attention)
- 전체 모델은 3:1 비율로 KDA 레이어와 full global attention 레이어를 교차 배치한다.
- 이 설계는 메모리 사용량 최대 75% 절감, 최대 6.3배 더 높은 decoding throughput 달성, 동일 크기의 full attention 모델보다 더 높은 성능 등을 달성한다.
이 연구에서 Kimi Team은 KDA 커널(kernel) 및 vLLM 통합 버전, 그리고 사전학습(pretrained)·Instruction-tuned 체크포인트를 공개하였다. 이러한 구성 요소들은 기존 full-attention 기반 파이프라인과 완전히 호환되며, 캐싱이나 스케줄링 인터페이스를 수정할 필요가 없다. 즉, 즉시 적용이 가능하다.
Ⅱ. 결론
Kimi Linear는 기존 Full-Attention 아키텍처 대비 성능은 유지하면서도 학습 및 추론에 필요한 리소스를 줄이고 속도 측면에서도 상당한 수준의 개선을 보였다는 점에서 주목할 만한 개념으로 판단된다. 다만 저자들이 공개한 체크포인트를 그대로 사용하는 것은 언어 및 Task 활용도 측면에서 어려움이 있을 것으로 보이며, 기존 LLama나 Gemma 등의 모델에서 Attention 매커니즘만 본 논문의 하이브리드 구조로 바꾸기 위해서는 별도의 작업이 필수적으로 수반되어야 한다.
또한 기존 모델의 체크포인트에 커스텀 KDA 모듈을 붙인다고 해도 전체 모델 구조의 상이함, 학습 데이터 차, 기타 하드웨어 환경 차 등으로 성능 향상이 크게 이루어지지 않을 수도 있다. 따라서 후속 연구 혹은 다른 오픈소스 모델의 커스터마이징 상황을 주의 깊게 살펴보고, 프로덕션 레벨에서 활용 가능한 모델이 공개되는 경우(혹은 그것을 만들어낼 수 있는 환경이 조성되었을 경우) 빠르게 대응할 수 있도록 하는 것이 적절할 것으로 보인다.
Appendix
