스터디 그룹에서 진행하는 토이 프로젝트에서 '여행 후기' 데이터가 필요하여 웹 스크래핑을 진행하게 되었습니다. 아무래도 여행 관련 카페가 활성화되어 있는 만큼 네이버 카페의 게시물들을 모아야 할 필요가 있었는데, 네이버 카페의 경우 동적 페이지로 구성되어 있어 Beautiful soup를 활용한 스크래핑으로는 각 게시물들의 본문 텍스트 데이터를 추출하는 것이 어려운 상황이었습니다. 하여 부득이하게 Selenium을 이용하여 스크래핑을 진행했고, 그 과정을 간단히 정리해 봅니다. 추후 네이버 카페의 데이터를 모을 필요가 있으신 분들께 조금이나마 도움이 되었으면 좋겠습니다.
필요 라이브러리 설정
네이버 카페의 경우 Beautiful soup를 이용한 스크래핑으로는 게시물의 작성자, 제목, 시간 등의 데이터만 추출 가능하며, 각 게시물의 본문 텍스트를 불러오지는 못하는 것으로 알고 있다. 따라서 셀레니움을 이용하여 스크래핑을 진행하며, 그 외 보조적인 라이브러리 몇 가지를 함께 사용할 것이다.
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from tqdm import tqdm
from collections import deque
import pyperclip
import json
import pickle웹드라이버 로드 및 브라우저 오픈
셀레니움이 업데이트되면서 더 이상 크롬 드라이버를 필요로 하지 않게 되었다(정확히는 별도의 파일을 다운받을 필요가 없다). 다음과 같이 설정하여 셀레니움 드라이버를 초기화하고 원격 제어할 브라우저를 오픈한다.
op = webdriver.ChromeOptions()
chrome_service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service = chrome_service, options=op)네이버 로그인
우선 카페에 진입하기 위해 네이버 로그인을 진행한다. 이 부분은 나도 보고 따라 한 거라 정확히는 모르지만, 일반적인 send_keys를 이용하여 아이디와 패스워드를 입력하는 일반적인 방식으로는 에러가 발생한다고 한다. 따라서 여기서는 pyperclip을 이용해 아이디와 패스워드를 각각 복사-붙여넣기하는 식으로 로그인을 실시한다.
my_id = "네이버 아이디"
my_pw = "네이버 패스워드"
driver.get("https://nid.naver.com/nidlogin.login")
try:
driver.find_element(By.CSS_SELECTOR,'#id') #예외처리에 필요 이 구문이 없으면 아이디가 클립보드에 계속 복사됨
time.sleep(3)
pyperclip.copy(my_id)
driver.find_element(By.CSS_SELECTOR,'#id').send_keys(Keys.CONTROL+'v')
time.sleep(1)
pyperclip.copy(my_pw)
secure='blank'
driver.find_element(By.CSS_SELECTOR,'#pw').send_keys(Keys.CONTROL + 'v')
pyperclip.copy(secure) #비밀번호 보안을 위해 클립보드에 blank 저장
driver.find_element(By.XPATH,'//*[@id="log.login"]').click()
except:
print("no such element") #예외처리게시판 정보 확인
이제 본격적으로 스크래핑을 위한 준비를 할 것이다. 대략적인 순서는 '게시판 진입-게시판의 첫 번째 게시물 클릭-다음 글로 이동하며 데이터 수집'이 될 것이다.
게시판 진입을 위해 게시판을 탐지할 수 있는 정보를 찾아야 한다. 내 경우에는 우선 '네일동'의 각 지역별 여행 후기 게시판이 목표였다.
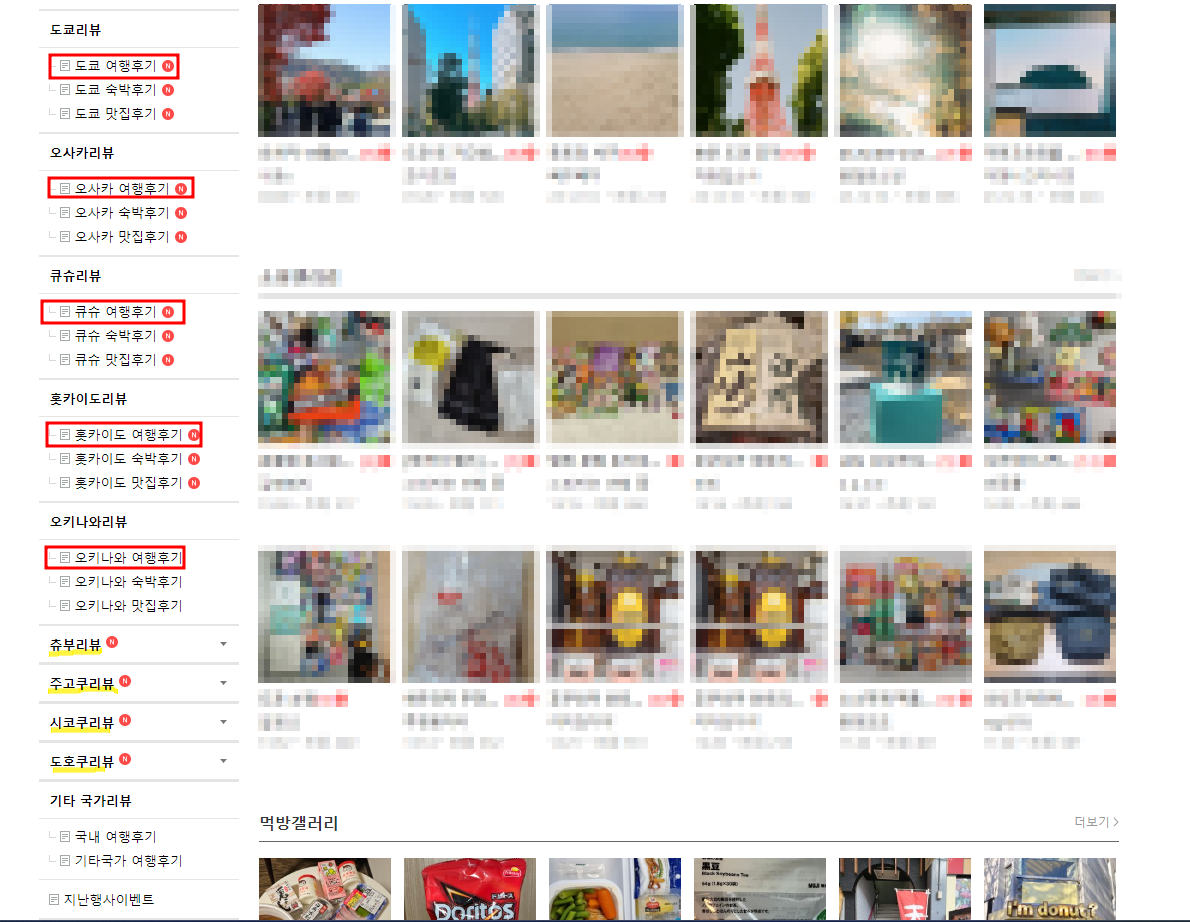
그런데 얼레? 상대적으로 마이너한 지역(쥬부, 주고쿠 등)은 드롭다운 설정이 되어 있다. 우선 이것부터 풀고 넘어가자.
크롬의 개발자 모드를 켜고 드롭다운 메뉴의 우측 화살표에 해당하는 엘리먼트를 찾아 CSS selector를 복사해보니 츄부부터 도호쿠까지 차례대로 '#group769btn > a > img', '#group1004btn > a > img', '#group1005btn > a > img', '#group1006btn > a > img'로 설정된 것을 확인할 수 있다. 이 selector들을 리스트로 저장하고, for문으로 순회하며 각 버튼을 클릭함으로써 드롭다운 메뉴를 활성화할 것이다.
btn_list = [
"#group769btn > a > img",
"#group1004btn > a > img",
"#group1005btn > a > img",
"#group1006btn > a > img"
]드롭다운 메뉴를 열었으니 이제 각 게시판의 정보도 확인해 보자. 마찬가지로 개발자 도구를 이용해 selector를 확인하면 각 게시판별로 "#menuLink{고유번호}"와 같은 형태로 설정되어 있는 것을 확인할 수 있다.
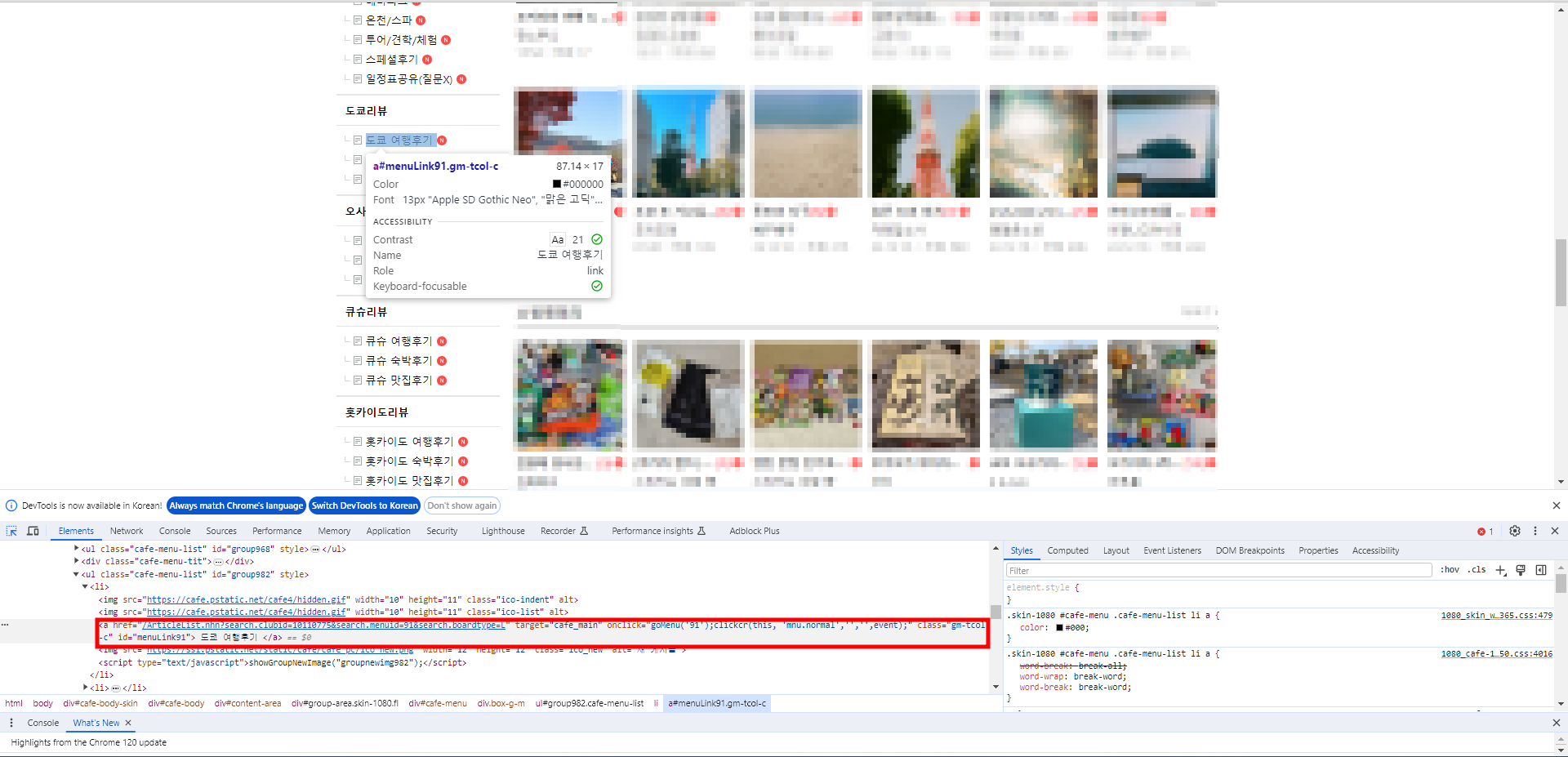
꼭 CSS SELECTOR를 이용할 필요는 없다. 상황에 맞게 XPATH나 CLASS, ID 등을 다양하게 이용하자.
게시판이 많지 않으니 딕셔너리 형태로 각 고유 번호를 저장하고, 추후 데이터를 정리할 때 사용하기 위해 지역명을 keys()로 추출해 별도의 리스트로 만들어 둔다.
board_dict = {
"도쿄": "91", "오사카": "92", "큐슈": "93",
"홋카이도": "94", "오키나와": "101", "츄부": "805",
"주고쿠": '808', "시코쿠": "813", "도호쿠": "818"
}
board_keys = list(board_dict.keys())게시물 정보 확인
이제 게시판 내의 게시물에 대한 정보를 확인하자. 우선 네이버 카페에서 게시물을 클릭하기 위해서는 iframe을 바꾸어야 한다. 게시판을 클릭한 뒤 게시물 영역의 정보를 확인하면 iframe의 이름을 확인할 수 있다.
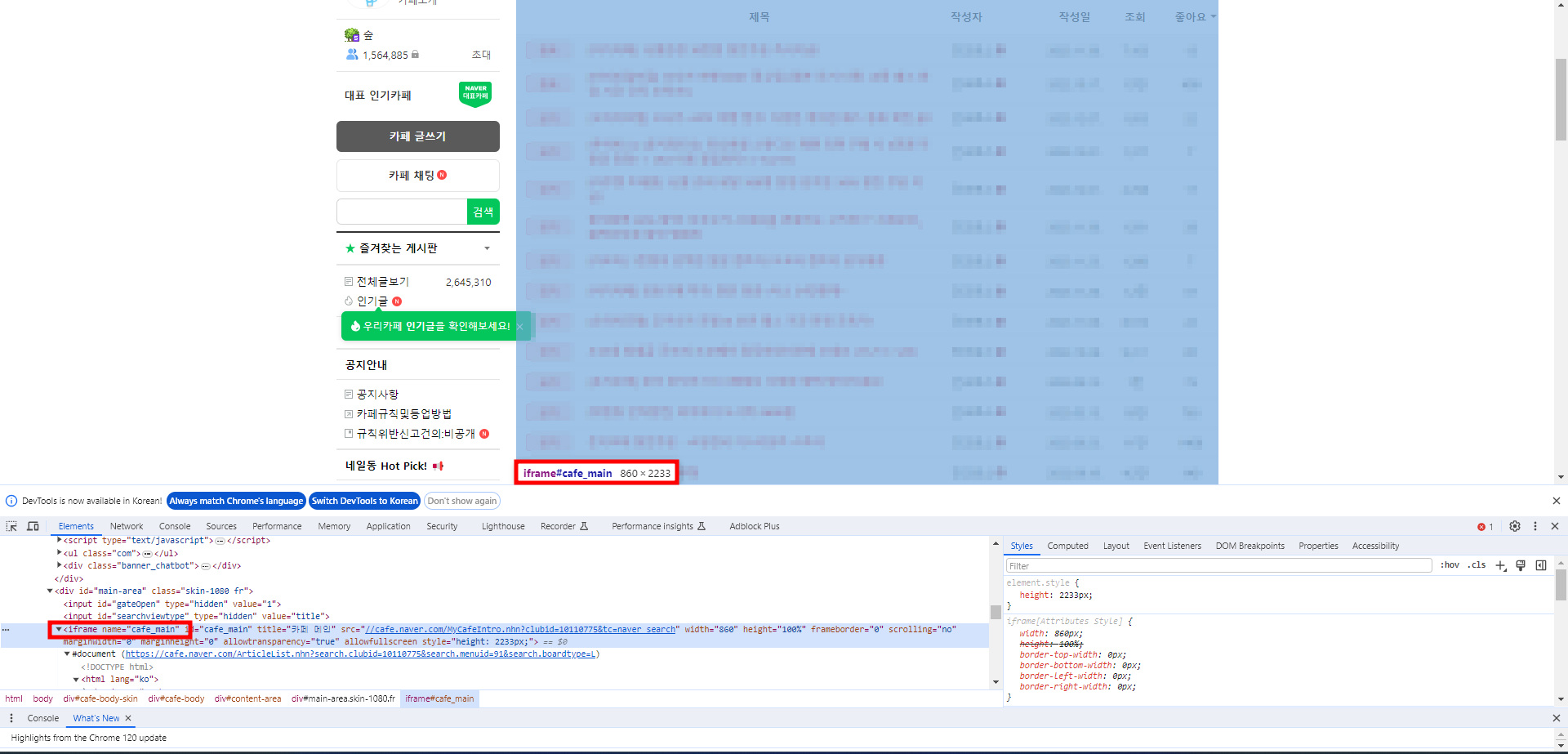
따라서 게시판에 접근한 뒤 가장 먼저 iframe을 전환할 것이다.
# 게시판 진입
board = driver.find_element(By.CSS_SELECTOR, f"#menuLink{board_dict[city]}")
driver.implicitly_wait(3)
board.click()
# iframe으로 전환
driver.switch_to.frame("cafe_main")그 다음에는 각 게시판의 첫 번째 게시물을 찾아 진입해야 한다. 이번에는 XPATH를 이용해 보자.
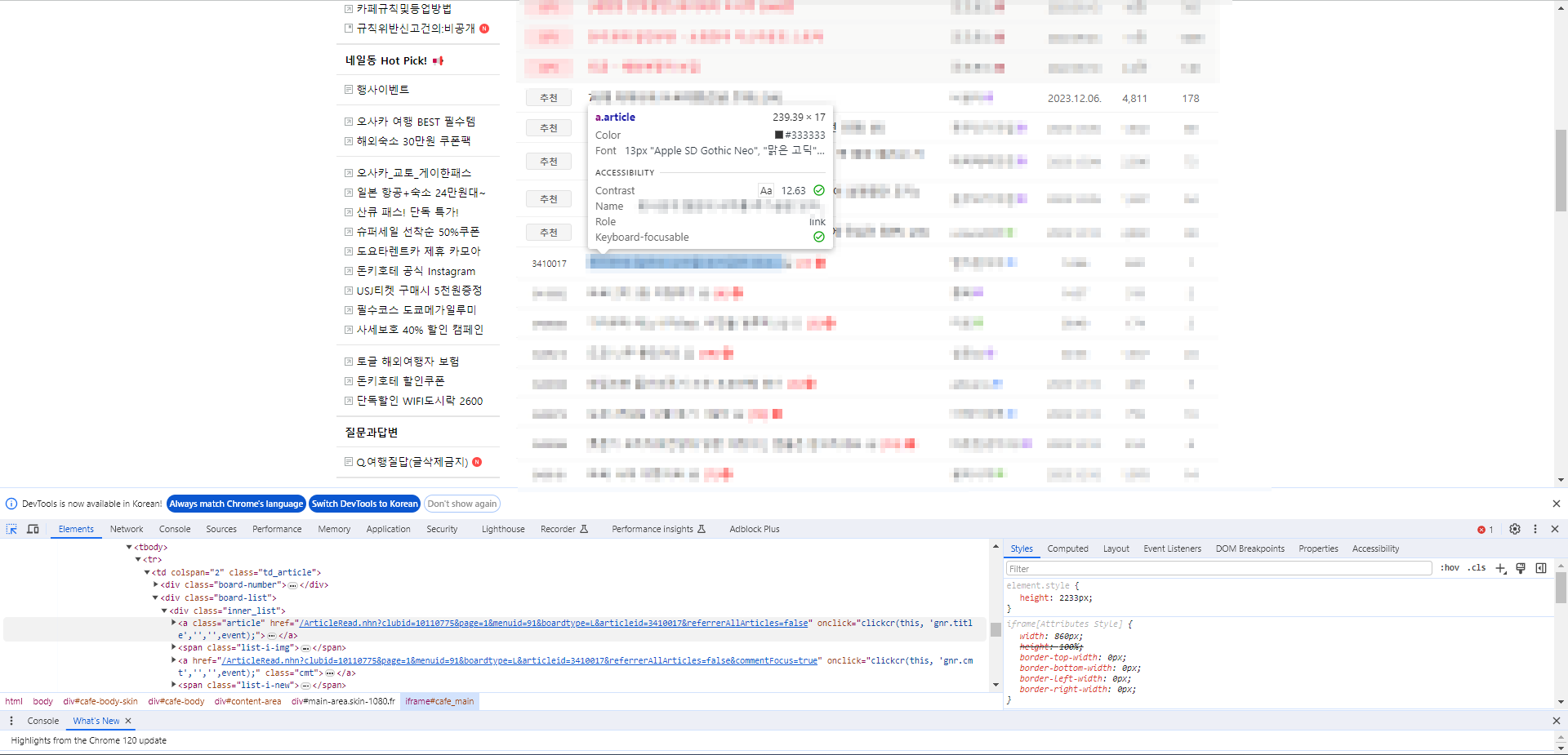
해당 게시물의 XPATH는 //*[@id="main-area"]/div[4]/table/tbody/tr[1]/td[1]/div[2]/div/a[1]이다. 해당 게시물을 클릭하여 진입한다.
# 게시판별 첫 번째 게시글 클릭
driver.find_element(By.XPATH, '//*[@id="main-area"]/div[4]/table/tbody/tr[1]/td[1]/div[2]/div/a[1]').click()
time.sleep(1)Naver 서버에서 비정상적인 접근(DDoS 등)으로 판단하여 차단하는 일이 없도록 각 동작 중간중간에 time을 이용해 휴지를 주어야 한다.
게시물 정보 추출 및 이동
이 부분은 다시 크게 둘로 나누어 진행할 수 있다.
- 게시물에서 필요한 정보를 추출한다.
- 다음 게시물로 이동한다.
필요 정보 추출
이 부분은 어려울 것이 없다. 개발자 도구를 이용해 필요한 정보(게시물 제목, 작성 일자, 작성자, 본문 내용 등)를 확인하고 각각 변수에 할당해주면 된다. 이 부분은 CLASS NAME을 이용하는 것이 편리할 것이다. 예컨대 게시물 본문은 아래에서 보듯 'se-main-container'라는 클래스명을 사용한다.
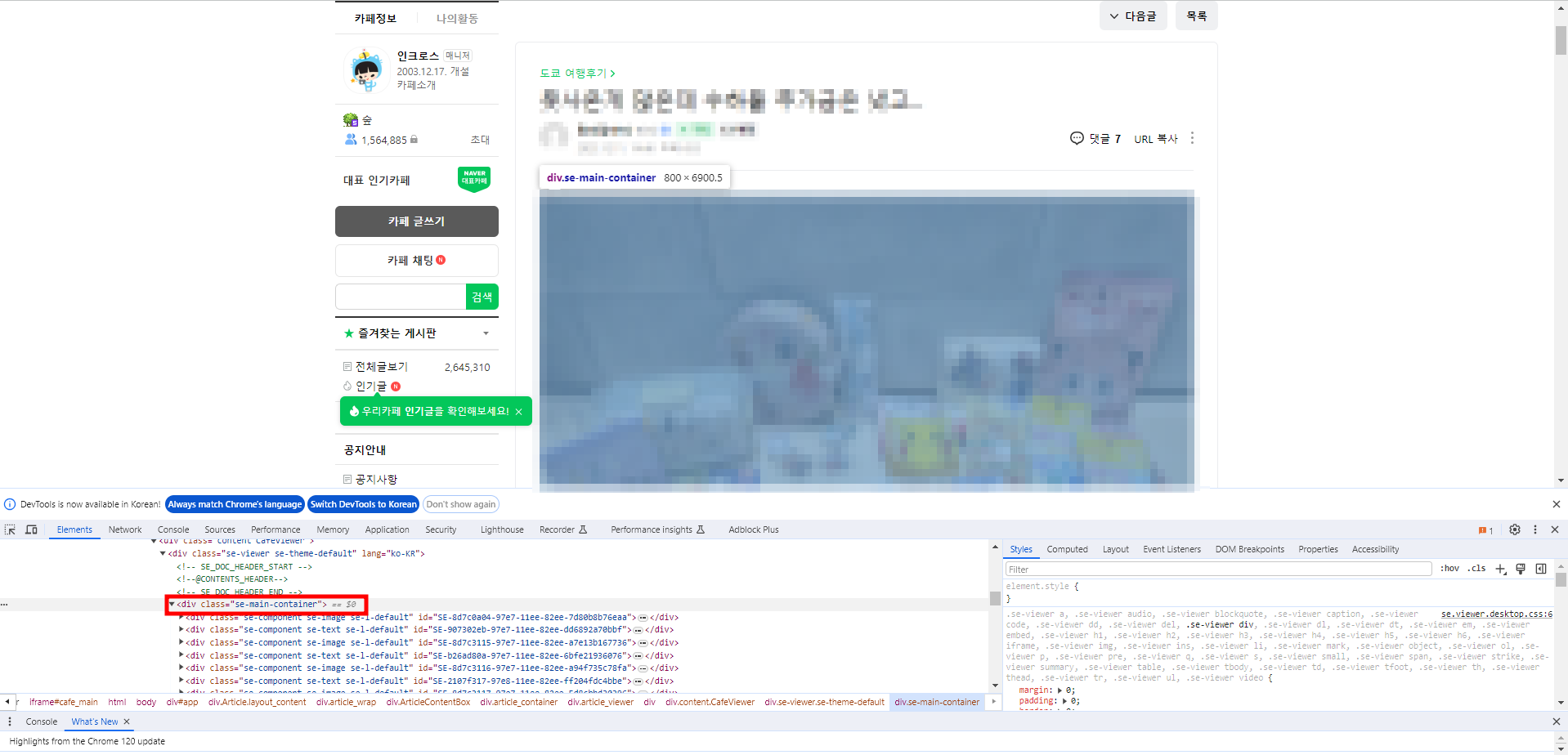
한 가지 조금 헤맸던 것은 게시물의 url을 찾는 부분이었는데, 네이버 카페 게시물의 경우 게시물 하단의 '공유' 버튼을 통해 url을 확인할 수 있다.
이렇게 필요한 정보들을 추출하여 변수에 할당하고, 필요하다면 다른 형태로 가공하여 저장하거나 하는 식으로 데이터 추출을 완료했다면 이제 다음 게시물로 넘어갈 차례다.
cont_url = driver.find_element(By.XPATH, '//*[@id="spiButton"]').get_attribute('data-url')
cont_num = cont_url.split("/")[-1]
cont_date = driver.find_element(By.CLASS_NAME, 'date').text
cont_author = driver.find_element(By.CLASS_NAME, 'nickname').text
cont_title = driver.find_element(By.CLASS_NAME, 'title_text').text
cont_text = driver.find_element(By.CLASS_NAME, 'se-main-container').text게시물 이동
여기서는 게시물 상단의 '다음글' 버튼을 찾아 클릭함으로써 다음 게시물로 넘어가는 방법을 사용했다. 복잡할 것 없이 앞서와 마찬가지로 개발자 도구를 이용해 XPATH(혹은 CSS SELECTOR 등)를 찾으면 된다.
driver.find_element(By.CSS_SELECTOR, "#app > div > div > div.ArticleTopBtns > div.right_area > a.BaseButton.btn_next.BaseButton--skinGray.size_default").click()
time.sleep(3)최종 정리
이제 필요한 코드는 모두 작성했다. 이제 이 코드들을 모아 정리하고, 실행하면 된다. 여기서 정리라고 하면 첫 번째 게시물로부터 '다음글'을 눌러 이동하는 것을 몇 번이나 진행할 것인지(즉, 각 게시판별로 몇 개의 게시물을 모을 것인지) 결정하고, 해당 작업을 각 게시판별로 반복하도록 설정하는 등의 일이다. 내 경우 2021년까지의 데이터만 필요했으므로 게시물의 작성 일자를 확인하여 2020년(혹은 그 이전)의 게시물로 넘어가는 순간 반복을 종료하고 다음 스텝으로 넘어가도록 설정했다.
전체 코드를 적어 보면 다음과 같다.
# 로그인
my_id = "네이버 아이디"
my_pw = "네이버 패스워드"
driver.get("https://nid.naver.com/nidlogin.login")
try:
driver.find_element(By.CSS_SELECTOR,'#id') #예외처리에 필요 이 구문이 없으면 아이디가 클립보드에 계속 복사됨
time.sleep(3)
pyperclip.copy(my_id)
driver.find_element(By.CSS_SELECTOR,'#id').send_keys(Keys.CONTROL+'v')
time.sleep(1)
pyperclip.copy(my_pw)
secure='blank'
driver.find_element(By.CSS_SELECTOR,'#pw').send_keys(Keys.CONTROL + 'v')
pyperclip.copy(secure) #비밀번호 보안을 위해 클립보드에 blank 저장
driver.find_element(By.XPATH,'//*[@id="log.login"]').click()
except:
print("no such element") #예외처리
# 추출한 데이터를 저장할 딕셔너리 생성(추후 JSON 파일로 저장)
data = {"도쿄": {},
"오사카": {},
"큐슈": {},
"홋카이도": {},
"오키나와": {},
"츄부": {},
"시코쿠": {},
"도호쿠": {},
"주고쿠": {}}
# 게시판 정보 및 카페 url 등을 설정
board_dict = {"도쿄": "91", "오사카": "92", "큐슈": "93", "홋카이도": "94", "오키나와": "101", "츄부": "805", "주고쿠": '808', "시코쿠": "813", "도호쿠": "818"}
board_keys = list(board_dict.keys())
cafe_url = "https://cafe.naver.com/jpnstory"
# 각 게시판별로 탐색할 게시물의 수 설정
num_conts = 5000
# 카페 진입
driver.get(cafe_url)
# 드롭다운 메뉴 활성화
btn_list = ["#group769btn > a > img", "#group1004btn > a > img", "#group1005btn > a > img", "#group1006btn > a > img"]
for btn in btn_list:
dropdown = driver.find_element(By.CSS_SELECTOR, btn)
dropdown.click()
driver.implicitly_wait(3)
# 각 게시판별로 스크래핑 진행
for city in board_keys:
# 게시판 진입
board = driver.find_element(By.CSS_SELECTOR, f"#menuLink{board_dict[city]}")
driver.implicitly_wait(3)
board.click()
# iframe으로 전환
driver.switch_to.frame("cafe_main")
# 게시판별 첫 번째 게시글 클릭
driver.find_element(By.XPATH, '//*[@id="main-area"]/div[4]/table/tbody/tr[1]/td[1]/div[2]/div/a[1]').click()
time.sleep(1)
for i in tqdm(range(1, num_conts)):
try:
cont_url = driver.find_element(By.XPATH, '//*[@id="spiButton"]').get_attribute('data-url')
cont_num = cont_url.split("/")[-1]
cont_date = driver.find_element(By.CLASS_NAME, 'date').text
cont_author = driver.find_element(By.CLASS_NAME, 'nickname').text
cont_title = driver.find_element(By.CLASS_NAME, 'title_text').text
cont_text = driver.find_element(By.CLASS_NAME, 'se-main-container').text
except:
pass
# 게시물 작성 날짜가 2021년 이전일 경우 탐색 중지, 다음 게시판으로 이동
if cont_date[:4] <= '2020':
break
# 2020년 이후의 데이터는 data 딕셔너리에 추가
else:
data[city][i] = {
"url": cont_url,
"id": cont_num,
"date": cont_date,
"author": cont_author,
"title": cont_title,
"text": cont_text
}
# 다음 게시물로 이동
try:
driver.find_element(By.CSS_SELECTOR, "#app > div > div > div.ArticleTopBtns > div.right_area > a.BaseButton.btn_next.BaseButton--skinGray.size_default").click()
except:
driver.find_element(By.CSS_SELECTOR, "#app > div > div > div.ArticleTopBtns > div.right_area > a.BaseButton.btn_next.BaseButton--skinGray.size_default > span").click()
time.sleep(3)
# 게시물을 1000개 탐색할 때마다 JSON 파일로 데이터 백업
if i % 1000 == 0:
with open("./naver_japan_city_review.json", 'w') as f:
json.dump(data, f)일단 이 코드로 네일동의 데이터 스크래핑은 잘 마무리했는데, 문제는 두 번째 목표였던 태국 여행 카페 '태사랑'의 데이터 스크래핑에서 발생하였다. 동일한 방식이었음에도 불구하고 많게는 1000여 개, 적게는 500여 개의 게시물을 탐색하고 나면 크롬 브라우저가 out of memory 에러를 뱉으면서 뻗어버리는 것.
크롬의 임시 파일들(캐시 등)도 지워 보고 내 PC의 가상 메모리 영역도 확인해봤지만 그 부분의 문제는 아니었다(작업관리자로 모니터링해 보니 실제 메모리는 16GB 중 8GB 이상 사용하는 일이 없었다). 여기저기 확인해본 결과 이를 해결하는 방법은 selenium으로 구동하는 브라우저를 중간중간 껐다 켜는 것뿐.
문제는 상기에서 작성한 코드는 각 게시판별로 '첫 번째' 게시물에서 시작하여 '다음글'로 이동하는 것을 반복함으로써 게시물을 탐색하는 방식인데, 이 경우 중간에 탐색이 끊어지면 그 끊어진 부분부터 재시작하는 것이 상당히 까다롭다(게다가 기껏 자동화한다고 해 놓고 이게 죽었는지 살았는지 확인하다가 죽을 때마다 다시 실행해주는 것도 웃기는 일이다).
따라서 게시물을 탐색하는 방법을 완전히 바꿔서 코드를 다시 작성하였다. 이건 다음 포스트에서 정리할 것이다. 다만 이 코드로도 크롤링이 가능하긴 하므로(그리고 바꾼 코드보다 속도가 조금이나마 빠르므로) 이 방식을 이용해 보는 것도 괜찮을 것이다.
