스터디 그룹에서 진행하는 토이 프로젝트에서 '여행 후기' 데이터가 필요하여 웹 스크래핑을 진행하게 되었습니다. 아무래도 여행 관련 카페가 활성화되어 있는 만큼 네이버 카페의 게시물들을 모아야 할 필요가 있었는데, 네이버 카페의 경우 동적 페이지로 구성되어 있어 Beautiful soup를 활용한 스크래핑으로는 각 게시물들의 본문 텍스트 데이터를 추출하는 것이 어려운 상황이었습니다. 하여 부득이하게 Selenium을 이용하여 스크래핑을 진행했고, 그 과정을 간단히 정리해 봅니다. 추후 네이버 카페의 데이터를 모을 필요가 있으신 분들께 조금이나마 도움이 되었으면 좋겠습니다.
앞선 포스트에서 발생한 크롬의 out of memory 문제를 해결하기 위하여 코드의 수정이 필요하였다. 동시에 에러 등으로 프로세스가 중단되지 않도록(그래야 켜 놓고 외출을 하든 잠을 자든 할 것이니) 몇 가지 안전 장치도 추가하였다.
수정한 사항을 대략적으로 정리하면 다음과 같다.
-
게시물의 탐색 방식을 게시판별 첫 번째 게시물에서 '다음글'로 넘어가는 방식이 아니라 각 게시판의 게시물을 직접 클릭하여 탐색하는 방식으로 수정
-
일정 구간을 탐색할 때마다 브라우저를 재시작함으로써 메모리 누수 문제를 방지하고 동시에 에러 등으로 동작이 정지되었을 경우에도 중간부터 재시작이 가능하도록 수정
본격적인 수정에 앞서, 셀레니움 드라이버의 실행과 네이버 로그인 등은 함수로 선언하여 이후 다른 카페의 탐색 시에도 깔끔하게 사용할 수 있도록 해 두었다.
# 브라우저 오픈
def open_browser():
op = webdriver.ChromeOptions()
chrome_service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service = chrome_service, options=op)
return driver
# 네이버 로그인
def naver_login(naver_id, naver_pw):
driver.get("https://nid.naver.com/nidlogin.login")
try:
driver.find_element(By.CSS_SELECTOR,'#id') #예외처리에 필요 이 구문이 없으면 아이디가 클립보드에 계속 복사됨
time.sleep(2)
pyperclip.copy(my_id)
driver.find_element(By.CSS_SELECTOR,'#id').send_keys(Keys.CONTROL+'v')
time.sleep(1)
pyperclip.copy(my_pw)
secure='blank'
driver.find_element(By.CSS_SELECTOR,'#pw').send_keys(Keys.CONTROL + 'v')
pyperclip.copy(secure) #비밀번호 보안을 위해 클립보드에 blank 저장
driver.find_element(By.XPATH,'//*[@id="log.login"]').click()
except:
print("no such element") #예외처리게시판 URL 및 게시물의 XPATH 확인
게시판 URL 확인
이번에는 일본이 아닌 '베트남'의 여행 후기 데이터를 모아볼 예정이다. 관련 카페 중 가장 많은 사용자를 보유한 '도깨비' 카페를 확인할 것인데, 이 카페의 경우 하나의 카페에 각 지역별 정보를 모아 둔 것이 아니라 지역별로 별도의 카페를 만들어 운영하고 있었다. 따라서 우선 각 카페별로 여행 후기에 해당하는 게시판의 URL을 확인하여 딕셔너리 자료형으로 저장한다.
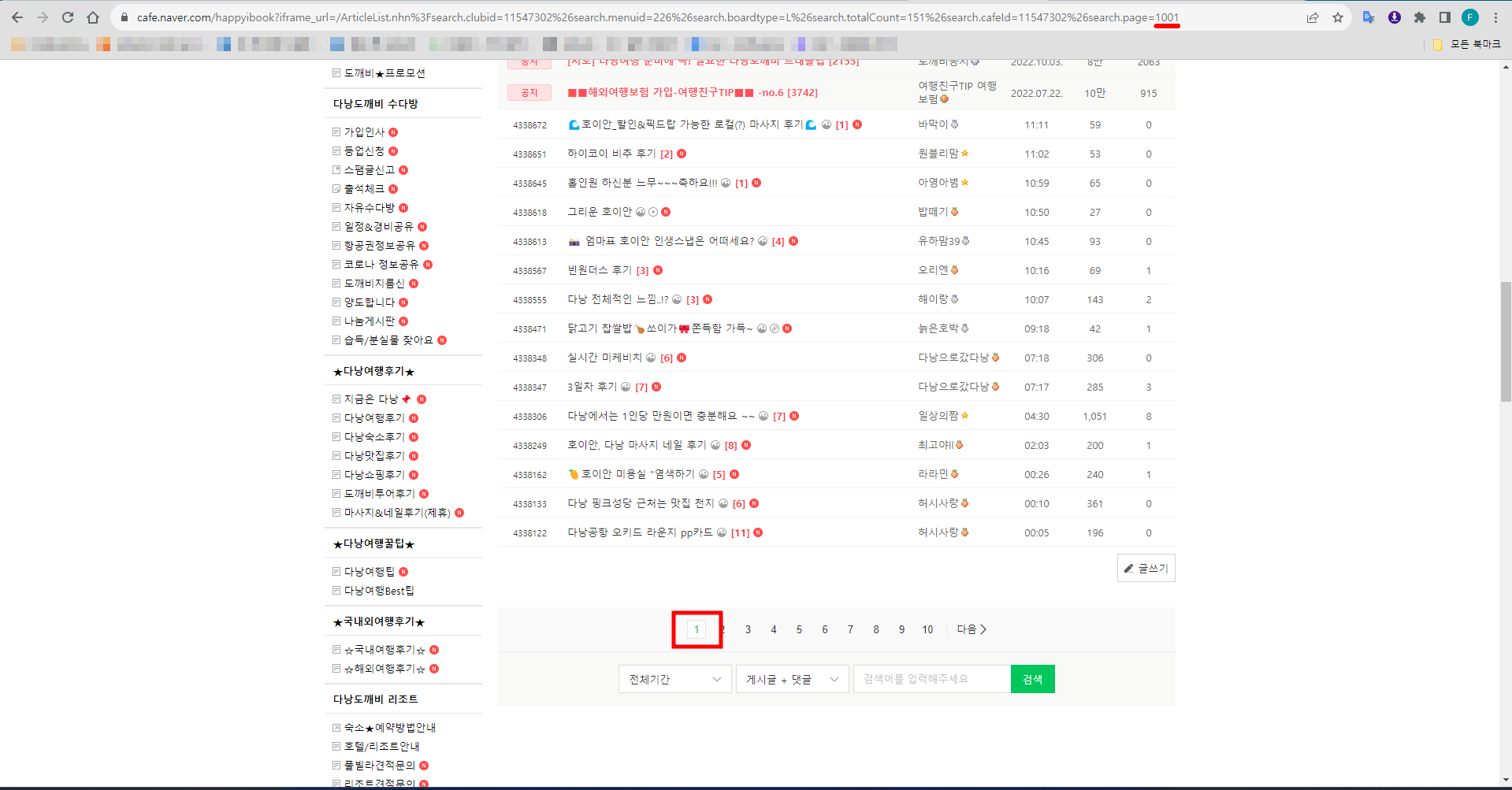
기본적으로 개발자 모드에서 해당 게시판의 엘리먼트를 찾아 URL을 확인하는 과정은 동일하다. 그런데 앞서 일본 여행 데이터를 모을 때 한 가지 간과한 것이 있었다. 네이버 카페 게시판은 최대 페이지 수를 1000까지만 지원한다는 것이다. 만약 1000페이지를 넘거가게 되면 다시 1페이지로 돌아오고, 크롤러는 다시 1페이지부터 데이터를 추출하기 시작할 것이다.
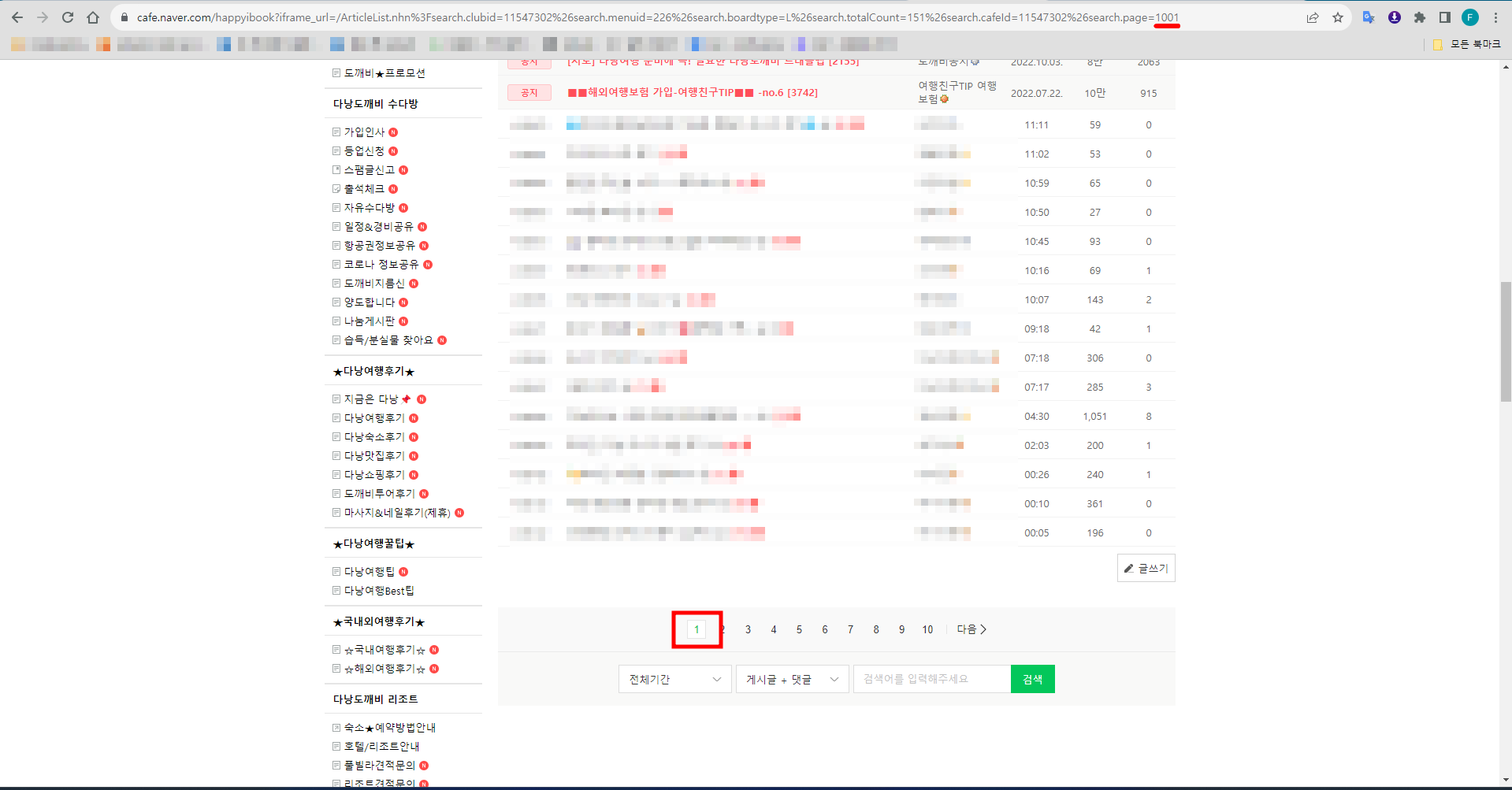 페이지 수를 1001로 설정하는 순간 1페이지로 되돌아온다.
페이지 수를 1001로 설정하는 순간 1페이지로 되돌아온다.
그런데 게시판의 게시글이 많을 경우 내가 원하는 데이터(2021년까지의 데이터)가 1000페이지를 넘길 수도 있을 것이다. 당장 상기 다낭 카페의 경우도 그러한데, 최대 페이지인 1000페이지까지 이동해도 2023년 1월 6일에 작성된 후기까지만 볼 수 있다.
다행히 네이버 카페 게시판은 한 게시판에 몇 개의 게시물을 보여줄지를 설정할 수 있고, 해당 설정에 따라 확인 가능한 게시물의 수가 다르다. 즉, 한 게시판 페이지에 나타나는 게시물의 수를 50으로 설정하고 1000페이지로 이동하면 훨씬 더 이전에 작성된 게시물도 확인 가능한 것이다.
따라서 크롬 개발자 도구를 통해 표시 게시물 수에 따라 url이 달라지는지 확인하고, 해당 url을 저장하여 순회할 수 있도록 설정한다.
표시 게시물 수가 15개일 때의 여행 후기 게시판의 url은 다음과 같다.
https://cafe.naver.com/happyibook?iframe_url=/ArticleList.nhn%3Fsearch.clubid=11547302%26search.menuid=226%26search.boardtype=L%26search.totalCount=151%26search.cafeId=11547302%26search.page=1
표시 게시물 수를 50개로 바꾸면 다음과 같이 변경된다.
https://cafe.naver.com/happyibook?iframe_url=/ArticleList.nhn%3Fsearch.clubid=11547302%26search.menuid=226%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=11547302%26search.page=1
url을 살펴보면 '...menuid226%26' 뒤에 'userDisplay=50%'이 추가되었고, 'search.' 뒤의 'boardtype=L'도 'specialmenutype='으로 수정되었다. 그리고 'totalCount=' 뒤의 숫자도 '151'에서 '501'로 바뀐 것을 확인할 수 있다.
사실 자세하게 뜯어볼 필요는 없고, 마지막 'page=1'의 숫자 '1'을 바꿔 가면서 각 페이지별로 잘 접속되는지, 페이지마다 표시되는 게시물의 수가 50으로 일정한지 정도만 확인해도 충분하다.
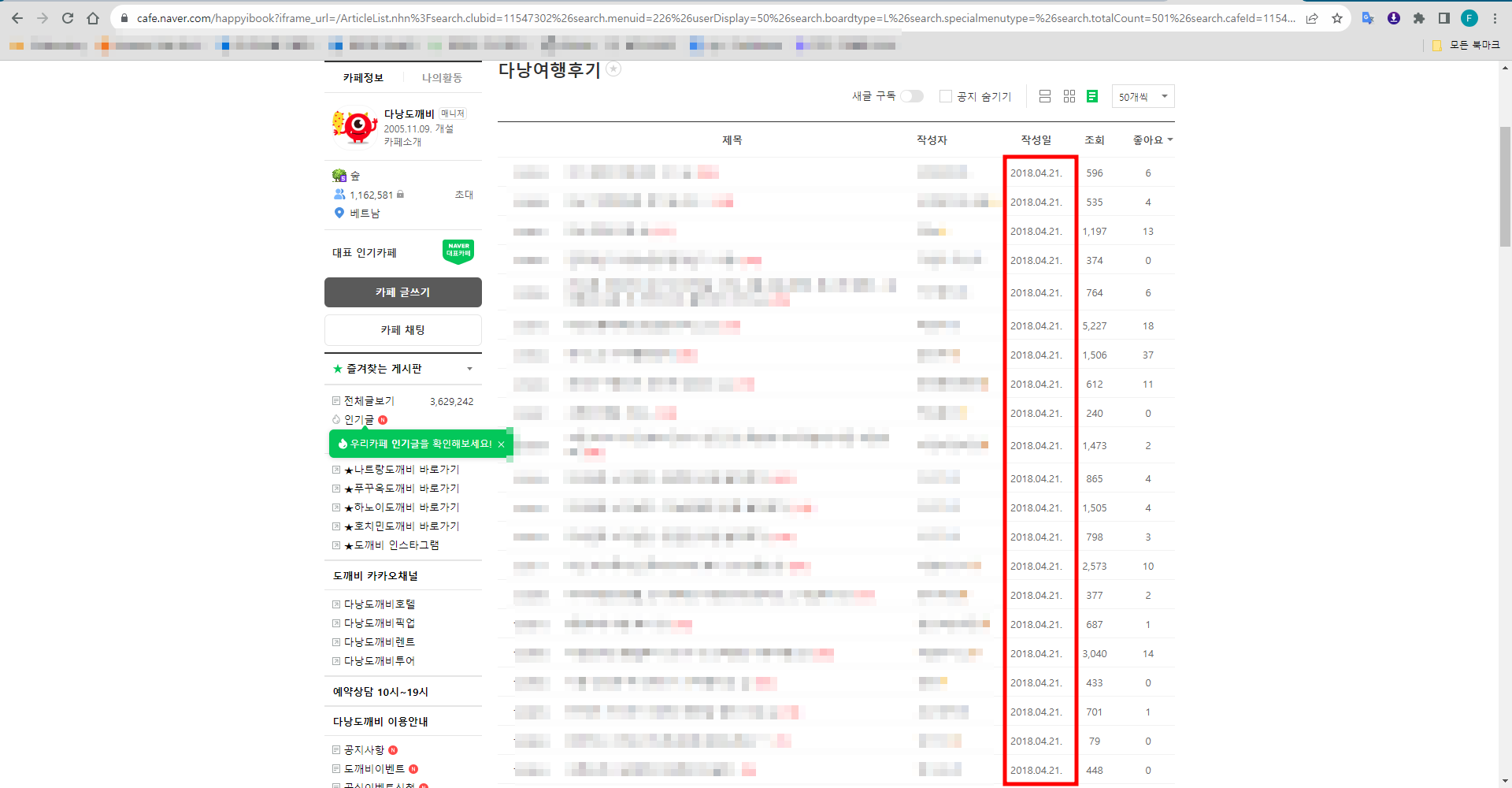 이제 2018년까지의 데이터도 확인할 수 있다.
이제 2018년까지의 데이터도 확인할 수 있다.
그러면 이제 각 지역별 카페를 확인하여 게시물 표시 수를 50으로 바꾼 뒤 url을 확인, 딕셔너리로 저장해 두자. 이때 'page=' 뒤의 수는 지워 두어야 이후 반복문을 통해 게시판을 순회할 때 해당 부분에 게시판 페이지 수를 입력할 수 있다.
urls = {"다낭": "https://cafe.naver.com/happyibook?iframe_url=/ArticleList.nhn%3Fsearch.clubid=11547302%26search.menuid=226%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=11547302%26search.page=",
"호치민": "https://cafe.naver.com/stereovinylcruiser?iframe_url=/ArticleList.nhn%3Fsearch.clubid=24939052%26search.menuid=128%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=24939052%26search.page=",
"하노이": "https://cafe.naver.com/sjdia76?iframe_url=/ArticleList.nhn%3Fsearch.clubid=14464362%26search.menuid=758%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=14464362%26search.page=",
"푸꾸옥": "https://cafe.naver.com/ysm5828?iframe_url=/ArticleList.nhn%3Fsearch.clubid=13903827%26search.menuid=414%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=13903827%26search.page=",
"나트랑": "https://cafe.naver.com/zzop?iframe_url=/ArticleList.nhn%3Fsearch.clubid=10070820%26search.menuid=607%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=10070820%26search.page="
}게시물 XPATH 확인
이번엔 게시판의 게시물에 대하여 각각의 XPATH를 확인해 보자. 게시판의 첫 번째 게시물부터 4번째 게시물, 그리고 마지막 게시물(50번째)까지 각각 XPATH를 복사하여 붙여넣고 비교해 보았다.
//*[@id="main-area"]/div[4]/table/tbody/tr[1]/td[1]/div[2]/div/a[1]
//*[@id="main-area"]/div[4]/table/tbody/tr[2]/td[1]/div[2]/div/a[1]
//*[@id="main-area"]/div[4]/table/tbody/tr[3]/td[1]/div[2]/div/a
//*[@id="main-area"]/div[4]/table/tbody/tr[4]/td[1]/div[2]/div/a[1]
...
//*[@id="main-area"]/div[4]/table/tbody/tr[50]/td[1]/div[2]/div/a[1]
다행히도 tr 뒤의 숫자만 바뀌는 깔끔한 구성이다. a 뒤에 [1]이 붙었다 안 붙었다 하는 애매한 부분은 있지만, [1]의 유무가 크게 영향을 미치지는 않을 것으로 보이니 이 부분은 추후에 테스트를 통해 확인하면 될 것이다.
그러면 각 게시판 페이지별로 게시물을 찾기 위한 XPATH는 다음과 같이 정리할 수 있을 것이다.
f'//*[@id="main-area"]/div[4]/table/tbody/tr[{변수}]/td[1]/div[2]/div/a[1]'게시물 새 탭으로 열기 및 전환
이전과 달리 이제 게시물을 일일이 클릭하여 진입하는 형태이므로 게시판-게시물-게시판(복귀)를 반복해야 한다. 이때 (우리가 브라우저를 이용할 때와 마찬가지로) 두 가지 방법 중 하나를 선택해야 하는데, 하나는 게시물을 클릭하여 데이터를 추출한 후 '뒤로가기'를 통해 되돌아오는 방법이고, 다른 하나는 게시물을 새 탭으로 열어 해당 탭으로 이동한 뒤 데이터를 추출, 추출이 완료되면 탭을 닫고 원래의 탭(게시판)으로 되돌아오는 방법이다.
일단 생각하기로는 게시물을 클릭하고 뒤로가기를 통해 돌아오는 게 단순할 것 같지만, 게시판 페이지를 매번 다시 로드하는 것이 시간 면에서나 안정성 면에서나 썩 좋을 것 같지는 않으니 새 탭으로 여는 방식을 이용하자.
방법 자체는 단순하다. XAPTH를 통해 게시물의 위치를 찾는 것은 이전과 동일하고, 다만 메서드를 .click()이 아니라 .send_keys(Keys.CONTROL+"\n")를 이용하는 것만 다르다.
Keys.CONTROL+"\n"는 ctrl+enter와 동일한 입력이다. 윈도우 등에서 폴더를 열 때에도 ctrl+enter를 이용해 새 창(탐색기)으로 폴더를 열 수 있다.
다만 셀레니움은 새 탭으로 열었다고 해서 자동으로 해당 탭으로 이동하지는 않는다. 그리고 이는 탭을 닫았을 때에도 동일하다. 따라서 '새 탭으로 열기 - 새로 연 탭으로 이동 - 데이터 추출 - 탭 닫기 - 이전 탭(게시판)으로 이동'이라는 단계를 차례로 거쳐야 한다.
탭으로 이동할 때는 .switch_to.window(driver.window_handles[-1]) 메서드를 사용하며, 여기서 [-1]은 현재 열려 있는 탭 중 가장 마지막 탭으로 이동한다는 의미이다. 따라서 이후 탭을 닫고 원래의 탭으로 이동할 때는 저 위치에 [0](첫 번째 탭)을 입력하면 된다.
그 다음 단계는 동일하다. iframe을 전환하고, 데이터를 추출한 뒤 이를 data에 추가한다.
그 다음 .close() 메서드를 이용해 현재 탭을 닫고 .switch_to.window() 메서드로 기존의 탭으로 이동한다.
파일 백업 및 브라우저 재시작
여기까지 진행한다면 이제 게시판에서 게시물을 클릭하여 데이터를 추출하는 작업은 완료된 것이다. 이제는 주기적으로 스크래핑한 데이터를 저장하고, 메모리 누수를 방지하기 위해 브라우저를 재시작하는 작업을 실시한다.
페이지당 게시물 표시 수를 50으로 설정하였으므로 2페이지마다 해당 작업을 실시하기로 하자.
pickle을 이용해 data 변수에 모아 놓은 데이터를 pkl 파일로 저장하고, 셀레니움의 quit() 메서드로 브라우저를 종료한다. 그리고 앞서 선언해 두었던 브라우저 오픈 및 네이버 로그인 함수를 호출하여 브라우저를 다시 실행한다.
반복문의 말미에 해당 작업을 수행하도록 해 두었으므로 자동으로 다음 페이지의 url로 이동, 스크래핑 작업을 실시하게 된다.
if i % 2 == 0: # 게시물 100개 탐색 시마다 데이터 저장 후 브라우저 재시작
# 크롤링한 데이터를 pickle 파일로 저장
with open("./naver_vietnam_city_review.pkl", 'wb') as f:
pickle.dump(data, f)
# 브라우저 재시작
driver.quit()
time.sleep(1)
driver = open_browser()
time.sleep(1)
naver_login(my_id, my_pw)
time.sleep(1)최종 정리
이제 전체 코드를 정리하여 스크래핑을 실시한다. 중간 중간 try-except 구문이나 if문을 통해 몇 가지 추가적인 장치를 설정해 두었는데, 주석을 통해 확인할 수 있다.
브라우저 오픈 및 네이버 로그인 함수 선언
def open_browser():
op = webdriver.ChromeOptions()
chrome_service = ChromeService(ChromeDriverManager().install())
driver = webdriver.Chrome(service = chrome_service, options=op)
return driver
def naver_login(naver_id, naver_pw):
driver.get("https://nid.naver.com/nidlogin.login")
try:
driver.find_element(By.CSS_SELECTOR,'#id') #예외처리에 필요 이 구문이 없으면 아이디가 클립보드에 계속 복사됨
time.sleep(2)
pyperclip.copy(my_id)
driver.find_element(By.CSS_SELECTOR,'#id').send_keys(Keys.CONTROL+'v')
time.sleep(1)
pyperclip.copy(my_pw)
secure='blank'
driver.find_element(By.CSS_SELECTOR,'#pw').send_keys(Keys.CONTROL + 'v')
pyperclip.copy(secure) #비밀번호 보안을 위해 클립보드에 blank 저장
driver.find_element(By.XPATH,'//*[@id="log.login"]').click()
except:
print("no such element") #예외처리스크래핑에 필요한 정보 설정
my_id = "네이버 아이디"
my_pw = "네이버 패스워드"
urls = {"다낭": "https://cafe.naver.com/happyibook?iframe_url=/ArticleList.nhn%3Fsearch.clubid=11547302%26search.menuid=226%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=11547302%26search.page=",
"호치민": "https://cafe.naver.com/stereovinylcruiser?iframe_url=/ArticleList.nhn%3Fsearch.clubid=24939052%26search.menuid=128%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=24939052%26search.page=",
"하노이": "https://cafe.naver.com/sjdia76?iframe_url=/ArticleList.nhn%3Fsearch.clubid=14464362%26search.menuid=758%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=14464362%26search.page=",
"푸꾸옥": "https://cafe.naver.com/ysm5828?iframe_url=/ArticleList.nhn%3Fsearch.clubid=13903827%26search.menuid=414%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=13903827%26search.page=",
"나트랑": "https://cafe.naver.com/zzop?iframe_url=/ArticleList.nhn%3Fsearch.clubid=10070820%26search.menuid=607%26userDisplay=50%26search.boardtype=L%26search.specialmenutype=%26search.totalCount=501%26search.cafeId=10070820%26search.page="
}
cities = urls.keys() # ['다낭', '호치민', '하노이', '푸꾸옥', '나트랑']
data = []
max_board = 400 # 게시판별로 탐색할 최대 페이지 수스크래핑 시작
# 셀레니움 브라우저 오픈
driver = open_browser()
# 최초 로그인
naver_login(my_id, my_pw)
# 최대 대기 시간 설정 : 페이지가 다 로드되지 않았을 때 element를 찾다가
# 오류가 나는 것을 방지하기 위한 설정. 최대 50초까지 기다리고,
# 그 이전에 페이지가 로드되면 자동으로 다음 명령을 실행한다.
driver.implicitly_wait(50)
# 각 지역별로 게시판에 접속하여 순회
for city in cities:
for i in tqdm(range(1, max_board+1)):
driver.get(urls[city]+str(i))
driver.switch_to.frame("cafe_main")
time.sleep(2)
for j in range(1, 51):
# 페이지 오류 등으로 게시물 목록이 오픈되지 않으면 순회 중단
try:
driver.find_element(By.XPATH, f'//*[@id="main-area"]/div[4]/table/tbody/tr[{j}]/td[1]/div[2]/div/a[1]').send_keys(Keys.CONTROL+"\n")
driver.switch_to.window(driver.window_handles[-1])
time.sleep(3.5)
driver.switch_to.frame("cafe_main")
time.sleep(0.5)
except:
break
# 게시물 이상 등으로 데이터를 추출하지 못하더라도 다음 게시물로 넘어가도록 설정
try:
city_name = city
cont_url = driver.find_element(By.XPATH, '//*[@id="spiButton"]').get_attribute('data-url')
cont_num = cont_url.split("/")[-1]
cont_date = driver.find_element(By.CLASS_NAME, 'date').text
cont_author = driver.find_element(By.CLASS_NAME, 'nickname').text
cont_title = driver.find_element(By.CLASS_NAME, 'title_text').text
cont_text = driver.find_element(By.CLASS_NAME, 'se-main-container').text
except:
pass
if len(cont_text) > 0:
data.append([city_name, cont_url, cont_num, cont_date, cont_author, cont_title, cont_text])
# 띄워 놓은 새 탭을 닫고 이전 탭(게시판)으로 이동
driver.close()
driver.switch_to.window(driver.window_handles[0])
driver.switch_to.frame("cafe_main")
# 추가한 데이터가 2021년 이전 데이터일 경우 탐색을 중단
if cont_date[:4] <= '2020':
break
if i % 2 == 0: # 게시물 100개 탐색 시마다 데이터 저장 후 브라우저 재시작
# 크롤링한 데이터를 pickle 파일로 저장
with open("./naver_vietnam_city_review.pkl", 'wb') as f:
pickle.dump(data, f)
# 브라우저 재시작
driver.quit()
time.sleep(1)
driver = open_browser()
time.sleep(1)
naver_login(my_id, my_pw)
time.sleep(1)
# 도시별 탐색이 마무리될 때마다 데이터 저장
with open("./naver_vietnam_city_review.pkl", 'wb') as f:
pickle.dump(data, f)사실 베트남 카페 탐색에 앞서 태국 여행 카페를 상기와 유사한 코드로 탐색하였으며, 중간에 예상치 못한 오류가 발생하는 경우를 제외하면 out of memory 등의 에러 발생 없이 성공적으로 스크래핑이 진행되었다. 그리고 그 예상치 못한 오류(주로 페이지 로드 완료 이전에 element를 탐색하면서 발생한 오류들)들을 방지하기 위해 몇 가지 장치를 추가한 것이 상기 최종 코드이다(물론 늘 말하듯이 나는 개발자는커녕 개나 발 정도의 프로그래밍 능력을 보유하였으므로 위의 코드가 좋은 코드라고 하지는 못하겠다).
selenium 특성상 bs에 비해 속도가 상당히 느리다는 게 아쉽지만, 그래도 동적 페이지로 구성된 웹사이트를 탐색하는 데 도움이 많이 되었다. 앞서 첫 번째 포스트의 코드와 이번 최종 코드를 본인이 탐색하고자 하는 카페에 맞게 수정해서 사용하다 보면 selenium의 사용 방법 자체를 쉽게 이해할 수 있을 것이며, 카페뿐만 아니라 다른 동적 웹사이트의 탐색에도 쉽게 응용할 수 있을 것이다(내가 그랬기 때문에).
