
1편에서는 OTEL + Grafana 스택을 띄우고 첫 번째 지표 확인,
2편에서는 Spring Boot → Prometheus/Loki 로그·메트릭 수집을 정리했습니다.
이번 3편에서는,
수집된 데이터(메트릭·로그)를 운영 친화적인 Grafana 대시보드로 정비하는 과정을 공유합니다.
제가 직접 겪은 문제와,
변수를 정비하고 패널을 커스터마이징하면서 얻은 경험을 풀어보겠습니다.
1. Before – 기본 Spring Boot 대시보드 한계
처음에는 Grafana에서 제공하는 Spring Boot Metrics (ID: 6756) 대시보드를 불러왔습니다.
하지만 기본 상태에서는 문제가 많았습니다.
- 변수(Query) 설정이 잘못되어 필터 드롭다운이 “No data”를 띄움
- JVM/CPU 지표는 나오지만, 실제 서비스 진단에는 부족
- SQL 로그 같은 운영 분석 지표는 없음
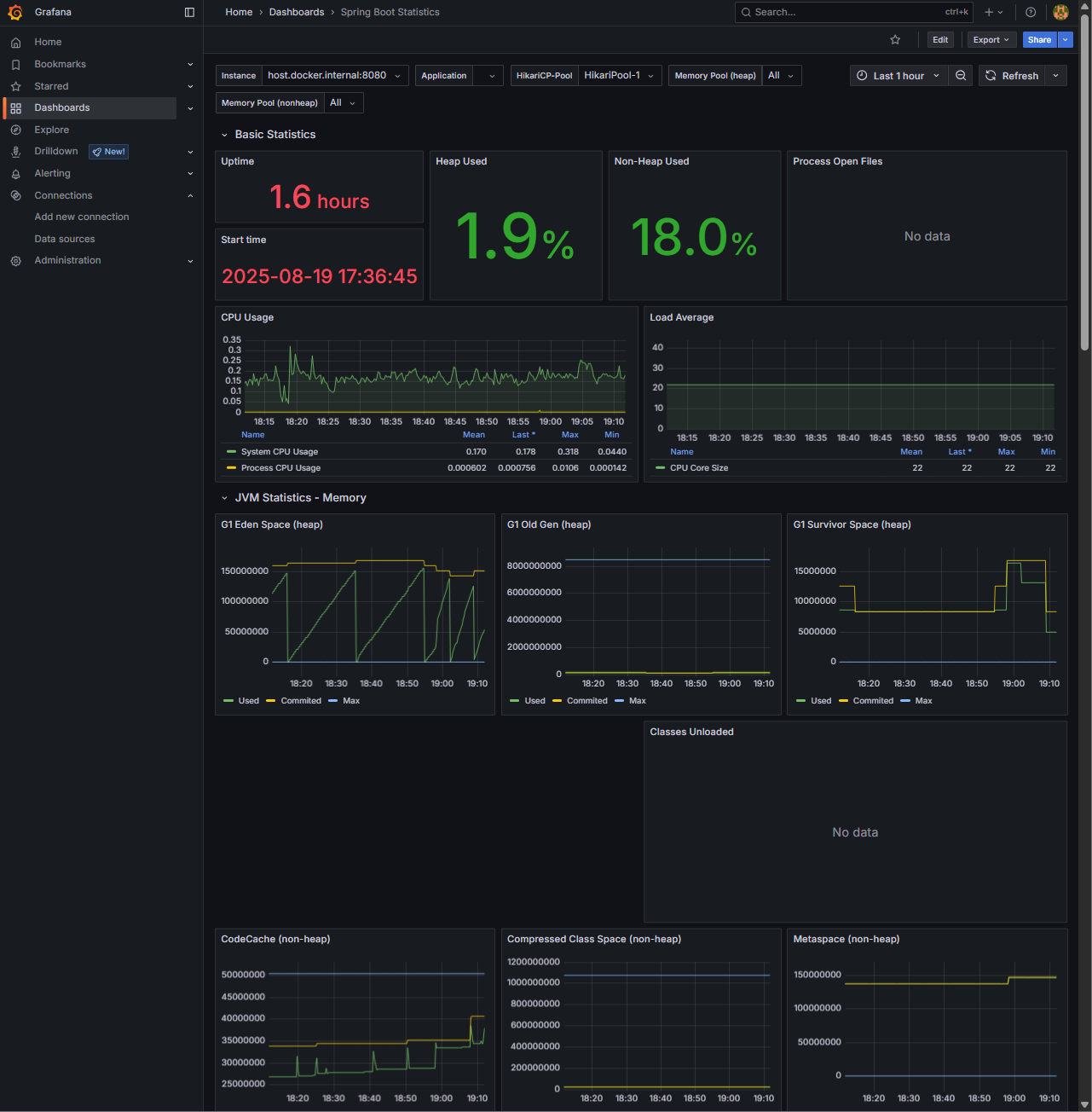
결론: 데이터는 있는데 시각화가 답답하다는 느낌.
운영자가 바로 원인 분석하기엔 부족했습니다.
2. Variables 오류 수정
문제 원인: Dashboard Variables 정의가 실제 라벨과 불일치.
예: instance 변수가 잘못된 메트릭을 기준으로 작성되어 값이 안 나옴.
해결: label_values(metric, label)로 정확히 수정.
# 수정 예시
label_values(http_server_requests_seconds_count, job)
label_values(http_server_requests_seconds_count, instance)
이 과정을 통해 서비스별 / 인스턴스별 Drill-down이 가능해졌습니다.
3. Explore + Prometheus로 검증
수정된 변수가 올바른지 확인하려면,
Prometheus에서 해당 메트릭이 실제 수집되고 있는지 먼저 체크하는 게 중요합니다.
- Spring Boot 애플리케이션 →
http://localhost:8080/actuator/prometheus에서 노출 확인
- Prometheus 웹 UI →
http://localhost:9090/graph→http_server_requests_seconds_count입력 → 라벨(job, instance, uri, method 등) 확인
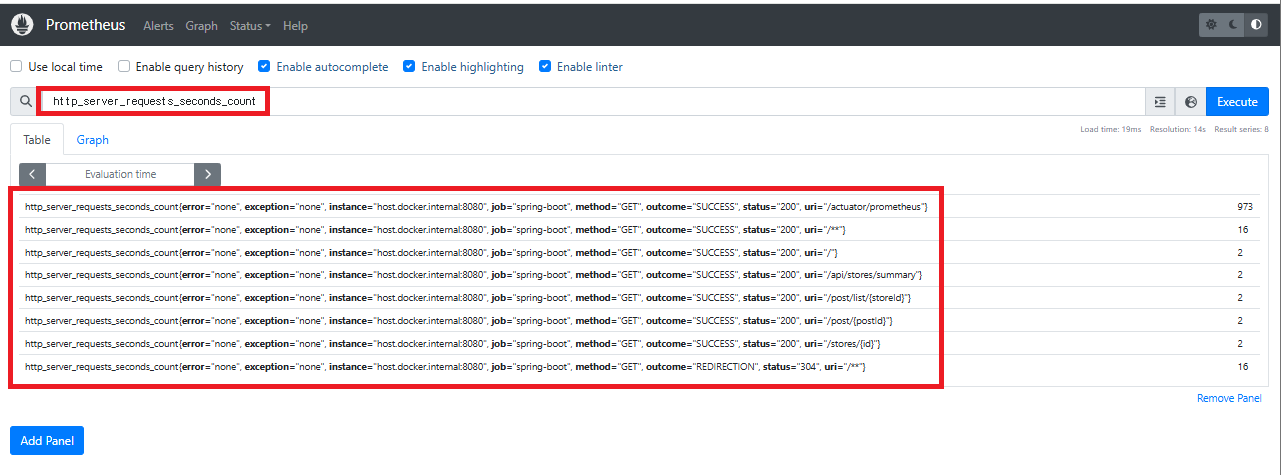
이 과정을 거치면, Grafana 변수가 실제 존재하는 라벨 기반인지 확실히 검증할 수 있습니다.
🔧 4. After – 커스텀 대시보드 구성
단순 지표 모니터링에서 그치지 않고, 운영자가 즉시 활용할 수 있는 패널을 추가했습니다.
SQL 로그 패널
- Loki 쿼리:
{job="pinup-service"} |= "select" | json - SQL 실행 로그(JSON) 조회 → DB 쿼리 병목 추적 가능
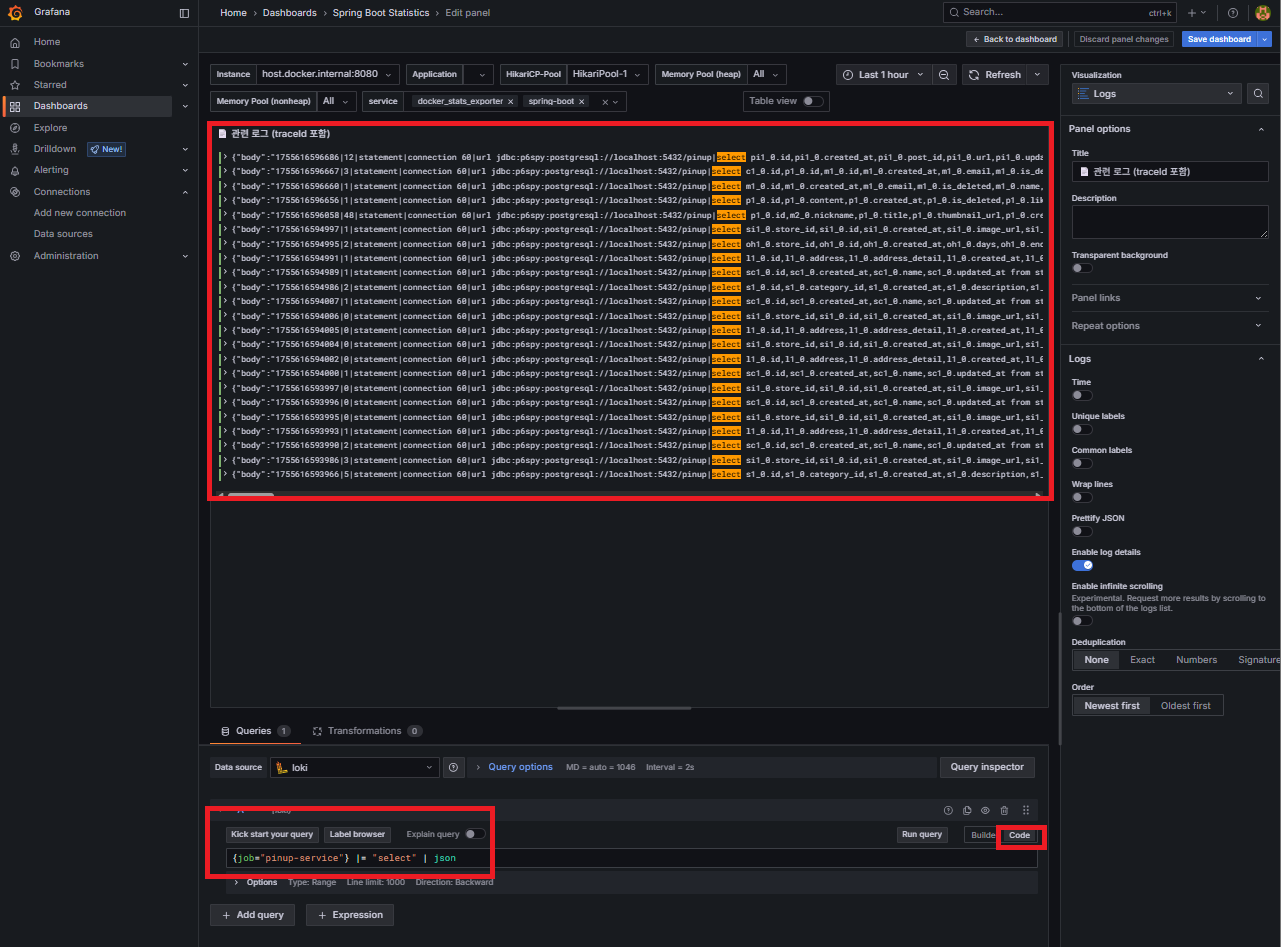
커스텀 지표 개선
- 기존 JVM/CPU 그래프에 $job / $instance 변수 반영
- SQL 로그 + 메트릭을 한 대시보드에서 동시에 확인 가능
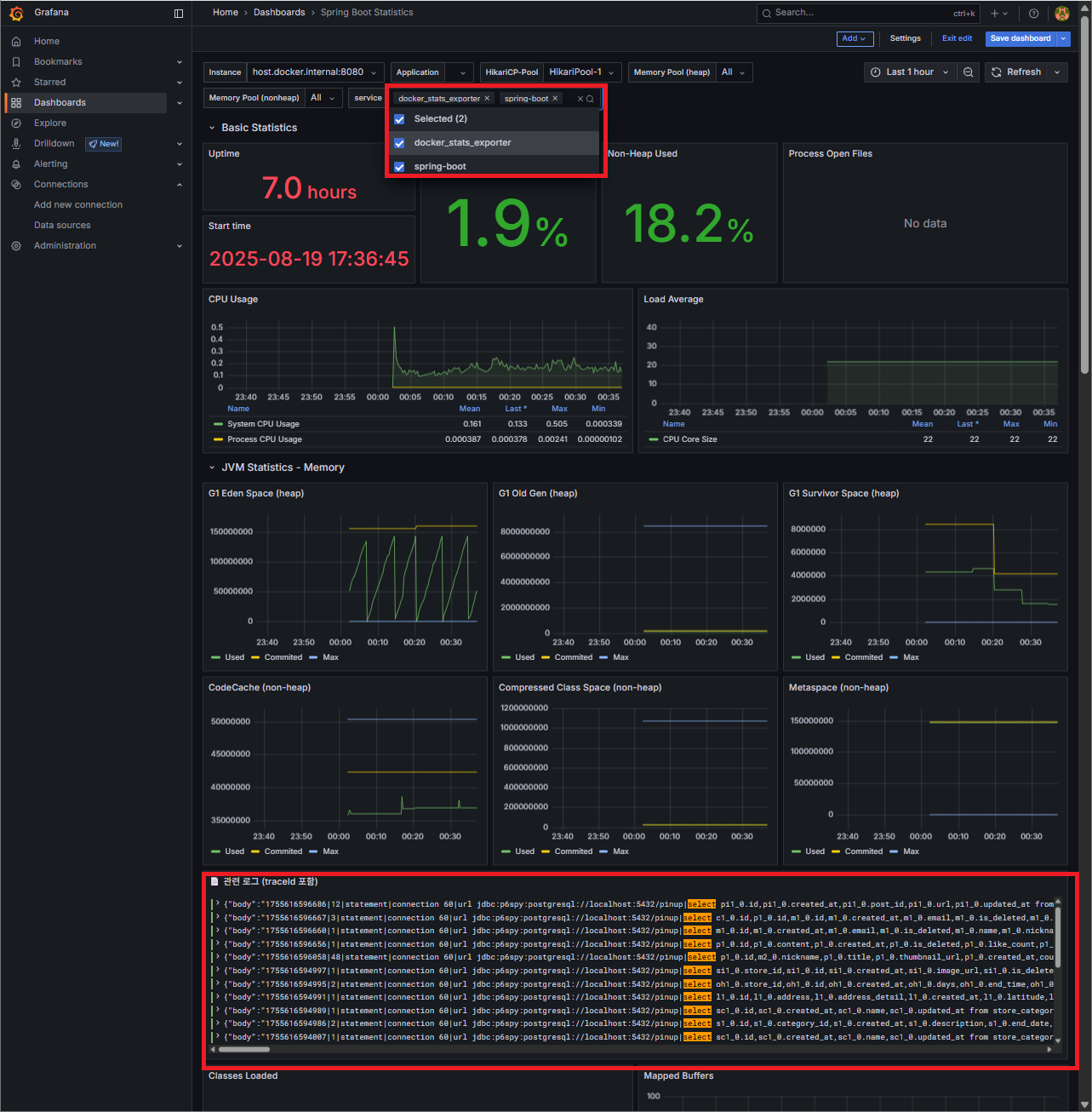
결과적으로, 단순한 메트릭 뷰어 →
실제 문제 원인을 추적할 수 있는 운영 대시보드로 발전했습니다.
✅ 마무리
이번 편에서 배운 점:
- Grafana 기본 대시보드는 Import만으로는 부족 → Variables/쿼리 수정이 필요
- Prometheus
/graph에서 라벨 확인 → Grafana 변수 정의 신뢰성 확보 - Loki 로그 패널 추가 → SQL Slow Query까지 한 눈에 모니터링 가능
다음 편(4편)에서는 OTEL Agent + Tempo로 슬로우 쿼리 트레이싱을 통합하는 과정을 다룰 예정입니다.
