[6편] DB 인덱스와 JPQL 최적화로 성능 ×39배 개선하기
Side Projects

전략 A(단일 3개) vs 전략 B(복합+보조 1개), 그리고 JPQL 최적화까지
들어가며
이번 글은 제가 Pinup 서비스 /post/list/{storeId} API 병목을 실제로 어떻게 개선했는지 기록한 글입니다.
특히 강조하고 싶은 점은, 제가 단순히 쿼리 튜닝부터 시작한 게 아니라는 겁니다.
먼저 Tomcat Thread / HikariCP 커넥션 풀 / JVM Heap 같은 서버·DB 설정을 점검했습니다.
목표
“지금은 프리티어지만, 내 서비스의 성격(=커뮤니티형)을 기준으로 미리 성능 설계를 잡고,
로컬에서 최대한 현실적인 부하 테스트를 해보자.”
- 운영이 저사양(t2.micro)이므로, 그 수준을 그대로 테스트하는 건 의미 없다고 판단.
- 서비스 구조(=읽기 중심 + 일부 burst 쓰기)가 어떤 병목을 만드는지 먼저 이해해야 확장 가능.
- 따라서 운영 서버 기준이 아니라 서비스 성격 기준으로 설정을 잡았다.
설정 기준
-
로컬은 여유가 있으니, 실제 커뮤니티처럼 100명 이상 동시 요청 상황을 시뮬레이션
-
운영은 추후 t3.medium 이상 업그레이드 예정이므로 이식 가능한 기준을 지금부터 마련
즉, 지금 하는 건 단순 “프리티어 맞춤”이 아니라, 향후 확장에도 그대로 가져갈 수 있는 기반을 다져두는 작업이다.
서비스 개요
PinUp은 실시간 팝업 리스트와 위치를 제공하며 사용자 참여를 유도하는 커뮤니티 플랫폼입니다.
-
기술 스택: Spring Boot, Spring Security, PostgreSql, AWS EC2, Docker
-
기능 구조:
- 실시간 팝업 리스트 조회 (읽기 중심, 반복성 높음)
- 후기 작성, 좋아요, 댓글 (쓰기 중심, 간헐적)
- OAuth2 로그인 및 세션 유지
-
운영 환경: AWS EC2 프리티어 (t2.micro)
내가 점검한 서버/DB 설정
# Tomcat (Web Thread)
server.tomcat.max-threads: 32
server.tomcat.accept-count: 100
server.tomcat.connection-timeout: 15000
# HikariCP (DB Connection Pool)
spring.datasource.hikari.maximum-pool-size: 30
spring.datasource.hikari.minimum-idle: 10
spring.datasource.hikari.connection-timeout: 15000
# JVM Heap
-Xmx: 4096m
-Xms: 512m문제 정의와 초기 상황
- 대상 API:
GET /post/list/{storeId} - 서비스 특성: 커뮤니티형 (읽기 중심 + 댓글/좋아요 집계가 많음)
- 초기 증상:
- 단일 요청도 9초+ (curl 실측)
- 10 VU 부하에서 p95가 50초까지 상승
초기 구현(문제 코드):
return posts.stream()
.map(post -> PostResponse.fromPostWithComments(
post,
commentRepository.countByPostId(post.getId()),
postLikeRepository.existsByPostIdAndMemberId(post.getId(), member.getId())
))
.collect(Collectors.toList());
-
게시글 1건마다 2쿼리 (댓글 수, 좋아요 여부) → N+1 폭발
-
댓글이 많은 특성상 Full Scan + 반복 집계로 I/O 과다
실험 환경
- 데이터 세팅
- 스토어 100개
- 게시글: 스토어당 100개 → 총 1만
- 댓글: 게시글당 50~200 랜덤 → 총 24만+
- 좋아요: 랜덤 분포
- 측정 도구
- k6: Baseline(1 VU, 1분) / Light Load(10 VU, 3분)
- curl: 단일 요청 실측
- Grafana: p95 Latency, HikariCP, GC
- pg_stat_statements: 호출 수/총시간/평균/표준편차 + 블록 I/O
- EXPLAIN (ANALYZE, BUFFERS): 실행 플랜/버퍼
1) 쿼리 패턴과 병목
핵심 쿼리:
SELECT p.id, p.title, p.created_at, COUNT(c.id) AS comment_count
FROM posts p
LEFT JOIN comments c ON c.post_id = p.id
WHERE p.store_id = :storeId
GROUP BY p.id
ORDER BY p.created_at DESC;
패턴 요약
- WHERE:
store_id - ORDER BY:
created_at DESC - 집계:
COUNT(c.id)
필터(store_id) + 정렬(created_at) 을 한 번에 커버하는 인덱스가 핵심.
2) 인덱스 전략
전략 A: 단일 인덱스 3개
CREATE INDEX IF NOT EXISTS idx_comment_post_id ON comments(post_id);
CREATE INDEX IF NOT EXISTS idx_post_store_id ON posts(store_id);
CREATE INDEX IF NOT EXISTS idx_post_created_at ON posts(created_at DESC);
- 장점: 적용이 단순, 부분적으로 체감 개선
- 단점: 필터 후 정렬이라 정렬 비용/랜덤 I/O가 일부 남음
전략 B: 복합 + 보조 1개 ✅ 최종 채택
CREATE INDEX IF NOT EXISTS idx_comment_post_id ON comments(post_id);
CREATE INDEX IF NOT EXISTS idx_posts_store_created ON posts(store_id, created_at DESC);
- 장점: 필터+정렬을 한 번에 커버 → 정렬 비용·랜덤 I/O 최소화
- 관찰 포인트: 캐시/디스크 I/O 안정성
3) EXPLAIN(ANALYZE, BUFFERS) 전/후
쿼리
EXPLAIN (ANALYZE, BUFFERS)
SELECT p.id, p.title, p.created_at, COUNT(c.id) AS comment_count
FROM posts p
LEFT JOIN comments c ON c.post_id = p.id
WHERE p.store_id = 1
GROUP BY p.id
ORDER BY p.created_at DESC;
-
인덱스 없음 —
Execution Time: 324.659 ms이미지:
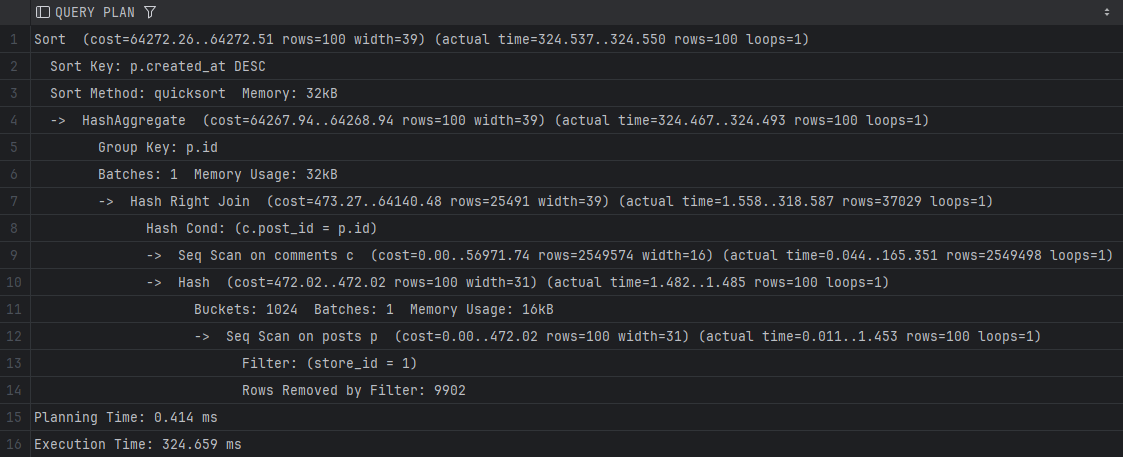
포인트:
Seq Scan + HashAggregate,shared_blks_read매우 큼. -
전략 A(단일 3개) —
Execution Time: 9.717 ms이미지:
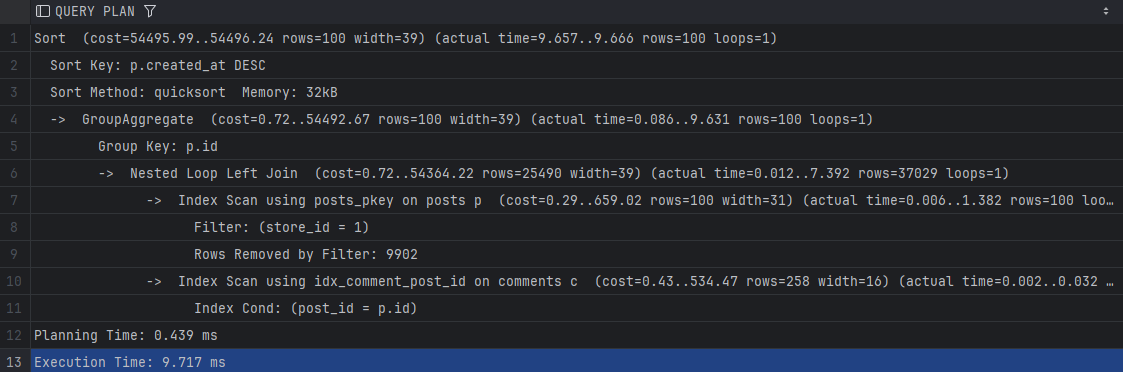
포인트:
Index Scan로 전환, 정렬비용 잔존. -
전략 B(복합+보조) —
Execution Time: 8.698 ms이미지:
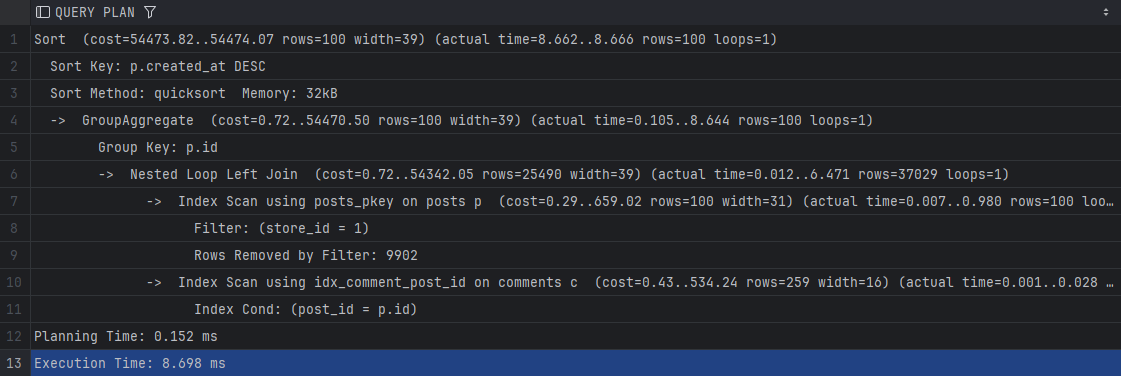
포인트: 필터+정렬 동시 충족 → 추가로 1ms 정도 더 단축.
캡션 예시: “복합 인덱스에서 ORDER BY p.created_at DESC가 인덱스 순서로 해결 → 정렬/랜덤 I/O 감소.”
4) pg_stat_statements 요약 (50회 반복 실행)
쿼리:
SELECT
calls,
round(total_exec_time::numeric, 2) AS total_ms,
round(mean_exec_time::numeric, 2) AS mean_ms,
round(stddev_exec_time::numeric, 2) AS stddev_ms,
rows, shared_blks_hit, shared_blks_read, query
FROM pg_stat_statements
WHERE query ILIKE '%FROM posts p%'
AND query ILIKE '%GROUP BY p.id%'
AND query ILIKE '%ORDER BY p.created_at%'
ORDER BY total_exec_time DESC
LIMIT 5;
표 1 — pg_stat_statements(고정 세션에서 50회 반복)
| 시나리오 | calls | total_ms | mean_ms | stddev_ms | rows | shared_blks_hit | shared_blks_read |
|---|---|---|---|---|---|---|---|
| 인덱스 없음 | 50 | 8,986.75 | 179.73 | 13.40 | 5,000 | 162,950 | 1,428,200 |
| 전략 A (단일 3개) | 50 | 378.44 | 7.57 | 1.94 | 5,000 | 73,768 | 32 |
| 전략 B (복합+보조) | 50 | 406.89 | 8.14 | 2.35 | 5,000 | 73,800 | 0 |
해석
- shared_blks_read(디스크 블록 읽기)가 “인덱스 없음 → 전략 A/B”에서 1,428,200 → 32/0으로 급락 → I/O 병목 제거가 핵심.
- 평균 실행(ms)은 A≈B이지만, B는 읽기 0으로 더 안정적(캐시 적중/정렬 회피).
한 줄 결론: “단일 3개 ≠ 복합 1개. 우리 패턴에서는 복합이 ‘정렬 비용’까지 없앤다.”
5) JPQL 최적화 — 집계/존재 여부는 한 번에
개선 전 (N+1 패턴)
return posts.stream()
.map(post -> PostResponse.fromPostWithComments(
post,
commentRepository.countByPostId(post.getId()),
postLikeRepository.existsByPostIdAndMemberId(post.getId(), member.getId())
))
.collect(Collectors.toList());
- 게시글 N건 × 2쿼리 → 폭발
개선 후 (DTO 프로젝션 + EXISTS)
@Query("""
SELECT new kr.co.pinup.posts.model.dto.PostResponse(
p.id,
p.member.nickname,
p.title,
p.thumbnail,
p.createdAt,
COUNT(c.id), -- 댓글 수
p.likeCount, -- 유지된 좋아요 수
CASE
WHEN :memberId IS NOT NULL AND
EXISTS (SELECT 1 FROM PostLike pl WHERE pl.post.id = p.id AND pl.member.id = :memberId)
THEN TRUE ELSE FALSE
END
)
FROM Post p
LEFT JOIN Comment c ON c.post.id = p.id
WHERE p.store.id = :storeId
AND p.isDeleted = :isDeleted
GROUP BY p.id, p.member.nickname, p.title, p.thumbnail, p.createdAt, p.likeCount
ORDER BY p.createdAt DESC
""")
List<PostResponse> findPostListItems(Long storeId, boolean isDeleted, Long memberId);
- 댓글 집계: COUNT 한 번으로 끝
- 좋아요 여부: EXISTS → 불필요 조인 방지
- DTO 프로젝션으로 추가 변환 비용 제거
6) 최종 결과
단일 요청 (curl)
| 단계 | Real(s) | 개선 배수 |
|---|---|---|
| 인덱스 전 | 9.147 | – |
| 인덱스 후 | 0.450 | ×20.3 |
| 인덱스 + JPQL | 0.230 | ×2.0 / ×39.8 |
k6 (Baseline: 1 VU, 1분)
| 단계 | p95(ms) | 평균(ms) | 요청 수 | 개선 |
|---|---|---|---|---|
| 인덱스 전 | 304.43 | 257.16 | 48 | – |
| 인덱스 후 | 70.48 | 43.36 | 58 | ×4.32 |
| 인덱스 + JPQL | 41.34 | 30.11 | 59 | ×7.36 |
k6 (Light: 10 VU, 3분)
| 단계 | p95(ms) | 평균(ms) | 요청 수 | 개선 |
|---|---|---|---|---|
| 인덱스 전 | 320.72 | 208.55 | 1,495 | – |
| 인덱스 후 | 42.33 | 31.53 | 1,750 | ×7.57 |
| 인덱스 + JPQL | 39.55 | 30.68 | 1,750 | ×8.11 |
- 여기서 중요한 건,
“환경 튜닝은 병목을 좁히는 과정”이었고,
“실제 개선은 쿼리/JPQL 최적화”에서 터졌다는 겁니다.
즉, 설정을 먼저 확인했기에 병목의 원인을 정확히 DB로 좁힐 수 있었고,
DB 최적화(쿼리/JPQL 최적화)로 전환했기에 ×39배 개선을 만들 수 있었습니다.
7) 부하 테스트 & Grafana 대시보드 측정
인덱스/JPQL 최적화를 하고 나서, 실제 k6 부하를 걸고 Grafana 대시보드로 측정했다.
단순 수치 로그(k6 CLI 출력)만 보는 게 아니라, 커스텀 대시보드에서 p95 Latency 패널을 잡아둔 덕분에 Before/After 그래프를 시각적으로 비교할 수 있었다.
Light Load (10 VU, 3분)
- Before: p95 ~320ms
- After: p95 ~39ms
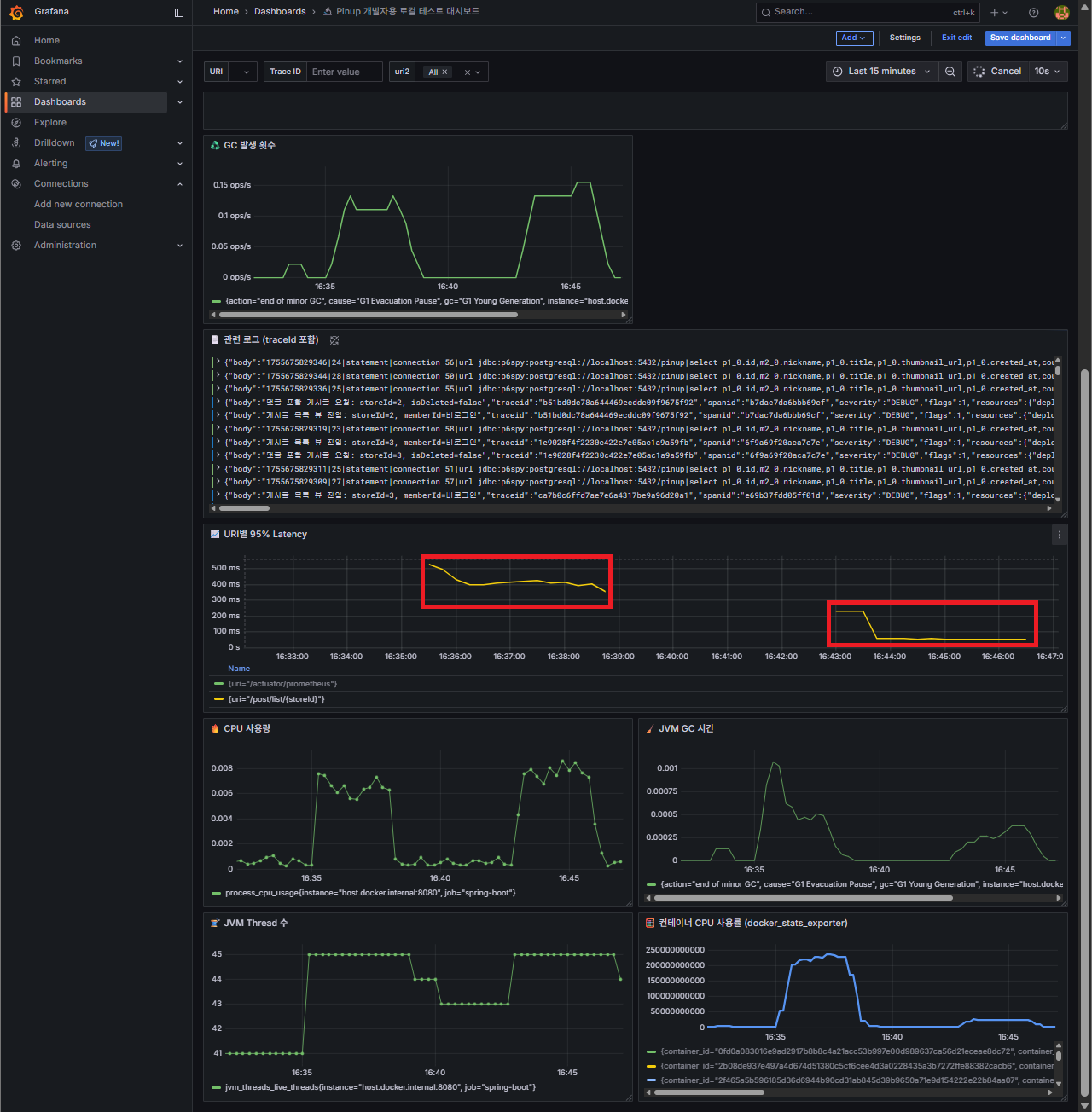
-
효과: 수치상으로는 7~8배 개선, 그래프 상으로는 “Latency 밴드가 통째로 내려앉은 것”이 눈에 보였다.
-
포인트: 운영 대시보드와 달리, 로컬에서는 성능 개선 전후를 같은 구간에 겹쳐보는 게 핵심이다.
8) 내가 배운 점
- 인덱스는 패턴에 맞춘다 단일 3개 ≠ 복합 1개. 이 쿼리(WHERE store_id + ORDER BY created_at)엔 복합 인덱스가 정답.
- 순서가 중요하다: 인덱스 → JPQL 먼저 I/O 병목 줄이고, 그다음 N+1/조인 구조 정리 → p95와 평균 모두 안정화.
- 측정 가능한 개선만 남긴다 pg_stat_statements, EXPLAIN, k6, Grafana p95 → 전/후 수치가 있으면 협업·블로그·이력서에서 설득력이 생김.
- 실패 경험도 자산 전략 A가 순간 평균은 더 좋아 보였지만, shared_blks_read가 남아 B를 선택. cadvisor 라벨 실패 → docker_stats_exporter로 전환. 이런 시행착오가 글에 힘을 실어줌.
9) 재현용 스크립트
-- 초기화
DROP INDEX IF EXISTS idx_comment_post_id;
DROP INDEX IF EXISTS idx_post_store_id;
DROP INDEX IF EXISTS idx_post_created_at;
DROP INDEX IF EXISTS idx_posts_store_created;
-- 전략 A: 단일 3개
CREATE INDEX IF NOT EXISTS idx_comment_post_id ON comments(post_id);
CREATE INDEX IF NOT EXISTS idx_post_store_id ON posts(store_id);
CREATE INDEX IF NOT EXISTS idx_post_created_at ON posts(created_at DESC);
-- 전략 B: 복합 + 보조 1개 (A 제거 후)
DROP INDEX IF EXISTS idx_post_store_id;
DROP INDEX IF EXISTS idx_post_created_at;
CREATE INDEX IF NOT EXISTS idx_comment_post_id ON comments(post_id);
CREATE INDEX IF NOT EXISTS idx_posts_store_created ON posts(store_id, created_at DESC);
ANALYZE posts;
ANALYZE comments;
측정 쿼리
SELECT pg_stat_statements_reset();
-- 동일 세션에서 50회 반복 실행
SELECT p.id, p.title, p.created_at, COUNT(c.id)
FROM posts p
LEFT JOIN comments c ON c.post_id = p.id
WHERE p.store_id = 1
GROUP BY p.id
ORDER BY p.created_at DESC;
-- 집계
SELECT
calls,
round(total_exec_time::numeric, 2) AS total_ms,
round(mean_exec_time::numeric, 2) AS mean_ms,
round(stddev_exec_time::numeric, 2) AS stddev_ms,
rows, shared_blks_hit, shared_blks_read, query
FROM pg_stat_statements
WHERE query ILIKE '%FROM posts p%'
AND query ILIKE '%GROUP BY p.id%'
AND query ILIKE '%ORDER BY p.created_at%'
ORDER BY total_exec_time DESC
LIMIT 5;
마무리
B-Tree는 “어떤 순서로 쓰는가”에 따라 성능이 갈렸다.
전략 B(복합 인덱스)로 정렬까지 커버하고, JPQL 최적화로 N+1 제거하자,
- 단일 요청: ×39.8배 개선
- 부하 p95: ×7~8배 개선
측정 기반으로 성과를 증명할 수 있었고, 이 경험 자체가 제일 값진 수확이었다.
