
Spring Boot Cache 심화: Caffeine 내부 구조 완전 정리
— Spring Cache 추상화 원리부터 JVM 내부 구조까지
“왜 Caffeine인가?”
이 글은 Spring Cache 추상화의 기본 원리부터 Caffeine 캐시의 내부 동작까지, JVM 수준에서 캐시가 어떻게 작동하는지를 완전히 해부합니다.
2편에서는 이 개념을 기반으로 PinUp 서비스에 실제 적용한 설계 구조를 다룹니다.
1. Spring Cache 추상화 기본 구조
1-1. Cache Abstraction 개요
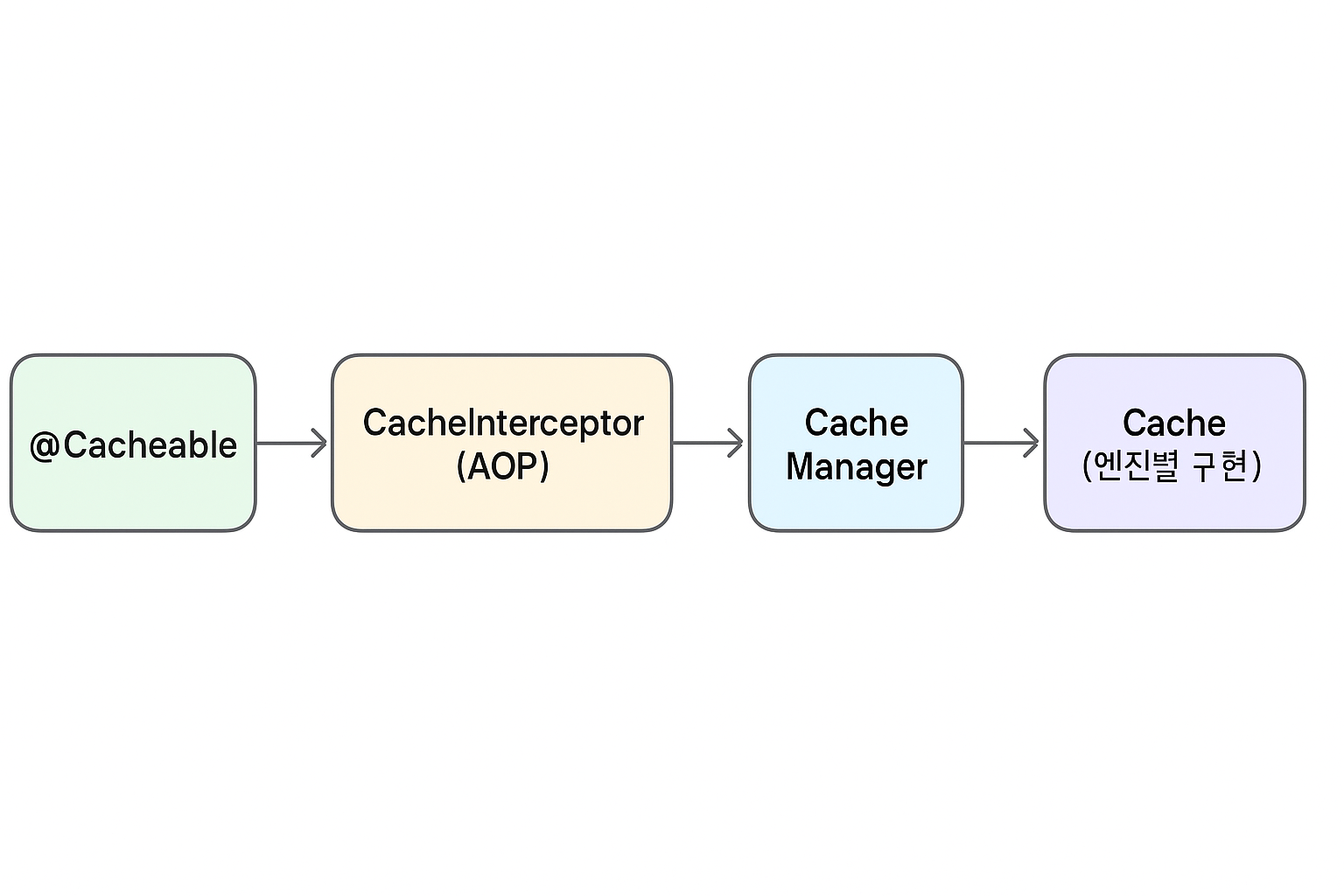
핵심 개념: Cache Abstraction, @Cacheable, CacheManager, AOP Proxy, CacheInterceptor
Spring Cache는 다양한 캐시 엔진(Caffeine, Ehcache, Redis 등)을 공통 인터페이스로 감싸고,
AOP 프록시를 통해 메서드 호출을 가로채 캐싱 로직을 적용합니다.
동작 흐름
`
⚠️ 주의: 같은 클래스 내에서 자기 자신 메서드를 호출(self-invocation)하면 프록시를 우회해 캐시가 적용되지 않습니다.
구조 분리 또는 인터페이스 추출을 권장합니다.
1-2. CacheManager ↔ Cache 구현체 연결 구조
| 구성 요소 | 역할 |
|---|---|
| @Cacheable | 프록시가 메서드 호출을 가로채 캐시 조회/저장 여부 결정 |
| CacheInterceptor | 캐시 hit/miss 판단 및 put/evict 처리 로직 |
| CacheManager | 캐시 이름으로 Cache 인스턴스 조회/생성 |
| Cache 구현체 | 실제 저장소 (CaffeineCache, EhcacheCache, RedisCache 등) |
@Configuration
@EnableCaching
public class CacheConfig {
@Bean
public CacheManager cacheManager() {
var cm = new CaffeineCacheManager("posts", "users");
cm.setCaffeine(com.github.benmanes.caffeine.cache.Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(java.time.Duration.ofMinutes(10))
.recordStats());
return cm;
}
}
1-3. Spring Boot 자동 구성 원리
Spring Boot는 클래스패스에 존재하는 라이브러리를 자동 감지해 적절한 CacheManager를 구성합니다.
우선순위 예시
JCache → Ehcache → Hazelcast → Infinispan → Couchbase → Redis → Caffeine → Simple
- 별도의 라이브러리가 없으면 기본적으로
SimpleCacheManager(ConcurrentMap 기반)사용 - 단, TTL/Size 제한 없음 → 운영 환경에는 부적합
cach 관련해서 yml 을 작성이랑 어떻게 작동하는지 이런것에대해서 적는게 어떠할까???
2. Local vs Global Cache
| 구분 | Local Cache | Global(Distributed) Cache |
|---|---|---|
| 위치 | 각 JVM 내부 (온-힙/오프힙) | 외부 캐시 서버 (Redis, Hazelcast 등) |
| 지연 | 네트워크 hop 없음 → 초저지연 | 네트워크 왕복 존재 |
| 일관성 | 인스턴스 간 불일치 가능 (무효화 전략 필요) | 공유 일관성 및 전파 용이 |
| 운영성 | 단순 (내부 메모리 관리 중심) | 인프라/장애 대응 복잡 |
| 확장성 | 인스턴스별 중복 저장 | 클러스터 확장 용이 |
Local: 초저지연·단순 운용이 강점이나 다노드 일관성이 과제
Global: 일관성·공유성은 뛰어나지만 네트워크 비용·운영 복잡성 존재
3. Java 캐시 엔진 비교
| 엔진 | 핵심 특징 | 장점 | 한계/비고 |
|---|---|---|---|
| Caffeine | 순수 Java, W-TinyLFU | 고성능, TTL/size/통계 지원 | In-memory 전용 |
| Ehcache 3 | Heap + Off-heap + Disk 티어링 | 대용량·지속성 | 설정 복잡, 과스펙 가능 |
| Guava Cache | LRU 중심 간단 구조 | 가벼움 | 기능 제한, 유지보수 축소 |
| Redis | 분산/공유 | TTL, Pub/Sub, 클러스터 | 네트워크 비용 |
| Memcached | 단순 K-V 구조 | 초고속 읽기 | TTL 외 기능 부족 |
오프힙/디스크 티어링이 필요하면 Ehcache,
단일 JVM 초저지연이면 Caffeine이 가장 효율적입니다.
4. Caffeine vs Ehcache 3 심층 비교
| 관점 | Caffeine | Ehcache 3 |
|---|---|---|
| 성능/지연 | 매우 낮음 (온-힙) | 티어링 시 지연 증가 |
| 용량/티어링 | 온-힙 중심 | Heap + Off-heap + Disk |
| 알고리즘 | W-TinyLFU | 다양한 정책 |
| 분산/클러스터 | 없음 | 가능 (별도 구성) |
| 운영 복잡도 | 낮음 | 높음 |
| 적합성 | 단일/소수 노드, 읽기 중심 | 대용량·클러스터 환경 |
“노드 1~N의 초저지연, 단기 TTL 중심” → Caffeine
“대용량/지속성/클러스터 필요” → Ehcache 3
5. Caffeine 내부 구조 및 JVM 동작 원리
5-1. Caffeine이 빠른 이유
Caffeine은 JVM 내부에서 직접 작동하는 고성능 인메모리 캐시입니다.
직렬화나 네트워크 hop 없이 Java 객체를 그대로 힙 메모리에 유지합니다.
Cache<String, User> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.weakKeys()
.expireAfterWrite(5, TimeUnit.MINUTES)
.build();
특징 요약
- On-Heap 구조 → 네트워크·직렬화 비용 없음
- 나노초 단위 접근 → JVM 메모리 직접 접근
- GC 친화적 관리 → weakKeys(), softValues()
- 명시적 크기 제한으로 OOM 방지
5-2. 내부 구조 개요
Caffeine의 핵심 클래스는 BoundedLocalCache이며,
내부적으로 ConcurrentHashMap + TTL + Eviction + Concurrency 계층으로 구성됩니다.
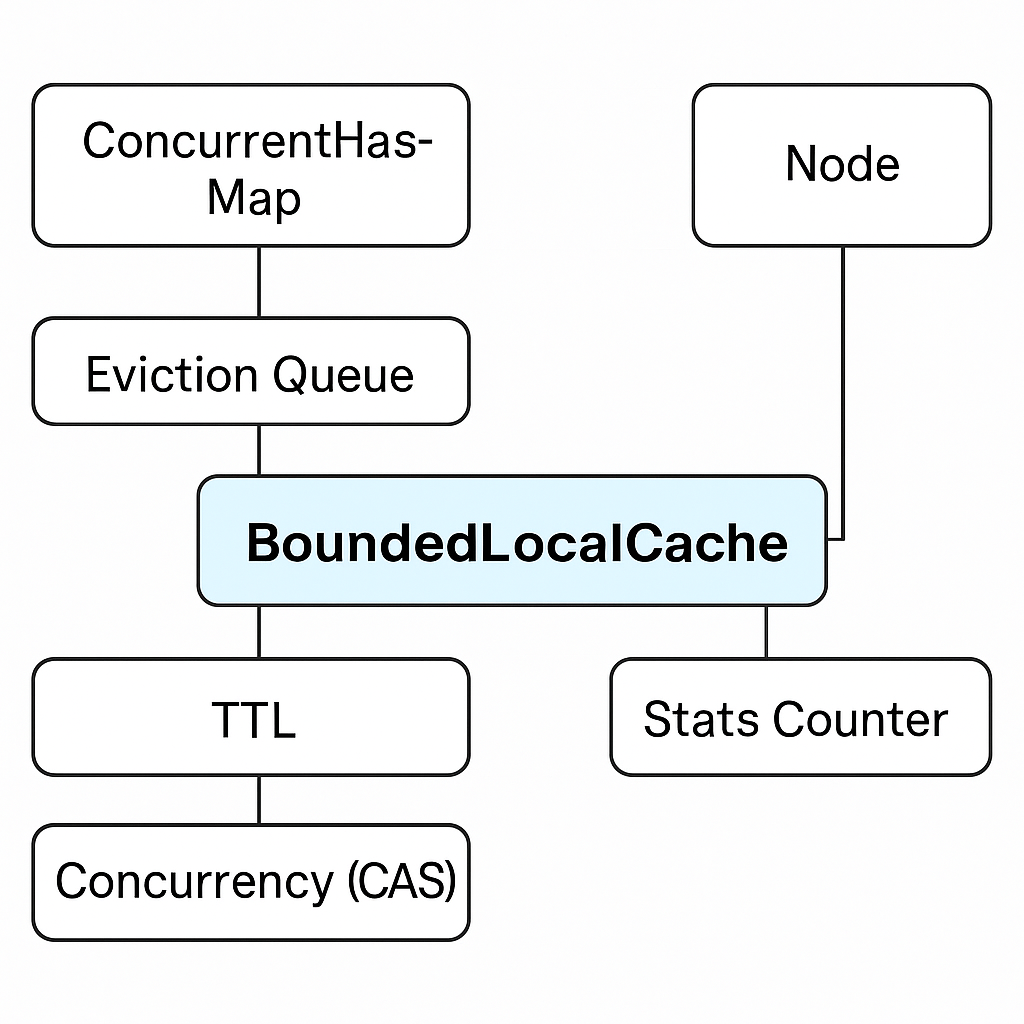
| 구성 요소 | 역할 |
|---|---|
| CacheBuilder | 캐시 설정(크기, 만료, 동시성 등) 정의 |
| BoundedLocalCache | 캐시 로직 구현부 |
| Node | Key-Value + 접근/작성 시각 등 메타데이터 |
| Eviction Queue | 오래된 항목 관리 |
| Stats Counter | hit/miss 통계 누적 |
5-3. Cache-Aside 패턴
Caffeine은 cache.get(key, mappingFunction)으로 Cache-Aside 패턴을 지원합니다.
Spring의 @Cacheable 내부 동작과 동일합니다.
User user = cache.get(userId, id -> repository.findById(id));
- 캐시 miss → DB 조회
- DB 결과를 캐시에 저장
- 이후 동일 key 요청 → 캐시 hit
5-4. TTL / Eviction / 통계 관리
Caffeine은 W-TinyLFU(Window TinyLFU) 알고리즘을 사용합니다.
최근성(Recency)과 사용 빈도(Frequency)를 결합하여 높은 적중률을 제공합니다.
Cache<String, User> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.expireAfterWrite(10, TimeUnit.MINUTES)
.recordStats()
.build();
CacheStats stats = cache.stats();
System.out.printf("HitRate=%.2f, MissRate=%.2f%n", stats.hitRate(), stats.missRate());
TTL과 Eviction이 핵심: 오래된 데이터는 자동 만료되고, 자주 사용된 데이터는 오래 유지됩니다.
5-5. Lock-Free 동시성 구조
Caffeine은 CAS(Compare-And-Swap) + LongAdder 기반의 락-프리 구조입니다.
- CAS 기반 갱신: 락 대신 원자적 비교·갱신
- LongAdder: 다중 스레드 환경에서도 contention-free 통계 집계
- 비동기 Eviction: 쓰기 경로 방해 없이 제거 처리
5-6. GC 협력 방식
| 설정 | 효과 |
|---|---|
weakKeys() | 참조되지 않은 키는 GC 시 자동 제거 |
softValues() | 메모리 부족 시 Value 우선 제거 |
maximumSize() | 자체 Eviction으로 OOM 방지 |
크기 제한을 지정하지 않으면 GC pause 증가 및 OOM 위험이 있습니다.
5-7. W-TinyLFU 알고리즘 구조
단계별 흐름
- 새 항목은 Window(LRU)에 임시 저장
- 용량 초과 시 기존 항목과 접근 빈도 비교
- 더 자주 사용된 항목을 유지
- hit 발생 시 Probation → Protected 구역 승격
- TTL 만료 항목은 TimeWheel로 제거
최근성 + 빈도 기반의 하이브리드 구조로 높은 hit rate 달성.
5-8. JVM 내부 구조 요약
┌───────────────────────────────────────────┐
│ JVM Process │
│ ┌────────────────────────────────────┐ │
│ │ Caffeine On-Heap Cache (Bounded) │ │
│ │ - ConcurrentHashMap 기반 Store │ │
│ │ - Eviction(W-TinyLFU) │ │
│ │ - TTL / Weak & Soft Reference │ │
│ │ - Lock-free Concurrency (CAS) │ │
│ │ - LongAdder 기반 통계 집계 │ │
│ └────────────────────────────────────┘ │
└───────────────────────────────────────────┘
6. Cache 설정(application.yml) 구성과 작동 원리
Spring Boot에서 캐시는 크게 두 계층으로 설정할 수 있다.
| 구분 | 목적 | 관리 주체 |
|---|---|---|
| Spring 기본 설정층 | CacheManager 생성 및 전역 엔진 제어 | Spring Boot |
| 사용자 확장 설정층 | 캐시별 TTL·Size 정책 관리 | 서비스 애플리케이션 |
6-1. Spring 기본 설정층 (spring.cache.*)
Spring Boot는 spring.cache 네임스페이스를 통해 CacheManager의 전역 동작을 구성한다.
spring:
cache:
type: caffeine
cache-names: 명칭, 명칭
caffeine:
spec: maximumSize=10000,expireAfterWrite=10m,recordStats
| 항목 | 설명 |
|---|---|
| type | 사용할 캐시 엔진 지정 (caffeine, redis, ehcache 등) |
| cache-names | 초기화할 캐시 이름 목록 |
| caffeine.spec | 전역 정책 (maximumSize, expireAfterWrite, recordStats 등) |
이 구조는 모든 캐시가 동일한 정책으로 동작할 때 간단하게 사용할 수 있다.
그러나 캐시별로 TTL이나 Size를 세분화해야 하는 경우 한계가 있다.
6-2. 사용자 확장 설정층 (spring.cache.app.*)
도메인별 TTL과 용량 정책이 달라야 할 경우,
Spring의 기본 설정 위에 타입 안전한 확장 레이어를 추가한다.
spring:
cache:
type: caffeine
strict: true
app:
defaults: { maximumSize: 40000, ttlSec: 300 }
caches:
"명칭": { maximumSize: 20000, ttlSec: 300 }
"명칭": { maximumSize: 20000, ttlSec: 1800 }
| 항목 | 설명 |
|---|---|
| strict | 선언되지 않은 캐시 접근 차단. 오타나 누락으로 인한 불일치 방지 |
| app.defaults | 모든 캐시에 공통 적용되는 기본 정책 (예: TTL 5분, Size 4만) |
| app.caches | 캐시별 세부 정책 (예: 상세·이미지 캐시 TTL 분리) |
| ttlSec / maximumSize | 캐시 만료 시간(초) 및 최대 항목 수 지정 |
이 구조는 defaults를 기본값으로 두고, caches로 각 캐시의 오버라이드 정책을 적용하는 방식이다.
실제 코드에서는 AppCacheProps를 통해 바인딩되고 CacheManager에서 per-cache로 주입된다.
(해당 구현은 2편에서 다룬다.)
6-3. 주요 항목 정리
| 항목 | 구분 | 필요성 | 설명 |
|---|---|---|---|
| type | Spring 기본 | 필수 | 사용할 캐시 엔진 지정 |
| cache-names | Spring 기본 | 선택 | 사전 초기화 캐시 이름 |
| caffeine.spec | Spring 기본 | 선택 | 전역 정책 (maximumSize, expireAfterWrite) |
| strict | 확장 | 추천 | 선언되지 않은 캐시 접근 방지 |
| app.defaults | 확장 | 필수 | 공통 TTL/Size 정책 |
| app.caches | 확장 | 필수 | 캐시별 오버라이드 정책 |
| ttlSec / maximumSize | 확장 | 필수 | 캐시 만료·용량 핵심 설정 |
| recordStats | 확장 | 권장 | hit/miss/eviction 통계 활성화 |
이 항목들만으로도 대부분의 운영 환경에서 완전한 캐시 구성을 구현할 수 있다.
6-4. 선택적 확장 옵션
| 항목 | 설명 |
|---|---|
| expireAfterAccessSec | 마지막 접근 이후 일정 시간 경과 시 만료 (LRU 패턴) |
| maximumWeight + weigherClass | 항목별 가중치 기반 용량 제어 |
| allowNullValues | null 캐싱 여부 제어 (false 권장) |
| cacheErrorHandler | 캐시 예외 발생 시 fallback 처리 |
| sync | 동일 key 동시 미스 시 single-flight 처리 |
| Micrometer Export | Prometheus/Grafana로 메트릭 노출 가능 |
6-5. 요약
spring.cache는 CacheManager의 기본 엔진을 구성한다.spring.cache.app은 캐시별 TTL·Size 정책을 확장 관리한다.defaults와caches구조로 전역·개별 정책을 병행할 수 있다.- 핵심 8개 항목만으로도 실무 환경에서 완전한 캐시 구성이 가능하다.
2편에서는 이 설정이 실제 코드(AppCacheProps, CacheManager)로 어떻게 연결되는지,
그리고 왜 전역
spec대신 per-cache 구조를 선택했는지를 다룬다.
7. 결론
Caffeine은 JVM 내부에서 작동하는 경량·고성능 로컬 캐시입니다.
ConcurrentMap 기반 구조 위에 TTL, Eviction, Lock-Free, 통계 계층을 결합해
“JVM 친화적 캐싱 엔진”을 완성했습니다.
특징 요약
- 네트워크 hop 없음
- GC 협력(weakKeys / softValues)
- 락 없는 동시성 구조
- TTL 및 Eviction 자동 관리
- Micrometer 통합으로 운영 모니터링 가능
Caffeine = JVM 친화적 + Lock-Free + 고성능 캐시.
단일 인스턴스 환경에서는 Redis보다 빠를 수 있으며,
내부 동작을 이해하면 캐시의 성능과 안정성을 동시에 확보할 수 있습니다.
