
1. 테스트 배경
이전 단계에서 ExponentialBackOffPolicy를 적용한 결과,
VU 200 이상 구간에서 성공률이 급격히 하락하며 최대 응답 시간이 17초를 초과하는 현상이 나타났다.
초기 설정은 다음과 같았다.
- initialInterval: 200~300ms
- multiplier: 1.5~2.0
- maxAttempts: 8~10회
테스트 결과, 100명 이하에서는 안정적이었으나
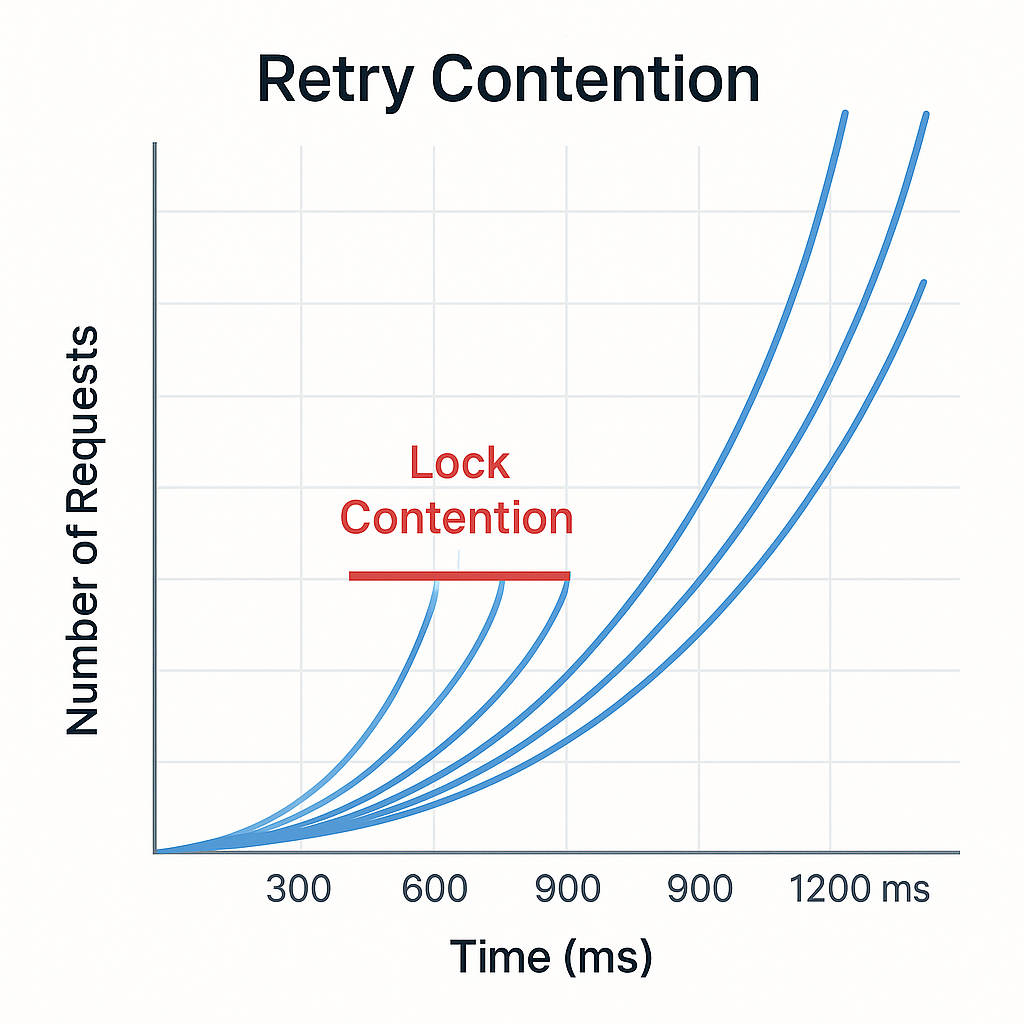
시각 요소 설명:
파란 곡선들 → 각기 다른 요청의 재시도 시점
x축(Time) / y축(Request 수)
빨간 “Lock Contention” 구간 → 재시도 타이밍이 겹치며 병목 발생
의미: “단순 지수 증가(backoff)는 있지만, 타이밍 분산이 없다 → 경합 집중”
재시도 타이밍이 동일하게 맞물리며 락 경합이 집중되는 문제가 발생했다.
락이 해제된 시점에 모든 요청이 동시에 재시도되면서
성공률은 80%대에 머물렀고 응답 시간은 급격히 증가했다.
이는 단순히 “대기 간격의 길이”보다 “재시도 타이밍의 일치”가 병목의 근본 원인임을 보여준다.
2. 테스트 환경
2.1 서버 및 DB 설정
application.yaml
server:
tomcat:
max-threads: 1000
accept-count: 3000
spring:
datasource:
hikari:
maximum-pool-size: 400
minimum-idle: 100
idle-timeout: 30000
connection-timeout: 15000
postgresql.conf
max_connections = 300
이 설정을 통해 Tomcat 스레드 수와 DB 커넥션 풀 크기를 확대하여
100~200명 수준의 동시 요청에서도 병목 없이 안정적인 처리가 가능하도록 구성했다.
로그인, 인증, 데이터베이스 락 대기 등의 구간에서 병목이 완화되었으며,
이는 재시도 정책 실험의 전제 조건이 되었다.
3. ExponentialBackOffPolicy 결과 요약
주요 현상
- 100명(VU) 이하에서는 성공률 98~100% 유지
- 200명 이상부터 성공률 급감, 최대 응답 시간 17초 이상
- 재시도 타이밍이 동일하게 겹치며 락 경합 집중
주요 결과
| 설정명 | Script | VU | Retry | Mult | 성공률 | 실패율 | 평균응답 | 최대응답 |
|---|---|---|---|---|---|---|---|---|
| A | like-test2 | 100 | 8 | 1.5 | 50% | 25.0% | 2.29s | 6.84s |
| B | like-test2 | 200 | 8 | 1.5 | 78.5% | 10.7% | 2.58s | 8.62s |
| C | like-test2 | 100 | 9 | 1.8 | 60% | 20.0% | 4.73s | 14.12s |
| D | like-test2 | 200 | 9 | 1.8 | 83.5% | 8.2% | 2.15s | 12.41s |
| E | like-test2 | 100 | 10 | 2.0 | 56% | 22.0% | 6.85s | 19.13s |
| F | like-test2 | 200 | 10 | 2.0 | 80.5% | 9.7% | 3.14s | 17.58s |
요약
VU 200 이상에서 락 재경합으로 인한 실패율 상승이 두드러졌다.
재시도 정책이 동일하게 동작하여 재시도 타이밍이 집중되며,
최대 응답 시간은 17초 이상으로 지연이 급격히 증가했다.
결국 ExponentialBackOffPolicy는 “대기 간격의 증가”는 제공하지만
“재시도 시점의 분산”은 보장하지 않는다.
4. ExponentialRandomBackOffPolicy 적용
4.1 정책 변경 의도
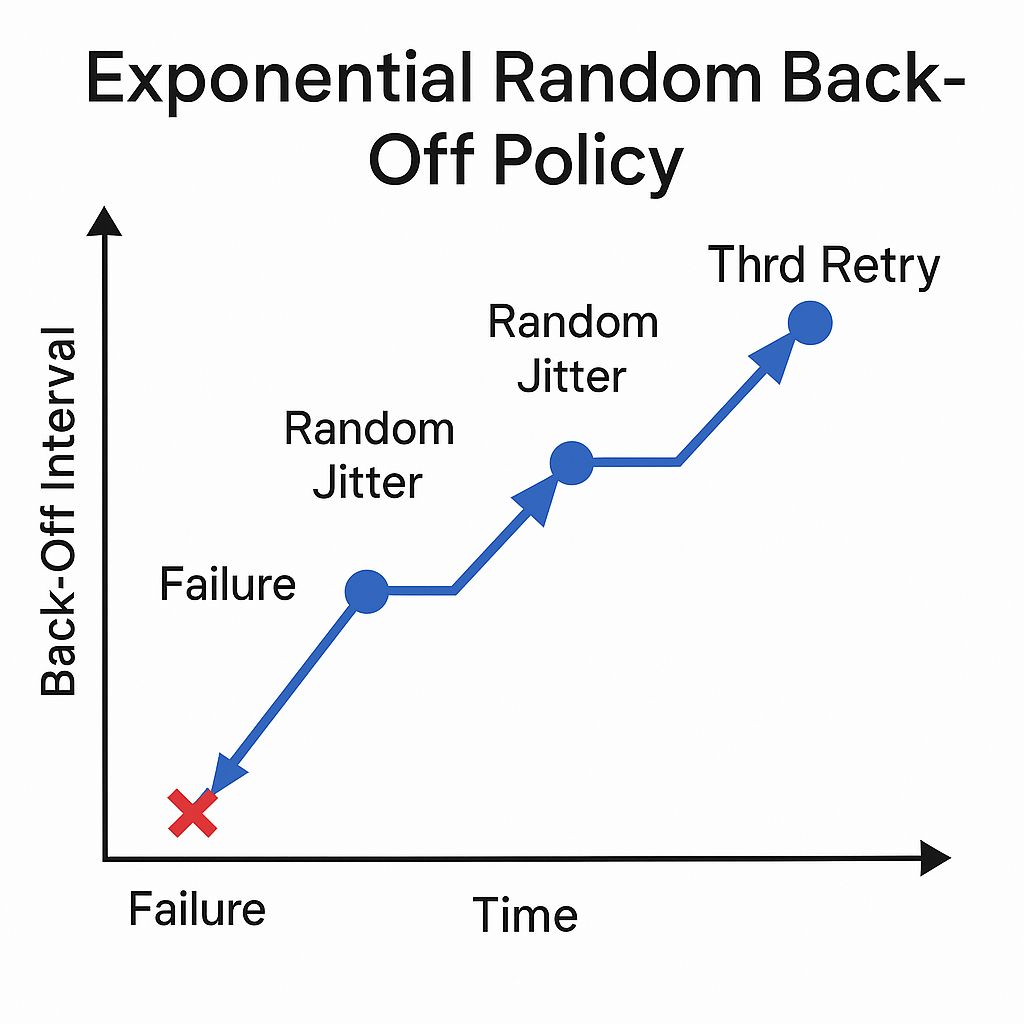
시각 요소 설명:
x축(Time) / y축(BackOff Interval)
각 점 → 재시도 타이밍
“Random Jitter” 표기된 화살표 → 각 요청마다 약간의 지연이 무작위로 추가됨
의미: “같은 지수 증가지만, 재시도 시점이 어긋나 충돌 분산됨”
ExponentialBackOffPolicy는 재시도 시마다 간격을 지수적으로 늘려 충돌 빈도를 완화하지만,
모든 트랜잭션이 동일한 타이밍으로 재시도하는 문제를 근본적으로 해결하지는 못한다.
이에 따라 고정된 지수 간격 대신, 무작위성(Random Jitter)을 포함한
ExponentialRandomBackOffPolicy를 적용하였다.
이 정책의 목표는 다음과 같다:
- 동일한 간격의 재시도가 동시에 발생하지 않도록 타이밍 분산
- 락 해제 직후 요청 집중을 완화
- 대규모 동시성 환경에서도 성공률·응답 시간 안정화
4.2 원리
ExponentialRandomBackOffPolicy는 ExponentialBackOffPolicy를 확장한 구현이다.
각 재시도 간격(nextInterval)을 계산할 때 무작위(Random Jitter) 값을 더해
스레드 간 타이밍이 미세하게 달라지도록 설계되어 있다.
nextInterval = currentInterval * (1 + random[0,1))
이로써 재시도 타이밍이 서로 어긋나며,
락 경합이 집중되는 현상을 방지할 수 있다.
이후 내부 동작 구조(RetryTemplate의 Context, BackOff 계산, Callback 루프)는
아래 내부 구조 분석(4.3) 에서 상세히 다룬다.
4.3 내부 동작 분석 — BackOffPolicy와 RetryTemplate 구조
(1) 개념 요약
Spring Retry의 핵심은 특정 대상을 식별해 재시도하는 것이 아니라,
execute() 단위로 실행 세션(RetryContext)을 생성하고
그 세션 안에서 동일한 Callback을 반복 실행하는 구조다.
즉,
“재시도 대상은 특정 엔티티나 ID가 아니라 RetryContext 자체이며,
RetryTemplate은 이 Context에 연결된 Callback을 반복 실행한다.”
(2) ExponentialRandomBackOffPolicy의 동작
해당 정책은 기본적으로 ExponentialBackOff 구조를 유지하면서
각 재시도 간격에 무작위(Random Jitter)를 추가한다.
@Override
public void backOff(BackOffContext context) {
ExponentialRandomBackOffContext c = (ExponentialRandomBackOffContext) context;
long next = (long) (c.getCurrentInterval() * (1 + Math.random()));
Thread.sleep(Math.min(next, maxInterval));
c.setCurrentInterval(next * multiplier);
}
이 메서드는 RetryTemplate의 내부 루프에서 호출된다.
즉, RetryPolicy가 “재시도 가능”이라고 판단할 때마다
backOff()가 호출되어 대기 시간과 Context 상태를 함께 갱신한다.
이는 단순히 “지연시간을 늘리는 것”이 아니라
Context에 저장된 상태(currentInterval, multiplier)를 기반으로
동적으로 대기 시간을 계산·조정하는 방식이다.
(3) RetryTemplate 내부 구조 요약
┌──────────────────────────────────────────────────────────┐
│ RetryTemplate │
│──────────────────────────────────────────────────────────│
│ ① RetryCallback (람다 함수) → 비즈니스 로직 실행 │
│ ② RetryContext (세션 상태 저장) │
│ ③ RetryPolicy (재시도 여부 판단) │
│ ④ BackOffPolicy (대기 시간 계산, Random Jitter 적용) │
│ ⑤ Callback 재실행 (Context 기반 루프) │
└──────────────────────────────────────────────────────────┘
각 구성 요소는 독립적인 책임을 가지며,
RetryTemplate이 전체 제어 흐름을 관리한다.
(4) 실행 흐름 (Pseudo-code)
RetryContext context = retryPolicy.open(null); // 세션 시작
while (retryPolicy.canRetry(context)) {
try {
return retryCallback.doWithRetry(context); // 비즈니스 로직 실행
} catch (Exception e) {
context.registerThrowable(e); // 예외 기록
backOffPolicy.backOff(context.getBackOffContext()); // 대기 후 재시도
}
}
retryPolicy.close(context); // 세션 종료
이 루프 내에서:
- RetryContext: 재시도 세션의 상태를 저장
- BackOffPolicy: 다음 재시도까지의 대기 시간을 계산
- execute() 호출 = 하나의 재시도 세션 → 이 Context 단위로 상태가 누적·관리된다.
(5) 주요 구성 요소 역할
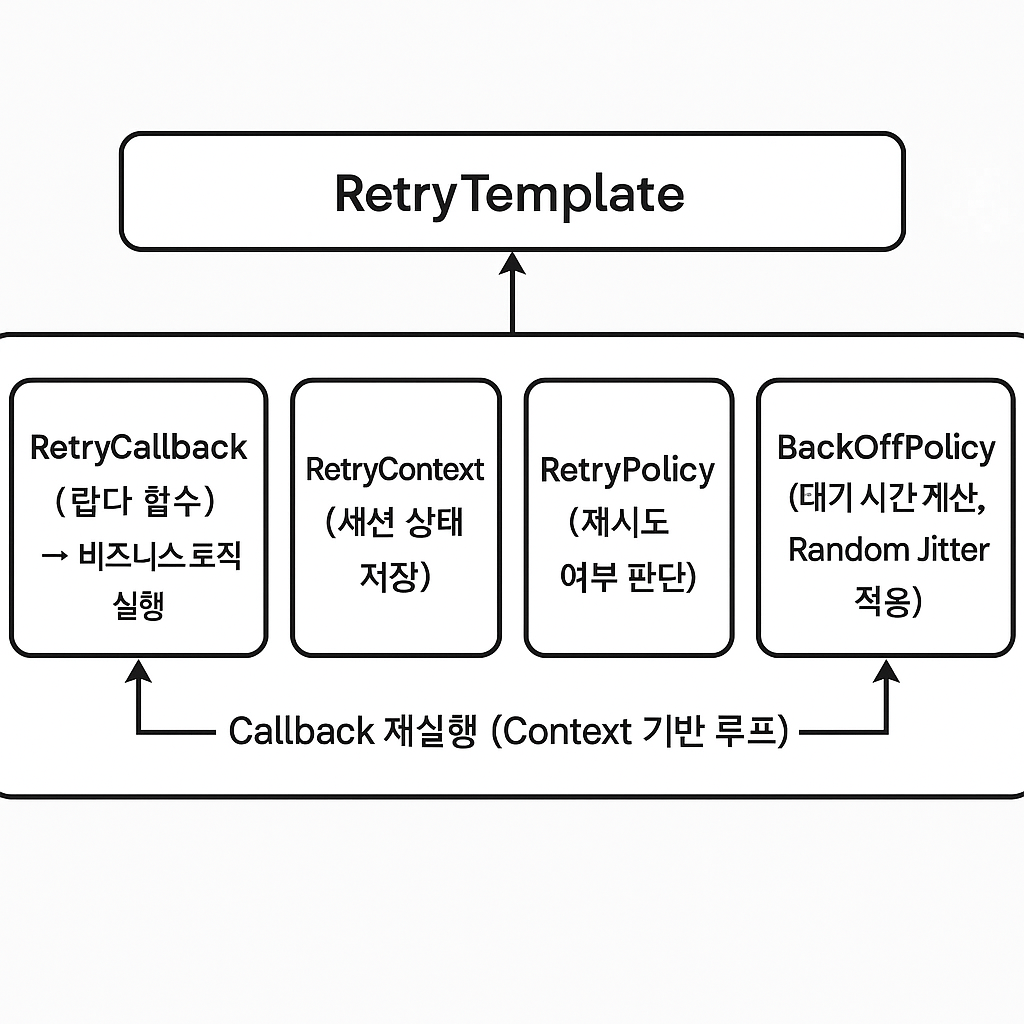
| 구성 요소 | 역할 | 주요 책임 |
|---|---|---|
| RetryCallback | 재시도할 함수(람다) | 비즈니스 로직 실행 |
| RetryContext | 재시도 세션의 상태 저장소 | 재시도 횟수·예외·BackOff 상태 관리 |
| RetryPolicy | 재시도 가능 여부 판단 | 실패 횟수·예외 유형 기반 결정 |
| BackOffPolicy | 대기 간격 계산기 | Exponential + Random Jitter 기반 분산 제어 |
| RetryTemplate | 제어 루프 | Context 단위로 동일 Callback 반복 실행 |
(6) RetryTemplate의 재시도 단위와 Context 구조
Spring Retry는 재시도 대상을 객체나 ID로 구분하지 않는다.
즉, “postId=1인 요청을 재시도한다”는 개념이 아니라,
하나의 execute() 호출 자체를 하나의 재시도 세션(RetryContext)으로 인식한다.
(1) 재시도 단위: execute() 호출
RetryTemplate은 execute() 메서드가 호출될 때마다
새로운 RetryContext를 생성하고,
그 세션(Context) 내에서 동일한 RetryCallback을 반복 실행한다.
retryTemplate.execute(context -> {
// 이 블록 전체가 하나의 재시도 세션
return someBusinessOperation();
});
이 “execute() 호출”이 곧 RetryTemplate이 인식하는 하나의 재시도 대상 단위이며,
각 Context는 재시도 횟수, 예외, BackOff 상태 등을 내부적으로 관리한다.
| 구분 기준 | 의미 |
|---|---|
| execute() 호출 횟수 | 각각이 하나의 재시도 실행 단위 |
| RetryContext | 해당 실행 세션의 상태 저장소 |
| BackOffContext | 재시도 간격·대기 상태 추적 객체 |
(2) 내부 동작 구조
RetryTemplate 내부는 다음과 같이 동작한다.
public <T, E extends Throwable> T execute(RetryCallback<T, E> retryCallback) throws E {
RetryContext context = retryPolicy.open(null); // 세션 생성
try {
do {
try {
return retryCallback.doWithRetry(context);
} catch (Exception e) {
if (retryPolicy.canRetry(context)) {
backOffPolicy.backOff(backOffContext); // 대기 후 재시도
} else {
throw e;
}
}
} while (true);
} finally {
retryPolicy.close(context); // 세션 종료
}
}
이 구조에서 RetryContext는 재시도 세션의 상태 저장소이자 식별자 역할을 한다.
| 필드 | 설명 |
|---|---|
| retryCount | 현재 재시도 횟수 |
| lastThrowable | 마지막 예외 |
| attributes | 개발자 커스텀 속성 (postId, operation 등) |
즉, RetryTemplate은 “대상을 찾아서 재시도”하지 않고,
“동일한 Callback을 같은 Context 안에서 반복 실행”한다.
(3) Context = 대상의 정체성(Identity)
Spring Retry는 “이 요청이 어떤 ID를 가진 대상인가”를 인식하지 않는다.
대신, open()으로 생성된 하나의 RetryContext가
그 실행 세션의 정체성(Identity)으로 작동한다.
이 Context는 다음과 같은 순서로 재사용된다.
open() → canRetry() → registerThrowable() → backOff() → close()
즉, 하나의 execute() 호출 = 하나의 Context = 하나의 재시도 세션이다.
이 세션 단위로 재시도 상태가 누적·관리된다.
(4) 필요 시 대상 정보를 명시적으로 추가
RetryTemplate은 내부적으로 postId 등의 식별자를 추적하지 않는다.
그러나 개발자가 Context에 직접 속성을 추가할 수 있다.
retryTemplate.execute(context -> {
context.setAttribute("postId", postId);
context.setAttribute("operation", "like");
...
});
이후 재시도 중 예외가 발생하면 다음과 같이 로그로 확인할 수 있다.
catch (Exception e) {
log.warn("Retry failed for postId={} (attempt {})",
context.getAttribute("postId"),
context.getRetryCount());
}
이 구조는 RetryTemplate이 본질적으로 “대상 추적 기능”을 내장하지 않고,
필요 시 개발자가 Context를 확장하여
모니터링, 디버깅, 장애 분석에 활용할 수 있게 설계된 것이다.
(5) 요약
| 질문 | Spring Retry의 동작 방식 |
|---|---|
| “RetryTemplate은 어떤 대상을 재시도하나?” | execute() 호출 단위(= RetryContext 세션) |
| “대상을 ID로 구분하나?” | 아니다. Context 자체가 Identity |
| “동일 대상을 어떻게 인식하나?” | 동일 execute()에서 생성된 Context로 판단 |
| “대상을 명시적으로 넣으려면?” | context.setAttribute("id", id)로 직접 주입 가능 |
정리:
RetryTemplate은 “특정 대상을 다시 찾는 구조”가 아니라
하나의 execute() 세션(Context)을 하나의 실행 단위로 반복한다.
즉, RetryContext가 곧 재시도 단위이며,
Spring Retry는 이 Context를 기반으로 재시도 횟수·대기 간격·상태를 제어한다.
5. 실제 코드 적용 구조
5.1 RetryConfig.java
@Configuration
public class RetryConfig {
@Bean
public RetryTemplate retryTemplate() {
RetryTemplate template = new RetryTemplate();
ExponentialRandomBackOffPolicy backOffPolicy = new ExponentialRandomBackOffPolicy();
backOffPolicy.setInitialInterval(200);
backOffPolicy.setMultiplier(1.5);
backOffPolicy.setMaxInterval(3000);
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy(10, Map.of(Exception.class, true));
template.setBackOffPolicy(backOffPolicy);
template.setRetryPolicy(retryPolicy);
return template;
}
}
설명
- 기존
ExponentialBackOffPolicy를ExponentialRandomBackOffPolicy로 교체 - 초기 간격, 배수, 최대 간격은 동일하게 유지하여 실험 조건 일치
- 예외 매핑을 통해
OptimisticLockingFailureException포함
5.2 PostLikeRetryExecutor.java
@Component
@RequiredArgsConstructor
public class PostLikeRetryExecutor {
private final RetryTemplate retryTemplate;
private final TransactionTemplate transactionTemplate;
public <T> T likeWithRetry(Callable<T> action) {
return retryTemplate.execute(context -> {
log.debug("재시도 시작 (attempt {})", context.getRetryCount());
try {
return transactionTemplate.execute(status -> {
try {
return action.call();
} catch (Exception e) {
if (e instanceof RuntimeException) throw (RuntimeException) e;
throw new RuntimeException(e);
}
});
} catch (Exception e) {
log.warn("재시도 실패 (attempt {}): {}", context.getRetryCount(), e.getMessage());
throw e;
}
});
}
}
설명
RetryTemplate내부에서TransactionTemplate을 함께 사용하여 매 재시도 시 새로운 트랜잭션을 열고 롤백 후 다시 시도하도록 구성
RetryContext는 자동으로 관리되며, 별도context.setAttribute()호출 불필요OptimisticLockingFailureException발생 시 자동 재시도- 시도 횟수(
context.getRetryCount()) 기반 로깅으로 디버깅 용이
5.3 PostLikeService.java
@Service
@RequiredArgsConstructor
public class PostLikeService {
private final PostRepository postRepository;
private final PostLikeRetryExecutor retryExecutor;
@Transactional
public void likePost(Long postId) {
retryExecutor.likeWithRetry(() -> {
Post post = postRepository.findByIdWithOptimisticLock(postId)
.orElseThrow(PostNotFoundException::new);
post.increaseLikeCount();
postRepository.save(post);
return null;
});
}
}
설명
- 낙관적 락 충돌 시 발생하는 예외는
RetryExecutor내부의 재시도 루프로 전달됨 - 서비스 계층은 비즈니스 로직만 유지하며, 재시도 및 트랜잭션 제어는 외부화됨
- 트랜잭션 안정성과 로직 단순화를 동시에 확보
6. ExponentialRandomBackOffPolicy 성능 결과
| 설정명 | Script | VU | Retry | Mult | 성공률 | 실패율 | 평균응답 | 최대응답 |
|---|---|---|---|---|---|---|---|---|
| XR1 | like-test2 | 100 | 8 | 1.5 | 100% | 0.0% | 2.93s | 12.79s |
| XR2 | like-test2 | 200 | 8 | 1.5 | 99.75% | 0.25% | 3.55s | 16.58s |
| XR3 | like-test2 | 100 | 9 | 1.8 | 100% | 0.0% | 1.20s | 8.30s |
| XR4 | like-test2 | 200 | 9 | 1.8 | 98.75% | 1.25% | 3.06s | 10.86s |
| XR5 | like-test2 | 100 | 10 | 2.0 | 100% | 0.0% | 2.66s | 16.32s |
| XR6 | like-test2 | 200 | 10 | 2.0 | 100% | 0.0% | 3.68s | 17.20s |
비교 요약
| 구분 | 정책 유형 | 평균 성공률 | 최대 응답 시간 | 특징 |
|---|---|---|---|---|
| ExponentialBackOffPolicy | 고정 지수 재시도 | VU 200 기준 약 77~93% | 최대 17.48s | 부하 집중 시 실패율 상승 |
| ExponentialRandomBackOffPolicy | 무작위 지수 재시도 | VU 200 기준 98~100% | 최대 17.20s | 충돌 분산, 안정적 성능 확보 |
7. 결론
ExponentialBackOffPolicy는 동일한 간격 증가 로직으로 인해
대규모 동시 요청 시 재시도 타이밍이 집중되는 구조적 한계를 가진다.
반면 ExponentialRandomBackOffPolicy는 무작위성을 부여함으로써
재시도 타이밍이 분산되고, DB 락 경합 및 실패율이 현저히 감소했다.
서버 및 DB 설정 확장(Tomcat, Hikari, PostgreSQL)을 기반으로
VU 200 이상 환경에서도 99~100%의 성공률을 유지했으며,
지수적 증가 + 무작위 오프셋 조합이 가장 안정적인 패턴으로 확인되었다.
최종 결론
- ExponentialRandomBackOffPolicy는 락 충돌 완화와 재시도 타이밍 분산에 탁월하다.
- TransactionTemplate 결합 구조는 재시도마다 트랜잭션 재시작을 보장한다.
- RetryTemplate 기반 설계는 비즈니스 로직과 정책을 완전히 분리하여 확장성과 유지보수성을 동시에 확보했다.
