1. 낙관적 락의 한계: 충돌 후 예외 발생
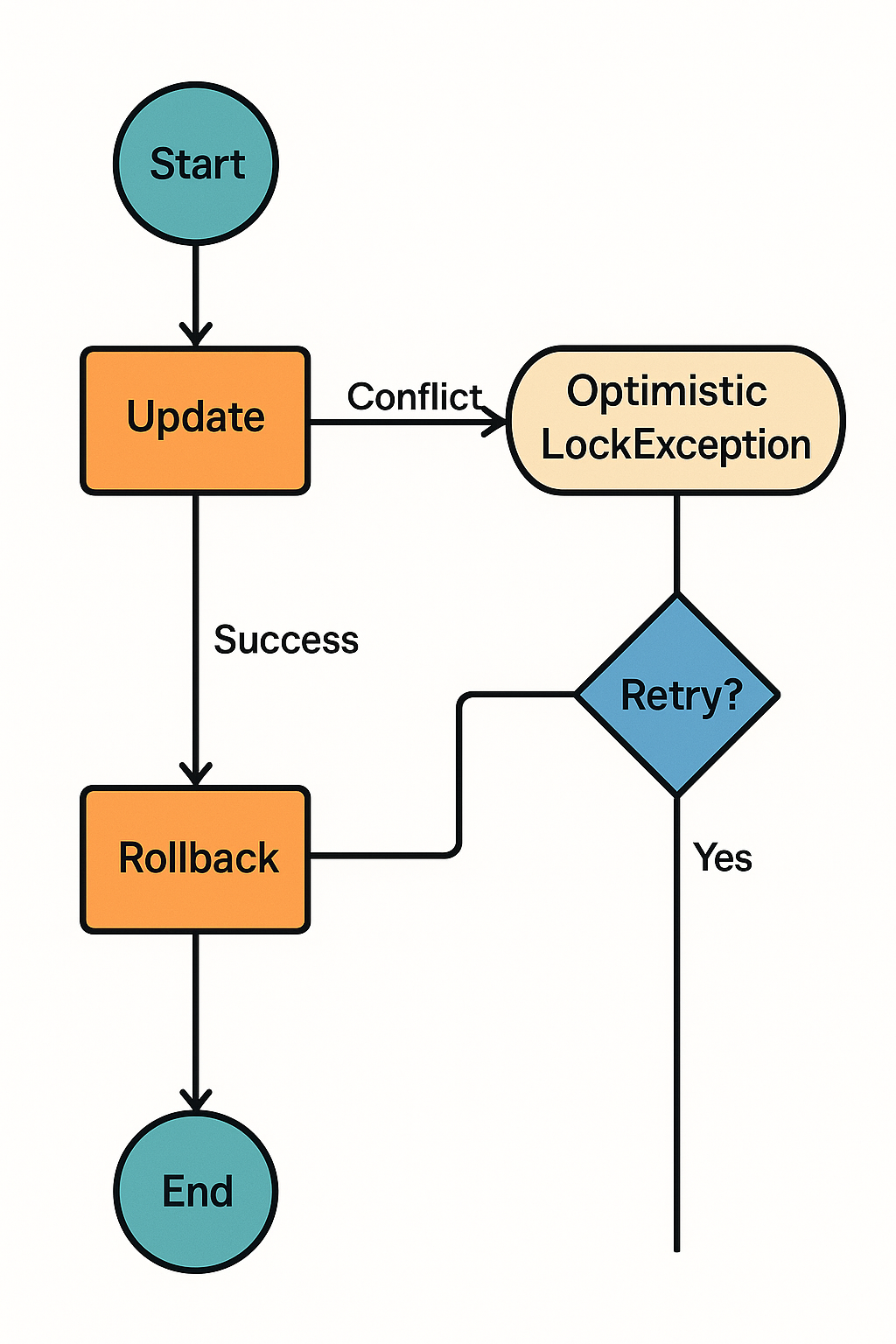
💡 두 사용자가 동시에 같은 데이터를 수정할 때 발생하는 낙관적 락 충돌. 충돌 시점에 예외가 발생하고 트랜잭션이 롤백된다.
2편에서 살펴본 낙관적 락은 “충돌을 허용하고, 커밋 시점에 감지한다.”
이 방식은 동시성 제어의 유연성을 높이지만, OptimisticLockException이 발생하면 트랜잭션이 롤백된다.
즉, 충돌이 발생한 사용자는 아무 일도 일어나지 않은 것처럼 보이게 된다.
좋아요 기능처럼 즉시 반응성과 데이터 정합성을 모두 요구하는 기능에서는
이 단점이 그대로 사용자 체감 오류로 이어진다.
이 문제를 해결하기 위해, 충돌 후 재시도(retry) 가 필요하다.
다만 단순 반복이 아니라, “정책(policy)”으로 설계된 재시도여야 한다.
2. 단순 반복이 아닌 정책 기반 접근
단순히 for 문으로 감싸는 것은 임시방편이다.
for (int i = 0; i < 3; i++) {
try {
updateLikeCount();
break;
} catch (OptimisticLockException e) {
// 재시도
}
}
이런 구조는 간단하지만 다음과 같은 문제가 있다:
- 재시도 간 간격 제어 불가
- 예외별 재시도 정책 분리 불가능
- 동일 시점에 다수의 재시도가 겹침 (락 충돌 재발)
따라서 재시도 로직은 RetryPolicy와 BackOffPolicy로 분리되어야 한다.
3. Spring Retry의 정책 구조
Spring Retry는 재시도를 독립된 템플릿으로 제공한다.
RetryTemplate
├── RetryPolicy: 재시도 횟수와 조건 정의
├── BackOffPolicy: 재시도 간 대기 시간 제어
└── RetryCallback: 실제 수행할 로직
이 구조를 활용하면
“언제, 몇 번, 어떤 간격으로” 다시 시도할지를 독립적으로 설정할 수 있다.
4. Spring 기반 재시도 구현 방식 비교
| 구분 | 구현 방식 | 대표 코드 / Annotation | 특징 | 장점 | 단점 | 추천 상황 |
|---|---|---|---|---|---|---|
| ① 선언적 재시도 (AOP 기반) | @Retryable, @Recover | Spring Retry | 어노테이션 기반 자동 재시도 | 단순, 가독성 높음 | 세밀한 제어 어려움 | 간단한 API 호출 |
| ② 프로그래밍적 재시도 (템플릿 기반) | RetryTemplate | Spring Retry | 정책 객체로 세밀한 설정 가능 | 유연한 구성 | 코드량 많음 | 락 충돌, DB 갱신 |
| ③ 함수형 재시도 | 직접 구현 (try-catch) | Java 표준 | 최소 구현 | 의존성 없음 | 제어 불가 | 실험, 간단한 테스트 |
| ④ 회로형 재시도 | Resilience4j | 외부 라이브러리 | 회로 차단·지연 등 고급 제어 | 모듈화, 복원력 | 설정 복잡 | 외부 API 통신 |
| ⑤ 비동기/메시지 기반 | Kafka DLQ 등 | MQ 기반 | 실패 이벤트 재처리 | 부하 분산 | 실시간성 부족 | 비동기 처리 파이프라인 |
좋아요 기능은 짧은 트랜잭션, 높은 빈도, 즉시성 중심이므로
② RetryTemplate + ExponentialBackOffPolicy 조합이 가장 적합하다.
5. RetryTemplate 적용 예시
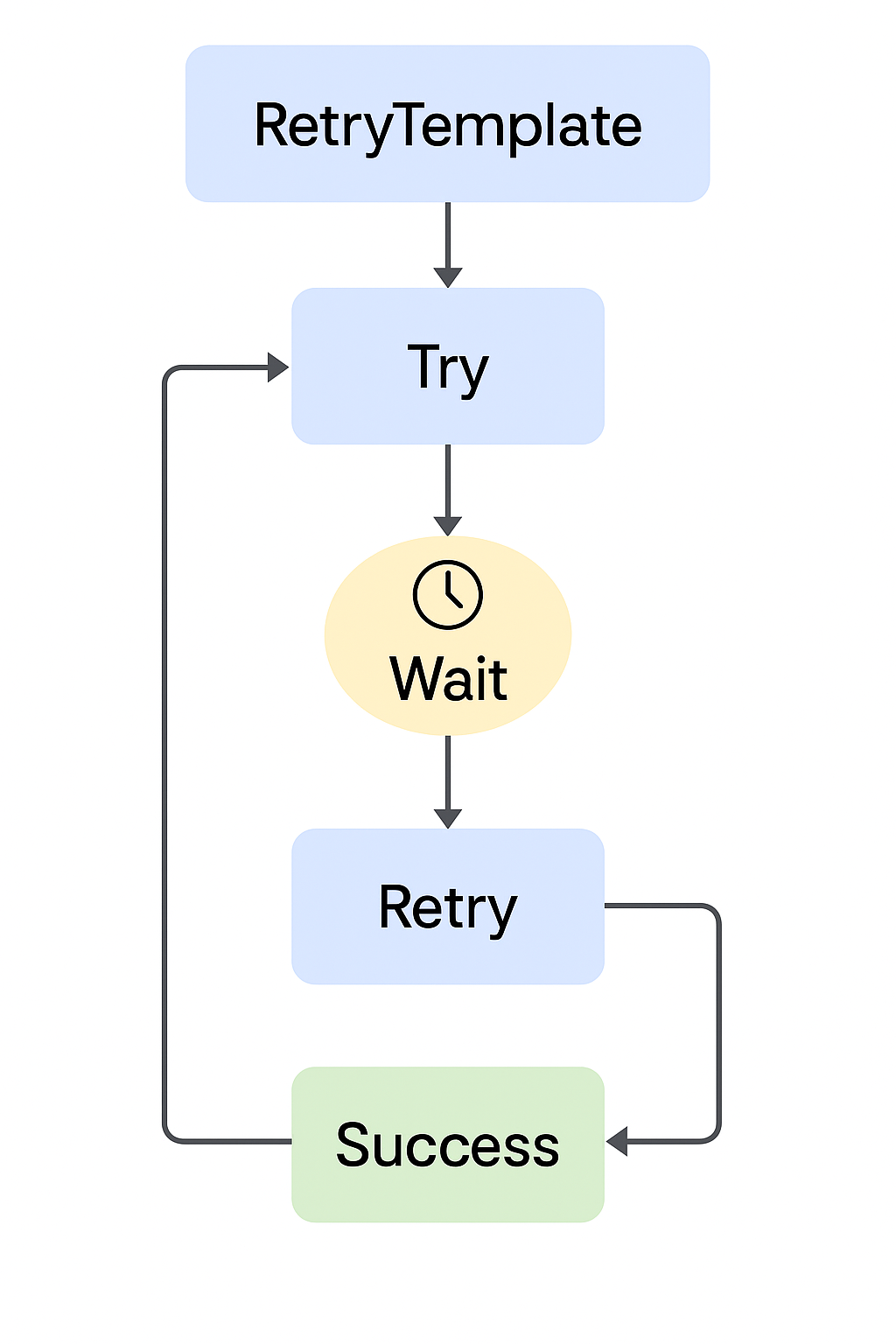
🔁 실패 시 BackOff 대기 후 재시도를 반복하며, 성공 시 루프를 종료하는 RetryTemplate의 동작 흐름.
@Configuration
public class RetryConfig {
@Bean
public RetryTemplate retryTemplate() {
RetryTemplate template = new RetryTemplate();
SimpleRetryPolicy retryPolicy = new SimpleRetryPolicy(
3, Map.of(OptimisticLockException.class, true)
);
ExponentialBackOffPolicy backOffPolicy = new ExponentialBackOffPolicy();
backOffPolicy.setInitialInterval(300);
backOffPolicy.setMultiplier(2.0);
backOffPolicy.setMaxInterval(2000);
template.setRetryPolicy(retryPolicy);
template.setBackOffPolicy(backOffPolicy);
return template;
}
}
- 최대 3회 재시도
- 300ms → 600ms → 1200ms 간격으로 대기
OptimisticLockException발생 시 재시도
6. 좋아요 기능 적용
@Service
@RequiredArgsConstructor
public class PostLikeService {
private final RetryTemplate retryTemplate;
private final PostRepository postRepository;
private final PostLikeRepository postLikeRepository;
@Transactional
public void toggleLike(Long postId, Long memberId) {
retryTemplate.execute(context -> {
Post post = postRepository.findByIdWithOptimisticLock(postId)
.orElseThrow(PostNotFoundException::new);
boolean liked = postLikeRepository.existsByPostIdAndMemberId(postId, memberId);
if (liked) {
postLikeRepository.deleteByPostIdAndMemberId(postId, memberId);
post.decreaseLikeCount();
} else {
postLikeRepository.save(new PostLike(postId, memberId));
post.increaseLikeCount();
}
return null;
});
}
}
이제 낙관적 락 충돌이 발생하더라도 자동으로 재시도가 수행된다.
그러나 이 정책이 실제 부하 환경에서도 효과적일까?
7. ExponentialBackOffPolicy 적용 후 K6 테스트 결과
이 구조가 실전에서 얼마나 안정적으로 동작하는지를 확인하기 위해
K6 부하 테스트를 수행했다.
테스트 개요
- 테스트 대상:
/post/{id}/likeAPI - 목적: 동시에 같은 게시글에 좋아요 요청 시 성공률 검증
- 환경: VU 100 → 200까지 점진적 증가
- 정책:
Retry 8~10,Multiplier 1.5~2.0,Initial 200~300ms
7-1. 테스트 결과 요약
| Script | VU | Retry | Mult | 👍 성공률 | ❌ 실패율 | 평균 응답 | 최대 응답 | p95 |
|---|---|---|---|---|---|---|---|---|
| like-test2 | 100 | 8 | 1.5 | 50% | 25.0% | 2.29s | 6.84s | 6.83s |
| like-test2 | 200 | 8 | 1.5 | 78.5% | 10.75% | 2.58s | 8.62s | 8.61s |
| like-test2 | 200 | 9 | 1.8 | 83.5% | 8.25% | 2.15s | 12.41s | 12.37s |
| like-test2 | 200 | 10 | 2.0 | 80.5% | 9.75% | 3.14s | 17.58s | 17.54s |
7-2. 분석
- VU 100 수준에서는 성공률 80~90%로 비교적 양호
- 그러나 200 이상에서는 성공률이 급격히 하락
- 재시도 횟수를 늘려도 개선 폭이 제한적
- 최대 응답 시간은 최대 17초 이상까지 증가
이 현상은 모든 요청이 같은 간격(지수 증가)으로 재시도되기 때문이다.
즉, 재시도 타이밍이 다시 겹치며 락 경합이 재발생했다.
8. ExponentialBackOffPolicy의 구조적 한계와 개선 방향
ExponentialBackOffPolicy는 재시도 시마다 대기 시간을 지수적으로 늘리는 방식이다.
이론적으로는 부하를 완화하기 위한 구조지만,
모든 트랜잭션이 동일한 알고리즘과 파라미터로 동작하면
다음과 같은 현상이 발생한다.
- 재시도 타이밍이 일치한다.
- 락 경합이 다시 집중된다.
- 성공률이 하락하고 응답 지연이 증가한다.
결과적으로, “한 발 늦게 재시도하려던 설계”가
현실에서는 “모두 동시에 늦게 재시도”하는 구조로 변해버린다.
즉, 지수 백오프는 네트워크 장애나 일시적 처리 지연에는 효과적이지만,
동시성 충돌을 완화하는 데에는 한계가 있다.
VU 200 이상 테스트에서 이 문제가 명확히 드러났으며,
락 충돌이 완전히 해소되지 않아 성공률이 80~90% 수준에 머물렀다.
9. ExponentialRandomBackOffPolicy로의 전환
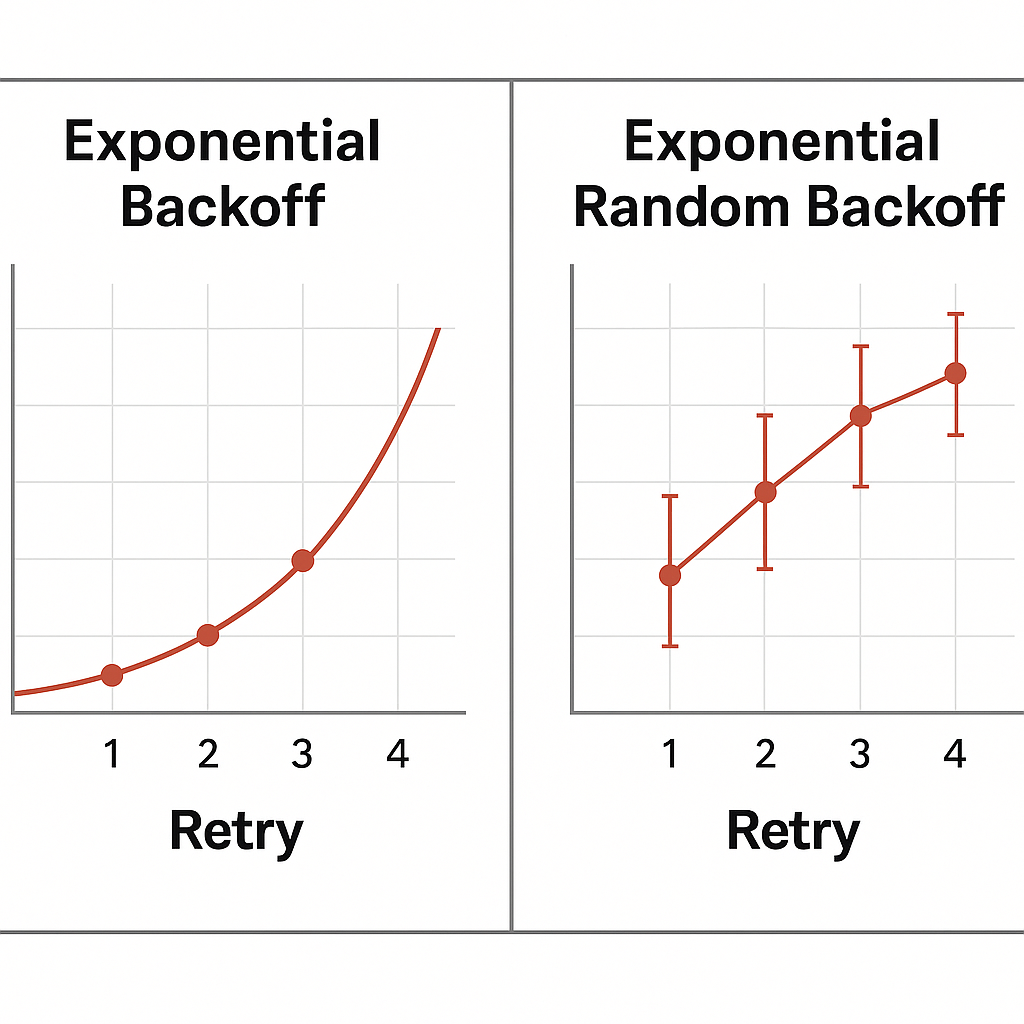
📊 Exponential은 동일 간격으로 증가하지만, RandomBackOff는 각 요청의 대기 간격을 무작위로 분산시켜 충돌 타이밍을 줄인다.
이 시점에서 문제의 본질은 “대기 시간의 형태”가 아니라 “타이밍의 일치”였다.
즉, 모두가 같은 시점에 재시도하기 때문에 락 충돌이 반복되는 구조였다.
이를 해결하기 위해 선택한 접근이
ExponentialRandomBackOffPolicy,
즉 무작위 지연(Random Jitter)을 도입하는 방식이다.
이 정책은 기존 지수 백오프 구조를 유지하면서도,
각 요청마다 재시도 간격을 미세하게 달리해 재시도 타이밍을 분산시킨다.
- 기존: 300 → 600 → 1200ms (고정된 간격)
- 개선: 300~600 → 600~1200 → 1200~2400ms (무작위 분산)
결과적으로 각 요청이 서로 다른 타이밍으로 재시도되어
락 해제 시점이 자연스럽게 분산되고,
DB 부하 및 충돌 확률이 감소하게 된다.
이제 다음 편에서는
ExponentialBackOffPolicy와ExponentialRandomBackOffPolicy를
같은 조건에서 비교 실험하고,
무작위 분산이 실제로 시스템 성공률과 안정성에 어떤 차이를 만드는지
테스트 데이터와 내부 동작 코드를 기반으로 검증한다.
